キャパシティと性能の管理:ベスト プラクティス ホワイト ペーパー
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
概要
大規模な企業やサービス プロバイダーのネットワークにおいて、ハイ アベイラビリティはミッションクリティカルな要件です。より高いアベイラビリティを実現する上で、ネットワーク マネージャは、予定外のダウン タイム、専門知識の不足、不十分なツール、複雑なテクノロジー、ビジネスの統合、競争の激しい市場など、増え続ける課題に直面します。キャパシティおよびパフォーマンス管理は、ネットワーク マネージャが新しいビジネス目標と、ネットワークの一貫したアベイラビリティおよびパフォーマンスを実現する際に役立ちます。
このドキュメントでは、次のトピックを扱います。
-
ネットワークにおけるリスクと潜在的なキャパシティ問題など、キャパシティとパフォーマンスに関する一般的な問題。
-
what-if 分析、ベースライン化、傾向分析、例外管理、QoS 管理など、キャパシティおよびパフォーマンス管理のベスト プラクティス。
-
キャパシティ プランニングで使用される一般的な技術、ツール、MIB 変数、しきい値など、キャパシティ プランニング戦略の構築方法。
キャパシティおよびパフォーマンス管理の概要
キャパシティ プランニングとは、ビジネスに不可欠なアプリケーションにパフォーマンスまたはアベイラビリティの影響が及ばないよう、必要なネットワーク リソースを決定するプロセスです。パフォーマンス管理とは、ネットワーク サービスの応答時間、一貫性、個々のサービスおよびサービス全体の品質を管理する方法です。
注:パフォーマンスの問題は通常、容量に関連しています。帯域幅に問題があると、ネットワーク経由で送信されるデータがキューで待機する必要が生じ、アプリケーションの動作が遅くなります。音声アプリケーションの場合、遅延やジッターなどの問題は音声コールの品質に直接影響します。
多くの組織は、すでにキャパシティに関するかなりの情報を収集し、問題の解決、変更の検討、新しいキャパシティおよびパフォーマンス機能の実装に絶えず取り組んでいます。ところが、組織で傾向分析と what-if 分析が定期的に行われることはありません。what-if 分析とは、ネットワーク変更の影響を特定するプロセスです。傾向分析は、ネットワークのキャパシティとパフォーマンスの問題をベースライン化し、ネットワーク トレンドの基準を見直して将来的なアップグレード要件を把握するためのプロセスです。キャパシティおよびパフォーマンス管理には、ユーザから報告される前に問題を特定して解決する例外管理と、ネットワーク管理者が個々のサービス パフォーマンスを計画および管理して問題を特定する QoS 管理も含まれます。次の図は、キャパシティおよびパフォーマンス管理のプロセスを示しています。
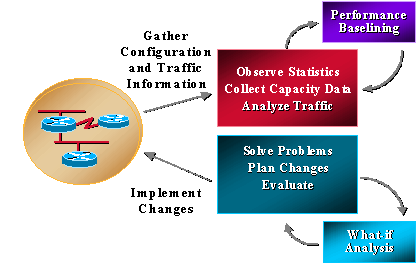
また、キャパシティおよびパフォーマンス管理は、一般的に CPU とメモリに関連するものに制限されます。問題が潜在する可能性のあるエリアは次のとおりです。
-
CPU
-
バックプレーンまたは I/O
-
メモリとバッファ
-
インターフェイスとパイプのサイズ
-
キューイング、遅延、ジッター
-
速度と距離
-
アプリケーションの特徴
キャパシティ プランニングおよびパフォーマンス管理に関する資料では、「データ プレーン」と「コントロール プレーン」という用語が使用されていることがあります。 データ プレーンでは、キャパシティとパフォーマンスの問題が単純にネットワークを通過するデータに関係するのに対し、コントロール プレーンではデータ プレーンが適切に機能するために必要なリソースに関係します。コントロール プレーンの機能には、ルーティング、スパニング ツリー、インターフェイスのキープアライブ、デバイスの SNMP 管理といったサービス オーバーヘッドが含まれます。これらのコントロール プレーン要件では、ネットワークを通過するトラフィックと同様に、CPU、メモリ、バッファリング、キューイング、および帯域幅が使用されます。コントロール プレーン要件の多くは、システムの機能全体にとっても不可欠です。これらに必要なリソースがなければ、ネットワークは機能しません。
CPU
通常、CPU はどのネットワーク デバイスでもコントロール プレーンとデータ プレーンの両方で使用されます。キャパシティおよびパフォーマンス管理では、常にデバイスとネットワークが機能するのに十分な CPU を確保する必要があります。1 台のデバイスでリソースが不足するだけでネットワーク全体に影響が及ぶ可能性があり、CPU が不十分なためにネットワークが機能しなくなることも珍しくありません。また、メイン CPU 以外によるハードウェア スイッチングが行われない場合は、十分な CPU がないとデータが処理を待機する必要があるため、遅延が増大する可能性もあります。
