Informazioni sul ritardo nelle reti voce dei pacchetti
Sommario
Introduzione
Quando si progettano reti che trasportano la voce su pacchetti, frame o infrastrutture cellulari, è importante comprendere e tenere conto dei componenti di ritardo nella rete. Se si tiene conto in modo corretto di tutti i potenziali ritardi, le prestazioni complessive della rete saranno accettabili. La qualità vocale complessiva è una funzione di molti fattori, tra cui l'algoritmo di compressione, gli errori e la perdita di frame, la cancellazione dell'eco e il ritardo. Questo documento spiega le cause del ritardo quando si usano router/gateway Cisco su reti di pacchetti. Anche se gli esempi sono adattati a Frame Relay, i concetti sono applicabili anche alle reti Voice over IP (VoIP) e Voice over ATM (VoATM).
Flusso vocale di base
Il flusso di un circuito vocale compresso è mostrato nel diagramma. Il segnale analogico del telefono viene digitalizzato in segnali PCM (Pulse Code Modulation) dal codec voce-decoder (codec). Gli esempi PCM vengono quindi passati all'algoritmo di compressione che comprime la voce in un formato pacchetto per la trasmissione sulla WAN. Sul lato più lontano della nuvola le stesse funzioni vengono eseguite in ordine inverso. L'intero flusso è mostrato nella Figura 2-1.
Figura 2-1 Flusso vocale end-to-end 
A seconda della configurazione della rete, il router/gateway può eseguire sia le funzioni di codec che quelle di compressione o solo una di esse. Ad esempio, se si usa un sistema voce analogico, il router/gateway esegue la funzione CODEC e la funzione di compressione, come mostrato nella Figura 2-2.
Figura 2-2 Funzione codec in Router/Gateway 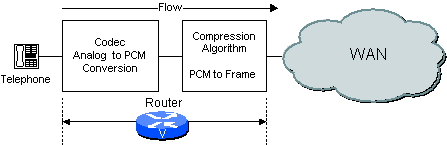
Se si utilizza un PBX digitale, il PBX esegue la funzione di codec e il router elabora i campioni PCM passati dal PBX. Un esempio è mostrato nella Figura 2-3.
Figura 2-3 Funzione codec in PBX 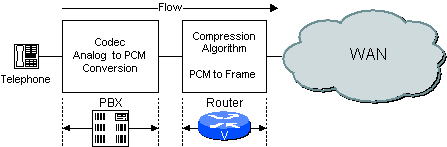
Come funziona la compressione vocale
Gli algoritmi di compressione ad alta complessità utilizzati nei router/gateway Cisco analizzano un blocco di campioni PCM forniti dal codec voce. Questi blocchi variano in lunghezza in base al codificatore. Ad esempio, la dimensione di blocco di base utilizzata da un algoritmo G.729 è 10 ms, mentre la dimensione di blocco di base utilizzata dagli algoritmi G.723.1 è 30 ms. Un esempio di come funziona un sistema di compressione G.729 è mostrato nella Figura 3-1.
Figura 3-1 Compressione vocale 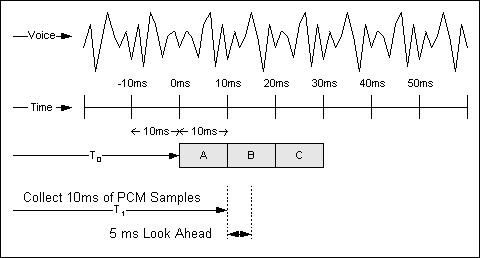
Lo streaming vocale analogico viene digitalizzato in campioni PCM e consegnato all'algoritmo di compressione in incrementi di 10 ms. Lo sguardo al futuro è discusso in Algorithmic Delay.
Standard per i limiti di ritardo
L'Unione internazionale delle telecomunicazioni (UIT) prende in considerazione il ritardo della rete per le applicazioni vocali nella raccomandazione G.114. La presente raccomandazione definisce tre fasce di ritardo unidirezionale, come indicato nella tabella 4.1.
Tabella 4.1 Specifiche del ritardo
| Intervallo in millisecondi | Descrizione |
|---|---|
| 0-150 | Accettabile per la maggior parte delle applicazioni utente. |
| 150-400 | Accettabile, a condizione che gli amministratori siano a conoscenza dei tempi di trasmissione e dell'impatto che questo ha sulla qualità di trasmissione delle applicazioni degli utenti. |
| Oltre 400 | Inaccettabile per la pianificazione generale della rete. Si riconosce tuttavia che in alcuni casi eccezionali tale limite è superato. |
Nota: queste raccomandazioni si riferiscono ai collegamenti con l'eco adeguatamente controllati. Ciò implica che vengono utilizzate le tecniche di eliminazione dell'eco. Se il ritardo unilaterale supera i 25 ms (G.131), è richiesta la cancellazione dell'eco.
Queste raccomandazioni sono rivolte alle amministrazioni nazionali delle telecomunicazioni. Pertanto, queste restrizioni sono più severe di quelle applicate normalmente nelle reti voce private. Quando la posizione e le esigenze aziendali degli utenti finali sono ben note al progettista della rete, un ritardo maggiore può rivelarsi accettabile. Per le reti private, 200 ms di ritardo sono un obiettivo ragionevole e 250 ms un limite. Tutte le reti devono essere progettate in modo da conoscere e ridurre al minimo il ritardo massimo previsto della connessione vocale.
