Risoluzione dei problemi relativi agli errori del controllo di integrità di Intersight per i cluster HX
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
In questo documento viene descritto come risolvere i problemi relativi agli errori comuni di Intersight Health Check per i cluster Hyperflex.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
- Nozioni di base su NTP (Network Time Protocol) e DNS (Domain Name System).
- Comprensione di base della riga di comando di Linux.
- Conoscenza di base di VMware ESXi.
- Conoscenza di base dell'editor di testo VI.
- Operazioni cluster Hyperflex.
Componenti usati
Le informazioni fornite in questo documento si basano su:
Hyperflex Data Platform (HXDP) 5.0.1(2a) e versioni successive
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Cisco Intersight offre la capacità di eseguire una serie di test su un cluster Hyperflex per garantire che lo stato del cluster sia in condizioni ottimali per le operazioni quotidiane e le attività di manutenzione.
A partire da HX 5.0(2a), Hyperflex introduce nella riga di comando di Hyperflex un account utente diag con privilegi di risoluzione dei problemi escalati. Connettersi a Hyperflex Cluster Management IP (CMIP) utilizzando SSH come utente amministrativo e quindi passare a diag.
HyperFlex StorageController 5.0(2d)
admin@192.168.202.30's password:
This is a Restricted shell.
Type '?' or 'help' to get the list of allowed commands.
hxshell:~$ su diag
Password:
____ __ _____ _ _ _ _____
| ___| / /_ _ | ____(_) __ _| |__ | |_ |_ _|_ _____
|___ \ _____ | '_ \ _| |_ | _| | |/ _` | '_ \| __| _____ | | \ \ /\ / / _ \
___) | |_____| | (_) | |_ _| | |___| | (_| | | | | |_ |_____| | | \ V V / (_) |
|____/ \___/ |_| |_____|_|\__, |_| |_|\__| |_| \_/\_/ \___/
|___/
Enter the output of above expression: 5
Valid captcha
diag#Risoluzione dei problemi
Correzione di ESXi VIB Verifica "Alcuni dei VIB installati utilizzano vmkAPI obsolete"
Quando si esegue l'aggiornamento a ESXi 7.0 e versioni successive, Intersight garantisce che gli host ESXi in un cluster Hyperflex non dispongano di driver creati con dipendenze di versioni precedenti di vmkapi. VMware fornisce un elenco dei vSphere Installation Bundle (VIB) interessati e descrive il problema in questo articolo: KB 78389
Accedere all'interfaccia utente Web (UI) di Hyperflex Connect e selezionare System Information. Fare clic su Nodi e selezionare il nodo Hyperflex (HX). Quindi, fare clic su Accedi alla modalità di manutenzione HX.
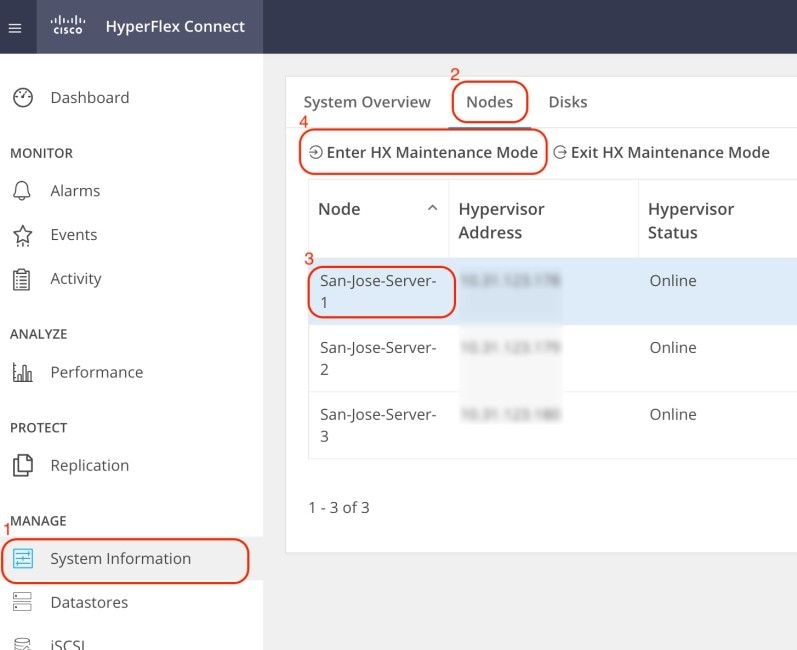
Utilizzare un client SSH per collegarsi all'indirizzo IP di gestione dell'host ESXi. Confermare quindi i VIB sull'host ESXi con questo comando:
esxcli software vib listRimuovere il file VIB con questo comando:
esxcli software vib remove -n driver_VIB_nameRiavviare l'host ESXi. Quando torna online, da HX Connect, selezionare il nodo HX e fare clic su Exit HX Maintenance Mode.
