DOCSIS 세계에서의 데이터 처리량 이해
목차
소개
케이블 네트워크의 성능을 측정하기 전에 고려해야 할 몇 가지 제한 요소가 있습니다.가용성과 안정성을 갖춘 네트워크를 설계하고 구축하려면 케이블 네트워크 성능의 기본 원칙과 측정 매개변수를 이해해야 합니다.이 문서에서는 이러한 제한 요소 중 일부를 소개하고 구축된 시스템에서 실제로 처리량과 가용성을 최적화하고 검증하는 방법에 대해 설명합니다.
사전 요구 사항
요구 사항
이 문서의 독자는 다음 주제에 대해 알고 있어야 합니다.
-
DOCSIS(Data-over-Cable Service Interface Specification)
-
무선 주파수(RF) 기술
-
Cisco IOS® 소프트웨어 CLI(Command-Line Interface)
사용되는 구성 요소
이 문서는 특정 소프트웨어 또는 하드웨어 버전으로 제한되지 않습니다.
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다.이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다.현재 네트워크가 작동 중인 경우, 모든 명령어의 잠재적인 영향을 미리 숙지하시기 바랍니다.
표기 규칙
문서 규칙에 대한 자세한 내용은 Cisco 기술 팁 표기 규칙을 참조하십시오.
배경 정보
비트, 바이트 및 보드
이 섹션에서는 비트, 바이트 및 보드 간의 차이점을 설명합니다.비트는 BiNaryDigiT의 축약이며, 보통 소문자 b로 상징됩니다.이진수는 두 개의 전자 상태를 나타냅니다."on" 상태 또는 "off" 상태(때때로 "1s" 또는 "0s"라고도 함)
바이트는 대문자 B로 상징되며, 대개 길이가 8비트입니다.바이트는 8비트 이상일 수 있으므로 8비트 단어는 8진수로 더 정확하게 불립니다.또한, 1바이트에 두 개의 니블이 있습니다.니블은 4비트 단어로 정의되며, 이는 바이트의 절반입니다.
비트 속도 또는 처리량은 초당 비트(bps)로 측정되며 지정된 미디어를 통한 신호 속도와 연결됩니다.예를 들어, 이 신호는 베이스밴드 디지털 신호 또는 디지털 신호를 나타내기 위해 설정된 모듈형 아날로그 신호일 수 있습니다.
모듈화된 아날로그 신호의 한 유형은 QPSK(Quadrature Phase Shift Keying)입니다. 이는 그림 1에 나와 있는 것처럼 신호의 단계를 90도 정도 조작하여 4개의 다른 시그니처를 생성하는 변조 기술입니다. 이러한 시그니처를 기호라고 하며 그 속도를 보드라고 합니다.Baud는 초당 기호와 같습니다.
그림 1 - QPSK 다이어그램 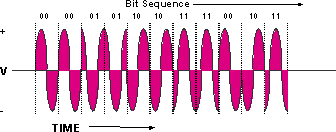
QPSK 신호는 4개의 다른 상징을 가지고 있습니다.4는 22와 같습니다. 지수를 나타내는 이론적 비트 수(기호)가 이 경우 2와 같습니다.네 개의 기호는 이진 숫자 00, 01, 10 및 11을 나타냅니다. 따라서 QPSK 캐리어를 전송하는 데 2.56Msymbols/s의 기호 속도를 사용하는 경우, 이를 2.56Mbaud라고 하며 이론적 비트 속도는 2.56Msymbols x 2비트/기호 = 5.12Mbps입니다.이 내용은 이 문서의 뒷부분에서 자세히 설명합니다.
또한 PPS(packets per second)라는 용어에 익숙할 수도 있습니다. 이는 패킷에 64바이트 또는 1518바이트 이더넷 프레임이 포함되어 있는지 여부와 상관없이 패킷을 기반으로 디바이스의 처리량을 검증하는 방법입니다.때때로 네트워크의 "병목" 현상은 특정 양의 PPS를 처리하는 CPU의 힘이며, 반드시 총 bps가 아닐 수도 있습니다.
