Risoluzione dei problemi CDL (Common Data Layer)
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
1. Introduzione
In questo articolo verranno illustrate le nozioni di base per la risoluzione dei problemi CDL (Common Data Layer) nell'ambiente SMF. La documentazione è disponibile su questo link.
2. Panoramica
Cisco Common Data Layer (CDL) è un livello di archivio dati KV (Key-value) di nuova generazione ad alte prestazioni per tutte le applicazioni native cloud.
CDL è attualmente utilizzato come componente di gestione dello stato con funzioni HA (High Availability) e Geo HA.
La CDL offre:
- Un livello di archivio dati comune tra diverse funzioni di rete (NF).
- Lettura e scrittura a bassa latenza (nell'archivio delle sessioni di memoria)
- Notificare agli NF di bloccare il sottoscrittore quando viene segnalato un attacco DoS (Denial of Service) nella stessa sessione.
- Alta disponibilità: ridondanza locale con almeno 2 repliche.
- Ridondanza geografica con 2 siti.
- Nessun concetto primario/secondario disponibile su tutti gli slot per le operazioni di scrittura. Migliora i tempi di failover in quanto non viene effettuata alcuna scelta primaria.
3. Componenti
- Endpoint: (cdl-ep-session-c1-d0-7c79c87d65-xpm5v)
- L'endpoint CDL è un POD Kubernetes (K8s). Viene distribuito per esporre l'interfaccia gRPC su HTTP2 al client NF per l'elaborazione delle richieste del servizio di database e funge da punto di ingresso per le applicazioni con associazione a nord.
- Slot (cdl-slot-session-c1-m1-0)
- L'endpoint CDL supporta microservizi a più slot. Questi microservizi sono POD K8s distribuiti per esporre l'interfaccia gRPC interna verso il Cisco Data Store
- Ogni POD slot contiene un numero finito di sessioni. Queste sessioni rappresentano i dati effettivi della sessione in formato matrice di byte
- Indice: (cdl-index-session-c1-m1-0)
- Il microservizio Index contiene i dati correlati all'indicizzazione
- Questi dati di indicizzazione vengono quindi utilizzati per recuperare i dati di sessione effettivi dai microservizi slot
- ETCD: (etcd-smf-etcd-cluster-0)
- CDL utilizza ETCD (un archivio chiave-valore open source) come individuazione del servizio DB. Quando Cisco Data Store EP viene avviato, interrotto o chiuso, si verifica l'aggiunta di un evento da parte dello stato di pubblicazione. Pertanto, le notifiche vengono inviate a ciascuno dei POD sottoscritti a questi eventi. Inoltre, quando un evento chiave viene aggiunto o rimosso, aggiorna la mappa locale.
- Kafka (kafka-0)
- Il POD Kafka replica i dati tra le repliche locali e tra i siti per l'indicizzazione. Per la replica tra siti, Kafak utilizza MirrorMaker.
- Mirror Maker: (mirror-maker-0)
- Il POD di Mirror Maker esegue la replica geografica dei dati di indicizzazione sui siti CDL remoti. Prende i dati dai siti remoti e li pubblica sul sito Kafka locale per le istanze di indicizzazione appropriate da raccogliere.
