Risoluzione dei problemi di replica del database CUCM
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Introduzione
In questo documento viene descritto come diagnosticare i problemi di replica del database e come risolverli con procedure apposite.
Procedura per la diagnosi dei problemi di replica del database
In questa sezione vengono descritti gli scenari in cui la replica del database viene interrotta e viene fornita la metodologia di risoluzione dei problemi per diagnosticare e isolare il problema.
Passaggio 1. Verificare che il processo di replica del database sia privo di errori
Per stabilire se durante la replica del database si sono verificati degli errori, è necessario conoscere i vari stati che può assumere lo strumento RTMT (Real Time Monitoring Tool) durante il processo.
| Valore | Significato | Descrizione |
|---|---|---|
| 0 |
Stato di inizializzazione |
La replica è in fase di configurazione. Se la replica rimane in questo stato per più di un'ora, è possibile che si verifichi un errore di installazione. |
| 1 |
Numero di repliche non corretto |
La configurazione è ancora in corso. Questo stato si riscontra raramente nelle versioni 6.x e 7.x; nella versione 5.x, indica che la configurazione è ancora in corso. |
| 2 |
La replica è corretta |
Le connessioni logiche sono state stabilite e le tabelle sono state associate agli altri server del cluster. |
| 3 |
Mancata corrispondenza tra le tabelle |
Le connessioni logiche vengono stabilite, ma non è chiaro se le tabelle corrispondono. Nelle versioni 6.x e 7.x, tutti i server possono mostrare lo stato 3 anche se un server del cluster è inattivo. Questo problema può verificarsi quando gli altri server non rilevano con certezza che l'aggiornamento della funzione User Facing Feature (UFF) è stato trasferito dal subscriber all'altro dispositivo del cluster. |
| 4 |
Configurazione non riuscita / interrotta |
Il server non dispone più di una connessione logica attiva per ricevere le tabelle del database sulla rete. In questo stato non è possibile effettuare alcuna replica. |
Per verificare la replica del database, eseguire il comando utils duplication runtimestate dalla CLI del nodo del server di pubblicazione, come mostrato in questa immagine.
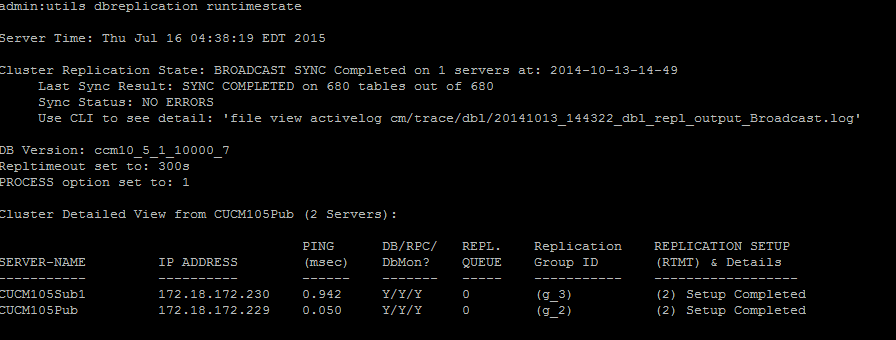
Nell'output, verificare che lo stato di replica del cluster non contenga informazioni obsolete sulla sincronizzazione. Controllare la stessa procedura e utilizzare l'indicatore orario.
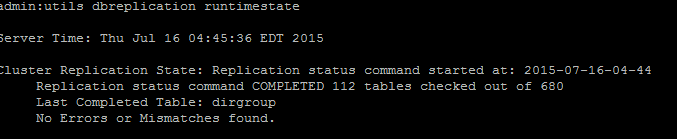
Se la sincronizzazione di broadcast non è aggiornata a una data recente, eseguire il comando utils dbreplication status per controllare tutte le tabelle e la replica. Se vengono rilevati errori o mancate corrispondenze, questi vengono visualizzati nell'output del comando e lo stato RTMT cambia di conseguenza, come mostrato nell'immagine.
o
Dopo aver eseguito il comando, vengono controllate tutte le tabelle per verificarne la coerenza e viene visualizzato lo stato aggiornato della replica.
