Descrizione e risoluzione dei problemi di timeout di Astro/Lemans/NiceR sugli switch Catalyst serie 4000/4500
Sommario
Introduzione
Gli switch Catalyst serie 4000/4500 usano un design ASIC di stub nell'architettura dello switch. Switch gestisce questi ASIC stub linecard (Astro/Leman/NiceR) tramite un protocollo di controllo interno. Quando le richieste e le risposte di gestione interna vengono perse o ritardate, vengono generati messaggi della console e del syslog. Poiché le cause di queste perdite di comunicazione variano, la causa principale non è ovvia con questi messaggi di errore.
Lo scopo di questo documento è aiutare a comprendere il messaggio di timeout di Astro/Leman/Nicer generato sulla piattaforma Cat4000 e risolverlo con l'assistenza di Cisco TAC. Le versioni future di CatOS e Cisco IOS® offriranno messaggi di errore migliorati e, se possibile, identificheranno la root cause del problema.
Quando si verifica il timeout dello stub ASIC (Astro/Lemans/Nicer), vengono visualizzati messaggi simili a quelli riportati di seguito su uno switch Catalyst 4000/4500 con CatOS:
%SYS-4-P2_WARN: 1/Astro(4/3) - timeout occurred %SYS-4-P2_WARN: 1/Astro(4/3) - timeout is persisting
A seconda delle versioni del software, la formulazione del messaggio di errore può variare. Astro, Lemans e Nicer si riferiscono a diversi tipi di ASIC stub. Ulteriori dettagli sono descritti nella sezione Teoria di base di questo documento.
Per i Supervisor Cisco IOS (Supervisor II+, III e IV), il messaggio di errore viene visualizzato come segue:
%C4K_LINECARDMGMTPROTOCOL-4-INITIALTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - management request timed out. %C4K_LINECARDMGMTPROTOCOL-4-ONGOINGTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - consecutive management requests timed out.
Nota: questo documento tratta principalmente la risoluzione dei problemi sui Supervisor o sugli switch CatOS. Alcune informazioni, se note, sono applicabili al Supervisor basato su Cisco IOS.
Nota: anche questo documento si riferisce all'Astro stub ASIC, ma la maggior parte delle sezioni sono applicabili ad altri tipi di schede di linea ASIC (Lemans e Nicer) e come tali saranno annotate nelle sezioni appropriate.
Dopo aver letto questo documento, il lettore comprenderà quanto segue:
-
La funzione degli ASIC stub in Catalyst 4000/4500.
-
Le condizioni che possono portare ai messaggi di timeout dei pacchetti di gestione interni.
-
Le procedure da seguire e i comandi da raccogliere per Cisco TAC quando si risolve questo problema.
Le sezioni Timeout Astro e Risoluzione dei problemi forniscono informazioni di base e spiegazioni dettagliate su ciascun problema. In alternativa, è possibile passare direttamente alla sezione Metodi semplici per risolvere i problemi di questo documento.
Operazioni preliminari
Convenzioni
Per ulteriori informazioni sulle convenzioni usate, consultare il documento Cisco sulle convenzioni nei suggerimenti tecnici.
Prerequisiti
Non sono previsti prerequisiti specifici per questo documento.
Componenti usati
Questo documento è specifico per il Supervisor Catalyst 4000/4500 o per le schede di linea che utilizzano ASIC stub.
Nozioni di base
L'ASIC Astro stub si riferisce al gruppo di 8 porte 10/100 stub che controlla un gruppo di 8 porte 10/100 adiacenti in comunicazione con il Supervisor tramite una connessione Gigabit a larghezza di banda al backplane, come mostrato nella Figura seguente.
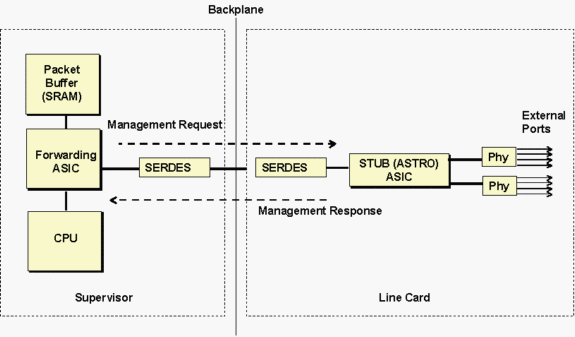
I supervisori comunicano con l'ASIC dello stub della scheda di linea tramite il componente SERDES (SERealizer-DESerializer). Sul lato Supervisor, è presente un componente SERDES che si collega al backplane, mentre sulla scheda di linea è presente un altro componente SERDES che si collega al backplane per ogni ASIC stub.
