Introduzione
In questo documento vengono descritti i problemi relativi a Gestione configurazione ridondanza (RCM) e alla Funzione piano utente (UPF) che causano lo stato del server sessmgr.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
Componenti usati
Le informazioni fornite in questo documento si basano sulle seguenti versioni software e hardware:
- RCM-checkpoint mgr
- UPF-sessmgr
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Fornisce inoltre una guida dettagliata alla risoluzione dei problemi relativi allo stato del server sessmgr, che impedisce il traffico e l'elaborazione delle chiamate. Inoltre, è disponibile una sezione di test di laboratorio per il ripristino.
Panoramica delle nozioni di base
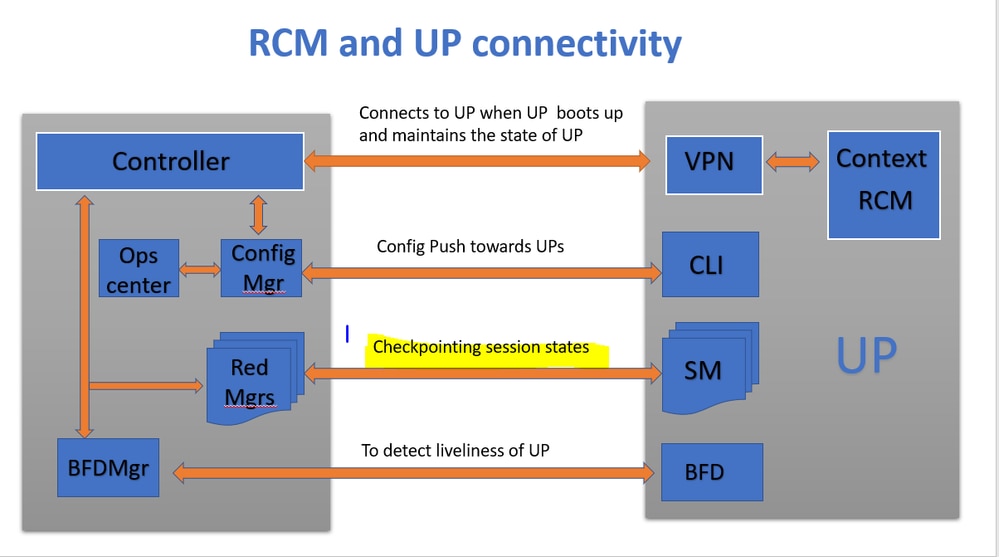
Come illustrato nell'immagine, è possibile osservare le connessioni dirette tra i gestori di ridondanza (denominati checkpoint mgrs) in RCM e i sessmgrs in UPF per la registrazione dei checkpoint.
Mappatura Redmgrs e Sessmgrs
1. Ogni UP ha un numero "N" di sessmgr.
2. RCM ha un numero "M" di redmgrs a seconda del numero di sessmgrs in UPF.
3. Sia redmgrs che sessmgrs hanno un mapping 1:1 basato sui rispettivi ID in cui sono presenti redmgrs separati per ogni sessmgrs.
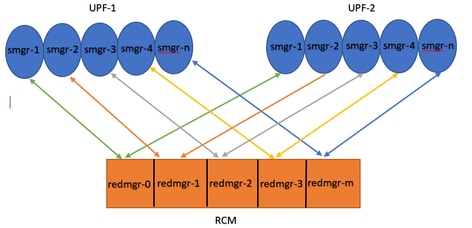
Note :: Redmgr IDs (m) = sessmgr instance ID (n-1)
For example :: smgr-1 is mapped with redmgr 0;smgr-2 is mapped with redmgr-1,
smgr-n is mapped with redmgr(m) = (n-1)
This is important to understand proper IDs of redmgr because we need to have proper logs to be checked
Registri necessari
Log di RCM - Output dei comandi:
rcm show-statistics checkpointmgr-endpointstats
RCM controller and checkpointmgr logs (refer this link)
Log collection
UPF:
Command outputs (hidden mode)
show rcm checkpoint statistics verbose
show session subsystem facility sessmgr all debug-info | grep Mode
If you see any sessmgr in server state check the sessmgr instance IDs and no of sessmgr
show task resources facility sessmgr all
Risoluzione dei problemi
In UPF in genere sono presenti 21 istanze di sessmgr, composte da 20 sessioni attive e 1 istanza in standby (sebbene questo conteggio possa variare in base alla progettazione specifica).
Esempio:
- Per identificare le sessioni attive inattive, è possibile utilizzare questo comando:
show task resources facility sessmgr all
-
In questo scenario, il tentativo di risolvere il problema riavviando le sessmgrs con problemi e persino riavviando sessctrl non determina il ripristino delle sessmgrs interessate.
