Introduzione
In questo documento viene descritto come risolvere i problemi relativi alla gestione degli errori di memoria sui server UCS.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti.
- Conoscenze base di UCS.
- Conoscenza di base dell'architettura di memoria.
Componenti usati
Le informazioni fornite in questo documento si basano sulle seguenti versioni software e hardware:
- UCS Family Server M5, M6, M7 e superiori.
- UCS Manager
- Cisco Integrated Management Controller (CIMC)
- Cisco Intersight Managed Mode (IMM)
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Errori di memoria
Si verificano errori di memoria quando si tenta di leggere un percorso di memoria. Il valore letto dalla memoria non corrisponde al valore previsto. Questi errori sono classificati in due tipi:
1. Errori soft
Gli errori soft sono transitori e non continuano a essere ripetuti. Questi sono temporanei e possono spesso essere corretti ripetendo la lettura o riscrivendo la posizione della memoria.
2. Errori gravi
Sono causati da difetti fisici permanenti. La riscrittura del percorso della memoria e il nuovo tentativo di accesso in lettura non eliminano un errore hardware. Di conseguenza, questo errore di memoria non può essere corretto e la memoria deve essere sostituita mentre l'errore continua a ripetersi.
Errori correggibili
Gli errori rilevati e corretti sono considerati correggibili. A tale scopo, è possibile riprovare la lettura o calcolare il contenuto corretto della memoria utilizzando i dati ECC (Error Correction Code) e riscrivendo i dati corretti in memoria. Dopo aver rilevato e corretto un errore, Cisco Integrated Management Controller (IMC) registra l'evento nel registro eventi di sistema.
In genere, gli errori correggibili sono il risultato di errori soft. Se gli errori correggibili persistono nella stessa posizione di memoria per un periodo di tempo prolungato, potrebbe indicare un potenziale errore hardware.
Adaptive Double Device Data Correction (ADDDC)
ADDDC Sparing è in grado di correggere due errori DRAM consecutivi se risiedono nella stessa regione. ADDDC sposta in modo dinamico i dati dai bit con errori alla memoria di riserva, impedendo che gli errori correggibili diventino non correggibili. Per attivare il meccanismo è necessaria una soglia di errori ECC correggibili.
ADDDC è utile in alcuni scenari in cui gli errori ECC correggibili precedono gli errori ECC non correggibili.
Post Package Repair (PPR)
Post Package Repair (PPR) è in grado di riparare in modo permanente le aree di memoria in errore all'interno di un modulo DIMM sfruttando le righe DRAM ridondanti. Questa riparazione permanente sul campo consente un rapido ripristino dagli errori hardware senza la necessità di sostituire la DIMM. Per eseguire un ripristino, il sistema deve sperimentare un evento ADDDC e passare attraverso almeno un ciclo di riavvio. Questa attività di ripristino non influisce sulle prestazioni o sulla memoria totale disponibile per il sistema operativo.
PPR e ADDDC sono abilitati per impostazione predefinita, ma possono essere configurati. PPR richiede l'attivazione anche della modalità RAS di riserva ADDDC. Se l'impostazione RAS è diversa da Risparmio ADDC o Predefinito piattaforma, PPR non è operativo. L'unica modalità PPR supportata è Hard PPR, il che significa che le riparazioni sono permanenti.
PCLS (Partial Cache Line Sparing)
Il controller della memoria contiene un meccanismo di prevenzione degli errori. Funziona identificando piccole porzioni di dati difettose in memoria. Questi percorsi danneggiati vengono registrati in una directory speciale, insieme ai dati di backup che possono sostituirli. Quando si accede alla memoria, se si verifica un errore in questi punti difettosi, il controller utilizza i dati di backup della directory per garantire il corretto funzionamento di tutti gli elementi.
Nota: le funzionalità sono disponibili in base all'architettura della CPU e alla versione del firmware in esecuzione sul server. Assicurarsi di essere nell'ultima versione consigliata per gestire meglio gli errori di memoria.
Risoluzione dei problemi relativi agli errori RAS
UCS Manager
In genere, questi errori vengono visualizzati in UCS Manager come un evento RAS.
