パブリッククラウドにおける ASA Virtual クラスタの展開
クラスタリングを利用すると、複数の ASA 仮想 をグループ化して 1 つの論理デバイスとすることができます。クラスタは、単一デバイスのすべての利便性(管理、ネットワークへの統合)を備える一方で、複数デバイスによって高いスループットおよび冗長性を達成します。以下を使用して、パブリッククラウドに ASA 仮想 クラスタを展開できます。
-
Amazon Web Services(AWS)
-
Microsoft Azure
現在は、ルーテッド ファイアウォール モードのみがサポートされます。
 (注) |
パブリッククラウドにおける ASA Virtual クラスタリングについて
ここでは、クラスタリング アーキテクチャとその動作について説明します。
クラスタをネットワークに適合させる方法
クラスタは、複数のファイアウォールで構成され、これらは 1 つのデバイスとして機能します。ファイアウォールをクラスタとして機能させるには、次のインフラストラクチャが必要です。
-
クラスタ内通信用の、隔離されたネットワーク。VXLAN インターフェイスを使用したクラスタ制御リンクと呼ばれます。レイヤ 3 物理ネットワーク上でレイヤ 2 仮想ネットワークとして機能する VXLAN により、ASA 仮想 はクラスタ制御リンクを介してブロードキャスト/マルチキャストメッセージを送信できます。
-
ロードバランサ:外部ロードバランシングには次のオプションがあります。
-
AWS Gateway Load Balancer
AWS ゲートウェイロードバランサは、透過的なネットワークゲートウェイと、トラフィックを分散し、仮想アプライアンスをオンデマンドで拡張するロードバランサを組み合わせます。ASA 仮想 は、Geneve インターフェイスのシングルアームプロキシを使用して分散データプレーン(ゲートウェイ ロード バランサ エンドポイント)を備えたゲートウェイロードバランサ集中型コントロールプレーンをサポートします。
-
シスコ クラウド サービス ルータなどの内部および外部ルータを使用した等コスト マルチパス ルーティング(ECMP)
ECMP ルーティングでは、ルーティング メトリックが同値で最高である複数の「最適パス」を介してパケットを転送できます。EtherChannel のように、送信元および宛先の IP アドレスや送信元および宛先のポートのハッシュを使用してネクスト ホップの 1 つにパケットを送信できます。ECMP ルーティングにスタティックルートを使用する場合は、ASA 仮想 の障害発生時に問題が起きることがあります。ルートは引き続き使用されるため、障害が発生した ASA 仮想 へのトラフィックが失われるからです。スタティック ルートを使用する場合は必ず、オブジェクト トラッキングなどのスタティック ルート モニタリング機能を使用してください。ダイナミック ルーティング プロトコルを使用してルートの追加と削除を行うことを推奨します。この場合は、ダイナミック ルーティングに参加するように各 ASA 仮想 を設定する必要があります。
(注)
レイヤ 2 スパンド EtherChannels はロードバランシングではサポートされません。
-
クラスタ ノード
クラスタノードは連携して動作し、セキュリティポリシーおよびトラフィックフローの共有を達成します。ここでは、各ノードのロールの特長について説明します。
ブートストラップ コンフィギュレーション
各デバイスで、最小限のブートストラップ コンフィギュレーション(クラスタ名、クラスタ制御リンク インターフェイスなどのクラスタ設定)を設定します。通常、クラスタリングを有効にする最初のノードが制御ノードになります。以降のノードに対してクラスタリングをイネーブルにすると、そのノードはデータノードとしてクラスタに参加します。
制御ノードとデータノードの役割
クラスタ内のメンバーの 1 つが制御ノードになります。複数のクラスタノードが同時にオンラインになる場合、制御ノードは、ブートストラップ コンフィギュレーション内のプライオリティ設定によって決まります。プライオリティは 1 ~ 100 の範囲内で設定され、1 が最高のプライオリティです。他のすべてのメンバーはデータノードです。一般的には、クラスタを作成した後で最初に追加したノードが制御ノードとなります。これは単に、その時点でクラスタに存在する唯一のノードであるからです。
すべてのコンフィギュレーション作業(ブートストラップ コンフィギュレーションを除く)は、制御ノード上のみで実行する必要があります。コンフィギュレーションは、データノードに複製されます。物理的アセット(たとえばインターフェイス)の場合は、制御ノードのコンフィギュレーションがすべてのデータノード上でミラーリングされます。たとえば、内部インターフェイスとしてイーサネット 1/2 を設定し、外部インターフェイスとしてイーサネット 1/1 を設定した場合、これらのインターフェイスは内部および外部インターフェイスとしてデータノードでも使用されます。
機能によっては、クラスタ内でスケーリングしないものがあり、そのような機能については制御ノードがすべてのトラフィックを処理します。
個々のインターフェイス
クラスターフェイスを個々のインターフェイスとして設定できます。
個別インターフェイスは通常のルーテッド インターフェイスであり、それぞれが専用のローカル IP アドレスを持ちます。インターフェイス構成は、制御ノードでのみ設定する必要があり、各インターフェイスは DHCP を使用します。
(注) |
レイヤ 2 スパンド EtherChannels はサポートされません。 |
クラスタ制御リンク
ノードごとに 1 つのインターフェイスをクラスタ制御リンク専用の VXLAN(VTEP)インターフェイスにする必要があります。
VXLAN トンネル エンドポイント
VXLAN トンネル エンドポイント(VTEP)デバイスは、VXLAN のカプセル化およびカプセル化解除を実行します。各 VTEP には 2 つのインターフェイスタイプ(VXLAN Network Identifier(VNI)インターフェイスと呼ばれる 1 つ以上の仮想インターフェイスと、 VTEP 間に VNI をトンネリングする VTEP 送信元インターフェイスと呼ばれる通常のインターフェイス)がありますVTEP 送信元インターフェイスは、VTEP 間通信のトランスポート IP ネットワークに接続されます。
VTEP 送信元インターフェイス
VTEP 送信元インターフェイスは、VNI インターフェイスに関連付けられる予定の標準の ASA Virtual インターフェイスです。1 つの VTEP ソースインターフェイスをクラスタ制御リンクとして機能するように設定できます。ソースインターフェイスは、クラスタ制御リンクの使用専用に予約されています。各 VTEP ソースインターフェイスには、同じサブネット上の IP アドレスがあります。このサブネットは、他のすべてのトラフィックからは隔離し、 クラスタ制御リンクインターフェイスだけが含まれるようにしてください。
VNI インターフェイス
VNI インターフェイスは VLAN インターフェイスに似ています。VNI インターフェイスは、タギングを使用して特定の物理インターフェイスでのネットワークトラフィックの分割を維持する仮想インターフェイスです。設定できる VNI インターフェイスは 1 つだけです。各 VNI インターフェイスは、同じサブネット上の IP アドレスを持ちます。
ピア VTEP
単一の VTEP ピアを許可するデータインターフェイス用の通常の VXLAN とは異なり、ASA Virtual クラスタリングでは複数のピアを設定できます。
クラスタ制御リンク トラフィックの概要
クラスタ制御リンク トラフィックには、制御とデータの両方のトラフィックが含まれます。
制御トラフィックには次のものが含まれます。
-
制御ノードの選択。
-
設定の複製。
-
ヘルス モニタリング。
データ トラフィックには次のものが含まれます。
-
状態の複製。
-
接続所有権クエリおよびデータ パケット転送。
クラスタ制御リンクの障害
ユニットのクラスタ制御リンク回線プロトコルがダウンした場合、クラスタリングはディセーブルになります。データ インターフェイスはシャット ダウンされます。クラスタ制御リンクの修復後、クラスタリングを再度イネーブルにして手動でクラスタに再参加する必要があります。
(注) |
ASA 仮想 が非アクティブになると、すべてのデータ インターフェイスがシャットダウンされます。管理専用インターフェイスのみがトラフィックを送受信できます。管理インターフェイスは、そのユニットが DHCP またはクラスタ IP プールから受け取った IP アドレスを使用して引き続き稼働状態となります。クラスタ IP プールを使用している場合、リロードしてもクラスタでユニットがまだ非アクティブになっていると、管理インターフェイスはアクセスできません(制御ノードと同じメイン IP アドレスを使用するため)。さらに設定を行う場合は、コンソールポート(使用可能な場合)を使用する必要があります。 |
コンフィギュレーションの複製
クラスタ内のすべてのノードは、単一の設定を共有します。設定の変更は制御ノードでのみ可能(ブートストラップ設定は除く)で、変更はクラスタに含まれる他のすべてのノードに自動的に同期されます。
ASA 仮想 クラスタの管理
ASA 仮想 クラスタリングを使用することの利点の 1 つは、管理のしやすさです。ここでは、クラスタを管理する方法について説明します。
管理ネットワーク
すべてのノードを単一の管理ネットワークに接続することを推奨します。このネットワークは、クラスタ制御リンクとは別のものです。
管理インターフェイス
管理用に、管理 0/0 インターフェイスを使用します。
(注) |
管理インターフェイスの動的ルーティングを有効にすることはできません。スタティック ルートを使用する必要があります。 |
管理 IP アドレスには、静的アドレスまたは DHCP を使用できます。
静的 IP アドレスを使用する場合は、常に現在の制御ノードに属するクラスタの固定アドレスであるメインクラスタ IP アドレスを使用できます。インターフェイスごとに、管理者はアドレス範囲も設定します。これで、各ノード(現在の制御ノードも含まれます)がその範囲内のローカルアドレスを使用できるようになります。このメインクラスタ IP アドレスによって、管理アクセスのアドレスが一本化されます。制御ノードが変更されると、メインクラスタ IP アドレスは新しい制御ノードに移動するので、クラスタの管理をシームレスに続行できます。ローカル IP アドレスは、ルーティングに使用され、トラブルシューティングにも役立ちます。たとえば、クラスタを管理するにはメインクラスタ IP アドレスに接続します。このアドレスは常に、現在の制御ノードに関連付けられています。個々のメンバを管理するには、ローカル IP アドレスに接続します。TFTP や syslog などの発信管理トラフィックの場合、制御ノードを含む各ノードは、ローカル IP アドレスを使用してサーバーに接続します。
DHCP を使用する場合、ローカルアドレスのプールを使用したり、メインクラスタの IP アドレスを使用したりしません。
制御ノードの管理対データノードの管理
すべての管理とモニタリングは制御ノードで実行できます。制御ノードから、すべてのノードのランタイム統計情報、リソース使用状況、その他のモニタリング情報を確認できます。また、クラスタ内のすべてのノードに対してコマンドを発行したり、コンソールメッセージをデータノードから制御ノードに複製したりできます。
必要に応じて、データノードを直接モニタできます。制御ノードからも可能ですが、ファイル管理(設定のバックアップやイメージの更新など)をデータノード上で実行できます。次の機能は、制御ノードからは使用できません。
-
ノードごとのクラスタ固有統計情報のモニタリング。
-
ノードごとの Syslog モニタリング(コンソールレプリケーションが有効な場合にコンソールに送信される Syslog を除く)。
-
SNMP
-
NetFlow
暗号キー複製
制御ノード上で暗号キーを作成すると、そのキーはすべてのデータノードに複製されます。メインクラスタ IP アドレスへの SSH セッションがある場合、制御ノードで障害が発生すると接続が切断されます。新しい制御ノードでは、SSH 接続に対して同じキーが使用されるため、新しい制御ノードに再接続するときに、キャッシュ済みの SSH ホストキーを更新する必要はありません。
ASDM 接続証明書 IP アドレス不一致
デフォルトでは、自己署名証明書は、ローカル IP アドレスに基づいて ASDM 接続に使用されます。ASDM を使用してメインクラスタ IP アドレスに接続すると、IP アドレス不一致に関する警告メッセージが表示される場合があります。これは、証明書で使用されているのがローカル IP アドレスであり、メインクラスタ IP アドレスではないためです。このメッセージは無視して、ASDM 接続を確立できます。ただし、この種の警告を回避するには、新しい証明書を登録し、この中でメイン クラスタ IP アドレスと、IP アドレス プールからのすべてのローカル IP アドレスを指定します。この証明書を各クラスタ メンバに使用します。詳細については、「https://www.cisco.com/c/en/us/td/docs/security/asdm/identity-cert/cert-install.html」を参照してください。
ASA Virtual クラスタリングのライセンス
各クラスタノードには、同じモデルライセンスが必要です。すべてのノードに同じ数の CPU とメモリを使用することをお勧めします。そうしないと、パフォーマンスが最小能力のメンバーに一致するようにすべてのノードで制限されます。スループットレベルは、一致するように制御ノードから各データノードに複製されます。
(注) |
ASA 仮想 を登録解除してライセンスを解除した場合、ASA 仮想 をリロードすると、重大なレート制限状態に戻ります。ライセンスのない、パフォーマンスの低いクラスタノードは、クラスタ全体のパフォーマンスに悪影響を及ぼします。すべてのクラスタノードのライセンスを保持するか、ライセンスのないノードを削除してください。 |
ASA Virtual クラスタリングの要件と前提条件
モデルの要件
-
ASAv30、ASAv50、ASAv100
-
以下のパブリッククラウドサービス:
-
Amazon Web Services(AWS)
-
Microsoft Azure
-
-
最大 16 ノード
『ASA Virtual Getting Started Guide』の ASA virtual の一般的な要件も参照してください。
ハードウェアおよびソフトウェアの要件
クラスタ内のすべてのノード:
-
同じパフォーマンス層である必要があります。すべてのノードに同じ数の CPU とメモリを使用することをお勧めします。そうしないと、パフォーマンスが最小能力のノードに一致するようにすべてのノードで制限されます。
-
イメージ アップグレード時を除き、同じソフトウェアを実行する必要があります。ヒットレス アップグレードがサポートされます。ソフトウェアバージョンが一致しないとパフォーマンスが低下する可能性があるため、すべてのノードを同じメンテナンス期間でアップグレードするようにしてください。
-
単一の可用性ゾーンの展開がサポートされています。
-
クラスタ制御リンクのインターフェイスは同じサブネット内に配置される必要があるため、クラスタは同じサブネットに展開する必要があります。
MTU
クラスタ制御リンクに接続されているポートに適切な MTU 値(高い値) が設定されていること。MTU の不一致がある場合、クラスタの形成に失敗します。クラスタ制御リンクの MTU は、データインターフェイスよりも 154 バイト大きく設定されているはずです。クラスタ制御リンクのトラフィックにはデータパケット転送が含まれるため、クラスタ制御リンクはデータパケット全体のサイズに加えてクラスタトラフィックのオーバーヘッド(100 バイト)と VXLAN のオーバーヘッド(54 バイト)にも対応する必要があります。
GWLB を使用する AWS の場合、データインターフェイスは Geneve カプセル化を使用します。この場合、イーサネット データグラム全体がカプセル化されるため、新しいパケットのサイズが大きくなるため、より大きな MTU が必要になります。送信元インターフェイス MTU をネットワーク MTU + 306 バイトに設定する必要があります。したがって、標準の 1500 MTU ネットワークパスの場合、送信元インターフェイスの MTU は 1806 であり、クラスタ制御リンクの MTU は +154 の 1960 である必要があります。
GWLB を使用する Azure の場合、データインターフェイスは VXLAN カプセル化を使用します。この場合、イーサネット データグラム全体がカプセル化されるため、新しいパケットのサイズが大きくなるため、より大きな MTU が必要になります。送信元インターフェイス MTU をネットワーク MTU + 54 バイトに設定する必要があります。
次の表は、推奨されるクラスタ制御リンク MTU とデータインターフェイス MTU を示しています。
|
パブリック クラウド |
クラスタ制御リンク MTU |
データインターフェイス MTU |
|---|---|---|
|
GWLB を使用した AWS |
1960 |
1806 |
|
AWS |
1654 |
1500 |
|
GWLB を使用した Azure |
1554 |
1454 |
|
Azure |
1554 |
1400 |
ASA Virtual クラスタリングのガイドライン
ハイ アベイラビリティ
クラスタリングでは、高可用性はサポートされません。
IPv6
クラスタ制御リンクは、IPv4 のみを使用してサポートされます。
その他のガイドライン
-
大々的なトポロジ変更が発生する場合(EtherChannel インターフェイスの追加または削除、ASA virtual 上でのインターフェイスまたはスイッチの有効化または無効化、冗長スイッチシステムを形成するための追加スイッチの追加など)、ヘルスチェック機能や無効なインターフェイスに対するインターフェイス モニタリングを無効にする必要があります。トポロジの変更が完了して、コンフィギュレーション変更がすべてのユニットに同期されたら、インターフェイスのヘルス チェック機能を再度有効にできます。
-