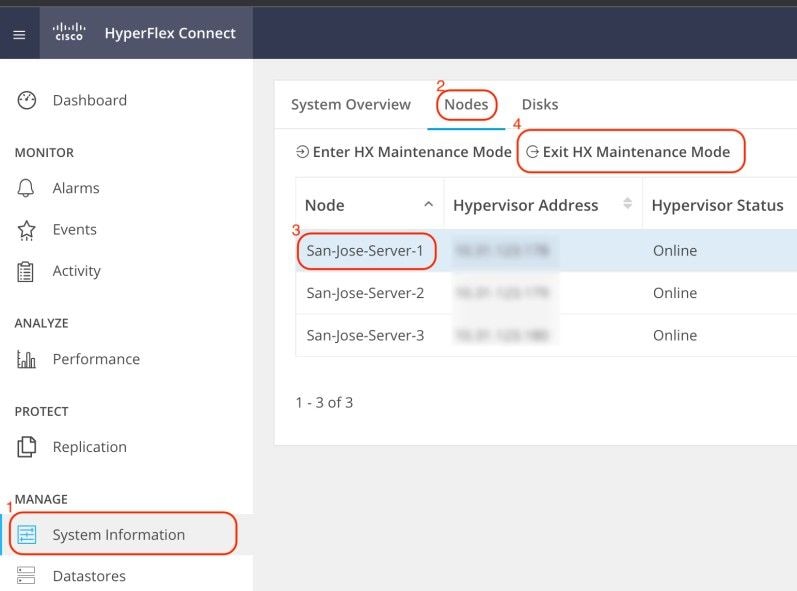
Attendere che il cluster HX diventi integro. Eseguire quindi gli stessi passaggi per gli altri nodi del cluster.
Fix vMotion Enabled "VMotion è disabilitato sull'host ESXi"
Questo controllo assicura che vMotion sia abilitato su tutti gli host ESXi nel cluster HX. Da vCenter, ciascun host ESXi deve disporre di uno switch virtuale (vSwitch) e di un'interfaccia vmkernel per vMotion.
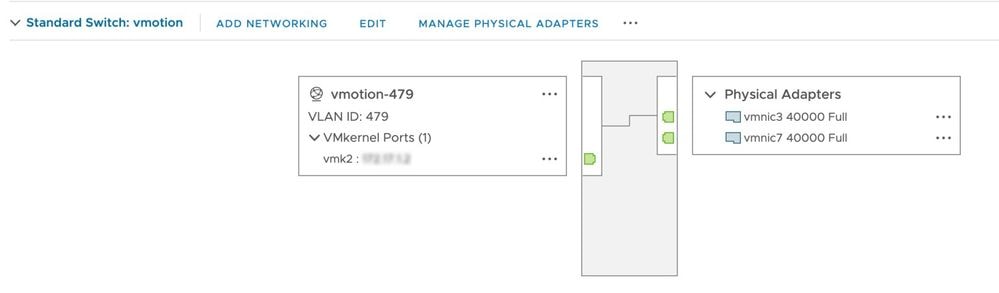
Connettersi a Hyperflex Cluster Management IP (CMIP) utilizzando SSH come utente amministrativo e quindi eseguire questo comando:
hx_post_installSelezionare l'opzione 1 per configurare vMotion:
admin@SpringpathController:~$ hx_post_install
Select hx_post_install workflow-
1. New/Existing Cluster
2. Expanded Cluster (for non-edge clusters)
3. Generate Certificate
Note: Workflow No.3 is mandatory to have unique SSL certificate in the cluster. By Generating this certificate, it will replace your current certificate. If you're performing cluster expansion, then this option is not required.
Selection: 1
Logging in to controller HX-01-cmip.example.com
HX CVM admin password:
Getting ESX hosts from HX cluster...
vCenter URL: 192.168.202.35
Enter vCenter username (user@domain): administrator@vsphere.local
vCenter Password:
Found datacenter HX-Clusters
Found cluster HX-01
post_install to be run for the following hosts:
HX-01-esxi-01.example.com
HX-01-esxi-02.example.com
HX-01-esxi-03.example.com
Enter ESX root password:
Enter vSphere license key? (y/n) n
Enable HA/DRS on cluster? (y/n) y
Successfully completed configuring cluster HA.
