超M AutoVNF クラスタ失敗における回復手順- vEPC
ダウンロード オプション
偏向のない言語
この製品のマニュアルセットは、偏向のない言語を使用するように配慮されています。このマニュアルセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザーインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブランゲージに対する取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
目次
概要
この資料がオートメーション サービス(UAS)または超M セットアップの AutoVNF クラスタ失敗を超回復 するために必要なステップをそのホスト StarOS バーチャルネットワーク 機能(VNFs)記述したものです。
背景説明
超M 事前包装され、検証された仮想化されたモービル パケット コア ソリューションはです VNFs の配備を簡素化するために設計されている。
超M ソリューションは mentoned Virtual Machine (VM)型で構成されています:
- 自動 IT
- 自動導入
- UAS か AutoVNF
- Element Manager (EM)
- Elastic Services Controller(ESC)
- 制御機能(CF)
- セッション 機能(SF)
超M の高レベル アーキテクチャおよび含まれるコンポーネントはこのイメージで描写されます:
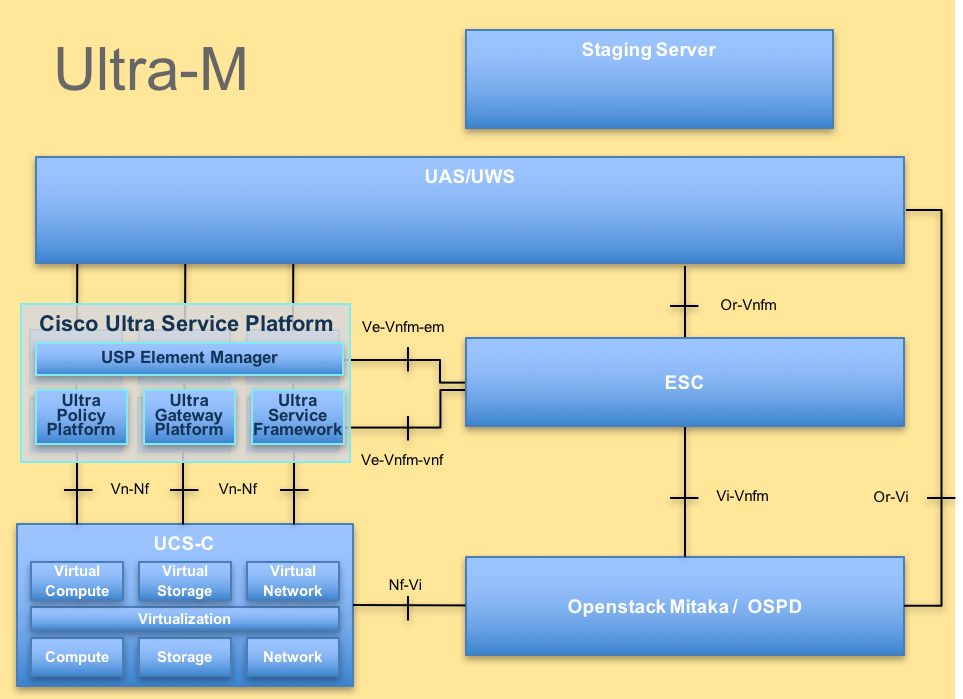 UltraM アーキテクチャ
UltraM アーキテクチャ
この資料は Cisco 超M プラットフォームについて詳しく知っている Cisco社員のために意図されています。
注: 超 M 5.1.x リリースはこの資料の手順を定義するために考慮されます。
省略形
| VNF | バーチャルネットワーク 機能 |
| CF | 制御機能 |
| SF | サービス 機能 |
| ESC | 伸縮性があるサービス コントローラ |
| MOP | プロシージャの方式 |
| OSD | オブジェクト ストレージ ディスク |
| HDD | ハードディスク ドライブ |
| SSD | ソリッド ステート ドライブ |
| VIM | 仮想 な インフラストラクチャ マネージャ |
| VM | 仮想マシン |
| EM | Element Manager |
| UAS | Ultra Automation Services |
| UUID | ユニバーサル固有の識別番号 |
Mop の作業の流れ
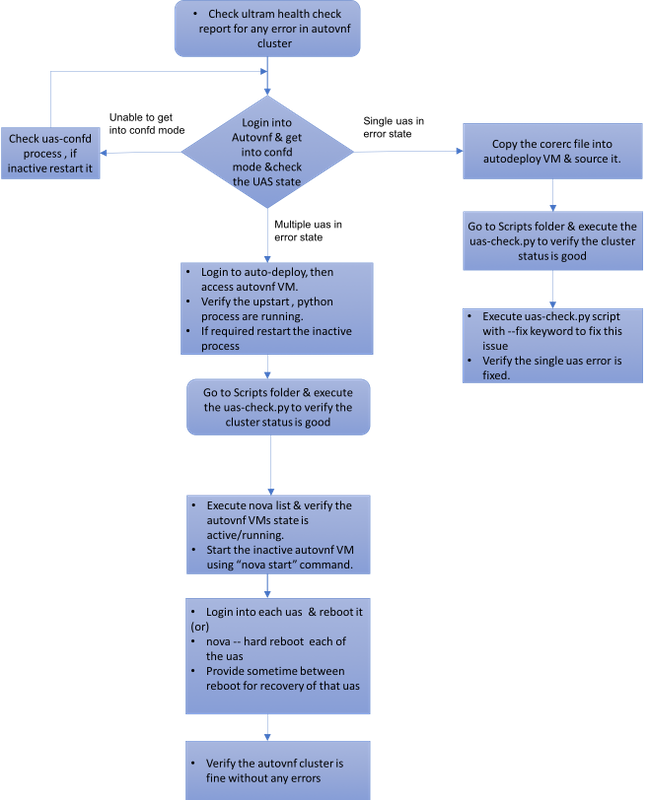
ケース UAS クラスタの単一失敗の 1.リカバリ
ステータス チェック
1.超M マネージャは超M ノードの健康診断を行います。 UAS レポートのためのレポート /var/log/cisco/ultram-health/ ディレクトリおよびグレップにナビゲート して下さい。
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. UAS クラスタの期待されたステータスは描写されるようにすべての 3 つ UAS が稼働しているところに、あります。
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
UAS に接続することを試みる場合の Confd サーバに接続する失敗
1. 場合によっては、confd サーバに接続できません。
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. uas-confd プロセスのステータスをチェックして下さい。
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. confd サーバが動作しない場合、サービスを再開して下さい。
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
エラー状態からの UAS を回復 して下さい
1. クラスタの中の 1 AutoVNF の失敗の場合には、UAS クラスタはエラー状態で UAS の 1 を示します。
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. corerc ファイル(VNF の rc ファイル)を OSPD サーバの /home/stack から AutoDeploy にコピーし、それをソースをたどって下さい。
