概要
このドキュメントでは、クライアント側からGUI関連の問題を絞り込んでトラブルシューティングするために、HTTP ARchive形式(HAR)ログを収集するプロセスについて説明します。また、これらのファイルが有用である理由と、さまざまなブラウザからファイルを収集する方法についても説明します。
HTTP Archive形式
なぜハル?
インターネット経由でSoftware as Service(SaaS)にアクセスまたは使用すると、サービスにアクセスする際にさまざまな問題が発生する可能性があります。問題を絞り込んで切り分けるには、クライアント側とサーバ/サービス側のインタラクションを理解する必要があります。HARログは、クライアント側からのインタラクションを提供します。HARログは、ログを記録し、ブラウザのサイトとのインタラクションを追跡する独自のキャプチャセットです。このログセットは、クライアント側で何が起きているのかを十分に理解し、その結果、トラブルシューティングのプロセスがスピードアップします。
いくつかの一般的なシナリオでHARログを見てみましょう
- Webページのレンダリングの問題のトラブルシューティング(Webページの一部が読み込まれない、ページのフォーマットが正しくない、またはWebページの一部が見つからない場合など)
- パフォーマンスの問題のトラブルシューティング(読み込みに時間がかかったり、イベントがトリガーされたときにタイムアウトになったりするなど)
HARの内容と利点
HARファイルはJSON形式で情報を保存します。これにより、視覚補助を使用したデータの表示が容易になります。HARファイルには、複数のコンポーネントのタイミング情報が含まれています。Googleの「リソースタイミングについて」に基づいて、ログに存在するいくつかのタイマーがあります。
停止/ブロッキング:要求が送信されるまでの待ち時間。キューイングに関して説明されている理由を待っている可能性があります。さらに、この時間には、プロキシネゴシエーションに費やされた時間が含まれます。