Disable SSH warning? (y/n) y
Add vmotion interfaces? (y/n) y
Netmask for vMotion: 255.255.254.0
VLAN ID: (0-4096) 208
vMotion MTU is set to use jumbo frames (9000 bytes). Do you want to change to 1500 bytes? (y/n) y
vMotion IP for HX-01-esxi-01.example.com: 192.168.208.17
Adding vmotion-208 to HX-01-esxi-01.example.com
Adding vmkernel to HX-01-esxi-01.example.com
vMotion IP for HX-01-esxi-02.example.com: 192.168.208.18
Adding vmotion-208 to HX-01-esxi-02.example.com
Adding vmkernel to HX-01-esxi-02.example.com
vMotion IP for HX-01-esxi-03.example.com: 192.168.208.19
Adding vmotion-208 to HX-01-esxi-03.example.com
Adding vmkernel to HX-01-esxi-03.example.com
Nota: per i cluster Edge distribuiti con HX Installer, è necessario eseguire lo script hx_post_install dalla CLI di HX Installer.
Correzione controllo connettività vCenter "Controllo connettività vCenter non riuscito"
Connettersi a Hyperflex Cluster Management IP (CMIP) utilizzando SSH come utente amministrativo e switch per diagnosticare l'utente. Verificare che il cluster HX sia registrato in vCenter con questo comando:
diag# hxcli vcenter info
Cluster Name : San_Jose
vCenter Datacenter Name : MX-HX
vCenter Datacenter ID : datacenter-3
vCenter Cluster Name : San_Jose
vCenter Cluster ID : domain-c8140
vCenter URL : 10.31.123.186L'URL di vCenter deve visualizzare l'indirizzo IP o il nome di dominio completo (FQDN) del server vCenter. Se le informazioni visualizzate non sono corrette, registrare nuovamente il cluster HX con vCenter con questo comando:
diag# stcli cluster reregister --vcenter-datacenter MX-HX --vcenter-cluster San_Jose --vcenter-url 10.31.123.186 --vcenter-user administrator@vsphere.local
Reregister StorFS cluster with a new vCenter ...
Enter NEW vCenter Administrator password:
Cluster reregistration with new vCenter succeededVerificare che esista una connettività tra HX CMIP e vCenter con questi comandi:
diag# nc -uvz 10.31.123.186 80
Connection to 10.31.123.186 80 port [udp/http] succeeded!
diag# nc -uvz 10.31.123.186 443
Connection to 10.31.123.186 443 port [udp/https] succeeded!Correggi controllo stato pulitura "Controllo pulitura non riuscito"
Connettersi a Hyperflex CMIP utilizzando SSH come utente amministrativo e quindi passare a diag. Eseguire questo comando per identificare il nodo in cui il servizio di pulitura non è in esecuzione:
diag# stcli cleaner info
{ 'type': 'node', 'id': '7e83a6b2-a227-844b-87fb-f6e78e6a59be', 'name': '172.16.1.6' }: ONLINE
{ 'type': 'node', 'id': '8c83099e-b1e0-6549-a279-33da70d09343', 'name': '172.16.1.8' }: ONLINE
{ 'type': 'node', 'id': 'a697a21f-9311-3745-95b4-5d418bdc4ae0', 'name': '172.16.1.7' }: OFFLINEIn questo caso, 172.16.1.7 è l'indirizzo IP della macchina virtuale del controller di archiviazione (SCVM) in cui la pulitura non è in esecuzione. Connettersi all'indirizzo IP di gestione di ciascuna SCVM nel cluster utilizzando SSH, quindi cercare l'indirizzo IP di eth1 con questo comando:
diag# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 00:0c:29:38:2c:a7
inet addr:172.16.1.7 Bcast:172.16.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
RX packets:1036633674 errors:0 dropped:1881 overruns:0 frame:0
TX packets:983950879 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:723797691421 (723.7 GB) TX bytes:698522491473 (698.5 GB)Avviare il servizio di pulizia nel nodo interessato con questo comando:
diag# sysmtool --ns cleaner --cmd startCorreggere lo stato del servizio NTP "Stato servizio NTPD inattivo"
Connettersi a HX CMIP utilizzando SSH come utente amministrativo e quindi passare a diag user. Eseguire questo comando per verificare che il servizio NTP sia stato arrestato.
