概要
このドキュメントでは、Cloud Native Deployment Platform(CNDP)セットアップの最初のサーバからCluster Managerを回復する手順について説明します。
前提条件
要件
次の項目に関する知識があることが推奨されます。
- Cisco Subscriber Microservices Infrastructure(SMI)
- 5G CNDPまたはSMI-Bare-Metal(BM)アーキテクチャ
- 分散レプリケーションブロックデバイス(DRBD)
使用するコンポーネント
このドキュメントの情報は、次のソフトウェアとハードウェアのバージョンに基づいています。
- スイス株価指数2020.02.2.35
- Kubernetes v1.21.0
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
背景説明
SMI Cluster Managerについて教えてください。
クラスタマネージャは、コントロールプレーンとユーザプレーンの両方のクラスタ展開の初期ポイントとして使用される2ノードのキープアライブクラスタです。シングルノードのKubernetesクラスタと、クラスタ全体のセットアップを担当する一連のPODを実行します。プライマリクラスタマネージャのみがアクティブで、セカンダリは障害発生時にのみ引き継ぎ、メンテナンスのために手動でダウンさせます。
Inception Serverとは
このノードは、基盤となるCluster Manager(CM)のライフサイクル管理を実行します。ここからDay0 Configをプッシュできます。
このサーバは通常、地域別またはトップレベルのオーケストレーション機能(NSOなど)と同じデータセンターに導入され、通常はVMとして実行されます。
問題
クラスタマネージャは、分散複製ブロックデバイス(DRBD)を使用する2ノードクラスタでホストされ、クラスタマネージャプライマリおよびクラスタマネージャセカンダリとしてキープアライブされます。この場合、UCSでのOSの初期化/インストール中にCluster Managerセカンダリが自動的に電源オフ状態になり、OSが破損していることが示されます。
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 WFConnection Primary/Unknown UpToDate/DUnknown /mnt/stateful_partition ext4 568G 369G 170G 69%
メンテナンスの手順
このプロセスは、CMサーバにOSを再インストールするのに役立ちます。
ホストの特定
Cluster-Managerにログインし、ホストを特定します。
cloud-user@POD-NAME-cm-primary:~$ cat /etc/hosts | grep 'deployer-cm'
127.X.X.X POD-NAME-cm-primary POD-NAME-cm-primary
X.X.X.X POD-NAME-cm-primary
X.X.X.Y POD-NAME-cm-secondary
Inception Serverからのクラスターの詳細の識別
Inceptionサーバにログインし、Deployerに入り、Cluster-Managerからhosts-IPを使用してクラスタ名を確認します。
最初のサーバへのログインが成功したら、次に示すようにオペレーションセンターにログインします。
user@inception-server: ~$ ssh -p 2022 admin@localhost
Cluster Manager SSH-IPからクラスタ名を確認します(ssh-ip =ノードSSH IP ip-address = ucs-server cimc ip-address)。
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tab
SSH
NAME NAME IP SSH IP IP ADDRESS
------------------------------------------------------------------------------
POD-NAME-deployer cm-primary - X.X.X.X 10.X.X.X ---> Verify Name and SSH IP if Cluster is part of inception server SMI.
cm-secondary - X.X.X.Y 10.X.X.Y
ターゲットクラスタの設定を確認します。
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME-deployer
仮想ドライブを取り外してサーバからオペレーティングシステムをクリアする
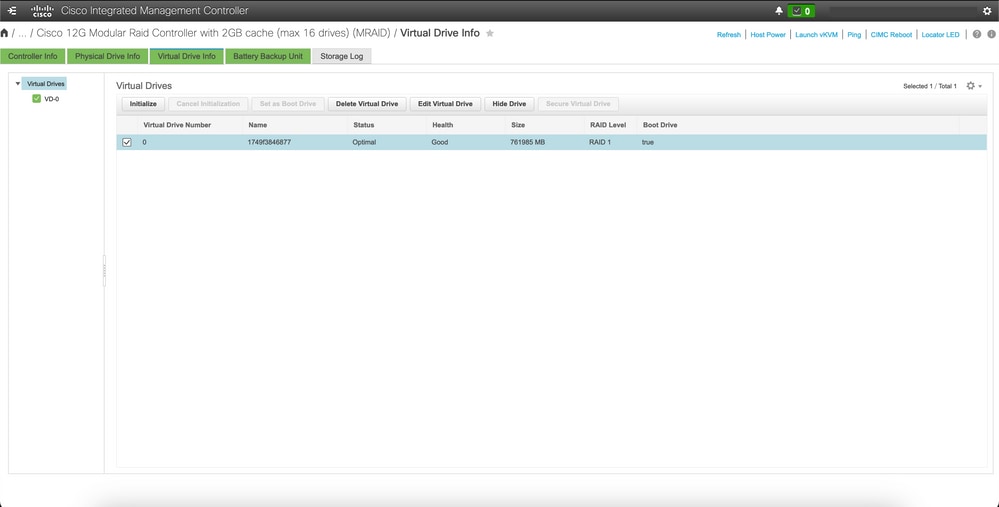
影響を受けるホストのCIMCに接続し、ブートドライブをクリアして仮想ドライブ(VD)を削除します。
a) CIMC > Storage > Cisco 12G Modular Raid Controller > Storage Log > Clear Boot Drive
b) CIMC > Storage > Cisco 12G Modular Raid Controller > Virtual drive > Select the virtual drive > Delete Virtual Drive
クラスター同期の実行
最初のサーバーからCluster-Managerの既定のクラスター同期を実行します。
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
デフォルトのcluster-syncが失敗した場合、完全な再インストールのためにforce-vm redeployオプションを使用してcluster-syncを実行します(Cluster-syncアクティビティの完了には約45 ~ 55分かかる場合があります。これは、クラスタでホストされているノードの数によって異なります)
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true force-vm-redeploy true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Cluster-sync同期ログの監視
[inception-server] SMI Cluster Deployer# monitor sync-logs POD-NAME-deployer