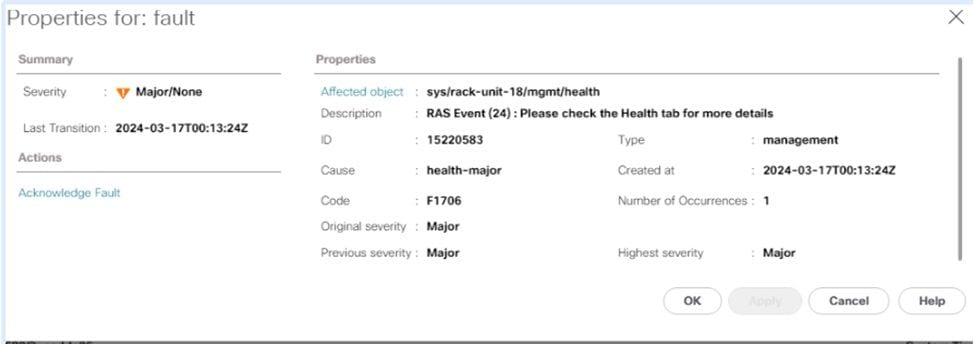
Nel riepilogo dello stato sono disponibili ulteriori informazioni sull'errore, ad esempio se è stato attivato PCLS o PPR.
Esempio di PCLS
Sui server M6 e versioni successive, è possibile abilitare il PCLS (Patrial Cache Line Sparing) come opzione del BIOS, un meccanismo di prevenzione degli errori. Il server deve essere riavviato il prima possibile, in modo che PPR possa avviare e riparare la DIMM. Una volta riavviato il server, monitorare altri errori di UCS Manager per lo stesso DIMM.
Come indicato nell'avviso, si consiglia di riavviare il server il prima possibile, poiché esiste il rischio associato di un errore irreversibile e, di conseguenza, un tempo di inattività imprevisto del server.
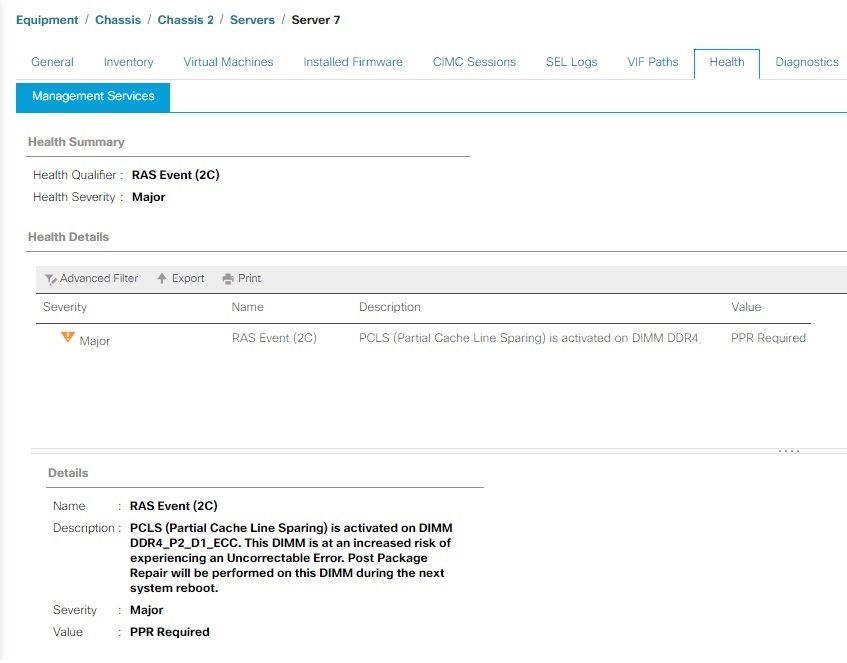
esempio PPR
Nel server sono abilitati ADDDC e PPR e si è verificato un evento RAS. Il guasto suggerisce il riavvio di PPR per ripristinare la DIMM. Il server deve essere riavviato il prima possibile affinché PPR avvii e ripristini la DIMM.
Una volta riavviato il server, monitorare altri errori di UCS Manager per lo stesso DIMM.
Come indicato nell'avviso, si consiglia di riavviare il server il prima possibile, poiché esiste il rischio associato di un errore irreversibile e, di conseguenza, un tempo di inattività imprevisto del server.