Origini del ritardo
Esistono due tipi distinti di ritardo, definiti fisso e variabile.
-
I componenti a ritardo fisso aggiungono direttamente al ritardo complessivo della connessione.
-
I ritardi variabili derivano dai ritardi di accodamento nei buffer del trunk in uscita sulla porta seriale connessa alla WAN. Questi buffer creano ritardi variabili, denominati jitter, nella rete. I ritardi variabili vengono gestiti tramite il buffer di deformazione sul router/gateway ricevente. Il buffer per la riduzione dell'instabilità è descritto nella sezione Ritardo dejitter (Δn) di questo documento.
La Figura 5-1 identifica tutte le sorgenti di ritardo fisse e variabili presenti nella rete. Ciascuna fonte è descritta in dettaglio nel presente documento.
Figura 5-1: Origini ritardo 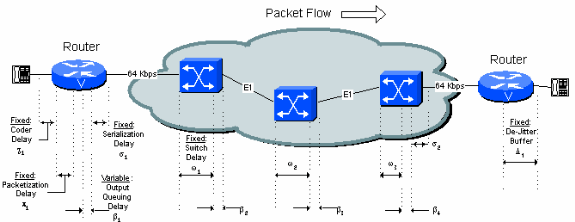
Ritardo codificatore (elaborazione)
Il ritardo del codificatore è il tempo impiegato dal DSP (Digital Signal Processor) per comprimere un blocco di campioni PCM. Questo processo viene anche denominato ritardo di elaborazione (χn). Questo ritardo varia in base al codificatore vocale utilizzato e alla velocità del processore. Ad esempio, gli algoritmi ACELP (algebraic code excited linear prediction) analizzano un blocco di 10 ms di campioni PCM e quindi li comprimono.
Il tempo di compressione per un processo Conjugate Structure Algebraic Code Excited Linear Prediction (CS-ACELP) varia da 2,5 ms a 10 ms in base al caricamento del processore DSP. Se il DSP dispone di quattro canali vocali, il ritardo del codificatore è di 10 ms. Se il DSP è caricato con un solo canale vocale, il ritardo del codificatore è di 2,5 ms. Per scopi di progettazione utilizzare il tempo peggiore tra 10 ms.
Il tempo di decompressione è all'incirca il 10% del tempo di compressione per ogni blocco. Tuttavia, il tempo di decompressione è proporzionale al numero di campioni per fotogramma a causa della presenza di più campioni. Di conseguenza, il tempo di decompressione peggiore per un frame con tre campioni è 3 x 1 ms o 3 ms. Di solito, due o tre blocchi di uscita G.729 compressa vengono inseriti in un frame mentre un campione di uscita G.723.1 compressa viene inviato in un singolo frame.
I ritardi migliori e peggiori del codificatore sono indicati nella tabella 5.1.
Tabella 5.1 Ritardo di elaborazione caso migliore e caso peggiore
| Coder | Velocità | Blocco di esempio obbligatorio | Ritardo codice caso migliore | Ritardo codice caso peggiore |
|---|---|---|---|---|
| ADPCM, G.726 | 32 Kbps | 10 ms | 2.5 ms | 10 ms |
| CS-ACELP, G.729A | 8.0 Kbps | 10 ms | 2.5 ms | 10 ms |
| MP-MLQ, G.723.1 | 6.3 Kbps | 30 ms | 5 ms | 20 ms |
| MP-ACELP, G.723.1 | 5.3 Kbps | 30 ms | 5 ms | 20 ms |
Ritardo algoritmico
L'algoritmo di compressione si basa su caratteristiche vocali note per elaborare correttamente il blocco campione N. L'algoritmo deve avere una certa conoscenza di ciò che si trova nel blocco N+1 al fine di riprodurre accuratamente il blocco campione N. Questo sguardo in avanti, che è in realtà un ulteriore ritardo, è chiamato ritardo algoritmico. In questo modo la lunghezza del blocco di compressione aumenta.
Questo accade ripetutamente, in modo che il blocco N+1 guarda nel blocco N+2, e così via e così via. L'effetto netto è un'aggiunta di 5 ms al ritardo complessivo sul collegamento. Ciò significa che il tempo totale richiesto per elaborare un blocco di informazioni è 10 m con un fattore di sovraccarico costante di 5 ms. Vedere la Figura 3-1: Compressione vocale.
-
Il ritardo algoritmico per i codificatori G.726 è di 0 ms
-
Il ritardo algoritmico per i coder G.729 è di 5 ms.
-
Il ritardo algoritmico per i coder G.723.1 è di 7,5 ms
Per gli esempi riportati nella parte restante di questo documento, si supponga che la compressione G.729 abbia un payload di 30 ms/30 byte. Per facilitare la progettazione e adottare un approccio conservativo, le tabelle riportate nella parte restante di questo documento presuppongono il ritardo peggiore tra i codici. Il ritardo del codificatore, il ritardo di decompressione e il ritardo algoritmico vengono raggruppati in un fattore chiamato ritardo del codificatore.