Esempio:
master-1:~$ kubectl get pods -n smf-smf -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cdl-ep-session-c1-d0-7889db4d87-5mln5 1/1 Running 0 80d 192.168.16.247 smf-data-worker-5 <none> <none> cdl-ep-session-c1-d0-7889db4d87-8q7hg 1/1 Running 0 80d 192.168.18.108 smf-data-worker-1 <none> <none> cdl-ep-session-c1-d0-7889db4d87-fj2nf 1/1 Running 0 80d 192.168.24.206 smf-data-worker-3 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z6c2z 1/1 Running 0 34d 192.168.4.164 smf-data-worker-2 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z7c89 1/1 Running 0 80d 192.168.7.161 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-0 1/1 Running 0 80d 192.168.7.172 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-1 1/1 Running 0 80d 192.168.24.241 smf-data-worker-3 <none> <none> cdl-index-session-c1-m2-0 1/1 Running 0 49d 192.168.18.116 smf-data-worker-1 <none> <none> cdl-index-session-c1-m2-1 1/1 Running 0 80d 192.168.7.173 smf-data-worker-4 <none> <none> cdl-index-session-c1-m3-0 1/1 Running 0 80d 192.168.24.197 smf-data-worker-3 <none> <none> cdl-index-session-c1-m3-1 1/1 Running 0 80d 192.168.18.107 smf-data-worker-1 <none> <none> cdl-index-session-c1-m4-0 1/1 Running 0 80d 192.168.7.158 smf-data-worker-4 <none> <none> cdl-index-session-c1-m4-1 1/1 Running 0 49d 192.168.16.251 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m1-0 1/1 Running 0 80d 192.168.18.117 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m1-1 1/1 Running 0 80d 192.168.24.201 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m2-0 1/1 Running 0 80d 192.168.16.245 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m2-1 1/1 Running 0 80d 192.168.18.123 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m3-0 1/1 Running 0 34d 192.168.4.156 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m3-1 1/1 Running 0 80d 192.168.18.78 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m4-0 1/1 Running 0 34d 192.168.4.170 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m4-1 1/1 Running 0 80d 192.168.7.177 smf-data-worker-4 <none> <none> cdl-slot-session-c1-m5-0 