ノードを既存のクラスタに追加したときや、ノードをリロードしたときは、一時的に、限定的なパケット/接続ドロップが発生します。これは予定どおりの動作です。場合によっては、ドロップされたパケットが原因で接続がハングすることがあります。たとえば、FTP 接続の FIN/ACK パケットがドロップされると、FTP クライアントがハングします。この場合は、FTP 接続を再確立する必要があります。
-
復号された TLS/SSL 接続の場合、復号状態は同期されず、接続オーナーに障害が発生すると、復号された接続がリセットされます。新規ノードへの接続を新たに確立する必要があります。復号されていない接続(復号しないルールに一致)は影響を受けず、正しく複製されます。
-
ダイナミックスケーリングはサポートされていません。
-
各メンテナンスウィンドウの完了後にグローバル展開を実行します。
-
自動スケールグループ(AWS)やスケールセット(Azure)から一度に複数のデバイスを削除しないでください。また、自動スケールグループ(AWS)やスケールセット(Azure)からデバイスを削除する前に、デバイスで cluster disable コマンドを実行することを推奨します。
-
クラスタ内のデータノードと制御ノードを無効にする場合は、制御ノードを無効にする前にデータノードを無効にすることを推奨します。クラスタ内に他のデータノードがあるときに制御ノードが無効になっている場合は、いずれかのデータノードを制御ノードに昇格させる必要があります。ロールの変更はクラスタを妨害する可能性があることに注意してください。
-
このガイドに記載されている Day 0 構成スクリプトでは、要件に応じて IP アドレスを変更し、カスタムインターフェイス名を指定して、CCL-Link インターフェイスのシーケンスを変更することができます。
クラスタリングのデフォルト
-
cLACP システム ID は自動生成され、システムの優先順位はデフォルトでは 1 になっています。
-
クラスタのヘルス チェック機能は、デフォルトで有効になり、ホールド時間は 3 秒です。デフォルトでは、すべてのインターフェイスでインターネット ヘルス モニタリングが有効になっています。
-
失敗したクラスタ制御リンクのクラスタ再結合機能が 5 分おきに無制限に試行されます。
-
失敗したデータインターフェイスのクラスタ自動再結合機能は、5 分後と、2 に設定された増加間隔で合計で 3 回試行されます。
-
HTTP トラフィックでは、5 秒間の接続複製遅延がデフォルトで有効になっています。
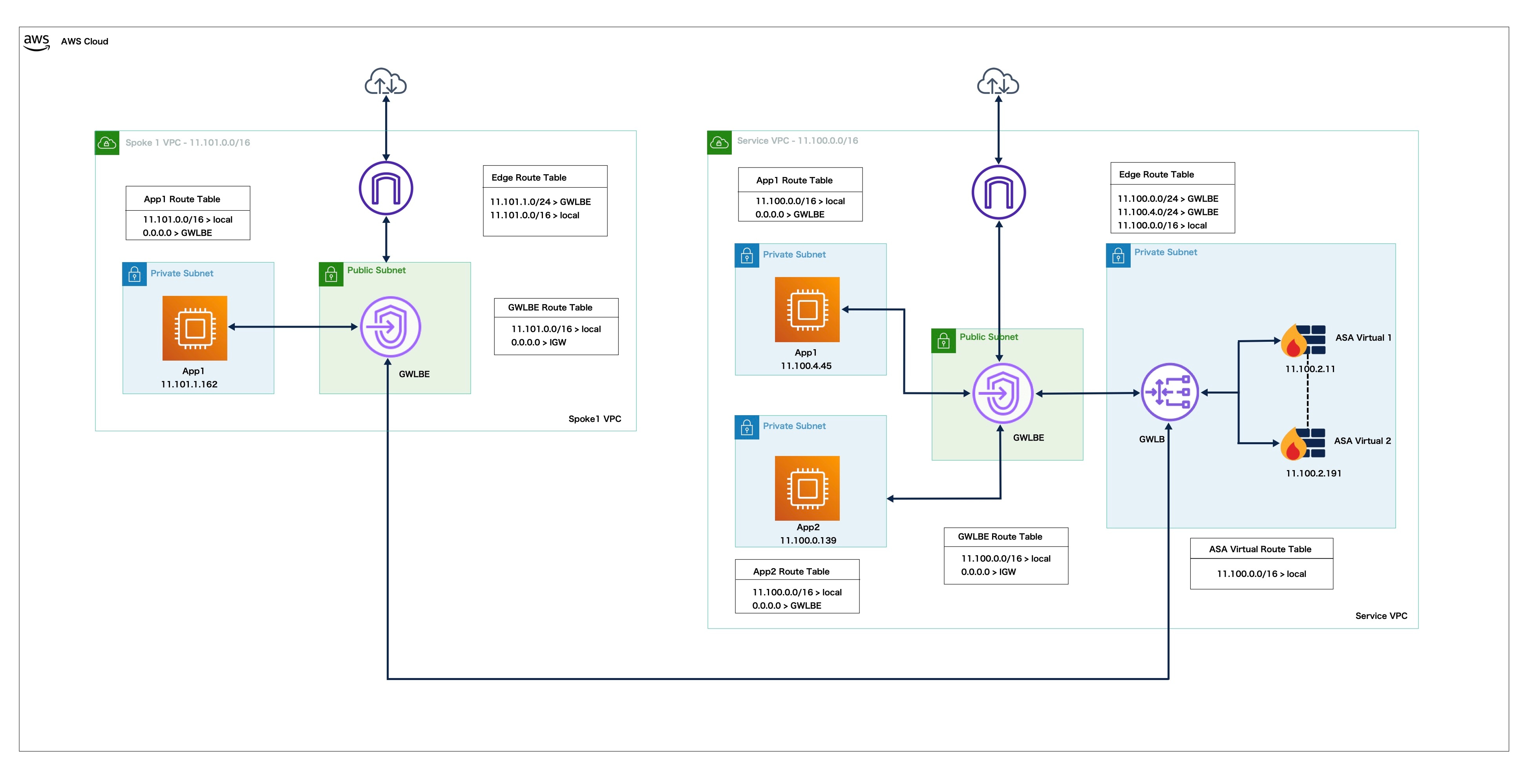
AWS でクラスタを展開する
AWS にクラスタを展開する場合、手動で展開するか、スタックを展開する CloudFormation テンプレートを使用できます。AWS ゲートウェイロードバランサ、または Cisco Cloud Services Router などの非ネイティブのロード バランサでクラスタを使用できます。
AWS ゲートウェイロードバランサおよび Geneve シングルアームプロキシ
(注) |
この使用例は、現在サポートされている Geneve インターフェイスの唯一の使用例です。 |
AWS ゲートウェイロードバランサは、透過的なネットワークゲートウェイと、トラフィックを分散し、仮想アプライアンスをオンデマンドで拡張するロードバランサを組み合わせます。ASA Virtual は、分散データプレーン(ゲートウェイ ロード バランサ エンドポイント)を備えたゲートウェイロードバランサ集中型コントロールプレーンをサポートします。次の図は、ゲートウェイロードバランサのエンドポイントからゲートウェイロードバランサに転送されるトラフィックを示しています。ゲートウェイロードバランサは、複数の ASA Virtual の間でトラフィックのバランスをとり、トラフィックをドロップするか、ゲートウェイロードバランサに送り返す(U ターントラフィック)前に検査します。ゲートウェイロードバランサは、トラフィックをゲートウェイロードバランサのエンドポイントと宛先に送り返します。
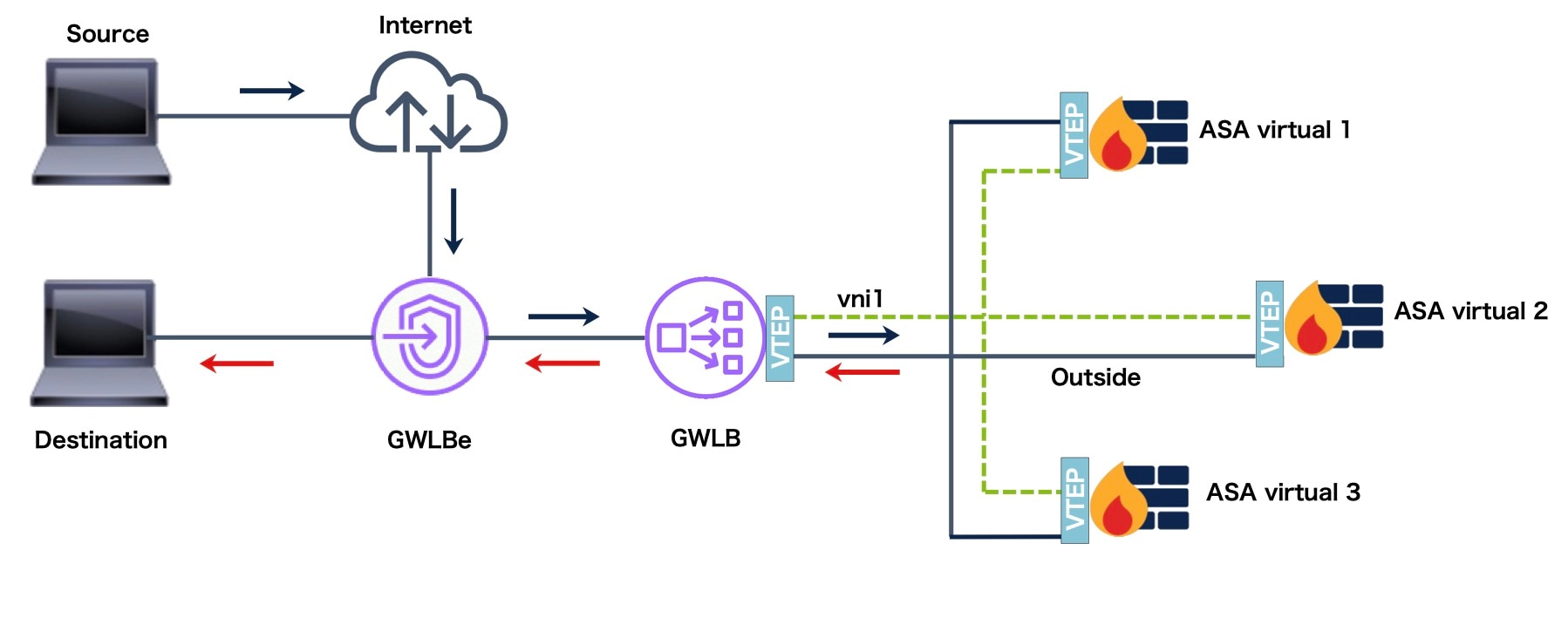
トポロジの例
次に示すトポロジは、着信と発信の両方のトラフィックフローを示しています。GWLB に接続されているクラスタには、2 つの ASA Virtual インスタンスがあります。
インターネットからの着信トラフィックは、GWLB エンドポイントに送られ、そこから GWLB にトラフィックが送信されます。その後、トラフィックは ASA Virtual クラスタに転送されます。トラフィックは、クラスタ内の ASA Virtual インスタンスによって検査された後、アプリケーション VM App1 に転送されます。
App1 からの発信トラフィックは、GWLB エンドポイントに送信され、そこからインターネットに送信されます。
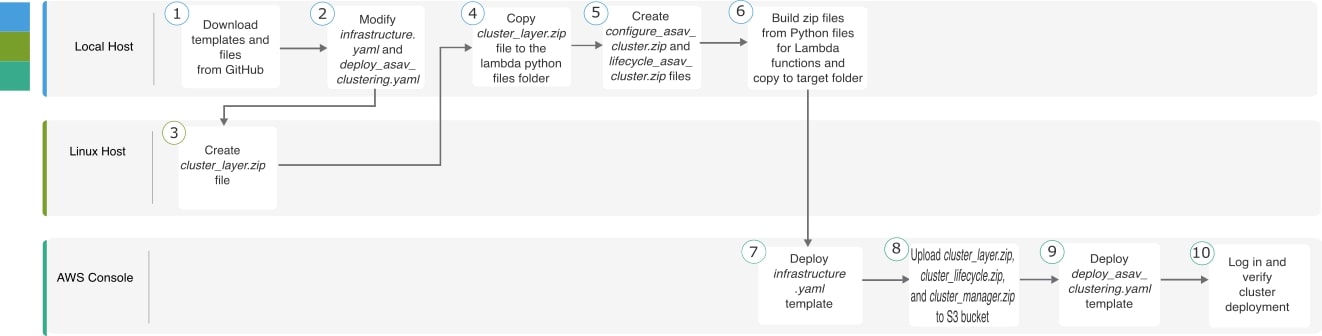
AWS で ASA Virtual クラスタを展開するためのエンドツーエンドのプロセス
テンプレートベースの展開
次のフローチャートは、AWS での ASA Virtual クラスタのテンプレートベース展開のワークフローを示しています。
手動展開
次のフローチャートは、AWS での ASA Virtual クラスタの手動展開のワークフローを示しています。
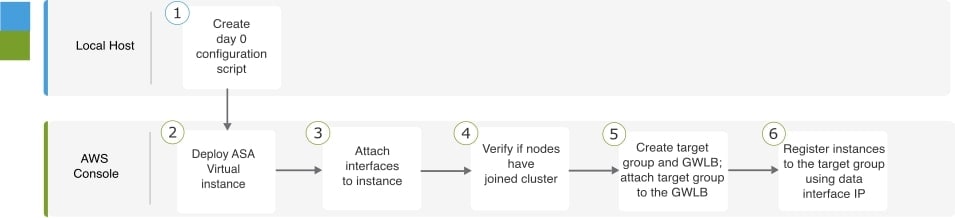
|
ワークスペース |
手順 |
|
|---|---|---|
| ローカルホスト | Day 0 構成スクリプトを作成します。 | |
| AWS コンソール | ASA virtual インスタンスを展開します。 | |
| AWS コンソール | インスタンスにインターフェイスを接続します。 | |
| AWS コンソール | ノードがクラスタに参加しているかどうかを確認します。 | |
| AWS コンソール | ターゲットグループと GWLB を作成します。ターゲットグループを GWLB に割り当てます。 | |
| AWS コンソール | データインターフェイス IP を使用してターゲットグループにインスタンスを登録します。 |
テンプレート
以下のテンプレートは GitHub で入手できます。パラメータ値は、テンプレートで指定されたパラメータ名、デフォルト値、使用可能な値、および説明により自明です。
-
infrastructure.yaml:インフラストラクチャ展開用のテンプレート。
-
deploy_asav_clustering.yaml:クラスタ展開用のテンプレート。
(注) |
クラスタノードを展開する前に、サポートされている AWS インスタンスタイプのリストを確認してください。このリストは、deploy_asav_clustering.yaml テンプレートのパラメータ InstanceType に使用可能な値の下にあります。 |
AWS における GWLB を使用した ASA 仮想 クラスタリングのターゲットフェールオーバーの設定
AWS の ASA virtual クラスタリングは、ゲートウェイロードバランサ(GWLB)を使用して、指定された ASA virtual ノードにインスペクション用のネットワークパケットをバランシングおよび転送します。GWLB は、ターゲットノードのフェールオーバーまたは登録解除が発生した場合に、ターゲットノードにネットワークパケットを送信し続けるように設計されています。
AWS でターゲットフェールオーバー機能を使用すると、計画メンテナンス中またはターゲットノードの障害時にノードの登録が解除された場合に、GWLB がネットワークパケットを正常なターゲットノードにリダイレクトできるようになります。この機能ではクラスタのステートフル フェールオーバーを利用しています。
(注) |
GWLB が SSH、SCP、CURL、またはその他のプロトコルを使用してトラフィックをルーティングしている間にターゲットノードに障害が発生した場合、正常なターゲットへのトラフィックのリダイレクトに遅延が発生する可能性があります。この遅延は、トラフィックフローの再調整と再ルーティングが原因で発生します。 |
AWS では、AWS ELB API または AWS コンソールを介してターゲットフェールオーバーを設定できます。
-
AWS API(AWS Elastic Load Balancing(ELB)API 内)の modify-target-group-attributes で、次の 2 つの新しいパラメータを変更することにより、フロー処理の動作を定義できます。
-
target_failover.on_unhealthy:ターゲットが正常でなくなった場合に GWLB がネットワークフローをどのように処理するかを定義します。
-
target_failover.on_deregistration:ターゲットが登録解除された場合に GWLB がネットワークフローをどのように処理するかを定義します。
次のコマンドは、これら 2 つのパラメータを定義するサンプルの API パラメータ設定を示しています。
aws elbv2 modify-target-group-attributes \ --target-group-arn arn:aws:elasticloadbalancing:…/my-targets/73e2d6bc24d8a067 \ --attributes \ Key=target_failover.on_unhealthy, Value=rebalance[no_rebalance] \ Key=target_failover.on_deregistration, Value=rebalance[no_rebalance]詳細については、AWS のマニュアルの「TargetGroupAttribute」を参照してください。
-
-
AWS コンソール:EC2 コンソールでは、次のオプションを設定することにより、[ターゲットグループ(Target Group)] ページの [ターゲットフェールオーバー(Target Failover)] オプションを有効にすることができます。
-
ターゲットグループの属性を編集する
-
ターゲットフェールオーバーを有効にする
-
再調整フローを確認する
ターゲットフェールオーバーを有効にする方法の詳細については、「ターゲットフェールオーバー機能を有効にする」を参照してください。
-
CloudFormation テンプレートを使用した AWS へのスタックの展開
CloudFormation テンプレートを使用して AWS にスタックを展開します。
始める前に
-
Python 3 をインストールした Linux コンピューターが必要です。
手順
|
ステップ 1 |
テンプレートを準備します。 |
|
ステップ 2 |
Infrastructure.yaml を展開し、クラスタ展開の出力値をメモします。
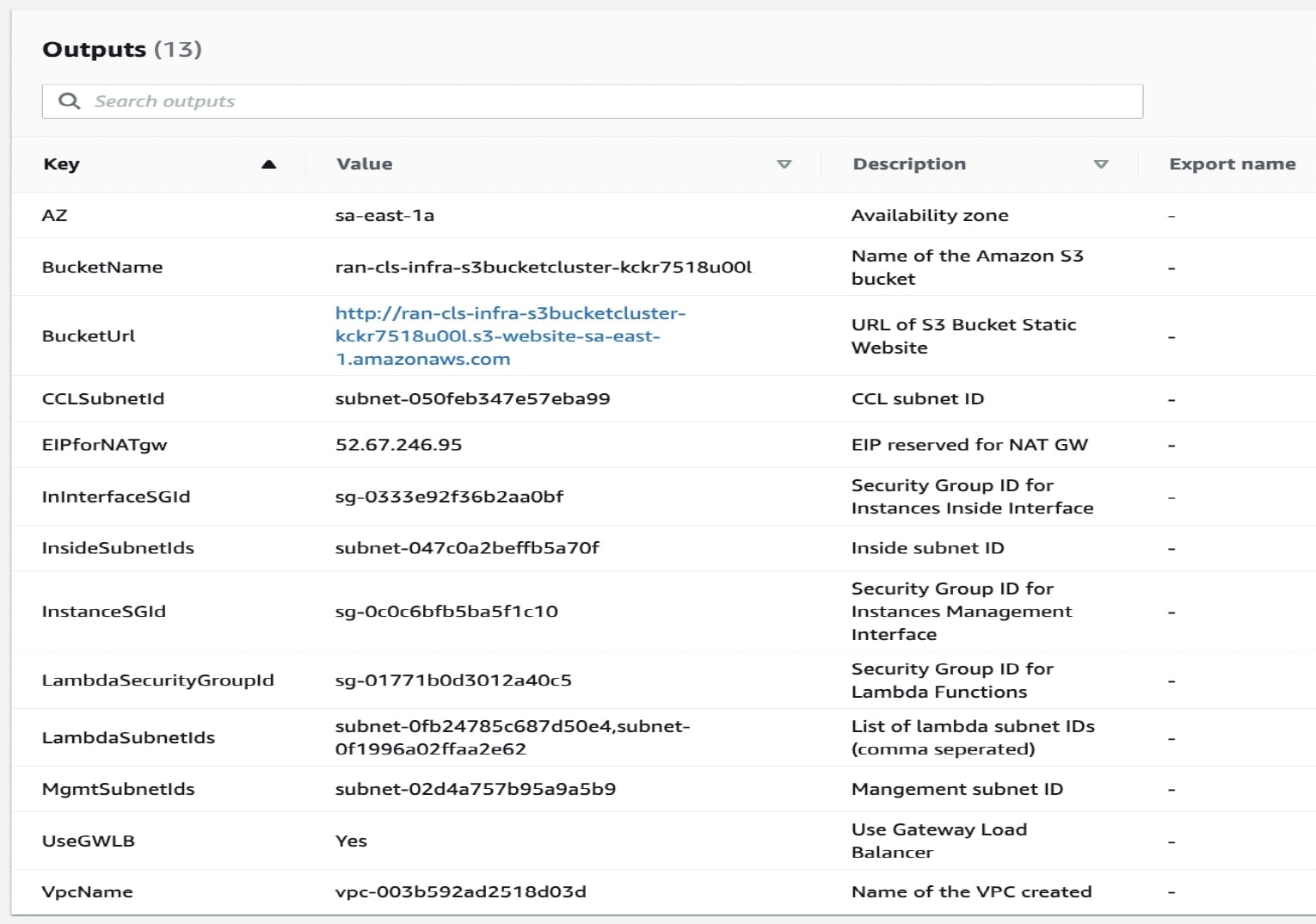
|
|
ステップ 3 |
cluster_layer.zip、cluster_lifecycle.zip、および cluster_manager.zip を infrastructure.yaml で作成した S3 バケットにアップロードします。 |
|
ステップ 4 |
deploy_asav_clustering.yaml を展開します。
|
|
ステップ 5 |
いずれかのノードにログインし、show cluster info コマンドを入力して、クラスタの展開を確認します。 |
AWS でのクラスタの手動展開
クラスタを手動で展開するには、day0 構成を準備し、各ノードを展開します。
AWS 向け Day 0 構成の作成
以下のコマンドを使用して各クラスタノードのブートストラップ設定を指定します。
ゲートウェイロードバランサの例
次の実行コンフィギュレーションの例では、U ターントラフィック用の 1 つの Geneve インターフェイスと、クラスタ制御リンク用の 1 つの VXLAN インターフェイスを備えたゲートウェイロードバランサの構成を作成します。
cluster interface-mode individual force
policy-map global_policy
class inspection_default
no inspect h323 h225
no inspect h323 ras
no inspect rtsp
no inspect skinny
int m0/0
management-only
nameif management
security-level 100
ip address dhcp setroute
no shut
interface TenGigabitEthernet0/0
nameif geneve-vtep-ifc
security-level 0
ip address dhcp
no shutdown
interface TenGigabitEthernet0/1
nve-only cluster
nameif ccl_link
security-level 0
ip address dhcp
no shutdown
interface vni1
description Clustering Interface
segment-id 1
vtep-nve 1
interface vni2
proxy single-arm
nameif ge
security-level 0
vtep-nve 2
object network ccl_link
range 10.1.90.4 10.1.90.254 //Mandatory user input, use same range on all nodes
object-group network cluster_group
network-object object ccl_link
nve 2
encapsulation geneve
source-interface geneve-vtep-ifc
nve 1
encapsulation vxlan
source-interface ccl_link
peer-group cluster_group
cluster group asav-cluster // Mandatory user input, use same cluster name on all nodes
local-unit 1 //Value in bold here must be unique to each node
cluster-interface vni1 ip 1.1.1.1 255.255.255.0 //Value in bold here must be unique to each node
priority 1
enable noconfirm
mtu geneve-vtep-ifc 1806
mtu ccl_link 1960
aaa authentication listener http geneve-vtep-ifc port 7575 //Use same port number on all nodes
jumbo-frame reservation
wr mem(注) |
AWS ヘルスチェックの設定では、ここで設定した aaa authentication listener http ポートを必ず指定してください。 |
非ネイティブロードバランサの例
次の例では、管理、内部、および外部インターフェイスと、クラスタ制御リンク用の VXLAN インターフェイスを使用して、非ネイティブロードバランサ用の構成を作成します。
cluster interface-mode individual force
interface Management0/0
management-only
nameif management
ip address dhcp
interface GigabitEthernet0/0
no shutdown
nameif outside
ip address dhcp
interface GigabitEthernet0/1
no shutdown
nameif inside
ip address dhcp
interface GigabitEthernet0/2
nve-only cluster
nameif ccl_link
ip address dhcp
no shutdown
interface vni1
description Clustering Interface
segment-id 1
vtep-nve 1
jumbo-frame reservation
mtu ccl_link 1654
object network ccl_link
range 10.1.90.4 10.1.90.254 //mandatory user input
object-group network cluster_group
network-object object ccl_link
nve 1
encapsulation vxlan
source-interface ccl_link
peer-group cluster_group
cluster group asav-cluster //mandatory user input
local-unit 1 //mandatory user input
cluster-interface vni1 ip 10.1.1.1 255.255.255.0 //mandatory user input
priority 1
enable(注) |
上記の設定をコピーして貼り付ける場合は、設定から //mandatory user input を必ず削除してください。 |
クラスタノードの展開
クラスタを形成するためにクラスタノードを展開します。
手順
|
ステップ 1 |
必要な数のインターフェイス(ゲートウェイロードバランサ(GWLB)を使用している場合は 3 つのインターフェイス、非ネイティブロードバランサを使用している場合は 4 つのインターフェイス)でクラスタの Day 0 構成を使用することにより、ASA Virtual インスタンスを展開します。これを行うには、[インスタンスの詳細設定(Configure Instance Details)] > [高度な詳細(Advanced Details)] セクションで、クラスタの Day 0 構成に貼り付けます。
AWS での ASA Virtual の展開の詳細については、「Deploy the ASA Virtual on AWS」を参照してください。 |
||
|
ステップ 2 |
ステップ 1 を繰り返して、必要な数の追加ノードを展開します。 |
||
|
ステップ 3 |
ASA Virtual コンソールで show cluster info コマンドを使用して、すべてのノードがクラスタに正常に参加したかどうかを確認します。 |