L'equazione utilizzata per generare il parametro lumped Coder Delay è:
Equazione 1: Parametro ritardo codificatore lumped 
Il ritardo del codice raggruppato per G.729 utilizzato nel prosieguo del presente documento è:
Tempo di compressione peggiore per blocco: 10 ms
Tempo di decompressione per blocco x 3 blocchi 3 ms
Ritardo algoritmico 5 ms —
Totale (18 ms)
Ritardo di pacchettizzazione
Il ritardo di pacchettizzazione (πn) è il tempo necessario per riempire un payload del pacchetto con parlato codificato/compresso. Questo ritardo è una funzione della dimensione del blocco campione richiesta dal vocoder e del numero di blocchi inseriti in un singolo fotogramma. Il ritardo della pacchettizzazione può anche essere chiamato ritardo di accumulazione, poiché i campioni vocali si accumulano in un buffer prima di essere rilasciati.
In genere, il ritardo per la pacchettizzazione dei pacchetti non deve essere superiore a 30 ms. Sui router/gateway Cisco è necessario usare le seguenti cifre della tabella 5.2 in base alle dimensioni del payload configurate:
Tabella 5.2. Pacchettizzazione comune
| Coder | Dimensioni payload (byte) | Ritardo pacchettizzazione (ms) | Dimensioni payload (byte) | Ritardo pacchettizzazione (ms) | |
|---|---|---|---|---|---|
| PCM, G.711 | 64 Kbps | 160 | 20 | 240 | 30 |
| ADPCM, G.726 | 32 Kbps | 80 | 20 | 120 | 30 |
| CS-ACELP, G.729 | 8.0 Kbps | 20 | 20 | 30 | 30 |
| MP-MLQ, G.723.1 | 6.3 Kbps | 24 | 24 | 60 | 48 |
| MP-ACELP, G.723.1 | 5.3 Kbps | 20 | 30 | 60 | 60 |
È necessario bilanciare il ritardo della pacchettizzazione con il carico della CPU. Minore è il ritardo, maggiore è la frequenza dei frame e maggiore è il carico sulla CPU. Su alcune piattaforme meno recenti, i payload di 20 ms potrebbero sovraccaricare la CPU principale.
Ritardo pipeline nel processo di pacchettizzazione
Anche se ogni campione di voce sperimenta sia un ritardo algoritmico che un ritardo di pacchettizzazione, in realtà, i processi si sovrappongono e c'è un effetto netto di beneficio da questa pipeline. Si consideri l'esempio mostrato nella Figura 2-1.
Figura 5-2 : Pipeline e pacchettizzazione 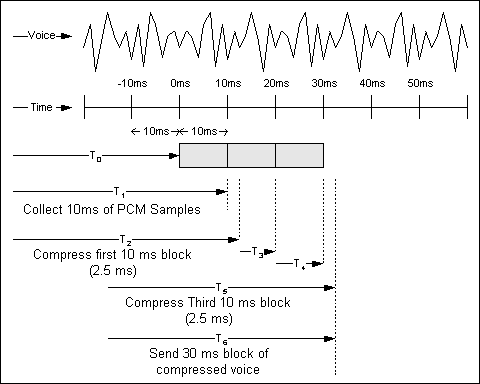
La riga superiore della figura mostra un esempio di forma d'onda vocale. La seconda linea è una scala temporale in incrementi di 10 ms. A T0, l'algoritmo CS-ACELP inizia a raccogliere campioni PCM dal codec. A T1, l'algoritmo ha raccolto il suo primo blocco di campioni da 10 ms e inizia a comprimerlo. A T2, il primo blocco di campioni è stato compresso. In questo esempio il tempo di compressione è 2,5 ms, come indicato da T2-T1.
Il secondo e il terzo blocco vengono raccolti in T3 e T4. Il terzo blocco viene compresso in T5. Il pacchetto viene assemblato e inviato (si presume istantaneo) in T6. A causa della natura pipeline dei processi di compressione e pacchettizzazione, il ritardo tra il momento in cui il processo inizia e il momento in cui viene inviato il voice frame è T6-T0, o circa 32,5 ms.
Ad esempio, questo esempio si basa sul miglior ritardo tra maiuscole e minuscole. Se si utilizza il ritardo peggiore, il valore è 40 ms, 10 ms per il ritardo del codificatore e 30 ms per il ritardo di pacchettizzazione.
Si noti che questi esempi non includono il ritardo algoritmico.
Ritardo serializzazione
Il ritardo di serializzazione (σn) è il ritardo fisso necessario per registrare una voce o un frame di dati sull'interfaccia di rete. È direttamente correlata alla frequenza di clock sul trunk. Con velocità di clock ridotte e dimensioni di frame ridotte, il flag aggiuntivo necessario per separare i frame è significativo.
La Tabella 5.3 mostra il ritardo di serializzazione richiesto per diverse dimensioni di fotogramma a diverse velocità di linea. Questa tabella utilizza per il calcolo le dimensioni totali dei frame, non le dimensioni del payload.