バックプレーンまたは I/O
バックプレーンまたは I/O はデバイスが処理できるトラフィックの総量を指し、通常はバス サイズまたはバックプレーン性能という用語で表されます。バックプレーンが不十分な場合はパケットのドロップが発生しやすくなり、再送信や追加トラフィックの原因になる可能性があります。
メモリ
メモリは、データ プレーンおよびコントロール プレーン要件があるもう 1 つのリソースです。メモリは、ルーティング テーブルや ARP テーブル、その他のデータ構造などの情報に必要です。デバイスのメモリが不足すると、デバイスでの操作が失敗する場合があります。状況によっては、その操作がコントロール プレーンまたはデータ プレーンのプロセスに影響することもあります。コントロール プレーン プロセスが失敗すると、ネットワーク全体のパフォーマンスが低下します。これは、ルーティング コンバージェンスに追加のメモリが必要なときなどに発生する場合があります。
インターフェイスとパイプのサイズ
インターフェイスとパイプのサイズは、1 つの接続で同時に送信できるデータの量を指します。これは、しばしば接続の速度と間違われることがありますが、実際にはデバイス間でのデータの送信速度が異なることはありません。シリコン スピードとハードウェア性能は、メディアに基づいた使用可能な帯域幅の特定に役立ちます。さらに、ソフトウェア メカニズムがサービスの特定の帯域幅割り当てに合わせてデータを「スロットリング」する場合があります。これは通常、本来の速度性能が 1.54 kpbs ~ 155 mbps 以上のフレーム リレーまたは ATM のサービス プロバイダー ネットワークで実現します。帯域幅制限がある場合、データは送信キューにキューイングされます。送信キューでは、キュー内のデータに優先順位を付けるさまざまなソフトウェア メカニズムが使用されていますが、キュー内にデータがある場合は、既存のデータを先に処理しないとインターフェイスからデータを転送できません。
キューイング、遅延、ジッター
キューイング、遅延、ジッターもパフォーマンスに影響します。さまざまな方法で送信キューを調整し、パフォーマンスに影響を与えることができます。たとえば、キューが大きければデータの待機時間は長くなり、キューが小さければデータはドロップされます。これはテール ドロップと呼ばれ、データが再送信される TCP アプリケーションでは許容されます。ただし音声とビデオは、キューのドロップや著しいキューの遅延が発生すると適切に動作しなくなるため、帯域幅やパイプ サイズには特に注意が必要です。デバイスのリソースが不足していて迅速にパケットを転送できないと、入力キューでもキューの遅延が発生する場合があります。これは、CPU、メモリ、またはバッファが原因になる可能性があります。
遅延とは、パケットを受信してから転送するまでに要する通常の処理時間のことです。標準的な最新のデータ スイッチおよびルータは、リソースの制約がない正常な状態でかなりの低遅延(1 ミリ秒未満)を実現しています。アナログ音声パケットを変換および圧縮するデジタル シグナル プロセッサを搭載した最新デバイスの場合は、遅延が 20 ミリ秒まで大きくなる場合があります。
ジッターとは、音声やビデオなどのストリーミング アプリケーションで起こるパケット間ギャップを意味します。パケット間ギャップの間隔にばらつきがあり、パケットの到着時間が一定しないと、ジッターが大きくなって音声品質は低下します。ジッターは主にキューイング遅延の要因になります。
速度と距離
速度と距離もネットワーク パフォーマンスの要素です。データ ネットワークには、光の速度に基づく一貫したデータ転送速度があります。これは、およそ 100 マイル/ミリ秒です。国際的にクライアント/サーバ アプリケーションを実行している組織では、相応のパケット転送遅延が予想されます。アプリケーションがネットワーク パフォーマンスに合わせて最適化されていない場合、速度と距離がアプリケーション パフォーマンスを左右する重大な要素になる可能性があります。
アプリケーションの特徴
アプリケーションの特徴は、キャパシティとパフォーマンスに与える影響が最も小さいエリアです。小さなウィンドウ サイズ、アプリケーションのキープアライブ、ネットワークを介して送信されるデータ量と必要なデータ量の差といった問題は、多くの環境、特に WAN 環境でアプリケーションのパフォーマンスに影響する場合があります。
