DOCSIS におけるデータのスループットについて
内容
概要
ケーブル ネットワークのパフォーマンス測定を試みる前に、考慮すべき制限要因がいくつかあります。可用性と信頼性の高いネットワークを設計し、導入するには、ケーブル ネットワークのパフォーマンス測定の基本的原理を確実に理解する必要があります。このドキュメントではこれらの制限要因の一部を挙げ、導入済みシステムのスループットと可用性を実際に最適化し要件を満たす方法について説明します。
前提条件
要件
このドキュメントの読者は次のトピックについての専門知識を有している必要があります。
-
Data-over-Cable Service Interface Specifications(DOCSIS)
-
無線周波数(RF)技術
-
Cisco IOS® ソフトウェア コマンドライン インターフェイス(CLI)
使用するコンポーネント
このドキュメントの内容は、特定のソフトウェアやハードウェアのバージョンに限定されるものではありません。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、初期(デフォルト)設定の状態から起動しています。対象のネットワークが実稼働中である場合には、どのようなコマンドについても、その潜在的な影響について確実に理解しておく必要があります。
表記法
ドキュメント表記の詳細は、「シスコ テクニカル ティップスの表記法」を参照してください。
背景説明
ビット、バイトとボー
このセクションでは、ビット、バイトとボーの違いを説明します。ビットという言葉は 2 進数を意味するバイナリ ディジットの略で、通常は小文字 b で表記します。2 進数は、電子回路における 2 つの状態である、「オン」または「オフ」の状態を示し、それぞれ「1」と「0」で表記されることもあります。
バイトは大文字 B で表記され、通常、その長さは 8 ビットです。8 ビット以上のバイトもあるため、8 ビット ワードはより正確な表現として、オクテットと呼ばれることもあります。また、バイトには 2 つのニブルがあります。ニブルは 4 ビット ワードとして定義され、バイトの半分です。
ビット レート、またはスループットはビット/秒(bps)を単位として測定し、ビット/秒(bps)で信号の速度に関連付けられています。たとえば、この信号はベースバンドのデジタル信号の場合もあり、デジタル信号を表すように変調されたアナログ信号の場合もあります。
変調されたアナログ信号の一種に 4 位相偏移変調(QPSK)があります。 図1に示すように、信号の位相を90度ずつ操作して4つの異なるシグニチャを作成する変調技術です。これらのシグニチャはシンボルと呼ばれて、そのレートはボーと呼ばれます。ボーは、シンボル/秒と一致します。
図 1:QPSK の図 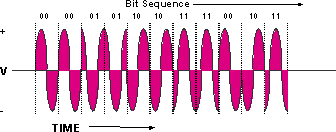
QPSK 信号には 4 つの異なるシンボルがあります。4は22に等しい。指数は、表現できるサイクルごとのビット(シンボル)の理論上の数を示し、この場合は2に等しい。4つのシンボルは2進数00、01、10、および11を表します。したがって、シンボルレート2.56 Msymbols/sを使用してQPSKキャリアを転送する場合、2.56 Mbaudと呼ばれ、論理ビットレートは2.56 Msymbols/s × 2 bits/symbol = 5.12 Mbps2 Mbpsです。この詳細については、このドキュメントで後述します。
また、パケット/秒(PPS)という用語もよく使われます。 これは、パケットに基づいてデバイスのスループットを評価する方法です。この方法では、パケットに含まれるイーサネット フレームが 64 バイトなのか、1518 バイトなのかは関係ありません。ネットワークの「ボトルネック」は、特定の PPS の量を処理する CPU の能力である場合があり、必ずしも bps の合計ではありません。
スループットとは
データのスループットを求めるには、まず理論上の最大スループットを計算し、次に実効スループットを導きます。サービスのサブスクライバが利用できる実効スループットは必ず理論上の最大スループット以下になるため、この計算は必須です。
スループットは、多くの要因に基づいて決まります。
-
ユーザの総数
-
ボトルネックの速度
-
アクセスするサービスの種類
-
キャッシュとプロキシ サーバの使用状況
-
MAC 層の効率
-
ケーブル設備上のノイズとエラー
-
その他の多くの要因
このドキュメントの目的は、DOCSIS 環境のスループットと可用性を最適化する方法と、パフォーマンスに影響を及ぼすプロトコル固有の制限について説明することです。パフォーマンスの問題をテストし、またトラブルシューティングするには、「速度が出ないケーブル モデム ネットワークのトラブルシューティング」を参照してください。アップストリーム(US)またはダウンストリーム(DS)の最大ユーザ数についてのガイドラインは、「CMTS ごとの最大ユーザ数」を参照してください。
レガシー ケーブル ネットワークは、MAC プロトコルとして、ポーリングまたはキャリア検知多重アクセス/衝突検出(CSMA/CD)に依存しています。現在の DOCSIS モデムは、モデムが送信する時間を要求し、CMTS が使用可能なタイムスロットを付与する予約スキームに依存しています。ケーブル モデムには、サービス クラス(CoS)パラメータかサービス品質(QoS)パラメータにマッピングされたサービス ID(SID)が割り当てられます。
集中的な伝送が発生する時分割多重アクセス(TDMA)ネットワークで一定のアクセス速度をすべてのアクセス要求ユーザに保証するには、同時に送信できるケーブルモデムの総数を制限する必要があります。同時ユーザの総数は、統計的な確率アルゴリズムであるポアソン分布に基づいて求められます。
テレフォニーベースのネットワークで使用される統計として、トラフィック エンジニアリングでは、この総数はピーク時の使用状況の約 10 % として示されています。この計算は、このドキュメントの範囲を越えるものです。また、データ トラフィックは音声のトラフィックとは異なります。ユーザがコンピュータに精通した場合や、Voice over IP(VoIP)やビデオ オン デマンド(VoD)サービスの提供が普及するに従い、トラフィックの動向は変化していきます。わかりやすくするため、ピーク時のユーザ数の 50% に、実際に同時にダウンロードしているユーザ数の 20% をかけた場合を想定します。すると、これは、ピーク時の利用状況の 10% と同じ値になります。
同時に使用しているすべてのユーザは、アップストリームとダウンストリームのアクセスで競合します。最初のポーリングでは多くのモデムがアクティブとなることがありますが、どの瞬間でも US でアクティブとなることができるモデムは 1 台だけです。全体的なノイズに影響するモデムは 1 度に 1 台のみのため、これはノイズ対策の面では好都合です。
現在の標準規格に継承されている制約の 1 つは、多くのモデムが単一のケーブル モデム終端システム(CMTS)に接続されているにもかかわらず、メンテナンスとプロビジョニングのために一定のスループットを必要とする点にあります。 この分は、アクティブな顧客のペイロードを犠牲にして賄われます。これはキープアライブ ポーリングと呼ばれ、DOCSIS では通常 20 秒ごとに発生しますが、より頻繁となることもあります。また、モデムごとの US 速度は要求と許可の仕組みにより限界があります。このことは当ドキュメントで後述します。
注: ファイル サイズの参照は 8 ビットから成るバイトで表記されていることに注意してください。つまり、128 kbps は 16 KBps と同じです。同様に、1 MBは100万バイトではなく1,048,576バイトと実際に等しくなります。バイナリ値は常に2の累乗の数値になるためです。 5 MBファイルは5 × 8 × 1,048,576 = 41.94 Mb4 Mb4 Mb4 Mb0です。
スループットの計算
DS ポートが 1 つ、US ポートが 6 つを搭載した CMTS カードを使用していると仮定します。1 つの DS ポートは約 12 のノードを供給するために分割されています。このネットワークの半分を図 2 に示します。
図 2:ネットワークのレイアウト 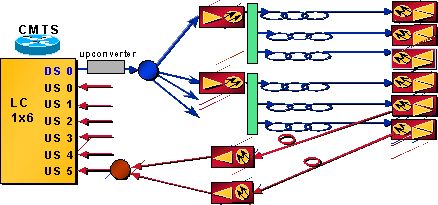
-
ノードあたり 500 世帯 X ケーブルの使用率 80% X モデムの使用率 20% = ノードあたりモデム数 80 台
-
12 ノード X モデム 80 台 = DS ポートあたりのモデム数 960 台
注:多くの複数のサービス事業者(MSO)は、ノードごとに世帯数(HHP)としてシステムを数量化するようになりました。放送衛星を直接受信するサービス(DBS)のサブスクライバが、高速データ サービス(HSD)またはビデオなしのテレフォニー サービスだけを購入している場合もある現在のアーキテクチャでは、これが唯一の定数となります。
注:これらの各ノードからのUS信号は、2つのノードが1つのUSポートを供給するように、おそらく2:1の比率で結合されます。
-
6 つの US ポート X 2 ノード/US = 12 ノード
-
ノードあたりのモデム数 80 X 2 ノード/US = US ポートあたりモデム 160 台
ダウンストリーム
