クラスタリングを利用すると、複数の Threat Defense Virtual をグループ化して 1 つの論理デバイスとすることができます。クラスタは、単一デバイスのすべての利便性(管理、ネットワークへの統合)を備える一方で、複数デバイスによって高いスループットおよび冗長性を達成します。
現在は、ルーテッド ファイアウォール モードのみがサポートされます。
 (注) |
クラスタリングを使用する場合、一部の機能はサポートされません。詳細については、 |
GCP での Threat Defense Virtual クラスタリングについて
ここでは、クラスタリング アーキテクチャとその動作について説明します。
クラスタをネットワークに適合させる方法
クラスタは、複数のファイアウォールで構成され、これらは 1 つのデバイスとして機能します。ファイアウォールをクラスタとして機能させるには、次のインフラストラクチャが必要です。
-
クラスタ内通信用の、隔離されたネットワーク。VXLAN インターフェイスを使用したクラスタ制御リンクと呼ばれます。レイヤ 3 物理ネットワーク上でレイヤ 2 仮想ネットワークとして機能する VXLAN により、Threat Defense Virtual はクラスタ制御リンクを介してブロードキャスト/マルチキャストメッセージを送信できます。
-
ロードバランサ:外部ロードバランシングには、次のオプションがあります。
-
内部および外部のネイティブ GCP ロードバランサ
-
シスコ クラウド サービス ルータなどの内部および外部ルータを使用した等コスト マルチパス ルーティング(ECMP)
ECMP ルーティングでは、ルーティング メトリックが同値で最高である複数の「最適パス」を介してパケットを転送できます。EtherChannel のように、送信元および宛先の IP アドレスや送信元および宛先のポートのハッシュを使用してネクスト ホップの 1 つにパケットを送信できます。ECMP ルーティングにスタティックルートを使用する場合は、Threat Defense の障害発生時に問題が起きることがあります。ルートは引き続き使用されるため、障害が発生した Threat Defense へのトラフィックが失われるからです。スタティック ルートを使用する場合は必ず、オブジェクト トラッキングなどのスタティック ルート モニタリング機能を使用してください。ダイナミック ルーティング プロトコルを使用してルートの追加と削除を行うことを推奨します。この場合は、ダイナミック ルーティングに参加するように各 Threat Defense を設定する必要があります。
(注)
レイヤ 2 スパンド EtherChannels はロードバランシングではサポートされません。
-
個々のインターフェイス
クラスターフェイスを個々のインターフェイスとして設定できます。
個別インターフェイスは通常のルーテッド インターフェイスであり、それぞれが専用のローカル IP アドレスを持ちます。インターフェイス構成は、制御ノードでのみ設定する必要があり、各インターフェイスは DHCP を使用します。
(注) |
レイヤ 2 スパンド EtherChannels はサポートされません。 |
制御ノードとデータノードの役割
クラスタ内のメンバーの 1 つが制御ノードになります。複数のクラスタノードが同時にオンラインになる場合、制御ノードは、プライオリティ設定によって決まります。プライオリティは 1 ~ 100 の範囲内で設定され、1 が最高のプライオリティです。他のすべてのメンバーはデータノードです。 最初にクラスタを作成するときに、制御ノードにするノードを指定します。これは、クラスタに追加された最初のノードであるため、制御ノードになります。
クラスタ内のすべてのノードは、同一の設定を共有します。最初に制御ノードとして指定したノードは、データノードがクラスタに参加するときにその設定を上書きします。そのため、クラスタを形成する前に制御ノードで初期設定を実行するだけで済みます。
機能によっては、クラスタ内でスケーリングしないものがあり、そのような機能については制御ノードがすべてのトラフィックを処理します。
クラスタ制御リンク
ノードごとに 1 つのインターフェイスをクラスタ制御リンク専用の VXLAN(VTEP)インターフェイスにする必要があります。
VXLAN トンネル エンドポイント
VXLAN トンネル エンドポイント(VTEP)デバイスは、VXLAN のカプセル化およびカプセル化解除を実行します。各 VTEP には 2 つのインターフェイスタイプ(VXLAN Network Identifier(VNI)インターフェイスと呼ばれる 1 つ以上の仮想インターフェイスと、 VTEP 間に VNI をトンネリングする VTEP 送信元インターフェイスと呼ばれる通常のインターフェイス)がありますVTEP 送信元インターフェイスは、VTEP 間通信のトランスポート IP ネットワークに接続されます。
VTEP 送信元インターフェイス
VTEP 送信元インターフェイスは、VNI インターフェイスに関連付けられる予定の標準の Threat Defense Virtual インターフェイスです。1 つの VTEP ソースインターフェイスをクラスタ制御リンクとして機能するように設定できます。ソースインターフェイスは、クラスタ制御リンクの使用専用に予約されています。各 VTEP ソースインターフェイスには、同じサブネット上の IP アドレスがあります。このサブネットは、他のすべてのトラフィックからは隔離し、 クラスタ制御リンクインターフェイスだけが含まれるようにしてください。
VNI インターフェイス
VNI インターフェイスは VLAN インターフェイスに似ています。VNI インターフェイスは、タギングを使用して特定の物理インターフェイスでのネットワークトラフィックの分割を維持する仮想インターフェイスです。設定できる VNI インターフェイスは 1 つだけです。各 VNI インターフェイスは、同じサブネット上の IP アドレスを持ちます。
ピア VTEP
単一の VTEP ピアを許可するデータインターフェイス用の通常の VXLAN とは異なり、Threat Defense Virtual クラスタリングでは複数のピアを設定できます。
クラスタ制御リンク トラフィックの概要
クラスタ制御リンク トラフィックには、制御とデータの両方のトラフィックが含まれます。
制御トラフィックには次のものが含まれます。
-
制御ノードの選択。
-
設定の複製。
-
ヘルス モニタリング。
データ トラフィックには次のものが含まれます。
-
状態の複製。
-
接続所有権クエリおよびデータ パケット転送。
コンフィギュレーションの複製
クラスタ内のすべてのノードは、単一の設定を共有します。設定の変更は制御ノードでのみ可能(ブートストラップ設定は除く)で、変更はクラスタに含まれる他のすべてのノードに自動的に同期されます。
管理ネットワーク
管理インターフェイスを使用して各ノードを管理する必要があります。クラスタリングでは、データインターフェイスからの管理はサポートされていません。
Threat Defense Virtual クラスタリングのライセンス
各 Threat Defense Virtual クラスタノードには、同じパフォーマンス階層ライセンスが必要です。すべてのメンバーに同じ数の CPU とメモリを使用することをお勧めします。そうしないと、パフォーマンスが最小能力のメンバーに一致するようにすべてのノードで制限されます。スループットレベルは、一致するように制御ノードから各データノードに複製されます。
個別のノードではなく、クラスタ全体に機能ライセンスを割り当てます。ただし、クラスタの各ノードは機能ごとに個別のライセンスを使用します。クラスタリング機能自体にライセンスは必要ありません。
制御ノードを Management Center に追加する際に、そのクラスタに使用する機能ライセンスを指定できます。クラスタのライセンスは、 領域で変更できます。
(注) |
Management Center にライセンスを取得する(および評価モードで実行する)前にクラスタを追加した場合、Management Center にライセンスを取得する際にポリシーの変更をクラスタに展開するとトラフィックの中断が発生することがあります。ライセンスモードを変更したことによって、すべてのデータユニットがクラスタをいったん離れてから再参加することになります。 |
Threat Defense Virtual クラスタリングの要件および前提条件
モデルの要件
-
FTDv5、FTDv10、FTDv20、FTDv30、FTDv50、FTDv100
-
最大 16 ノード
Cisco Secure Firewall Threat Defense Virtual スタートアップガイド の Threat Defense Virtual の一般要件も参照してください。
ユーザの役割
-
管理者
-
アクセス管理者
-
ネットワーク管理者
ハードウェアおよびソフトウェアの要件
クラスタ内のすべてのユニット:
-
同じパフォーマンス層内にある必要があります。すべてのノードに同じ数の CPU とメモリを使用することをお勧めします。そうしないと、パフォーマンスが最小能力のノードに一致するようにすべてのノードで制限されます。
-
Management Center へのアクセスは管理インターフェイスから行うこと。データインターフェイスの管理はサポートされていません。
-
イメージ アップグレード時を除き、同じソフトウェアを実行する必要があります。ヒットレス アップグレードがサポートされます。
-
クラスタ内のすべてのユニットは、同じ可用性ゾーンに展開する必要があります。
-
すべてのユニットのクラスタ制御リンクインターフェイスは、同じサブネット内にある必要があります。
MTU
クラスタ制御リンクに接続されているポートに適切な MTU 値(高い値) が設定されていること。MTU の不一致がある場合、クラスタの形成に失敗します。クラスタ制御リンクの MTU は、データインターフェイスよりも 154 バイト大きく設定されているはずです。クラスタ制御リンクのトラフィックにはデータパケット転送が含まれるため、クラスタ制御リンクはデータパケット全体のサイズに加えてクラスタトラフィックのオーバーヘッド(100 バイト)と VXLAN のオーバーヘッド(54 バイト)にも対応する必要があります。
次の表は、クラスタ制御リンク MTU のデフォルト値とデータインターフェイス MTU を示しています。
|
パブリック クラウド |
クラスタ制御リンク MTU |
データインターフェイス MTU |
|---|---|---|
|
GCP |
1554 |
1400 |
Threat Defense Virtual クラスタリングのガイドライン
ハイ アベイラビリティ
クラスタリングでは、高可用性はサポートされません。
IPv6
クラスタ制御リンクは、IPv4 のみを使用してサポートされます。
その他のガイドライン
-
重要なトポロジの変更(EtherChannel インターフェイスの追加や削除、Threat Defense またはスイッチのインターフェイスの有効化や無効化、VSS または vPC を形成するスイッチの追加など)が発生した場合は、ヘルスチェック機能を無効にし、無効になっているインターフェイスのインターフェイス モニタリングも無効にする必要があります。トポロジの変更が完了して、コンフィギュレーション変更がすべてのユニットに同期されたら、インターフェイスのヘルス チェック機能を再度有効にできます。
-