1/1 Running 0 80d 192.168.24.246 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m5-1 1/1 Running 0 34d 192.168.4.163 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m6-0 1/1 Running 0 80d 192.168.18.119 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m6-1 1/1 Running 0 80d 192.168.16.228 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-0 1/1 Running 0 80d 192.168.16.215 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-1 1/1 Running 0 49d 192.168.4.167 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m8-0 1/1 Running 0 49d 192.168.24.213 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m8-1 1/1 Running 0 80d 192.168.16.253 smf-data-worker-5 <none> <none> etcd-smf-smf-etcd-cluster-0 2/2 Running 0 80d 192.168.11.176 smf-data-master-1 <none> <none> etcd-smf-smf-etcd-cluster-1 2/2 Running 0 48d 192.168.7.59 smf-data-master-2 <none> <none> etcd-smf-smf-etcd-cluster-2 2/2 Running 1 34d 192.168.11.66 smf-data-master-3 <none> <none> georeplication-pod-0 1/1 Running 0 80d 10.10.1.22 smf-data-master-1 <none> <none> georeplication-pod-1 1/1 Running 0 48d 10.10.1.23 smf-data-master-2 <none> <none> grafana-dashboard-cdl-smf-smf-77bd69cff7-qbvmv 1/1 Running 0 34d 192.168.7.41 smf-data-master-2 <none> <none> kafka-0 2/2 Running 0 80d 192.168.24.245 smf-data-worker-3 <none> <none> kafka-1 2/2 Running 0 49d 192.168.16.200 smf-data-worker-5 <none> <none> mirror-maker-0 1/1 Running 1 80d 192.168.18.74 smf-data-worker-1 <none> <none> zookeeper-0 1/1 Running 0 34d 192.168.11.73 smf-data-master-3 <none> <none> zookeeper-1 1/1 Running 0 48d 192.168.7.47 smf-data-master-2 <none> <none> zookeeper-2
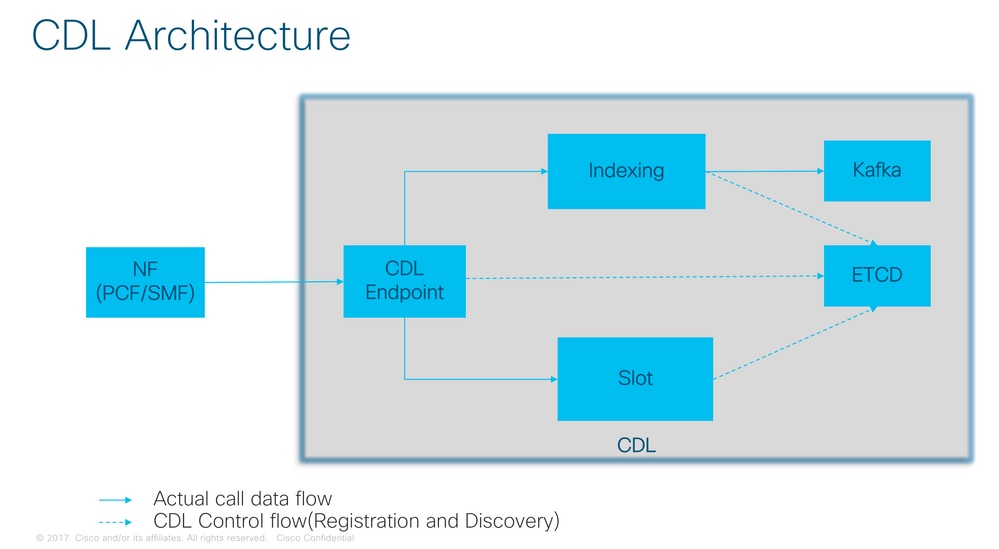 Architettura CDL
Architettura CDL
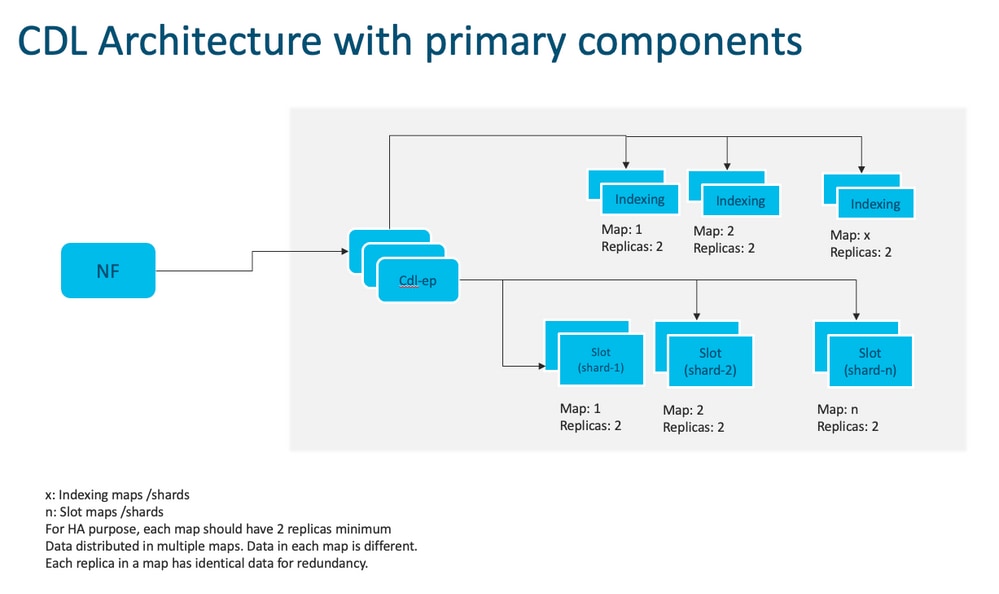
Nota: Nessun concetto primario/secondario disponibile su tutti gli slot per le operazioni di scrittura. Migliora i tempi di failover in quanto non viene effettuata alcuna scelta primaria.
Nota: Per impostazione predefinita, CDL è implementato con 2 repliche per db-ep, 1 mappa di slot (2 repliche per mappa) e 1 mappa di indice (2 repliche per mappa).