DS のシンボル レート = 5.057 Msymbols/秒(または Mbaud)。約 18% のフィルタ ロールオフ(α)により、図 3 のように 5.057 X(1 + 0.18)= ~ 6 MHz 幅の「丘状域」が発生します。
図 3:デジタル「丘状域」 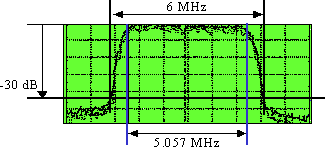
64-QAM を使用すると、64 = 2 の 6 乗(26)となります。 累乗の指数が 6 であるのは、64-QAM でシンボルごとに 6 ビットを使うことを意味しています。よって、5.057 × 6 = 30.3 Mbps です。全体の前方誤り訂正(FEC)と Motion Picture Experts Group(MPEG)圧縮のオーバーヘッドを考慮すると、ペイロードは約 28 Mbps になります。この帯域を DOCSIS シグナリングと共有するため、ペイロードはさらに狭くなります。
注:ITU-J.83 Annex Bは、128/122コードのReed-Solomon FECを示しています。これは、128シンボルごとに6つのオーバーヘッドのシンボルを意味します。したがって、6 / 128 = 4.7 %。トレリス コーディングでは、64-QAM で 15 バイトごとに 1 バイトが、256-QAM で 20 バイトごとに 1 バイトがオーバーヘッドになります。これは、それぞれ 6.7% および 5% のオーバーヘッドです。MPEG-2 は 188 バイトのパケットで構成され、これに 4 バイト(場合によっては、5 バイト)のオーバーヘッドが生じます。つまり、オーバーヘッドの率は 4.5 / 188 = 2.4% です。64-QAM では速度の表示が 27Mbps、256-QAM では 38 Mbps となるのは、これが理由です。イーサネットのパケット(46 バイトのパケット、1500 バイトのパケットを問わず)にも 18 バイトのオーバーヘッドがあることに注意してください。他に DOCSIS のオーバーヘッドが 6 バイトと、IP のオーバーヘッドもあります。これらを合わせてさらに 1.1 ~ 2.8% のオーバーヘッドが見込まれます。また、DOCSIS MAP トラフィックのために、さらに 2 % のオーバーヘッドが追加される可能性があります。64-QAM の実際の検証速度は 26 Mbps に近いものとなります。
960 台のモデムがまったく同時にデータをダウンロードする可能性は低いですが、その場合、各モデムのスピードは約 28 kbps にとどまります。より現実的なシナリオでは、使用のピークの 10% を想定し、最も混雑した状況での最悪の場合の理論的最大スループットを 280 kbps が得られます。オンラインになっている顧客が 1 名のみであれば、理論的には 26 Mbps の帯域を使用できます。しかし、TCP に送信する必要がある US の確認応答が DS のスループットに影響し、加えて、他のボトルネック(PC やネットワークのネットワーク インターフェイス カード(NIC)など)が顕著になります。 実際には、ケーブル配信会社では、サインアップするサブスクライバが増えた場合に、利用可能なスループットが達成できないと認識されないように、これを 1 Mbps または 2 Mbps にまでレート制限します。
アップストリーム
DOCSIS による 2 ビット/シンボルの QPSK 変調で、アップストリームの速度は約 2.56 Mbps となります。これは、シンボルレート 1.28 Msymbols/秒 X 2 ビット/シンボルから算出されます。フィルタの α を 25% とすると、帯域幅(BW)は 1.28 X(1 + 0.25)= 1.6 Mhz になります。FEC を使用する場合は、約 8% 少なくなります。メンテナンス、競合防止のための予約済みタイムスロット、確認応答(「ACK」)のオーバーヘッドとして、さらに 5~10% のオーバーヘッドが発生します。 したがって、全体としては約 2.2 Mbps になり、これが US ポートごとに 160 の潜在的な顧客間で共有されます。
注:DOCSIS層のオーバーヘッド= 64バイトから1518バイトまでのイーサネットフレームあたり6バイト(VLANタギングを使用する場合は1522バイトになる可能性があります)。 また、最大のバースト転送サイズと、結合やフラグメンテーションを使用するかにも左右されます。
-
US FEC は可変です。~ 128 / 1518 または~ 12 / 64 = ~ 8% または~ 18 %。メンテナンス、競合防止用の予約済みタイムスロット、確認応答(ACK)に約 10% が使用されます。
-
BPI セキュリティまたは拡張ヘッダー = 0~240 バイト(通常 3~7)。
-
プリアンブル = 9~20 バイト。
-
ガードタイム >= 5 シンボル =~ 2 バイト。
ピーク時の使用状況を 10 % と仮定すると、最悪ケースのサブスクライバごとのペイロードとして 2.2 Mbps /(160 × 0.1)= 137.5 kbps が求められます。一般的な家庭向けのデータ使用(Web 閲覧など)では、US には DS ほどの高いスループットは不要でしょう。この速度は家庭用の用途には十分といえますが、商用サービスでの展開には不十分です。
制約要因
要求と許可のサイクルから、DS インターリーブまで、「実際の」データスループットに影響する制約要因は数多く存在しています。制約要因の理解はスループットの予測と最適化に役立ちます。
ダウンストリーム パフォーマンス - MAP
モデムへ MAP メッセージを送信することで、DS のスループットは低下します。モデムが US 送信のための時間を要求できできるよう、時間の MAP メッセージが DS から送出されます。MAP が 2 ミリ秒ごとに送信されるとすると、合計で 1/0.002 秒 = 毎秒 500 の MAP になります。MAP メッセージが 64 バイトであれば、64 バイト X 8 ビット X 500 MAP/秒 = 256 kbps を消費します。CMTS シャーシにあるブレード 1 台に 6 つのアップストリームポートと 1 つのダウンストリームポートがある場合、モデムのすべての MAP メッセージに対応するために DS で使用されるスループットは 6 X 256000 bps = 約 1.5 Mbps となります。この場合、MAP は 64 バイトで、実際には 2 ミリ秒ごとに送信されるものと仮定されています。実際には、変調方式と使用されている US 帯域幅の量によって、MAP サイズが若干大きくなる場合があります。これが 3 ~ 10% のオーバーヘッドとなることは珍しくありません。さらに、DS チャネルで送信されるシステム メンテナンス メッセージは他にもあります。これらもオーバーヘッドを増加させます。しかし、その影響は通常無視できる程度のものです。中央処理装置(CPU)はすべての MAP を追跡する必要があるため、MAP メッセージにより CPU に負荷がかかり、また DS のスループットに悪影響を及ぼすことがあります。
TDMA と標準符号分割多重接続(S-CDMA)チャネルを同一の US で行った場合、CMTS は各物理ポートに「double maps」を送信する必要があります。よって、DS における帯域幅消費は倍増します。これは DOCSIS 2.0 の仕様の一部であり、相互運用性確保のために必要です。加えて、US チャネルのディスクリプタや他の US 制御メッセージも倍増します。
アップストリーム パフォーマンス - DOCSIS 遅延
US パスでは、CMTS と CM 間の要求と認可のサイクルだけが、他のすべての MAP を活用できます。これは、ラウンド トリップ時間(RTT)、MAP の長さ、および MAP アドバンス時間によって変わります。これは、DS のインターリーブの影響を受ける RTT と、モデムが複数の未決要求を抱えることができない DOCSIS の仕様、さらに、これに関連した「要求と許可による遅延」によるものです。この遅延は CM と CMTS との通信に起因しています。よって、これはプロトコルによる遅延と言えます。要するに、CM はデータを送信するためにまず CMTS の許可を求める必要があります。CMTS はこれらの要求に対応し、MAP スケジューラが使えるかを確認し、要求を次のユニキャスト送信に備えてキューに入れる必要があります。DOCSIS プロトコルによって指定されたこのような通信の交錯により、遅延が発生します。モデムは最後に行った要求の許可が DS に戻るのを待機するため、その他の MAP がすべて失われる可能性があります。
MAP の間隔が 2 ミリ秒の場合、1 秒に 500 回の MAP となり、それを 2 で割ると、送信の機会として毎秒 250 回の MAP が期待できるため、これは 250 PPS に相当します。500 回の機会を 2 で割るのは、実際の設備における要求と許可の間の RTT は 2 ミリ秒より相当に長いものであるためです。この長さは 4 ミリ秒を超えることもあり、順次発生する MAP すべてで RTT が長引くことがあります。1518 バイトのイーサネットフレームから成る典型的なパケットを 250 PPS で送信すると、バイト = 8 ビットであるため、伝送レートは 3 Mbps になります。これが、モデム単体のアップストリーム スループットの実用的な限界です。約 250 PPS の制限がある場合、小さなパケット(64 バイト)ではどうなるでしょう。この場合、128 kbps にしかなりません。ここで、連結が役立ちます。このドキュメントの「連結とフラグメンテーションの効果」のセクションを参照してください。