ノードを既存のクラスタに追加したときや、ノードをリロードしたときは、一時的に、限定的なパケット/接続ドロップが発生します。これは予定どおりの動作です。場合によっては、ドロップされたパケットが原因で接続がハングすることがあります。たとえば、FTP 接続の FIN/ACK パケットがドロップされると、FTP クライアントがハングします。この場合は、FTP 接続を再確立する必要があります。
-
ノードでクラスタリングを無効にせずにノードの電源を切らないでください。
-
復号された TLS/SSL 接続の場合、復号状態は同期されず、接続オーナーに障害が発生すると、復号された接続がリセットされます。新規ノードへの接続を新たに確立する必要があります。復号されていない接続(復号しないルールに一致)は影響を受けず、正しく複製されます。
-
ダイナミックスケーリングはサポートされていません。
-
各メンテナンスウィンドウの完了後にグローバル展開を実行します。
-
インスタンスグループから一度に複数のデバイスを削除しないでください。また、インスタンスグループからデバイスを削除する前に、デバイスで cluster disable コマンドを実行することを推奨します。
-
クラスタ内のデータノードと制御ノードを無効にする場合は、制御ノードを無効にする前にデータノードを無効にすることを推奨します。クラスタ内に他のデータノードがあるときに制御ノードが無効になっている場合は、いずれかのデータノードを制御ノードに昇格させる必要があります。ロールの変更はクラスタを妨害する可能性があることに注意してください。
-
このガイドに記載されているカスタマイズした Day 0 構成スクリプトでは、要件に応じて IP アドレスを変更し、カスタムインターフェイス名を指定して、CCL-Link インターフェイスのシーケンスを変更することができます。
クラスタリングのデフォルト
-
cLACP システム ID は自動生成され、システムの優先順位はデフォルトでは 1 になっています。
-
クラスタのヘルス チェック機能は、デフォルトで有効になり、ホールド時間は 3 秒です。デフォルトでは、すべてのインターフェイスでインターネット ヘルス モニタリングが有効になっています。
-
失敗したクラスタ制御リンクのクラスタ再結合機能が 5 分おきに無制限に試行されます。
-
失敗したデータインターフェイスのクラスタ自動再結合機能は、5 分後と、2 に設定された増加間隔で合計で 3 回試行されます。
-
HTTP トラフィックでは、5 秒間の接続複製遅延がデフォルトで有効になっています。
GCP でのクラスタの展開
クラスタを GCP で展開するには、手動で展開するか、インスタンステンプレートを使用してインスタンスグループを展開します。GCP ロードバランサ、または Cisco Cloud Services Router などの非ネイティブのロードバランサでクラスタを使用できます。
(注) |
発信トラフィックはインターフェイス NAT が必要であり、64K 接続に制限されています。 |
トポロジの例
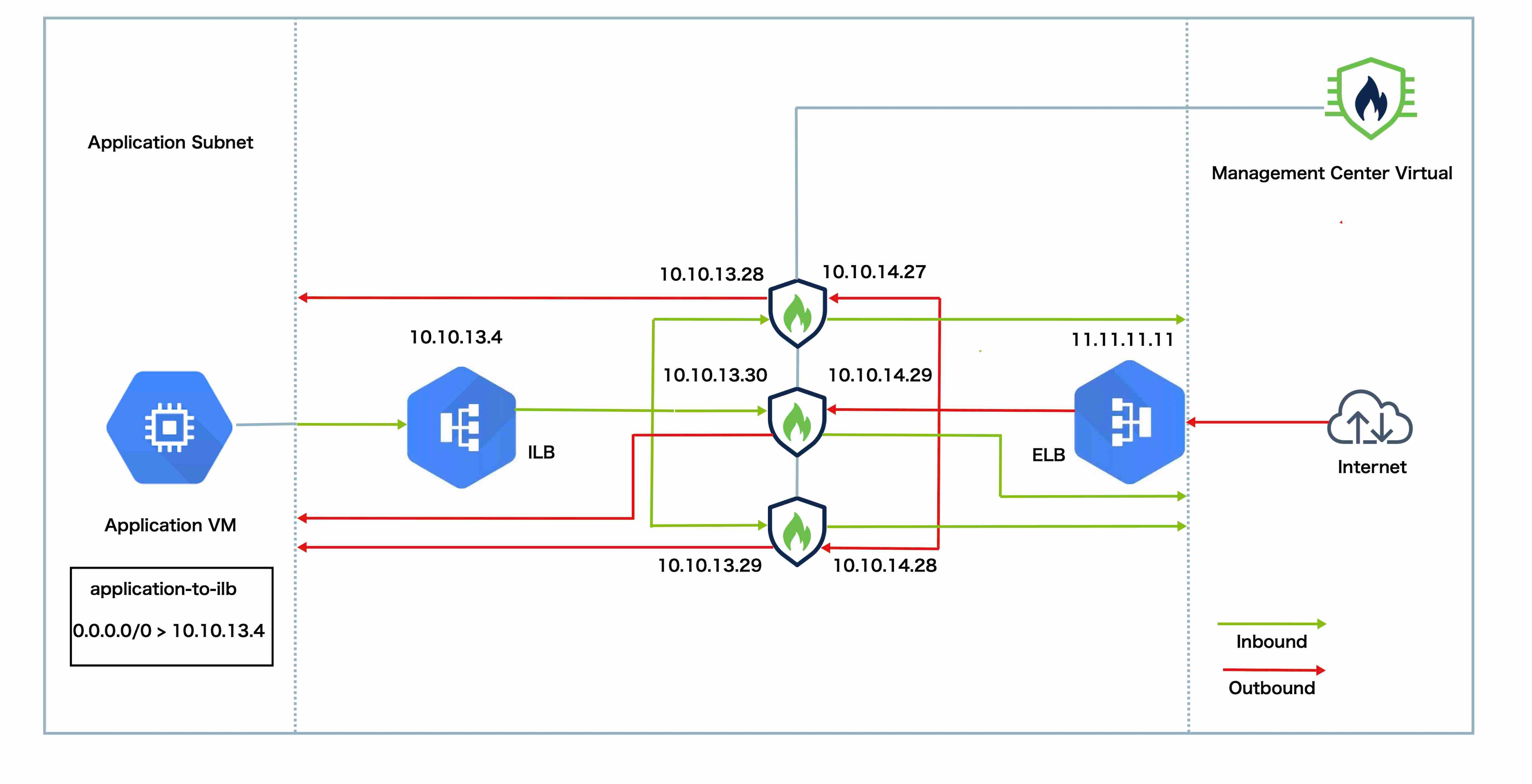
このトポロジは、着信と発信の両方のトラフィックフローを示しています。Threat Defense Virtual クラスタは、内部ロードバランサと外部ロードバランサの間に挟まれています。Management Center Virtual インスタンスは、クラスタの管理に使用されます。
インターネットからの着信トラフィックは、外部ロードバランサに送られ、そこから Threat Defense Virtual クラスタにトラフィックが送信されます。トラフィックは、クラスタ内の Threat Defense Virtual インスタンスによって検査された後、アプリケーション VM に転送されます。
アプリケーション VM からの発信トラフィックは、内部ロードバランサに送信されます。その後、トラフィックは Threat Defense Virtual クラスタに転送され、インターネットに送信されます。
GCP で Threat Defense Virtual クラスタを展開するためのエンドツーエンドのプロセス
テンプレートベースの展開
次のフローチャートは、GCP での Threat Defense Virtual クラスタのテンプレートベース展開のワークフローを示しています。

|
ワークスペース |
手順 |
|
|---|---|---|
| ローカルホスト | GitHub からテンプレートとファイルをダウンロードします。 | |
| ローカルホスト | テンプレートパラメータを編集します。 | |
| Google Cloud Platform | GCP バケットを作成します。 | |
| ローカルホスト | Google Cloud 関数ソースアーカイブファイル ftdv_cluster_function.zip を作成します。 | |
| Google Cloud Platform | Google 関数ソースアーカイブファイルをアップロードします。 | |
| Google Cloud Platform | infrastructure.yaml を展開します。 | |
| Google Cloud Platform | プライベート IP アドレスが使用されている場合は、VPC コネクタを作成します。 | |
| Google Cloud Platform | 外部 IP アドレスが使用されている場合は、cluster_function_infra.yaml で deployWithExternalIP を True に設定します。 | |
| Google Cloud Platform | クラスタ機能インフラストラクチャ テンプレートを展開します。 | |
| Google Cloud Platform | クラスタを展開します。 |
手動展開
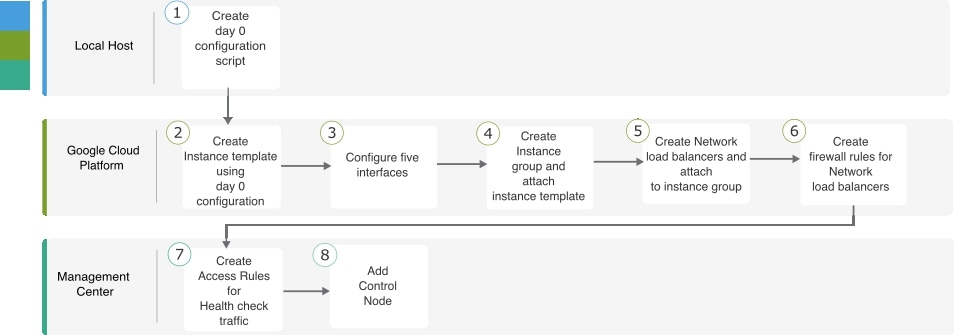
次のフローチャートは、GCP での Threat Defense Virtual クラスタの手動展開のワークフローを示しています。
|
ワークスペース |
手順 |
|
|---|---|---|
| ローカルホスト | Day 0 構成スクリプトを作成します。 | |
| Google Cloud Platform | Day 0 構成を使用してインスタンステンプレートを作成します。 | |
| Google Cloud Platform | インターフェイスを設定します。 | |
| Google Cloud Platform | インスタンスグループを作成し、インスタンステンプレートを割り当てます。 | |
| Google Cloud Platform | NLB を作成し、インスタンスグループにアタッチします。 | |
| Google Cloud Platform | NLB のファイアウォールルールを作成します。 | |
| Management Center | ヘルスチェックトラフィックのアクセスルールを作成します。 | |
| Management Center | 制御ノードを追加します。 |
テンプレート
以下のテンプレートは GitHub で入手できます。パラメータ値は、テンプレートで指定されたパラメータ名、および値であり、自明です。
-
East-West トラフィック用のクラスタ展開テンプレート:deploy_ngfw_cluster_yaml
-
North-South トラフィック用のクラスタ展開テンプレート:deploy_ngfw_cluster.yaml
インスタンステンプレートを使用した GCP でのインスタンスグループの展開
インスタンステンプレートを使用して、GCP にインスタンスグループを展開します。
始める前に
-
展開には Google Cloud Shell を使用します。または、任意の macOS/Linux/Windows マシンで Google SDK を使用できます。
-
クラスタが Management Center に自動登録されるようにするには、REST API を使用できる管理者権限を持つユーザーを Management Center で作成する必要があります。Cisco Secure Firewall Management Center アドミニストレーション ガイドを参照してください。
-
cluster_function_infra.yaml で指定したポリシー名と一致するアクセスポリシーを Management Center に追加します。
手順
|
ステップ 1 |
テンプレートを GitHub からローカルフォルダにダウンロードします。 |
|
ステップ 2 |
必要な resourceNamePrefix パラメータ(ngfwvcls など)と他の必要なユーザー入力を使用して、infrastructure.yaml、cluster_function_infra.yaml、および deploy_ngfw_cluster.yaml を編集します。 deploy_ngfw_cluster.yaml ファイルは、GitHub で east-west フォルダと north-south フォルダの両方にあることに注意してください。トラフィックフローの要件に従って、適切なテンプレートをダウンロードします。 |
|
ステップ 3 |
Google Cloud Shell を使用してバケットを作成し、Google Cloud 関数ソースアーカイブファイル ftdv_cluster_function.zip をアップロードします。 gsutil mb --pap enforced gs://resourceNamePrefix-ftdv-cluster-bucket/ ここでの resourceNamePrefix 変数が cluster_function_infra.yaml で指定した resourceNamePrefix 変数と一致していることを確認します。 |
|
ステップ 4 |
クラスタ インフラストラクチャのアーカイブファイルを作成します。 例: |
|
ステップ 5 |
前に作成した Google ソースアーカイブをアップロードします。 gsutil cp ftdv_cluster_function.zip gs://resourceNamePrefix-ftdv-cluster-bucket/ |
|
ステップ 6 |
クラスタのインフラストラクチャを展開します。 gcloud deployment-manager deployments create cluster_name --config infrastructure.yaml |
|
ステップ 7 |
プライベート IP アドレスを使用している場合は、次の手順を実行します。 |
|
ステップ 8 |
Management Center が Threat Defense Virtual からリモートに配置され、Threat Defense Virtual に外部 IP アドレスが必要な場合は、必ず cluster_function_infra.yaml で deployWithExternalIP を True に設定してください。 |
|
ステップ 9 |
クラスタ機能インフラストラクチャを展開します。 gcloud deployment-manager deployments create cluster_name --config cluster_function_infra.yaml |
|
ステップ 10 |
クラスタを展開します。
|
GCP でのクラスタの手動展開
クラスタを手動で展開するには、Day0 構成を準備し、各ノードを展開してから制御ノードを Management Center に追加します。
GCP 向け Day 0 構成の作成
固定構成またはカスタマイズ構成のいずれかを使用できます。