||
|
ステップ 4 |
AWS ゲートウェイロードバランサを設定します。 |
AWS での ASA virtual のターゲットフェールオーバーの有効化
ASA virtual のデータインターフェイスは、AWS の GWLB のターゲットグループに登録されます。ASA virtual クラスタリングでは、各インスタンスはターゲットグループに関連付けられています。GWLB は、ターゲットグループのターゲットノードとして識別または登録されているこの正常なインスタンスにトラフィックを負荷分散して送信します。
始める前に
手動で、または CloudFormation テンプレートを使用して、AWS で ASA virtual スタックを展開している必要があります。
CloudFormation テンプレートを使用してクラスタを展開する場合、クラスタ展開ファイル deploy_asav_clustering.yaml の [GWLBの設定(GWLB Configuration)] セクションで使用可能な [再調整(rebalance)] 属性を割り当てることにより、[ターゲットフェールオーバー(Target Failover)] のパラメータを有効にすることもできます。テンプレートでは、このパラメータの値はデフォルトで [再調整(rebalance)] に設定されています。ただし、AWS コンソールでは、このパラメータのデフォルト値は [再調整なし(no_rebalance)] に設定されています。
それぞれの説明は次のとおりです。
-
再調整なし(no_rebalance):GWLB は、機能していないターゲットまたは登録解除されたターゲットにネットワークフローを送信し続けます。
-
再調整(rebalance):既存のターゲットが機能していないか登録解除された場合、GWLB はネットワークフローを別の正常なターゲットに送信します。
AWS でのスタックの展開については、以下を参照してください。
手順
|
ステップ 1 |
AWS コンソールで、[サービス(Services)] > [EC2] に移動します。 |
|
ステップ 2 |
[ターゲットグループ(Target Groups)] をクリックして、ターゲットグループのページを表示します。 |
|
ステップ 3 |
ASA virtual インスタンスの IP アドレスが登録されているターゲットグループを選択して開きます。ターゲットグループの詳細ページが表示されます。 |
|
ステップ 4 |
[属性(Attributes)] メニューに移動します。 |
|
ステップ 5 |
[編集(Edit)] をクリックして属性を編集します。 |
|
ステップ 6 |
[フローの再調整(Rebalance Flows)] スライダボタンを右に切り替えます。これによりターゲットフェールオーバーが有効になり、ターゲットフェールオーバーや登録解除の際に既存のネットワークパケットを再調整して正常なターゲットノードに転送するように GWLB が設定されます。 |
Azure でクラスタを展開する
Azure サービスチェーンでは、ASA virtual がインターネットと顧客サービス間のパケットをインターセプトできる透過的なゲートウェイとして機能します。Azure での ASA virtual インスタンスのクラスタリングは、単一のデバイスとして抽象化することにより、マルチノード ASAv のスループットをスケールアップするのに役立ちます。
ASAv は、2 つの論理インターフェイスで構成されています。インターネットに向けた外部インターフェイスと、顧客サービスに向けた内部インターフェイスです。これらのインターフェイスは、ペアリングされたプロキシで VXLAN セグメントを利用することにより、ASAv の単一のネットワーク インターフェイス カード(NIC)で定義されます。
Azure Gateway Load Balancer について
Azure Gateway Load Balancer(GWLB)は、トラフィック検査のために VXLAN セグメントを介して ASAv にルーティングすることにより、着信トラフィックと発信トラフィックのバランスを取り、管理するのに役立ちます。ASAv クラスタ環境では、Azure GWLB はトラフィックの負荷に応じて ASAv ノードのスループットレベルを自動的にスケールアップします。GWLB を使用すると、ルートを手動で更新することなく、ネットワーク仮想アプライアンスへの対称フローまたは一貫性のあるルートを確保できます。この機能により、パケットは同じネットワークパスを双方向で通過できます。
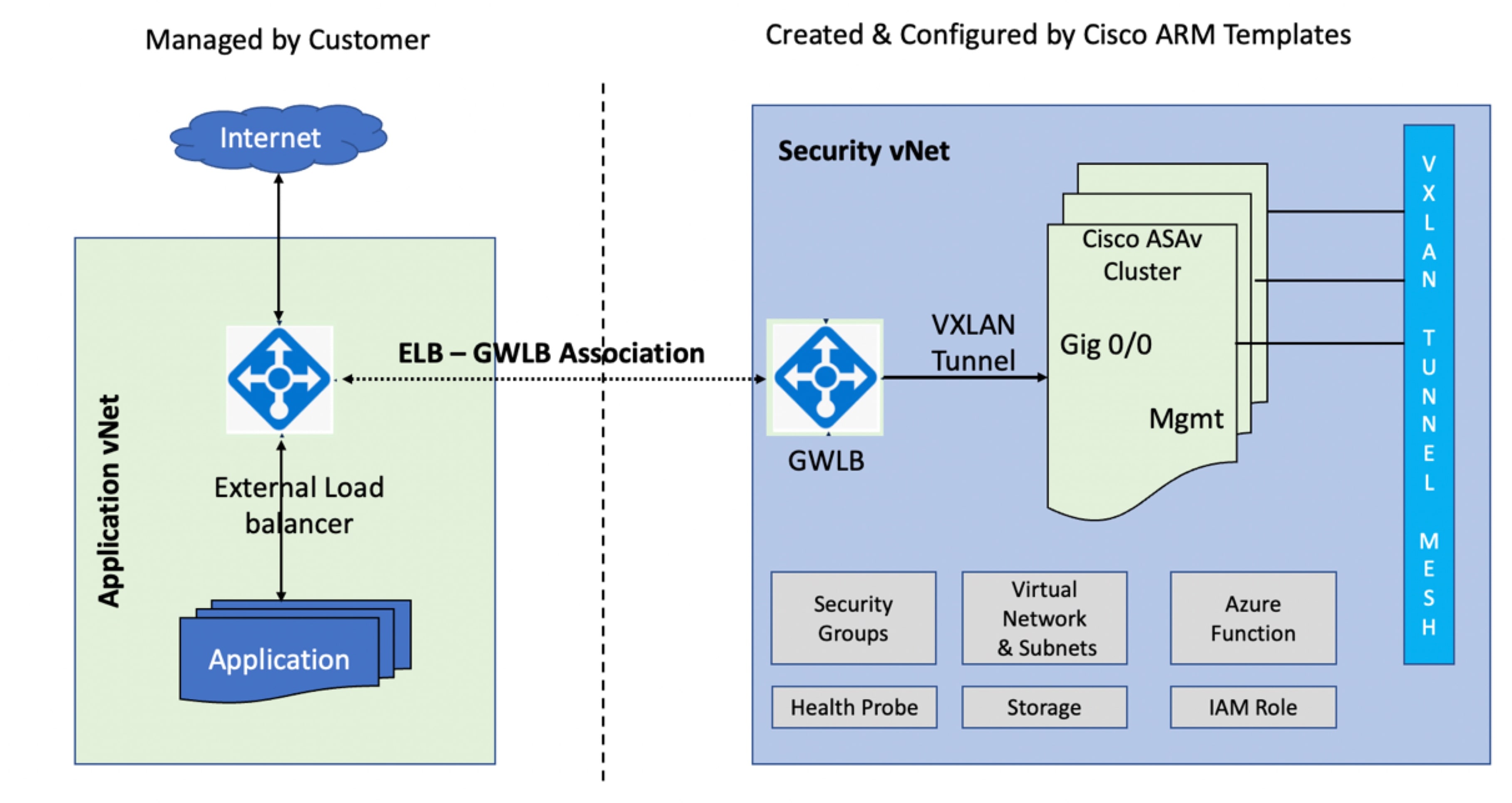
次の図は、外部 VXLAN セグメント上のパブリック ゲートウェイ ロードバランサから Azure GWLB に転送されるトラフィックを示しています。ゲートウェイロードバランサは、まず複数の ASAv の間でトラフィックのバランスを取り、トラフィックをドロップするか、内部の VXLAN セグメント上の GWLB に送り返す前に検査します。Azure GWLB は、トラフィックをパブリック ゲートウェイ ロードバランサと宛先に送り返します。
次の図は、Azure の GWLB と ASAv 間のネットワークフローを示しています。
Azure でのクラスタ展開について
カスタマイズされた Azure Resource Manager(ARM)テンプレートを使用して、Azure GWLB の仮想マシンスケールセットを展開できます。
クラスタ展開の後、デイゼロ設定を使用して、または Azure portal の Function アプリを介して、クラスタ上の各ノードを手動で設定できます。
Azure Resource Manager テンプレートを使用したクラスタの展開
Azure Resource Manager(ARM)テンプレートを使用してクラスタを形成するようにクラスタノード(仮想マシンスケールセット)を展開します。
始める前に
-
Azure クラスタを手動で作成するには、デイゼロ設定で構成テキストファイルを準備する必要があります。「Prepare Configuration File for Cluster deployment on Azure」を参照してください。
手順
|
ステップ 1 |
テンプレートを準備します。
|
|
ステップ 2 |
Azure ポータル:https://portal.azure.com にログインします。 |
|
ステップ 3 |
リソースグループを作成します。  |
|
ステップ 4 |
ASAv クラスタの管理、外部、およびクラスタ制御リンク(CCL)の 3 つのサブネットを持つ仮想ネットワークを作成します。 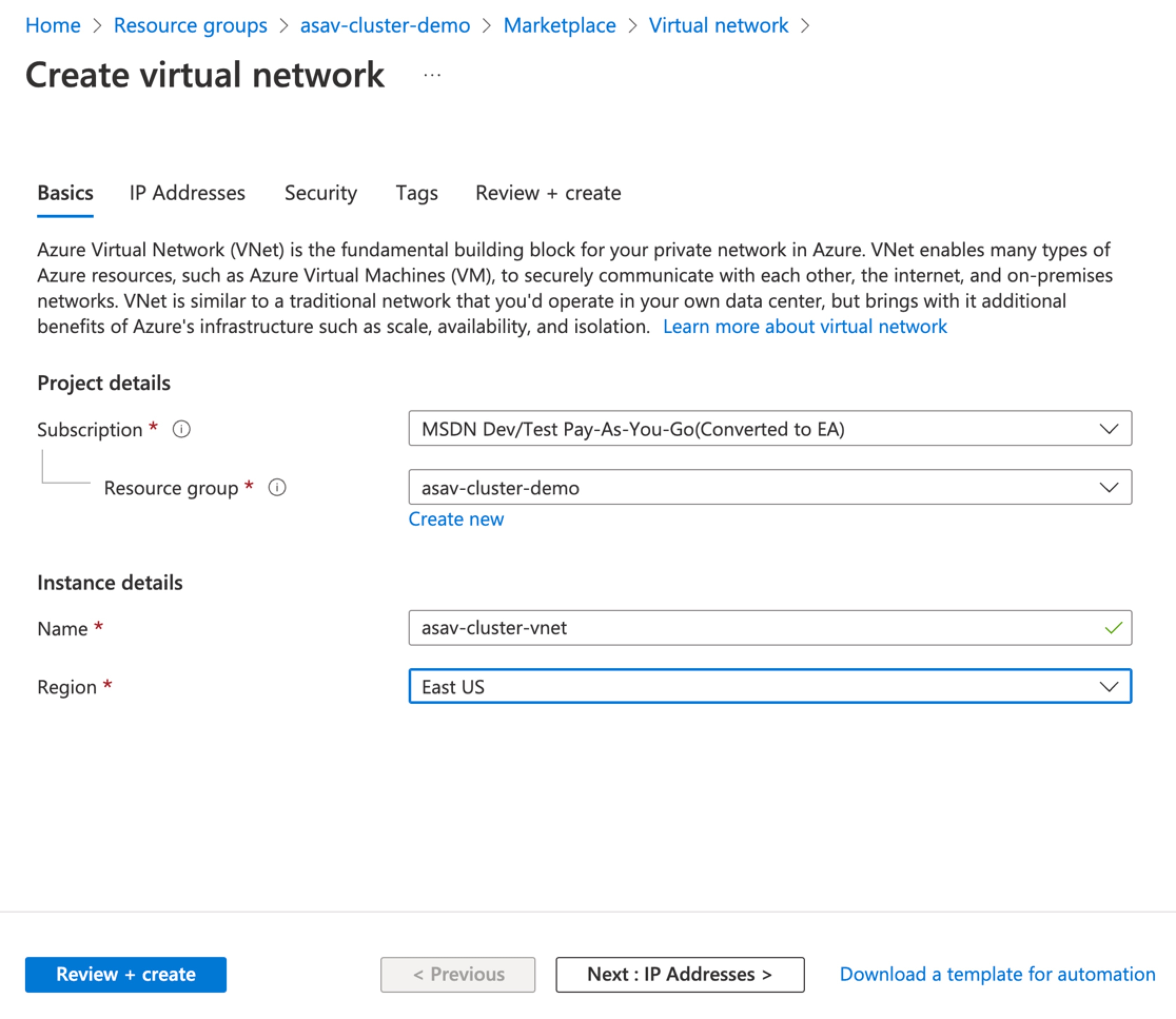 |
|
ステップ 5 |
サブネットを追加します。 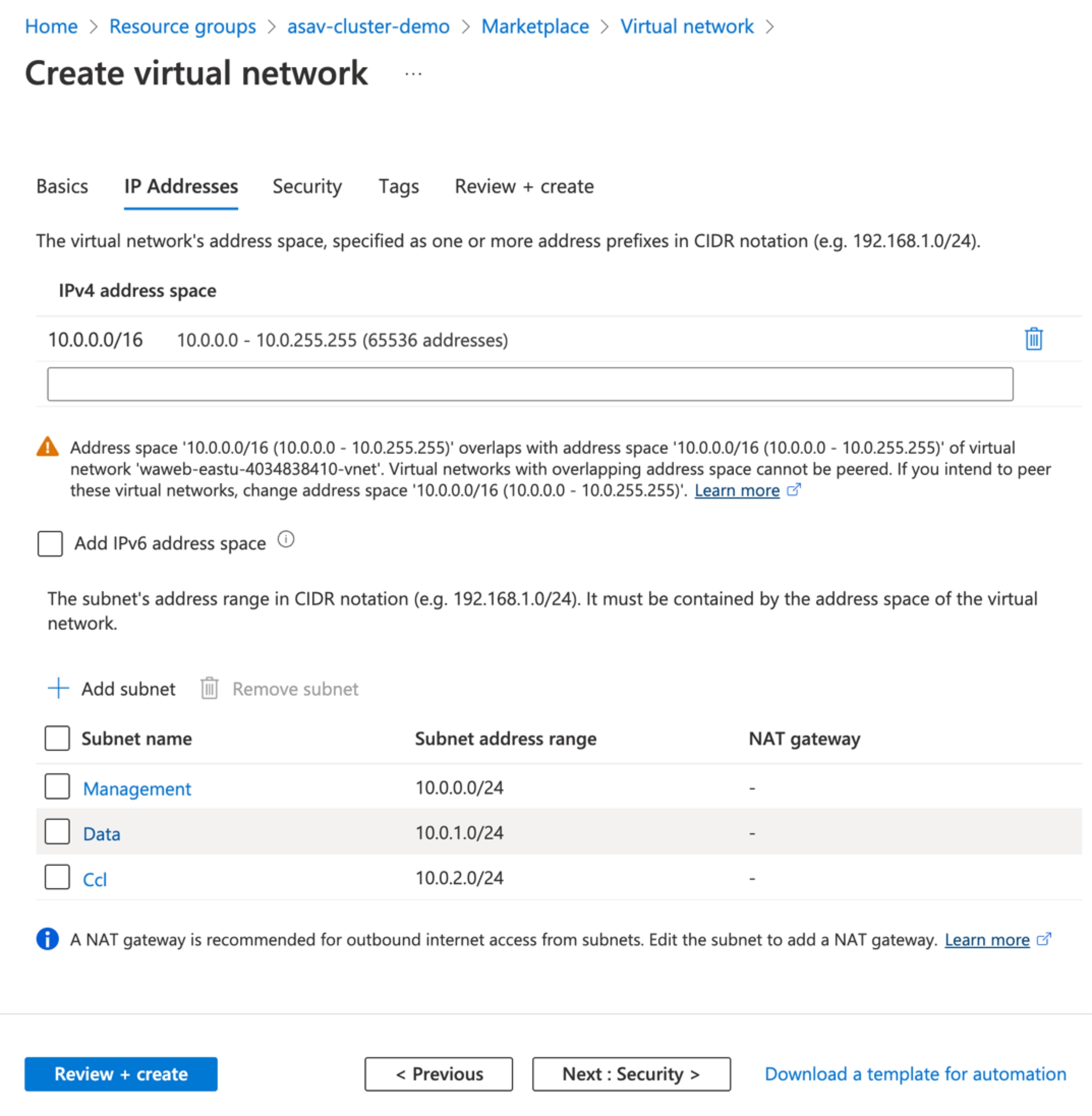 |
|
ステップ 6 |
カスタムテンプレートを展開します。
|
|
ステップ 7 |
インスタンスの詳細を設定します。 |
|
ステップ 8 |
必要な値を入力し、[確認して作成(Review + create)] をクリックします。 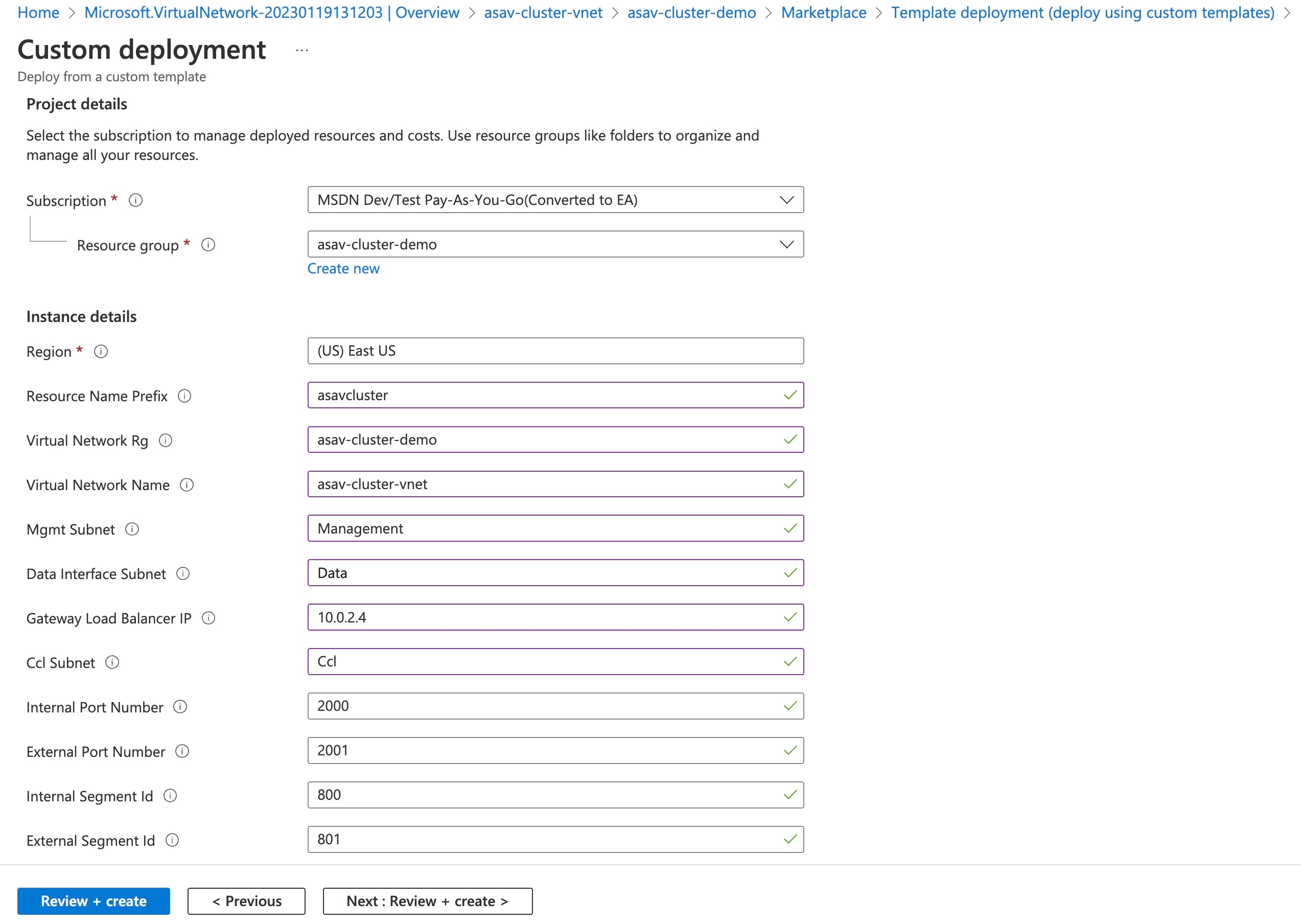 |
|
ステップ 9 |
検証に合格したら、[作成(Create)] をクリックします。 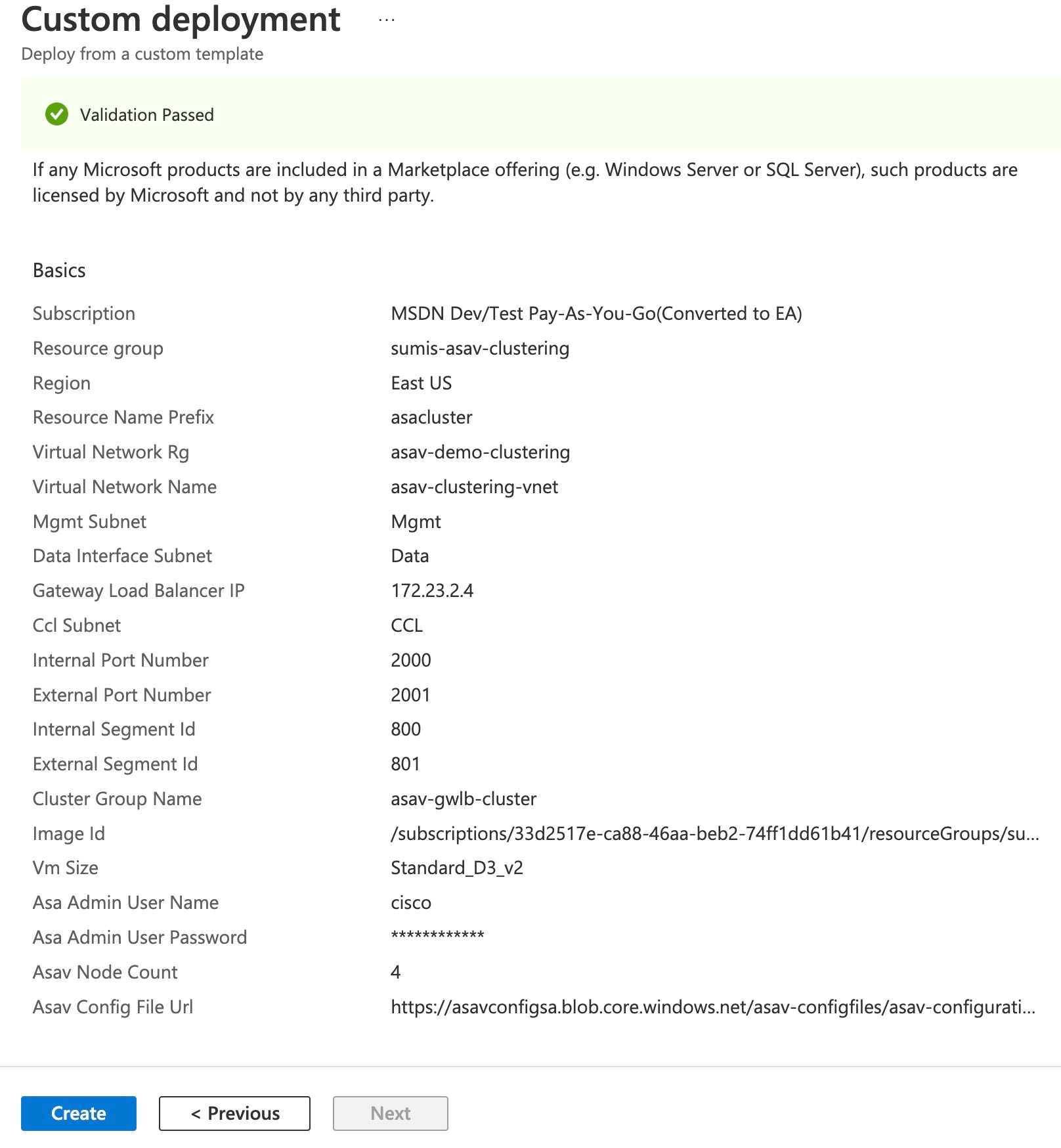 |
|
ステップ 10 |
インスタンスの実行後、いずれかのノードにログインし、show cluster info コマンドを入力して、クラスタの展開を確認します。 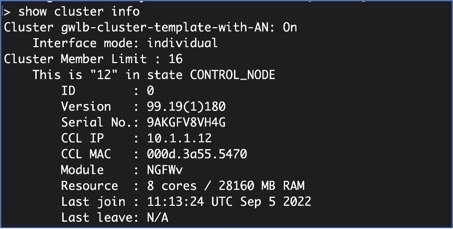 |
次のタスク
Azure でクラスタを設定する
Azure の ASAv ノードでクラスタを設定するには、構成ファイルを使用するか、Azure Function App を使用して手動で設定できます。ネイティブ GWLB でクラスタを使用できます。
Azure でクラスタを作成するための構成ファイルを準備する
構成ファイルまたは Azure portal の Function App を使用して、ASA 仮想 ノードでクラスタを手動で設定できます。
ASA 仮想 ノードでクラスタを手動で設定するには、asav-gwlb-cluster-config.txt を設定しておく必要があります。このファイルでは、クラスタの ASA 仮想 ノードで設定されている範囲オブジェクト、デイゼロ、クラスタグループ名、ライセンスタイプなどのパラメータを定義する必要があります。
このセクションでは、GWLB を使用して Azure の ASA 仮想 ノードを設定するためのクラスタの構成ファイルの作成について説明します。
手順
|
ステップ 1 |
Cisco GitHub リポジトリディレクトリ asav-cluster/sample-config-file から asav-gwlb-cluster-config.txt をダウンロードします。 |
||
|
ステップ 2 |
クラスタ作成のためにデイゼロ設定を準備できます。 次の day0 構成のサンプルは、GWLB を使用した Azure でのクラスタ作成に必要なパラメータを理解するのに役立ちます。
以下は、vni インターフェイスに必要な設定のサンプルです。
|
||
|
ステップ 3 |
構成ファイルを Azure ストレージにアップロードし、この場所のパス(URL)をメモします。この URL パスは、ASA 仮想 ノードでのクラスタの手動設定に必要です。 |
構成ファイルを使用して手動でクラスタを設定する
構成ファイルを使用して、Azure の ASAv ノードでクラスタを手動で構成するには以下の手順を実行します。
始める前に
構成ファイルを準備し、アップロード先の Azure ストレージの場所をメモしておく必要があります。「Prepare Cluster Configuration File for Azure」を参照してください。
手順
|
ステップ 1 |
Azure ポータルにログインします。 |
|
ステップ 2 |
Azure に展開された ASAv インスタンスを開きます。 |
|
ステップ 3 |
次のコマンドを実行して、Azure ストレージコンテナにアップロードしたファイルの URL を指定して、クラスタ構成ファイルを ASAv ノードにコピーします。 copy <Config File URL> running-config |
|
ステップ 4 |
次のコマンドを実行して、ASAv インスタンスでクラスタを設定します。 |
|
ステップ 5 |
手順 2 ~ 4 を繰り返して、すべての ASAv ノードでクラスタを設定します。 |
Azure Function App を使用してクラスタを設定する
Azure Function App サービスを使用して Azure の ASAv ノードでクラスタを設定するには、以下の手順を実行します。
手順
|
ステップ 1 |
Azure ポータルにログインします。 |
|
ステップ 2 |
[Function App] をクリックします。 |
|
ステップ 3 |
をクリックして FTPS の資格情報を作成し、[保存(Save)] をクリックします。 |
|
ステップ 4 |
ローカルのターミナルで次のコマンドを実行して、Cluster_Function.zip ファイルを関数アプリにアップロードします。 curl -X POST -u <Userscope_Username> --data-binary @"Cluster_Function.zip" https://<Function_App_Name>.scm.azurewebsites.net/api/zipdeploy
   関数が Function アプリにアップロードされます。関数が開始され、ストレージアカウントのアウトキューにログが表示されます。 関数の実行後、クラスタはすべての ASAv ノードで有効になります。
|
Azure における ASA Virtual クラスタのトラブルシューティング
トラフィックの問題
トラフィックが機能していない場合は、次のことを確認します。
-
ロードバランサを使用した ASA virtual インスタンスの正常性プローブのステータスが正常であることを確認します。
ASA virtual インスタンスの正常性プローブのステータスが正常でない場合は、次を実行します。
-
ASA virtual で設定されたスタティックルートを確認します。
-
デフォルトゲートウェイがデータサブネットのゲートウェイ IP であることを確認します。
-
ASA virtual インスタンスが正常性プローブトラフィックを受信していることを確認します。
-
ASA virtual で設定されているアクセスポリシーが正常性プローブトラフィックを許可していることを確認します。
-
クラスタの問題
クラスタが形成されていない場合は、次のことを確認してください。
-
ネットワーク仮想化エンドポイント(NVE-only)のクラスタインターフェイスの IP アドレス。他のノードの NVE-only のクラスタインターフェイスに ping を実行できることを確認します。
-
NVE-only のクラスタインターフェイスの IP アドレスは、オブジェクトグループの一部です。NVE がオブジェクトグループで設定されていることを確認します。
-
クラスタグループのクラスタインターフェイスに正しい VNI インターフェイスがあります。この VNI インターフェイスには、対応するオブジェクトグループの NVE があります。
-
各ノードには独自の IP インターフェイスがあります。クラスタ内のノード間の接続を確保するために、ノードが相互に ping できることを確認します。
-
テンプレートのデプロイ中に指定された CCL サブネットの開始アドレスと終了アドレスが正しいことを確認します。開始アドレスは、サブネット内で使用可能な最初の IP アドレスで始まる必要があります。たとえばサブネットが 192.168.1.0/24 の場合、開始アドレスは 192.168.1.4 である必要があります(最初の 3 つの IP アドレスは azure によって予約されています)。
ロールに関連する問題
同じリソースグループに再度リソースを展開しているときにロールに関連するエラーが発生した場合は、次の手順を実行します。
特定のロールに関連する問題がある場合、エラーメッセージが表示されます。
エラーメッセージの例を次に示します。
"error": {
"code": "RoleAssignmentUpdateNotPermitted",
"message": "Tenant ID, application ID, principal ID, and scope are not allowed to be updated.”}
ターミナルから以下のコマンドを実行して、以下のロールを削除します。
-
ストレージキューデータ寄稿者ロールを削除するコマンド:
az role assignment delete --resource-group <Resource Group Name> --role "Storage Queue Data Contributor"
-
寄稿者ロールを削除するコマンド:
az role assignment delete --resource-group <Resource Group Name> --role "Contributor"
クラスタリング動作のカスタマイズ
Day 0 設定の一環として、またはクラスタの展開後に、クラスタリング ヘルス モニタリング、TCP 接続複製の遅延、フローのモビリティ、他の最適化をカスタマイズできます。
制御ノードで次の手順を実行します。
ASA クラスタの基本パラメータの設定
制御ノード上のクラスタ設定をカスタマイズできます。
手順
|
ステップ 1 |
クラスタの設定モードを開始します。 cluster group name |
|
ステップ 2 |
(任意) データノードから制御ノードへのコンソール複製を有効にします。 console-replicate この機能はデフォルトで無効に設定されています。ASA は、特定の重大イベントが発生したときに、メッセージを直接コンソールに出力します。コンソール複製を有効にすると、データノードから制御ノードにコンソールメッセージが送信されるので、モニタする必要があるのはクラスタのコンソールポート 1 つだけです。 |
|
ステップ 3 |
クラスタリング イベントの最小トレース レベルを設定します。 trace-level level 必要に応じて最小レベルを設定します。
|
|
ステップ 4 |
フローオーナーからディレクタおよびバックアップオーナーへのフロー状態更新メッセージ(clu_keepalive および clu_update メッセージ)のキープアライブ間隔を設定します。 clu-keepalive-interval seconds
クラスタ制御リンクのトラフィック量を減らすために、デフォルトよりも長い間隔を設定することもできます。 |
ヘルスモニタリングおよび自動再参加設定の設定
この手順では、ノードとインターフェイスのヘルスモニタリングを設定します。
たとえば、管理インターフェイスなど、必須以外のインターフェイスのヘルス モニタリングをディセーブルにすることができます。ヘルスモニタリングは VLAN サブインターフェイスでは実行されません。クラスタ制御リンクのモニタリングは設定できません。このリンクは常にモニターされています。
手順
|
ステップ 1 |
クラスタの設定モードを開始します。 cluster group name 例: |
|
ステップ 2 |
クラスタノードのヘルスチェック機能をカスタマイズします。 health-check [holdtime timeout] ノードのヘルスを確認するため、ASA のクラスタノードはクラスタ制御リンクで他のノードにハートビートメッセージを送信します。ノードが保留時間内にピアノードからハートビートメッセージを受信しない場合、そのピアノードは応答不能またはデッド状態と見なされます。
何らかのトポロジ変更を行うとき(たとえば、データインターフェイスの追加または削除、ASA またはスイッチ上のインターフェイスの有効化または無効化)は、ヘルスチェック機能を無効にし、無効化したインターフェイスのインターフェイス モニタリングも無効にする必要があります(no health-check monitor-interface )。トポロジの変更が完了して、設定の変更がすべてのノードに同期されたら、ヘルスチェック機能を再度有効にできます。 例: |
|
ステップ 3 |