Il diagramma precedente può essere utilizzato in generale per risolvere i problemi relativi a diversi tipi di schede di linea. L'ASIC stub a cui si fa riferimento nei messaggi di timeout sarebbe diverso a seconda del tipo di scheda di linea. Per un elenco dei nomi ASIC e delle relative descrizioni, vedere la tabella seguente.
| ASIC stub | Descrizione | Esempio |
|---|---|---|
| Astro | ASIC stub controller 10/100 a 8 porte | WS-X4148-RJ45V |
| NiceR | ASIC stub a 4 porte 1000 | WS-X4418-GB (porte 3-18) |
| Lemani | ASIC stub controller 10/100/1000 a 8 porte | WS-X448-GB-RJ |
Il traffico di gestione interno passa attraverso il componente SERDES insieme al normale traffico di dati. Il traffico di gestione interno viene utilizzato per leggere/scrivere i registri ASIC e Phy dello stub. Le operazioni più comuni includono la lettura dello stato e delle statistiche dei collegamenti.
Metodi semplici di risoluzione dei problemi
Nelle sezioni seguenti vengono illustrati il significato e le possibili cause di %SYS-4-P2_WARN: 1/(Stub)(module_number/) Stub_reference - timeout detected error message on Catalyst 4000/4500.
I messaggi di timeout Astro (stub) sono stati aggiunti alla versione software a partire dalle 6.2.3 e 6.3.1 e successivamente migliorati nella 6.4.4 (CSCea73908) per indicare che Supervisor ha perso i pacchetti di controllo della gestione interna durante la comunicazione con Astro Astub ASIC su una scheda di linea 10/100. Le cause di questa perdita di comunicazione sono molteplici, come spiegato in dettaglio nella sezione Risoluzione dei problemi riportata di seguito.
Il seguente diagramma di flusso per la risoluzione dei problemi consente di isolare in modo semplice e rapido il problema tra le possibili cause principali:
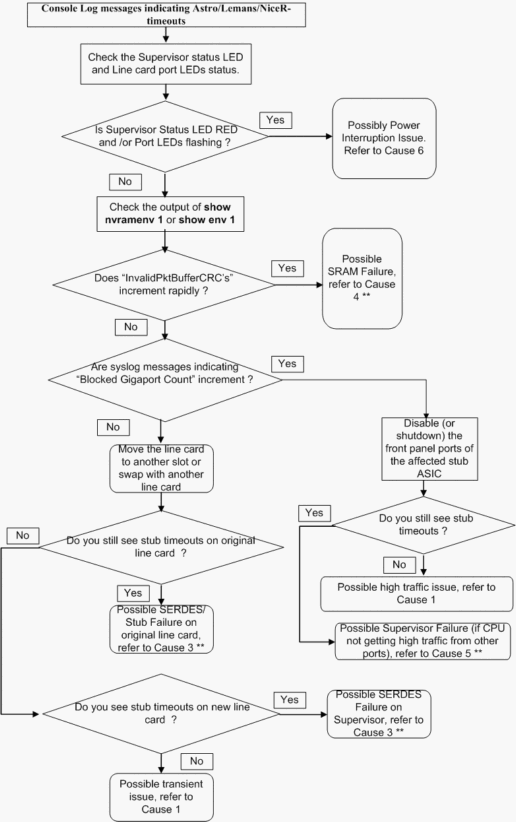
** Varie cause radice possono presentare sintomi simili. Contattare TAC per ulteriori informazioni sulla risoluzione dei problemi.
Timeout ASIC Stub (Astro/Lemans/NiceR)
I timeout Astro/Lemans/Nicer vengono segnalati quando il software Supervisor non riceve più risposte di gestione interna dall'ASIC dello stub della scheda di linea. Ciò può verificarsi se:
-
Richiesta di gestione persa o ritardata
-
Risposta di gestione persa o ritardata
Un messaggio "timeout..." viene stampato quando il software è scaduto per 10 volte consecutive in attesa della risposta del pacchetto di gestione. I timeout che ne derivano determinano la stampa di una "gestione consecutiva..." o "..timeout persistente.." a seconda della versione del software.