Nota: Consentire il controllo di tutte le tabelle e quindi continuare con la risoluzione dei problemi.

Dopo aver visualizzato lo stato aggiornato della replica, controllare la configurazione della replica (RTMT) e i dettagli visualizzati nel primo output. Lo stato deve essere controllato su ciascun nodo. Se un nodo presenta uno stato diverso da 2, continuare con la risoluzione dei problemi.
Passaggio 2. Raccogliere lo stato del database CM dalla pagina Cisco Unified Reporting in CUCM
- Dopo aver completato il passaggio 1, scegliere l'opzione Cisco Unified Reporting dall'elenco a discesa Navigazione nell'autore di Cisco Unified Communications Manager (CUCM), come mostrato in questa immagine.
2. Selezionare System Reports (Report di sistema), quindi fare clic su Unified CM Database Status (Stato del database Unified CM) come mostrato in questa immagine.
3. Generare un nuovo report, fare clic sull'icona Generate New Report (Genera nuovo report) come mostrato in questa immagine.

4. Attendere che il nuovo report venga generato correttamente.

5. Una volta generato, fare clic sull'icona per scaricare il rapporto e salvarlo in modo che possa essere fornito a un tecnico TAC nel caso in cui sia necessario aprire una richiesta di assistenza (SR).

Passaggio 3. Esaminare il report del database Unified CM di qualsiasi componente contrassegnato come errore
Se i componenti contengono errori, questi vengono contrassegnati con un'icona a forma di X rossa, come mostrato nell'immagine.
-
Verificare che i database locale e del server di pubblicazione siano accessibili.
- In caso di errore, verificare la connettività di rete tra i nodi. Verificare se il servizio A Cisco DB viene eseguito dalla CLI del nodo e utilizza il comando utils service list.
- Se il servizio A Cisco DB è inattivo, eseguire il comando utils service start A Cisco DB per avviare il servizio. Se l'operazione non riesce, contattare Cisco TAC.
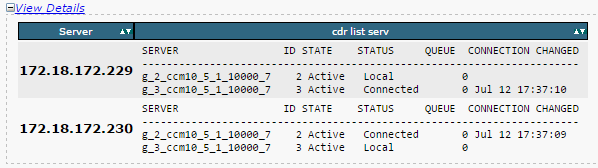
- Accertarsi che l'elenco dei server di replica (cdr list serv) sia popolato su tutti i nodi.
Questa immagine mostra un output ideale.
Se l'elenco di Cisco Database Replicator (CDR) è vuoto su alcuni nodi, fare riferimento al passaggio 8.
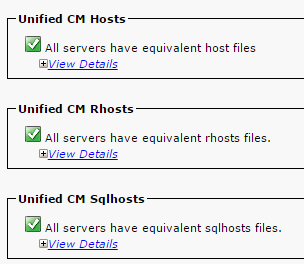
- Accertarsi che i file Hosts, Rhosts e Sqlhosts di Unified CM corrispondano su tutti i nodi.
Questo è un passaggio importante. Come mostrato in questa immagine, i file Hosts, Rhosts e Sqlhosts di Unified CM sono uguali su tutti i nodi.
I file Hosts non corrispondono:
Quando un indirizzo IP viene cambiato o aggiornato al nome host sul server, è possibile che si verifichino degli errori.
Fare riferimento al link seguente per modificare l'indirizzo IP con il nome host del CUCM.
Modifiche dell'indirizzo IP e del nome host
Riavviare questi servizi dalla CLI del server di pubblicazione e verificare che la mancata corrispondenza sia stata cancellata. In caso affermativo, andare al passaggio 8. In caso negativo, contattare Cisco TAC. Generare un nuovo report ogni volta che si apporta una modifica alla GUI/CLI per verificare che le modifiche siano effettivamente apportate.
Cluster Manager ( utils service restart Cluster Manager)
A Cisco DB ( utils service restart A Cisco DB)
I file Rhosts non corrispondono:
Se insieme ai file Hosts, anche i file Rhosts non corrispondono, seguire i passaggi indicati in I file Hosts non corrispondono. Se solo i file Rhosts non corrispondono, eseguire questo comando dalla CLI:
A Cisco DB ( utils service restart A Cisco DB ) Cluster Manager ( utils service restart Cluster Manager)
Generare un nuovo report e verificare che i file Rhosts siano uguali su tutti i server. In caso affermativo, andare al passaggio 8. In caso negativo, contattare Cisco TAC.
