概要
このドキュメントでは、Cisco Hyperflexクラスタのオフラインノードを再導入するプロセスについて説明します。
前提条件
要件
これは、Intersightから導入され、バージョン5.0(2b)以降のHyperflexクラスタでのみサポートされます。Hyperflexインストーラを介して導入され、Intersightにインポートされるクラスタは、この機能ではまだサポートされていません。
このIntersight機能でサポートされるシナリオのタイプ:
- FI/標準クラスタ、ストレッチクラスタ、エッジクラスタ、DC-No-FIクラスタ
- SED(自己暗号化ドライブ)を使用したクラスタ
- Intersightからのみ導入されるクラスタ
- ESXiとSCVMの再導入
- SCVMの再導入のみ
サポートされないシナリオ
- 1GbE HyperFlex EdgeおよびStretchクラスタ
- Intersightにインポートされたクラスタ
ライセンス
HyperFlexノードの再導入には、Intersight Essentialsまたは上位ライセンスが必要です。HyperFlexクラスタ内のすべてのサーバは、Intersight Essentialsまたは上位ライセンスを使用して要求および設定する必要があります。
使用するコンポーネント
- Cisco Intersight
- Cisco UCSM(オプション)
- Cisco UCSサーバ
- Cisco Hyperflex Clusterバージョン5.0(2c)
- VMWare ESXi
- VMware vCenter