US チャネルのシンボルレートと変調方式により、1518 バイトのパケット送信に要する時間は 5 ミリ秒を超えることがあります。US を通じて CMTS にパケットを送るのに 5 ミリ秒かかると、CM では DS 上の MAP 機会が約 3 回失われるだけです。そのため、PPS は 165 ほどに減ってしまいます。MAP の間隔を縮めれば、MAP メッセージを増やせますが、代償として DS のオーバーヘッドが発生します。MAP を増やすと US の送信機会は増えますが、実際の光同軸ハイブリッド(HFC)設備では、いずれにしてもそれ以上の機会を失います。
幸いにも、DOCSIS 1.1 は Unsolicited Grant Service(UGS)を追加し、これにより音声トラフィックには要求と許可のサイクルが不要となりました。代わりに、通話終了まで、音声パケットの伝送は 10 または 20 ミリ秒ごとにスケジュールされます。
注:CMが大量のデータブロックUS(20 MBファイルなど)を送信している場合、帯域幅の要求を個別の要求ではなくデータパケットでピギーバックしますが、モデムは要求と許可のサイクルを行う必要があります。ピギーバックにより、要求をデータとともに、競合するタイムスロットではなく、専用のタイムスロットで送ることができます。これにより、パケットの衝突や要求パケットの破損を防止できます。
TCP か、UDP か
スループットを検証するときによく見過ごされる点として、実際に使用されているプロトコルがあります。TCP のようなコネクション型のプロトコルであるか、または User Datagram Protocol(UDP)のようなコネクションレス型なのかを確認すべきです。UDP では、受信品質とは無関係に情報が送信されます。これは、「ベスト エフォート型」配信と呼ばれます。エラーがあるビットを受信しても、そのまま次のビットへと進みます。TFTP はベスト エフォート型配信プロトコルのもう 1 つの例です。これはリアルタイムの音声またはストリーミング ビデオの送信で一般的なプロトコルです。一方で TCP は、パケットを正しく受信したことを証明する確認応答を必要としています。FTP がこの一例です。ネットワークが正しく管理されていれば、プロトコルが十分にダイナミックになり、確認応答が要求される前に多くのパケットを連続して送信できる可能性があります。このことを、「ウィンドウ サイズの拡大」といい、この機能は Transmission Control Protocol の標準規格の一部です。
注:TFTPに関して注意すべき点は、UDPを使用するためオーバーヘッドが少なくなっても、通常はステップ確認方式が使用され、スループットに悪影響を及ぼします。このアプローチにより、複数の未処理のデータパケットを保持できなくなります。このため、正確なスループットを調べるのに適した方法ではありません。
DS トラフィックが確認応答を呼び、US トラフィックを生む結果になるという点に注意します。また、短時間の US 中断により TCP 確認応答がドロップすると、TCP の速度が低下します。これは UDP では発生しません。US のパスが混雑すると、CM は最終的にキープアライブ ポーリングに失敗し、約 30 秒後には DS の再スキャンが始まります。TCP も UDP も、短時間の中断に耐えることができます。TCP パケットはキューに保持されるか、喪失します。DS の UDP トラフィックは維持されます。
US スループットの制限により DS のスループットも制限されることがあります。たとえば DS のトラフィックが同軸ケーブルまたは衛星回線により伝送され、US のトラフィックが電話回線で伝送される場合、最速 10 Mbps とアドバタイズされていても、28.8 kbps の US のスループットが DS のスループットを 1.5 Mbps にまで低下させることもあります。これは、低速なリンクが US の確認応答フローを遅延させ、TCP が DS の速度を下げるためです。このボトルネックを軽減するため、US を電話回線とする Telco-Return 方式ではポイントツーポイント プロトコル(PPP)を活用してよりスマートな確認応答を行っています。
DS での MAP 生成は US での要求と許可のサイクルに影響します。TCP トラフィックが処理される際に、応答確認の伝送でも要求と許可のサイクルが必要です。US で確認応答を連結しないと、DS に著しい影響が出ることがあります。たとえば、ゲームのユーザが DS に 512 バイトのパケットからなるトラフィックを送信した場合を考えます。US の限界を 234 PPS とし、DS には確認応答ごとにパケットが 2 つ投入される場合、512 × 8 × 2 × 234 = 1.9 Mbps の伝送が生じます。
Windows の TCP/IP スタック
Windows での一般的なダウンロードの速度は 2.1~3 Mpbs です。UNIX または Linux デバイスの場合は、TCP/IP スタックが改良されており、DS パケットの受信ごとに確認応答を送信する必要がないため、多くの場合 Windows よりもパフォーマンスが向上しています。パフォーマンスの制限が Windows TCP/IP ドライバによるものかを確認できます。確認応答のパフォーマンスに制約がある場合、このドライバ機能が低下することがよくあります。確認にはインターネットにあるプロトコル アナライザを使用できます。これは、サーバに送信した TCP パケットから直接取得したインターネット接続パラメータを表示するように設計されたプログラムです。プロトコル アナライザは特殊な Web サーバとして機能します。しかし、別の Web ページを表示するためのものではありません。そうではなく、同じページ内でのすべての要求に応答します。表示される値は、要求を送信するクライアントの TCP 設定に応じて変化します。ソフトウェアは、制御を CGI スクリプトに渡し、これが分析を実際に行って結果を表示します。プロトコル アナライザで、ダウンロードのパケットの長さが 1518 バイトであり(DOCSIS 最大伝送ユニット [MTU])、US の確認応答が概ね 160~175 PPS で伝送されているかどうかを確認できます。パケットの伝送レートがこれらの数値を下回る場合は Windows ドライバを更新し、Unix や Windows NT のホストを調整します。
Windows のホストを調整するには、レジストリの設定を変更します。まず、MTU を増やすことができます。パケットのサイズは MTU と呼ばれ、ネットワークの物理フレーム単体で伝送できるデータの最大量です。イーサネットでは、MTU は 1518 バイトです。PPPoE では、1492 です。ダイヤルアップ接続の場合は、576個です。大きなパケットを使用すると、オーバーヘッドが小さく、ルーティングの決定が少なくなり、クライアントのプロトコル処理とデバイス割り込みが少なくなるという点が違います。
各伝送ユニットは、ヘッダーと実際のデータから構成されます。実際のデータ部分の長さは最大セグメント サイズ(MSS)と呼ばれ、伝送可能な TCP データの最大のセグメントを定義します。基本的に、MTU = MSS + TCP/IP ヘッダーといえます。よって、各パケット内の最大有効データを反映するために、MSS を 1380 に調整することもできます。また、MTU と MSS の現在の設定を調整した後は、Default Receive Window(RWIN)も最適化できます。プロトコル アナライザが、この設定での最適な値を提示します。さらに、プロトコル アナライザにより、以下の設定を確認できます。
-
MTU Discovery(RFC1191)= ON

-
Selective Acknowledgement(RFC2018)= ON
-
Timestamps(RFC1323)= OFF
-
TTL(Time to Live)= OK
ネットワークプロトコルごとに Windows レジストリを設定することで、性能を向上できます。ケーブル モデムのための最適な TCP 設定は、Windows のデフォルト設定と異なるようです。したがって、レジストリの最適化については、オペレーティング システムごとに固有の情報があります。たとえば、Windows 98 以降のバージョンでは TCP/IP スタックがいくらか改善されています。802.11 の標準規格には以下があります。
-
選択的な確認応答(SACK)のサポート
-
高速再送(Fast Retransmission)と高速リカバリ(Fast Recovery)のサポート
Windows 95 の WinSock 2 アップデートは、TCP のラージウィンドウとタイムスタンプをサポートしました。つまり、オリジナルの Windows Socket をバージョン 2 にアップデートした場合、Windows 98 の推奨事項を使用できます。Windows NT では、TCP/IP の処理は Windows 9x と少し異なっています。Windows NT はすでにネットワーク向けに最適化されているため、Windows 9x と異なり、少々の微調整ではパフォーマンス向上は感じられないことに留意してください。