I file Sqlhosts non corrispondono:
Se insieme ai file Hosts, anche i file Sqlhosts non corrispondono, seguire i passaggi indicati in I file Hosts non corrispondono. Se solo i file Sqlhosts non corrispondono, eseguire questo comando dalla CLI:
utils service restart A Cisco DB
Generare un nuovo report e verificare se i file Sqlhosts corrispondono su tutti i server. In caso affermativo, andare al passaggio 8. In caso negativo, contattare Cisco TAC
-
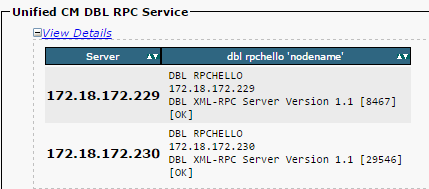
Verificare che la chiamata DBL RPC (Database Layer Remote Procedural Call) sia completata correttamente, come mostrato nell'immagine.
Se il pacchetto RPC Hello non funziona su un determinato nodo:
- Verificare la connettività di rete tra il nodo specifico e il publisher.
- Accertarsi che il numero di porta 1515 sia consentito sulla rete.
Fare riferimento a questo link per informazioni dettagliate sull'utilizzo della porta TCP/UDP:
Utilizzo delle porte TCP e UDP di Cisco Unified Communications Manager
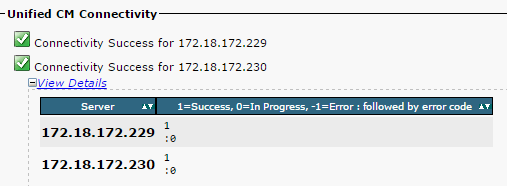
- Verificare che la connettività di rete sia stabilita correttamente tra i nodi, come mostrato nell'immagine:

Se la connettività di rete non riesce per i nodi:
- Accertarsi che i nodi siano raggiungibili sulla rete.
- Accertarsi che i numeri di porta TCP/UDP corretti siano autorizzati sulla rete.
Generare un nuovo report e verificare che la connessione sia corretta. In caso non sia possibile stabilire la connessione, andare al passaggio 8.
Passaggio 4. Controllare i singoli componenti che utilizzano il comando Utils Diagnose Test
Il comando utils diagnose test controlla tutti i componenti e restituisce un valore test superato o test non superato. I componenti essenziali per il corretto funzionamento della replica del database sono:
-
Connettività di rete:
Il comando validate_network controlla tutti gli aspetti della connettività di rete su tutti i nodi del cluster. Se è presente un problema di connettività, viene visualizzato un errore sul server DNS/RDNS (Domain Name Server/Reverse Domain Name Server). Il comando validate_network completa l'operazione in 300 secondi. Questi sono i messaggi di errore più comuni che possono essere generati dai test di connettività di rete:
1. Errore "Comunicazione intra-cluster interrotta", come mostrato in questa immagine.

- Causa
Questo errore si verifica quando uno o più nodi del cluster presentano un problema di connettività di rete. Verificare che tutti i nodi siano raggiungibili tramite ping.
- Effetto
La comunicazione tra cluster interrotta causa problemi di replica del database.
2. Ricerca DNS inversa non riuscita.
- Causa
Questo errore si verifica quando è impossibile effettuare la ricerca DNS inversa su un nodo. È tuttavia possibile verificare se il DNS è configurato e funziona correttamente quando si utilizzano i seguenti comandi:
utils network eth0 all - Shows the DNS configuration (if present) utils network host <ip address/Hostname> - Checks for resolution of ip address/Hostname
- Effetto
Se il DNS non funziona correttamente, potrebbero verificarsi problemi di replica del database quando i server vengono definiti e utilizzano i nomi host.
-
Raggiungibilità del protocollo NTP (Network Time Protocol):
L'NTP è responsabile di mantenere l'ora del server sincronizzata con l'orologio di riferimento. Il publisher sincronizza sempre l'ora a quella del dispositivo il cui indirizzo IP risulta nell'elenco dei server NTP; i subscriber sincronizzano l'ora a quella del publisher.