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
背景説明
クラスタを正常な状態に維持することは、さまざまな理由から優先度が高くなりますが、最も重要なのは、Hypercovergeストレージソリューションのデータの整合性を確保するための冗長性です。コンバージェンスノードのブートドライブの交換など、ESXiとSCVM(ストレージコントローラ仮想マシン)の同時再導入が必要なシナリオは複数あります。
Intersightから導入されたクラスタの場合、SCVMを再導入してHyperflexクラスタに追加し直すことができます。このアクティビティは、TACのサポートなしでIntersightから実行できます。
警告:このプロセスを正しく実行しないと、将来のクラスタアップグレードの失敗やクラスタの拡張の失敗など、予期しない問題がクラスタで複数発生する可能性があることを強調してください。
コンフィギュレーション
この例では、M.2ディスク障害によりノード3が破損したMedellinという名前の3ノードエッジクラスタを使用します
Intersightでは、以下の点について説明しています。
- M.2ストレージは交換済み
- Hyperflexクラスタは、そのノードがオフラインであるため、まだ異常です
クラスタノードのオフライン検証
クラスタが正常でないことが説明されているので、M.2の問題が修正されたので、オフラインのノードを回復する必要があります
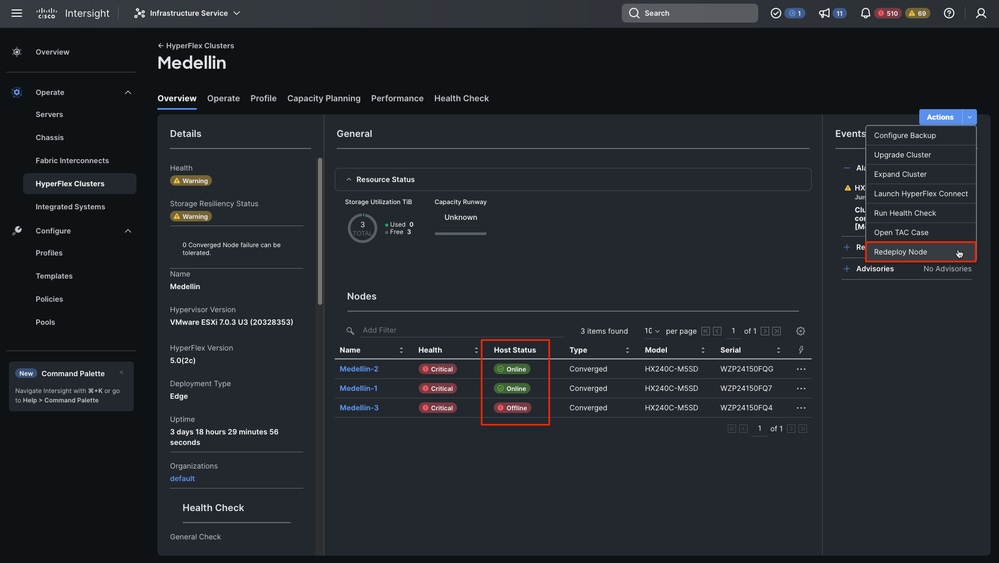