4. Procedura dettagliata per la configurazione
smf# show running-config cdl cdl system-id 1 /// unique across the site, system-id 1 is the primary site ID for sliceNames SMF1 SMF2 in HA GR CDL deploy cdl node-type db-data /// node label to configure the node affinity cdl enable-geo-replication true /// CDL GR Deployment with 2 RACKS cdl remote-site 2 db-endpoint host x.x.x.x /// Remote site cdl-ep configuration on site-1 db-endpoint port 8882 kafka-server x.x.x.x 10061 /// Remote site kafka configuration on site-1 exit kafka-server x.x.x.x 10061 exit exit cdl label-config session /// Configures the list of label for CDL pods endpoint key smi.cisco.com/node-type-3 endpoint value session slot map 1 key smi.cisco.com/node-type-3 value session exit slot map 2 key smi.cisco.com/node-type-3 value session exit slot map 3 key smi.cisco.com/node-type-3 value session exit slot map 4 key smi.cisco.com/node-type-3 value session exit slot map 5 key smi.cisco.com/node-type-3 value session exit slot map 6 key smi.cisco.com/node-type-3 value session exit slot map 7 key smi.cisco.com/node-type-3 value session exit slot map 8 key smi.cisco.com/node-type-3 value session exit index map 1 key smi.cisco.com/node-type-3 value session exit index map 2 key smi.cisco.com/node-type-3 value session exit index map 3 key smi.cisco.com/node-type-3 value session exit index map 4 key smi.cisco.com/node-type-3 value session exit exit cdl datastore session /// unique with in the site label-config session geo-remote-site [ 2 ] slice-names [ SMF1 SMF2 ] endpoint cpu-request 2000 endpoint go-max-procs 16 endpoint replica 5 /// number of cdl-ep pods endpoint external-ip x.x.x.x endpoint external-port 8882 index cpu-request 2000 index go-max-procs 8 index replica 2 /// number of replicas per mop for cdl-index, can not be changed after CDL deployement.
NOTE: If you need to change number of index replica, set the system mode to shutdown from respective ops-center CLI, change the replica and set the system mode to running index map 4 /// number of mops for cdl-index index write-factor 1 /// number of copies to be written before a successful response slot cpu-request 2000 slot go-max-procs 8 slot replica 2 /// number of replicas per mop for cdl-slot slot map 8 /// number of mops for cdl-slot slot write-factor 1 slot metrics report-idle-session-type true features instance-aware-notification enable true /// This enables GR failover notification features instance-aware-notification system-id 1 slice-names [ SMF1 ] exit features instance-aware-notification system-id 2 slice-names [ SMF2 ] exit exit cdl kafka replica 2 cdl kafka label-config key smi.cisco.com/node-type-3 cdl kafka label-config value session cdl kafka external-ip x.x.x.x 10061 exit cdl kafka external-ip x.x.x.x 10061 exit
5. Risoluzione dei problemi
5.1 Guasti dei dispositivi di storage
Il funzionamento di CDL è semplice Chiave > Valore db.
- Tutte le richieste vengono inviate ai pod dell'endpoint cdl.
- Nei pod cdl-index vengono memorizzate chiavi, round robin.
- In cdl-slot memorizzare valore (informazioni sessione), round robin.
- Viene definito il backup (numero di repliche) per ciascuna mappa pod (tipo).
- Il barattolo Kafka è usato come autobus da trasporto.
- mirror maker viene utilizzato come bus di trasporto per un rack diverso (ridondanza geografica).
I guasti di ciascun pod possono essere tradotti come, cioè se tutti i pod di questo tipo/mappa sono andati giù allo stesso tempo:
- cdl-endpoint - errori di comunicazione con CDL
- cdl-index - perdita delle chiavi per i dati della sessione
- cdl-slot - perdita dei dati della sessione
- Kafka - perde l'opzione di sincronizzazione tra le mappe del tipo di baccello
- mirror maker - perdita di sincronizzazione con altri nodi geo redudand
Possiamo sempre raccogliere i log dai pod rilevanti perché i log pod cdl non eseguono il rollover così velocemente, quindi c'è un valore extra per raccoglierli.
Remambra tac-debug raccoglie lo snapshot in tempo, mentre i log stampano tutti i dati da quando è archiviato.
