APIおよびPythonを使用したカスタムレポートへのメタデータの利用
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
概要
このドキュメントでは、Pythonスクリプト内でカスタムレポートを作成するために、APIとメタデータを併用する方法について説明します。
前提条件
要件
次の項目に関する知識があることが推奨されます。
- CloudCenter
- Python
使用するコンポーネント
このドキュメントの内容は、特定のソフトウェアやハードウェアのバージョンに限定されるものではありません。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、初期(デフォルト)設定の状態から起動しています。対象のネットワークが実稼働中である場合には、どのようなコマンドについても、その潜在的な影響について確実に理解しておく必要があります。
背景説明
CloudCenterでは、すぐにレポートを作成できますが、カスタムフィルタに基づくレポートを作成することはできません。APIを使用してデータベースから情報を直接取得するには、ジョブに添付されたメタデータと共に、カスタムレポートを許可できます。
メタデータの設定
メタデータはアプリケーションレベルごとに追加する必要があるため、カスタムレポートを使用して追跡する必要があるすべてのアプリケーションを変更する必要があります。
これを行うには、[Application Profiles]に移動して、編集するアプリケーションのドロップダウンを選択し、次に図に示すように[Edit/Update]を選択します。
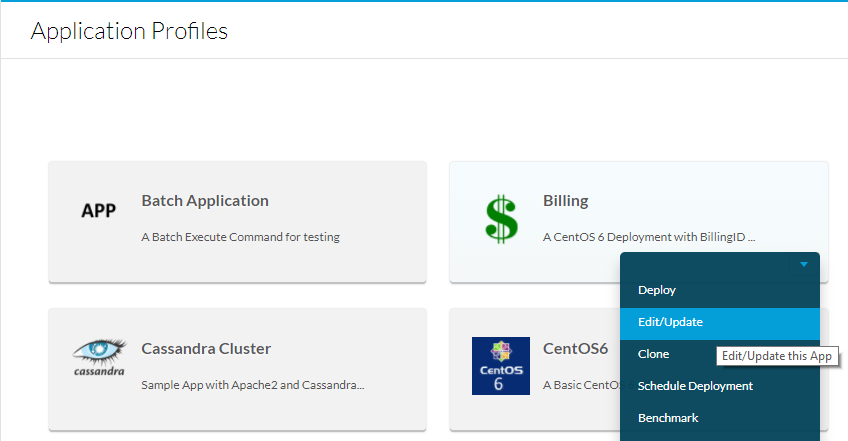
基本情報の下部までスクロールして、メタデータ・タグ(BillingIDなど)を追加します。このメタデータをユーザーが入力する場合は、必須と編集可能の両方にします。単なるマクロの場合は、既定値を入力し、編集できないようにします。メタデータを入力したら、図に示すように、[追加]、[アプリを保存]の順に選択します。
APIキーの収集
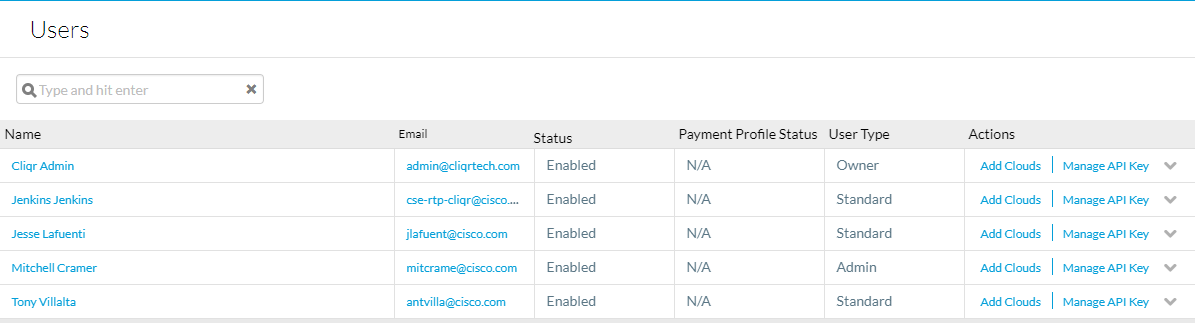
APIコールを処理するには、ユーザ名とAPIキーが必要です。これらのキーはユーザと同じレベルのアクセスを提供するため、すべてのユーザの展開をレポートに追加する場合は、テナントAPIキーの管理者を取得することをお勧めします。複数のサブテナントを一緒に記録する場合、ルートテナントがすべての導入環境にアクセスする必要があるか、すべてのサブテナント管理者のAPIキーが必要です。
APIキーを取得するには、[Admin] > [Users] > [Manage API Key]に移動し、必要なユーザのユーザ名とキーをコピーします。
カスタムレポートの作成
レポートを作成するPythonスクリプトを作成する前に、Pythonとpipがインストールされていることを確認します。次に、pip install tabulateを実行します。tabulateは、レポートのフォーマットを自動的に処理するライブラリです。
このガイドには2つのサンプルレポートが添付されています。最初に、すべての導入に関する情報を収集し、テーブルに出力します。2つ目は、同じ情報を使用して、BillingIDメタデータを使用してカスタムレポートを作成します。このスクリプトは、ガイドとして使用するために詳細に説明されています。
import datetime import json import sys import requests ##pip install tabulate from tabulate import tabulate from operator import itemgetter from decimal import Decimal
datetimeは、日付を正確に計算するために使用されます。これは、最新のX日のレポートを作成するために実行されます。
jsonは、api呼び出しの出力であるjsonデータの解析に使用されます。
sysはシステムコールに使用されます。
requestsは、API呼び出しに対するweb要求の作成を簡素化するために使用されます。
tabulateは、テーブルのフォーマットを自動的に行うために使用されます。
itemgetterは、2Dテーブルをソートするイテレータとして使用されます。
10進数は、コストを小数点以下2桁に丸めるために使用されます。
if(len(sys.argv)==1):
days = -1
elif(len(sys.argv)==2):
try:
days = int(sys.argv[1])
if(days < 1):
raise ValueError('Less than 1')
start=datetime.datetime.now()+datetime.timedelta(days*-1)
except ValueError:
print("Number of days must be an integer greater than 0")
exit()
else:
print("Enter number of days to report on, or leave blank to report all time")
exit()
この部分は、日数のコマンドラインパラメータを解析するために使用されます。
コマンドラインパラメータ(sys.argv ==1)がない場合、レポートは常に実行されます。
1つのコマンドラインパラメータがある場合は、1以上の整数かどうかをチェックします。その日数でレポートされている場合は、エラーが返されます。
複数のパラメータがある場合は、エラーが返されます。
departments = [] users = ['user1','user2','user3'] passwords = ['user1Key','user2Key','user3Key']
departmentsは、最終的な出力を保持するリストです。
