Introduzione
Questo documento descrive Cisco Express Forwarding (CEF) switching e come viene implementato nel Cisco serie 12000 Internet Router.
Prerequisiti
Requisiti
Nessun requisito specifico previsto per questo documento.
Componenti usati
Il documento può essere consultato per tutte le versioni software o hardware.
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Convenzioni
Per ulteriori informazioni sulle convenzioni usate, consultare il documento Cisco sulle convenzioni nei suggerimenti tecnici.
Panoramica
La commutazione CEF (Cisco Express Forwarding) è una forma proprietaria di commutazione scalabile destinata a risolvere i problemi associati al demand caching. Con la commutazione CEF, le informazioni normalmente memorizzate in una cache route vengono suddivise in più strutture di dati. Il codice CEF è in grado di mantenere queste strutture di dati nel Gigabit Route Processor (GRP), e anche in processori secondari come le schede di linea nei router 12000. Le strutture di dati che consentono una ricerca ottimizzata per l'inoltro efficiente dei pacchetti includono:
-
La tabella Forwarding Information Base (FIB) - CEF utilizza un FIB per prendere decisioni di switching basate sul prefisso della destinazione IP. Il FIB è concettualmente simile a una tabella di routing o a una base di informazioni. e conserva un'immagine speculare delle informazioni di inoltro contenute nella tabella di routing IP. Quando si verificano modifiche di routing o topologia nella rete, la tabella di routing IP viene aggiornata e le modifiche vengono riflesse nel file FIB. Il FIB gestisce le informazioni sull'indirizzo dell'hop successivo in base alle informazioni contenute nella tabella di routing IP. Poiché esiste una correlazione uno-a-uno tra le voci FIB e le voci della tabella di routing, FIB contiene tutti i percorsi noti ed elimina la necessità di manutenzione della cache dei percorsi associata ai percorsi di switching, ad esempio l'opzione di commutazione rapida e quella ottimale.
-
Tabella di adiacenza: i nodi della rete sono definiti adiacenti se possono raggiungere l'uno l'altro con un solo hop attraverso un livello di collegamento. Oltre al FIB, il CEF utilizza tabelle adiacenti per aggiungere informazioni sull'indirizzamento di layer 2. La tabella adiacente mantiene gli indirizzi dell'hop successivo di layer 2 per tutte le voci FIB.
Il CEF può essere abilitato in una delle due modalità seguenti:
-
Modalità CEF centrale: quando la modalità CEF è attivata, le tabelle CEF FIB e adiacenze risiedono sul processore di routing e quest'ultimo esegue l'inoltro rapido. È possibile utilizzare la modalità CEF quando le schede di linea non sono disponibili per la commutazione CEF o quando è necessario utilizzare funzioni non compatibili con la commutazione CEF distribuita.
-
Modalità CEF (dCEF) distribuita - Quando dCEF è abilitato, le schede di linea mantengono copie identiche delle tabelle FIB e adiacenti. Le schede di linea sono in grado di eseguire l'inoltro rapido da sole, riducendo il coinvolgimento del processore principale, il Gigabit Route Processor (GRP), nell'operazione di commutazione. Questo è l'unico metodo di commutazione disponibile sui router Cisco serie 12000.
dCEF utilizza un meccanismo IPC (Inter-Process Communication) per garantire la sincronizzazione delle FIB e delle tabelle adiacenti sul processore di routing e sulle schede di linea.
Per ulteriori informazioni sulla commutazione CEF, consultare il white paper Cisco Express Forwarding (CEF).
Operazioni CEF
Aggiorna le tabelle di routing GRP
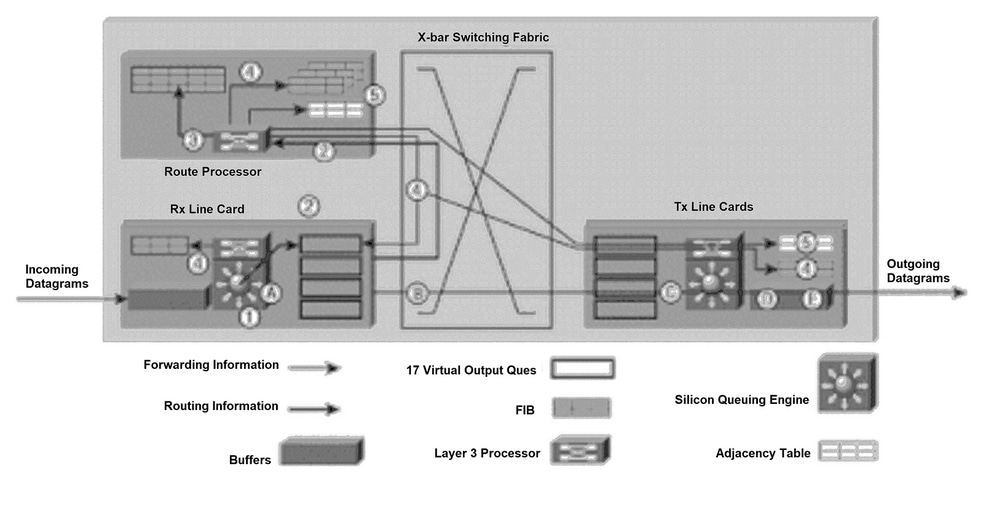
La Figura 1 illustra il processo con cui un pacchetto di aggiornamento del routing viene inviato al Gigabit Route Processor (GRP) e i messaggi di aggiornamento dell'inoltro risultanti vengono inviati alle tabelle FIB sulle schede di linea.