Descrivi baccelli
kubectl describe pod cdl-ep-session-c1-d0-7889db4d87-5mln5 -n smf-rcdn
Raccogli registri pod
kubectl logs cdl-ep-session-c1-d0-7c79c87d65-xpm5v -n smf-rcdn
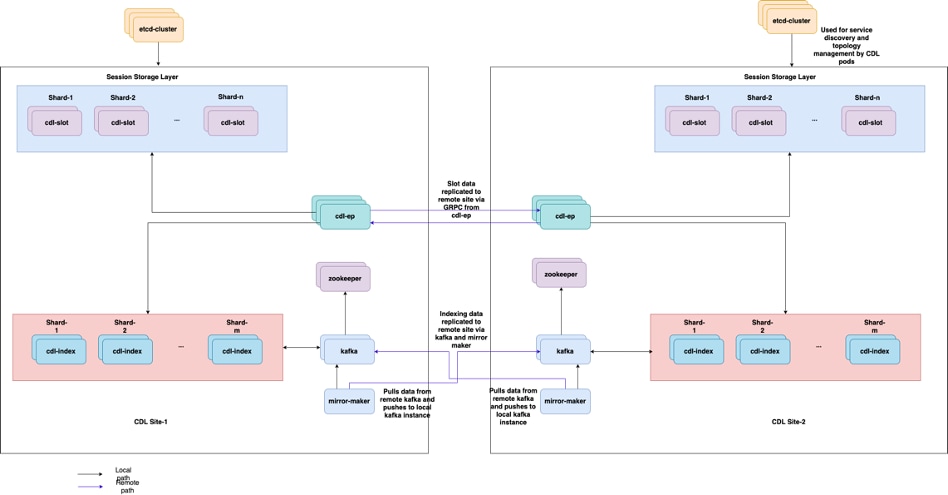
5.2 CDL Come ottenere le informazioni sulla sessione dalle chiavi di sessione
All'interno di CDL ogni sessione dispone di un campo denominato chiavi univoche che identifica questa sessione.
Se si confronta la stampa della sessione da show subscriber supi e cdl, viene visualizzato il riepilogo delle sessioni slice-name slice1 db-name session filter
- indirizzo sessione ipv4 combinato con supi = "1#/#imsi-123969789012404:10.0.0.3"
- ddn + indirizzo ip4 = "1#/#lab:10.0.0.3"
- indirizzo sessione ipv6 combinato con supi = "1#/#imsi-123969789012404:2001:db0:0:2:"
- ddn + indirizzo ipv6 dalla sessione = "1#/#lab:2001:db0:0:2:"
- smfTeid anche N4 Session Key = "1#/#293601283" Questo è molto utile per risolvere gli errori su UPF, è possibile cercare tra i log di sessione e trovare le informazioni relative alla sessione.