3. uas-check.py スクリプトの使用と UAS/AutoVNF のステータスをチェックして下さい。 autovnf1is AutoVNF 名前。
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. uas-check.py スクリプトの使用の UAS を回復 し、追加して下さい --キーワードを固定して下さい。
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. 新しく作成された UAS がクラスタの稼働し、一部であることがわかります。
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
ケース 2。 3 つすべて UAS (AutoVNF)はエラー状態にあります
1. 超M マネージャは超M ノードの健康診断を行います。
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. 出力で観察されるように、超M マネージャはクラスタのすべての 3 つ UAS がエラー状態にあることを AutoVNF のための失敗がある示すことを報告し。
uas-check.py スクリプトと UAS 健全性をチェックして下さい
1. AutoVNF UAS にアクセスし、ステータスを調べることができる場合自動導入およびチェックへのログイン。
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. 自動導入から、AutoVNF ノードへのセキュア シェル(SSH)は confd モードになり。 ステータスをと示します uas をチェックして下さい。
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. すべての 3 つの UAS ノードのステータスをチェックすることを推奨します。
OpenStack レベルの VM の状態をチェックして下さい
新星リストの AutoVNF VM のステータスをチェックして下さい。 必要であれば、切断 VM を開始するために新星開始するを行って下さい。
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Zookeeper ビューをチェックして下さい
1. リーダーとしてモードを確認するために zookeeper の状態をチェックして下さい。
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. Zookeeper は普通稼働するはずです。
解決して下さい AutoVNF -プロセスおよびタスク
1. ノードのエラー状態のための原因を特定して下さい。 動作するべき AutoVNF に関しては示されているように作動中の必要があるプロセスのセットがあります:
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. これらの python プロセスが動作していることを確認して下さい:
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. 期待されたプロセスのうちのどれかが開始する/走行状態ではない場合、プロセスを再起動し、ステータスをチェックして下さい。 それがエラー状態でそれでも示したりこの問題を解決するために次の セクションで述べられるプロシージャに従って下さい。
エラー状態の多重 UAS のための修正
1.新星 ----OSPD からの VM> のハードな再度ブートする <name は、次の UAS に進む前にこの VM のリカバリの時間を与えます。 すべての UAS VM でそれをして下さい。
または
2.Log UAS および使用 sudo 再度ブートするのそれぞれに。 リカバリを待ち、次に他の UAS VM に進んで下さい。
トランザクションログに関しては、チェックして下さい:
/var/log/upstart/autovnf.log
show logs xxx | display xml
これは問題を解決し、エラー状態からの UAS を回復 します。
1. ultram_health_check レポートの使用と同じを確認して下さい。
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
シスコ エンジニア提供
- Partheeban RajagopalCisco アドバンスド サービス
- Padmaraj RamanoudjamCisco アドバンスド サービス
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)