GCP 向け固定構成を使用した Day 0 構成の作成
固定構成により、クラスタのブートストラップ構成が自動生成されます。
{
"AdminPassword": "password",
"Hostname": "hostname",
"FirewallMode": "Routed",
"ManageLocally": "No",
"Cluster": {
"CclSubnetRange": "ip_address_start ip_address_end",
"ClusterGroupName": "cluster_name"
}
}
次に例を示します。
{
"AdminPassword": "DeanW1nche$ter",
"Hostname": "ciscoftdv",
"FirewallMode": "Routed",
"ManageLocally": "No",
"Cluster": {
"CclSubnetRange": "10.10.55.2 10.10.55.253", //mandatory user input
"ClusterGroupName": "ftdv-cluster" //mandatory user input
}
}
(注) |
上記の設定をコピーして貼り付ける場合は、設定から //mandatory user input を必ず削除してください。 |
CclSubnetRange 変数では、サブネット内の最初の 2 つの IP アドレスと最後の 2 つの IP アドレスを使用できないことに注意してください。詳細については、「Reserved IP addresses in IPv4 subnets」を参照してください。クラスタリングに使用可能な IP アドレスが 16 個以上あることを確認します。開始 IP アドレスと終了 IP アドレスの例を次に示します。
|
CIDR |
開始 IP アドレス |
終了 IP アドレス |
|---|---|---|
| 10.1.1.0/27 | 10.1.1.2 | 10.1.1.29 |
| 10.1.1.32/27 | 10.1.1.34 | 10.1.1.61 |
| 10.1.1.64/27 | 10.1.1.66 | 10.1.1.93 |
| 10.1.1.96/27 | 10.1.1.98 | 10.1.1.125 |
| 10.1.1.128/27 | 10.1.1.130 | 10.1.1.157 |
| 10.1.1.160/27 | 10.1.1.162 | 10.1.1.189 |
| 10.1.1.192/27 | 10.1.1.194 | 10.1.1.221 |
| 10.1.1.224/27 | 10.1.1.226 | 10.1.1.253 |
| 10.1.1.0/24 | 10.1.1.2 | 10.1.1.253 |
GCP 向けカスタマイズ構成を使用した Day 0 構成の作成
{
"AdminPassword": "password",
"Hostname": "hostname",
"FirewallMode": "Routed",
"ManageLocally": "No",
"run_config": [comma_separated_threat_defense_configuration]
}
次の例では、管理、内部、および外部インターフェイスと、クラスタ制御リンク用の VXLAN インターフェイスを使用して構成を作成します。太字の値はノードごとに一意である必要があることに注意してください。
{
"AdminPassword": "W1nch3sterBr0s",
"Hostname": "ftdv1",
"FirewallMode": "Routed",
"ManageLocally": "No",
"run_config": [
"cluster interface-mode individual force",
"interface Management0/0",
"management-only",
"nameif management",
"ip address dhcp",
"interface GigabitEthernet0/0",
"no shutdown",
"nameif outside",
"ip address dhcp",
"interface GigabitEthernet0/1",
"no shutdown",
"nameif inside",
"ip address dhcp",
"interface GigabitEthernet0/2",
"nve-only cluster",
"nameif ccl_link",
"ip address dhcp",
"no shutdown",
"interface vni1",
"description Clustering Interface",
"segment-id 1",
"vtep-nve 1",
"object network ccl_link",
"range 10.1.90.2 10.1.90.17",
"object-group network cluster_group",
"network-object object ccl_link",
"nve 1",
"encapsulation vxlan",
"source-interface ccl_link",
"peer-group cluster_group",
"cluster group ftdv-cluster",
"local-unit 1",
"cluster-interface vni1 ip 10.1.1.1 255.255.255.0",
"priority 1",
"enable",
"mtu outside 1400",
"mtu inside 1400"
]
}(注) |
クラスタ制御リンク ネットワーク オブジェクトには、アドレスを必要な数だけ指定します(最大 16個)。範囲を大きくすると、パフォーマンスに影響する可能性があります。 |
クラスタノードの手動展開
クラスタが形成されるようにクラスタノードを展開します。GCP でのクラスタリングの場合、4 vCPU マシンタイプは使用できません。4 vCPU マシンタイプがサポートするインターフェイスは 4 つのみですが、インターフェイスは 5 つ必要です。c2-standard-8 など、5 つのインターフェイスがサポートされるマシンタイプを使用します。
手順
|
ステップ 1 |
5 つのインターフェイス(外部、内部、管理、診断、クラスタ制御リンク)を備えた Day 0 構成を使用して、インスタンステンプレートを作成します([メタデータ(Metadata)] > [スタートアップスクリプト(Startup Script)] セクション)。 |
|
ステップ 2 |
インスタンスグループを作成し、インスタンステンプレートを割り当てます。 |
|
ステップ 3 |
GCP ネットワークロードバランサ(内部および外部)を作成し、インスタンスグループを割り当てます。 |
|
ステップ 4 |
GCP ネットワークロードバランサの場合、Management Center のセキュリティポリシーでヘルスチェックを許可します。GCP ネットワークロードバランサのヘルスチェックの許可 を参照してください。 |
|
ステップ 5 |
Management Center に制御ノードを追加します。Management Center へのクラスタの追加(手動展開) を参照してください。 |
GCP ネットワークロードバランサのヘルスチェックの許可
Google Cloud は、バックエンドがトラフィックに応答するかどうかを判断するヘルスチェック機能を提供します。
ネットワークロードバランサのファイアウォール ルールを作成するには、「https://cloud.google.com/load-balancing/docs/health-checks」を参照してください。次に、Management Center でヘルスチェックトラフィックを許可するアクセスルールを作成します。必要なネットワーク範囲については、「https://cloud.google.com/load-balancing/docs/health-check-concepts」を参照してください。
また、動的な手動 NAT ルールを設定して、ヘルスチェックトラフィックを 169.254.169.254 の Google メタデータサーバーにリダイレクトする必要もあります。
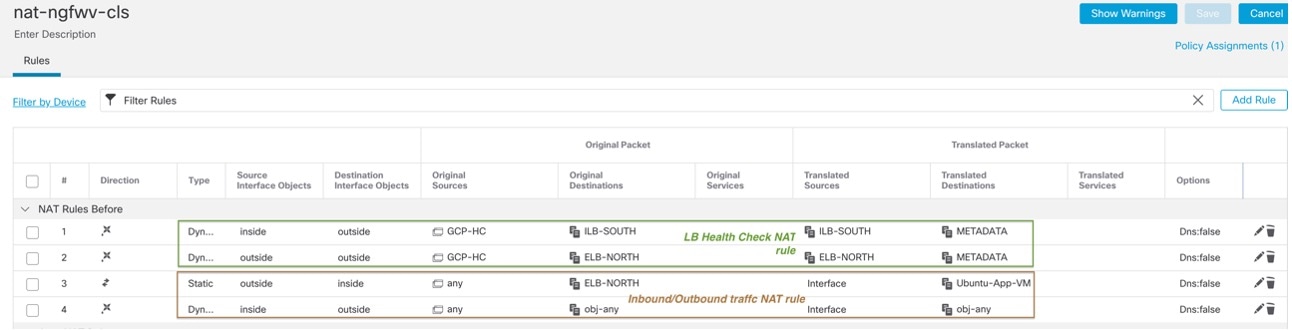
North-South NAT ルールの設定例
nat (inside,outside) source dynamic GCP-HC ILB-SOUTH destination static ILB-SOUTH METADATA
nat (outside,outside) source dynamic GCP-HC ELB-NORTH destination static ELB-NORTH METADATA
nat (outside,inside) source static any interface destination static ELB-NORTH Ubuntu-App-VM
nat (inside,outside) source dynamic any interface destination static obj-any obj-any
object network Metadata
host 169.254.169.254
object network ILB-SOUTH
host <ILB_IP>
object network ELB-NORTH
host <ELB_IP>
object-group network GCP-HC
network-object 35.191.0.0 255.255.0.0
network-object 130.211.0.0 255.255.252.0
network-object 209.85.204.0 255.255.252.0
network-object 209.85.152.0 255.255.252.0
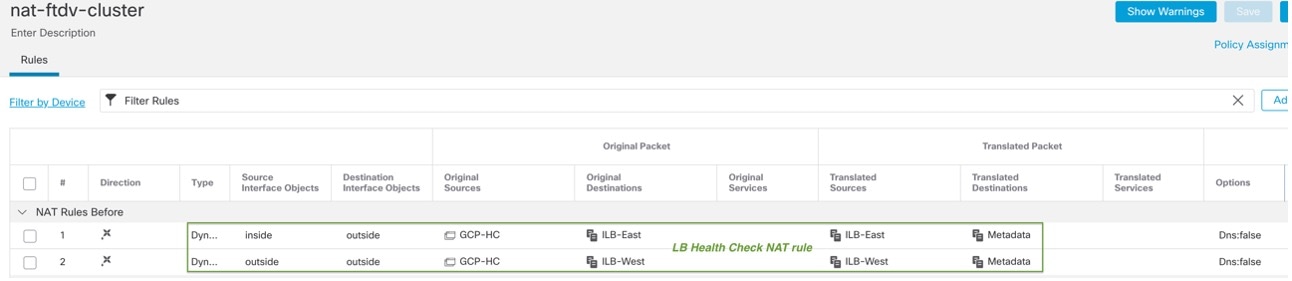
East-West NAT ルールの設定例
nat (inside,outside) source dynamic GCP-HC ILB-East destination static ILB-East Metadata
nat (outside,outside) source dynamic GCP-HC ILB-West destination static ILB-West Metadata
object network Metadata
host 169.254.169.254
object network ILB-East
host <ILB_East_IP>
object network ILB-West
host <ILB_West_IP>
object-group network GCP-HC
network-object 35.191.0.0 255.255.0.0
network-object 130.211.0.0 255.255.252.0
network-object 209.85.204.0 255.255.252.0
network-object 209.85.152.0 255.255.252.0
Management Center へのクラスタの追加(手動展開)
クラスタを手動で展開した場合は、この手順を使用してクラスタを Management Center に追加します。テンプレートを使用した場合、クラスタは自動的に Management Center に登録されます。