Per chiarezza, la numerazione dei paragrafi successivi corrisponde alla numerazione della Figura 1.
Il processo successivo si verifica durante l'inizializzazione della tabella di route o ogni volta che la topologia di rete cambia (quando le route vengono aggiunte, rimosse o modificate). Il processo illustrato nella Figura 1 prevede cinque fasi principali:
-
Un datagramma IP viene inserito nei buffer di input sulla scheda di linea ricevente (scheda di linea in entrata) e il motore di inoltro L2/L3 accede alle informazioni sul layer 2 e sul layer 3 nel pacchetto e lo invia al processore di inoltro. Il processore di inoltro determina che il pacchetto contiene informazioni di routing. Il processore di inoltro invia il puntatore alla coda di output virtuale (VOQ) GRP e indica che il pacchetto nella memoria buffer deve essere inviato al GRP.
-
La scheda di linea invia una richiesta all'orologio e alla scheda di programmazione (CSC, Scheduler Card). La scheda dello scheduler concede una sovvenzione e il pacchetto viene inviato al GRP attraverso il fabric di switching.
-
Il GRP elabora le informazioni di routing. R5000 (processore) sul GRP aggiorna la tabella di routing di rete. In base alle informazioni di routing contenute nel pacchetto, il processore di layer 3 può essere costretto a inviare le informazioni sullo stato del collegamento ai router adiacenti (se il protocollo di routing interno è Open Shortest Path First [OSPF]). Il processore genera i pacchetti IP che contengono le informazioni sullo stato del collegamento e l'aggiornamento interno per le tabelle FIB. Inoltre, il GRP calcola tutte le route ricorsive che si verificano quando viene fornito il supporto sia per un protocollo interno che per i protocolli gateway esterni (ad esempio, Border Gateway Protocol [BGP]).
Le informazioni sul percorso ricorsivo calcolate vengono inviate alle FIB su ciascuna scheda di linea. Ciò accelera in modo significativo il processo di inoltro, in quanto il processore di layer 3 sulla scheda di linea può concentrarsi sull'inoltro del pacchetto e non calcola il percorso ricorsivo.
-
Il GRP invia aggiornamenti interni alle tabelle FIB su tutte le schede di linea e include quelle presenti nel GRP. Gli aggiornamenti FIB alle schede di linea sono monitorati e limitati. Il GRP dispone di una copia di ogni tabella FIB della scheda di linea, quindi se viene inserita una nuova scheda di linea nello chassis, il GRP scarica le ultime informazioni di inoltro nella nuova scheda una volta che questa diventa attiva.
-
Il GRP riceve una notifica dalle schede di linea ogni volta che un nuovo router adiacente viene collegato al router 12000. Il processore sulla scheda di linea invia un pacchetto al GRP che contiene le nuove informazioni sul layer 2 (in genere informazioni dell'intestazione PPP (Point-to-Point Protocol)). Il GRP utilizza queste informazioni sul layer 2 per aggiornare la tabella adiacente situata sul GRP e sulle schede di linea. Ogni scheda di linea aggiunge queste informazioni di layer 2 a ciascun pacchetto quando questo viene inviato dal router 12000. Una copia della tabella adiacente viene conservata nel GRP a scopo di inizializzazione.
Figura 1: diagramma di determinazione del percorso e di switching di livello 3
 Determinazione del percorso e diagramma di switching di livello 3
Determinazione del percorso e diagramma di switching di livello 3
Inoltro pacchetti per tutte le schede di linea ad eccezione di OC48 e QOC12
Quando le schede di linea hanno informazioni di inoltro sufficienti per determinare il percorso attraverso il fabric di switching (ad esempio, la destinazione dell'hop successivo), il router 12000 è pronto per inoltrare i pacchetti. I passaggi seguenti descrivono la tecnica di inoltro semplice e rapido utilizzata dal router 12000 (vedere la Figura 1). Per chiarezza, le lettere dei paragrafi corrispondono alle lettere della Figura 1.