インターフェイスでインターフェイス ヘルス チェックを無効化します。 no health-check monitor-interface interface_id インターフェイスのヘルス チェックはリンク障害をモニターします。ASA がメンバーをクラスタから削除するまでの時間は、そのノードが確立済みメンバーであるか、またはクラスタに参加しようとしているかによって異なります。デフォルトでは、ヘルス チェックはすべてのインターフェイスでイネーブルになっています。このコマンドの no 形式を使用してディセーブル(無効)にすることができます。たとえば、管理インターフェイスなど、必須以外のインターフェイスのヘルス モニタリングをディセーブルにすることができます。
何らかのトポロジ変更を行うとき(たとえば、データインターフェイスの追加または削除、ASA またはスイッチ上のインターフェイスの有効化または無効化)は、ヘルスチェック機能を無効(no health-check )にし、無効化したインターフェイスのインターフェイス モニタリングも無効にする必要があります。トポロジの変更が完了して、設定の変更がすべてのノードに同期されたら、ヘルスチェック機能を再度有効にできます。 例: |
|
ステップ 4 |
ヘルス チェック失敗後の自動再結合クラスタ設定をカスタマイズします。 health-check {data-interface | cluster-interface | system} auto-rejoin [unlimited | auto_rejoin_max] auto_rejoin_interval auto_rejoin_interval_variation
例: |
|
ステップ 5 |
ASA がインターフェイスを障害が発生していると見なし、クラスタからノードが削除されるまでのデバウンス時間を設定します。 health-check monitor-interface debounce-time ms 例:デバウンス時間は 300 ~ 9000 ms の範囲の値を設定します。デフォルトは 500 ms です。値を小さくすると、インターフェイスの障害をより迅速に検出できます。デバウンス時間を短くすると、誤検出の可能性が高くなることに注意してください。インターフェイスのステータス更新が発生すると、ASA はインターフェイスを障害としてマークし、クラスタからノードを削除するまで指定されたミリ秒数待機します。 |
|
ステップ 6 |
(任意) トラフィック負荷のモニタリングを設定します。 load-monitor [ frequency seconds] [ intervals intervals]
クラスタメンバのトラフィック負荷をモニターできます。対象には、合計接続数、CPU とメモリの使用率、バッファドロップなどが含まれます。負荷が高すぎる場合、残りのノードが負荷を処理できる場合は、ノードのクラスタリングを手動で無効にするか、外部スイッチのロードバランシングを調整するかを選択できます。この機能は、デフォルトでイネーブルにされています。トラフィックの負荷を定期的にモニターできます。負荷が高すぎる場合は、ノードでクラスタリングを手動で無効にすることを選択できます。 トラフィック負荷を表示するには、show cluster info load-monitor コマンドを使用します。 例: |
例
次の例では、ヘルスチェック保留時間を .3 秒に設定し、管理 0/0 インターフェイスのモニタリングを無効にし、データインターフェイスの自動再結合の試行回数を 2 分から開始して前回の間隔の 3 倍増加させる計 4 回に設定し、クラスタ制御リンクの自動再結合の試行回数を 2 分おきの計 6 回に設定しています。
ciscoasa(config)# cluster group test
ciscoasa(cfg-cluster)# health-check holdtime .3
ciscoasa(cfg-cluster)# no health-check monitor-interface management0/0
ciscoasa(cfg-cluster)# health-check data-interface auto-rejoin 4 2 3
ciscoasa(cfg-cluster)# health-check cluster-interface auto-rejoin 6 2 1
クラスタノードの管理
クラスタを導入した後は、コンフィギュレーションを変更し、クラスタノードを管理できます。
非アクティブノードになる
クラスタの非アクティブなメンバーになるには、クラスタリング コンフィギュレーションは変更せずに、そのノード上でクラスタリングをディセーブルにします。
(注) |
ASA が(手動で、またはヘルス チェック エラーにより)非アクティブになると、すべてのデータ インターフェイスがシャットダウンされます。管理専用インターフェイスのみがトラフィックを送受信できます。トラフィックフローを再開させるには、クラスタリングを再びイネーブルにします。または、そのノードをクラスタから完全に削除します。管理インターフェイスは、そのノードがクラスタ IP プールから受け取った IP アドレスを使用して引き続き稼働状態となります。ただし、リロードしてもノードがクラスタ内でまだアクティブではない場合(クラスタリングが無効な状態で設定を保存した場合など)、管理インターフェイスは無効になります。それ以降のコンフィギュレーション作業には、コンソール ポートを使用する必要があります。 |
手順
|
ステップ 1 |
クラスタの設定モードを開始します。 cluster group name 例: |
|
ステップ 2 |
クラスタリングをディセーブルにします。 no enable このノードが制御ノードであった場合は、新しい制御ノードの選定が実行され、別のメンバーが制御ノードになります。 クラスタ コンフィギュレーションは維持されるので、後でクラスタリングを再度イネーブルにできます。 |
制御ノードからのデータノードの非アクティブ化
ログインしているノード以外のメンバを非アクティブにするには、次のステップを実行します。
(注) |
ASA が非アクティブになると、すべてのデータ インターフェイスがシャットダウンされます。管理専用インターフェイスのみがトラフィックを送受信できます。トラフィック フローを再開するには、クラスタリングを再度有効にします。管理インターフェイスは、そのノードがクラスタ IP プールから受け取った IP アドレスを使用して引き続き稼働状態となります。ただし、リロードしてもノードがクラスタ内でまだアクティブではない場合(クラスタリングが無効な状態で設定を保存した場合など)、管理インターフェイスは無効になります。それ以降のコンフィギュレーション作業には、コンソール ポートを使用する必要があります。 |
手順
|
クラスタからノードを削除します。 cluster remove unit node_name ブートストラップ コンフィギュレーションは変更されず、制御ノードから最後に同期されたコンフィギュレーションもそのままであるので、コンフィギュレーションを失わずに後でそのノードを再度追加できます。制御ノードを削除するためにデータノードでこのコマンドを入力した場合は、新しい制御ノードが選定されます。 メンバ名を一覧表示するには、cluster remove unit ? と入力するか、show cluster info コマンドを入力します。 例: |
クラスタへの再参加
ノードがクラスタから削除された場合(たとえば、障害が発生したインターフェイスの場合、またはメンバーを手動で非アクティブにした場合)は、クラスタに手動で再参加する必要があります。
手順
|
ステップ 1 |
コンソールで、クラスタ コンフィギュレーション モードを開始します。 cluster group name 例: |
|
ステップ 2 |
クラスタリングをイネーブルにします。 enable |
クラスタからの脱退
クラスタから完全に脱退するには、クラスタ ブートストラップ コンフィギュレーション全体を削除する必要があります。各ノードの現在のコンフィギュレーションは(アクティブユニットから同期されて)同じであるため、クラスタから脱退すると、クラスタリング前のコンフィギュレーションをバックアップから復元するか、IP アドレスの競合を避けるためコンフィギュレーションを消去して初めからやり直すことも必要になります。
手順
|
ステップ 1 |
データノードの場合、クラスタリングを次のように無効化します。 cluster group cluster_name no enable 例:クラスタリングがデータノード上でイネーブルになっている間は、コンフィギュレーション変更を行うことはできません。 |
|
ステップ 2 |
クラスタ コンフィギュレーションをクリアします。 clear configure cluster ASA は、管理インターフェイスとクラスタ制御リンクを含むすべてのインターフェイスをシャットダウンします。 |
|
ステップ 3 |
クラスタ インターフェイス モードをディセーブルにします。 no cluster interface-mode モードはコンフィギュレーションには保存されないため、手動でリセットする必要があります。 |
|
ステップ 4 |
バックアップ コンフィギュレーションがある場合、実行コンフィギュレーションにバックアップ コンフィギュレーションをコピーします。 copy backup_cfg running-config 例: |
|
ステップ 5 |
コンフィギュレーションをスタートアップに保存します。 write memory |
|
ステップ 6 |
バックアップ コンフィギュレーションがない場合は、管理アクセスを再設定します。たとえば、インターフェイス IP アドレスを変更し、正しいホスト名を復元します。 |
制御ノードの変更
 注意 |
制御ノードを変更する最良の方法は、制御ノードでクラスタリングを無効にし、新しい制御ユニットの選択を待ってから、クラスタリングを再度有効にする方法です。制御ノードにするノードを厳密に指定する必要がある場合は、この項の手順を使用します。ただし、中央集中型機能の場合は、この手順を使用して制御ノード変更を強制するとすべての接続がドロップされるので、新しい制御ノード上で接続を再確立する必要があります。 |
制御ノードを変更するには、次の手順を実行します。
手順
|
新しいノードを制御ノードとして設定します。 cluster control-node unitnode_name 例:メイン クラスタ IP アドレスへの再接続が必要になります。 メンバー名を表示するには、cluster control-node unit ? (現在のノードを除くすべての名前が表示される)と入力するか、show cluster info コマンドを入力します。 |
クラスタ全体でのコマンドの実行
コマンドをクラスタ内のすべてのノードに、または特定のノードに送信するには、次の手順を実行します。show コマンドをすべてのノードに送信すると、すべての出力が収集されて現在のノードのコンソールに表示されます。その他のコマンド、たとえば capture や copy も、クラスタ全体での実行を活用できます。
手順
|
すべてのノードにコマンドを送信します。ノード名を指定した場合は、特定のノードに送信します。 cluster exec [unit node_name] コマンド 例:ノード名を表示するには、cluster exec unit ? (現在のノードを除くすべての名前が表示される)と入力するか、show cluster info コマンドを入力します。 |
例
同じキャプチャファイルをクラスタ内のすべてのノードから同時に TFTP サーバにコピーするには、制御ノードで次のコマンドを入力します。
ciscoasa# cluster exec copy /pcap capture: tftp://10.1.1.56/capture1.pcap
複数の PCAP ファイル(各ノードから 1 つずつ)が TFTP サーバにコピーされます。宛先のキャプチャファイル名には自動的にノード名が付加され、capture1_asa1.pcap、capture1_asa2.pcap などとなります。この例では、asa1 と asa2 はクラスタノード名です。
クラスタのモニタリング
クラスタの状態と接続をモニターおよびトラブルシューティングできます。
クラスタ ステータスのモニタリング
クラスタの状態のモニタリングについては、次のコマンドを参照してください。
-
show cluster info [health [details]]
キーワードを指定しないで show cluster info コマンドを実行すると、クラスタ内のすべてのメンバのステータスが表示されます。
show cluster info health コマンドは、インターフェイス、ノードおよびクラスタ全体の現在の状態を表示します。details キーワードは、ハートビート メッセージの失敗数を表示します。
show cluster info コマンドについては次の出力を参照してください。
ciscoasa# show cluster info Cluster stbu: On This is "C" in state DATA_NODE ID : 0 Site ID : 1 Version : 9.4(1) Serial No.: P3000000025 CCL IP : 10.0.0.3 CCL MAC : 000b.fcf8.c192 Last join : 17:08:59 UTC Sep 26 2011 Last leave: N/A Other members in the cluster: Unit "D" in state DATA_NODE ID : 1 Site ID : 1 Version : 9.4(1) Serial No.: P3000000001 CCL IP : 10.0.0.4 CCL MAC : 000b.fcf8.c162 Last join : 19:13:11 UTC Sep 23 2011 Last leave: N/A Unit "A" in state CONTROL_NODE ID : 2 Site ID : 2 Version : 9.4(1) Serial No.: JAB0815R0JY CCL IP : 10.0.0.1 CCL MAC : 000f.f775.541e Last join : 19:13:20 UTC Sep 23 2011 Last leave: N/A Unit "B" in state DATA_NODE ID : 3 Site ID : 2 Version : 9.4(1) Serial No.: P3000000191 CCL IP : 10.0.0.2 CCL MAC : 000b.fcf8.c61e Last join : 19:13:50 UTC Sep 23 2011 Last leave: 19:13:36 UTC Sep 23 2011 -
show cluster info auto-join
時間遅延後にクラスタノードがクラスタに自動的に再参加するかどうか、および障害状態(ライセンスの待機やシャーシのヘルスチェック障害など)がクリアされたかどうかを示します。ノードが永続的に無効になっている場合、またはノードがすでにクラスタ内にある場合、このコマンドでは出力が表示されません。
show cluster info auto-join コマンドについては次の出力を参照してください。
ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster in 253 seconds. Quit reason: Received control message DISABLE ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Control node has application down that data node has up. ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Chassis-blade health check failed. ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Service chain application became down. ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Unit is kicked out from cluster because of Application health check failure. ciscoasa(cfg-cluster)# show cluster info auto-join Unit join is pending (waiting for the smart license entitlement: ent1) ciscoasa(cfg-cluster)# show cluster info auto-join Unit join is pending (waiting for the smart license export control flag) -
show cluster info transport{asp |cp[detail]}
次のトランスポート関連の統計情報を表示します。
-
asp:データ プレーンのトランスポート統計情報。
-
cp:コントロール プレーンのトランスポート統計情報。
detail キーワードを入力すると、クラスタで信頼性の高いトランスポート プロトコルの使用状況が表示され、バッファがコントロール プレーンでいっぱいになったときにパケット ドロップの問題を特定できます。show cluster info transport cp detail コマンドについては次の出力を参照してください。