Tabella 5.3. Ritardo di serializzazione in millisecondi per dimensioni di frame diverse
| Dimensioni frame (byte) | Velocità linea (Kbps) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 19.2 | 56 | 64 | 128 | 256 | 384 | 512 | 768 | 1024 | 1544 | 2048 | |
| 38 | 15.83 | 5.43 | 4.75 | 2.38 | 1.19 | 0.79 | 0.59 | 0.40 | 0.30 | 0.20 | 0.15 |
| 48 | 20.00 | 6.86 | 6.00 | 3.00 | 1.50 | 1.00 | 0.75 | 0.50 | 0.38 | 0.25 | 0.19 |
| 64 | 26.67 | 9.14 | 8.00 | 4.00 | 2.00 | 1.33 | 1.00 | 0.67 | 0.50 | 0.33 | 0.25 |
| 128 | 53.33 | 18.29 | 16.00 | 8.00 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 | 0.66 | 0.50 |
| 256 | 106.67 | 36.57 | 32.00 | 16.00 | 8.00 | 5.33 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 |
| 512 | 213.33 | 73.14 | 64.00 | 32.00 | 16.00 | 10.67 | 8.00 | 5.33 | 4.00 | 2.65 | 2.00 |
| 1024 | 426.67 | 149.29 | 128.00 | 64.00 | 32.00 | 21.33 | 16.00 | 10.67 | 8.00 | 5.31 | 4.00 |
| 1500 | 625.00 | 214.29 | 187.50 | 93.75 | 46.88 | 31.25 | 23.44 | 15.63 | 11.72 | 7.77 | 5.86 |
| 2048 | 853.33 | 292.57 | 256.00 | 128.00 | 64.00 | 42.67 | 32.00 | 21.33 | 16.00 | 10.61 | 8.00 |
Nella tabella, su una linea a 64 Kbps, un frame vocale ACELP CS con una lunghezza di 38 byte (flag 37+1) ha un ritardo di serializzazione di 4,75 ms.
Nota: il ritardo di serializzazione per una cella ATM da 53 byte (T1: 0,275 ms, E1: 0,207 ms) è trascurabile a causa dell'alta velocità della linea e delle dimensioni ridotte delle celle.
Ritardo accodamento/buffer
Dopo la creazione del payload vocale compresso, viene aggiunta un'intestazione e il frame viene accodato per la trasmissione sulla connessione di rete. La voce deve avere priorità assoluta nel router/gateway. Pertanto, un frame voce deve attendere solo un frame dati già in riproduzione o altri frame voce prima di esso. Essenzialmente, il frame vocale attende il ritardo di serializzazione dei frame precedenti nella coda di output. Il ritardo di accodamento (ßn) è un ritardo variabile e dipende dalla velocità del trunk e dallo stato della coda. Sono presenti elementi casuali associati al ritardo di accodamento.
Si supponga, ad esempio, di trovarsi su una linea a 64 Kbps e di essere in coda dietro un frame di dati (48 byte) e un frame voce (42 byte). Poiché esiste la natura casuale di quanto è stato riprodotto il frame da 48 byte, si può tranquillamente supporre che sia stata riprodotta metà del frame di dati. In base ai dati della tabella di serializzazione, il componente del frame dati è 6 ms * 0,5 = 3 ms. Aggiungendo il tempo per un altro frame vocale in anticipo nella coda (5,25 ms), si ottiene un ritardo totale di 8,25 ms.
Il modo in cui viene definito il ritardo dell'accodamento dipende dal tecnico di rete. In genere, è necessario progettare lo scenario peggiore e quindi regolare le prestazioni dopo l'installazione della rete. Maggiore è il numero di linee vocali disponibili per gli utenti, maggiore è la probabilità che il pacchetto vocale medio attenda nella coda. Il frame vocale, a causa della struttura di priorità, non attende mai dietro più di un frame dati.
Ritardo switching di rete
Il frame relay pubblico o la rete ATM che interconnette le posizioni dell'endpoint è l'origine dei ritardi maggiori per le connessioni voce. I ritardi di switching di rete (ωn) sono anche i più difficili da quantificare.
Se la connettività ad ampio raggio è fornita da apparecchiature Cisco o da un'altra rete privata, è possibile identificare i singoli componenti del ritardo. In generale, i componenti fissi derivano dai ritardi di propagazione sui trunk all'interno della rete, mentre i ritardi variabili derivano dai ritardi di accodamento che bloccano i frame in entrata e in uscita dagli switch intermedi. Per stimare il ritardo di propagazione, è ampiamente utilizzata una stima popolare di 10 microsecondi/miglio o 6 microsecondi/km (G.114). Tuttavia, le apparecchiature multiplex intermedie, il backhauling, i collegamenti a microonde e altri fattori che si trovano nelle reti portanti creano molte eccezioni.
L'altra componente importante del ritardo è l'inserimento in coda all'interno della rete WAN. In una rete privata, è possibile misurare i ritardi nelle code esistenti o stimare il budget per hop all'interno della rete WAN.
I ritardi tipici della portante per le connessioni Frame Relay USA sono di 40 ms fissi e 25 ms variabili per un ritardo totale di 65 ms nel caso peggiore. Per semplicità, negli esempi 6-1, 6-2 e 6-3, sono inclusi tutti i ritardi di serializzazione a bassa velocità nel ritardo fisso di 40 ms.