usersは、APIコールを発信するすべてのユーザのリストです。複数のサブテナントがある場合、各ユーザが異なるサブテナントの管理者になります。
passwordsは、ユーザAPIキーのリストです。正しいキーを使用するには、ユーザとキーの順序が同じである必要があります。
for j in xrange(0,len(users)):
jobs = []
r = requests.get('https://ccm2.cisco.com/v1/jobs', auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data = r.json()
for i in xrange(0,len(data["jobs"])):
test = datetime.datetime.strptime((data["jobs"][i]["startTime"]), '%Y-%m-%d %H:%M:%S.%f')
if(days != -1):
if(start < test):
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
else:
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
for id in jobs:
q = requests.get('https://ccm2.cisco.com/v1/jobs/'+id[0], auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data2 = q.json()
id[2]=round(id[2],2)
for i in xrange(0,len(data2["metadatas"])):
if('BillingID' == data2["metadatas"][i]["name"]):
id[1]=data2["metadatas"][i]["value"]
added=0
for i in xrange(0,len(departments)):
if(departments[i][0]==id[1]):
departments[i][1]+= 1
departments[i][2]+=id[2]
added=1
if(added==0):
departments.append([id[1],1,id[2]])
xrange(0,len(users))のj:前のコードチャンクで定義されたすべてのユーザーをループ処理するfor loopは、すべてのAPI呼び出しを処理するメインループです。
jobsは、ジョブの情報を保持するために使用される一時リストで、リストに照合されます。
r = requests.get....は最初のAPI呼び出しです。この呼び出しはすべてのジョブをリストします。詳細については、「ジョブのリスト」を参照してください。
結果はjson形式でデータに保存されます。
for i in xrange(0,len(data["jobs"])):前のAPI呼び出しから返されたすべてのジョブを反復処理します。
各ジョブの時間がjsonから取得され、datetimeオブジェクトに変換されます。その後、入力したコマンドラインパラメータと比較して、それが境界内にあるかどうかを確認します。
ジョブが存在する場合、ジョブのリストに追加されるjsonからの情報id、totalCost、status、name、start timeです。この情報のすべてが使用されているわけではなく、返すことができるすべての情報が使用されているわけでもありません。リストジョブは、同じ方法で追加できる戻り済みのすべての情報を示します。
そのユーザーから返されたすべてのジョブを繰り返し実行した後、ジョブのIDに移動します。開始日を確認した後に取得されたすべてのジョブを繰り返し実行します。
q = requests.get(..... 2番目のAPI呼び出しです。最初のAPI呼び出しから取得したジョブIDに関連するすべての情報がリストされます。 詳細については、「ジョブの詳細を取得する」を参照してください。
jsonファイルはdata2に保存されます。
id[2]に格納されているコストは、小数点以下2桁に丸められます。
for i in xrange(0,len(data2["metadatas"]):ジョブに関連付けられたすべてのメタデータを反復処理します。
BillingIDという名前のメタデータがある場合は、ジョブ情報に保存されます。
addedは、BillingIDが部署リストにすでに追加されているかどうかを判断するために使用するフラグです。
xrange(0,len(departments))のiの場合:追加されたすべての部門を反復処理します。
このジョブが既に存在する部署の一部である場合、ジョブ数が1ずつ繰り返され、その部署の総コストにコストが加算されます。
そうでない場合は、ジョブ数が1で、コストの合計がこの1つのジョブのコストに等しい部門に新しい行が追加されます。
departments = sorted(departments, key=itemgetter(1)) print(tabulate(departments,headers=['Department','Number of Jobs','Total Cost']))
departments = sorted(departments, key=itemgetter(1))は、部署をジョブの数でソートします。
print(tabulate(departments,headers=['Department','Number of Jobs', 'Total Cost']))は、3つのヘッダーを持つtabulateによって作成されたテーブルを印刷します。
関連情報
シスコ エンジニア提供
- Jesse LafuentiCisco TAC Engineer
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)