È estremamente importante che il protocollo NTP funzioni correttamente per evitare problemi di replica del database.
È essenziale che lo strato NTP (numero di hop fino all'orologio di riferimento principale) sia inferiore a 5, altrimenti viene ritenuto inaffidabile.
Per verificare lo stato NTP, attenersi a questa procedura:
- Utilizzare il comando utils diagnose test per verificare l'output, come mostrato nell'immagine.
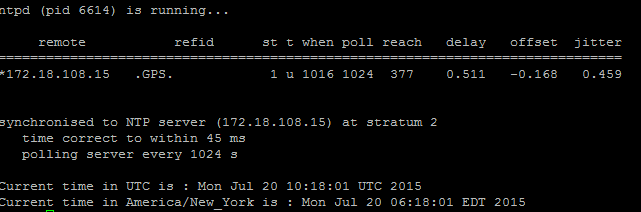
2. Inoltre, è possibile eseguire questo comando:
utils ntp status
Passaggio 5. Controllare lo stato di connettività su tutti i nodi e verificare che siano autenticati
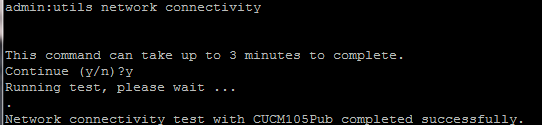
- Dopo aver completato il passaggio 4, se non sono stati segnalati errori, eseguire il comando utils network connectivity su tutti i nodi per verificare che la connettività ai database sia corretta, come mostrato nell'immagine.

2. Se si riceve il messaggio di errore "Impossibile inviare pacchetti TCP/UDP", verificare se la rete ha ricevuto ritrasmissioni o bloccare le porte TCP/UDP. Il comando show network cluster permette di controllare che tutti i nodi siano stati autenticati.
3. Se lo stato del nodo non è autenticato, verificare che la connettività di rete e la password di protezione siano uguali su tutti i nodi, come mostrato in questa immagine.
Fare riferimento a questi link per modificare o reimpostare le password di sicurezza:
Come reimpostare le password su CUCM
Ripristino della password dell'amministratore di sistema CUCM
Passaggio 6. Usare il comando utils dbreplication runtimestate per visualizzare gli stati dei nodi non sincronizzati o non richiesti
Tenere sempre presente che la replica del database è un'attività che richiede molte risorse di rete, in quanto invia le tabelle aggiornate a tutti i nodi del cluster. Accertarsi che:
-
I nodi si trovino nello stesso data center o sito e quindi tutti i nodi siano raggiungibili con un tempo di round trip, o RTT (Round Trip Time), minimo. Se il valore RTT è insolitamente elevato, verificare le prestazioni della rete.
-
I nodi siano sparsi sull'intera WAN (Wide Area Network) Verificare che la connettività di rete dei nodi sia inferiore a 80 ms. Se alcuni nodi non sono in grado di partecipare al processo di replica, aumentare il parametro a un valore superiore, come mostrato.
utils dbreplication setprocess <1-40>
Nota: Quando si modifica questo parametro, vengono migliorate le prestazioni di configurazione della replica, ma vengono utilizzate ulteriori risorse di sistema.
-
Il timeout di replica si basa sul numero di nodi presenti nel cluster. Il timeout di replica (impostazione predefinita: 300 secondi) è il tempo di attesa del publisher su tutti i subscriber prima di inviare messaggi specifici. Calcolare il timeout di replica in base al numero di nodi del cluster.
Server 1-5 = 1 Minute Per Server Servers 6-10 = 2 Minutes Per Server Servers >10 = 3 Minutes Per Server.
Example: 12 Servers in Cluster : Server 1-5 * 1 min = 5 min, + 6-10 * 2 min = 10 min, + 11-12 * 3 min = 6 min, Repltimeout should be set to 21 Minutes.
Comandi per controllare o impostare il timeout di replica:
show tech repltimeout ( To check the current replication timeout value ) utils dbreplication setrepltimeout ( To set the replication timeout )
Dopo aver completato l'elenco di controllo, eseguire i passaggi 7 e 8:
Elenco di controllo:
- La connettività è stabilita su tutti i nodi. Fare riferimento al passaggio 5.