クラスタ ユニットのいずれかを新しいデバイスとして Management Center に追加します。Management Center は、他のすべてのクラスタ メンバーを自動検出します。
始める前に
-
すべてのクラスタユニットは、Management Center に追加する前に、正常な形式のクラスタ内に存在している必要があります。また、どのユニットが制御ユニットかを確認することも必要です。Threat Defense show cluster info コマンドを使用します。
手順
|
ステップ 1 |
Management Center で、 を選択してから、 を選択し、制御ユニットの管理 IP アドレスを使用して制御ユニットを追加します。 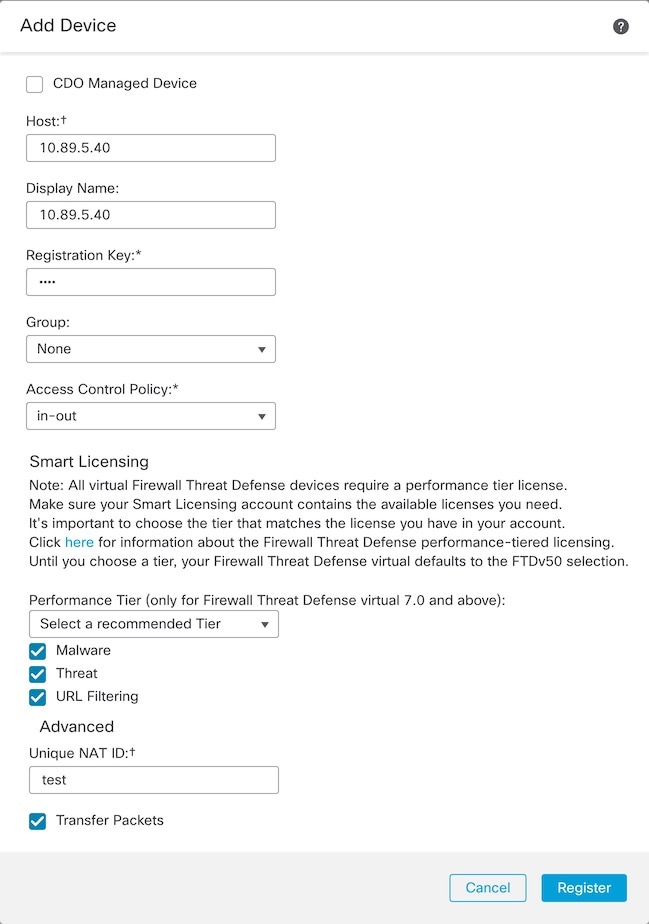
|
|
ステップ 2 |
クラスタの [編集(Edit)]( ほとんどの設定は、クラスタ内のノードではなく、クラスタ全体に適用できます。たとえば、ノードごとに表示名を変更できますが、インターフェイスはクラスタ全体についてのみ設定できます。 |
|
ステップ 3 |
画面に、[全般(General)]、[ライセンス(License)]、[システム(System)]、および [ヘルス(Health)] の設定が表示されます。
次のクラスタ固有の項目を参照してください。
|
|
ステップ 4 |
の右上のドロップダウンメニューで、クラスタ内の各メンバーを選択し、次の設定を指定することができます。
|

![[編集(Edit)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/442001-443000/442546.jpg) )
)


クラスタのヘルスモニターの設定
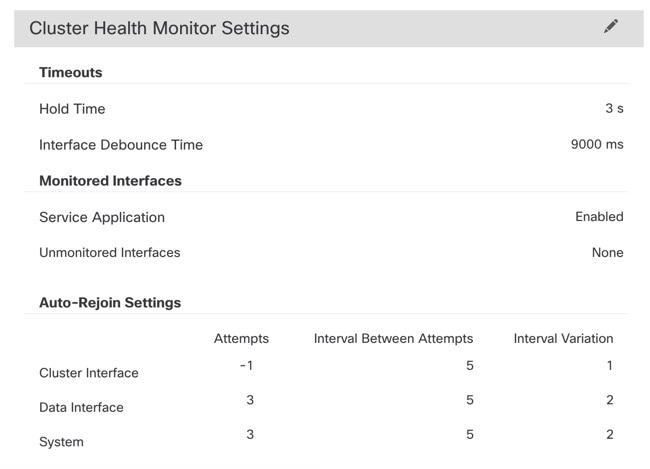
[クラスタ(Cluster)] ページの [クラスタヘルスモニターの設定(Cluster Health Monitor Settings)] セクションには、次の表で説明されている設定が表示されます。
|
フィールド |
説明 |
|---|---|
|
タイムアウト |
|
|
保留時間(Hold Time) |
ノードの状態を確認するため、クラスタノードはクラスタ制御リンクで他のノードにハートビートメッセージを送信します。ノードが保留時間内にピアノードからハートビートメッセージを受信しない場合、そのピアノードは応答不能またはデッド状態と見なされます。 |
|
インターフェイスのデバウンス時間 |
インターフェイスのデバウンス時間は、インターフェイスで障害が発生していると見なされ、クラスタからノードが削除されるまでの時間です。 |
|
Monitored Interfaces |
インターフェイスのヘルス チェックはリンク障害をモニターします。特定の論理インターフェイスのすべての物理ポートが、特定のノード上では障害が発生したが、別のノード上の同じ論理インターフェイスでアクティブポートがある場合、そのノードはクラスタから削除されます。ノードがメンバーをクラスタから削除するまでの時間は、インターフェイスのタイプと、そのノードが確立済みノードであるか、またはクラスタに参加しようとしているかによって異なります。 |
|
サービスアプリケーション |
Snort プロセスおよび disk-full プロセスが監視されているかどうかを示します。 |
|
モニタリング対象外のインターフェイス |
モニタリング対象外のインターフェイスを表示します。 |
|
自動再結合の設定 |
|
|
クラスタ インターフェイス |
クラスタ制御リンクの自動再結合の設定の不具合を表示します。 |
|
データ インターフェイス |
データインターフェイスの自動再結合の設定を表示します。 |
|
システム(System) |
内部エラー時の自動再結合の設定を表示します。内部の障害には、アプリケーション同期のタイムアウト、矛盾したアプリケーション ステータスなどがあります。 |
(注) |
システムのヘルスチェックを無効にすると、システムのヘルスチェックが無効化されている場合に適用されないフィールドは表示されません。 |
このセクションからこれらの設定を行うことができます。
任意のポートチャネル ID、単一の物理インターフェイス ID、Snort プロセス、および disk-full プロセスを監視できます。ヘルス モニタリングは VLAN サブインターフェイス、または VNI や BVI などの仮想インターフェイスでは実行されません。クラスタ制御リンクのモニタリングは設定できません。このリンクは常にモニターされています。
手順
|
ステップ 1 |
を選択します。 |
|
ステップ 2 |
変更するクラスタの横にある [編集(Edit)]( マルチドメイン展開では、リーフドメインにいない場合、システムによって切り替えるように求められます。 |
|
ステップ 3 |
[クラスタ(Cluster)] をクリックします。 |
|
ステップ 4 |
[クラスタのヘルスモニターの設定(Cluster Health Monitor Settings)] セクションで、[編集(Edit)]( |
|
ステップ 5 |
[ヘルスチェック(Health Check)] スライダをクリックして、システムのヘルスチェックを無効にします。 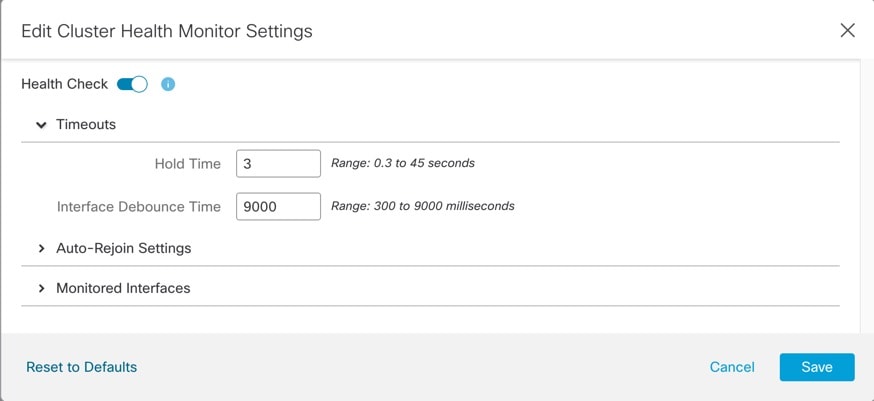
何らかのトポロジ変更(たとえばデータインターフェイスの追加/削除、ノードやスイッチのインターフェイスの有効化/無効化、VSS や vPC を形成するスイッチの追加)を行うときには、システムのヘルスチェック機能を無効にし、無効化したインターフェイスのモニタリングも無効にしてください。トポロジの変更が完了して、設定の変更がすべてのノードに同期されたら、システムのヘルスチェック機能を再度有効にてインターフェイスをモニタリングできます。 |
|
ステップ 6 |
ホールド時間とインターフェイスのデバウンス時間を設定します。
|
|
ステップ 7 |
ヘルス チェック失敗後の自動再結合クラスタ設定をカスタマイズします。 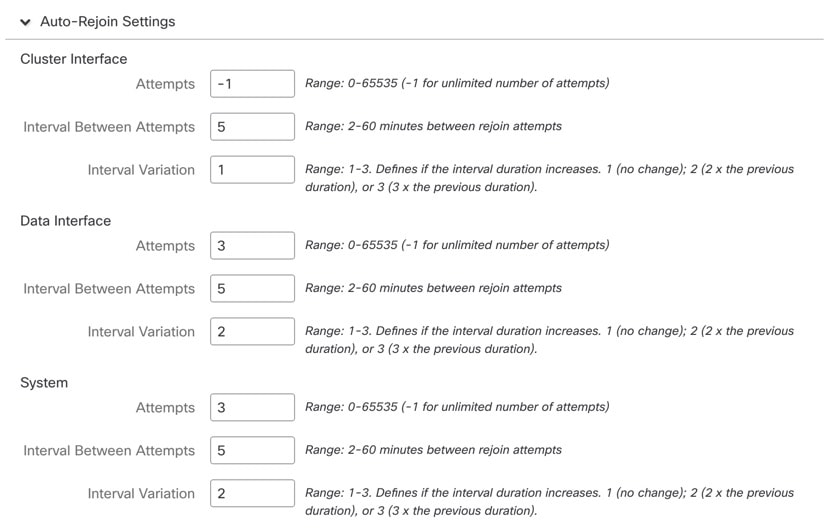
|
|
ステップ 8 |
[モニタリング対象のインターフェイス(Monitored Interfaces)] または [モニタリング対象外のインターフェイス(Unmonitored Interfaces)] ウィンドウでインターフェイスを移動して、モニタリング対象のインターフェイスを設定します。[サービスアプリケーションのモニタリングを有効にする(Enable Service Application Monitoring)] をオンまたはオフにして、Snort プロセスと disk-full プロセスのモニタリングを有効または無効にすることもできます。 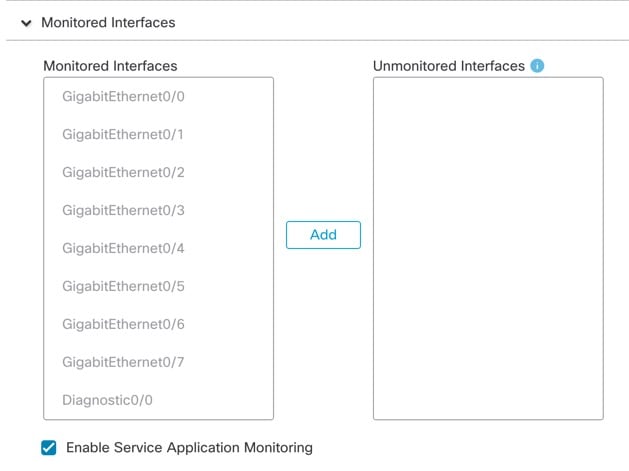
インターフェイスのヘルス チェックはリンク障害をモニターします。特定の論理インターフェイスのすべての物理ポートが、特定のノード上では障害が発生したが、別のノード上の同じ論理インターフェイスでアクティブポートがある場合、そのノードはクラスタから削除されます。ノードがメンバーをクラスタから削除するまでの時間は、インターフェイスのタイプと、そのノードが確立済みノードであるか、またはクラスタに参加しようとしているかによって異なります。デフォルトでは、ヘルスチェックはすべてのインターフェイス、および Snort プロセスと disk-full プロセスで有効になっています。 たとえば、管理インターフェイスなど、必須以外のインターフェイスのヘルス モニタリングを無効にできます。 何らかのトポロジ変更(たとえばデータインターフェイスの追加/削除、ノードやスイッチのインターフェイスの有効化/無効化、VSS や vPC を形成するスイッチの追加)を行うときには、システムのヘルスチェック機能を無効にし、無効化したインターフェイスのモニタリングも無効にしてください。トポロジの変更が完了して、設定の変更がすべてのノードに同期されたら、システムのヘルスチェック機能を再度有効にてインターフェイスをモニタリングできます。 |
|
ステップ 9 |
[保存(Save)] をクリックします。 |
|
ステップ 10 |
構成の変更を展開しますを参照してください。 |
クラスタノードの管理
クラスタリングを無効にする
ノードの削除に備えて、またはメンテナンスのために一時的にノードを非アクティブ化する場合があります。この手順は、ノードを一時的に非アクティブ化するためのものです。ノードは引き続き Management Center のデバイスリストに表示されます。ノードが非アクティブになると、すべてのデータインターフェイスがシャットダウンされます。
(注) |
クラスタリングを無効にせずにノードの電源を切らないでください。 |
手順
|
ステップ 1 |
無効にするユニットに対して、[デバイス(Devices)] > [デバイス管理(Device Management)] の順に選択して その他( |
|
ステップ 2 |
ノードのクラスタリングを無効にすることを確認します。 ノードは、[デバイス(Devices)] > [デバイス管理(Device Management)] リストの名前の横に [(無効(Disabled))] と表示されます。 |
|
ステップ 3 |
クラスタリングを再び有効にするには、クラスタへの再参加を参照してください。 |
クラスタへの再参加
(たとえば、インターフェイスで障害が発生したために)ノードがクラスタから削除された場合、または手動でクラスタリングを無効にした場合は、クラスタに手動で再参加する必要があります。クラスタへの再参加を試行する前に、障害が解決されていることを確認します。ノードをクラスタから削除できる理由の詳細については、「クラスタへの再参加」を参照してください。
手順
|
ステップ 1 |
再度有効にするユニットに対して、[デバイス(Devices)] > [デバイス管理(Device Management)] の順に選択して その他( |
|
ステップ 2 |
ノードのクラスタリングを有効にすることを確認します。 |
クラスタノードの照合
クラスタノードの登録に失敗した場合は、デバイスから Management Center に対してクラスタメンバーシップを照合できます。たとえば、Management Center が特定のプロセスで占領されているか、ネットワークに問題がある場合、データノードの登録に失敗することがあります。
手順
|
ステップ 1 |
クラスタの その他( |
|
ステップ 2 |
[すべてを照合(Reconcile All)] をクリックします。 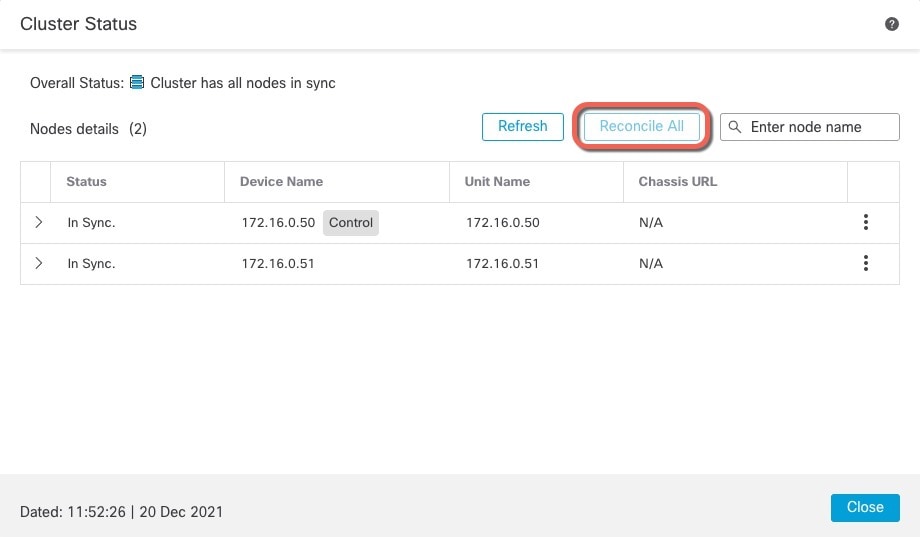
クラスタ ステータスの詳細については、クラスタのモニタリングを参照してください。 |
Management Center からのクラスタまたはノードの削除
Management Center からクラスタを削除できます。これにより、クラスタはそのまま維持されます。クラスタを新しい Management Center に追加する場合は、クラスタを削除してもかまいません。
クラスタからノードを除外することなく、Management Center からノードを削除することもできます。ノードは Management Center に表示されていませんが、まだクラスタの一部であり、引き続きトラフィックを渡して制御ノードになることも可能です。現在動作している制御ノードを削除することはできません。Management Center から到達不可能になったノードは削除してもかまいませんが、クラスタの一部として残しておくことも可能です。