diag# service ntp status
* NTP server is not runningSe il servizio NTP non è in esecuzione, eseguire questo comando per avviarlo.
diag# priv service ntp start
* Starting NTP server
...done.Correzione raggiungibilità server NTP "Controllo raggiungibilità server NTP non riuscito"
Connettersi a HX CMIP utilizzando SSH come utente amministrativo e quindi passare a diag user. Verificare che il cluster HX abbia server NTP raggiungibili configurati. Eseguire questo comando per visualizzare la configurazione NTP nel cluster.
diag# stcli services ntp show
10.31.123.226Verificare che esista una connettività di rete tra ogni SCVM nel cluster HX e il server NTP sulla porta 123.
diag# nc -uvz 10.31.123.226 123
Connection to 10.31.123.226 123 port [udp/ntp] succeeded!Se il server NTP configurato nel cluster non è più in uso, è possibile configurare un server NTP diverso nel cluster.
stcli services ntp set NTP-IP-Address
Avviso: il set ntp dei servizi stcli sovrascrive la configurazione NTP corrente nel cluster.
Correggere la raggiungibilità del server DNS "Controllo di raggiungibilità DNS non riuscito"
Connettersi a HX CMIP utilizzando SSH come utente amministrativo e quindi passare a diag user. Verificare che il cluster HX disponga di server DNS raggiungibili configurati. Eseguire questo comando per visualizzare la configurazione DNS nel cluster.
diag# stcli services dns show
10.31.123.226Verificare che esista una connettività di rete tra ogni SCVM nel cluster HX e il server DNS sulla porta 53.
diag# nc -uvz 10.31.123.226 53
Connection to 10.31.123.226 53 port [udp/domain] succeeded!Se il server DNS configurato nel cluster non è più in uso, è possibile configurare un server DNS diverso nel cluster.
stcli services dns set DNS-IP-AdrressAvviso: il set di DNS dei servizi stcli sovrascrive la configurazione DNS corrente nel cluster.
Correzione della versione della VM del controller "Valore della versione della VM del controller mancante nel file di impostazioni dell'host ESXi"
Questo controllo verifica che ogni SCVM includa guestinfo.stctlvm.version = "3.0.6-3" nel file di configurazione.
Accedere a HX Connect e verificare che il cluster sia integro.
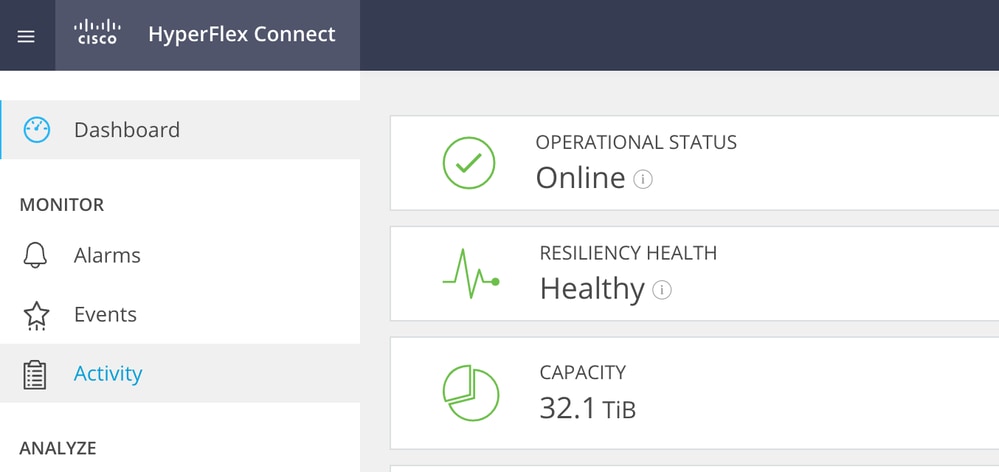
Connettersi a ciascun host ESXi nel cluster utilizzando SSH con l'account root. Quindi, eseguire questo comando
[root@San-Jose-Server-1:~] grep guestinfo /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx
guestinfo.stctlvm.version = "3.0.6-3"
guestinfo.stctlvm.configrdm = "False"
guestinfo.stctlvm.hardware.model = "HXAF240C-M4SX"
guestinfo.stctlvm.role = "storage"
Attenzione: il nome dell'archivio dati e il nome SCVM possono essere diversi nel cluster. È possibile digitare Primavera, quindi premere il tasto Tab per completare automaticamente il nome dell'archivio dati. Per il nome dello SCVM, è possibile digitare stCtl, quindi premere il tasto Tab per completare automaticamente il nome dello SCVM.