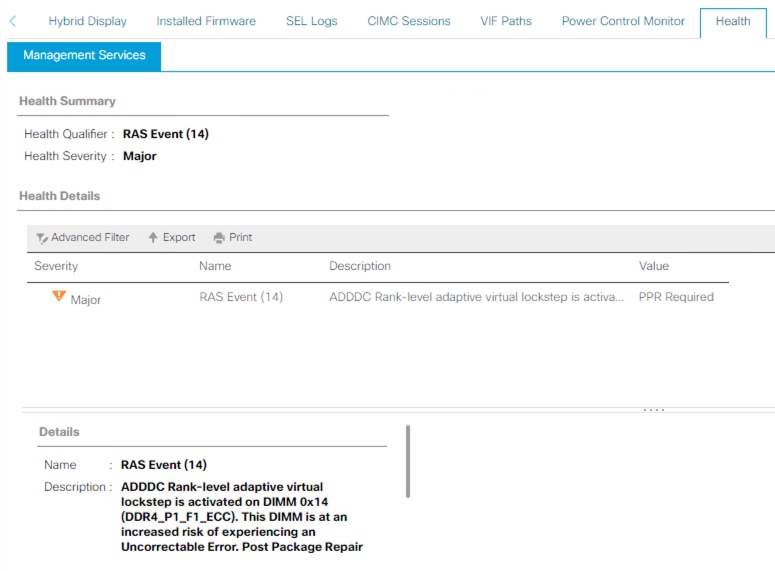
Modalità Intersight Managed
Nel server è abilitato ADDDC e si è verificato un evento BANK VLS che ha causato l'errore visualizzato. In questo scenario, il passo successivo consiste nell'eseguire al più presto il riavvio del server per consentire l'esecuzione di PPR.

Cisco Integrated Management Controller (CIMC)
L'errore viene visualizzato come mostrato quando si utilizza Cisco Integrated Management Controller. Se il server dispone di ADDDC e si è verificato un evento VLS, questa operazione funziona come previsto per impedire errori irreversibili.
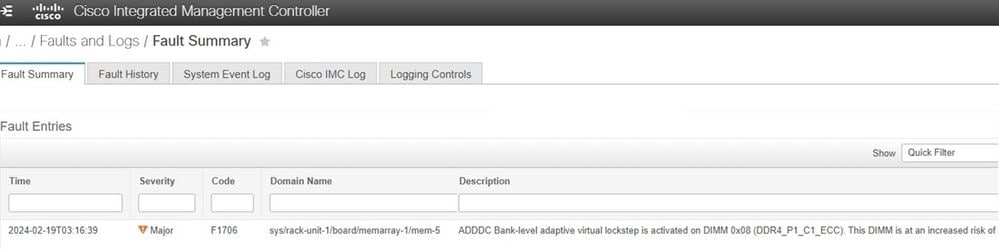
Procedura di risoluzione dei problemi
- Verificare che non siano presenti altri errori DIMM, ad esempio Errore irreversibile.
- Pianificare una finestra di manutenzione.
- Attivare la modalità di manutenzione per un host e riavviare il server per tentare di riparare definitivamente la DIMM utilizzando Post Package Repair (PPR).
Fasi del riavvio di UCSM
Nota: è possibile riavviare il server anche dal sistema operativo. In questo esempio viene utilizzata l'opzione di riavvio dell'interfaccia utente del server.
Passare all'interfaccia Web di UCS Manager.
Server blade
Passare a Apparecchiature > Chassis > Server X.
Server integrato
Selezionare Apparecchiature > Montaggi su rack > Server X.
Fare clic su Console KVM.