手順
|
ステップ 1 |
[デバイス(Devices)] > [デバイス管理(Device Management)] の順に選択し、クラスタかノードの その他( |
|
ステップ 2 |
クラスタかノードを削除するよう求められたら、[はい(Yes)] をクリックします。 |
|
ステップ 3 |
新しい Management Center にクラスタを追加するには、[デバイス(Devices)] > [デバイス管理(Device Management)] の順に選択し、[デバイスの追加(Add Device)] をクリックします。 クラスタメンバーの 1 つをデバイスとして追加するだけで、残りのクラスタノードが検出されます。 削除したノードを再度追加する方法については、「クラスタノードの照合」を参照してください。 |
クラスタのモニタリング
クラスタは、Management Center と Threat Defense の CLI でモニターできます。
-
[クラスタステータス(Cluster Status)] ダイアログボックスには、[デバイス(Devices)] > [デバイス管理(Device Management)] > その他(
![[その他(More)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/448001-449000/448310.jpg) ) アイコンから、または [デバイス(Devices)] > [デバイス管理(Device Management)] > [クラスタ(Cluster)] ページ > [全般(General)] 領域 > [クラスタのライブステータス(Cluster
Live Status)] リンクからアクセスできます。
) アイコンから、または [デバイス(Devices)] > [デバイス管理(Device Management)] > [クラスタ(Cluster)] ページ > [全般(General)] 領域 > [クラスタのライブステータス(Cluster
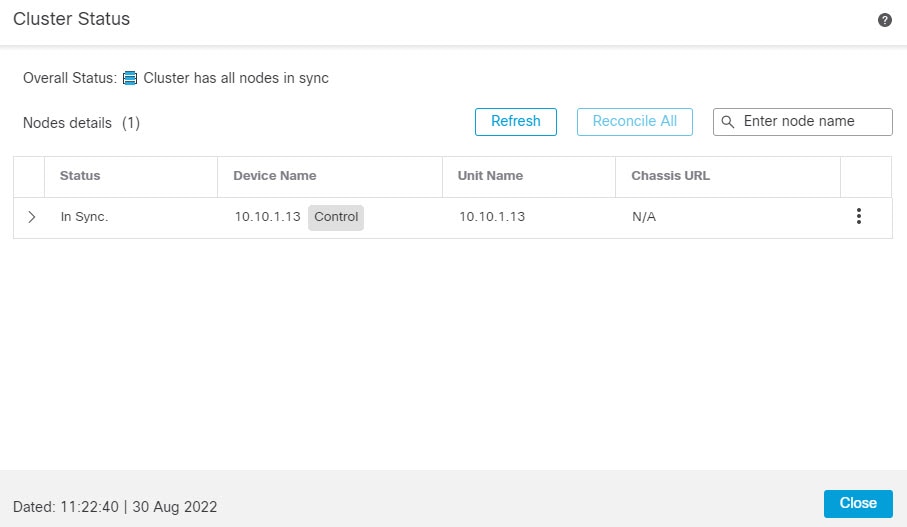
Live Status)] リンクからアクセスできます。図 9. クラスタのステータス 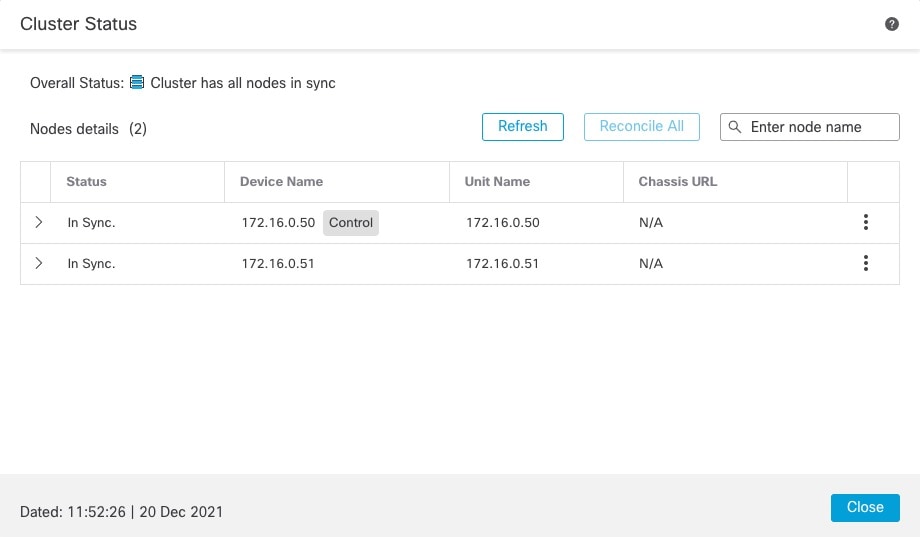
制御ノードには、そのロールを示すグラフィックインジケータがあります。
クラスタメンバーステータスには、次の状態が含まれます。
-
同期中(In Sync):ノードは Management Center に登録されています。
-
登録の保留中(Pending Registration):ノードはクラスタの一部ですが、まだ Management Center に登録されていません。ノードの登録に失敗した場合は、[すべてを照合(Reconcile All)] をクリックして登録を再試行できます。
-
クラスタリングが無効(Clustering is disabled):ノードは Management Center に登録されていますが、クラスタの非アクティブなメンバーです。クラスタリング設定は、後で再有効化する予定がある場合は変更せずに維持できます。また、ノードをクラスタから削除することも可能です。
-
クラスタに参加中...(Joining cluster...):ノードがシャーシ上でクラスタに参加していますが、参加は完了していません。参加後に Management Center に登録されます。
ノードごとに [概要(Summary)] と [履歴(History)] を表示できます。
図 10. ノードの [概要(Summary)] ![ノードの [概要(Summary)]](/c/dam/en/us/td/i/400001-500000/450001-460000/459001-460000/459937.jpg)
図 11. ノードの [履歴(History)] ![ノードの [履歴(History)]](/c/dam/en/us/td/i/400001-500000/450001-460000/459001-460000/459938.jpg)
-
-
システム(
![[システム歯車(system gear}] アイコン](/c/dam/en/us/td/i/400001-500000/450001-460000/451001-452000/451292.jpg) ) > [Tasks] ページ。
) > [Tasks] ページ。
[タスク(Tasks)] ページには、ノードが登録されるたびにクラスタ登録タスクの最新情報が表示されます。
-
[デバイス(Devices)] > [デバイス管理(Device Management)] > cluster_name。
デバイスの一覧表示ページでクラスタを展開すると、IP アドレスの横にそのロールが表示されている制御ノードを含む、すべてのメンバーノードを表示できます。登録中のノードには、ロード中のアイコンが表示されます。
-
show cluster {access-list [acl_name] | conn [count] | cpu [usage] | history | interface-mode | memory | resource usage | service-policy | traffic | xlate count}
クラスタ全体の集約データまたはその他の情報を表示するには、show cluster コマンドを使用します。
-
show cluster info [auto-join | clients | conn-distribution | flow-mobility counters | goid [options] | health | incompatible-config | loadbalance | old-members | packet-distribution | trace [options] | transport { asp | cp}]
クラスタ情報を表示するには、show cluster info コマンドを使用します。
クラスタ ヘルス モニター ダッシュボード
Cluster Health Monitor
Threat Defense がクラスタの制御ノードである場合、Management Center はデバイス メトリック データ コレクタからさまざまなメトリックを定期的に収集します。クラスタの ヘルスモニターは、次のコンポーネントで構成されています。
-
概要ダッシュボード:クラスタトポロジ、クラスタ統計、およびメトリックチャートに関する情報を表示します。
-
トポロジセクションには、クラスタのライブステータス、個々の脅威防御の状態、脅威防御ノードのタイプ(制御ノードまたはデータノード)、およびデバイスの状態が表示されます。デバイスの状態は、[無効(Disabled)](デバイスがクラスタを離れたとき)、[初期状態で追加(Added out of box)](パブリッククラウドクラスタで Management Center に属していない追加ノード)、または [標準(Normal)](ノードの理想的な状態)のいずれかです。
-
クラスタの統計セクションには、CPU 使用率、メモリ使用率、入力レート、出力レート、アクティブな接続数、および NAT 変換数に関するクラスタの現在のメトリックが表示されます。
(注)
CPU とメモリのメトリックは、データプレーンと Snort の使用量の個々の平均を示します。
-
メトリックチャート、つまり、CPU 使用率、メモリ使用率、スループット、および接続数は、指定された期間におけるクラスタの統計を図表で示します。
-
-
負荷分散ダッシュボード:2 つのウィジェットでクラスタノード全体の負荷分散を表示します。
-
分布ウィジェットには、クラスタノード全体の時間範囲における平均パケットおよび接続分布が表示されます。このデータは、ノードによって負荷がどのように分散されているかを示します。このウィジェットを使用すると、負荷分散の異常を簡単に特定して修正できます。
-
ノード統計ウィジェットには、ノードレベルのメトリックが表形式で表示されます。クラスタノード全体の CPU 使用率、メモリ使用率、入力レート、出力レート、アクティブな接続数、および NAT 変換数に関するメトリックデータが表示されます。このテーブルビューでは、データを関連付けて、不一致を簡単に特定できます。
-
-
メンバー パフォーマンス ダッシュボード:クラスタノードの現在のメトリックを表示します。セレクタを使用してノードをフィルタリングし、特定ノードの詳細を表示できます。メトリックデータには、CPU 使用率、メモリ使用率、入力レート、出力レート、アクティブな接続数、および NAT 変換数が含まれます。
-
CCL ダッシュボード:クラスタの制御リンクデータ、つまり入力レートと出力レートをグラフ形式で表示します。
-
トラブルシューティングとリンク: 頻繁に使用されるトラブルシューティングのトピックと手順への便利なリンクを提供します。
-
時間範囲:さまざまなクラスタ メトリック ダッシュボードやウィジェットに表示される情報を制限するための調整可能な時間枠。
-
カスタムダッシュボード:クラスタ全体のメトリックとノードレベルのメトリックの両方に関するデータを表示します。ただし、ノードの選択は脅威防御メトリックにのみ適用され、ノードが属するクラスタ全体には適用されません。
クラスタ ヘルスの表示
この手順を実行するには、管理者ユーザー、メンテナンスユーザー、またはセキュリティ アナリスト ユーザーである必要があります。
クラスタヘルスモニターは、クラスタとそのノードのヘルスステータスの詳細なビューを提供します。このクラスタヘルスモニターは、一連のダッシュボードでクラスタのヘルスステータスと傾向を提供します。
始める前に
-
Management Center の 1 つ以上のデバイスからクラスタを作成しているかを確認します。
手順
|
ステップ 1 |
システム( [モニタリング(Monitoring)] ナビゲーションウィンドウを使用して、ノード固有のヘルスモニターにアクセスします。 |
|
ステップ 2 |
デバイスリストで [展開(Expand)]( |
|
ステップ 3 |
クラスタのヘルス統計を表示するには、クラスタ名をクリックします。デフォルトでは、クラスタモニターは、いくつかの事前定義されたダッシュボードで正常性およびパフォーマンスのメトリックを報告します。メトリックダッシュボードには次のものが含まれます。
ラベルをクリックすると、さまざまなメトリックダッシュボードに移動できます。サポートされているクラスタメトリックの包括的なリストについては、「Cisco Secure Firewall Threat Defense Health Metrics」を参照してください。 |
|
ステップ 4 |
右上隅のドロップダウンで、時間範囲を設定できます。最短で 1 時間前(デフォルト)から、最長では 2 週間前からの期間を反映できます。ドロップダウンから [Custom] を選択して、カスタムの開始日と終了日を設定します。 更新アイコンをクリックして、自動更新を 5 分に設定するか、自動更新をオフに切り替えます。 |
|
ステップ 5 |
選択した時間範囲について、トレンドグラフの展開オーバーレイの展開アイコンをクリックします。 展開アイコンは、選択した時間範囲内の展開数を示します。垂直の帯は、展開の開始時刻と終了時刻を示します。複数の展開の場合、複数の帯または線が表示されます。展開の詳細を表示するには、点線の上部にあるアイコンをクリックします。 |