- supi + ebi = "1#/#imsi-123969789012404:ebi-5"
- supi + ddn= "1#/#imsi-123969789012404:lab"
[smf/data] smf# cdl show sessions summary slice-name slice1 db-name session filter { condition match key 1#/#293601283 }
Sun Mar 19 20:17:41.914 UTC+00:00
message params: {session-summary cli session {0 100 1#/#293601283 0 [{0 1#/#293601283}] [] 0 0 false 4096 [] [] 0} slice1}
session {
primary-key 1#/#imsi-123969789012404:1
unique-keys [ "1#/#imsi-123969789012404:10.0.0.3" "1#/#lab:10.0.0.3" "1#/#imsi-123969789012404:2001:db0:0:2::" "1#/#lab:2001:db0:0:2::" "1#/#293601283" "1#/#imsi-123969789012404:ebi-5" "1#/#imsi-123969789012404:lab" ]
non-unique-keys [ "1#/#roaming-status:visitor-lbo" "1#/#ue-type:nr-capable" "1#/#supi:imsi-123969789012404" "1#/#gpsi:msisdn-22331010101010" "1#/#pei:imei-123456789012381" "1#/#psid:1" "1#/#snssai:001000003" "1#/#dnn:lab" "1#/#emergency:false" "1#/#rat:nr" "1#/#access:3gpp" access "1#/#connectivity:5g" "1#/#udm-uecm:10.10.10.215" "1#/#udm-sdm:10.10.10.215" "1#/#auth-status:unauthenticated" "1#/#pcfGroupId:PCF-dnn=lab;" "1#/#policy:2" "1#/#pcf:10.10.10.216" "1#/#upf:10.10.10.150" "1#/#upfEpKey:10.10.10.150:10.10.10.202" "1#/#ipv4-addr:pool1/10.0.0.3" "1#/#ipv4-pool:pool1" "1#/#ipv4-range:pool1/10.0.0.1" "1#/#ipv4-startrange:pool1/10.0.0.1" "1#/#ipv6-pfx:pool1/2001:db0:0:2::" "1#/#ipv6-pool:pool1" "1#/#ipv6-range:pool1/2001:db0::" "1#/#ipv6-startrange:pool1/2001:db0::" "1#/#id-index:1:0:32768" "1#/#id-value:2/3" "1#/#chfGroupId:CHF-dnn=lab;" "1#/#chf:10.10.10.218" "1#/#amf:10.10.10.217" "1#/#peerGtpuEpKey:10.10.10.150:20.0.0.1" "1#/#namespace:smf" ]
flags [ flag3:peerGtpuEpKey:10.10.10.150:20.0.0.1 session-state-flag:smf_active ]
map-id 2
instance-id 1
app-instance-id 1
version 1
create-time 2023-03-19 20:14:14.381940117 +0000 UTC
last-updated-time 2023-03-19 20:14:14.943366502 +0000 UTC
purge-on-eval false
next-eval-time 2023-03-26 20:14:14 +0000 UTC
session-types [ rat_type:NR wps:non_wps emergency_call:false pdu_type:ipv4v6 dnn:lab qos_5qi_1_rat_type:NR ssc_mode:ssc_mode_1 always_on:disable fourg_only_ue:false up_state:active qos_5qi_5_rat_type:NR dcnr:disable smf_roaming_status:visitor-lbo dnn:lab:rat_type:NR ]
data-size 2866
}
[smf/data] smf#
Se la confrontiamo con la stampa del file SMF:
[smf/data] smf# show subscriber supi imsi-123969789012404 gr-instance 1 namespace smf
Sun Mar 19 20:25:47.816 UTC+00:00
subscriber-details
{
"subResponses": [
[
"roaming-status:visitor-lbo",
"ue-type:nr-capable",
"supi:imsi-123969789012404",
"gpsi:msisdn-22331010101010",
"pei:imei-123456789012381",
"psid:1",
"snssai:001000003",
"dnn:lab",
"emergency:false",
"rat:nr",
"access:3gpp access",
"connectivity:5g",
"udm-uecm:10.10.10.215",
"udm-sdm:10.10.10.215",
"auth-status:unauthenticated",
"pcfGroupId:PCF-dnn=lab;",
"policy:2",
"pcf:10.10.10.216",
"upf:10.10.10.150",
"upfEpKey:10.10.10.150:10.10.10.202",
"ipv4-addr:pool1/10.0.0.3",
"ipv4-pool:pool1",
"ipv4-range:pool1/10.0.0.1",
"ipv4-startrange:pool1/10.0.0.1",
"ipv6-pfx:pool1/2001:db0:0:2::",
"ipv6-pool:pool1",
"ipv6-range:pool1/2001:db0::",
"ipv6-startrange:pool1/2001:db0::",
"id-index:1:0:32768",
"id-value:2/3",
"chfGroupId:CHF-dnn=lab;",
"chf:10.10.10.218",
"amf:10.10.10.217",
"peerGtpuEpKey:10.10.10.150:20.0.0.1",
"namespace:smf",
"nf-service:smf"
]
]
}
Controllare lo stato CDL su SMF:
cdl show status
cdl show sessions summary slice-name <slice name> | more
5.3 I CDL Pod non sono attivi
Come identificare
Controllare l'output di descrizione dei pod (container/member/State/Reason, events).