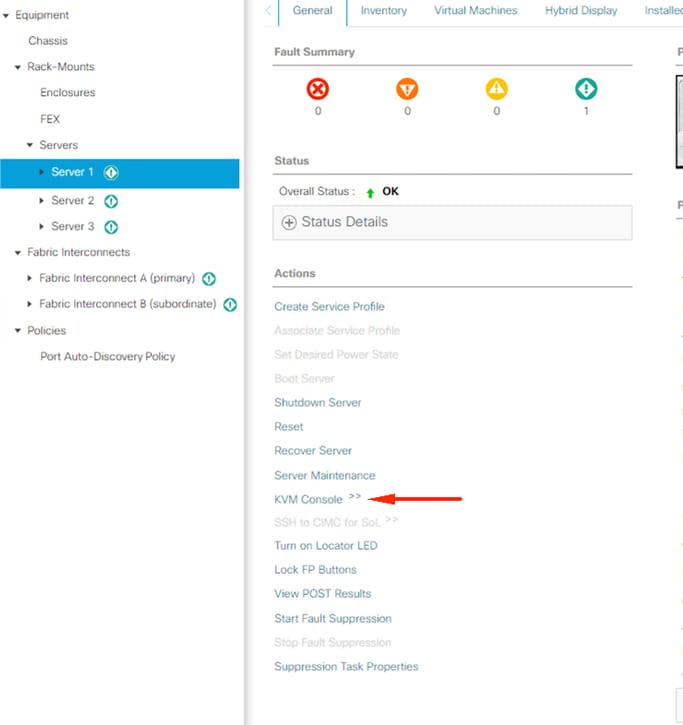
nelle finestre KVM, fare clic su azioni server, selezionare Reimposta, quindi fare clic su OK.
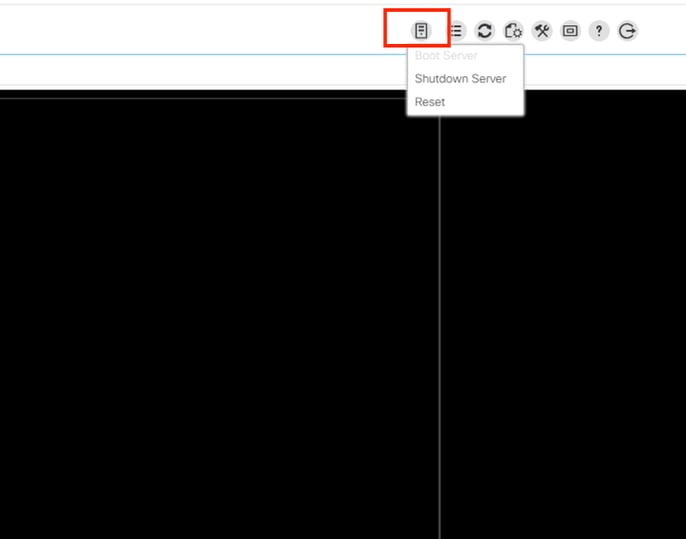
Monitorare il processo di riavvio dello switch KVM e verificare che il sistema operativo sia stato avviato correttamente.
Fasi del riavvio di IMM
Passare alla scheda Server, identificare il server e fare clic sul menu Azione (tre punti).
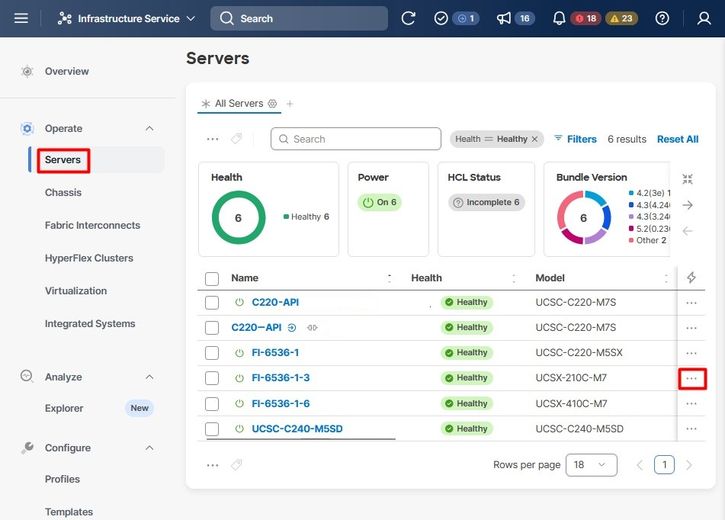
Selezionare quindi il menu Power e l'opzione Power Cycle.