La velocità di questo messaggio registro è limitata a una volta ogni 10 minuti. L'inoltro del pacchetto agli ASIC dello stub interessati continua quando si verificano i timeout. Tuttavia, le modifiche apportate al collegamento / velocità automatica / duplex non vengono visualizzate perché il software non riceve le risposte del pacchetto di gestione. Inoltre, il processo di aggiornamento delle statistiche del traffico per il gruppo di interfacce è influenzato dal verificarsi di timeout.
Risoluzione dei problemi
Le cause per la visualizzazione dei messaggi di timeout Astro/Lemans/Nicer sono diverse. Di seguito sono descritte le varie modalità.
Causa 1: Carico di traffico elevato, loop di livello 2 o traffico di rete eccessivo verso la CPU
Di seguito vengono riportate le possibili condizioni di timeout dello stub:
-
Problemi di rete
-
Problemi di configurazione
-
Elementi adiacenti
-
Altri fattori al di fuori di uno switch Catalyst
Un loop di layer 2 o una tempesta broadcast che provoca un carico elevato del traffico può causare la perdita dei pacchetti di controllo della gestione interna. Ciò si verifica in genere quando la CPU è occupata (CPU inattiva) e non è in grado di elaborare le code.
Il traffico di controllo interno della gestione porta al Supervisor lo stesso percorso dati del normale traffico dati proveniente dall'Astro (o da qualsiasi altro chip Stub). Pertanto, i pacchetti di controllo potrebbero andare persi a causa della congestione.
Con la correzione dell'ID bug Cisco CSCea73908 (solo utenti registrati), il periodo di timeout per le richieste di gestione interne viene gestito meglio in CatOS versione 6.4(4) e successive. Questo miglioramento può impedire molti timeout dei pacchetti di controllo temporanei causati da CPU occupata.
Azione: Risolvere i problemi relativi al loop di layer 2; o modificare la configurazione per risolvere i modelli di traffico.
Soluzione temporanea: Spostare l'interfaccia di gestione dello switch (sc0) sulla VLAN del traffico non utente sugli switch con CatOS. Usare il comando set interface sc0 <vlan-id> per spostare la vlan dell'interfaccia sc0.
Nota: a partire da Cisco IOS 12.1(20)EW, i Supervisor basati su Cisco IOS introducono un miglioramento nella gestione del meccanismo di gestione dei pacchetti interno da parte della CPU. Questo miglioramento aiuterà a prevenire la perdita dei pacchetti di controllo della gestione interna a causa di traffico inavvertitamente a bassa priorità che blocca la CPU.
Soluzione: Vedere la soluzione precedente.
Causa 2: Cablaggio Half Duplex/Tipo 1A
Le porte utente del pannello anteriore sono configurate nella modalità half-duplex. Le collisioni tra il traffico in uscita e il traffico in entrata nell'ASIC dello stub possono causare un drenaggio molto lento del buffer dello stub. Ciò può causare il riempimento delle code tx sul Supervisor e l'eliminazione di nuove richieste di gestione interna con conseguente messaggio di errore di timeout.
Questo problema può essere causato anche da una rete con cavi di tipo 1A. Quando una workstation collegata a un server di tipo 1A con una patch RJ-45 viene disconnessa, il server esegue un loop all'interno e determina la restituzione del traffico in uscita. In questa situazione viene simulato il collegamento di un loopback esterno sulla porta del pannello anteriore. Prima che la porta passi allo stato di blocco, il traffico in uscita viene rimandato indietro allo switch. Ciò può causare l'overflow dei buffer di stub, a seconda della velocità del traffico.
Azione: Vedere soluzione alternativa.
Soluzione temporanea: Evitare la configurazione half-duplex. Nel caso dei cavi di tipo 1A, evitare di collegare il cavo patch RJ-45 al Balun di tipo 1A per evitare di formare un loopback interno nel Balun.
Soluzione: Vedere soluzione alternativa.