プロキシネゴシエーション:プロキシサーバ接続とのネゴシエーションに費やされた時間。
DNSルックアップ:DNSルックアップの実行に費やされた時間。ページ上の新しいドメインはすべて、DNSルックアップを実行するために完全なラウンドトリップが必要です。
初期接続/接続中:TCPハンドシェイク/リトライやSSLのネゴシエーションなど、接続の確立にかかる時間。
SSL:SSLハンドシェイクの完了に費やされた時間。
要求の送信/送信:ネットワーク要求の発行に費やされた時間。通常、ミリ秒の分数です。
待機中(TTFB):最初の応答(最初のバイトまでの時間)を待機するために費やされた時間。この時間は、サーバが応答を配信するのを待つ時間に加えて、サーバへのラウンドトリップの遅延をキャプチャします。
コンテンツのダウンロード/ダウンロード:応答データの受信に費やされた時間。
推論
HARログからのこのタイミング情報は、ネットワークのどの部分を最初に調べればよいかを絞り込むのに役立ちます。
- ネットワークの遅延に気付いた場合は、ネットワークのどの側面を対象にしてトラブルシューティングを行うべきかを把握できます。
- これがWebページのレンダリングの問題である場合は、「コンテンツのダウンロード/ダウンロード」セクションを参照して、各コンテンツに対して返された要求と応答を確認し、エラーや問題がないかどうかを確認できます。
メモ帳でHARログファイルが開きます。次に、その外観の一部を示します。
オンラインツールソフトウェアにロードされたファイルのプレビューを次に示します。
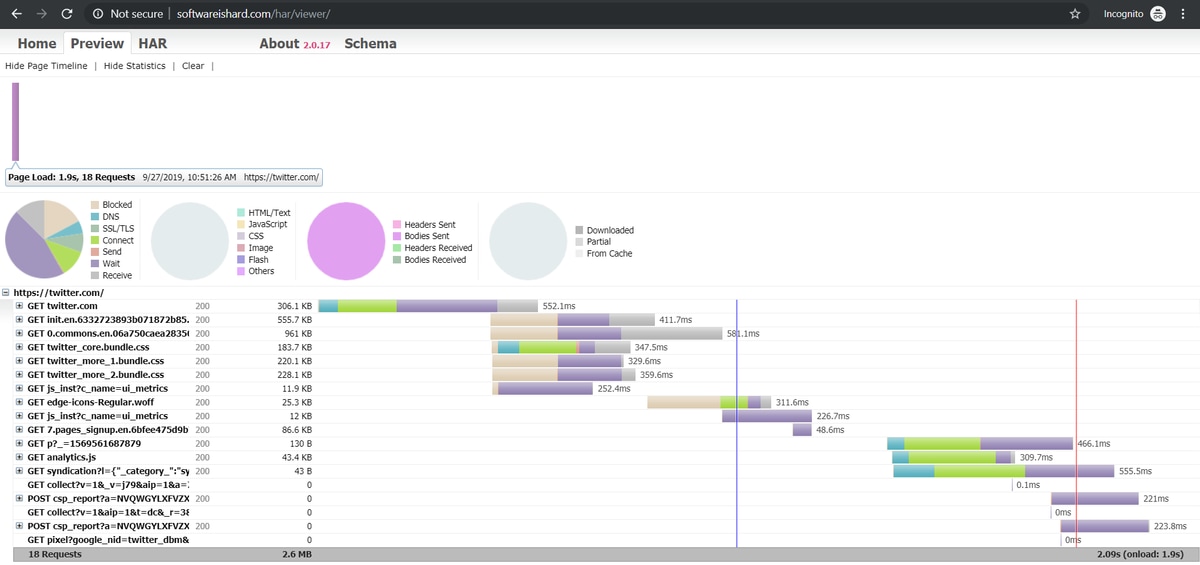
この画像から、時間を費やす場所と、どのコンポーネントが最も長い時間を要するかについての公平なアイデアを得ることができます。
オンラインツールG-Suiteにロードされたファイルのプレビューを次に示します。
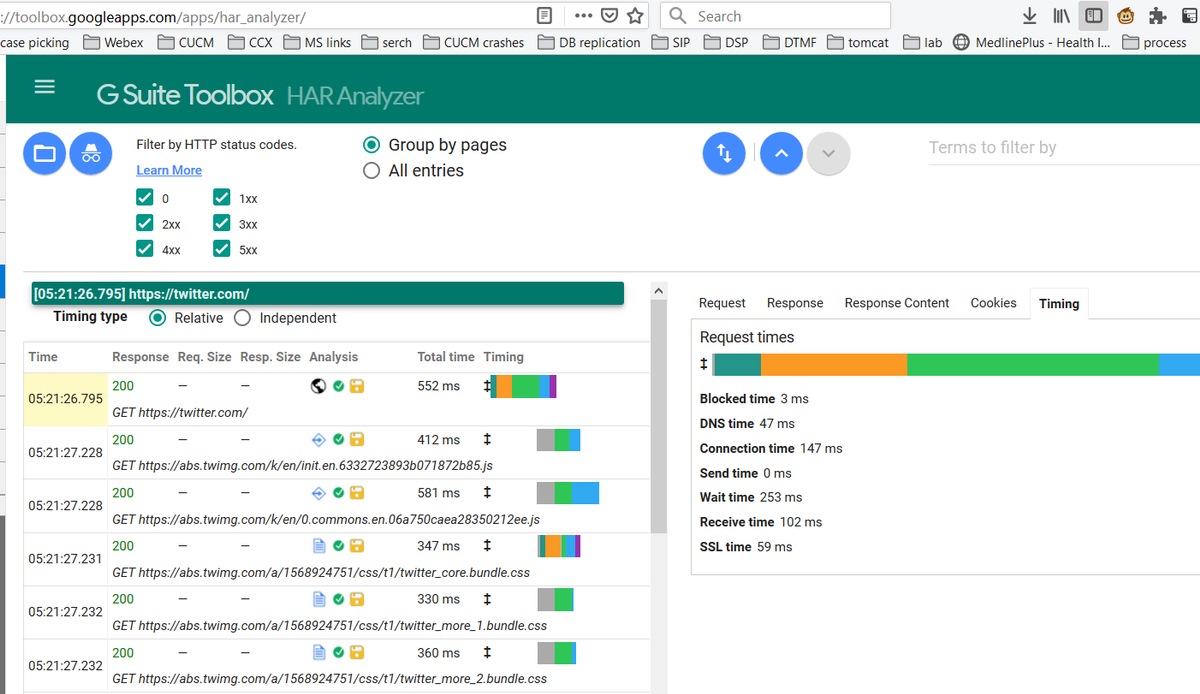
ここでは、各リクエストのタイマー情報を確認できます。