Si tratta di cifre pubblicate da portanti di frame relay statunitensi, al fine di coprire ovunque copertura all'interno degli Stati Uniti. Ci si aspetta che due località geograficamente più vicine al peggiore dei casi abbiano migliori prestazioni in termini di ritardo, ma i vettori normalmente documentano solo il caso peggiore.
I vettori Frame Relay offrono a volte servizi premium. Questi servizi sono in genere destinati al traffico voce o SNA (Systems Network Architecture), dove è garantito il ritardo della rete e è inferiore al livello di servizio standard. Ad esempio, un vettore statunitense ha recentemente annunciato un servizio di questo tipo con un limite di ritardo complessivo di 50 ms, invece dei 65 ms del servizio standard.
Ritardo riduzione variazione
Poiché il riconoscimento vocale è un servizio a velocità bit costante, è necessario rimuovere lo jitter da tutti i ritardi variabili prima che il segnale esca dalla rete. Nei router/gateway Cisco, ciò viene realizzato con un buffer de-jitter (Δn) sul router/gateway remoto (ricevente). Il buffer di deformazione trasforma il ritardo variabile in un ritardo fisso. Contiene il primo campione ricevuto per un periodo di tempo prima di riprodurlo. Questo periodo di attesa è noto come ritardo di riproduzione iniziale.
Figura 5-3: Funzionamento del buffer per ridurre l'instabilità 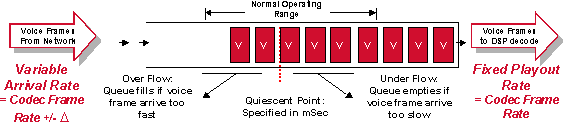
È essenziale gestire correttamente il buffer di deformazione . Se i campioni vengono conservati per un periodo di tempo troppo breve, le variazioni di ritardo possono causare un sovraccarico del buffer e causare interruzioni nel discorso. Se l'esempio viene mantenuto per troppo tempo, il buffer potrebbe sovraccaricarsi e i pacchetti ignorati potrebbero causare di nuovo interruzioni nel discorso. Infine, se i pacchetti vengono bloccati troppo a lungo, il ritardo complessivo sulla connessione può raggiungere livelli inaccettabili.
Il ritardo di riproduzione iniziale ottimale per il buffer di deformazione è uguale al ritardo variabile totale lungo la connessione. come mostrato nella Figura 5-4.
Nota: i buffer di deformazione possono essere adattivi, ma il ritardo massimo è fisso. Quando i buffer adattivi sono configurati, il ritardo diventa una figura variabile. Tuttavia, il ritardo massimo può essere utilizzato come caso peggiore ai fini della progettazione.
Per ulteriori informazioni sui buffer adattivi, vedere Miglioramenti del ritardo di riproduzione per Voice over IP.
Figura 5 -4 : Ritardo variabile e buffer di riduzione dell'instabilità 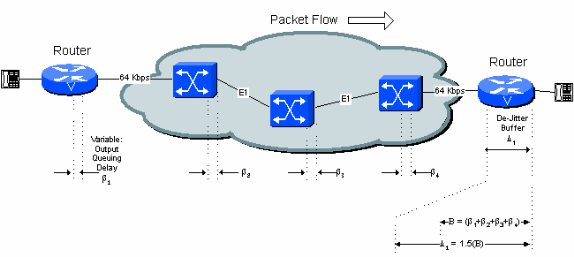
Il ritardo iniziale di riproduzione è configurabile. La profondità massima del buffer prima del suo overflow è normalmente impostata su 1,5 o 2 volte questo valore.
Se si utilizza l'impostazione del ritardo nominale di 40 ms, il primo campione di voce ricevuto quando il buffer di deviazione è vuoto viene mantenuto per 40 ms prima di essere riprodotto. Ciò significa che un pacchetto successivo ricevuto dalla rete può subire un ritardo fino a 40 ms (rispetto al primo pacchetto) senza perdita di continuità vocale. Se il ritardo è superiore a 40 ms, il buffer di flessione si svuota e il pacchetto successivo ricevuto viene mantenuto per 40 ms prima della riproduzione per ripristinare il buffer. Il risultato è un gap nella voce riprodotta per circa 40 ms.
Il contributo effettivo del buffer di deviazione al ritardo è il ritardo di riproduzione iniziale del buffer di deviazione più la quantità effettiva in cui il primo pacchetto è stato memorizzato nel buffer della rete. Il caso peggiore è il doppio del ritardo iniziale del buffer di dejitter (si presume che il primo pacchetto attraverso la rete abbia sperimentato solo un ritardo minimo nel buffer). In pratica, su diversi hop di switch di rete, probabilmente non è necessario ipotizzare il caso peggiore. I calcoli negli esempi nel prosieguo di questo documento aumentano il ritardo di riproduzione iniziale di un fattore di 1,5 per consentire questo effetto.
Nota: sul router/gateway ricevente è presente un ritardo dovuto alla funzione di decompressione. Tuttavia, di questo si tiene conto agganciandolo al ritardo di elaborazione della compressione, come descritto in precedenza.