Intersightから、Infrastructure Service > Hyperflex Cluster > Overview > Eventsの順に選択します。復元力ステータスを確認できます
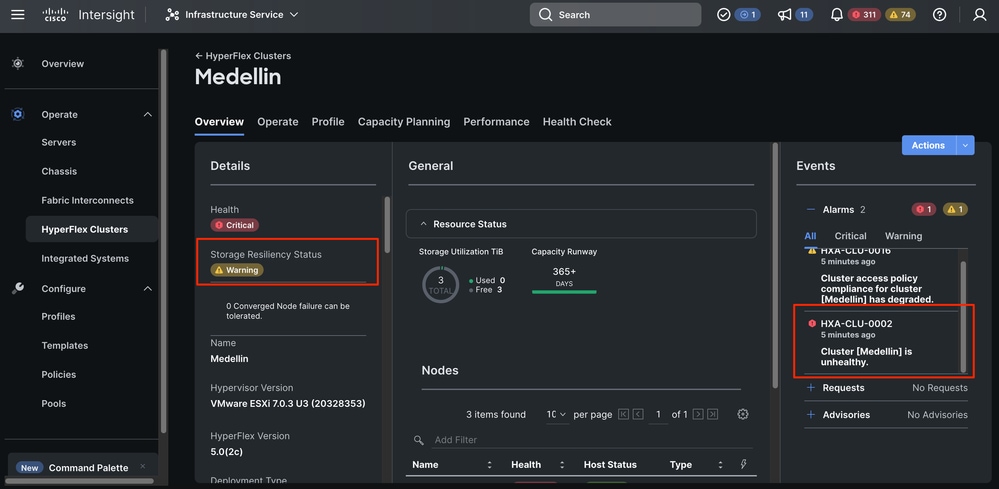
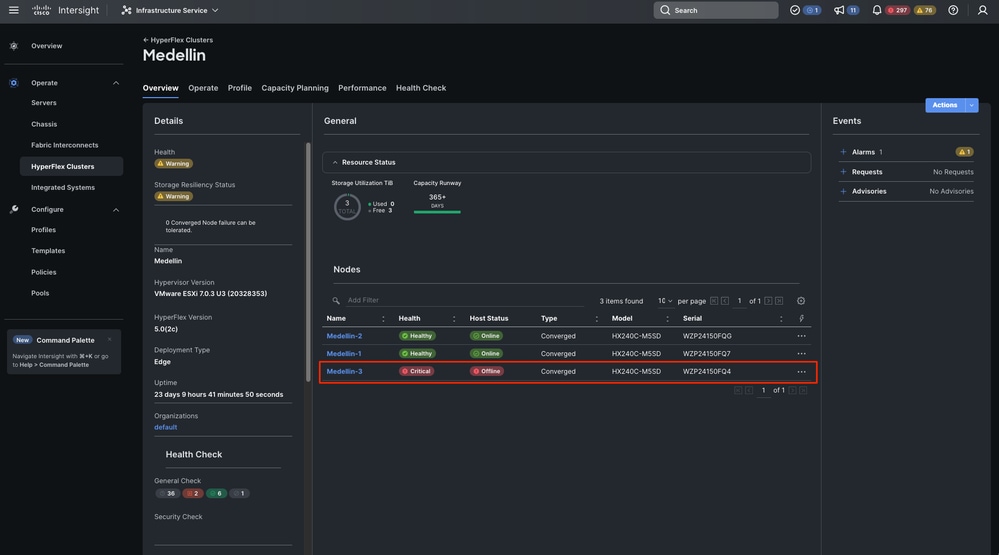
同じOverviewタブで、オフラインになっている特定のノードも確認できます
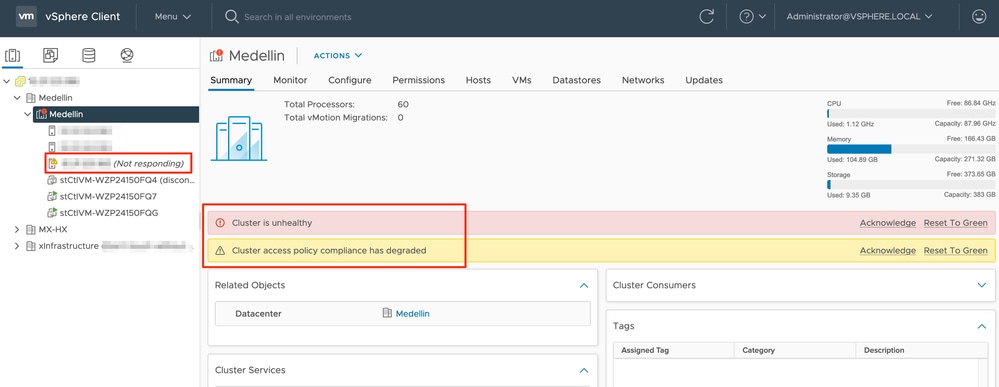
vCenterからは、クラスタが異常であることについてのアラートも取得できます
最後に、CLIからクラスタステータスを割り当てることもできます。
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : WARNING
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 0
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 30.4 GiB
Free Capacity : 3.0 TiB
Compression Savings : 62.06%
Deduplication Savings : 0.00%
Total Savings : 62.06%
# of Nodes Configured : 3
# of Nodes Online : 2
Data IP Address : 169.254.218.1