キャパシティおよびパフォーマンス管理のベスト プラクティス
この項では、キャパシティおよびパフォーマンス管理の主な 5 つのベスト プラクティスについて詳しく説明します。
サービス レベル管理
サービス レベル管理は、その他の必要なキャパシティおよびパフォーマンス管理プロセスを定義および規制します。ネットワーク マネージャはキャパシティ プランニングの必要性を理解していても、予算と人員の配置に関する制約により、完全なソリューションを実現することができません。サービス レベル管理は、成果物を定義してその成果物に関係するサービスに対する 2 方向のアカウンタビリティを確立することで、リソース問題の解決に役立つことが実証されている方法です。これは、次の 2 つの方法で実現できます。
-
キャパシティおよびパフォーマンス管理を含むサービスについて、ユーザとネットワーク組織の間でサービス レベル契約を作成する。サービス品質を維持するため、サービスにはレポートと推奨情報が含まれているが、ユーザはサービスおよび必要なアップグレードへの資金提供に備える必要がある。
-
ネットワーク組織は、キャパシティおよびパフォーマンス管理サービスを定義し、状況に応じてそのサービスおよびアップグレードへの資金提供を試みる。
いずれにしても、ネットワーク組織はまずキャパシティ プランニングおよびパフォーマンス管理サービスを定義する必要があります。これには、現時点でどのようなサービスを提供できるか、また将来的に何を計画するかが含まれます。完全なサービスには、ネットワーク変更とアプリケーション変更の what-if 分析、定義したパフォーマンス変数のベースライン化と傾向分析、定義したキャパシティおよびパフォーマンス変数の例外管理、および QoS 管理が含まれます。
ネットワークおよびアプリケーションの what-if 分析
計画している変更がもたらす結果を判断するため、ネットワークとアプリケーションの what-if 分析を実施します。what-if 分析を行わないと、組織は変更の成功とネットワーク全体のアベイラビリティに対して大きなリスクを負うことになります。多くの場合、ネットワーク変更は長時間の本稼働ダウンタイムを引き起こす輻輳崩壊の原因となります。また、かなりの数のアプリケーション導入が失敗し、他のユーザとアプリケーションにも影響が及ぶことになります。多くのネットワーク組織で現在も続いているこのような失敗は、わずかなツールと追加の計画手順を利用することで完全に回避できます。
通常、品質の what-if 分析を実施するにはいくつかの新しいプロセスが必要です。最初の手順は、すべての変更のリスク レベルを特定し、リスクの高い変更にはより詳細な what-if 分析を必須にすることです。リスク レベルは、すべての変更の提案で必須項目にすることができます。リスク レベルのより高い変更では、その変更に定義された what-if 分析が必要になります。ネットワークの what-if 分析では、ネットワーク変更がネットワーク使用率とネットワーク コントロール プレーンのリソース問題に与える影響を特定します。アプリケーションの what-if 分析では、プロジェクト アプリケーションの成功、帯域幅要件、およびネットワーク リソースの問題を特定します。次の表は、リスク レベルの割り当てと対応するテスト要件の例です。
| リスク レベル | 定義 | 変更計画での推奨事項 |
|---|---|---|
| 1 |
|
|
| 0 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 |
|
|
what-if 分析が必要な状況を定義した後は、サービスを定義します。
ネットワークの what-if 分析は、モデリング ツールや、実稼働環境を再現したラボを利用して実施できます。モデリング ツールは、アプリケーションがデバイスのリソース問題をどの程度認識するかによって制限されますが、ほとんどのネットワーク変更は新しいデバイスの追加であるため、アプリケーションが変更の影響を認識しない可能性があります。最善の方法は、実稼働ネットワークを表したものをラボ内に構築し、トラフィック ジェネレータを使用して負荷をかけた状態で目的のソフトウェア、機能、ハードウェア、設定をテストすることです。実稼動ネットワークからラボにルート(またはその他の制御情報)をリークした場合も、ラボ環境が強化されます。SNMP、ブロードキャスト、マルチキャスト、暗号化、または圧縮トラフィックなど、さまざまなトラフィック タイプで追加のリソース要件をテストします。このようなさまざまな方法をすべて利用して、ルートの収束、リンク フラッピング、デバイスの再起動など、想定される負荷状況でデバイスのリソース要件を分析します。リソース使用率の問題には、CPU、メモリ、バックプレーン使用率、バッファ、キューイングなど、一般的なキャパシティ リソース エリアが含まれます。