また、Windows レジストリの変更には、Windows のカスタマイズに関してある程度の習熟が必要です。レジストリの編集が不安な場合、レジストリに自動的に最適な値を設定できる出来合いのパッチをインターネットからダウンロードし、利用します。レジストリを編集するには、Regedit のようなエディタを使用する必要があります([START] > [Run] を選択し、[Open] フィールドに「Regedit」と入力します)。
パフォーマンス向上の要因
スループットの決定
データ スループットに影響を与える要素は多数あります。
-
ユーザの総数
-
ボトルネックの速度
-
アクセスするサービスの種類
-
キャッシュ サーバの使用率
-
MAC 層の効率
-
ケーブル設備上のノイズとエラー
-
Windows TCP/IP ドライバ内の制限など、他のさまざまな要因
「パイプ」を共有するユーザが増えるほど、サービスの速度は低下します。さらに、ボトルネックは、ネットワークではなく、アクセス対象である Web サイトに存在していることもあります。使用中のサービスについて考えると、普通のメールや Web 閲覧は時間の経過に関しては効率が非常に悪いものといえます。ビデオ ストリーミングの使用がある場合は、この種類のサービスでより多くのタイムスロットが必要となります。
プロキシ サーバを使用し、ローカル エリア ネットワークのコンピュータで頻繁にダウンロードするサイトをキャッシュし、インターネット全体のトラフィックを軽減できます。
「予約と許可」が DOCSIS モデムで推奨される方法である限り、モデム単体の速度は限られたものになります。この方法は、ポーリングや純粋な CSMA/CD での使用より、家庭用の用途で効率的です。
アクセス速度の向上
多くのシステムでは、ノードごとの世帯数を 1000 から 500 へ、そして 250 へ、さらには受動光ネットワーク(PON)や FTTH へと削減しています。PON は、正しく設計すれば、アクティブなリンクが接続されていない状態でノードあたり 60 世帯まで対応できます。FTTH は、一部の地域でテスト中ですが、ユーザの大部分にはまだコストが高すぎます。ノードあたりの世帯数を減らしても、ヘッドエンドで受信機を組み合わせるのであれば、実際の速度は悪化することが考えられます。2 台の光ファイバ受信機は、単体の受信機より劣った結果を生みます。ファイバあたりの世帯数が少ないほど、入力からのレーザー クリッピングに遭遇する可能性は低くなります。
最も明確なセグメンテーション技術として、光ファイバ機器を追加することが挙げられます。最近の設計では、ノードごとの世帯数は 50~150 HHP にまで低下しています。ヘッドエンド(HE)で結局信号を合流させるのであれば、ノードごとのホームを減らしても効果はありません。ノードごと 500 世帯のオプティカルリンク 2 本を HE で合流させ、同一の CMTS US ポートを共有すると、ノードごと 1000 世帯の単一のオプティカルリンクにも劣る結果となることもあります。
多くの場合、アクティブ状態が多数集中しても、光リンクはノイズの制限に効果的です。高速化には、ノードごとの世帯数ばかり削減するのではなく、サービスによってセグメント分けすることが必要です。CMTS ポートやサービスごとの世帯数を減らすにはより多くのコストがかかりますが、ボトルネックを特異的に軽減できます。ノードごとの世帯数を削減すると、レーザーのクリッピングを引き起こすノイズや流合雑音も減り、後のセグメンテーションでもより少数の US ポートを扱うだけで済みます。
DOCSIS は DS、US に使用できる 2 つの変調方式と、5 つの帯域幅を定義しています。シンボル レートは 0.16、0.32、0.64、1.28、2.56 Msymbols/秒、変調方式は QPSK または 16-QAM などが使用できます。これにより、使用中のリターン システムで要求される堅牢性に合わせた必要なスループットを柔軟に選択できます。DOCSIS 2.0 にはさらなる柔軟性が加わりましたが、この説明は後述します。
また、周波数ホッピングが使え、「非コミュニケータ」を他の周波数へと移行させることができます。ここの妥協案としては、より多くの帯域幅冗長性を割り当てる必要があり、できれば、ホップが行われる前に「他の」周波数がクリーンな状態であることが望ましいところです。一部の製造者は、切り替え前に周波数帯が未使用か確認する機能をモデムに搭載しています。
技術が進歩するにつれて、より堅牢な、あるいは帯域幅の要求が緩い高度なプロトコルによって効率の高い圧縮方法や情報の送信方法が出現すると考えられます。DOCSIS 1.1 の QoS プロビジョニングやペイロード ヘッダー抑制(PHS)、または DOCSIS 2.0 の機能の併用が必要となるかもしれません。
堅牢性とスループットはトレードオフの関係にあります。通常、ネットワークの速度は使用する帯域幅、割り当てられたリソース、ノイズや干渉に対する堅牢性、そしてコストと関係しています。
チャネル幅と変調
前述の DOCSIS の遅延により、アップストリームのスループットは 3 Mbps に限定されると考えがちです。また、US 帯域幅を 3.2 MHz に増加したり、変調方式を 16-QAM に強化したりすると、理論的には 10.24 Mbps のスループットとなりますが、これは関係ないようにも見えます。チャネルの帯域幅拡大と変調方式の変更ではモデム単体の伝送レートを改善することはあまりできませんが、より多くのモデムがこのチャネルで送信できるようにはなります。US は TDMA ベースでタイムスロットに分割された競合メディアであり、タイムスロットは CMTS が許可する点に注意してください。チャネル帯域幅が広がることは、US に流すことのできる bps(毎秒のビット数)を引き上げることにほかなりません。よって、より多くのモデムをサポートできるようになります。そのため、US チャネルの帯域幅を広げることは重要です。また、US では、1518 バイトのパケットが回線を占有するのはわずかに 1.2 ミリ秒で、RTT 遅延には有効であることを思い起こしてください。
また、DS の変調を 256-QAM に変えると、DS の合計スループットを 40% 改善し、US のパフォーマンス向上のため、インターリーブによる遅延を削減できます。しかし、この変更を加えると、システム内のすべてのモデムが一時的に切断されるので注意してください。
 注意:DS 変調方式を変更する前には、十分に注意を払ってください。システムが 256-QAM 信号を扱えるかどうかは、DS の周波数特性を徹底的に分析して確認する必要があります。これを怠ると、ケーブルネットワークのパフォーマンスが著しく低下する場合があります。
注意:DS 変調方式を変更する前には、十分に注意を払ってください。システムが 256-QAM 信号を扱えるかどうかは、DS の周波数特性を徹底的に分析して確認する必要があります。これを怠ると、ケーブルネットワークのパフォーマンスが著しく低下する場合があります。
注意:ケーブルダウンレッド変調{64qam | 256qam}コマンドを発行して、DS変調を256-QAMに変更します。
VXR(config)# interface cable 3/0 VXR(config-if)# cable downstream modulation 256qam
US の変調方式のプロファイルとリターンパスの最適化の詳細については、「リターンパスの可用性とスループットの向上」を参照してください。また、「Cisco CMTS のケーブル変調プロファイルの設定」を参照してください。Interval Usage Codes(IUC)が短い、あるいは長い場合は、デフォルトの mix プロファイルで、uw8 を uw16 に変更します。
注意:チャネル幅を増加する、または US 変調方式を変更する前には、十分に注意を払ってください。16-QAM をサポートするのに適切な CNR 比を持つ十分広い周波数帯を特定するため、スペクトルアナライザを使用して US の周波数特性を詳細に分析する必要があります。これを怠ると、ケーブルネットワークのパフォーマンスが著しく低下するか、US の完全な停止を招くことがあります。
注意:US チャネル幅を増加するには、次のように、cable upstream channel-width コマンドを発行します。
VXR(config-if)# cable upstream 0 channel-width 3200000
「高度なスペクトラム管理」を参照してください。
インターリーブの効果
増幅器の電源や DS の経路にある機器の電源から混入する電気的なバーストノイズはブロックのエラーの原因となります。このノイズは、熱雑音によるエラーより重大で、スループット品質に影響する問題の原因となることがあります。バースト エラーの影響を最小限に抑えるには、時間軸上にデータを分散するインターリーブと呼ばれる技術を使用します。送信側のシンボルは相互に混合され、受信側で再度組み立てられます。エラーはばらばらに分散されます。FEC は、分散されたエラーに対して大変効果的です。インターリーブを使用すると、比較的長いバーストの干渉を受けたエラーは FEC により修正できます。ほとんどのエラーはバーストノイズで起こるため、効果的にエラー率を改善できます。