Resiliency Health : WARNING
Policy Compliance : NON_COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 0
# of persistent device failures tolerable : 1
# of cache device failures tolerable : 1
Zone Type : Unknown
All Flash : No
再配置の手順
ステップ 1: ESXi OSを再インストールします。 そのためには、Servers > Select the Server > Options (three dots)> Select Launch the KVMの順に選択します。
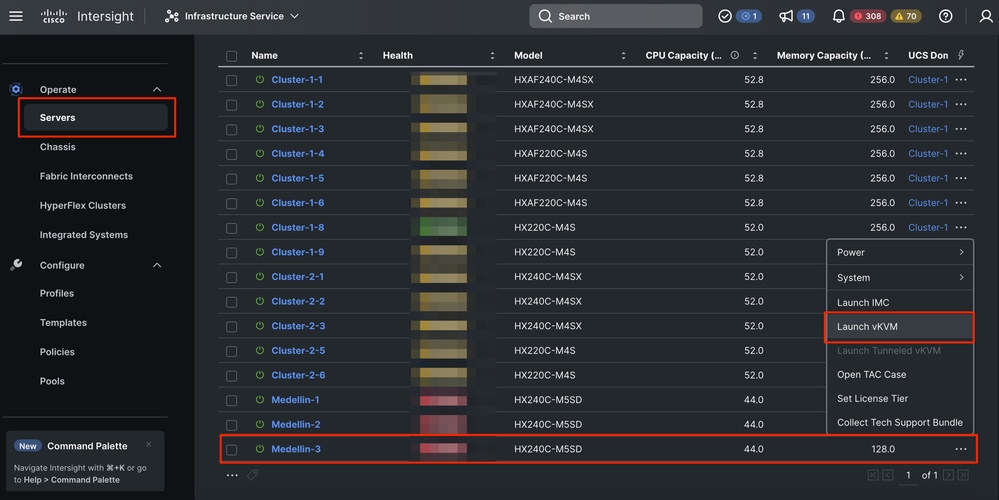
注意:他のノードがクラスタで実行しているのと同じESXiバージョンのCisco Hyperflexカスタムイメージをダウンロードする必要があります。こちらからダウンロードできます
KVMが起動したら、Virtual Media > Select Activate Virtual Devicesに移動します

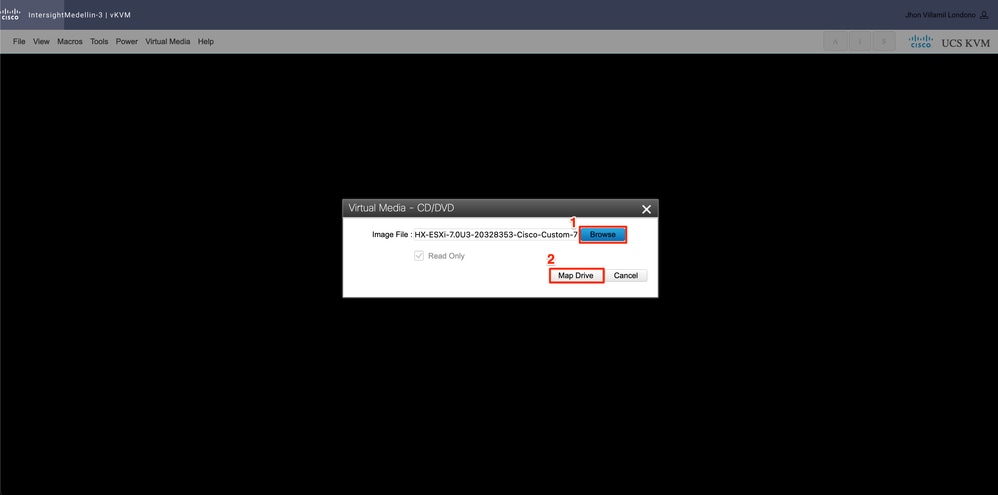
次に、Browseを選択し、ローカルコンピュータからHyperflex ESXi isoイメージを選択します。>Select Map Drive