|
ステップ 6 |
(ノード固有のヘルスモニターの場合)ページ上部のデバイス名の右側にあるアラート通知で、ノードの正常性アラートを確認します。 正常性アラートにポインタを合わせると、ノードの正常性の概要が表示されます。ポップアップウィンドウに、上位 5 つの正常性アラートの概要の一部が表示されます。ポップアップをクリックすると、正常性アラート概要の詳細ビューが開きます。 |
|
ステップ 7 |
(ノード固有のヘルスモニターの場合)デフォルトでは、デバイスモニターは、いくつかの事前定義されたダッシュボードで正常性およびパフォーマンスのメトリックを報告します。メトリックダッシュボードには次のものが含まれます。
ラベルをクリックすると、さまざまなメトリックダッシュボードに移動できます。サポートされているデバイスメトリックの包括的なリストについては、「Cisco Secure Firewall Threat Defense Health Metrics」を参照してください。 |
|
ステップ 8 |
ヘルスモニターの右上隅にあるプラス記号([+])をクリックして、使用可能なメトリックグループから独自の変数セットを構成し、カスタムダッシュボードを作成します。 クラスタ全体のダッシュボードの場合は、クラスタのメトリックグループを選択してから、メトリックを選択します。 |
![[展開(Expand)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/447001-448000/447115.jpg) )
)![[折りたたみ(Collapse)] アイコン](/c/dam/en/us/td/i/400001-500000/440001-450000/447001-448000/447117.jpg) )
)クラスタメトリック
クラスタのヘルスモニターは、クラスタとそのノードに関連する統計情報と、負荷分散、パフォーマンス、および CCL トラフィックの統計データの集約結果を追跡します。
|
Metric |
説明 |
書式 |
|---|---|---|
|
CPU |
クラスタノード上の CPU メトリックの平均(データプレーンと snort についてそれぞれ表示)。 |
percentage |
|
メモリ |
クラスタノード上のメモリメトリックの平均(データプレーンと snort についてそれぞれ表示)。 |
percentage |
|
データスループット |
クラスタの着信および発信データトラフィックの統計。 |
bytes |
|
CCL スループット |
クラスタの着信および発信 CCL トラフィックの統計。 |
bytes |
|
接続(Connections) |
クラスタ内のアクティブな接続数。 |
number |
|
NAT Translations |
クラスタの NAT 変換数。 |
number |
|
Distribution |
1 秒ごとのクラスタ内の接続分布数。 |
number |
|
パケット |
クラスタ内の 1 秒ごとのパケット配信の件数。 |
number |
クラスタのアップグレード
Threat Defense Virtual クラスタをアップグレードするには、次の手順を実行します。
手順
|
ステップ 1 |
ターゲット イメージ バージョンをクラウドイメージストレージにアップロードします。 |
|
ステップ 2 |
更新されたターゲット イメージ バージョンでクラスタのクラウド インスタンス テンプレートを更新します。
|
|
ステップ 3 |
ターゲット イメージ バージョンのアップグレードパッケージを Management Center にアップロードします。 |
|
ステップ 4 |
アップグレードするクラスタで準備状況チェックを実行します。 |
|
ステップ 5 |
準備状況チェックが成功したら、アップグレードパッケージのインストールを開始します。 |
|
ステップ 6 |
Management Center は、クラスタノードを一度に 1 つずつアップグレードします。 |
|
ステップ 7 |
クラスタのアップグレードが成功すると、Management Center に通知が表示されます。 アップグレード後のインスタンスのシリアル番号と UUID に変更はありません。 |
クラスタリングの参考資料
このセクションには、クラスタリングの動作に関する詳細情報が含まれます。
Threat Defense の機能とクラスタリング
Threat Defense の一部の機能はクラスタリングではサポートされず、一部は制御ユニットだけでサポートされます。その他の機能については適切な使用に関する警告がある場合があります。
サポートされていない機能とクラスタリング
次の各機能は、クラスタリングが有効なときは設定できず、コマンドは拒否されます。
(注) |
クラスタリングでもサポートされていない FlexConfig 機能(WCCP インスペクションなど)を表示するには、ASA の一般的な操作のコンフィギュレーション ガイドを参照してください。FlexConfig では、Management Center GUI にはない多くの ASA 機能を設定できます。 |
-
リモート アクセス VPN(SSL VPN および IPsec VPN)
-
DHCP クライアント、サーバー、およびプロキシ。DHCP リレーはサポートされています。
-
仮想トンネルインターフェイス(VTI)
-
高可用性
-
統合ルーティングおよびブリッジング
-
Management Center UCAPL/CC モード
クラスタリングの中央集中型機能
次の機能は、制御ノード上だけでサポートされます。クラスタの場合もスケーリングされません。
(注) |
中央集中型機能のトラフィックは、クラスタ制御リンク経由でメンバーノードから制御ノードに転送されます。 再分散機能を使用する場合は、中央集中型機能のトラフィックが中央集中型機能として分類される前に再分散が行われて、制御ノード以外のノードに転送されることがあります。この場合は、トラフィックが制御ノードに送り返されます。 中央集中型機能については、制御ノードで障害が発生するとすべての接続がドロップされるので、新しい制御ノード上で接続を再確立する必要があります。 |
(注) |
クラスタリングでも一元化されている FlexConfig 機能(RADIUS インスペクションなど)を表示するには、ASA の一般的な操作のコンフィギュレーションガイドを参照してください。FlexConfig では、Management Center GUI にはない多くの ASA 機能を設定できます。 |
-
次のアプリケーション インスペクション:
-
DCERPC
-
ESMTP
-
NetBIOS
-
PPTP
-
RSH
-
SQLNET
-
SUNRPC
-
TFTP
-
XDMCP
-
-
スタティック ルート モニタリング
Cisco TrustSec とクラスタリング
制御ノードだけがセキュリティグループタグ(SGT)情報を学習します。その後、制御ノードからデータノードに SGT が渡されるため、データノードは、セキュリティポリシーに基づいて SGT の一致を判断できます。
接続設定とクラスタリング
接続制限は、クラスタ全体に適用されます。各ノードには、ブロードキャストメッセージに基づくクラスタ全体のカウンタの推定値があります。クラスタ全体で接続制限を設定しても、効率性を考慮して、厳密に制限数で適用されない場合があります。各ノードでは、任意の時点でのクラスタ全体のカウンタ値が過大評価または過小評価される可能性があります。ただし、ロードバランシングされたクラスタでは、時間の経過とともに情報が更新されます。
ダイナミック ルーティングおよびクラスタリング
個別インターフェイスモードでは、各ノードがスタンドアロンルータとしてルーティングプロトコルを実行します。ルートの学習は、各ノードが個別に行います。
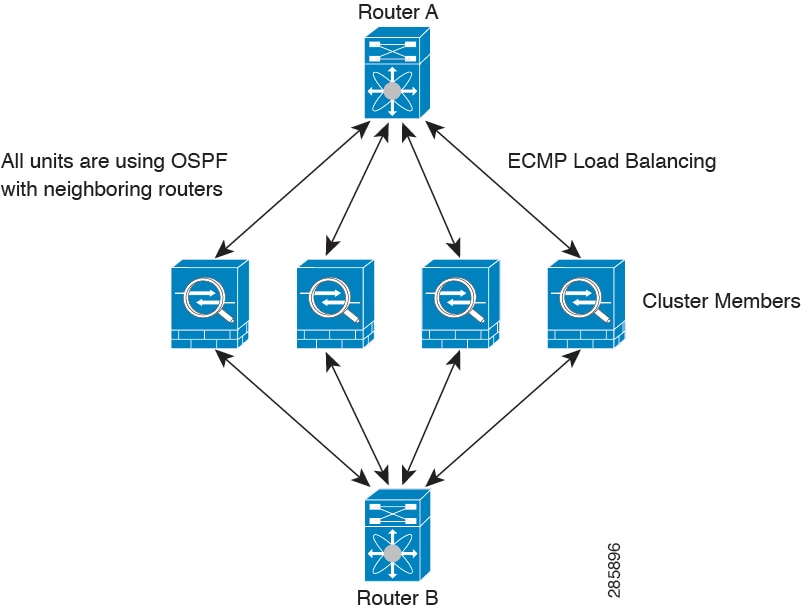
上の図では、ルータ A はルータ B への等コストパスが 4 本あることを学習します。パスはそれぞれ 1 つのノードを通過します。ECMP を使用して、4 パス間でトラフィックのロード バランシングを行います。各ノードは、外部ルータと通信するときに、それぞれ異なるルータ ID を選択します。
管理者は、各ノードに異なるルータ ID が設定されるように、ルータ ID のクラスタプールを設定する必要があります。
FTP とクラスタリング
-
FTP D チャネルとコントロール チャネルのフローがそれぞれ別のクラスタ メンバーによって所有されている場合は、D チャネルのオーナーは定期的にアイドル タイムアウト アップデートをコントロール チャネルのオーナーに送信し、アイドル タイムアウト値を更新します。ただし、コントロール フローのオーナーがリロードされて、コントロール フローが再ホスティングされた場合は、親子フロー関係は維持されなくなります。したがって、コントロール フローのアイドル タイムアウトは更新されません。
NAT とクラスタリング
GCP では、アウトバウンドトラフィックにインターフェイス NAT が必要です。インターフェイス NAT を使用したアウトバウンドトラフィックは、64 k 接続に制限されています。その他の NAT の使用については、次の制限事項を参照してください。
NAT は、クラスタの全体的なスループットに影響を与えることがあります。インバウンドおよびアウトバウンドの NAT パケットが、それぞれクラスタ内の別の Threat Defense に送信されることがあります。ロード バランシング アルゴリズムは IP アドレスとポートに依存していますが、NAT が使用されるときは、インバウンドとアウトバウンドとで、パケットの IP アドレスやポートが異なるからです。NAT オーナーではない Threat Defense に到着したパケットは、クラスタ制御リンクを介してオーナーに転送されるため、クラスタ制御リンクに大量のトラフィックが発生します。NAT オーナーは、セキュリティおよびポリシーチェックの結果に応じてパケットの接続を作成できない可能性があるため、受信側ノードは、オーナーへの転送フローを作成しないことに注意してください。
それでもクラスタリングで NAT を使用する場合は、次のガイドラインを考慮してください。
-
プロキシ ARP なし:個別インターフェイスの場合は、マッピング アドレスについてプロキシ ARP 応答が送信されることはありません。これは、クラスタに存在しなくなった可能性のある ASA と隣接ルータとがピア関係を維持することを防ぐためです。アップストリーム ルータは、メイン クラスタ IP アドレスを指すマッピング アドレスについてはスタティック ルートまたは PBR とオブジェクト トラッキングを使用する必要があります。
-
ポート ブロック割り当てによる PAT:この機能については、次のガイドラインを参照してください。
-
ホストあたりの最大制限は、クラスタ全体の制限ではなく、ノードごとに個別に適用されます。したがって、ホストあたりの最大制限が 1 に設定されている 3 ノードクラスタでは、ホストからのトラフィックが 3 つのノードすべてにロードバランシングされている場合、3 つのブロックを各ノードに 1 つずつ割り当てることができます。
-
バックアッププールからバックアップノードで作成されたポートブロックは、ホストあたりの最大制限の適用時には考慮されません。
-