-
R. Un datagramma IP viene inserito nei buffer di input della scheda di linea ricevente (scheda di linea Rx) e il motore di inoltro L2/L3 accede alle informazioni di layer 2 e layer 3 nel pacchetto e lo invia al processore di inoltro. Il processore di inoltro determina che il pacchetto contiene dati e non è un aggiornamento di routing. In base alle informazioni sul layer 2 e sul layer 3 nella tabella FIB, il processore di inoltro invia il puntatore alla scheda di linea VOQ appropriata indicando che il pacchetto nella memoria buffer deve essere inviato a tale scheda di linea.
-
B. Lo scheduler della scheda di linea invia una richiesta allo scheduler. L'utilità di pianificazione rilascia una concessione e il pacchetto viene inviato dalla memoria buffer attraverso il fabric di switching alla scheda di linea (scheda di linea Tx).
-
C.La scheda di linea Tx memorizza i pacchetti in arrivo.
-
D.Il processore di layer 3 e i circuiti integrati specifici dell'applicazione (ASIC) associati sulla scheda di linea Tx collegano le informazioni di layer 2 (un indirizzo PPP) a ciascun pacchetto trasmesso. Il pacchetto viene duplicato per ciascuna porta sulla scheda di linea (se necessario).
-
E. I trasmettitori della scheda di linea Tx inviano il pacchetto attraverso l'interfaccia della fibra.
Il vantaggio di questo semplice processo di inoltro è che la maggior parte delle operazioni di trasmissione dei dati può essere eseguita in ASIC e consente al modello 12000 di funzionare a velocità gigabit. Inoltre, i pacchetti di dati non vengono mai inviati al GRP.
Inoltro pacchetti per schede di linea OC48 e QOC12
Quando le schede di linea dispongono di informazioni di inoltro sufficienti per determinare il percorso attraverso il fabric di switching (ad esempio, la destinazione dell'hop successivo), il router 12000 è pronto per inoltrare i pacchetti. I passaggi successivi costituiscono la tecnica di inoltro semplice e superveloce utilizzata dalla 12000 (vedere la Figura 2). Per chiarezza, le lettere dei paragrafi corrispondono alle lettere della Figura 2.
-
R. Un datagramma IP (non un aggiornamento di routing, ICMP (Internet Control Message Protocol) e pacchetti IP con opzioni) viene ricevuto nella scheda di linea e sottoposto all'elaborazione di layer 2. In base alle informazioni sul layer 2 e sul layer 3 nella tabella FIB locale, il Fast Packet Processor determina la destinazione del pacchetto e modifica l'intestazione del pacchetto. A seconda della destinazione, il pacchetto viene quindi collocato nella scheda di linea VOQ appropriata.
-
B. Nei rari casi in cui il Fast Packet Processor non è in grado di inoltrare correttamente il pacchetto, il pacchetto viene elaborato dal processore di inoltro. Il processore di inoltro, in base alle informazioni sul layer 2 e sul layer 3 della tabella FIB locale, invia il puntatore alla scheda di linea VOQ appropriata, che indica che il pacchetto nella memoria buffer deve essere inviato a quella scheda di linea.
-
C. Quando il pacchetto è nel VOQ appropriato, lo scheduler della scheda di linea invia una richiesta allo scheduler. L'utilità di pianificazione rilascia una concessione e il pacchetto viene inviato dalla memoria buffer attraverso il fabric di switching alla scheda di linea (scheda di linea Tx).
-
D. La scheda di linea Tx memorizza i pacchetti in arrivo.
-
E. Il processore di layer 3 e gli ASIC associati sulla scheda di linea Tx collegano le informazioni di layer 2 (un indirizzo PPP) a ciascun pacchetto trasmesso. Il pacchetto viene duplicato per ciascuna porta sulla scheda di linea (se necessario).
-
F. I trasmettitori della scheda di linea Tx inviano il pacchetto attraverso l'interfaccia della fibra.
Il vantaggio del nuovo processo di inoltro consiste nell'ottimizzazione della scheda per velocità più elevate, ad esempio OC48/STM16.
Figura 2: Packet Switching per schede di linea più veloci
 Packet Switching per schede di linea più veloci
Packet Switching per schede di linea più veloci
Informazioni correlate
 Feedback
Feedback