ciscoasa# show cluster info transport cp detail Member ID to name mapping: 0 - unit-1-1 2 - unit-4-1 3 - unit-2-1 Legend: U - unreliable messages UE - unreliable messages error SN - sequence number ESN - expecting sequence number R - reliable messages RE - reliable messages error RDC - reliable message deliveries confirmed RA - reliable ack packets received RFR - reliable fast retransmits RTR - reliable timer-based retransmits RDP - reliable message dropped RDPR - reliable message drops reported RI - reliable message with old sequence number RO - reliable message with out of order sequence number ROW - reliable message with out of window sequence number ROB - out of order reliable messages buffered RAS - reliable ack packets sent This unit as a sender -------------------------- all 0 2 3 U 123301 3867966 3230662 3850381 UE 0 0 0 0 SN 1656a4ce acb26fe 5f839f76 7b680831 R 733840 1042168 852285 867311 RE 0 0 0 0 RDC 699789 934969 740874 756490 RA 385525 281198 204021 205384 RFR 27626 56397 0 0 RTR 34051 107199 111411 110821 RDP 0 0 0 0 RDPR 0 0 0 0 This unit as a receiver of broadcast messages --------------------------------------------- 0 2 3 U 111847 121862 120029 R 7503 665700 749288 ESN 5d75b4b3 6d81d23 365ddd50 RI 630 34278 40291 RO 0 582 850 ROW 0 566 850 ROB 0 16 0 RAS 1571 123289 142256 This unit as a receiver of unicast messages --------------------------------------------- 0 2 3 U 1 3308122 4370233 R 513846 879979 1009492 ESN 4458903a 6d841a84 7b4e7fa7 RI 66024 108924 102114 RO 0 0 0 ROW 0 0 0 ROB 0 0 0 RAS 130258 218924 228303 Gated Tx Buffered Message Statistics ------------------------------------- current sequence number: 0 total: 0 current: 0 high watermark: 0 delivered: 0 deliver failures: 0 buffer full drops: 0 message truncate drops: 0 gate close ref count: 0 num of supported clients:45 MRT Tx of broadcast messages ============================= Message high watermark: 3% Total messages buffered at high watermark: 5677 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage Cluster Redirect Client 4153 73% Route Cluster Client 419 7% RRI Cluster Client 1105 19% Current MRT buffer usage: 0% Total messages buffered in real-time: 1 [Per-client message usage in real-time] Legend: F - MRT messages sending when buffer is full L - MRT messages sending when cluster node leave R - MRT messages sending in Rx thread ---------------------------------------------------------------------------- Client name Total messages Percentage F L R VPN Clustering HA Client 1 100% 0 0 0 MRT Tx of unitcast messages(to member_id:0) ============================================ Message high watermark: 31% Total messages buffered at high watermark: 4059 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage Cluster Redirect Client 3731 91% RRI Cluster Client 328 8% Current MRT buffer usage: 29% Total messages buffered in real-time: 3924 [Per-client message usage in real-time] Legend: F - MRT messages sending when buffer is full L - MRT messages sending when cluster node leave R - MRT messages sending in Rx thread ---------------------------------------------------------------------------- Client name Total messages Percentage F L R Cluster Redirect Client 3607 91% 0 0 0 RRI Cluster Client 317 8% 0 0 0 MRT Tx of unitcast messages(to member_id:2) ============================================ Message high watermark: 14% Total messages buffered at high watermark: 578 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage VPN Clustering HA Client 578 100% Current MRT buffer usage: 0% Total messages buffered in real-time: 0 MRT Tx of unitcast messages(to member_id:3) ============================================ Message high watermark: 12% Total messages buffered at high watermark: 573 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage VPN Clustering HA Client 572 99% Cluster VPN Unique ID Client 1 0% Current MRT buffer usage: 0% Total messages buffered in real-time: 0
-
-
show cluster history
クラスタの履歴、およびクラスタノードが参加できなかった理由や、ノードがクラスタを離れた理由に関するエラーメッセージが表示されます。
クラスタ全体のパケットのキャプチャ
クラスタでのパケットのキャプチャについては、次のコマンドを参照してください。
cluster exec capture
クラスタ全体のトラブルシューティングをサポートするには、cluster exec capture コマンドを使用して制御ノード上でのクラスタ固有トラフィックのキャプチャを有効にします。これで、クラスタ内のすべてのデータノードでも自動的に有効になります。
クラスタリソースのモニタリング
クラスタリソースのモニタリングについては、次のコマンドを参照してください。
show cluster {cpu | memory | resource} [options]
クラスタ全体の集約データを表示します。使用可能な options はデータのタイプによって異なります。
クラスタ トラフィックのモニタリング
クラスタトラフィックのモニタリングについては、次のコマンドを参照してください。
-
show conn [detail]、cluster exec show conn
show conn コマンドは、フローがディレクタ、バックアップ、またはフォワーダのどのフローであるかを示します。cluster exec show conn コマンドを任意のノードで使用すると、すべての接続が表示されます。このコマンドの表示からは、1 つのフローのトラフィックがクラスタ内のさまざまな ASA にどのように到達するかがわかります。クラスタのスループットは、ロード バランシングの効率とコンフィギュレーションによって異なります。このコマンドを利用すると、ある接続のトラフィックがクラスタ内をどのように流れるかが簡単にわかります。また、ロード バランサがフローのパフォーマンスにどのように影響を与えるかを理解するのに役立ちます。
また、show conn detail コマンドはフロー モビリティの影響を受けるフローを表示します。
次に、show conn detail コマンドの出力例を示します。
ciscoasa/ASA2/data node# show conn detail 12 in use, 13 most used Cluster stub connections: 0 in use, 46 most used Flags: A - awaiting inside ACK to SYN, a - awaiting outside ACK to SYN, B - initial SYN from outside, b - TCP state-bypass or nailed, C - CTIQBE media, c - cluster centralized, D - DNS, d - dump, E - outside back connection, e - semi-distributed, F - outside FIN, f - inside FIN, G - group, g - MGCP, H - H.323, h - H.225.0, I - inbound data, i - incomplete, J - GTP, j - GTP data, K - GTP t3-response k - Skinny media, L - LISP triggered flow owner mobility, M - SMTP data, m - SIP media, n - GUP O - outbound data, o - offloaded, P - inside back connection, Q - Diameter, q - SQL*Net data, R - outside acknowledged FIN, R - UDP SUNRPC, r - inside acknowledged FIN, S - awaiting inside SYN, s - awaiting outside SYN, T - SIP, t - SIP transient, U - up, V - VPN orphan, W - WAAS, w - secondary domain backup, X - inspected by service module, x - per session, Y - director stub flow, y - backup stub flow, Z - Scansafe redirection, z - forwarding stub flow ESP outside: 10.1.227.1/53744 NP Identity Ifc: 10.1.226.1/30604, , flags c, idle 0s, uptime 1m21s, timeout 30s, bytes 7544, cluster sent/rcvd bytes 0/0, owners (0,255) Traffic received at interface outside Locally received: 7544 (93 byte/s) Traffic received at interface NP Identity Ifc Locally received: 0 (0 byte/s) UDP outside: 10.1.227.1/500 NP Identity Ifc: 10.1.226.1/500, flags -c, idle 1m22s, uptime 1m22s, timeout 2m0s, bytes 1580, cluster sent/rcvd bytes 0/0, cluster sent/rcvd total bytes 0/0, owners (0,255) Traffic received at interface outside Locally received: 864 (10 byte/s) Traffic received at interface NP Identity Ifc Locally received: 716 (8 byte/s)接続フローのトラブルシューティングを行うには、最初にすべてのノードの接続を一覧表示します。それには、任意のノードで cluster exec show conn コマンドを入力します。ディレクタ(Y)、バックアップ(y)、およびフォワーダ(z)のフラグを持つフローを探します。次の例には、3 つのすべての ASA での 172.18.124.187:22 から 192.168.103.131:44727 への SSH 接続が表示されています。ASA1 には z フラグがあり、この接続のフォワーダであることを表しています。ASA3 には Y フラグがあり、この接続のディレクタであることを表しています。ASA2 には特別なフラグはなく、これがオーナーであることを表しています。アウトバウンド方向では、この接続のパケットは ASA2 の内部インターフェイスに入り、外部インターフェイスから出ていきます。インバウンド方向では、この接続のパケットは ASA1 および ASA3 の外部インターフェイスに入り、クラスタ制御リンクを介して ASA2 に転送され、次に ASA2 の内部インターフェイスから出ていきます。
ciscoasa/ASA1/control node# cluster exec show conn ASA1(LOCAL):********************************************************** 18 in use, 22 most used Cluster stub connections: 0 in use, 5 most used TCP outside 172.18.124.187:22 inside 192.168.103.131:44727, idle 0:00:00, bytes 37240828, flags z ASA2:***************************************************************** 12 in use, 13 most used Cluster stub connections: 0 in use, 46 most used TCP outside 172.18.124.187:22 inside 192.168.103.131:44727, idle 0:00:00, bytes 37240828, flags UIO ASA3:***************************************************************** 10 in use, 12 most used Cluster stub connections: 2 in use, 29 most used TCP outside 172.18.124.187:22 inside 192.168.103.131:44727, idle 0:00:03, bytes 0, flags Y -
show cluster info [conn-distribution | packet-distribution | loadbalance | flow-mobility counters]
show cluster info conn-distribution コマンドと show cluster info packet-distribution コマンドは、すべてのクラスタノードへのトラフィック分散を表示します。これらのコマンドは、外部ロード バランサを評価し、調整するのに役立ちます。
show cluster info loadbalance コマンドは、接続再分散の統計情報を表示します。
show cluster info flow-mobility counters コマンドは、EID およびフローの所有者の動作情報を表示します。show cluster info flow-mobility counters コマンドについては次の出力を参照してください。
ciscoasa# show cluster info flow-mobility counters EID movement notification received : 4 EID movement notification processed : 4 Flow owner moving requested : 2 -
show cluster info load-monitor [details]