サーバのステータスに応じてPower >に移動し、Power on System、Reset System、またはPower Cycle Systemのいずれかを選択します 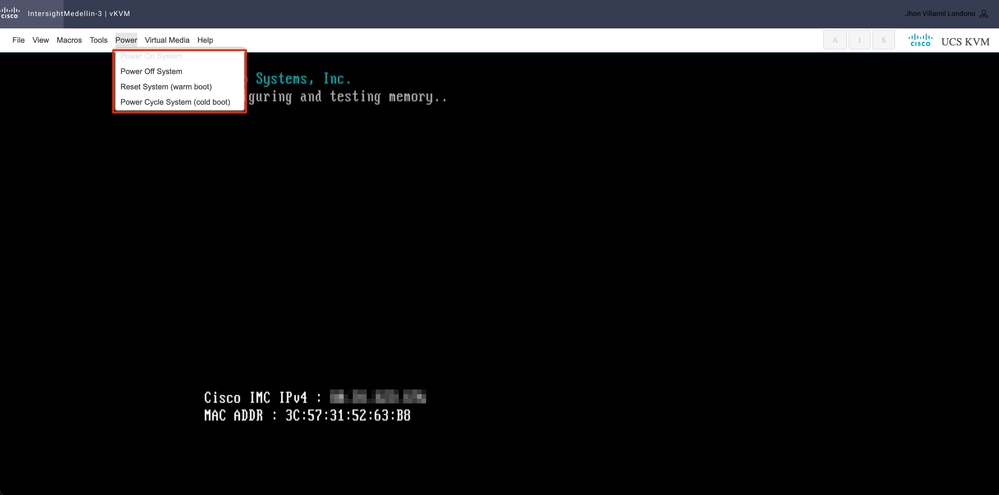
ヒント:Reset System(warm boot)を実行すると、電源をオフにせずにシステムが再起動しますが、Power Cycle System(cold boot)を実行するとシステムの電源がオフになり、再びオンになります。SCVMが破損し、ESXiが再インストールされているこのシナリオでは、両方のオプションが同じ目的を満たします
CD/DVD仮想デバイスデバイスを起動する必要があります。Tools > Select Keyboard >に移動します。Boot Menuプロンプトが表示されたら、F6キーを押します。
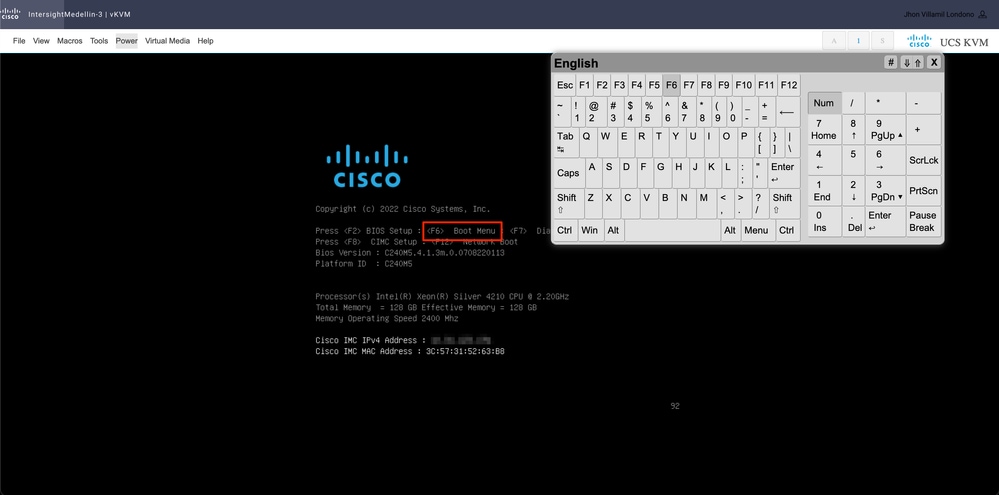
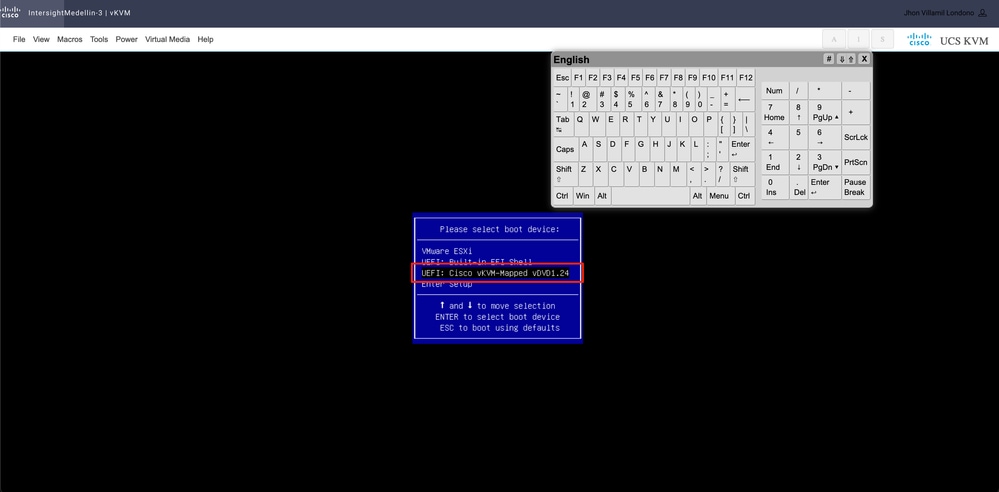
ブートメニューが表示されたら、Cisco vKVM-Mapped vDVD1.24を選択してEnterキーを押します
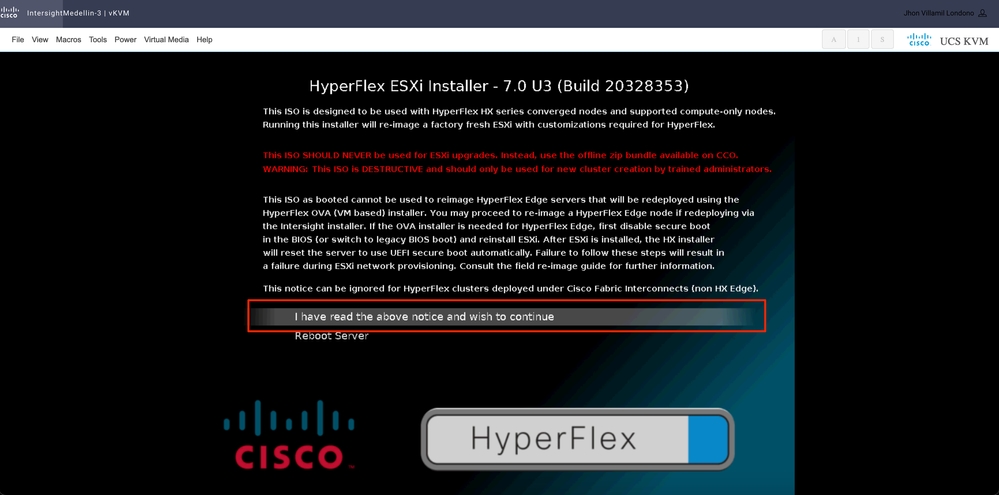
I have read the above notice and wish to continueを選択し、Enterキーを押します。
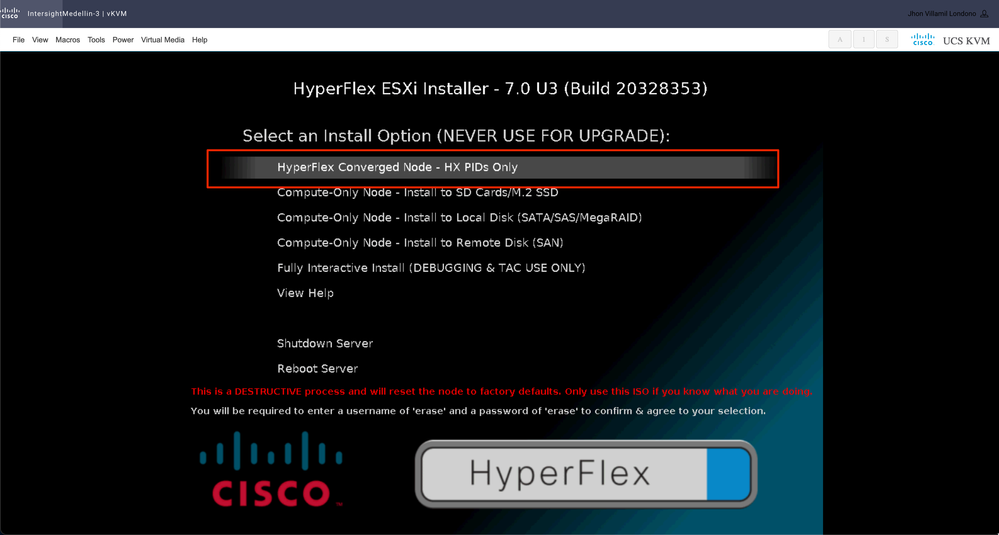
通常、コンピューティングノードには、使用されているブートデバイスによって異なるオプションが表示され、コンバージェンスノードには、ここで選択する必要があるオプションが表示されます
