Introduzione
In questo documento vengono descritti i passaggi necessari per sostituire entrambi i dischi rigidi difettosi nel server in una configurazione Ultra-M che ospita funzioni di rete virtuale (VNF) StarOS.
Premesse
Ultra-M è una soluzione di base di pacchetti mobili preconfezionata e convalidata, progettata per semplificare l'installazione di VNF. OpenStack è Virtualized Infrastructure Manager (VIM) per Ultra-M ed è costituito dai seguenti tipi di nodi:
- Calcola
- Disco Object Storage - Compute (OSD - Compute)
- Controller
- Piattaforma OpenStack - Director (OSPD)
L'architettura di alto livello di Ultra-M e i componenti coinvolti sono illustrati in questa immagine:
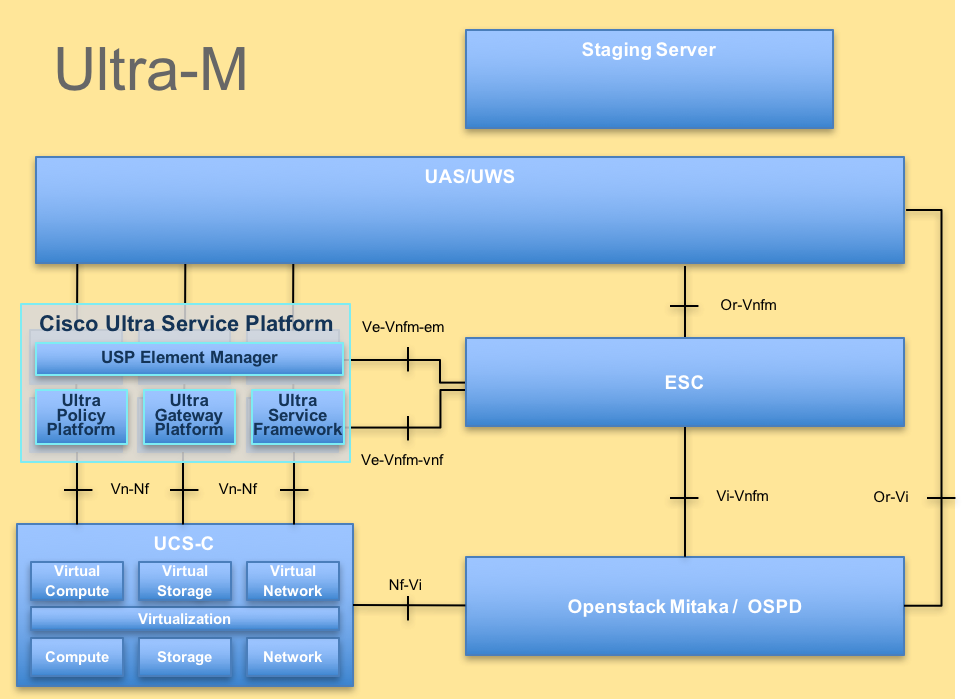 Architettura UltraM
Architettura UltraM
Questo documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M e descrive i passaggi richiesti da eseguire a livello OpenStack e StarOS VNF al momento della sostituzione del server dei controller.
Nota: Per definire le procedure descritte in questo documento, viene presa in considerazione la release di Ultra M 5.1.x.
Abbreviazioni
| VNF |
Funzione di rete virtuale |
| CF |
Funzione di controllo |
| SF |
Funzione di servizio |
| ESC |
Elastic Service Controller |
| MOP |
Metodo |
| OSD |
Dischi Object Storage |
| HDD |
Unità hard disk |
| SSD |
Unità a stato solido |
| VIM |
Virtual Infrastructure Manager |
| VM |
Macchina virtuale |
| EM |
Gestione elementi |
| UAS |
Ultra Automation Services |
| UUID |
Identificatore univoco universale |
Errore di entrambi i dischi rigidi
Ogni server bare-metal è dotato di due unità HDD che fungono da DISCO DI AVVIO nella configurazione Raid 1. In caso di guasto di un singolo disco rigido, poiché è presente la ridondanza di livello RAID 1, il disco rigido guasto può essere sostituito a caldo. Tuttavia, se entrambi gli HDD si guastano, il server non sarà attivo e si perderà l'accesso al server. Per ripristinare l'accesso al server e ai servizi, è necessario per sostituire entrambi gli HDD e aggiungere il server allo stack di overcloud esistente.
La procedura per sostituire un componente guasto su un server UCS C240 M4 può essere richiamata da Sostituzione dei componenti server.
In caso di guasto di entrambi gli HDD, sostituire solo questi due HDD difettosi nello stesso server UCS 240M4. La procedura di aggiornamento del BIOS non è necessaria dopo la sostituzione di nuovi dischi.
Nella soluzione Ultra-M basata su OpenStack, il server bare metal UCS 240M4 può assumere uno dei seguenti ruoli: Compute, OSD-Compute, Controller o OSPD. In queste sezioni vengono illustrati i passaggi necessari per gestire entrambi i guasti del disco rigido in ciascuno di questi ruoli server.
Nota: Negli scenari in cui entrambi gli HDD sono sani ma un altro hardware è difettoso nel server UCS 240M4, sostituire UCS 240M4 con il nuovo hardware, tuttavia, riutilizzare gli stessi HDD. In questo caso, solo gli HDD sono difettosi, quindi riutilizzare lo stesso UCS 240M4 e sostituire gli HDD difettosi con nuovi HDD.
Errore di entrambi i dischi rigidi sul server di elaborazione
Se il guasto di entrambi gli HDD viene rilevato in UCS 240M4 che funge da nodo di calcolo, seguire la procedura di sostituzione descritta in Procedura di sostituzione del server di calcolo.
Errore di entrambi i dischi rigidi sul server controller
Se il guasto di entrambi gli HDD viene rilevato in UCS 240M4 che funge da nodo di controllo, seguire la procedura di sostituzione descritta nell'esempio del router.
Poiché il server del controller che rileva entrambi gli errori del disco rigido non sarà raggiungibile tramite Secure Shell (SSH), accedere a un altro nodo del controller per eseguire la procedura di arresto normale indicata nel collegamento indicato.
Errore di entrambi i dischi rigidi sul server di elaborazione OSD
Se il guasto di entrambi gli HDD viene rilevato in UCS 240M4 che funge da nodo di calcolo OSD, seguire la procedura di sostituzione indicata nella .
Nella procedura qui descritta, non è possibile eseguire lo spegnimento regolare dello storage di Ceph poiché entrambi gli errori determinano l'irraggiungibilità del server. Ignorare quindi tali passaggi.
Errore di entrambi i dischi rigidi sul server OSPD
Se il guasto di entrambi gli HDD viene rilevato in UCS 240M4, che funge da nodo SN OSPD, seguire la procedura di sostituzione indicata nella .
In questo caso, il backup OSPD precedentemente archiviato è necessario per il ripristino dopo la sostituzione del disco rigido, altrimenti sarà come una completa ridistribuzione dello stack.
 Feedback
Feedback