このshow cluster info load-monitor コマンドは、最後の間隔のクラスタメンバのトラフィック負荷と、設定された間隔の合計数(デフォルトでは 30)を表示します。各間隔の各測定値を表示するには、details キーワードを使用します。
ciscoasa(cfg-cluster)# show cluster info load-monitor ID Unit Name 0 B 1 A_1 Information from all units with 20 second interval: Unit Connections Buffer Drops Memory Used CPU Used Average from last 1 interval: 0 0 0 14 25 1 0 0 16 20 Average from last 30 interval: 0 0 0 12 28 1 0 0 13 27 ciscoasa(cfg-cluster)# show cluster info load-monitor details ID Unit Name 0 B 1 A_1 Information from all units with 20 second interval Connection count captured over 30 intervals: Unit ID 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Unit ID 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Buffer drops captured over 30 intervals: Unit ID 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Unit ID 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Memory usage(%) captured over 30 intervals: Unit ID 0 25 25 30 30 30 35 25 25 35 30 30 30 25 25 30 25 25 35 30 30 30 25 25 25 25 20 30 30 30 30 Unit ID 1 30 25 35 25 30 30 25 25 35 25 30 35 30 30 35 30 30 30 25 20 30 25 25 30 20 30 35 30 30 35 CPU usage(%) captured over 30 intervals: Unit ID 0 25 25 30 30 30 35 25 25 35 30 30 30 25 25 30 25 25 35 30 30 30 25 25 25 25 20 30 30 30 30 Unit ID 1 30 25 35 25 30 30 25 25 35 25 30 35 30 30 35 30 30 30 25 20 30 25 25 30 20 30 35 30 30 35 -
show cluster {access-list | conn | traffic | user-identity | xlate} [options]
クラスタ全体の集約データを表示します。使用可能な options はデータのタイプによって異なります。
show cluster access-list コマンドについては次の出力を参照してください。
ciscoasa# show cluster access-list hitcnt display order: cluster-wide aggregated result, unit-A, unit-B, unit-C, unit-D access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096) alert-interval 300 access-list 101; 122 elements; name hash: 0xe7d586b5 access-list 101 line 1 extended permit tcp 192.168.143.0 255.255.255.0 any eq www (hitcnt=0, 0, 0, 0, 0) 0x207a2b7d access-list 101 line 2 extended permit tcp any 192.168.143.0 255.255.255.0 (hitcnt=0, 0, 0, 0, 0) 0xfe4f4947 access-list 101 line 3 extended permit tcp host 192.168.1.183 host 192.168.43.238 (hitcnt=1, 0, 0, 0, 1) 0x7b521307 access-list 101 line 4 extended permit tcp host 192.168.1.116 host 192.168.43.238 (hitcnt=0, 0, 0, 0, 0) 0x5795c069 access-list 101 line 5 extended permit tcp host 192.168.1.177 host 192.168.43.238 (hitcnt=1, 0, 0, 1, 0) 0x51bde7ee access list 101 line 6 extended permit tcp host 192.168.1.177 host 192.168.43.13 (hitcnt=0, 0, 0, 0, 0) 0x1e68697c access-list 101 line 7 extended permit tcp host 192.168.1.177 host 192.168.43.132 (hitcnt=2, 0, 0, 1, 1) 0xc1ce5c49 access-list 101 line 8 extended permit tcp host 192.168.1.177 host 192.168.43.192 (hitcnt=3, 0, 1, 1, 1) 0xb6f59512 access-list 101 line 9 extended permit tcp host 192.168.1.177 host 192.168.43.44 (hitcnt=0, 0, 0, 0, 0) 0xdc104200 access-list 101 line 10 extended permit tcp host 192.168.1.112 host 192.168.43.44 (hitcnt=429, 109, 107, 109, 104) 0xce4f281d access-list 101 line 11 extended permit tcp host 192.168.1.170 host 192.168.43.238 (hitcnt=3, 1, 0, 0, 2) 0x4143a818 access-list 101 line 12 extended permit tcp host 192.168.1.170 host 192.168.43.169 (hitcnt=2, 0, 1, 0, 1) 0xb18dfea4 access-list 101 line 13 extended permit tcp host 192.168.1.170 host 192.168.43.229 (hitcnt=1, 1, 0, 0, 0) 0x21557d71 access-list 101 line 14 extended permit tcp host 192.168.1.170 host 192.168.43.106 (hitcnt=0, 0, 0, 0, 0) 0x7316e016 access-list 101 line 15 extended permit tcp host 192.168.1.170 host 192.168.43.196 (hitcnt=0, 0, 0, 0, 0) 0x013fd5b8 access-list 101 line 16 extended permit tcp host 192.168.1.170 host 192.168.43.75 (hitcnt=0, 0, 0, 0, 0) 0x2c7dba0d使用中の接続の、すべてのノードでの合計数を表示するには、次のとおりに入力します。
ciscoasa# show cluster conn count Usage Summary In Cluster:********************************************* 200 in use (cluster-wide aggregated) cl2(LOCAL):*********************************************************** 100 in use, 100 most used cl1:****************************************************************** 100 in use, 100 most used -
show asp cluster counter
このコマンドは、データパスのトラブルシューティングに役立ちます。
クラスタのルーティングのモニタリング
クラスタのルーティングについては、次のコマンドを参照してください。
-
show route cluster
-
debug route cluster
クラスタのルーティング情報を表示します。
-
show lisp eid
EIDs とサイト ID を示す ASA EID テーブルを表示します。
cluster exec show lisp eid コマンドからの、次の出力を参照してください。
ciscoasa# cluster exec show lisp eid L1(LOCAL):************************************************************ LISP EID Site ID 33.44.33.105 2 33.44.33.201 2 11.22.11.1 4 11.22.11.2 4 L2:******************************************************************* LISP EID Site ID 33.44.33.105 2 33.44.33.201 2 11.22.11.1 4 11.22.11.2 4 -
show asp table classify domain inspect-lisp
このコマンドは、トラブルシューティングに役立ちます。
クラスタリングのロギングの設定
クラスタリングのロギングの設定については、次のコマンドを参照してください。
logging device-id
クラスタ内の各ノードは、syslog メッセージを個別に生成します。logging device-id コマンドを使用すると、同一または異なるデバイス ID 付きで syslog メッセージを生成することができ、クラスタ内の同一または異なるノードからのメッセージのように見せることができます。
クラスタのインターフェイスのモニタリング
クラスタのインターフェイスのモニタリングについては、次のコマンドを参照してください。
-
show cluster interface-mode
クラスタ インターフェイスのモードを表示します。
クラスタリングのデバッグ
クラスタリングのデバッグについては、次のコマンドを参照してください。
-
debug cluster [ccp | datapath | fsm | general | hc | license | rpc | transport]
クラスタリングのデバッグ メッセージを表示します。
-
debug cluster flow-mobility
クラスタリング フロー モビリティ関連のイベントを表示します。
-
debug lisp eid-notify-intercept
EID 通知メッセージ代行受信時のイベントを表示します。
-
show cluster info trace
show cluster info trace コマンドは、トラブルシューティングのためのデバッグ情報を表示します。
show cluster info trace コマンドについては次の出力を参照してください。
ciscoasa# show cluster info trace Feb 02 14:19:47.456 [DBUG]Receive CCP message: CCP_MSG_LOAD_BALANCE Feb 02 14:19:47.456 [DBUG]Receive CCP message: CCP_MSG_LOAD_BALANCE Feb 02 14:19:47.456 [DBUG]Send CCP message to all: CCP_MSG_KEEPALIVE from 80-1 at CONTROL_NODEたとえば、同じローカルユニット名を持つ 2 つのノードが制御ノードとして機能していることを示す次のメッセージが表示された場合は、2 つのノードのローカルユニット名が同じである(設定を確認してください)か、1 つのノードが自身のブロードキャストメッセージを受信している(ネットワークを確認してください)可能性があります。
ciscoasa# show cluster info trace May 23 07:27:23.113 [CRIT]Received datapath event 'multi control_nodes' with parameter 1. May 23 07:27:23.113 [CRIT]Found both unit-9-1 and unit-9-1 as control_node units. Control_node role retained by unit-9-1, unit-9-1 will leave then join as a Data_node May 23 07:27:23.113 [DBUG]Send event (DISABLE, RESTART | INTERNAL-EVENT, 5000 msecs, Detected another Control_node, leave and re-join as Data_node) to FSM. Current state CONTROL_NODE May 23 07:27:23.113 [INFO]State machine changed from state CONTROL_NODE to DISABLED
クラスタリングの参考資料
このセクションには、クラスタリングの動作に関する詳細情報が含まれます。
ASA の各機能とクラスタリング
ASA の一部の機能は ASA クラスタリングではサポートされず、一部の機能は制御ノードだけでサポートされます。その他の機能については適切な使用に関する警告がある場合があります。
クラスタリングでサポートされない機能
次の各機能は、クラスタリングが有効なときは設定できず、コマンドは拒否されます。
-
TLS プロキシを使用するユニファイド コミュニケーション機能
-
リモート アクセス VPN(SSL VPN および IPSec VPN)
-
仮想トンネルインターフェイス(VTI)
-
次のアプリケーション インスペクション:
-
CTIQBE
-
H323、H225、および RAS
-
IPsec パススルー
-
MGCP
-
MMP
-
RTSP
-
SCCP(Skinny)
-
WAAS
-
WCCP
-
-
ボットネット トラフィック フィルタ
-
Auto Update Server
-
DHCP クライアント、サーバー、およびプロキシ。DHCP リレーはサポートされています。
-
VPN ロード バランシング
-
Azure でのフェールオーバー
-
統合ルーティングおよびブリッジング
-
FIPS モード
クラスタリングの中央集中型機能
次の機能は、制御ノード上だけでサポートされます。クラスタの場合もスケーリングされません。
(注) |
中央集中型機能のトラフィックは、クラスタ制御リンク経由でメンバーノードから制御ノードに転送されます。 再分散機能を使用する場合は、中央集中型機能のトラフィックが中央集中型機能として分類される前に再分散が行われて、制御ノード以外のノードに転送されることがあります。この場合は、トラフィックが制御ノードに送り返されます。 中央集中型機能については、制御ノードで障害が発生するとすべての接続がドロップされるので、新しい制御ノード上で接続を再確立する必要があります。 |
-
次のアプリケーション インスペクション:
-
DCERPC
-
ESMTP
-
IM
-
NetBIOS
-
PPTP
-
RADIUS
-
RSH
-
SNMP
-
SQLNET
-
SUNRPC
-
TFTP
-
XDMCP
-
-
スタティック ルート モニタリング
-
ネットワーク アクセスの認証および許可。アカウンティングは非集中型です。
-
フィルタリング サービス
-
サイト間 VPN
-
マルチキャスト ルーティング
個々のノードに適用される機能
これらの機能は、クラスタ全体または制御ノードではなく、各 ASA ノードに適用されます。
-
QoS:QoS ポリシーは、コンフィギュレーション複製の一部としてクラスタ全体で同期されます。ただし、ポリシーは各ノードに個別に適用されます。たとえば、出力に対してポリシングを設定する場合は、適合レートおよび適合バースト値は、特定の ASA から出て行くトラフィックに適用されます。3 ノードから成るクラスタがあり、トラフィックが均等に分散している場合、適合レートは実際にクラスタのレートの 3 倍になります。
-
脅威検出:脅威検出はノードごとに個別に機能します。たとえば、上位統計情報はノード固有です。たとえば、ポートスキャン検出が機能しないのは、スキャントラフィックが全ノード間でロードバランシングされ、1 つのノードですべてのトラフィックを確認できないためです。
ネットワーク アクセス用の AAA とクラスタリング
ネットワーク アクセス用の AAA は、認証、許可、アカウンティングの 3 つのコンポーネントで構成されます。認証と許可は、クラスタリング制御ノード上で中央集中型機能として実装されており、データ構造がクラスタデータノードに複製されます。制御ノードが選択された場合、確立済みの認証済みユーザーおよびユーザーに関連付けられた許可を引き続き中断なく運用するために必要なすべての情報を新しい制御ノードが保有します。ユーザー認証のアイドルおよび絶対タイムアウトは、制御ノードが変更されたときも維持されます。
アカウンティングは、クラスタ内の分散型機能として実装されています。アカウンティングはフロー単位で実行されるため、フローに対するアカウンティングが設定されている場合、そのフローを所有するクラスタノードがアカウンティング開始と停止のメッセージを AAA サーバーに送信します。