注:FECインターリーブ値を増やすと、ネットワークに遅延が追加されます。
DOCSIS ではインターリーブについて 5 つの異なるレベルを指定できます(EuroDOCSIS には単一のレベルしかありません)。128:1 が最大、8:16 が最小のインターリーブです。128:1 では、128 のシンボルからなる 128 のコードワードを 1 対 1 で混合します。8:16 では 16 のシンボルをコードワードごとに 1 列に並べ、7 つの他のコードワードからの 16 のシンボルと混合されます。
ダウンストリームのインターリーブ遅延を以下の表にマイクロ秒(μs または usecs)で示しています。
| I (タップの数) | J (増分) | 64-QAM | 256-QAM |
|---|---|---|---|
| 8 | 16 | 220 | 150 |
| 16 | 8 | 480 | 330 |
| 32 | 4 | 980 | 680 |
| 64 | 0 | 2000 | 1400 |
| 128 | 1 | 4000 | 2800 |
インターリーブは、FEC のようなオーバーヘッドビットを挿入しません。しかし、遅延が発生し、音声やリアルタイムのビデオに影響することがあります。要求と許可の RTT も増加し、MAP による通信機会が 3 つ目、4 つ目の MAP メッセージにまで遅れることがあります。これは副次的な影響で、US のピーク時のデータスループットを低下させることがあります。インターリーブの値をデフォルトの 32 より少ない値に設定することで、US のスループット(モデム単体の PPS)をわずかに向上できます。
インパルスノイズ問題の回避策として、インターリーブ値を64または128に増やすことができます。ただし、この値を増やすとパフォーマンス(スループット)が低下する可能性がありますが、DSではノイズの安定性が増します。言い換えれば、設備を適切にメンテナンスしなければ、DS での修正不可能なエラー(パケット喪失)が発生し、モデムが次第に接続できなくなり、パケット再送が増えます。
ノイズが多い DS パスを補正するためにインターリーブ深度を上げると、ピークの CM US スループットの低下を招きます。多くの場合、家庭向けの使用で問題となることはありませんが、トレードオフの関係を理解しておくことは良いことです。4 ミリ秒で最大のインターリーブ深度である 128:1 を選択すると、US のスループットには悪影響が及びます。
注:遅延は、64-QAMと256-QAMでは異なります。
cable downstream interleave-depth {8 | 16 | 32 | 64 | 128}コマンド。これはインターリーブ深度を 8 に減らす例です。
VXR(config-if)# cable downstream interleave-depth 8
注意:このコマンドが実装されると、システム上のすべてのモデムの接続が解除されます。
アップストリームのノイズ耐性を確保するため、DOCSIS モデムでは FEC を調整でき、FEC を使用しないようにもできます。US の FEC をオフにすると、いくらかのオーバーヘッドを回避でき、より多くのパケットを伝送できますが、ノイズに対する堅牢性は損なわれます。バーストの種類に応じて異なる強度の FEC を用意しておくことも有効です。たとえば、本番データに対するバーストとステーションのメンテナンス時のバーストを区別します。また、64 バイトからなるデータ パケットと、1518 バイトからなるデータ パケットも区別する意味があるでしょう。より大きなパケットには、保護を強化することが必要になる場合があります。いろいろと手を打っても、得るものが少ない場合もあります。たとえば、FEC を 7 から 14% に強化しても、堅牢性は 0.5 dB しか改善しません。
現在、US にはインターリービングがありません。これは、送信がバースト性であり、バースト内にインターリービングをサポートする十分な遅延がないためです。一部のチップ製造者は、DOCSIS 2.0 をサポートするため、チップにこの機能を搭載しています。家庭内の電気製品が発生する多くのインパルス ノイズを考えると、この機能は絶大な効果をもたらす可能性があります。US のインターリーブは、FEC の効果的な動作にも貢献します。
Dynamic MAP Advance
Dynamic MAP Advance では MAP におけるダイナミックな先読みの仕組みにより、モデム単体のアップストリーム スループットに相当な改善をもたらします。Dynamic MAP Advance は MAP の先読み時間を自動的に微調整するアルゴリズムです。微調整の対象となるアップストリーム ポートに割り当てられている最も遠い CM に基づいて微調整を行います。
MAP アドバンスについての詳細は「ケーブル マップ アドバンス(ダイナミックまたはスタティック)」を参照してください。
MAP アドバンスがダイナミックに設定されているか確認するには、show controllers cable slot/port upstream port コマンドを発行します。
Ninetail# show controllers cable 3/0 upstream 1 Cable3/0 Upstream 1 is up Frequency 25.008 MHz, Channel Width 1.600 MHz, QPSK Symbol Rate 1.280 Msps Spectrum Group is overridden BroadCom SNR_estimate for good packets - 28.6280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2809 Ranging Backoff automatic (Start 0, End 3) Ranging Insertion Interval automatic (60 ms) Tx Backoff Start 0, Tx Backoff End 4 Modulation Profile Group 1 Concatenation is enabled Fragmentation is enabled part_id=0x3137, rev_id=0x03, rev2_id=0xFF nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 8 Minislot Size in Symbols = 64 Bandwidth Requests = 0xE224 Piggyback Requests = 0x2A65 Invalid BW Requests= 0x6D Minislots Requested= 0x15735B Minislots Granted = 0x15735F Minislot Size in Bytes = 16 Map Advance (Dynamic) : 2454 usecs UCD Count = 568189 DES Ctrl Reg#0 = C000C043, Reg#1 = 17
前述のように、インターリーブ深度を 8 に設定すると、DS 遅延が少なくなり、MAP アドバンスをさらに抑えることができます。
連結とフラグメンテーションの効果
DOCSIS 1.1 機器と、現在の 1.0 機器は、連結と呼ばれる新機能をサポートしています。フラグメンテーションはDOCSIS 1.1でもサポートされています。連結により、複数の小さなDOCSISフレームを1つの大きなDOCSISフレームに結合し、1つの要求とともに送信できます。
US 伝送の時間間隔では、最大で 255 のミニスロットが要求でき、ミニスロットは通常 8 または 16 バイトあるので、アップストリームの伝送間隔に一度に伝送できるのは、2040 または 4080 バイトです。この数量には、FEC と物理層のすべてのオーバーヘッドが含まれます。そのため、許可応答のフラグメント化とは関係なく、イーサネット フレームでの最大バースト転送量はその 90% ほどになります。2 ティックのミニスロットで、3.2 MHz で 16-QAM を使用する場合、ミニスロットは 16 バイトになります。この場合、16 X 255 = 4080 バイト - 10% 物理層オーバーヘッド = 約 3672 バイトの制約が発生します。さらに連結を行うには、ミニスロットを 4 または 8 ティックに変更し、最大連結を 8160 または 16,320 に設定します。
注意すべき点があります。伝送される最小のバーストは 32 または 64 バイトであり、この精度の粗さによって、パケットがミニスロットに分断されるときにさらに丸めエラーが生じやすくなっています。
フラグメンテーションを使用しない限り、US の最大のバースト転送は、VXR シャーシ内の MC28C または MC16x カードの場合では 4000 バイト以下に設定すべきです。また、DOCSIS 1.0 モデムで VoIP を使用する場合は、最大バーストを 2000 バイト以下に設定します。1.0 のモデムはフラグメンテーションを使用できず、UGS フローが適切に伝送されるには 2000 バイトは長すぎるので、音声にジッターを生じるためです。