Crea il budget di ritardo
Il limite generalmente accettato per un ritardo di connessione vocale di buona qualità è 200 ms unidirezionale (o 250 ms come limite). Mentre i ritardi aumentano su questa cifra, i parlatori e gli ascoltatori diventano non sincronizzati, e spesso parlano contemporaneamente, o entrambi aspettano che l'altro parli. Questa condizione viene comunemente definita sovrapposizione di parole. Mentre la qualità complessiva della voce è accettabile, gli utenti a volte trovano la natura arcuata della conversazione inaccettabile fastidiosa. La sovrapposizione di talker può essere osservata nelle chiamate telefoniche internazionali che viaggiano su connessioni satellitari (il ritardo satellite è dell'ordine di 500 ms, 250 ms in su e 250 ms in giù).
Questi esempi illustrano varie configurazioni di rete e i ritardi che il progettista della rete deve tenere in considerazione.
Connessione a hop singolo
Figura 6 - 1: Esempio di connessione a hop singolo 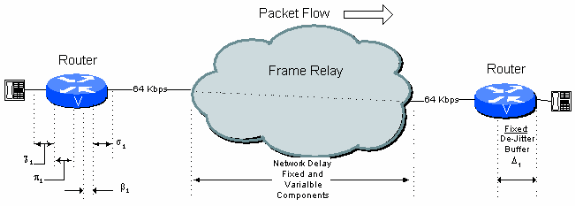
Da questa figura, una connessione un hop standard su una connessione frame relay pubblica può avere il budget di ritardo mostrato nella Tabella 6.1.
Tabella 6.1. Calcolo ritardo hop singolo
| Tipo di ritardo | Fisso (ms) | Variabile (ms) |
|---|---|---|
| Ritardo del codificatore,1 | 18 | |
| Ritardo pacchettizzazione, 1 | 30 | |
| Accodamento/buffering, ß1 | 8 | |
| Ritardo serializzazione (64 kbps), 1 | 5 | |
| Ritardo di rete (frame pubblico),‡1 | 40 | 25 |
| Dejitter Buffer Delay, ☐ 1 | 45 | |
| Totali | 138 | 33 |
Nota: poiché il ritardo di accodamento e il componente variabile del ritardo di rete sono già considerati nei calcoli del buffer di deformazione, il ritardo totale è in effetti solo la somma di tutti i ritardi fissi. In questo caso il ritardo totale è di 138 ms.
Due hop su una rete pubblica con un C7200 che funziona come switch tandem
Figura 6 - 2: Esempio di rete pubblica a due hop con router/gateway tandem 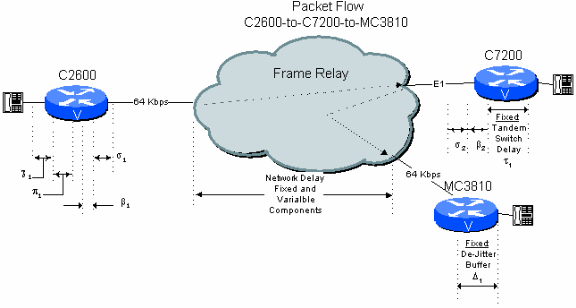
Si consideri ora una connessione da un ramo all'altro in una rete a topologia a stella in cui il C7200 nella sede centrale trasmette la chiamata al ramo di destinazione. In questo caso, il segnale rimane in formato compresso attraverso la centrale C7200. Ciò comporta un risparmio notevole nel budget di ritardo rispetto al prossimo esempio, una connessione a due hop su una rete pubblica con uno switch tandem PBX.
Tabella 6.2. Calcolo del ritardo di rete pubblica a due hop con router/gateway tandem
| Tipo di ritardo | Fisso (ms) | Variabile (ms) |
|---|---|---|
| Ritardo del codificatore,1 | 18 | |
| Ritardo pacchettizzazione, 1 | 30 | |
| Accodamento/buffering, ß1 | 8 | |
| Ritardo serializzazione (64 kbps), 1 | 5 | |
| Ritardo di rete (frame pubblico),‡1 | 40 | 25 |
| Ritardo tandem in MC3810,1 | 1 | |
| Accodamento/buffering, ß2 | 0.2 | |
| Ritardo Serializzazione (2 Mbps), 2 | 0.1 | |
| Ritardo di rete (frame pubblico),‡2 | 40 | 25 |
| Dejitter Buffer Delay, ☐ 1 | 75 | |
| Totali | 209.1 | 58.2 |
Nota: poiché il ritardo di accodamento e il componente variabile del ritardo di rete sono già considerati nei calcoli del buffer di deformazione, il ritardo totale è in effetti solo la somma di tutti i ritardi fissi. In questo caso il ritardo totale è 209,1 ms.