PAT プールが完全に新しい IP アドレスの範囲で変更される On-the-fly PAT ルールの変更では、新しいプールが有効になっていてもいまだ送信中の xlate バックアップ要求に対する xlate バックアップの作成が失敗します。この動作はポートのブロック割り当て機能に固有なものではなく、プールが分散されトラフィックがクラスタノード間でロードバランシングされるクラスタ展開でのみ見られる一時的な PAT プールの問題です。
-
クラスタで動作している場合、ブロック割り当てサイズを変更することはできません。新しいサイズは、クラスタ内の各デバイスをリロードした後にのみ有効になります。各デバイスのリロードの必要性を回避するために、すべてのブロック割り当てルールを削除し、それらのルールに関連するすべての xlate をクリアすることをお勧めします。その後、ブロックサイズを変更し、ブロック割り当てルールを再作成できます。
-
-
ダイナミック PAT の NAT プールアドレス配布:PAT プールを設定すると、クラスタはプール内の各 IP アドレスをポートブロックに分割します。デフォルトでは、各ブロックは 512 ポートですが、ポートブロック割り当てルールを設定すると、代わりにユーザのブロック設定が使用されます。これらのブロックはクラスタ内のノード間で均等に分散されるため、各ノードには PAT プール内の IP アドレスごとに 1 つ以上のブロックがあります。したがって、想定される PAT 接続数に対して十分である場合には、クラスタの PAT プールに含める IP アドレスを 1 つだけにすることができます。PAT プールの NAT ルールで予約済みポート 1 ~ 1023 を含めるようにオプションを設定しない限り、ポートブロックは 1024 ~ 65535 のポート範囲をカバーします。
-
複数のルールにおける PAT プールの再利用:複数のルールで同じ PAT プールを使用するには、ルールにおけるインターフェイスの選択に注意を払う必要があります。すべてのルールで特定のインターフェイスを使用するか、あるいはすべてのルールで「任意の」インターフェイスを使用するか、いずれかを選択する必要があります。ルール全般にわたって特定のインターフェイスと「任意」のインターフェイスを混在させることはできません。混在させると、システムがリターントラフィックとクラスタ内の適切なノードを一致させることができなくなる場合があります。ルールごとに固有の PAT プールを使用することは、最も信頼性の高いオプションです。
-
ラウンドロビンなし:PAT プールのラウンドロビンは、クラスタリングではサポートされません。
-
拡張 PAT なし:拡張 PAT はクラスタリングでサポートされません。
-
制御ノードによって管理されるダイナミック NAT xlate:制御ノードが xlate テーブルを維持し、データノードに複製します。ダイナミック NAT を必要とする接続をデータノードが受信したときに、その xlate がテーブル内にない場合、データノードは制御ノードに xlate を要求します。データノードが接続を所有します。
-
旧式の xlates:接続所有者の xlate アイドル時間が更新されません。したがって、アイドル時間がアイドルタイムアウトを超える可能性があります。refcnt が 0 で、アイドルタイマー値が設定されたタイムアウトより大きい場合は、旧式の xlate であることを示します。
-
次のインスペクション用のスタティック PAT はありません。
-
FTP
-
RSH
-
SQLNET
-
TFTP
-
XDMCP
-
SIP
-
-
1 万を超える非常に多くの NAT ルールがある場合は、デバイスの CLI で asp rule-engine transactional-commit nat コマンドを使用してトランザクション コミット モデルを有効にする必要があります。有効にしないと、ノードがクラスタに参加できない可能性があります。
SIP インスペクションとクラスタリング
制御フローは、(ロードバランシングにより)任意のノードに作成できますが、子データフローは同じノードに存在する必要があります。
SNMP とクラスタリング
SNMP エージェントは、個々の Threat Defense を、その [診断(Diagnostic)] 診断インターフェイスのローカル IP アドレスによってポーリングします。クラスタの統合データをポーリングすることはできません。
SNMP ポーリングには、メイン クラスタ IP アドレスではなく、常にローカル アドレスを使用してください。SNMP エージェントがメインクラスタ IP アドレスをポーリングする場合、新しい制御ノードが選択されると、新しい制御ノードのポーリングは失敗します。
syslog とクラスタリング
-
クラスタの各ノードは自身の syslog メッセージを生成します。ロギングを設定して、各ノードの syslog メッセージ ヘッダー フィールドで同じデバイス ID を使用するか、別の ID を使用するかを設定できます。たとえば、ホスト名設定はクラスタ内のすべてのノードに複製されて共有されます。ホスト名をデバイス ID として使用するようにロギングを設定した場合、すべてのノードで生成される syslog メッセージが 1 つのノードから生成されているように見えます。クラスタブートストラップ設定で割り当てられたローカルノード名をデバイス ID として使用するようにロギングを設定した場合、syslog メッセージはそれぞれ別のノードから生成されているように見えます。
VPN とクラスタリング
サイト間 VPN は、中央集中型機能です。制御ノードのみが VPN 接続をサポートします。
(注) |
リモート アクセス VPN は、クラスタリングではサポートされません。 |
VPN 機能を使用できるのは制御ノードだけであり、クラスタの高可用性機能は活用されません。制御ノードで障害が発生した場合は、すべての既存の VPN 接続が失われ、VPN ユーザにとってはサービスの中断となります。新しい制御ノードが選定されたときに、VPN 接続を再確立する必要があります。
PBR または ECMP を使用するときの個別インターフェイスへの接続については、ローカル アドレスではなく、常にメイン クラスタ IP アドレスに接続する必要があります。
VPN 関連のキーと証明書は、すべてのノードに複製されます。
パフォーマンス スケーリング係数
複数のユニットをクラスタに結合すると、期待できる合計クラスタパフォーマンスは、最大合計スループットの約 80%になります。
たとえば、モデルが単独稼働で約 10 Gbps のトラフィックを処理できる場合、8 ユニットのクラスタでは、最大合計スループットは 80 Gbps(8 ユニット x 10 Gbps)の約 80% で 64 Gbps になります。
制御ノードの選定
クラスタのノードは、クラスタ制御リンクを介して通信して制御ノードを選定します。方法は次のとおりです。
-
ノードに対してクラスタリングをイネーブルにしたとき(または、クラスタリングがイネーブル済みの状態でそのユニットを初めて起動したとき)に、そのノードは選定要求を 3 秒間隔でブロードキャストします。
-
プライオリティの高い他のノードがこの選定要求に応答します。プライオリティは 1 ~ 100 の範囲内で設定され、1 が最高のプライオリティです。
-
45 秒経過しても、プライオリティの高い他のノードからの応答を受信していない場合は、そのノードが制御ノードになります。
(注)
最高のプライオリティを持つノードが複数ある場合は、クラスタノード名、次にシリアル番号を使用して制御ノードが決定されます。
-
後からクラスタに参加したノードのプライオリティの方が高い場合でも、そのノードが自動的に制御ノードになることはありません。既存の制御ノードは常に制御ノードのままです。ただし、制御ノードが応答を停止すると、その時点で新しい制御ノードが選定されます。
-
「スプリットブレイン」シナリオで一時的に複数の制御ノードが存在する場合、優先順位が最も高いノードが制御ノードの役割を保持し、他のノードはデータノードの役割に戻ります。
(注) |
ノードを手動で強制的に制御ノードにすることができます。中央集中型機能については、制御ノード変更を強制するとすべての接続がドロップされるので、新しい制御ノード上で接続を再確立する必要があります。 |
クラスタ内のハイアベイラビリティ
クラスタリングは、ノードとインターフェイスの正常性をモニターし、ノード間で接続状態を複製することにより、ハイアベイラビリティを実現します。
ノードヘルスモニタリング
各ノードは、クラスタ制御リンクを介してブロードキャスト ハートビート パケットを定期的に送信します。設定可能なタイムアウト期間内にデータノードからハートビートパケットまたはその他のパケットを受信しない場合、制御ノードはクラスタからデータノードを削除します。データノードが制御ノードからパケットを受信しない場合、残りのノードから新しい制御ノードが選択されます。
ノードで実際に障害が発生したためではなく、ネットワークの障害が原因で、ノードがクラスタ制御リンクを介して相互に通信できない場合、クラスタは「スプリットブレイン」シナリオに移行する可能性があります。このシナリオでは、分離されたデータノードが独自の制御ノードを選択します。たとえば、2 つのクラスタロケーション間でルータに障害が発生した場合、ロケーション 1 の元の制御ノードは、ロケーション 2 のデータノードをクラスタから削除します。一方、ロケーション 2 のノードは、独自の制御ノードを選択し、独自のクラスタを形成します。このシナリオでは、非対称トラフィックが失敗する可能性があることに注意してください。クラスタ制御リンクが復元されると、より優先順位の高い制御ノードが制御ノードの役割を保持します。
インターフェイス モニタリング
各ノードは、使用中のすべての指名されたハードウェア インターフェイスのリンクステータスをモニタし、ステータス変更を制御ノードに報告します。
すべての物理インターフェイスがモニタリングされます。ただし、モニタリングできるのは、名前付きインターフェイスのみです。ヘルス チェックは、インターフェイスごとに、モニターリングをオプションで無効にすることができます。
ノードのモニタ対象のインターフェイスが失敗した場合、そのノードはクラスタから削除されます。ノードは 500 ミリ秒後に削除されます。
障害後のステータス
制御ノードで障害が発生した場合、そのクラスタの他のメンバーのうち、優先順位が最高(番号が最小)のメンバーが制御ノードになります。
障害イベントに応じて、Threat Defense は自動的にクラスタへの再参加を試みます。
(注) |
Threat Defense が非アクティブになり、クラスタへの自動再参加に失敗すると、すべてのデータインターフェイスがシャットダウンされ、管理/診断インターフェイスのみがトラフィックを送受信できます。 |
クラスタへの再参加
クラスタ メンバがクラスタから削除された後、クラスタに再参加するための方法は、削除された理由によって異なります。
-
最初に参加するときに障害が発生したクラスタ制御リンク:クラスタ制御リンクの問題を解決した後、クラスタリングを再び有効にして、手動でクラスタに再参加する必要があります。
-
クラスタに参加した後に障害が発生したクラスタ制御リンク:Threat Defense は、無限に 5 分ごとに自動的に再参加を試みます。
-
データ インターフェイスの障害:Threat Defense は自動的に最初は 5 分後、次に 10 分後、最終的に 20 分後に再参加を試みます。20 分後に参加できない場合、Threat Defense アプリケーションはクラスタリングを無効にします。データ インターフェイスの問題を解決した後、手動でクラスタリングを有効にする必要があります。
-