HARログの収集
これは、比較のために動作しているHARログと動作していないHARログのセットを収集できる場合のトラブルシューティングに非常に役立ちます。作業していないページでは、すべてのコンポーネントの平均時間を得るために複数のHARファイルを収集でき、同様のコンポーネントに問題があるかどうかを確認できる場合に最適です。
HARを収集する前に、ブラウザにすべての情報を強制的にダウンロードさせ、すでに存在するキャッシュされたデータを使用しないように、1つのプライベートブラウジングセッションを使用することを推奨します。
ブラウザのプロセスは次のとおりです。
- 開発者オプションを開きます。
- ネットワーク上のオプションを選択し、インタラクションをキャプチャする準備が整っていることを確認します。
- Webページで問題を再現します。
- キャプチャを保存します。
- 保存したファイルを送信して、詳細な分析を行います。
次に、これらのブラウザからHRAログを収集するプロセスを示します。
Google Chrome
1. F12を押して、図に示すように[Developer]タブが開きます。
2.図に示すように、[Network]タブをクリックします。
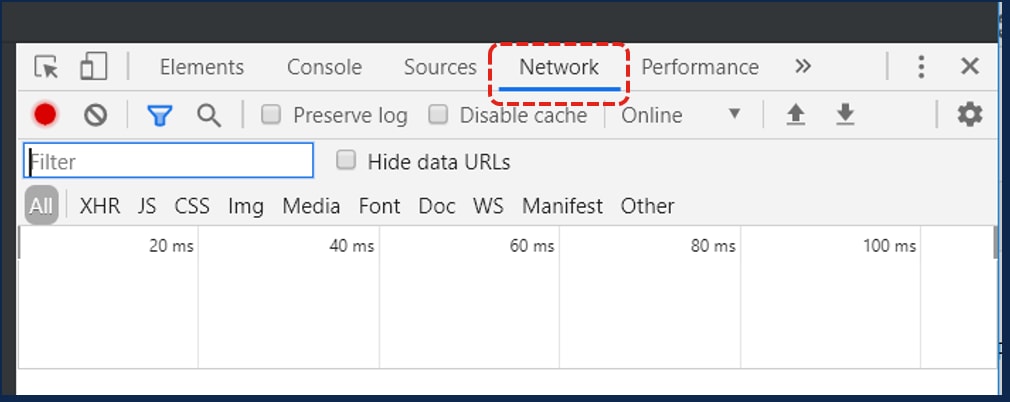
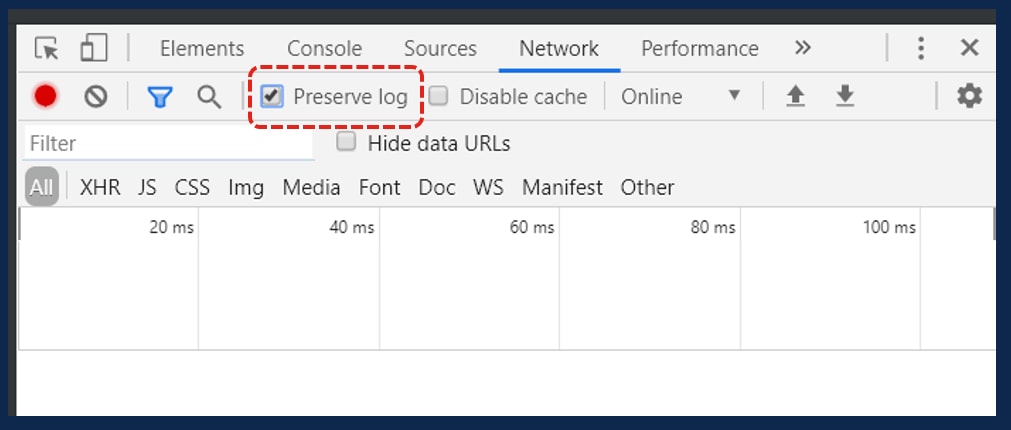
3.図に示すようにPreserveログを選択します。
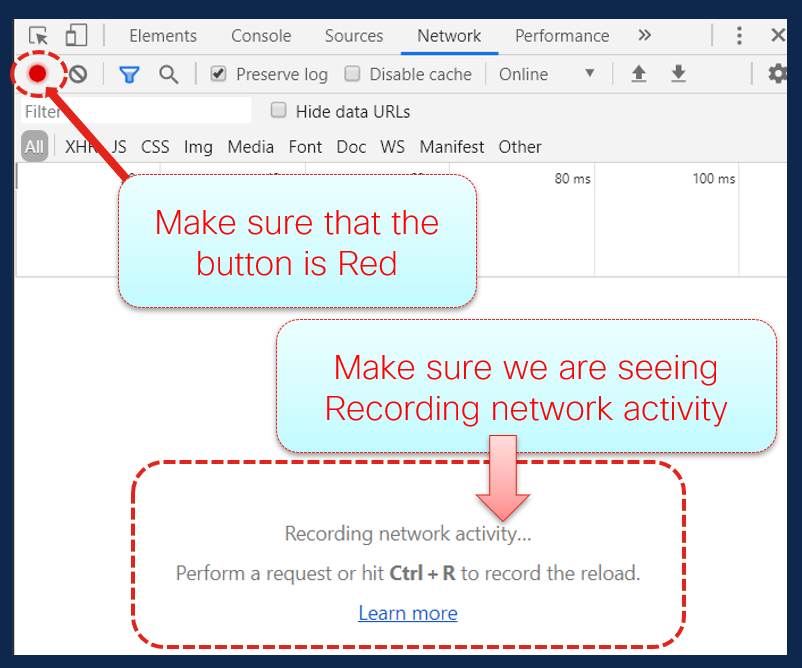
4. [Network]タブの左上にある[record]ボタンに注目してください。カラーが赤色の場合は、キャプチャが開始されたことを意味します。ボタンが黒の場合は、黒い円をクリックして色を赤に変更し、ブラウザで記録アクティビティを開始します。
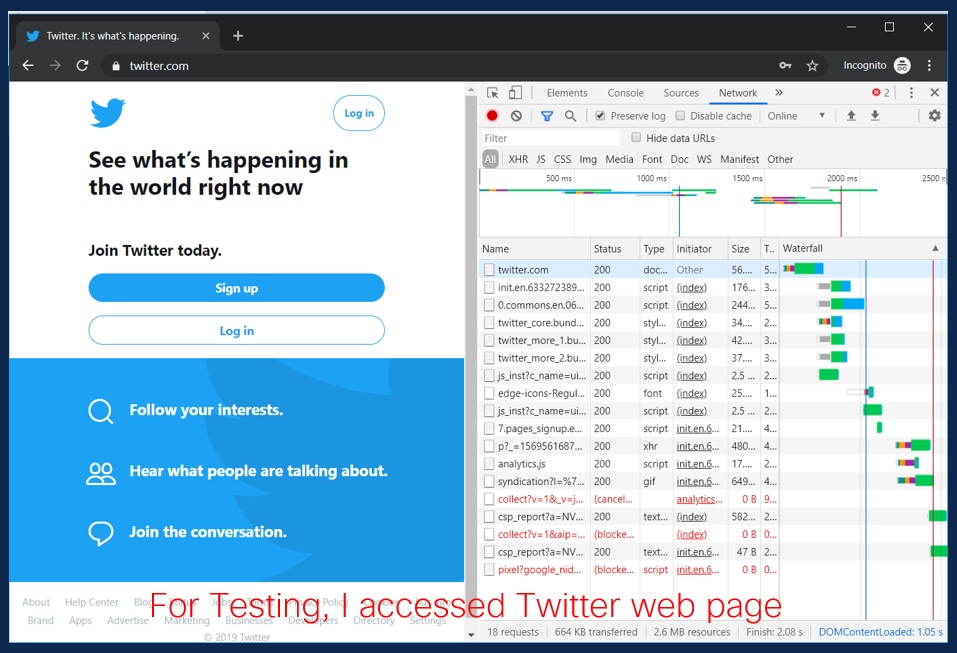
5.図に示すように、キャプチャの実行中に問題を再現します。