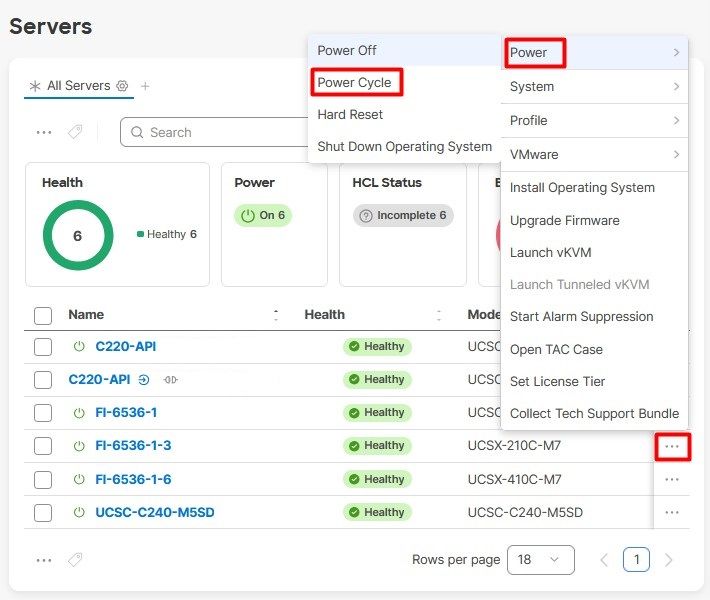
Fare clic sul pulsante Power Cycle per confermare l'azione.
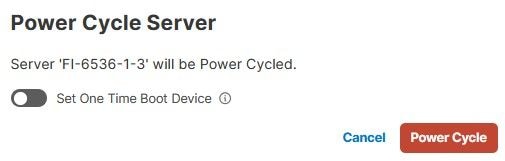
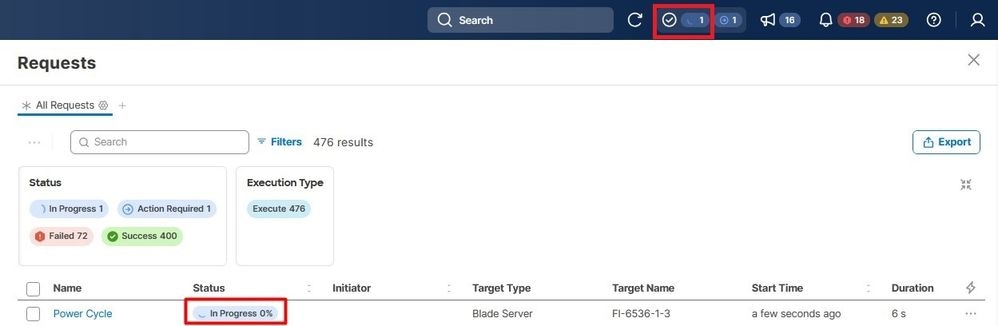
Convalidare l'avanzamento nel menu Richieste.
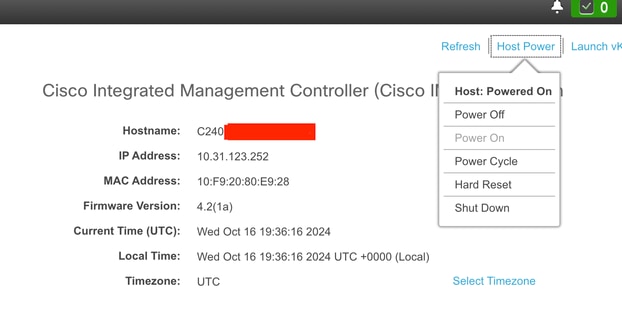
Procedura di riavvio di CIMC
Passare all'opzione Alimentazione host e selezionare Ciclo alimentazione.
Avviare lo switch KVM per monitorare il processo di riavvio e verificare che il sistema operativo venga avviato correttamente.
Esegui monitoraggio per nuovi errori
Se dopo il riavvio non si verificano errori, ovvero non sono presenti altri eventi RAS o errori correlati al DIMM, il processo PPR è riuscito e il server può essere riutilizzato.
Se si verificano nuovi eventi ADDDC, ripetere il processo di riavvio descritto nei passaggi precedenti per eseguire ulteriori riparazioni permanenti con PPR.