Causa 3: Errore componente SERDES
Se gli errori vengono rilevati solo su un Astro (o un altro ASIC stub) su un modulo e non si verifica alcun loop di layer 2, è molto probabile che il problema sia dovuto a un componente SERDES difettoso sul Supervisor o sulla Scheda di linea. Ad esempio, se il messaggio di errore è sempre su Astro 4 sul Modulo 3 come mostrato di seguito, il componente SERDES sul Modulo 3 o il componente SERDES sul Supervisor sono guasti.
%SYS-4-P2_WARN: 1/Astro(3/4) – timeout occurred
Nel messaggio di errore sopra riportato, il numero "4" tra parentesi si riferisce al numero Astro e non alla porta effettiva 3/4. Questo numero si riferisce a un gruppo di otto porte (3/3-3/40), in quanto si tratta della quarta Astro nel modulo 3.
Un componente SERDES difettoso può causare una connettività intermittente per il controllo del traffico e del traffico dati verso Astro/Lemans/NiceR, con conseguenti timeout. In genere, tuttavia, il messaggio di errore viene visualizzato continuamente se SERDES è difettoso.
Azione: Per determinare quale scheda (Supervisor o scheda di linea) SERDES è guasta, effettuare le seguenti operazioni:
-
Spostare la scheda di linea in uno slot di riserva nello chassis o in un altro chassis. Se è disponibile uno slot libero, sostituire gli slot con un modulo funzionante.
-
Se si continuano a ottenere timeout Astro/Lemans/Nicer sulla stessa Astro/Lemans/Nicer nella nuova slot, molto probabilmente la SERDES o l'Astro/Lemans/Nicer sulla scheda di linea ha fallito e la scheda di linea deve essere sostituita
Nota: reinserendo il modulo in uno slot di riserva, la diagnostica online viene eseguita sulla scheda di linea. Se viene rilevato un errore SERDES o Astro/Lemans/Nicer, lo switch contrassegnerà la porta come guasta.
-
Se i timeout non continuano a verificarsi sulla scheda di linea originale Astro/Lemans/Nicer, è possibile che il Supervisor SERDES sia difettoso. Per verificare questa condizione, inserire un modulo funzionante correttamente nello slot originale e verificare se i timeout si verificano con il nuovo modulo.
Se funziona, è possibile che SERDES sia sul Supervisor. Per un elenco dei numeri di serie interessati dal componente SERDES che causa il problema, consultare il avviso del campo Catalyst WS-X4013 Supervisor Exhibits Partial Loss of Connectivity (Il supervisore mostra la perdita parziale di connettività).
Soluzione temporanea: Nessuna
Soluzione: Per ulteriori informazioni sulla risoluzione dei problemi, contattare TAC.
Causa 4: Errore temporaneo/hard SRAM
I dispositivi collegati a Catalyst 4000 con Supervisor I o II o III o IV Engine o Catalyst 2948G, Cat2980G possono perdere parzialmente o completamente la connettività di rete. Il problema potrebbe riguardare alcune o tutte le porte. Questi sintomi saranno accompagnati da un rapido aumento dei pacchetti non validi CRC scartati nei messaggi di errore Supervisor basato su CatOS e ASIC stub.
Il problema è causato da un errore della memoria buffer del pacchetto (SRAM), che è un tipo rigido o temporaneo.
Azione: Selezionare l'azione da eseguire a seconda di quale delle due firme di errore temporaneo della memoria buffer del pacchetto riportate di seguito si è verificato:
-
Firma errore temporaneo memoria buffer pacchetto per SUP I , SUP II, 2948G, 2980G
Di seguito sono riportati i sintomi del problema:
-
Rapidi incrementi di InvalidPktBufferCRC con un messaggio simile al seguente
%SYS-4-P2_WARN: 1/Invalid crc, dropped packet, count = xxxx
-
Un reset a caldo con il comando reset impedirebbe al Supervisor di eseguire il POST.
-
Se viene eseguito un reset a freddo (ciclo di alimentazione), il Supervisor supererà il POST e non si verificherà più un errore.
Nota: in caso di errore della memoria buffer del pacchetto fisso per il Supervisor I, II, 2948G, 2980G, un reset a freddo non risolverebbe il problema e il POST continuerebbe ad avere esito negativo per il Supervisor o lo switch.
Per ulteriori informazioni su questo problema, fare riferimento all'ID bug Cisco CSCdy46288 (solo utenti registrati) per Supervisor II, all'ID bug Cisco CSCeb56266 (solo utenti registrati) per Supervisor I/2948G/2980G e all'ID bug Cisco CSCeb56325 (solo utenti registrati) per WS-C2980G-A.