6.問題が再作成されたら、アクティビティ・ペインの任意の行を右クリックし、図に示すように[Save All as HAR with content]を選択します。
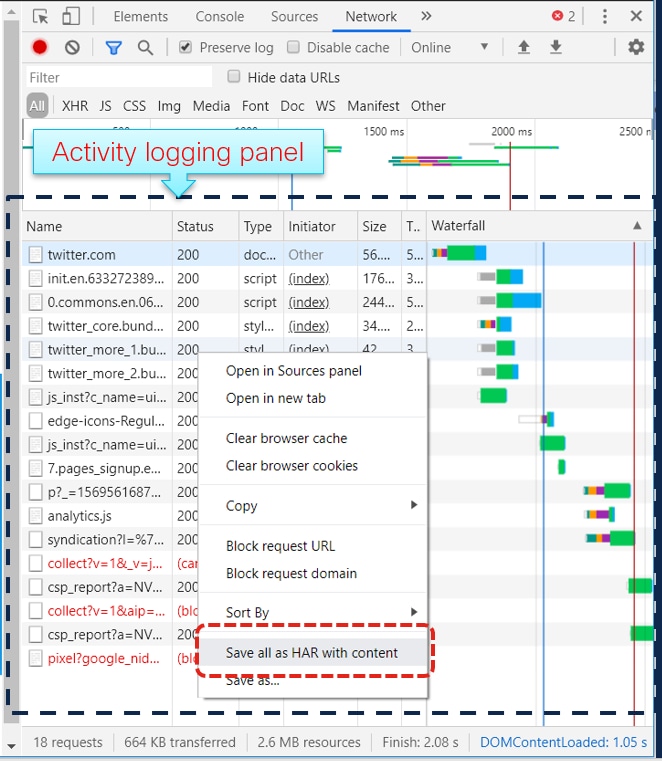
7.ファイルを保存し、分析のためにファイルを送信します。
Firefox
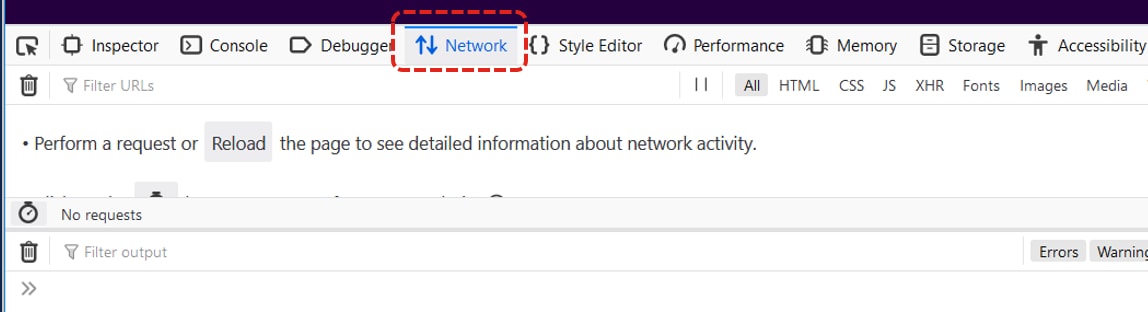
1. F12を押し、開いた状態で開発者タブを開きます。[開発ツール]ウィンドウがFirefoxの側面または下部にドッキングされたパネルとして開きます。

2.図に示すように、[Network]タブをクリックします。
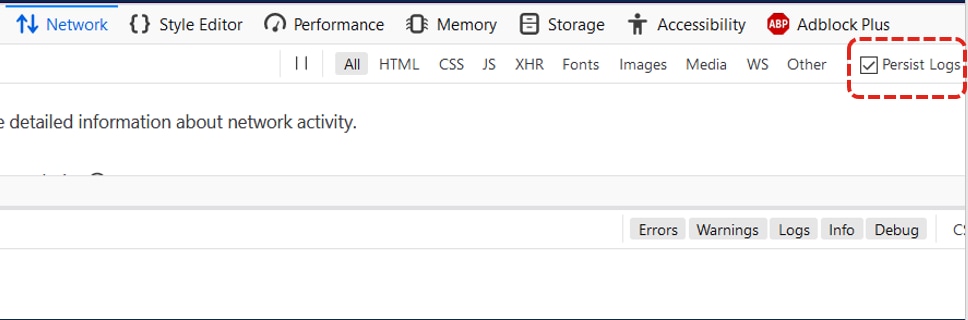
3. [Persist logs]がオンになっていることを確認します。
4.問題を再現します。
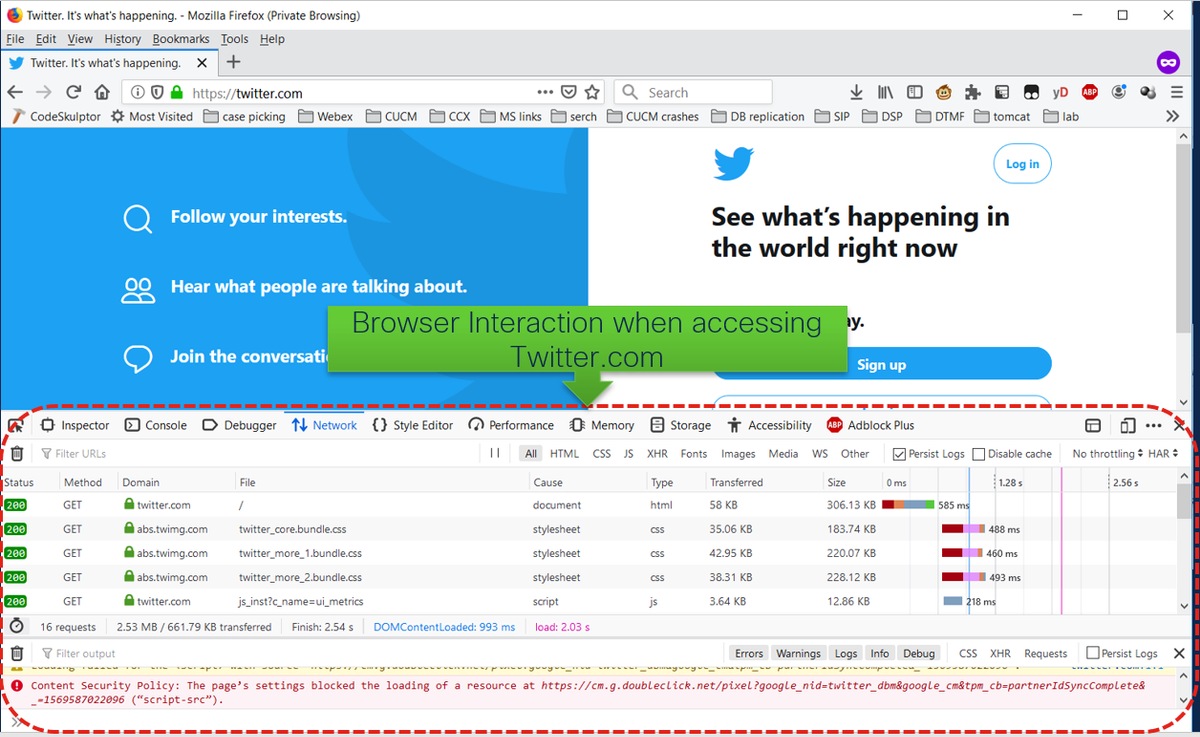
5.問題が再作成されたら、アクティビティパネルを右クリックし、図に示すようにSave all as HARを選択します。