Se il file di configurazione di SCVM non include guestinfo.stctlvm.version = "3.0.6-3" accedere a vCenter e selezionare SCVM. Fare clic su Azioni, passare a Alimentazione e selezionare Arresta sistema operativo guest per spegnere normalmente SCVM.
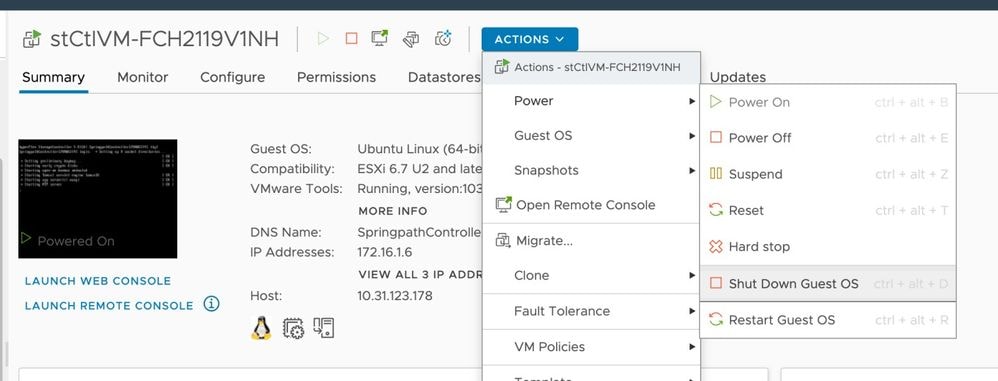
Dall'interfaccia CLI (Command Line Interface) ESXi, creare un backup del file di configurazione SCVM con questo comando:
cp /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx.bakEseguire quindi questo comando per aprire il file di configurazione di SCVM:
[root@San-Jose-Server-1:~] vi /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmxPremere il tasto I per modificare il file, quindi spostarsi alla fine del file e aggiungere questa riga:
guestinfo.stctlvm.version = "3.0.6-3"Premere ESC e digitare :wq per salvare le modifiche.
Identificare l'ID della macchina virtuale (VMID) della SCVM con il comando vim-cmd vmsvc/getallvms e ricaricare il file di configurazione della SCVM:
[root@San-Jose-Server-1:~] vim-cmd vmsvc/getallvms
Vmid Name File Guest OS Version Annotation
1 stCtlVM-FCH2119V1NH [SpringpathDS-FCH2119V1NH] stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx ubuntu64Guest vmx-15
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1Ricaricare e accendere SCVM con questi comandi:
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1
[root@San-Jose-Server-1:~] vim-cmd vmsvc/power.on 1Avviso: nell'esempio, il valore VMID è 1.
È necessario attendere il ripristino dello stato integro del cluster HX prima di passare al successivo SCVM.
Ripetere la stessa procedura una alla volta sugli SCVM interessati.
Infine, accedere a ciascuna SCVM utilizzando SSH e passare a un account utente specifico. Riavviare stMgr un nodo alla volta con questo comando:
diag# priv restart stMgr
stMgr start/running, process 22030Prima di passare al successivo SCVM, verificare che stMgr sia completamente operativo con questo comando:
diag# stcli about
Waiting for stmgr management server on port 9333 to get ready . .
productVersion: 5.0.2d-42558
instanceUuid: EXAMPLE
serialNumber: EXAMPLE,EXAMPLE,EXAMPLE
locale: English (United States)
apiVersion: 0.1
name: HyperFlex StorageController
fullName: HyperFlex StorageController 5.0.2d
serviceType: stMgr
build: 5.0.2d-42558 (internal)
modelNumber: HXAF240C-M4SX
displayVersion: 5.0(2d)Informazioni correlate
Attenzione: nell'esempio il valore VMID è 1.
Cronologia delle revisioni
| Revisione | Data di pubblicazione | Commenti |
|---|---|---|
2.0 |
06-Nov-2023 |
Release iniziale |
1.0 |
11-Oct-2023 |
Versione iniziale |
Contributo dei tecnici Cisco
- Carlos RazoCisco TAC Engineer
 Feedback
Feedback