新しいアプリケーションについても、what-if 分析を実施して、アプリケーションの成功と帯域幅要件を判断する必要があります。通常この分析は、プロトコル アナライザと WAN 遅延シミュレータを使用してラボ環境で行い、距離による影響を特定します。必要なものは、PC、ハブ、WAN 遅延デバイス、および実稼動ネットワークに接続されたラボ ルータのみです。テスト ルータで一般的なトラフィック シェーピングまたはレート制限を使用してトラフィックをスロットリングすることで、ラボで帯域幅をシミュレートできます。ネットワーク管理者は、LAN と WAN の両方の環境でアプリケーションの帯域幅要件、ウィンドウイング問題、潜在的なパフォーマンス問題を把握するために、アプリケーション グループを併用することができます。
ビジネス アプリケーションを展開する場合は、事前にアプリケーションの what-if 分析を実施します。これを行わないと、ネットワークが原因でアプリケーション グループのパフォーマンスが低下することになります。新規展開を対象としたアプリケーションの what-if 分析を変更管理プロセスを通じて要求できれば、展開の失敗を回避し、クライアント/サーバとバッチの両方の要件に対する帯域幅使用量の急増をより適切に把握できます。
ベースライン化と傾向分析
ネットワーク管理者はベースライン化と傾向分析を行って、キャパシティの問題がネットワーク ダウンタイムやパフォーマンスの問題を引き起こす前に、ネットワークのアップグレードを計画、実行できます。連続する一定期間のリソース使用率を比較するか、データベースの継時的な情報を抽出すれば、プランナーは過去 1 時間、1 日、1 週間、1 ヵ月、1 年のリソース使用率パラメータを確認できます。いずれの場合も、週単位、隔週単位、または月単位で情報をレビューする必要があります。ベースライン化と傾向分析の問題点は、大規模なネットワークの場合に大量の情報をレビューする必要があることです。
この問題はいくつかの方法で解決できます。
-
キャパシティが問題にならないように、十分なキャパシティとスイッチングを LAN 環境に構築します。
-
傾向情報をグループに分けて、不可欠な WAN サイトやデータセンター LAN など、ネットワークのハイアベイラビリティまたは重要エリアに焦点を合わせます。
-
レポート メカニズムにより、特定のしきい値を超えた特に注意が必要なエリアを強調表示できます。最初に重要なアベイラビリティ エリアを実装すれば、レビューが必要な情報の量を大幅に削減できます。
上記の方法をすべて使用しても、情報を定期的にレビューする必要はあります。ベースライン化と傾向分析は予防的な取り組みであり、組織に事後対処的なサポートのリソースしか存在しない場合、個々がレポートを読むことはありません。
多くのネットワーク管理ソリューションで、キャパシティ リソースの変数に関する情報とグラフが提供されます。しかし残念ながら、ほとんどの場合、これらのツールは既存の問題への事後対処的なサポートに使用されるだけです。これは、ベースライン化と傾向分析の目的に適っていません。シスコ ネットワークに関するキャパシティの傾向情報の提供に有効なツールは、Concord Network Health 製品と INS EnterprisePRO 製品の 2 つです。多くの場合、ネットワーク組織は簡単なスクリプト言語を実行してキャパシティ情報を収集します。スクリプトを使用して収集されたリンク使用率、CPU 使用率、および ping パフォーマンスに関するレポート例を以下に示します。傾向分析が重要となり得るリソース変数として、他にもメモリ、キュー項目数、ブロードキャスト量、バッファ、フレーム リレー輻輳通知、バックプレーン使用率などがあります。リンク使用率と CPU 使用率の情報については、次の表を参照してください。
リンク使用率
| リソース | 住所 | セグメント | Average Utilization (%) | Peak Utilization (%) |
|---|---|---|---|---|
| JTKR01S2 | 10.2.6.1 | 128 Kbps | 66.3 | 97.6 |
| JYKR01S0 | 10.2.6.2 | 128 Kbps | 66.3 | 97.8 |
| FMCR18S4/4 | 10.2.5.1 | 384 Kbps | 51.3 | 109.7 |