-
Inoltre, si osserva che i sessmgrs interessati sono bloccati in modalità server anziché in modalità client prevista, una condizione che può essere verificata utilizzando i comandi forniti.
show rcm checkpoint statistics verbose
show rcm checkpoint statistics verbose
Tuesday August 29 16:27:53 IST 2023
smgr state peer recovery pre-alloc chk-point rcvd chk-point sent
inst conn records calls full micro full micro
---- ------- ----- ------- -------- ----- ----- ----- ----
1 Actv Ready 0 0 0 0 61784891 1041542505
2 Actv Ready 0 0 0 0 61593942 1047914230
3 Actv Ready 0 0 0 0 61471304 1031512458
4 Actv Ready 0 0 0 0 57745529 343772730
5 Actv Ready 0 0 0 0 57665041 356249384
6 Actv Ready 0 0 0 0 57722829 353213059
7 Actv Ready 0 0 0 0 61992022 1044821794
8 Actv Ready 0 0 0 0 61463665 1043128178
Here in above command all the connection can be seen as Actv Ready state which is required
show session subsystem facility sessmgr all debug-info | grep Mode
[local]
# show session subsystem facility sessmgr all debug-info | grep Mode
Tuesday August 29 16:28:56 IST 2023
Mode: UNKNOWN State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
In questo caso, tutte le sessioni dovrebbero essere in modalità client. Tuttavia, in questo problema, sono in modalità server, che impedisce loro di gestire il traffico.
Passaggio alla modalità server in corso
-
Per facilitare la comunicazione e il trasferimento dei checkpoint, ogni session manager (sessmgr) stabilisce una connessione peer TCP con il corrispondente redmgr (redundancy manager).
-
Una volta stabilita la connessione peer TCP, redmgr può controllare tutti i contesti del sottoscrittore da sessmgr e salvarli. Ciò consente il passaggio continuo, in quanto i checkpoint possono essere trasferiti ad altre funzioni UPF (User Plane Functions) con le rispettive istanze di sessmgr.
-
È fondamentale che sessmgr sia sempre in modalità CLIENT. Se, per qualsiasi motivo, sessmgr viene rilevato in modalità server, indica una connessione peer TCP interrotta con il redmgr associato. In questo scenario, il checkpoint non verrà eseguito.
-
Quando i membri della sessione sono bloccati in questo stato all'interno dell'UPF, l'esecuzione di un passaggio non pianificato a un altro UPF senza considerare lo stato di sessmgr causa lo stesso problema. sessmgr non è in grado di gestire il traffico in questa situazione.

Nota: In alcuni casi, checkpointmgr è in attesa del checkpoint quando RCM ha avviato il checkpointing e in attesa della risposta di UPF. Tuttavia, in assenza di risposta, il responsabile del checkpoint non è in grado di comunicare, il che comporta un ritardo nel completamento della procedura di switchover che supera il valore del timer di switchover. In questi casi UP si blocca anche nello stato PendActive.
È possibile verificare questa condizione nelle statistiche di RCM e nei registri di redmgr. Inoltre, con questo comando, è possibile conoscere quale checkpoint mgr presenta un problema con quale UPF.
rcm show-statistics checkpointmgr-endpointstats
4. Esistono diversi motivi per cui sessmgr entra in modalità server localmente, ma uno dei motivi principali è illustrato di seguito.
Motivo per cui Sessmgr entra in modalità server
1. In base al numero di responsabili di sessione nella funzione piano utente (UPF), le repliche vengono create per Gestione ridondanza (redmgr) e configurate in Gestione controllo risorse DITA (RCM). Questa configurazione garantisce che ogni redmgr sia connesso a un'istanza di gestione delle sessioni.
2. Se esiste un mapping 1:1 tra redmgr e sessmgr, che cosa si verifica quando l'ID istanza del gestore sessioni supera un valore superiore al numero di gestori sessioni?
For example :::
Sessmgr instance ID :: 1 to 20
Redmgr IDs :: 0 to 19
In this example somehow if my sessmgr instance ID goes beyond the mentioned limit i.e say 21/22/23/24/25 so in this case redmgr is already mapped with instance IDs 0 to 19 and would be unaware about this new sessmgr instance ID created by UPF from 21 to 25 and in such a case sessmgr with this instance IDs :: 21/22/23/24/25 will not be able to form any TCP peer connection with RCM redmgr leading to no checkpoint sync and since there won’t be any checkpoint sync sessmgr will get stuck into server mode and won’t take any traffic.
Refer this diagram
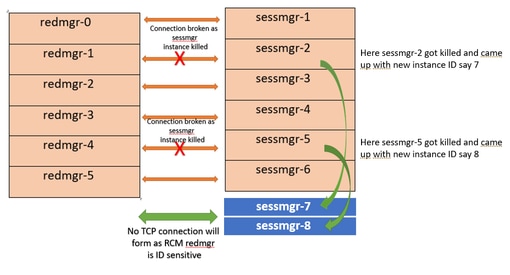
Both this sessmgr instance-7/8 have no TCP peer connection since for RCM redmgr-1 was
connected with instance-2 and redmgr-2 was connected to instance-5 so even though sessmgr
came up with new instance ID value which is beyond defined limit it wont have connection
back with redmgrs which is still just pointing to previous instance but connection is broken
Soluzione alternativa
Per risolvere il problema, limitare il numero di ID istanza di sessmgr in modo che corrisponda al numero di sessmgrs in UPF e al numero di redmgrs in RCM, come specificato dal comando indicato.
Max value of sessmgr instance ID = no of checkpointmgr – 1
In base a questa logica, è necessario definire il numero di sessmgrs, incluse le sessmgrs in standby.
task facility sessmgr max <no of max sessmgrs>
Note :: Implementation of this command needs node reload to enable full functionality of this command
Eseguendo questo comando, indipendentemente dal numero di volte in cui sessmgr viene ucciso, viene sempre restituito un valore ID istanza uguale o inferiore al numero massimo di sessmgr. Ciò consente di evitare problemi di checkpoint con RCM e impedisce a sessmgr di accedere alla modalità server per questo motivo.
 Feedback
Feedback