- RPC è raggiungibile. Fare riferimento al passaggio 3.
- Consultare Cisco TAC prima di procedere con i passaggi 7 e 8 nel caso di nodi superiori a 8.
- Eseguire la procedura durante l'orario di lavoro del centro TAC.
Passaggio 7. Ripristino di tutte le tabelle selettive per la replica del database
Se il comando utils dbreplication runtimestate mostra errori o mancate corrispondenze nelle tabelle, eseguire questo comando:
Utils dbreplication repair all
Eseguire il comando utils dbreplication runtimestate per controllare nuovamente lo stato.
Se lo stato non cambia, andare al passaggio 8.
Passaggio 8. Ripristino della replica di database da zero
Fare riferimento alla sequenza per reimpostare la replica del database e avviare il processo da zero.
utils dbreplication stop all (Only on the publisher) utils dbreplication dropadmindb (First on all the subscribers one by one then the publisher) utils dbreplication reset all ( Only on the publisher )
Per monitorare il processo, eseguire il comando RTMT/utils dbreplication runtimestate.
Fare riferimento alla sequenza per reimpostare la replica del database di uno specifico nodo:
utils dbreplication stop <sub name/IP> (Only on the publisher) utils dbreplcation dropadmindb (Only on the affected subscriber) utils dbreplication reset <sub name/IP> (Only on the publisher )
Se si raggiunge Cisco TAC per ulteriore assistenza, verificare che vengano forniti i seguenti output e i rapporti:
utils dbreplication runtimestate utils diagnose test utils network connectivity
Report:
- Il report del database Cisco Unified Reporting CM (fare riferimento al passaggio 2).
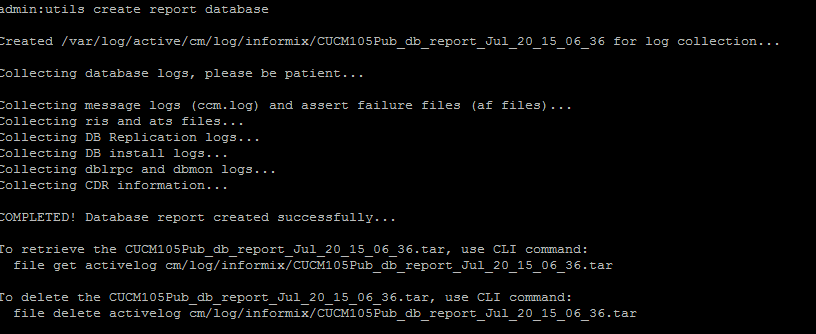
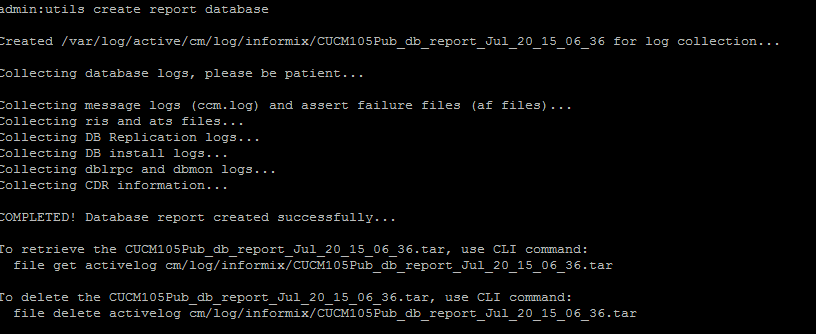
- Eseguire il comando utils create report database dalla CLI. Scaricate il file .tar e utilizzate un server SFTP.
Informazioni correlate
Cronologia delle revisioni
| Revisione | Data di pubblicazione | Commenti |
|---|---|---|
4.0 |
12-Nov-2024 |
Testo alternativo, traduzione automatica e formattazione aggiornati. |
1.0 |
13-Aug-2021 |
Versione iniziale |
Contributo dei tecnici Cisco
- Kaustubh AcharekarCisco TAC Engineer
- Jose Pablo Villalobos UrenaCisco TAC Engineer
 Feedback
Feedback