連結は、大きなパケットに対してはそれほど有用ではないものの、TCP の短い確認応答を処理するにはうってつけのツールといえます。送信の機会ごとの複数パケット伝送を許可した場合、連結により基本的な PPS 値がその倍数で増加されます。
連結した大きなパケットでは、シリアル化の時間がかかり、RTT と PPS に影響します。たとえば、1518 バイトのパケットで 250 PPS を達成していても、連結することによる速度低下は避けられません。しかし、結果的に連結されたパケットの合計バイト数はより多くなっています。4 つの 1518 バイト パケットを連結できた場合、これを 3.2 MHz で 16-QAM を使用して伝送するには少なくとも 3.9 ミリ秒はかかります。DS のインターリーブと処理に伴う遅延を加算する必要があります。また DS MAP は 8 ミリ秒ごとにしか発生しません。PPS は 114 に低下しますが、もともと 4 つのパケットを連結しているので、これは見かけ上 456 PPS に相当する速度です。よって、456 X 8 X 1518 = 5.5 Mbps のスループットとなります。「ゲーム」をプレイする例を考えます。連結により、アップストリームの多くの確認応答を 1 つの要求にまとめて送信でき、DS の TCP フローがより高速になります。CM の DOCSIS コンフィギュレーション ファイルでは最大 US バーストが 2000 バイトで設定されていることと、モデムが連結に対応していることを仮定します。CM は理論上 31 の ACK を連結できます(各 ACK は 64 バイト)。この大きなパケットは CM から CMTS へ伝送されるまである程度の時間がかかるため、PPS はそれなりに低下します。小さなパケットでは 234 PPS だったものが、大きなパケットでは 92 PPS 近くまで低下します。可能性としては、92 PPS × 31 acks = 2852 PPS 出るはずです。これは、512 バイトの DS パケット X 8 ビット/バイト X 2 パケット/ACK X 2852 ACK/秒 = 23.3 Mbps に相当します。しかし、ほとんどの CM で、転送レートは何らかの制限により、この数値より相当低くなっています。
アップストリームでは、理論的に CM のスループットは 512 バイト × 8 ビット/バイト × 110 PPS × 3 パケット連結 = 1.35 Mbps 出るはずです。これらの数値は、連結なしの場合より相当に優れたものといえます。ミニスロットによる丸めは、フラグメンテーションで悪化します。これは、フラグメンテーション自体でまた丸めが発生するためです。
注:古いBroadcomの問題があり、2つのパケットを連結することはできませんが、3つのパケットを連結することはできます。
連結を活用するには、Cisco IOS ソフトウェア リリース 12.1(1)T または 12.1(1)EC 以降を実行する必要があります。可能であれば、Broadcom 3300 をベースに設計されたモデムを使用してください。CM が連結をサポートしていることを確認するため、CMTS で show cable modem detail、show cable modem mac または show cable modem verbose コマンドを発行してください。
VXR# show cable modem detail Interface SID MAC address Max CPE Concatenation Rx SNR Cable6/1/U0 2 0002.fdfa.0a63 1 yes 33.26
連結をオンまたはオフにするには、[no] cable upstream n concatenation コマンドを発行します。n は US のポート番号を指定します。有効な値は 0 から開始します。ケーブル インターフェイス ライン カードの最初のアップストリーム ポートが 0 番です。
注:DOCSIS 1.0対1.1と、最大バーストサイズの設定に関する連結の問題についての詳細は、『最大アップストリームバーストパラメータの履歴』を参照してください。変更を有効にするため、モデムを再起動する必要がある点に注意してください。
単一モデム速度
より大きなフレームを連結し、モデム単体の速度を追求するなら、ミニスロットを 32 バイトに変更し、最大バーストを 8160 まで許可することができます。この変更の落とし穴は、送信される最小パケットが 32 バイトになるということです。これは、要求(長さ 16 バイト)など、小さなパケットが多いアップストリームでは効率的とはいえません。要求は競合が起こり得る領域にあるため、大きくなると衝突の可能性が高くなります。大きなパケットをミニスロットに分断することより、ミニスロットの丸めエラーは増加します。
このモデムの DOCSIS コンフィギュレーション ファイルで [Max Traffic Burst] と [Max Concat Burst] を約 6100 に設定する必要があります。これで、1518 バイトのフレームを 4 つ連結できます。モデムは、処理しやすいようにパケットを解体できるよう、フラグメンテーションをサポートしている必要があります。次の要求は通常ピギーバックされて最初のフラグメント内にあるため、モデムは期待値よりもさらに優れた PPS を達成できます。CM が長い連結パケットの送信を試みる場合に比べ、フラグメントの連結は早く済みます。
モデム単体の速度に影響するいくつかの設定について説明する必要があります。最大トラフィック バーストは 1.0 の CM では 1522 に設定しなければなりません。一部のケーブルモデムでは、この設定を 1600 以上とする必要があります。これは、想定外のオーバーヘッドに対応するための設定です。最大連結バーストはフラグメント化にも対応した 1.1 のモデムに影響します。これにより、単一リクエストの下にある多くのフレームを連結でき、かつ VoIP の考慮事項のために 2000 バイト パケットへのフラグメンテーションもできるようにします。最大トラフィック バーストと最大連結バーストを同じに設定しなければならない場合があります。このようにしないと、一部の CM はオンラインになりません。
CMTS のコマンドで有効なものとして cable upstream n rate-limit token-bucket shaping コマンドがあります。このコマンドは、コンフィギュレーション ファイルの設定どおりにポリシングを行わないケーブルモデムに対して、ポリシングを行うのに役立ちます。ポリシングによりパケットが遅延することがあるため、スループットに影響していることが疑われるときには、ポリシングを無効にします。これは最大トラフィック バーストと最大連結バーストを同じに設定しなければならないことと関係があるかもしれませんが、その検証にはさらなるテストが必要です。
東芝の製品では CM で Broadcom のチップセットを使用していないため、連結またはフラグメンテーションなしでも優秀に機能します。Libitを使用し、PCX2200よりも高いCMでTIを使用するようになりました。また、Toshibaは、より高いPPSを実現するために、認可の前で次の要求を送信します。これは、要求がピギーバックされず、また要求がコンテンションスロットに入ってしまうということを除いては、うまく機能します。同一のアップストリームにたくさんのケーブルモデムがあると、要求がドロップしてしまうこともあるでしょう。
cable default-phy-burst コマンドにより、ケーブルモデムの登録エラーを引き起こすことなく CMTS の DOCSIS 1.0 IOS ソフトウェアから 1.1 コードへアップグレードが可能となります。DOCSIS コンフィギュレーション ファイルでは、通常最大トラフィック バーストは 0 または空白になっています。これは、モデムの登録が失敗する原因となります。0 は最大バーストを無限大にすることを意味し、1.1 コードでは認められない設定で、拒否される CoS になります(VoIP サービス、最大遅延、レイテンシ、ジッターなどとの兼ね合いから)。 cable default-phy-burst コマンドは DOCSIS コンフィギュレーション ファイルの 0 設定を上書きし、2 つの数字のうち低い方が優先されます。デフォルト設定は 2000 で、最大 8000 まで設定できるようになりました。8000 に設定することで、1518 バイト フレームを 5 つ連結できます。0 を設定することで、オフにできます。
cable default-phy-burst 0
モデム単体の速度テストに関する推奨事項
-
アップストリームでは Advanced Time-Division Multiple Access(A-TDMA)を 6.4 MHz チャネルで 64-QAM で使用します。
-
ミニスロットサイズを2に設定します。DOCSISの制限はバースト当たり255ミニスロットなので、255 × 48バイト/ミニスロット= 12240最大バースト× 90% = ~11,000バイトになります。
-
フラグメンテーション、連結に対応しており、全二重方式で FastEthernet 接続を持つ CM を使用します。
-
DOCSIS コンフィギュレーション ファイルで、最小値なしで、上りと下りで最大値 20 MB を設定します。