-
-
Firma errore temporaneo memoria buffer pacchetto per SUP III, SUP IV
Di seguito sono riportati i sintomi del problema:
-
Il contatore VlanZeroBadCrc aumenta rapidamente e viene visualizzato nell'output del comando seguente:
show platform cpuport all (prior to 12.1(11b)EW1 ) or show platform cpu packet statistics all (Since 12.1(11b)EW1) depending upon the software version. Starting from 12.1(19)EW, you should also see the following error message rapidly incrementing errors: %C4K_SWITCHINGENGINEMAN-2-PACKETMEMORYERROR3: Persistent Errors in Packet Memory xxxx
-
Un reset a caldo provocherebbe il fallimento del POST da parte del Supervisor. Utilizzare il comando show diagnostics power-on per verificare l'errore.
-
Un hard reset (spegnimento e riaccensione) ripristinerà il Supervisor e supererà il POST.
Nota: in caso di errore hard SRAM per Supervisor III / IV, un reset a freddo non ripristinerebbe il Supervisor e mancherebbe comunque il POST.
Per ulteriori informazioni su questo problema sul Supervisor III/IV, fare riferimento all'ID bug Cisco CSCdz57255 (solo utenti registrati)
-
Soluzione temporanea: Spegnere e riaccendere lo switch o reimpostarlo a freddo in caso di problemi temporanei della SRAM. Il problema della SRAM rigida non offre soluzioni.
Soluzione: Per ulteriori informazioni sulla risoluzione dei problemi, contattare TAC.
Causa 5: Errore orologio supervisore
Se vengono visualizzati messaggi di errore di timeout Astro/Lemans/NiceR che fanno riferimento a più numeri di modulo o a più Astro/Lemans/Nicer, è possibile che si sia verificato un errore di clock sul Supervisor. In genere, un errore dell'orologio è accompagnato dal messaggio di errore Astro/Lemans/Nicer e dai messaggi di errore BlockTXQueue e BlockedGigaport, come mostrato di seguito:
%SYS-4-P2_WARN: 1/Blocked queue on gigaport ...
Azione: Per ulteriori informazioni sulla risoluzione dei problemi, contattare TAC per un ID bug Cisco CSCdp89537 (solo utenti registrati) e CSCdp93187 (solo utenti registrati).
Soluzione temporanea: Nessuna
Soluzione: Per ulteriori informazioni sulla risoluzione dei problemi, contattare TAC.
Causa 6: Interruzione alimentazione breve
Su uno switch Catalyst serie 4000 con Supervisor II (WS-X4013) potrebbe verificarsi uno stato in cui il Supervisor e le schede di linea non sono in grado di comunicare correttamente tra loro. Quando lo switch entra in questo stato, i LED di stato del modulo sono rossi (non lampeggianti) e/o i LED delle porte lampeggiano in sequenza, come nel caso di un modulo o di un reset dello switch. Il messaggio sarà accompagnato dai messaggi di timeout Astro/Lemans/NiceR.
Questo problema è causato da un'interruzione temporanea dell'alimentazione allo switch (inferiore a 500 ms). L'interruzione temporanea dell'alimentazione potrebbe essere dovuta a un'alimentazione instabile in un ambiente di produzione.
Azione: Vedere la soluzione seguente.
Soluzione temporanea: Ripristinare lo switch (soft o hard (spegnimento e riaccensione)).
Soluzione: Eseguire l'aggiornamento all'immagine software con la correzione per l'ID bug Cisco CSCea14710 (solo utenti registrati) o versioni successive.
Informazioni correlate
- Messaggi di errore comuni di CatOS sugli switch Catalyst serie 4000
- Risoluzione dei problemi hardware per gli switch Catalyst serie 4000/4912G/2980G/2948G
- Risoluzione dei problemi hardware e correlati su Catalyst 4000 e 4500 Supervisor III e IV
- Switch Catalyst serie 4000/4500 - Pagine di supporto
- Supporto della tecnologia di switching LAN
- Supporto dei prodotti per gli switch Catalyst LAN e ATM
- Documentazione e supporto tecnico – Cisco Systems
 Feedback
Feedback