kubectl describe pods -n <namespace> <failed pod name>
Come risolvere il problema
- I pod sono in stato in sospeso Verificare se un nodo k8s con i valori di etichetta uguali al valore del numero di repliche di tipo cdl/nodo è minore o uguale al numero di nodi k8s con i valori di etichetta uguali al valore di tipo cdl/nodo
kubectl get nodes -l smi.cisco.com/node-type=<value of cdl/node-type, default value is 'session' in multi node setup)
- I pod sono in stato di errore CrashLoopBackOff. Controllare lo stato dei pod etcd. Se i pod etcd non sono in esecuzione, risolvere i problemi relativi.
kubectl describe pods -n <namespace> <etcd pod name>
- I pod sono in stato di errore ImagePullBack Verificare se il repository del timone e il registro delle immagini sono accessibili. Verificare che i server proxy e DNS necessari siano configurati.
5.4 I gusci di Mirror Maker sono nello stato init
Controllare l'output del pod e i relativi registri
kubectl describe pods -n <namespace> <failed pod name> kubectl logs -n <namespace> <failed pod name> [-c <container name>]
Come risolvere il problema
- Verificare che gli IP esterni configurati per Kafka siano corretti
- Verificare la disponibilità di kafka sul sito remoto tramite IP esterni
5.5 L'indice CDL non viene replicato correttamente
Come identificare
I dati aggiunti in un sito non sono accessibili da un altro sito.
Come risolvere il problema
- Controllare la configurazione dell'ID di sistema locale e la configurazione del sito remoto.
- Verificare la raggiungibilità degli endpoint CDL e Kafka tra i vari siti.
- Controllare la mappa, la replica dell'indice e dello slot in ogni sito. Può essere identico in tutti i siti.
5.6 Le operazioni CDL non riescono, ma la connessione riesce
Come risolvere il problema
- Verificare che tutti i pod siano nello stato Pronto e In esecuzione.
- I pod di indice sono nello stato Pronto solo se la sincronizzazione è completa con la replica peer (locale o remota se disponibile)
- Gli slot pod sono in stato pronto solo se la sincronizzazione è completa con la replica peer (locale o remota se disponibile)
- Lo stato dell'endpoint NON è pronto se almeno uno slot e un pod'indice non sono disponibili. Anche se non è pronta, la connessione grpc sarà accettata dal client.
5.7 La notifica per l'eliminazione dei record è arrivata in anticipo/in ritardo da CDL
Come risolvere il problema
- In un cluster k8s tutti i nodi possono essere sincronizzati con l'ora
- Controllare lo stato di sincronizzazione NTP su tutti i nodi k8s. In caso di problemi, risolverli.