接続設定とクラスタリング
接続制限は、クラスタ全体に適用されます(set connection conn-max 、set connection embryonic-conn-max 、set connection per-client-embryonic-max および set connection per-client-max コマンド ページを参照)。各ノードには、ブロードキャストメッセージに基づくクラスタ全体のカウンタの推定値があります。クラスタ全体で接続制限を設定しても、効率性を考慮して、厳密に制限数で適用されない場合があります。各ノードでは、任意の時点でのクラスタ全体のカウンタ値が過大評価または過小評価される可能性があります。ただし、ロードバランシングされたクラスタでは、時間の経過とともに情報が更新されます。
ダイナミック ルーティングおよびクラスタリング
個別インターフェイスモードでは、各ノードがスタンドアロンルータとしてルーティングプロトコルを実行します。ルートの学習は、各ノードが個別に行います。
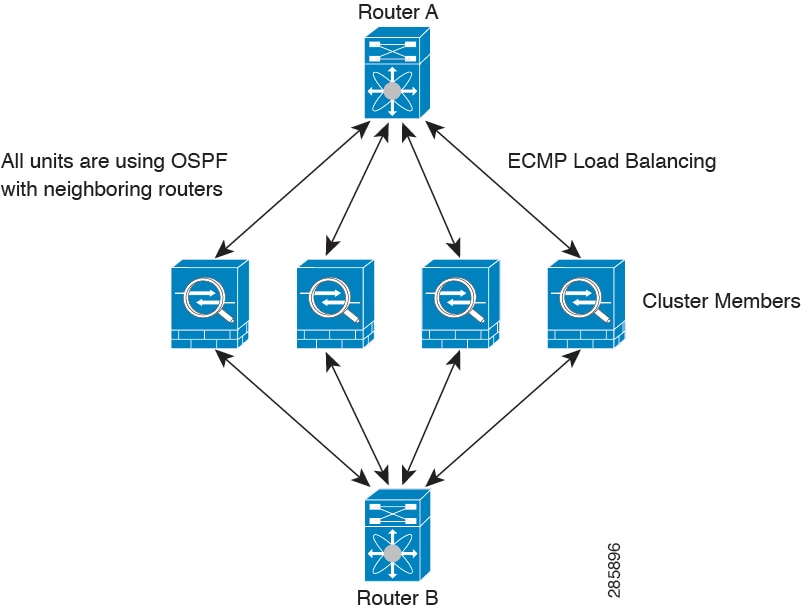
上の図では、ルータ A はルータ B への等コストパスが 4 本あることを学習します。パスはそれぞれ 1 つのノードを通過します。ECMP を使用して、4 パス間でトラフィックのロード バランシングを行います。各ノードは、外部ルータと通信するときに、それぞれ異なるルータ ID を選択します。
管理者は、各ノードに異なるルータ ID が設定されるように、ルータ ID のクラスタプールを設定する必要があります。
EIGRP は、個別のインターフェイス モードのクラスタ ピアとのネイバー関係を形成しません。
(注) |
冗長性確保のためにクラスタが同一ルータに対して複数の隣接関係を持つ場合、非対称ルーティングが原因で許容できないトラフィック損失が発生する場合があります。非対称ルーティングを避けるためには、同じトラフィックゾーンにこれらすべてのノードインターフェイスをまとめます。 |
FTP とクラスタリング
-
FTP D チャネルとコントロール チャネルのフローがそれぞれ別のクラスタ メンバーによって所有されている場合は、D チャネルのオーナーは定期的にアイドル タイムアウト アップデートをコントロール チャネルのオーナーに送信し、アイドル タイムアウト値を更新します。ただし、コントロール フローのオーナーがリロードされて、コントロール フローが再ホスティングされた場合は、親子フロー関係は維持されなくなります。したがって、コントロール フローのアイドル タイムアウトは更新されません。
-
FTP アクセスに AAA を使用する場合、制御チャネルのフローは制御ノードに集中されます。
ICMP インスペクションとクラスタリング
クラスタを通過する ICMP および ICMP エラーパケットのフローは、ICMP/ICMP エラーインスペクションが有効かどうかによって異なります。ICMP インスペクションを使用しない場合、ICMP は一方向のフローであり、ディレクタフローはサポートされません。ICMP インスペクションを使用する場合、ICMP フローは双方向になり、ディレクタ/バックアップフローによってバックアップされます。検査された ICMP フローの違いの 1 つは、転送されたパケットのディレクタ処理にあります。ディレクタは、パケットをフォワーダに返す代わりに、フローオーナーに ICMP エコー応答パケットを転送します。
マルチキャスト ルーティングとクラスタリング
個別インターフェイス モードでは、マルチキャストに関してユニットが個別に動作することはありません。データおよびルーティングのパケットはすべて制御ユニットで処理されて転送されるので、パケットレプリケーションが回避されます。
NAT とクラスタリング
NAT は、クラスタの全体的なスループットに影響を与えることがあります。インバウンドおよびアウトバウンドの NAT パケットが、それぞれクラスタ内の別の ASA に送信されることがあります。ロード バランシング アルゴリズムは IP アドレスとポートに依存していますが、NAT が使用されるときは、インバウンドとアウトバウンドとで、パケットの IP アドレスやポートが異なるからです。NAT オーナーではない ASA に到着したパケットは、クラスタ制御リンクを介してオーナーに転送されるため、クラスタ制御リンクに大量のトラフィックが発生します。NAT オーナーは、セキュリティおよびポリシーチェックの結果に応じてパケットの接続を作成できない可能性があるため、受信側ノードは、オーナーへの転送フローを作成しないことに注意してください。
それでもクラスタリングで NAT を使用する場合は、次のガイドラインを考慮してください。
-
プロキシ ARP なし:個別インターフェイスの場合は、マッピング アドレスについてプロキシ ARP 応答が送信されることはありません。これは、クラスタに存在しなくなった可能性のある ASA と隣接ルータとがピア関係を維持することを防ぐためです。アップストリーム ルータは、メイン クラスタ IP アドレスを指すマッピング アドレスについてはスタティック ルートまたは PBR とオブジェクト トラッキングを使用する必要があります。これは、スパンド EtherChannel の問題ではありません。クラスタ インターフェイスには関連付けられた IP アドレスが 1 つしかないためです。
-
ポート ブロック割り当てによる PAT:この機能については、次のガイドラインを参照してください。
-
ホストあたりの最大制限は、クラスタ全体の制限ではなく、ノードごとに個別に適用されます。したがって、ホストあたりの最大制限が 1 に設定されている 3 ノードクラスタでは、ホストからのトラフィックが 3 つのノードすべてにロードバランシングされている場合、3 つのブロックを各ノードに 1 つずつ割り当てることができます。
-
バックアッププールからバックアップノードで作成されたポートブロックは、ホストあたりの最大制限の適用時には考慮されません。
-
PAT プールが完全に新しい IP アドレスの範囲で変更される On-the-fly PAT ルールの変更では、新しいプールが有効になっていてもいまだ送信中の xlate バックアップ要求に対する xlate バックアップの作成が失敗します。この動作はポートのブロック割り当て機能に固有なものではなく、プールが分散されトラフィックがクラスタノード間でロードバランシングされるクラスタ展開でのみ見られる一時的な PAT プールの問題です。
-
クラスタで動作している場合、ブロック割り当てサイズを変更することはできません。新しいサイズは、クラスタ内の各デバイスをリロードした後にのみ有効になります。各デバイスのリロードの必要性を回避するために、すべてのブロック割り当てルールを削除し、それらのルールに関連するすべての xlate をクリアすることをお勧めします。その後、ブロックサイズを変更し、ブロック割り当てルールを再作成できます。
-
-
ダイナミック PAT の NAT プールアドレス配布:PAT プールを設定すると、クラスタはプール内の各 IP アドレスをポートブロックに分割します。デフォルトでは、各ブロックは 512 ポートですが、ポートブロック割り当てルールを設定すると、代わりにユーザのブロック設定が使用されます。これらのブロックはクラスタ内のノード間で均等に分散されるため、各ノードには PAT プール内の IP アドレスごとに 1 つ以上のブロックがあります。したがって、想定される PAT 接続数に対して十分である場合には、クラスタの PAT プールに含める IP アドレスを 1 つだけにすることができます。PAT プールの NAT ルールで予約済みポート 1 ~ 1023 を含めるようにオプションを設定しない限り、ポートブロックは 1024 ~ 65535 のポート範囲をカバーします。
-
複数のルールにおける PAT プールの再利用:複数のルールで同じ PAT プールを使用するには、ルールにおけるインターフェイスの選択に注意を払う必要があります。すべてのルールで特定のインターフェイスを使用するか、あるいはすべてのルールで「任意の」インターフェイスを使用するか、いずれかを選択する必要があります。ルール全般にわたって特定のインターフェイスと「任意」のインターフェイスを混在させることはできません。混在させると、システムがリターントラフィックとクラスタ内の適切なノードを一致させることができなくなる場合があります。ルールごとに固有の PAT プールを使用することは、最も信頼性の高いオプションです。
-
ラウンドロビンなし:PAT プールのラウンドロビンは、クラスタリングではサポートされません。
-
拡張 PAT なし:拡張 PAT はクラスタリングでサポートされません。
-
制御ノードによって管理されるダイナミック NAT xlate:制御ノードが xlate テーブルを維持し、データノードに複製します。ダイナミック NAT を必要とする接続をデータノードが受信したときに、その xlate がテーブル内にない場合、データノードは制御ノードに xlate を要求します。データノードが接続を所有します。
-
旧式の xlates:接続所有者の xlate アイドル時間が更新されません。したがって、アイドル時間がアイドルタイムアウトを超える可能性があります。refcnt が 0 で、アイドルタイマー値が設定されたタイムアウトより大きい場合は、旧式の xlate であることを示します。
-
per-session PAT 機能:クラスタリングに限りませんが、per-session PAT 機能によって PAT の拡張性が向上します。クラスタリングの場合は、各データノードが独自の PAT 接続を持てます。対照的に、multi-session PAT 接続は制御ノードに転送する必要があり、制御ノードがオーナーとなります。デフォルトでは、すべての TCP トラフィックおよび UDP DNS トラフィックは per-session PAT xlate を使用します。これに対し、ICMP および他のすべての UDP トラフィックは multi-session を使用します。TCP および UDP に対しこれらのデフォルトを変更するように per-session NAT ルールを設定できますが、ICMP に per-session PAT を設定することはできません。H.323、SIP、または Skinny などの multi-session PAT のメリットを活用できるトラフィックでは、関連付けられている TCP ポートに対し per-session PAT を無効にできます(それらの H.323 および SIP の UDP ポートはデフォルトですでに multi-session になっています)。per-session PAT の詳細については、ファイアウォールの設定ガイドを参照してください。
-
次のインスペクション用のスタティック PAT はありません。
-
FTP
-
PPTP
-
RSH
-
SQLNET
-
TFTP
-
XDMCP
-
SIP
-
-
1 万を超える非常に多くの NAT ルールがある場合は、デバイスの CLI で asp rule-engine transactional-commit nat コマンドを使用してトランザクション コミット モデルを有効にする必要があります。有効にしないと、ノードがクラスタに参加できない可能性があります。
SCTP とクラスタリング
SCTP アソシエーションは、(ロードバランシングにより)任意のノードに作成できますが、マルチホーミング接続は同じノードに存在する必要があります。
SIP インスペクションとクラスタリング
制御フローは、(ロードバランシングにより)任意のノードに作成できますが、子データフローは同じノードに存在する必要があります。
TLS プロキシ設定はサポートされていません。
SNMP とクラスタリング
SNMP エージェントは、個々の ASA を、その 診断インターフェイスのローカル IP アドレスによってポーリングします。クラスタの統合データをポーリングすることはできません。
SNMP ポーリングには、メイン クラスタ IP アドレスではなく、常にローカル アドレスを使用してください。SNMP エージェントがメインクラスタ IP アドレスをポーリングする場合、新しい制御ノードが選択されると、新しい制御ノードのポーリングは失敗します。
クラスタリングで SNMPv3 を使用している場合、最初のクラスタ形成後に新しいクラスタノードを追加すると、SNMPv3 ユーザーは新しいノードに複製されません。SNMPv3 ユーザーは、制御ノードに再追加して、新しいノードに強制的に複製するようにするか、データノードに直接追加する必要があります。
STUN とクラスタリング
ピンホールが複製されるとき、STUN インスペクションはフェールオーバー モードとクラスタ モードでサポートされます。ただし、トランザクション ID はノード間で複製されません。STUN 要求の受信後にノードに障害が発生し、別のノードが STUN 応答を受信した場合、STUN 応答はドロップされます。
syslog とクラスタリング
-
Syslog:クラスタの各ノードは自身の syslog メッセージを生成します。ロギングを設定して、各ノードの syslog メッセージ ヘッダー フィールドで同じデバイス ID を使用するか、別の ID を使用するかを設定できます。たとえば、ホスト名設定はクラスタ内のすべてのノードに複製されて共有されます。ホスト名をデバイス ID として使用するようにロギングを設定した場合、すべてのノードで生成される syslog メッセージが 1 つのノードから生成されているように見えます。クラスタブートストラップ設定で割り当てられたローカルノード名をデバイス ID として使用するようにロギングを設定した場合、syslog メッセージはそれぞれ別のノードから生成されているように見えます。
-
NetFlow:クラスタの各ノードは自身の NetFlow ストリームを生成します。NetFlow コレクタは、各 ASA を独立した NetFlow エクスポータとしてのみ扱うことができます。
Cisco TrustSec とクラスタリング
制御ノードだけがセキュリティグループタグ(SGT)情報を学習します。その後、制御ノードからデータノードに SGT が渡されるため、データノードは、セキュリティポリシーに基づいて SGT の一致を判断できます。
VPN とクラスタリング
サイト間 VPN は、中央集中型機能です。制御ノードのみが VPN 接続をサポートします。
(注) |
リモート アクセス VPN は、クラスタリングではサポートされません。 |
VPN 機能を使用できるのは制御ノードだけであり、クラスタの高可用性機能は活用されません。制御ノードで障害が発生した場合は、すべての既存の VPN 接続が失われ、VPN ユーザにとってはサービスの中断となります。新しい制御ノードが選定されたときに、VPN 接続を再確立する必要があります。
PBR または ECMP を使用するときの個別インターフェイスへの接続については、ローカル アドレスではなく、常にメイン クラスタ IP アドレスに接続する必要があります。
VPN 関連のキーと証明書は、すべてのノードに複製されます。
パフォーマンス スケーリング係数
複数のユニットをクラスタに結合すると、期待できる合計クラスタパフォーマンスは、最大合計スループットの約 80%になります。
たとえば、モデルが単独稼働で約 10 Gbps のトラフィックを処理できる場合、8 ユニットのクラスタでは、最大合計スループットは 80 Gbps(8 ユニット x 10 Gbps)の約 80% で 64 Gbps になります。
制御ノードの選定
クラスタのノードは、クラスタ制御リンクを介して通信して制御ノードを選定します。方法は次のとおりです。
-
ノードに対してクラスタリングをイネーブルにしたとき(または、クラスタリングがイネーブル済みの状態でそのユニットを初めて起動したとき)に、そのノードは選定要求を 3 秒間隔でブロードキャストします。
-
プライオリティの高い他のノードがこの選定要求に応答します。プライオリティは 1 ~ 100 の範囲内で設定され、1 が最高のプライオリティです。
-
45 秒経過しても、プライオリティの高い他のノードからの応答を受信していない場合は、そのノードが制御ノードになります。
(注)
最高のプライオリティを持つノードが複数ある場合は、クラスタノード名、次にシリアル番号を使用して制御ノードが決定されます。
-
後からクラスタに参加したノードのプライオリティの方が高い場合でも、そのノードが自動的に制御ノードになることはありません。既存の制御ノードは常に制御ノードのままです。ただし、制御ノードが応答を停止すると、その時点で新しい制御ノードが選定されます。
-
「スプリットブレイン」シナリオで一時的に複数の制御ノードが存在する場合、優先順位が最も高いノードが制御ノードの役割を保持し、他のノードはデータノードの役割に戻ります。
(注) |
ノードを手動で強制的に制御ノードにすることができます。中央集中型機能については、制御ノード変更を強制するとすべての接続がドロップされるので、新しい制御ノード上で接続を再確立する必要があります。 |
クラスタ内のハイアベイラビリティ
クラスタリングは、ノードとインターフェイスの正常性をモニターし、ノード間で接続状態を複製することにより、ハイアベイラビリティを実現します。
ノードヘルスモニタリング
各ノードは、クラスタ制御リンクを介してブロードキャスト ハートビート パケットを定期的に送信します。設定可能なタイムアウト期間内にデータノードからハートビートパケットまたはその他のパケットを受信しない場合、制御ノードはクラスタからデータノードを削除します。データノードが制御ノードからパケットを受信しない場合、残りのノードから新しい制御ノードが選択されます。
ノードで実際に障害が発生したためではなく、ネットワークの障害が原因で、ノードがクラスタ制御リンクを介して相互に通信できない場合、クラスタは「スプリットブレイン」シナリオに移行する可能性があります。このシナリオでは、分離されたデータノードが独自の制御ノードを選択します。たとえば、2 つのクラスタロケーション間でルータに障害が発生した場合、ロケーション 1 の元の制御ノードは、ロケーション 2 のデータノードをクラスタから削除します。一方、ロケーション 2 のノードは、独自の制御ノードを選択し、独自のクラスタを形成します。このシナリオでは、非対称トラフィックが失敗する可能性があることに注意してください。クラスタ制御リンクが復元されると、より優先順位の高い制御ノードが制御ノードの役割を保持します。