Connessione a due hop su una rete pubblica con uno switch tandem PBX
Figura 6-3: Esempio di rete pubblica a due hop con tandem PBX 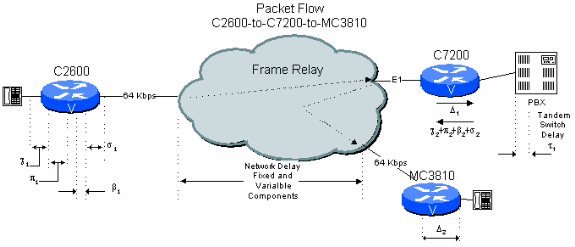
Si consideri una connessione da filiale a filiale in una rete da filiale a sede centrale in cui il C7200 nella sede centrale passa la connessione attraverso il PBX della sede centrale per la commutazione. Qui il segnale vocale deve essere decompresso e deformato e poi ricompresso e deformato una seconda volta. Ciò comporta ulteriori ritardi rispetto all'esempio precedente. Inoltre, i due cicli di compressione CS-ACELP riducono la qualità della voce (vedere Effetti di cicli di compressione multipli).
Tabella 6.3. Calcolo del ritardo di rete pubblica a due hop con tandem PBX
| Tipo di ritardo | Fisso (ms) | Variabile (ms) |
|---|---|---|
| Ritardo del codificatore,1 | 18 | |
| Ritardo pacchettizzazione, 1 | 30 | |
| Accodamento/buffering, ß1 | 8 | |
| Ritardo serializzazione (64 kbps), 1 | 5 | |
| Ritardo di rete (frame pubblico),‡1 | 40 | 25 |
| Dejitter Buffer Delay, ☐ 1 | 40 | |
| Ritardo del codificatore, ⌫ 2 | 15 | |
| Ritardo pacchettizzazione, 2 | 30 | |
| Accodamento/buffering, ß2 | 0.1 | |
| Ritardo Serializzazione (2 Mbps), 2 | 0.1 | |
| Ritardo di rete (frame pubblico),‡2 | 40 | 25 |
| Dejitter Buffer Delay, ☐ 2 | 40 | |
| Totali | 258.1 | 58.1 |
Nota: poiché il ritardo di accodamento e il componente variabile del ritardo di rete sono già considerati nei calcoli del buffer di deformazione, il ritardo totale è in effetti solo la somma di tutto il ritardo fisso più il ritardo del buffer di deformazione. In questo caso il ritardo totale è di 258,1 ms.
Se si utilizza il PBX sul sito centrale come switch, il ritardo della connessione unidirezionale aumenta da 206 ms a 255 ms. Ciò si avvicina ai limiti dell'ITU per il ritardo unidirezionale. Questo tipo di configurazione di rete richiede che il tecnico presti particolare attenzione alla progettazione per ridurre al minimo il ritardo.
Il caso peggiore è quello di un ritardo variabile (sebbene entrambe le componenti della rete pubblica non vedano il massimo ritardo contemporaneamente). Se si fanno ipotesi più ottimistiche sui ritardi variabili, la situazione migliora solo di poco. Tuttavia, con migliori informazioni sui ritardi fissi e variabili nella rete frame relay del vettore, il ritardo calcolato può essere ridotto. I collegamenti locali (ad esempio all'interno di uno Stato) dovrebbero avere caratteristiche di ritardo molto migliori, ma i vettori sono spesso riluttanti a fornire limiti di ritardo.
Connessione a due hop su una rete privata con uno switch tandem PBX
Figura 6-4: Esempio di rete privata a due hop con tandem PBX 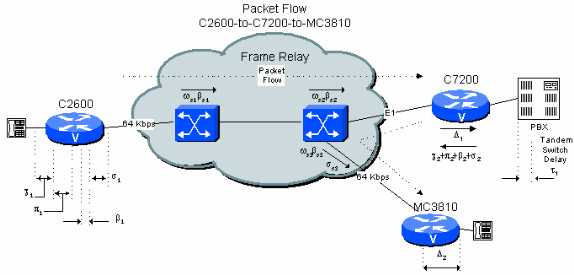
L'esempio 4.3 mostra che, con l'ipotesi di ritardi nel caso peggiore, è molto difficile mantenere il ritardo calcolato al di sotto di 200 ms quando una connessione da filiale a filiale include un hop tandem PBX nel sito centrale con connessioni di rete frame relay pubbliche su entrambi i lati. Tuttavia, se la topologia di rete e il traffico sono noti, è possibile ridurre notevolmente il valore calcolato. Questo perché le cifre generalmente fornite dai vettori sono limitate dalla trasmissione nel caso peggiore e dal ritardo delle code su un'ampia area. È molto più facile stabilire limiti più ragionevoli in una rete privata.