その後、ユーザ名とパスワードの入力を求められます。username erase > hit Enter > Type password erase > hitと入力します。
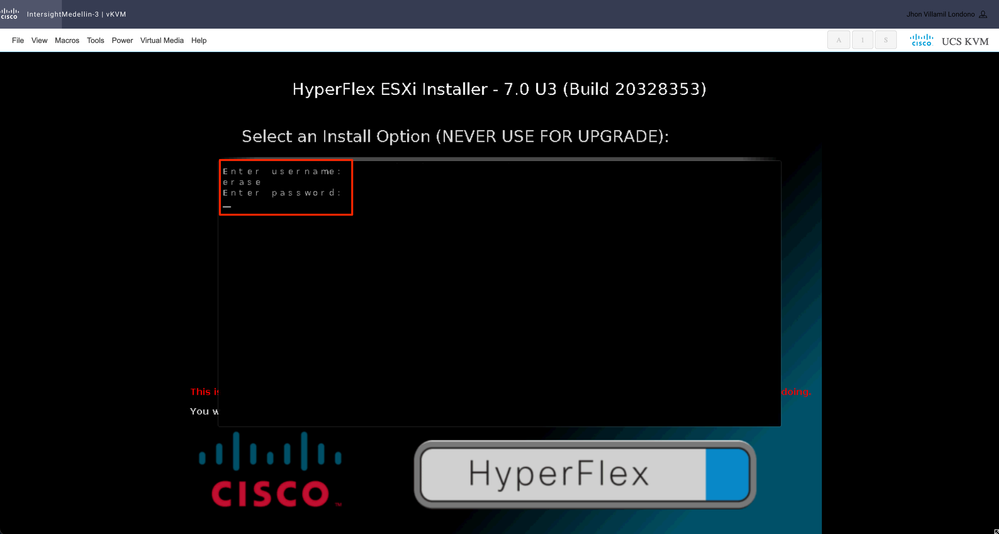
注:誤ったパスワード/ユーザ名を入力すると、1つ前のステップに戻り、再試行できます
この時点でインストールが開始され、vKVMを介してモニタできます
ステップ 2:Infrastructure Service > Hyperflex Clusters > Hyperflexクラスタの選択>アクションの選択>ノードの再導入の選択に移動します。

ヒント: SCVMだけが破損していて、再インストールが必要な場合は、「Redeploy」を選択する前に、「Redeploy Node cannot be triggered because no offline hosts in this cluster.」というエラーが発生する前にサーバの電源をオフにする必要があります。
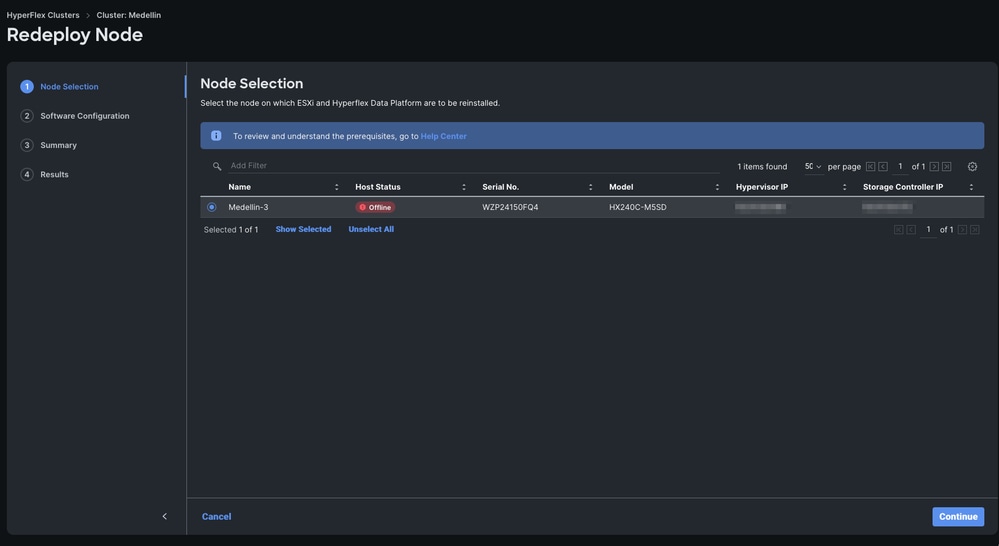
ステップ 3:ノードをオフラインで選択>続行を選択
ステップ 4:セキュリティ、vCenter、およびプロキシ設定のポリシーが同じクラスタに対応していることを確認し、[次へ]を選択します。
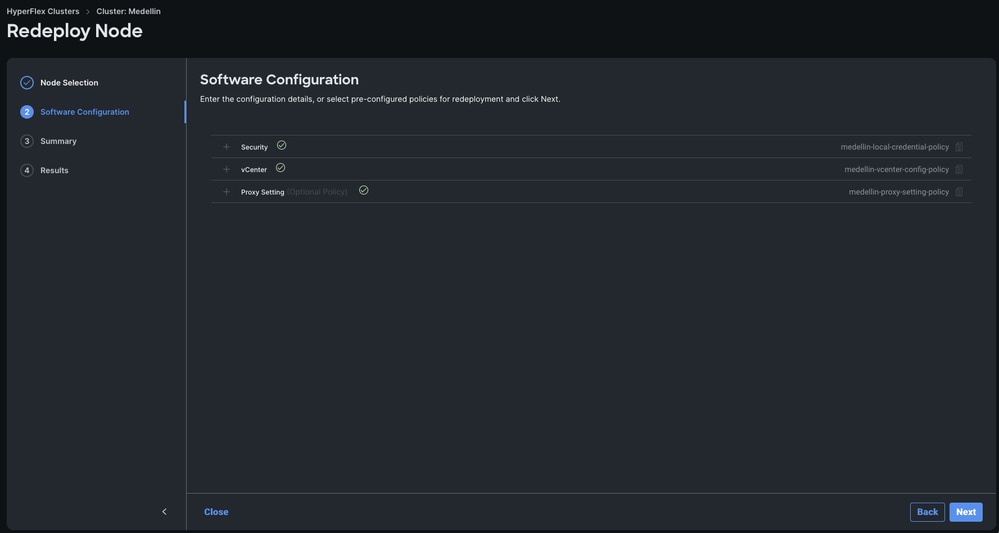