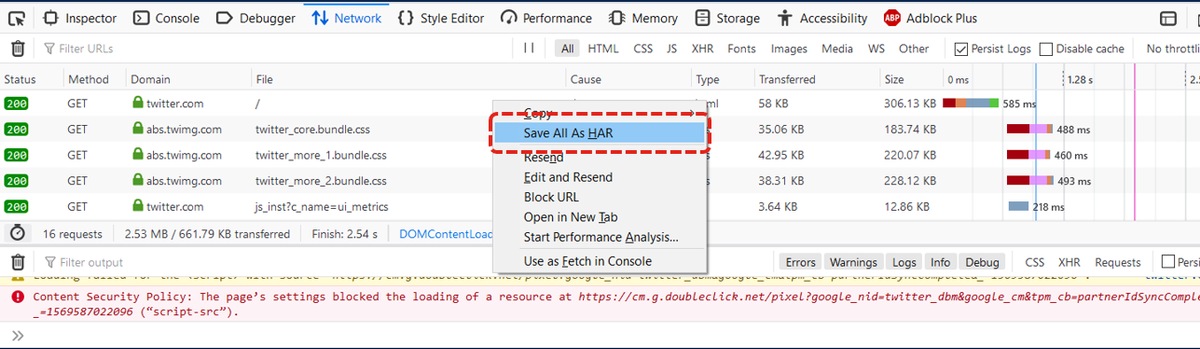
6.ファイルを保存し、分析のために送信します。
Internet Explorer
1. F12を押します。
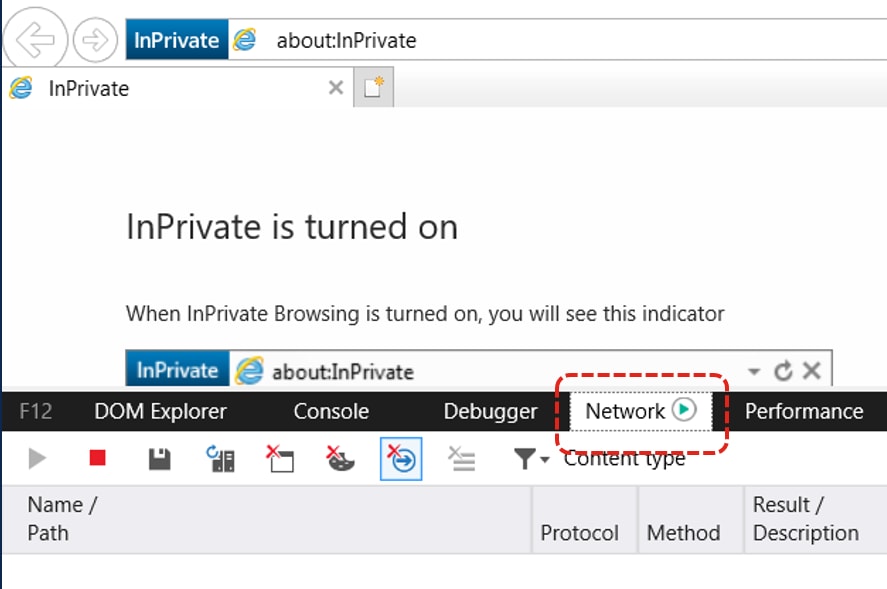
2. [ネットワーク]タブが表示されていることを確認します。
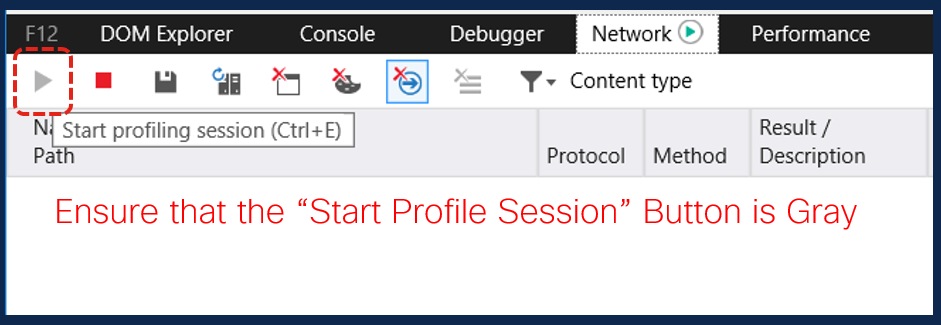
3. [Start Profile Session]がグレー表示されていることを確認します(デフォルトの状態である場合は、キャプチャが実行中であることを示します)。
4.問題を再現します。
5.問題が再作成されたら、[Save]アイコンをクリックしてログを保存します。
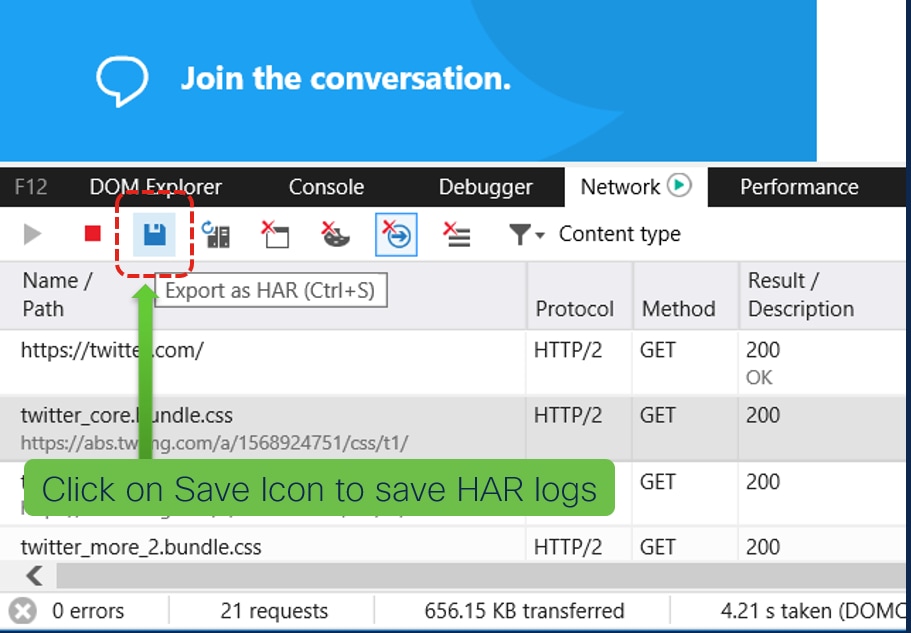
6.ファイルを保存し、分析のために送信します。
 フィードバック
フィードバック