-
アップストリームの rate-limit token-bucket shaping をオフにします。
-
cable upstream n data-backoff 3 5 コマンドを発行します。
-
最大トラフィック バーストと最大連結バーストを 11000 バイトに設定します。
-
DS では、256-QAM、16 インターリーブを使用します(8 も試してください)。 これで、MAP の遅延が減ります。
-
cable map-advance dynamic 300 1000 コマンドを発行します。
-
フラグメント化が正しいIOSソフトウェアリリース15(BC2)イメージを使用し、cable upstream n fragment-force 2000 5コマンドを発行します。
-
ケーブルモデムに UDP トラフィックを通し、最大のスループットを見つけるまで増量します。
-
TCP トラフィックを通す場合は、単一のケーブルモデムに複数の PC を使用します。
成果
-
Terayon TJ735 では 15.7 Mbps が得られました。おそらく連結されたフレームのバイト数が少ないことと、優秀な CPU による結果、良好な速度が得られたと考えられます。最初のフレームに 13 バイトの連結ヘッダー、以降に 6 バイトのヘッダーがあり、フラグメントヘッダーは 16 バイト、内部の最大バーストは 8200 バイトと想定されます。
-
Motorola SB5100 では 18 Mbps が得られました。また、ダウンストリームで 1418 バイトのパケットと 8 インターリーブを使用して 19.7 Mbps が得られました。
-
東芝 PCX2500 では 8 Mbps が得られました。内部で最大バーストに 4000 バイトの制限があるようです。
-
Ambit は Motorola と同様の結果でした。18 Mbps です。
-
これらの伝送レートの一部は、他の CM のトラフィックとのコンテンションにより低下することがあります。
-
(フラグメンテーション未対応の)1.0 ケーブルモデムでは、最大バーストが 2000 以下になるようにします。
-
Motorola と Ambit のケーブルモデムでは、アップストリーム使用率 98% で 27.2 Mbps が得られました。
新しい Fragment コマンド
cable upstream n fragment-force fragment-threshold number-of-fragments
| パラメータ | 説明 |
|---|---|
| n | アップストリーム ポート番号を指定します。有効な値は 0 から開始します。ケーブル インターフェイス ライン カードの最初のアップストリーム ポートが 0 番です。 |
| fragment-threshold | フラグメンテーションがトリガーされるバイト数。有効範囲は 0 ~ 4000、デフォルトは 2000 バイトです。 |
| number-of-fragments | フラグメント化された各フレームが分けられる、同じサイズのフラグメントの数。有効範囲は 1 ~ 10、デフォルトのフラグメント数は 3 つです。 |
DOCSIS 2.0 のメリット
DOCSIS 2.0 では DS の変更はありませんが、US には多くの変更があります。DOCSIS 2.0 の高度な物理層の仕様には、以下が追加されています。
-
8-QAM、32-QAM、および 64-QAM 変調方式
-
6.4 MHz チャネル幅
-
FEC の T-byte を 16 まで対応
また、モデムと US インターリービングで、プレイコライゼーションの 24 のタップが許可されます。これにより、反射、チャネル内部の傾き、グループ遅延および US のバースト性ノイズに対しする堅牢性が追加されます。CMTS の 24 タップの均等化は古い DOCSIS 1.0 モデムの動作にも有効です。DOCSIS 2.0 では、A-TDMA に加えて S-CDMA も使用できます。
64-QAM の優れた帯域効率は、チャネルの有効利用と容量増加に貢献します。これにより、アップストリームでは優れたスループットが得られ、PPS の向上によりモデム単体のスピードもわずかながら改善しています。6.4 MHz で 64-QAM 変調を行うことにより、大きなパケットを CMTS により速く伝送できます。シリアル化の時間は短縮され、PPS の向上につながっています。より広帯域なチャネルにより、統計多重化が改善しています。
A-TDMA によるアップストリームにおける理論上のピーク伝送レートは約 27 Mbps です(総スループット)。 これはオーバーヘッド、パケット サイズなどによって異なります。総スループットの向上によりスループットの共有を広げることができますが、モデム単体の速度向上につながるものではありません。
アップストリームで A-TDMA を使用することで、より高速なパケット伝送が可能となります。アップストリームで 6.4 MHz、64-QAM を使用すると、連結されたパケットを高速でシリアル化でき、PPS の向上につながります。A-TDMA で 2 ティックのミニスロットを使用すると、各ミニスロットに 48 バイトを格納でき、要求ごとに最大で 48 X 255 = 12240 バイトのバースト伝送が可能です。64-QAM、6.4 MHz、2 ティックのミニスロット、最大 10,000 の連結バースト、300 のダイナミック MAP アドバンスで、約 15 Mbps のスループットが得られます。
現在のすべてのDOCSIS 2.0シリコン実装では入力取り消しが採用されていますが、これはDOCSIS 2.0の一部ではありません。これにより、最悪のケースのプラント障害に対するサービスが堅牢になり、スペクトルの未使用部分が開かれ、ライフラインサービスの保険が追加されます。
他の要因
ケーブル ネットワークのパフォーマンスに直接影響する要因は他にも存在しています。QoS プロファイル、ノイズ、伝送レート制限、ノードの結合、過剰使用などです。これらのほとんどについて、「低速のケーブル モデム ネットワークのトラブルシューティング」で詳細に説明しています。
また、ケーブルモデムの制限には、表からはわからない潜在的なものもあります。ケーブル モデムの CPU に限界がある場合や、PC へのイーサネット接続が半二重であることもあります。パケット サイズや双方向のトラフィック フローによって、これらが目に見えないボトルネックとなることがあります。
スループットの確認
モデムが接続されているインターフェイスに対して、show cable modem コマンドを発行します。
ubr7246-2# show cable modem cable 6/0
MAC Address IP Address I/F MAC Prim RxPwr Timing Num BPI
State Sid (db) Offset CPE Enb
00e0.6f1e.3246 10.200.100.132 C6/0/U0 online 8 -0.50 267 0 N
0002.8a8c.6462 10.200.100.96 C6/0/U0 online 9 0.00 2064 0 N
000b.06a0.7116 10.200.100.158 C6/0/U0 online 10 0.00 2065 0 N
モデムの機能を調べるには、show cable modem mac コマンドを発行します。ここで表示されるのは、モデムの能力(できること)であり、現在実行している機能ではありません。
ubr7246-2# show cable modem mac | inc 7116
MAC Address MAC Prim Ver QoS Frag Concat PHS Priv DS US
State Sid Prov Saids Sids
000b.06a0.7116 online 10 DOC2.0 DOC1.1 yes yes yes BPI+ 0 4
モデムの物理層のアトリビュートを確認するには、show cable modem phy コマンドを発行します。この情報の一部は、CMTS に remote-query が設定されている場合のみ表示されます。
ubr7246-2# show cable modem phy
MAC Address I/F Sid USPwr USSNR Timing MicroReflec DSPwr DSSNR Mode
(dBmV)(dBmV) Offset (dBc) (dBmV)(dBmV)
000b.06a0.7116 C6/0/U0 10 49.07 36.12 2065 46 0.08 41.01 atdma
現在のモデムのアップストリーム設定を確認するには、show controllers cable slot/port upstream port コマンドを発行します。