chronyc tracking chronyc sources -v chronyc sourcestats -v
6. Segnalazioni
| AVVISO |
gravità |
riepilogo |
|---|---|---|
| ErroreRichiestaLocaleCdl |
critico |
Se la percentuale di successo delle richieste locali è inferiore al 90% per più di 5 minuti, viene attivato l'allarme |
| erroreConnessioneRemotaCDL |
critico |
Se le connessioni attive dal pod dell'endpoint al sito remoto hanno raggiunto 0 per più di 5 minuti , viene generato un allarme (solo per il sistema abilitato per GRE) |
| ErroreRichiestaRemotaCd |
critico |
Se la percentuale di successo delle richieste remote in arrivo è inferiore al 90% per più di 5 minuti, attiva l'allarme (solo per il sistema GR abilitato) |
| ErroreReplicaCdl |
critico |
Se il rapporto tra le richieste di replica in uscita e le richieste locali nello spazio dei nomi globale cdl è sceso al di sotto del 90% per più di 5 minuti (solo per il sistema abilitato per GRE). Questi avvisi sono previsti durante l'attività di aggiornamento e pertanto possono essere ignorati. |
| ritardoReplicaRemotaCDLkafka |
critico |
Se il ritardo di replica kafka al sito remoto supera i 10 secondi per più di 5 minuti, viene generato l'allarme (solo per il sistema abilitato GR) |
| cdlOverload - principale |
importante |
Se il sistema CDL raggiunge la percentuale configurata (80% predefinita) della sua capacità, il sistema attiva l'allarme (solo se la funzione di protezione da sovraccarico è attivata) |
| cdlOverload - Critico |
critico |
Se il sistema CDL raggiunge la percentuale configurata (per impostazione predefinita il 90%) della sua capacità, il sistema attiva l'allarme (solo se la funzione di protezione da sovraccarico è attivata) |
| erroreConnessioneKdlKafka |
critico |
Se i pod indice CDL vengono disconnessi da kafka per più di 5 minuti |
7. Problemi più comuni
7.1 erroreReplicaCdl
Questo avviso viene in genere visualizzato durante l'attivazione del centro operativo o l'aggiornamento del sistema, cercare di trovare CR per esso, cercare di controllare l'occorrenza CEE dell'avviso ed è stato già cancellato.
7.2 cdlRemoteConnectionFailure e GRPC_Connections_Remote_Site
La spiegazione è applicabile a tutti gli avvisi "cdlRemoteConnectionFailure" e "GRPC_Connections_Remote_Site".
Per gli avvisi cdlRemoteConnectionFailure:
Dai log degli endpoint CDL è possibile vedere che la connessione all'host remoto dall'endpoint CDL è stata persa:
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
È stato rilevato il pod dell'endpoint CDL durante il tentativo di connessione al server remoto, ma l'host remoto ha rifiutato la connessione:
2022/01/20 01:37:08.730 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.732 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.752 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.754 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
Poiché l'host remoto è rimasto irraggiungibile per 5 minuti, l'avviso è stato generato come indicato di seguito:
alerts history detail cdlRemoteConnectionFailure f5237c750de6
severity critical
type "Processing Error Alarm"
startsAt 2025-01-21T01:41:26.857Z
endsAt 2025-01-21T02:10:46.857Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes"
labels [ "alertname: cdlRemoteConnectionFailure" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" ]
annotations [ "summary: CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes" "type: Processing Error Alarm" ]
Connessione all'host remoto riuscita alle 02:10:32:
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
Configurazione presente in SMF per il sito remoto CDL:
cdl remote-site 2
db-endpoint host 10.10.10.141
db-endpoint port 8882
kafka-server 10.10.19.139 10061
exit
kafka-server 10.10.10.140 10061
exit
exit
Per l'avviso GRPC_Connections_Remote_Site:
La stessa spiegazione è applicabile anche a "GRPC_Connections_Remote_Site", in quanto anch'esso proviene dallo stesso pod dell'endpoint CDL.
alerts history detail GRPC_Connections_Remote_Site f083cb9d9b8d
severity critical
type "Communications Alarm"
startsAt 2025-01-21T01:37:35.160Z
endsAt 2025-01-21T02:11:35.160Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "GRPC connections to remote site are not equal to 4"
labels [ "alertname: GRPC_Connections_Remote_Site" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" "systemId: 2" ]
Dai log pod dell'endpoint CDL, l'avviso è stato avviato quando la connessione all'host remoto è stata rifiutata:
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
L'avviso è stato cancellato al completamento della connessione al sito remoto:
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
8. Grafana
Dashboard CDL fa parte di ogni distribuzione SMF.
Cronologia delle revisioni
| Revisione | Data di pubblicazione | Commenti |
|---|---|---|
1.0 |
04-Oct-2023 |
Versione iniziale |
Contributo dei tecnici Cisco
- Nebojsa KosanovicResponsabile tecnico
 Feedback
Feedback