インターフェイス モニタリング
各ノードは、使用中のすべての指名されたハードウェア インターフェイスのリンクステータスをモニタし、ステータス変更を制御ノードに報告します。
ヘルスモニタリングを有効化すると、すべての物理インターフェイスがデフォルトでモニターされるため、オプションでインターフェイスごとのモニタリングを無効化することができます。指名されたインターフェイスのみモニターできます。
ノードのモニタ対象のインターフェイスが失敗した場合、そのノードはクラスタから削除されます。ASA がメンバーをクラスタから削除するまでの時間は、そのノードが確立済みメンバーであるか、またはクラスタに参加しようとしているかによって異なります。ASA は、ノードがクラスタに参加する最初の 90 秒間はインターフェイスを監視しません。この間にインターフェイスのステータスが変化しても、ASA はクラスタから削除されません。ノード状態に関係なく、ノードは 500 ミリ秒後に削除されます。
障害後のステータス
制御ノードで障害が発生した場合、そのクラスタの他のメンバーのうち、優先順位が最高(番号が最小)のメンバーが制御ノードになります。
障害イベントに応じて、ASA は自動的にクラスタへの再参加を試みます。
(注) |
ASA が非アクティブになり、クラスタへの自動再参加に失敗すると、すべてのデータインターフェイスがシャットダウンされ、管理専用インターフェイスのみがトラフィックを送受信できます。管理インターフェイスは、そのノードがクラスタ IP プールから受け取った IP アドレスを使用して引き続き稼働状態となります。ただし、リロードする場合、クラスタでノードがまだ非アクティブになっていると、管理インターフェイスは無効になります。さらに設定を行う場合は、コンソールポートを使用する必要があります。 |
クラスタへの再参加
クラスタノードがクラスタから削除された後、クラスタに再参加するための方法は、削除された理由によって異なります。
-
クラスタ制御リンクの障害:(最初の参加時)クラスタ制御リンクの問題を解決した後、CLI で cluster group 名 を入力してから enable と入力して、クラスタリングを再び有効化することによって、手動でクラスタに再参加する必要があります。
-
クラスタに参加した後に障害が発生したクラスタ制御リンク:ASA は、無限に 5 分ごとに自動的に再参加を試みます。この動作は設定可能です。
-
データ インターフェイスの障害:ASA は自動的に最初は 5 分後、次に 10 分後、最終的に 20 分後に再参加を試みます。20 分後に参加できない場合、ASA はクラスタリングをディセーブルにします。データインターフェイスの問題を解決した後、CLIで cluster group name と入力してから enable と入力して、クラスタリングを手動で有効化する必要があります。この動作は設定可能です。
-
ノードの障害:ノードがヘルスチェック失敗のためクラスタから削除された場合、クラスタへの再参加は失敗の原因によって異なります。たとえば、一時的な電源障害の場合は、クラスタ制御リンクが稼働していて、クラスタリングが enable コマンドでまだイネーブルになっているなら、ノードは再起動するとクラスタに再参加することを意味します。ASA は 5 秒ごとにクラスタへの再参加を試みます。
-
内部エラー:内部の障害には、アプリケーション同期のタイムアウト、矛盾したアプリケーション ステータスなどがあります。ノードは、5 分、10 分、20 分の間隔で自動的にクラスタに再参加しようとします。この動作は設定可能です。
データ パス接続状態の複製
どの接続にも、1 つのオーナーおよび少なくとも 1 つのバックアップ オーナーがクラスタ内にあります。バックアップ オーナーは、障害が発生しても接続を引き継ぎません。代わりに、TCP/UDP のステート情報を保存します。これは、障害発生時に接続が新しいオーナーにシームレスに移管されるようにするためです。バックアップ オーナーは通常ディレクタでもあります。
トラフィックの中には、TCP または UDP レイヤよりも上のステート情報を必要とするものがあります。この種類のトラフィックに対するクラスタリングのサポートの可否については、次の表を参照してください。
|
トラフィック |
状態のサポート |
注 |
|---|---|---|
|
アップ タイム |
対応 |
システム アップ タイムをトラッキングします。 |
|
ARP テーブル |
対応 |
— |
|
MAC アドレス テーブル |
対応 |
— |
|
ユーザ アイデンティティ |
対応 |
AAA ルール(uauth)が含まれます。 |
|
IPv6 ネイバー データベース |
対応 |
— |
|
ダイナミック ルーティング |
対応 |
— |
|
SNMP エンジン ID |
なし |
— |
|
Firepower 4100/9300 の分散型 VPN(サイト間) |
対応 |
バックアップ セッションがアクティブ セッションになると、新しいバックアップ セッションが作成されます。 |
クラスタが接続を管理する方法
接続をクラスタの複数のノードにロードバランシングできます。接続のロールにより、通常動作時とハイ アベイラビリティ状況時の接続の処理方法が決まります。
接続のロール
接続ごとに定義された次のロールを参照してください。
-
オーナー:通常、最初に接続を受信するノード。オーナーは、TCP 状態を保持し、パケットを処理します。1 つの接続に対してオーナーは 1 つだけです。元のオーナーに障害が発生すると、新しいノードが接続からパケットを受信したときにディレクタがそれらのノードの新しいオーナーを選択します。
-
バックアップオーナー:オーナーから受信した TCP/UDP ステート情報を格納するノード。障害が発生した場合、新しいオーナーにシームレスに接続を転送できます。バックアップ オーナーは、障害発生時に接続を引き継ぎません。オーナーが使用不可能になった場合、(ロードバランシングに基づき)その接続からのパケットを受信する最初のノードがバックアップオーナーに問い合わせて、関連するステート情報を取得し、そのノードが新しいオーナーになります。
ディレクタ(下記参照)がオーナーと同じノードでない限り、ディレクタはバックアップオーナーでもあります。オーナーが自分をディレクタとして選択した場合は、別のバックアップ オーナーが選択されます。
1 台のシャーシに最大 3 つのクラスタノードを搭載できる Firepower 9300 のクラスタリングでは、バックアップオーナーがオーナーと同じシャーシにある場合、シャーシ障害からフローを保護するために、別のシャーシから追加のバックアップオーナーが選択されます。
サイト間クラスタリングのディレクタ ローカリゼーションを有効にすると、ローカル バックアップとグローバル バックアップの 2 つのバックアップ オーナー権限があります。オーナーは、常に同じサイトのローカル バックアップをオーナー自身として選択します(サイト ID に基づいて)。グローバルバックアップはどのサイトにも配置でき、ローカルバックアップと同一ノードとすることもできます。オーナーは、両方のバックアップへ接続ステート情報を送信します。
サイトの冗長性が有効になっており、バックアップ オーナーがオーナーと同じサイトに配置されている場合は、サイトの障害からフローを保護するために、別のサイトから追加のバックアップ オーナーが選択されます。シャーシ バックアップとサイト バックアップは独立しているため、フローにはシャーシ バックアップとサイト バックアップの両方が含まれている場合があります。
-
ディレクタ:フォワーダからのオーナールックアップ要求を処理するノード。オーナーは、新しい接続を受信すると、送信元/宛先 IP アドレスおよびポートのハッシュに基づいてディレクタを選択し、新しい接続を登録するためにそのディレクタにメッセージを送信します。パケットがオーナー以外のノードに到着した場合、そのノードはどのノードがオーナーかをディレクタに問い合わせることで、パケットを転送できます。1 つの接続に対してディレクタは 1 つだけです。ディレクタが失敗すると、オーナーは新しいディレクタを選択します。
ディレクタがオーナーと同じノードでない限り、ディレクタはバックアップオーナーでもあります(上記参照)。オーナーがディレクタとして自分自身を選択すると、別のバックアップ オーナーが選択されます。
サイト間クラスタリングのディレクタ ローカリゼーションを有効にすると、ローカル ディレクタとグローバル ディレクタの 2 つのディレクタ権限が区別されます。オーナーは、同一サイト(Site Id に基づき)のローカル ディレクタとして、常にオーナー自身を選択します。グローバルディレクタはどのサイトにも配置でき、ローカルディレクタと同一ノードとすることもできます。最初のオーナーに障害が発生すると、ローカル ディレクタは、同じサイトの新しい接続オーナーを選択します。
ICMP/ICMPv6 ハッシュの詳細:
-
エコーパケットの場合、送信元ポートは ICMP 識別子で、宛先ポートは 0 です。
-
応答パケットの場合、送信元ポートは 0 で、宛先ポートは ICMP 識別子です。
-
他のパケットの場合、送信元ポートと宛先ポートの両方が 0 です。
-
-
フォワーダ:パケットをオーナーに転送するノード。フォワーダが接続のパケットを受信したときに、その接続のオーナーが自分ではない場合は、フォワーダはディレクタにオーナーを問い合わせてから、そのオーナーへのフローを確立します。これは、この接続に関してフォワーダが受信するその他のパケット用です。ディレクタは、フォワーダにもなることができます。ディレクタ ローカリゼーションを有効にすると、フォワーダは常にローカル ディレクタに問い合わせを行います。フォワーダがグローバル ディレクタに問い合わせを行うのは、ローカル ディレクタがオーナーを認識していない場合だけです。たとえば、別のサイトで所有されている接続のパケットをクラスタ メンバーが受信する場合などです。フォワーダが SYN-ACK パケットを受信した場合、フォワーダはパケットの SYN クッキーからオーナーを直接取得できるので、ディレクタに問い合わせる必要がないことに注意してください。(TCP シーケンスのランダム化を無効にした場合は、SYN Cookie は使用されないので、ディレクタへの問い合わせが必要です)。存続期間が短いフロー(たとえば DNS や ICMP)の場合は、フォワーダは問い合わせの代わりにパケットを即座にディレクタに送信し、ディレクタがそのパケットをオーナーに送信します。1 つの接続に対して、複数のフォワーダが存在できます。最も効率的なスループットを実現できるのは、フォワーダが 1 つもなく、接続のすべてのパケットをオーナーが受信するという、優れたロードバランシング方法が使用されている場合です。
(注)
クラスタリングを使用する場合は、TCP シーケンスのランダム化を無効にすることは推奨されません。SYN/ACK パケットがドロップされる可能性があるため、一部の TCP セッションが確立されない可能性があります。
-
フラグメントオーナー:フラグメント化されたパケットの場合、フラグメントを受信するクラスタノードは、フラグメントの送信元と宛先の IP アドレス、およびパケット ID のハッシュを使用してフラグメントオーナーを特定します。その後、すべてのフラグメントがクラスタ制御リンクを介してフラグメント所有者に転送されます。スイッチのロードバランスハッシュで使用される 5 タプルは、最初のフラグメントにのみ含まれているため、フラグメントが異なるクラスタノードにロードバランシングされる場合があります。他のフラグメントには、送信元ポートと宛先ポートは含まれず、他のクラスタノードにロードバランシングされる場合があります。フラグメント所有者は一時的にパケットを再アセンブルするため、送信元/宛先 IP アドレスとポートのハッシュに基づいてディレクタを決定できます。新しい接続の場合は、フラグメントの所有者が接続所有者として登録されます。これが既存の接続の場合、フラグメント所有者は、クラスタ制御リンクを介して、指定された接続所有者にすべてのフラグメントを転送します。その後、接続の所有者はすべてのフラグメントを再構築します。
接続でポート アドレス変換(PAT)を使用すると、PAT のタイプ(per-session または multi-session)が、クラスタのどのメンバが新しい接続のオーナーになるかに影響します。
-
per-session PAT:オーナーは、接続の最初のパケットを受信するノードです。
デフォルトでは、TCP および DNS UDP トラフィックは per-session PAT を使用します。
-
multi-session PAT:オーナーは常に制御ノードです。multi-session PAT 接続がデータノードで最初に受信される場合、データノードがその接続を制御ノードに転送します。
デフォルトでは、UDP(DNS UDP を除く)および ICMP トラフィックは multi-session PAT を使用するため、それらの接続は常に制御ノードによって所有されています。
TCP および UDP の per-session PAT デフォルトを変更できるので、これらのプロトコルの接続は、その設定に応じて per-session または multi-session で処理されます。ICMP の場合は、デフォルトの multi-session PAT から変更することはできません。per-session PAT の詳細については、『ファイアウォールの構成ガイド』を参照してください。
新しい接続の所有権
新しい接続がロードバランシング経由でクラスタのノードに送信される場合は、そのノードがその接続の両方向のオーナーとなります。接続のパケットが別のノードに到着した場合は、そのパケットはクラスタ制御リンクを介してオーナーノードに転送されます。最適なパフォーマンスを得るには、適切な外部ロードバランシングが必要です。1 つのフローの両方向が同じノードに到着するとともに、フローがノード間に均等に分散されるようにするためです。逆方向のフローが別のノードに到着した場合は、元のノードにリダイレクトされます。
TCP のサンプルデータフロー
次の例は、新しい接続の確立を示します。
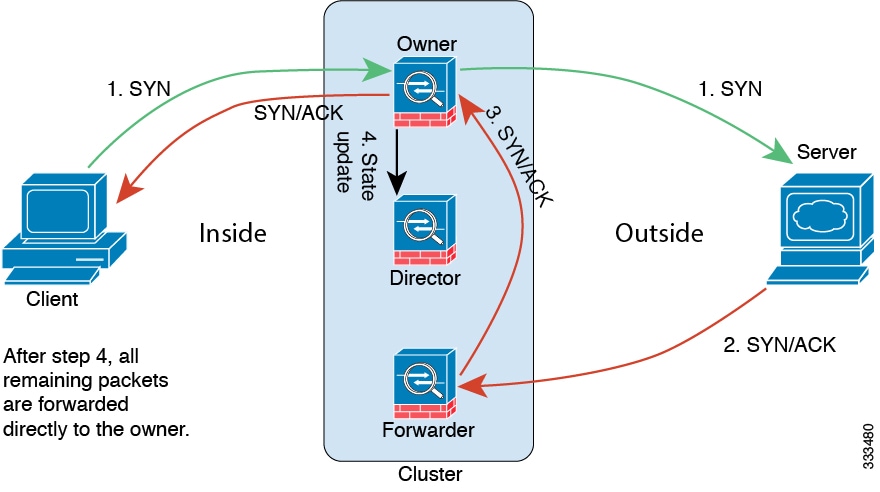
-
SYN パケットがクライアントから発信され、ASA の 1 つ(ロード バランシング方法に基づく)に配信されます。これがオーナーとなります。オーナーはフローを作成し、オーナー情報をエンコードして SYN Cookie を生成し、パケットをサーバに転送します。
-
SYN-ACK パケットがサーバから発信され、別の ASA(ロード バランシング方法に基づく)に配信されます。この ASA はフォワーダです。
-
フォワーダはこの接続を所有してはいないので、オーナー情報を SYN Cookie からデコードし、オーナーへの転送フローを作成し、SYN-ACK をオーナーに転送します。
-
オーナーはディレクタに状態アップデートを送信し、SYN-ACK をクライアントに転送します。
-
ディレクタは状態アップデートをオーナーから受信し、オーナーへのフローを作成し、オーナーと同様に TCP 状態情報を記録します。ディレクタは、この接続のバックアップ オーナーとしての役割を持ちます。
-
これ以降、フォワーダに配信されたパケットはすべて、オーナーに転送されます。
-
パケットがその他のノードに配信された場合、そのノードはディレクタに問い合わせてオーナーを特定し、フローを確立します。
-
フローの状態が変化した場合は、状態アップデートがオーナーからディレクタに送信されます。
ICMP および UDP のサンプルデータフロー
次の例は、新しい接続の確立を示します。
-
図 9. ICMP および UDP データフロー 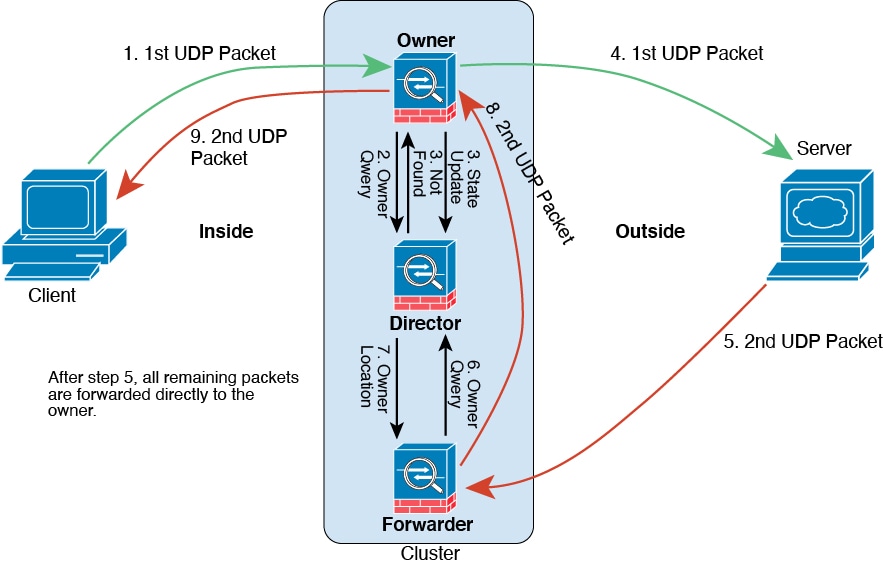
-
最初のパケットを受信したノードは、送信元/宛先 IP アドレスとポートのハッシュに基づいて選択されたディレクタノードをクエリします。
-
ディレクタは既存のフローを検出せず、ディレクタフローを作成して、以前のノードにパケットを転送します。つまり、ディレクタがこのフローのオーナーを選択したことになります。
-
オーナーはフローを作成し、ディレクタに状態アップデートを送信して、サーバーにパケットを転送します。
-
2 番目の UDP パケットはサーバーから発信され、フォワーダに配信されます。
-
フォワーダはディレクタに対して所有権情報をクエリします。存続期間が短いフロー(DNS など)の場合、フォワーダはクエリする代わりにパケットを即座にディレクタに送信し、ディレクタがそのパケットをオーナーに送信します。
-
ディレクタは所有権情報をフォワーダに返信します。
-
フォワーダは転送フローを作成してオーナー情報を記録し、パケットをオーナーに転送します。
-
オーナーはパケットをクライアントに転送します。
パブリッククラウドにおける ASA Virtual クラスタリングの履歴
|
機能 |
バージョン |
詳細 |
|---|---|---|
| AWS における GWLB を使用した ASA Virtual クラスタリングのターゲットフェールオーバーの設定 | 9.20(1) | AWS でターゲットフェールオーバー機能を使用すると、計画メンテナンス中またはターゲットノードの障害時にノードの登録が解除された場合に、GWLB がネットワークパケットを正常なターゲットノードにリダイレクトできるようになります。この機能ではクラスタのステートフル フェールオーバーを利用しています。 |
|
フローステータスの設定可能なクラスタキープアライブ間隔 |
9.20(1) |
フローオーナーは、キープアライブ(clu_keepalive メッセージ)と更新(clu_update メッセージ)をディレクタおよびバックアップオーナーに送信して、フローの状態を更新します。キープアライブ間隔を設定できるようになりました。デフォルトは 15 秒で、15 ~ 55 秒の範囲で間隔を設定できます。クラスタ制御リンクのトラフィック量を減らすために長い間隔を設定できます。 新規/変更されたコマンド: clu-keepalive-interval |
|
ASA Virtual Amazon Web Services(AWS)クラスタリング |
9.19(1) |
ASA Virtual は AWS で最大 16 ノードの個別インターフェイスのクラスタリングをサポートします。AWS ゲートウェイロードバランサ の有無にかかわらず、クラスタリングを使用できます。 |
 フィードバック
フィードバック