| PACR01S3/1 | 10.2.5.2 | 384 Kbps | 51.1 | 98.4 |
CPU Utilization
| リソース | ポーリング アドレス | Average Utilization (%) | Peak Utilization (%) |
|---|---|---|---|
| FSTR01 | 10.28.142.1 | 60.4 | 80 |
| NERT06 | 10.170.2.1 | 47 | 86 |
| NORR01 | 10.73.200.1 | 47 | 99 |
| RTCR01 | 10.49.136.1 | 42 | 98 |
リンク使用率
| リソース | 住所 | AvResT(ミリ秒)09-09-98 | AvResT(ミリ秒)09-09-98 | AvResT(ミリ秒)09-09-98 | AvResT(ミリ秒)10-01-98 |
|---|---|---|---|---|---|
| AADR01 | 10.190.56.1 | 469.1 | 852.4 | 461.1 | 873.2 |
| ABNR01 | 10.190.52.1 | 486.1 | 869.2 | 489.5 | 880.2 |
| APRR01 | 10.190.54.1 | 490.7 | 883.4 | 485.2 | 892.5 |
| ASAR01 | 10.196.170.1 | 619.6 | 912.3 | 613.5 | 902.2 |
| ASRR01 | 10.196.178.1 | 667.7 | 976.4 | 655.5 | 948.6 |
| ASYR01S | 503.4 | ||||
| AZWRT01 | 10.177.32.1 | 460.1 | 444.7 | ||
| BEJR01 | 10.195.18.1 | 1023.7 | 1064.6 | 1184 | 1021.9 |
例外管理
例外管理は、キャパシティとパフォーマンスの問題の特定および解決に有効な方法です。その概念は、キャパシティとパフォーマンスのしきい値違反に関する通知を受け取って、迅速に問題を調査、解決するというものです。たとえば、ルータの CPU 使用率が高いことを示すアラームが届いた場合、ネットワーク管理者は、ルータにログインして CPU 使用率が高くなっている理由を特定できます。その後、CPU 使用率を下げる修復設定を行ったり、問題の原因となっているトラフィックが特にビジネスに不可欠なものでなければ、そのトラフィックをブロックするアクセス リストを作成したりすることができます。
ルータで RMON 設定コマンドを使用するか、Netsys サービス レベル マネージャなどの高度なツールを SNMP、RMON、または NetFlow データと併用することで、より重大な問題に関する例外管理も非常に簡単に設定できます。ほとんどのネットワーク管理ツールは、しきい値と違反のアラームを設定する機能を備えています。例外管理プロセスで重要なのは、問題に関する通知をほぼリアルタイムで提供することです。提供が遅ければ、通知が届いたことに気付く前に問題が消滅してしまう可能性があります。組織で一貫したモニタリングが行われている場合、これは NOC で実現できます。それ以外の場合はポケットベル通知を推奨します。
次の設定例は、常にレビューできるログ ファイルにルータ CPU の上限および下限しきい値の通知を提供します。リンク使用率の重大なしきい値違反やその他の SNMP しきい値については、類似の RMON コマンドを設定できます。
rmon event 1 trap CPUtrap description "CPU Util >75%"rmon event 2 trap CPUtrap description "CPU Util <75%"rmon event 3 trap CPUtrap description "CPU Util >90%"rmon event 4 trap CPUtrap description "CPU Util <90%"rmon alarm 75 lsystem.56.0 10 absolute rising-threshold 75 1 falling-threshold 75 2rmon alarm 90 lsystem.56.0 10 absolute rising-threshold 90 3 falling-threshold 90 4
QoS 管理