Il valore generalmente accettato per il ritardo di trasmissione tra switch è dell'ordine di 10 microsecondi/miglio. In base all'apparecchiatura, il ritardo trans-switch in una rete frame relay deve essere nell'ordine di 1 ms fisso e 5 ms variabile per l'accodamento. Queste cifre dipendono dalle apparecchiature e dal traffico. I valori del ritardo per gli switch Cisco MGX WAN sono inferiori a 1 ms per totale switch se si usano trunk E1/T1. Partendo dal presupposto che la distanza sia di 500 miglia, con 1 ms fisso e 5 ms variabile per ogni hop, il calcolo del ritardo diventa:
Tabella 6.4. Calcolo del ritardo di rete privato a due hop con tandem PBX
| Tipo di ritardo | Fisso (ms) | Variabile (ms) |
|---|---|---|
| Ritardo del codificatore,1 | 18 | |
| Ritardo pacchettizzazione, 1 | 30 | |
| Accodamento/buffering, ß1 | 8 | |
| Ritardo serializzazione (64 kbps), 1 | 5 | |
| Ritardo di rete (frame privato), S1 + ßS1+ S2 + ßS2 | 2 | 10 |
| Dejitter Buffer Delay, ☐ 1 | 40 | |
| Ritardo del codificatore, ⌫ 2 | 15 | |
| Ritardo pacchettizzazione, 2 | 30 | |
| Accodamento/buffering, ß2 | 0.1 | |
| Ritardo Serializzazione (2 Mbps), 2 | 0.1 | |
| Ritardo di rete (frame privato), pericastS3 + ßS3 | 1 | 8 |
| Ritardo serializzazione (64 kbps), S3 | 5 | |
| Dejitter Buffer Delay, ☐ 2 | 40 | |
| Ritardo trasmissione/distanza (non scomposto) | 5 | |
| Totali | 191.1 | 26.1 |
Nota: poiché il ritardo di accodamento e il componente variabile del ritardo di rete sono già considerati nei calcoli del buffer di deformazione, il ritardo totale è solo la somma di tutti i ritardi fissi. In questo caso, il ritardo totale è 191,1 ms.
Quando si utilizza una rete frame relay privata, è possibile creare una connessione spoke-to-spoke attraverso il PBX nel sito hub e rimanere entro il valore di 200 ms.
Effetti di cicli di compressione multipli
Gli algoritmi di compressione CS-ACELP non sono deterministici. Ciò significa che il flusso di dati di input non è esattamente uguale al flusso di dati di output. Con ciascun ciclo di compressione viene introdotta una piccola quantità di distorsione, come mostrato nella Figura 7-1.
Figura 7-1: Effetti di compressione 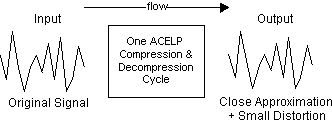
Di conseguenza, cicli di compressione multipli CS-ACELP introducono rapidamente livelli significativi di distorsione. Questo effetto di distorsione additiva non è così pronunciato con gli algoritmi ADPCM (Adaptive Differential Pulse Code Modulation).
L'impatto di questa caratteristica è che oltre agli effetti del ritardo, il progettista della rete deve considerare il numero di cicli di compressione CS-ACELP nel percorso.
La qualità della voce è soggettiva. La maggior parte degli utenti ritiene che due cicli di compressione forniscano ancora una qualità vocale adeguata. Un terzo ciclo di compressione produce in genere un degrado notevole, che può essere inaccettabile per alcuni utenti. Di norma, il progettista della rete deve limitare a due il numero di cicli di compressione CS-ACELP in un percorso. Se è necessario utilizzare più cicli, lasciare che il cliente lo senta prima.
Negli esempi precedenti , è dimostrato che quando una connessione da una filiale all'altra viene commutata in tandem attraverso il PBX (in formato PCM) presso la sede centrale, si verifica un ritardo significativamente maggiore rispetto a quando viene commutata in tandem nella sede centrale C7200. È chiaro che quando il PBX viene utilizzato per commutare, ci sono due cicli di compressione CS-ACELP nel percorso, anziché un ciclo quando la voce inserita in frame viene commutata dal C7200 centrale. La qualità della voce è migliore con l'esempio di commutazione C7200 (4.2), sebbene possa essere diversa motivi, ad esempio la gestione del piano di chiamata, che possono richiedere l'inclusione del PBX nel percorso.
Se si effettua una connessione da una filiale all'altra attraverso un PBX centrale, e dalla seconda filiale la chiamata viene estesa sulla rete vocale pubblica e termina su una rete telefonica cellulare, il percorso prevede tre cicli di compressione CS-ACELP, oltre a un ritardo notevolmente superiore. In questo scenario, la qualità ne risente notevolmente. Anche in questo caso, il progettista della rete deve prendere in considerazione il percorso di chiamata peggiore e decidere se è accettabile in base alla rete degli utenti, alle aspettative e ai requisiti aziendali.
Considerazioni sulle connessioni ad alto ritardo
È relativamente facile progettare reti voce a pacchetti che superano il limite di ritardo a senso unico ITU generalmente accettato di 150 ms.
Quando si progettano reti voce a pacchetti, il tecnico deve considerare la frequenza con cui tale connessione viene utilizzata, le esigenze dell'utente e il tipo di attività aziendale coinvolta. Non è raro che tali connessioni siano accettabili in circostanze particolari.
Se le connessioni frame relay non attraversano una grande distanza, è molto probabile che le prestazioni di ritardo della rete siano migliori di quelle mostrate negli esempi.
Se il ritardo totale riscontrato dalle connessioni router/gateway tandem diventa troppo grande, un'alternativa è spesso configurare circuiti virtuali permanenti (PVC) aggiuntivi direttamente tra gli MC3810 terminali. Ciò aggiunge costi ricorrenti alla rete, in quanto i vettori di solito si fanno pagare per PVC, ma in alcuni casi può essere necessario.
 Feedback
Feedback