ただし、SCVMのみが再導入され、ESXiが損なわれていない場合は、セキュリティポリシーから[このノードのハイパーバイザは工場出荷時のデフォルトパスワードを使用します]オプションを選択解除し、[次へ]を選択する前に、現在のESXiパスワードがここで更新されていることを確認する必要があります
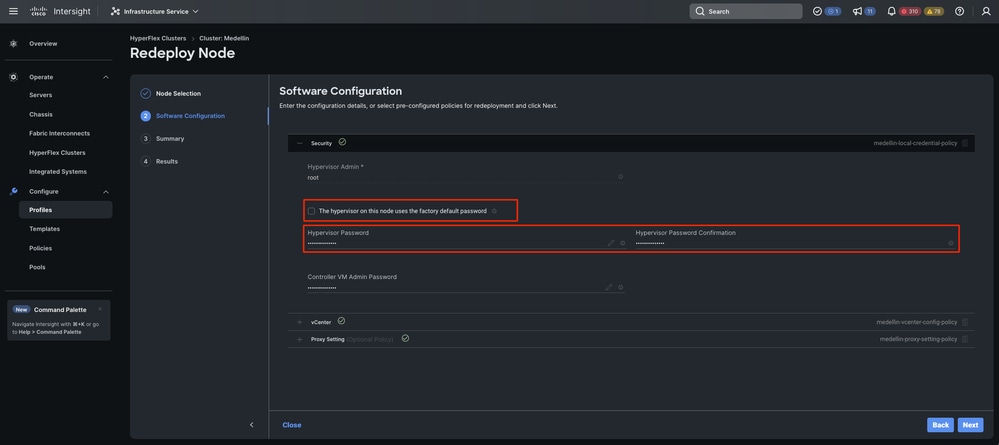
ステップ 5:Validate and Redeployの選択
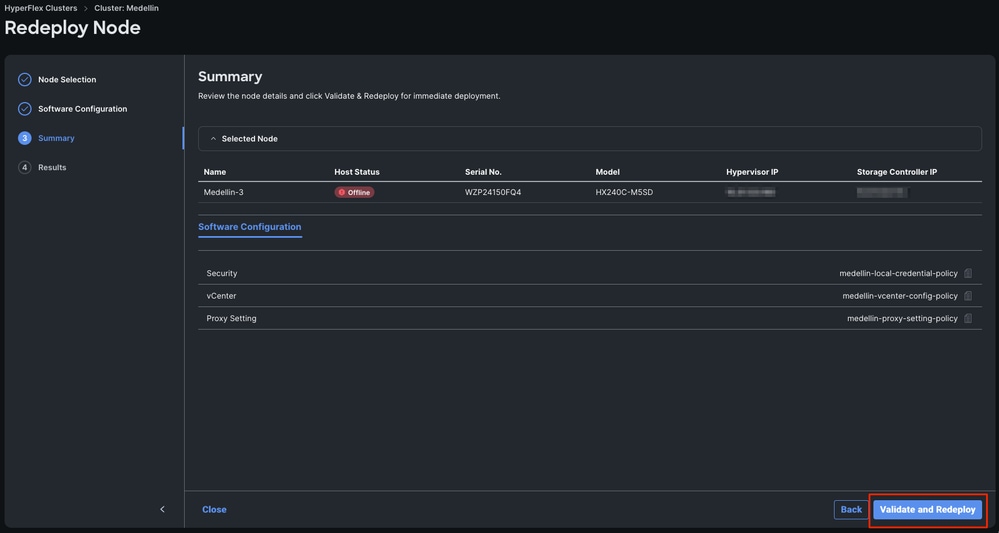
手順 6:ワークフローが完了するまで待ちます
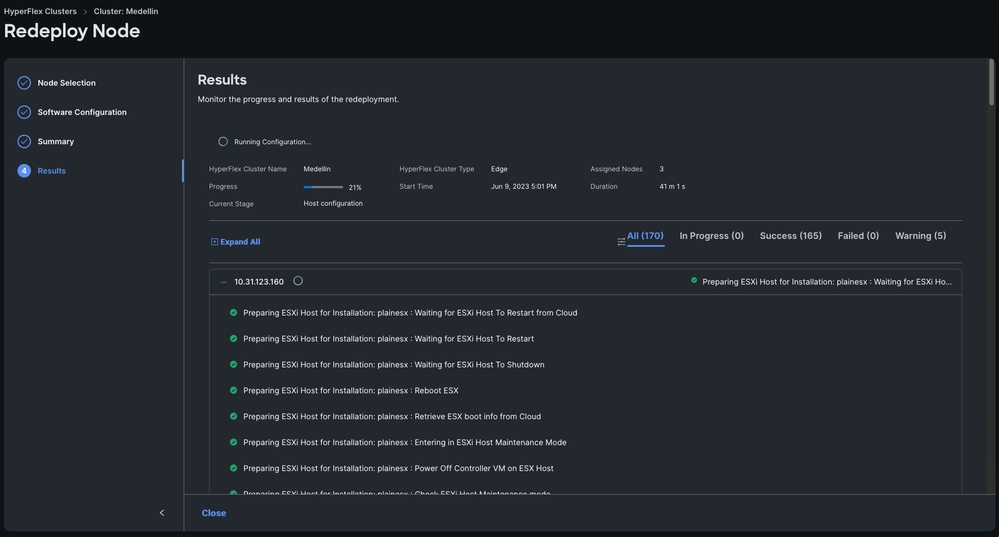
注: 進捗状況を監視できますが、通常は数時間かかります
最後に再展開が完了し、Medellinクラスタが正常な状態に戻りました
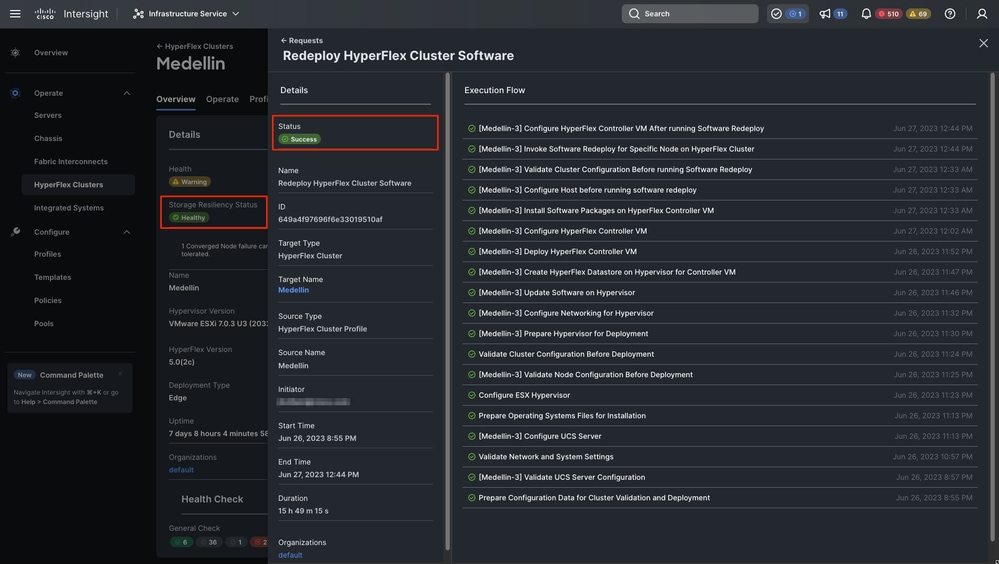
クラスタの正常な状態の検証
Intersightからの検証
Hyperflex Clustersに移動>クラスタを選択> Select Overviewタブ
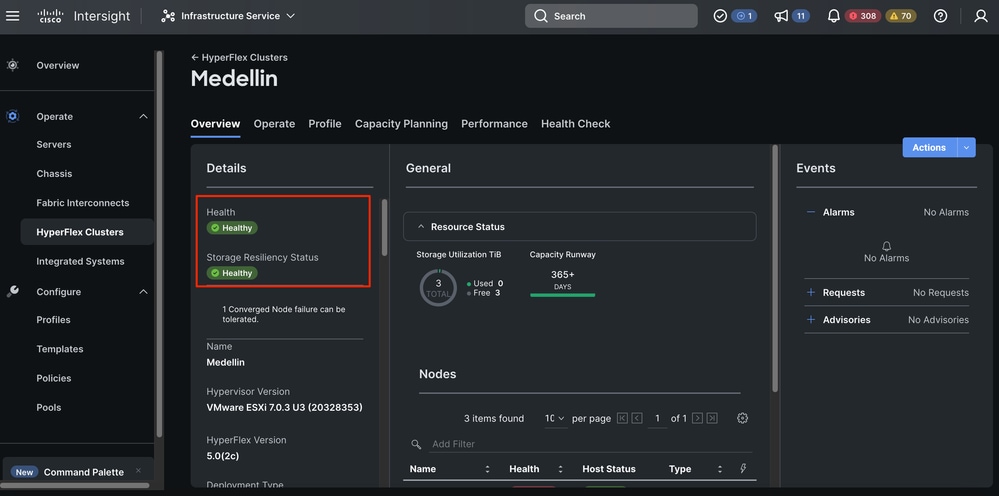
Hyperflex Connectからの検証
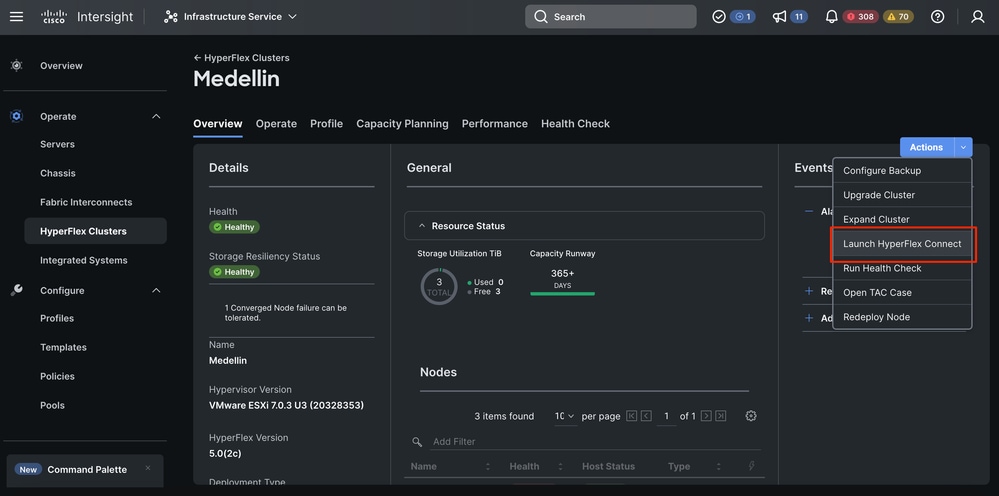
IntersightからHXDPを起動し、そこからステータスを検証します。
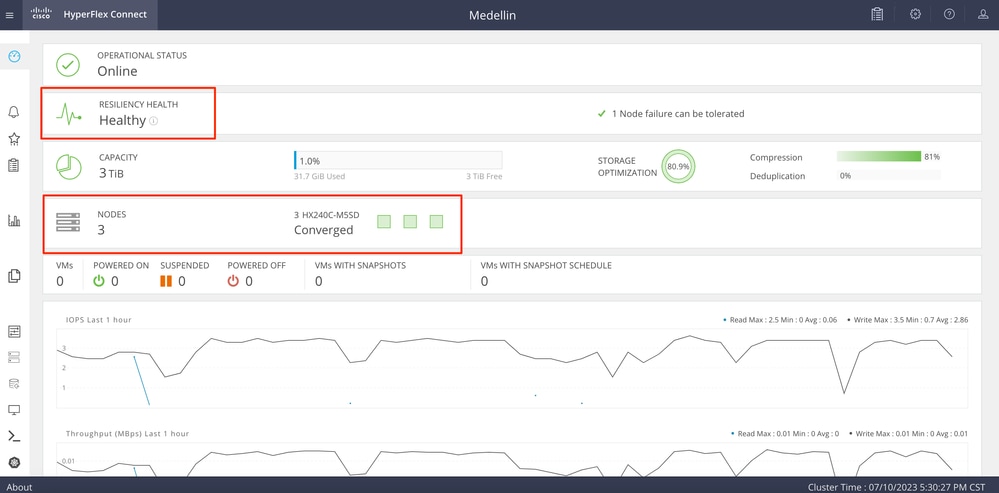
CLIからの検証
CLIからは、hxcli cluster status、hxcli cluster info、hxcli cluster health、hxcli node listなどのコマンドを使用できます。
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : HEALTHY
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 1
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 31.7 GiB
Free Capacity : 3.0 TiB
Compression Savings : 80.90%
Deduplication Savings : 0.00%
Total Savings : 80.90%
# of Nodes Configured : 3
# of Nodes Online : 3
Data IP Address : 169.254.218.1
Resiliency Health : HEALTHY
Policy Compliance : COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 1
# of persistent device failures tolerable : 2
# of cache device failures tolerable : 2
Zone Type : Unknown
All Flash : No
関連情報
HyperFlexノードの再導入ワークフロー
 フィードバック
フィードバック