QoS 管理では、ネットワーク内に特定のトラフィック クラスを作成し、モニタリングします。トラフィック クラス内に定義された特定のアプリケーション グループに対して、より一貫したトラフィック パフォーマンスが実現します。 トラフィック シェーピング パラメータにより、特定のトラフィック クラスでの優先順位付けおよびトラフィック シェーピングの柔軟性が増します。これらの機能には、専用アクセス レート(CAR)、重み付けランダム早期検出(WRED)、クラスベース重み付け均等化キューイングなどがあります。通常は、よりビジネス クリティカルなアプリケーション、および音声などの特定のアプリケーション要件を対象に、パフォーマンス SLA に基づいてトラフィック クラスを作成します。また、重要でないトラフィックやビジネスに関係のないトラフィックも、優先順位の高いアプリケーションとサービスに影響しない方法で制御されます。
トラフィック クラスを作成するには、ネットワーク使用率、特定のアプリケーション要件、およびビジネス アプリケーションのプライオリティに関する基本的な理解が必要です。アプリケーション要件には、パケット サイズ、タイムアウトの問題、ジッター要件、バースト要件、バッチ要件、および全体的なパフォーマンスの問題に関する知識が含まれます。ネットワーク管理者はこの知識を活用することで、さまざまな LAN/WAN トポロジ全体に一貫したアプリケーションのパフォーマンスを提供する、トラフィック シェーピングの計画と構成を作成できます。
たとえば、ある組織では 2 つの主要なサイト間を 10 メガビットの ATM で接続しています。このリンクは大きなファイルの転送によって輻輳状態になることがあり、オンライン トランザクション処理のパフォーマンス低下や、劣悪または使用不可能な音声品質の原因になっています。
この組織では、4 つの異なるトラフィック クラスが設定されています。音声には最も高い優先順位が指定されており、推定トラフィック量レートを超えてバーストが発生してもこの優先順位は維持されます。重要なアプリケーション クラスには次に高い優先順位が指定されていますが、想定される音声帯域幅要件に満たない合計リンク サイズを超えたバーストに対応できません。したがって、バーストした場合はドロップされます。ファイル転送トラフィックにはさらに低い優先順位が指定されており、他のトラフィックはすべてその中間に設定されています。
そこで、この組織は各クラスのトラフィック量を特定し、各クラス内のパフォーマンスを測定するために、このリンクで QoS 管理を行う必要があります。QoS 管理を行わないと、一部のクラスでスタベーションが発生したり、パフォーマンス SLA が特定のクラス内で満たされなかったりする場合があります。
QOS 設定の管理は、ツールがないため現在も難しい作業です。1 つの方法は、シスコのインターネット パフォーマンス マネージャ(IPM)を使用して、各トラフィック クラスに分類されるリンクで異なるトラフィックを送信することです。この方法を使えば、各クラスのパフォーマンスをモニタして、IPM が提供する傾向分析、リアルタイム分析、ホップバイホップ分析により問題のエリアを特定できます。他の方法は、インターフェイスの統計情報に基づいて、各トラフィック クラス内のキューイングやドロップされたパケットを調べるなど、依然として手動の操作にかなり依存しています。組織によっては、このデータが SNMP 経由で収集されたり、ベースライン化と傾向分析のためにデータベースで解析されたりする場合があります。ネットワーク全体に特定のトラフィック タイプを送信し、特定のサービスやアプリケーションのパフォーマンスを測定するツールなども市場に出回っています。
キャパシティ情報の収集と報告
キャパシティ情報の収集とレポートは、キャパシティ管理の 3 つの推奨エリアにリンクさせる必要があります。
-
ネットワーク変更と変更が環境に及ぼす影響を中心とする what-if 分析
-
ベースライン化と傾向分析
-
例外管理
これらの各エリアで情報収集の計画を作成します。ネットワークまたはアプリケーションの what-if 分析では、ネットワーク環境を再現して、デバイスのコントロール プレーンまたはデータ プレーン内で想定されるリソース問題に関連する変更の影響を特定するためのツールが必要です。ベースライン化と傾向分析を行うには、現在のリソース使用率を示すデバイスとリンクのスナップショットが必要です。そして、収集されるデータを継時的にレビューして、将来的なアップグレード要件を把握します。これにより、ネットワーク管理者はキャパシティまたはパフォーマンスの問題が発生する前に、アップグレードを適切に計画することができます。問題の発生時にネットワーク管理者がネットワークの調整または問題の修正を行えるように、例外管理で警告する必要があります。
このプロセスは次のステップに分けられます。