Se dopo il riavvio si verifica un errore irreversibile o un errore irreversibile, è necessario sostituire una memoria.
Nota: aprire una richiesta di assistenza in Cisco TAC per sostituire il DIMM, in caso si verifichi uno di questi problemi.
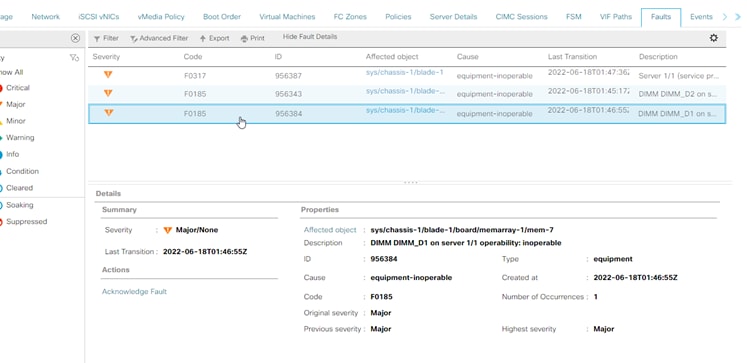
Errore di memoria non correggibile di UCS Manager
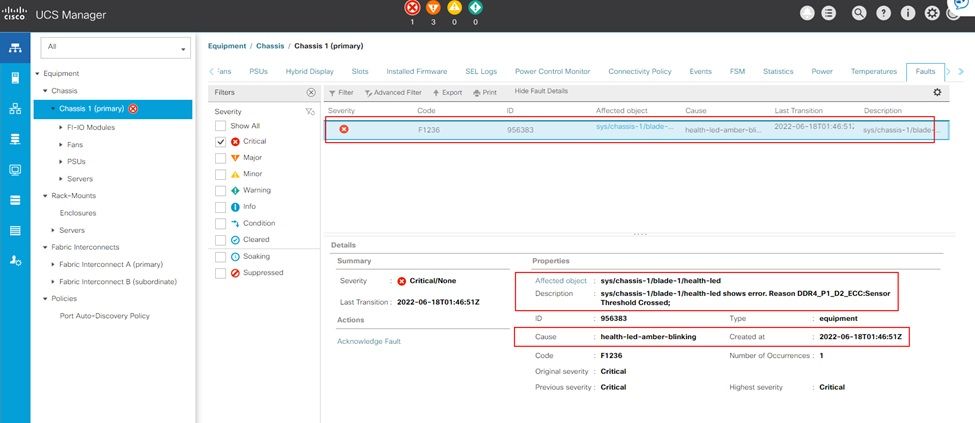
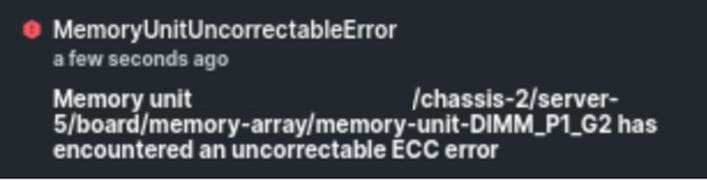
Errore irreversibile della memoria IMM
Errore irreversibile. Il guasto indica che il DIMM presenta un errore irreversibile e deve essere sostituito.
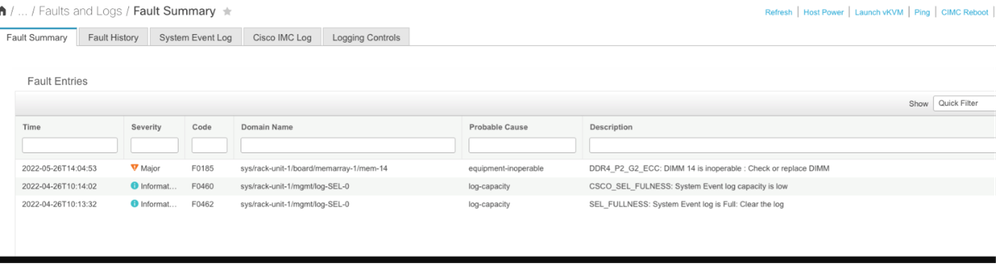
Errore di memoria non correggibile CIMC
Informazioni correlate
 Feedback
Feedback