ノードの障害:ノードがヘルスチェック失敗のためクラスタから削除された場合、クラスタへの再参加は失敗の原因によって異なります。たとえば、一時的な電源障害の場合は、クラスタ制御リンクが稼働している限り、ノードは再起動するとクラスタに再参加します。Threat Defense アプリケーションは 5 秒ごとにクラスタへの再参加を試みます。
-
内部エラー:内部エラーには、アプリケーション同期のタイムアウト、一貫性のないアプリケーション ステータスなどがあります。 問題の解決後、クラスタリングを再度有効にして手動でクラスタに再参加する必要があります。
-
障害が発生した設定の展開:Management Center から新しい設定を展開し、展開が一部のクラスタメンバーでは失敗したものの、他のメンバーでは成功した場合、失敗したノードはクラスタから削除されます。クラスタリングを再度有効にして手動でクラスタに再参加する必要があります。制御ノードで展開が失敗した場合、展開はロールバックされ、メンバーは削除されません。すべてのデータノードで展開が失敗した場合、展開はロールバックされ、メンバーは削除されません。
データ パス接続状態の複製
どの接続にも、1 つのオーナーおよび少なくとも 1 つのバックアップ オーナーがクラスタ内にあります。バックアップ オーナーは、障害が発生しても接続を引き継ぎません。代わりに、TCP/UDP のステート情報を保存します。これは、障害発生時に接続が新しいオーナーにシームレスに移管されるようにするためです。バックアップ オーナーは通常ディレクタでもあります。
トラフィックの中には、TCP または UDP レイヤよりも上のステート情報を必要とするものがあります。この種類のトラフィックに対するクラスタリングのサポートの可否については、次の表を参照してください。
|
トラフィック |
状態のサポート |
注 |
|---|---|---|
|
アップ タイム |
対応 |
システム アップ タイムをトラッキングします。 |
|
ARP テーブル |
対応 |
トランスペアレントモードのみ 。 |
|
MAC アドレス テーブル |
対応 |
トランスペアレントモードのみ 。 |
|
ユーザ アイデンティティ |
対応 |
— |
|
IPv6 ネイバー データベース |
対応 |
— |
|
ダイナミック ルーティング |
対応 |
— |
|
SNMP エンジン ID |
なし |
— |
クラスタが接続を管理する方法
接続をクラスタの複数のノードにロードバランシングできます。接続のロールにより、通常動作時とハイ アベイラビリティ状況時の接続の処理方法が決まります。
接続のロール
接続ごとに定義された次のロールを参照してください。
-
オーナー:通常、最初に接続を受信するノード。オーナーは、TCP 状態を保持し、パケットを処理します。1 つの接続に対してオーナーは 1 つだけです。元のオーナーに障害が発生すると、新しいノードが接続からパケットを受信したときにディレクタがそれらのノードの新しいオーナーを選択します。
-
バックアップオーナー:オーナーから受信した TCP/UDP ステート情報を格納するノード。障害が発生した場合、新しいオーナーにシームレスに接続を転送できます。バックアップ オーナーは、障害発生時に接続を引き継ぎません。オーナーが使用不可能になった場合、(ロードバランシングに基づき)その接続からのパケットを受信する最初のノードがバックアップオーナーに問い合わせて、関連するステート情報を取得し、そのノードが新しいオーナーになります。
ディレクタ(下記参照)がオーナーと同じノードでない限り、ディレクタはバックアップオーナーでもあります。オーナーが自分をディレクタとして選択した場合は、別のバックアップ オーナーが選択されます。
-
ディレクタ:フォワーダからのオーナールックアップ要求を処理するノード。オーナーは、新しい接続を受信すると、送信元/宛先 IP アドレスおよびポートのハッシュに基づいてディレクタを選択し、新しい接続を登録するためにそのディレクタにメッセージを送信します。パケットがオーナー以外のノードに到着した場合、そのノードはどのノードがオーナーかをディレクタに問い合わせることで、パケットを転送できます。1 つの接続に対してディレクタは 1 つだけです。ディレクタが失敗すると、オーナーは新しいディレクタを選択します。
ディレクタがオーナーと同じノードでない限り、ディレクタはバックアップオーナーでもあります(上記参照)。オーナーがディレクタとして自分自身を選択すると、別のバックアップ オーナーが選択されます。
ICMP/ICMPv6 ハッシュの詳細:
-
エコーパケットの場合、送信元ポートは ICMP 識別子で、宛先ポートは 0 です。
-
応答パケットの場合、送信元ポートは 0 で、宛先ポートは ICMP 識別子です。
-
他のパケットの場合、送信元ポートと宛先ポートの両方が 0 です。
-
-
フォワーダ:パケットをオーナーに転送するノード。フォワーダが接続のパケットを受信したときに、その接続のオーナーが自分ではない場合は、フォワーダはディレクタにオーナーを問い合わせてから、そのオーナーへのフローを確立します。これは、この接続に関してフォワーダが受信するその他のパケット用です。ディレクタは、フォワーダにもなることができます。フォワーダが SYN-ACK パケットを受信した場合、フォワーダはパケットの SYN クッキーからオーナーを直接取得できるので、ディレクタに問い合わせる必要がないことに注意してください。(TCP シーケンスのランダム化を無効にした場合は、SYN Cookie は使用されないので、ディレクタへの問い合わせが必要です)。存続期間が短いフロー(たとえば DNS や ICMP)の場合は、フォワーダは問い合わせの代わりにパケットを即座にディレクタに送信し、ディレクタがそのパケットをオーナーに送信します。1 つの接続に対して、複数のフォワーダが存在できます。最も効率的なスループットを実現できるのは、フォワーダが 1 つもなく、接続のすべてのパケットをオーナーが受信するという、優れたロードバランシング方法が使用されている場合です。
(注)
クラスタリングを使用する場合は、TCP シーケンスのランダム化を無効にすることは推奨されません。SYN/ACK パケットがドロップされる可能性があるため、一部の TCP セッションが確立されない可能性があります。
-
フラグメントオーナー:フラグメント化されたパケットの場合、フラグメントを受信するクラスタノードは、フラグメントの送信元と宛先の IP アドレス、およびパケット ID のハッシュを使用してフラグメントオーナーを特定します。その後、すべてのフラグメントがクラスタ制御リンクを介してフラグメント所有者に転送されます。スイッチのロードバランスハッシュで使用される 5 タプルは、最初のフラグメントにのみ含まれているため、フラグメントが異なるクラスタノードにロードバランシングされる場合があります。他のフラグメントには、送信元ポートと宛先ポートは含まれず、他のクラスタノードにロードバランシングされる場合があります。フラグメント所有者は一時的にパケットを再アセンブルするため、送信元/宛先 IP アドレスとポートのハッシュに基づいてディレクタを決定できます。新しい接続の場合は、フラグメントの所有者が接続所有者として登録されます。これが既存の接続の場合、フラグメント所有者は、クラスタ制御リンクを介して、指定された接続所有者にすべてのフラグメントを転送します。その後、接続の所有者はすべてのフラグメントを再構築します。
新しい接続の所有権
新しい接続がロードバランシング経由でクラスタのノードに送信される場合は、そのノードがその接続の両方向のオーナーとなります。接続のパケットが別のノードに到着した場合は、そのパケットはクラスタ制御リンクを介してオーナーノードに転送されます。逆方向のフローが別のノードに到着した場合は、元のノードにリダイレクトされます。
TCP のサンプルデータフロー
次の例は、新しい接続の確立を示します。
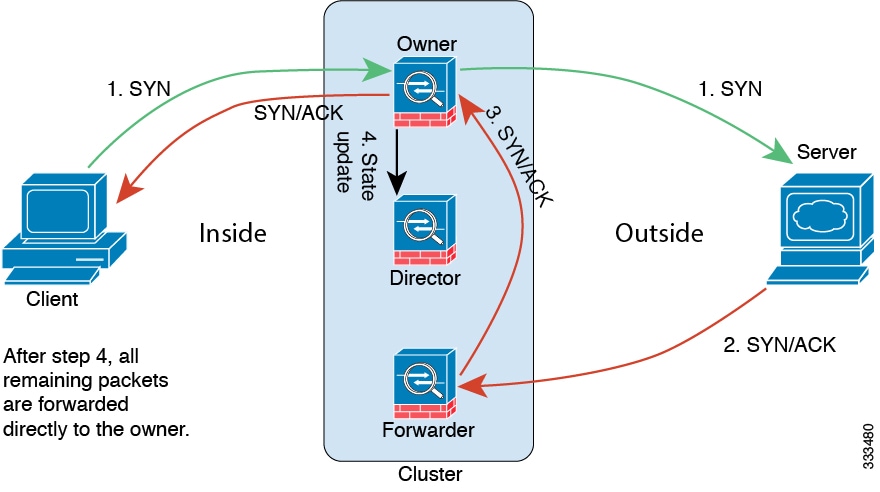
-
SYN パケットがクライアントから発信され、Threat Defense の 1 つ(ロード バランシング方法に基づく)に配信されます。これがオーナーとなります。オーナーはフローを作成し、オーナー情報をエンコードして SYN Cookie を生成し、パケットをサーバに転送します。
-
SYN-ACK パケットがサーバから発信され、別の Threat Defense(ロード バランシング方法に基づく)に配信されます。この Threat Defense はフォワーダです。
-
フォワーダはこの接続を所有してはいないので、オーナー情報を SYN Cookie からデコードし、オーナーへの転送フローを作成し、SYN-ACK をオーナーに転送します。
-
オーナーはディレクタに状態アップデートを送信し、SYN-ACK をクライアントに転送します。
-
ディレクタは状態アップデートをオーナーから受信し、オーナーへのフローを作成し、オーナーと同様に TCP 状態情報を記録します。ディレクタは、この接続のバックアップ オーナーとしての役割を持ちます。
-
これ以降、フォワーダに配信されたパケットはすべて、オーナーに転送されます。
-
パケットがその他のノードに配信された場合、そのノードはディレクタに問い合わせてオーナーを特定し、フローを確立します。
-
フローの状態が変化した場合は、状態アップデートがオーナーからディレクタに送信されます。
ICMP および UDP のサンプルデータフロー
次の例は、新しい接続の確立を示します。
-
図 13. ICMP および UDP データフロー 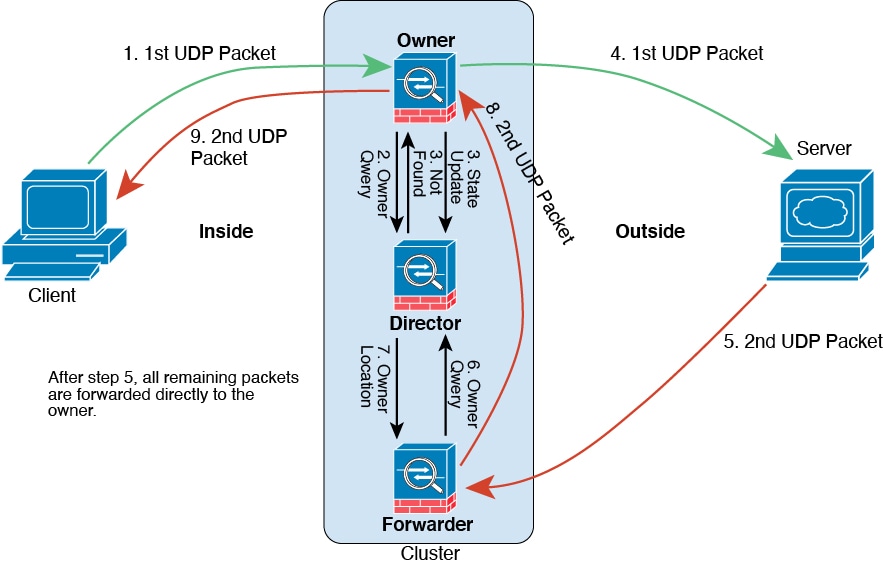
-
最初のパケットを受信したノードは、送信元/宛先 IP アドレスとポートのハッシュに基づいて選択されたディレクタノードをクエリします。
-
ディレクタは既存のフローを検出せず、ディレクタフローを作成して、以前のノードにパケットを転送します。つまり、ディレクタがこのフローのオーナーを選択したことになります。
-
オーナーはフローを作成し、ディレクタに状態アップデートを送信して、サーバーにパケットを転送します。
-
2 番目の UDP パケットはサーバーから発信され、フォワーダに配信されます。
-
フォワーダはディレクタに対して所有権情報をクエリします。存続期間が短いフロー(DNS など)の場合、フォワーダはクエリする代わりにパケットを即座にディレクタに送信し、ディレクタがそのパケットをオーナーに送信します。
-
ディレクタは所有権情報をフォワーダに返信します。
-
フォワーダは転送フローを作成してオーナー情報を記録し、パケットをオーナーに転送します。
-
オーナーはパケットをクライアントに転送します。
GCP での Threat Defense Virtual クラスタリングの履歴
|
機能 |
バージョン |
詳細 |
||
|---|---|---|---|---|
|
クラスタのヘルスモニターの設定 |
7.3 |
クラスタのヘルスモニター設定を編集できるようになりました。 新規/変更された画面:
|
||
|
クラスタ ヘルス モニター ダッシュボード |
7.3 |
クラスタのヘルス モニター ダッシュボードでクラスタの状態を表示できるようになりました。 新規/変更された画面:システム( |
||
|
Google Cloud Platform(GCP)での Threat Defense Virtual のクラスタリング |
7.2 |
Threat Defense Virtual は GCP で最大 16 ノードの個別インターフェイスのクラスタリングをサポートします。 新しい/変更された画面:
|
 フィードバック
フィードバック