ubr7246-2# show controllers cable 6/0 upstream 0 Cable6/0 Upstream 0 is up Frequency 33.000 MHz, Channel Width 6.400 MHz, 64-QAM Sym Rate 5.120 Msps This upstream is mapped to physical port 0 Spectrum Group is overridden US phy SNR_estimate for good packets - 36.1280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2066 Ranging Backoff Start 2, Ranging Backoff End 6 Ranging Insertion Interval automatic (312 ms) Tx Backoff Start 3, Tx Backoff End 5 Modulation Profile Group 243 Concatenation is enabled Fragmentation is enabled part_id=0x3138, rev_id=0x02, rev2_id=0x00 nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 2 Minislot Size in Symbols = 64 Bandwidth Requests = 0x7D52A Piggyback Requests = 0x11B568AF Invalid BW Requests= 0xB5D Minislots Requested= 0xAD46CE03 Minislots Granted = 0x30DE2BAA Minislot Size in Bytes = 48 Map Advance (Dynamic) : 1031 usecs UCD Count = 729621 ATDMA mode enabled
モデムのサービスフローを確認するには、show interface cable slot/port service-flow コマンドを発行します。
ubr7246-2# show interface cable 6/0 service-flow
Sfid Sid Mac Address QoS Param Index Type Dir Curr Active
Prov Adm Act State Time
18 N/A 00e0.6f1e.3246 4 4 4 prim DS act 12d20h
17 8 00e0.6f1e.3246 3 3 3 prim US act 12d20h
20 N/A 0002.8a8c.6462 4 4 4 prim DS act 12d20h
19 9 0002.8a8c.6462 3 3 3 prim US act 12d20h
22 N/A 000b.06a0.7116 4 4 4 prim DS act 12d20h
21 10 000b.06a0.7116 3 3 3 prim US act 12d20h
特定のモデムの特定のサービスフローを確認するには、show interface cable slot/port service-flow sfid verbose コマンドを発行します。US または DS の現在のスループットとモデムの設定ファイルを表示します。
ubr7246-2# show interface cable 6/0 service-flow 21 verbose Sfid : 21 Mac Address : 000b.06a0.7116 Type : Primary Direction : Upstream Current State : Active Current QoS Indexes [Prov, Adm, Act] : [3, 3, 3] Active Time : 12d20h Sid : 10 Traffic Priority : 0 Maximum Sustained rate : 21000000 bits/sec Maximum Burst : 11000 bytes Minimum Reserved Rate : 0 bits/sec Admitted QoS Timeout : 200 seconds Active QoS Timeout : 0 seconds Packets : 1212466072 Bytes : 1262539004 Rate Limit Delayed Grants : 0 Rate Limit Dropped Grants : 0 Current Throughput : 12296000 bits/sec, 1084 packets/sec Classifiers : NONE
遅延したパケットや破棄されたパケットがないことを確認します。
修正不能な FEC エラーを確認するには、show cable hop コマンドを発行します。
ubr7246-2# show cable hop cable 6/0
Upstream Port Poll Missed Min Missed Hop Hop Corr Uncorr
Port Status Rate Poll Poll Poll Thres Period FEC FEC
(ms) Count Sample Pcnt Pcnt (sec) Errors Errors
Cable6/0/U0 33.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U1 admindown 1000 * * * frequency not set * * * 0 0
Cable6/0/U2 10.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U3 admindown 1000 * * * frequency not set * * * 0 0
モデムがパケットをドロップしている場合は、物理プラントがスループットに影響を与えており、修正が必要です。
要約
このドキュメントのここまでのセクションでは、背景にある要件を理解せず、他の機能への影響を考えずにパフォーマンスの指標を操作することの弊害を強調してきました。特定のパフォーマンス指標を向上させるため、またはネットワークの問題を解決するためにシステムの微調整をしても、必ず他の何らかの機能が犠牲になります。毎秒の MAP 数とインターリーブ深度を変更してアップストリームの性能を向上できても、DS の伝送レートや堅牢性が犠牲になります。MAP の間隔を狭くすることは、現実のネットワークには大したメリットをもたらしません。一方で、CPU の負担は増加し、CMTS、CM 両方の帯域幅のオーバーヘッドが増加します。アップストリームの FEC を強化すると、アップストリームのオーバーヘッドが増加します。スループット、複雑さ、堅牢性とコストの間にはトレードオフの関係が常に存在しています。
アップストリームでアドミッション コントロールを使用すると、スループットの割り当てが使い果されたときにモデムが登録できなくなります。たとえば、US で 2.56 Mbps が使用可能で、最低保証帯域が 128k なら、アドミッション コントロールを 100% にすると登録できるモデムは 20 台だけになってしまいます。
結論
サブスクライバへ提供できるデータ速度とパフォーマンスを求めるには、設備から期待できるスループットを把握する必要があります。理論上可能な限界をまず求めることで、ダイナミックに変化するケーブルシステムの要件に合致するネットワークを設計し、運用することができます。それから、実際のトラフィック負荷をモニタし、どれほどの伝送が行われているかを把握し、ボトルネックを軽減するための容量追加をいつ行うか決定します。
ネットワークが適切に展開され、運用されていれば、サービスと可用性に関する認識がケーブル業界の差別化への鍵となり得ます。ケーブル会社は複合サービスへと移行するにつれて、サブスクライバが期待するサービスの健全性、可用性は、従来の音声サービスが確立したモデルに近づいています。このような変化に応じて、ケーブル会社はネットワークの姿をこの新しいパラダイムに沿ったものにする、新しいアプローチと戦略を採用する必要に迫られています。単なるエンターテイメント提供者ではなく、通信事業者としての厳しい要求と期待に応えなくてはなりません。
DOCSIS 1.1 は VoIP など高度なサービスに必要な水準の品質を確保できる仕様となっています。一方で、この仕様に準拠したサービスを展開するにはさまざまな困難が伴います。このような理由で、ケーブル事業者が問題を完全に理解することは不可欠です。本当に信頼できる優秀なシステムを提供するには、システムのコンポーネントとネットワーク戦略を選択する包括的なアプローチを考案する必要があります。
既存のサブスクライバのサービスを妨げずに、さらに多くのサブスクライバを加入させることを目標としています。サブスクライバあたりの最低スループットを保証するサービス レベル契約(SLA)を提供する場合は、この保証をサポートできるインフラストラクチャが必要です。業界は、法人顧客の開拓と、ボイスサービスの追加に向かって進んでいます。新市場が開拓され、新たなネットワークが構築されるに伴い、新しいアプローチが必要となります。たとえば、ポート数のより多い高密度 CMTS、遠距離での分散された CMTS、またはその中間にあるソリューション(家庭用の 10base-F の導入)などが考えられます。
将来どのようなことがあっても、ネットワークはより複雑になり、技術的課題は必ず増加します。ケーブルの業界は、高度なサービス信頼性、可用性、整合性をタイムリーに提供できるアーキテクチャや計画を採用してのみ、これからの課題に対応できるでしょう。
 フィードバック
フィードバック