-
ニーズの特定。
-
プロセスの定義。
-
キャパシティ エリアの定義。
-
キャパシティ変数の定義。
-
データの解釈。
ニーズの特定
キャパシティおよびパフォーマンス管理の計画を作成するには、必要な情報とその情報の目的を理解する必要があります。まずは、計画を 3 つの必要なエリアに分割します。それぞれ、what-if 分析、ベースライン化と傾向分析、および例外管理です。これらの各エリアで、どのリソースとツールが利用可能か、そして何が必要かを調べます。多くの組織がツールのテクノロジーと機能については検討しても、ツールの管理に必要な人材と専門知識を考慮しないため、ツールの導入に失敗しています。プロセスの改善だけでなく、必要な人材と専門知識も計画に含めてください。必要な人材には、ネットワーク管理ステーションを管理するシステム管理者、データベース管理をサポートするデータベース管理者、ツールを使用およびモニタするためのトレーニングを受けた管理者、ポリシー、しきい値、情報収集の要件を決定するより高いレベルのネットワーク管理者が含まれます。
プロセスの定義
ツールを正しく一貫して使用するためのプロセスも必要です。しきい値違反が発生したときにネットワーク管理者が行うべきことや、ネットワークのベースライン化、傾向分析、アップグレードで従うべきプロセスを定義するために、プロセスの改善が必要な場合があります。キャパシティ プランニングの成功に必要な要件とリソースが確定したら、次に方法を検討します。多くの組織は、このタイプの機能を INS などのネットワーク サービス組織にアウトソーシングするか、サービスを中核能力と見なして社内で専門技術を構築することを選択します。
キャパシティ エリアの定義
キャパシティ プランニングの計画では、キャパシティ エリアも定義する必要があります。これらは、共通のキャパシティ プランニング戦略を共有できるネットワーク エリアです。たとえば、企業 LAN、WAN のフィールド オフィス、重要な WAN サイト、ダイヤルイン アクセスなどがあります次に、さまざまなエリアを定義することが役立つ理由をいくつか紹介します。
-
異なるエリアには異なるしきい値を設定できます。たとえば、LAN 帯域幅は WAN 帯域幅よりもかなり安価なため、使用率しきい値は低くなります。
-
エリアが異なれば、モニタリングが必要な MIB 変数も異なる場合があります。たとえば、フレーム リレーのキャパシティ問題を把握するには、フレーム リレーの FECN および BECN カウンタが重要です。
-
ネットワークのエリアによっては、アップグレードが困難であったり、時間がかかったりすることがあります。たとえば、国際回線はリード タイムが非常に長いため、これに対応したより詳細な計画が必要です。
キャパシティ変数の定義
次の重要なエリアは、モニタする変数とアクションが必要なしきい値の定義です。キャパシティ変数の定義は、ネットワーク内で使用されるデバイスとメディアによって大きく異なります。一般的に、CPU、メモリ、リンク使用率などのパラメータは重要です。ただし、特定のテクノロジーや要件に関しては他のエリアが重要な場合があります。これには、キュー項目数、パフォーマンス、フレーム リレー輻輳通知、バックプレーン使用率、バッファ使用率、NetFlow 統計情報、ブロードキャスト量、RMON データが含まれます。確実に成功させるには、長期の計画を念頭に置きながら、いくつかの主要なエリアのみから始めてください。
データの解釈
収集したデータを理解することも、高品質なサービスを提供する上で重要です。たとえば、ほとんどの組織はピーク使用率と平均使用率のレベルを十分に理解していません。次の図は、5 分間の SNMP 収集間隔(緑)に基づいたキャパシティ パラメータのピークを示しています。
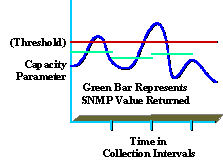
報告された値がしきい値(赤)に達していなくても、収集間隔の間にしきい値を超えるピークが発生している場合があります(青)。 収集間隔中に組織でネットワークのパフォーマンスまたはキャパシティに影響するピーク値が発生する可能性があるということですから、これは重要な情報です。有用性が高く、過剰なオーバーヘッドを引き起こさない収集間隔を慎重に選択してください。
もう 1 つの例は平均使用率です。従業員は 8 時から 17 時までしかオフィスにいないのに、平均使用率が 7X24 の場合、その情報は判断を誤る原因になる可能性があります。
関連情報
更新履歴
| 改定 | 発行日 | コメント |
|---|---|---|
1.0 |
04-Oct-2005 |
初版 |
 フィードバック
フィードバック