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Cluster name: POD-NAME
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Force VM Redeploy: true
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: Force partition Redeploy: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: reset_k8s_nodes: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: purge_data_disks: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: upgrade_strategy: auto
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: sync_phase: all
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: debug: true
...
...
...
クラスタ同期が正常に行われることで、サーバが再プロビジョニングされ、インストールされます。
PLAY RECAP *********************************************************************
cm-primary : ok=535 changed=250 unreachable=0 failed=0 skipped=832 rescued=0 ignored=0
cm-secondary : ok=299 changed=166 unreachable=0 failed=0 skipped=627 rescued=0 ignored=0
localhost : ok=59 changed=8 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
Thursday 23 February 2023 13:17:24 +0000 (0:00:00.109) 0:56:20.544 *****. ---> ~56 mins to complete cluster sync
===============================================================================
2023-02-23 13:17:24.539 DEBUG cluster_sync.POD-NAME: Cluster sync successful
2023-02-23 13:17:24.546 DEBUG cluster_sync.POD-NAME: Ansible sync done
2023-02-23 13:17:24.546 INFO cluster_sync.POD-NAME: _sync finished. Opening lock
検証
影響を受けるクラスタマネージャが到達可能であり、プライマリおよびセカンダリクラスタマネージャのDRBD概要がUpToDateステータスであることを確認します。
cloud-user@POD-NAME-cm-primary:~$ ping X.X.X.Y
PING X.X.X.Y (X.X.X.Y) 56(84) bytes of data.
64 bytes from X.X.X.Y: icmp_seq=1 ttl=64 time=0.221 ms
64 bytes from X.X.X.Y: icmp_seq=2 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=3 ttl=64 time=0.151 ms
64 bytes from X.X.X.Y: icmp_seq=4 ttl=64 time=0.154 ms
64 bytes from X.X.X.Y: icmp_seq=5 ttl=64 time=0.172 ms
64 bytes from X.X.X.Y: icmp_seq=6 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=7 ttl=64 time=0.174 ms
--- X.X.X.Y ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 6150ms
rtt min/avg/max/mdev = 0.151/0.171/0.221/0.026 ms
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 Connected Primary/Secondary UpToDate/UpToDate /mnt/stateful_partition ext4 568G 17G 523G 4%
影響を受けるクラスタマネージャがインストールされ、ネットワークに正常に再プロビジョニングされます。
2.2クラスタマネージャSSH-IPからのクラスタ名の確認
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip |ノードの選択* ssh-ip |ノードの選択* ucs-server cimc ip-address [|]タブ
SSH
名前名前IP SSH IP IPアドレス
------------------------------------------------------------------------------
POD-NAME cm-primary - 192.X.X.X 10.192.X.X
cmセカンダリ:192.X.X.Y 10.192.X.Y
*SSH IP =ノードSSH IP
*IPアドレス= ucs-server cimc ip-address
2.3ターゲットクラスタの設定を確認します。
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME Inceptionサーバにログインし、Deployerに移動して、Cluster-Managerからhosts-IPを使用してcluster-nameを確認します。 Inceptionサーバにログインし、Deployerに入り、Cluster-Managerからhosts-IPを使用してクラスタ名を確認します。
 フィードバック
フィードバック