처리량이란 무엇입니까?
데이터 처리량은 이론상 최대 처리량을 계산하는 것으로 시작된 다음 효과적인 처리량으로 마무리됩니다.서비스 가입자가 사용할 수 있는 유효 처리량은 항상 이론상 최대값보다 낮으며, 이를 계산해야 합니다.
처리량은 다음과 같은 여러 요소를 기반으로 합니다.
-
총 사용자 수
-
병목 속도
-
액세스한 서비스 유형
-
캐시 및 프록시 서버 사용
-
MAC 레이어 효율성
-
케이블 플랜트의 소음 및 오류
-
여러 가지 다른 요인들
이 문서의 목적은 DOCSIS 환경에서 처리량과 가용성을 최적화하는 방법과 성능에 영향을 미치는 기본 프로토콜 제한을 설명하는 것입니다.성능 문제를 테스트하거나 해결하려면 케이블 모뎀 네트워크에서 성능 저하 문제 해결을 참조하십시오.업스트림(미국) 또는 다운스트림(DS) 포트에서 권장되는 최대 사용자 수에 대한 지침은 CMTS당 최대 사용자 수는 얼마입니까?를 참조하십시오.
레거시 케이블 네트워크는 MAC 프로토콜로서 폴링을 사용하거나 CSMA/CD(Carrier Sense Multiple Access Collision Detect)를 사용합니다.현재 DOCSIS 모뎀은 모뎀이 전송 시간을 요청하고 CMTS는 사용 가능 여부에 따라 시간 슬롯을 부여하는 예약 체계에 의존합니다.케이블 모뎀에는 CoS(Class of Service) 또는 QoS(Quality of Service) 매개변수에 매핑되는 SID(Service ID)가 할당됩니다.
TDMA(Time Division Multiplex Access) 네트워크의 경우 모든 요청 사용자에게 일정한 액세스 속도를 보장하려면 동시에 전송할 수 있는 총 CM(케이블 모뎀) 수를 제한해야 합니다.총 동시 사용자 수는 통계 확률 알고리즘인 포아송 분포를 기반으로 합니다.
트래픽 엔지니어링은 텔레포니 기반 네트워크에서 사용되는 통계로서 약 10%의 피크 사용량을 나타냅니다.이 계산은 이 문서의 범위를 벗어납니다.반면 데이터 트래픽은 음성 트래픽과 다릅니다.사용자가 컴퓨터에 더 익숙해지거나 VoIP(Voice over IP) 및 VoD(Video on Demand) 서비스를 더 많이 사용할 경우 이러한 변화가 발생할 것입니다.간소화를 위해 피크 사용자 50% × 사용자의 20%가 동시에 실제로 다운로드하는 것으로 가정해 봅니다.이는 최대 사용량 10%와 동일합니다.
모든 동시 사용자는 미국 및 DS 액세스를 위해 경쟁합니다.많은 모뎀이 초기 폴링에 대해 활성 상태일 수 있지만, 미국에서는 특정 시간에 한 모뎀만 활성 상태일 수 있습니다.이 기능은 노이즈 기여도에 있어서 효과적입니다. 한 번에 하나의 모뎀만 노이즈를 보완하므로 효과적입니다.
현재 표준에서 내재된 제한은 많은 모뎀이 단일 케이블 모뎀 종단 시스템(CMTS)에 연결되어 있는 경우 유지 관리 및 프로비저닝에 일부 처리량이 필요하다는 것입니다. 활성 고객의 실제 페이로드에서 제거됩니다.이를 keepalive 폴링이라고 하며, DOCSIS는 일반적으로 20초마다 한 번씩 발생하지만 더 자주 발생할 수 있습니다.또한 이 문서의 뒷부분에서 설명한 대로 모뎀당 미국 속도는 요청-허가 메커니즘으로 제한될 수 있습니다.
참고: 파일 크기에 대한 참조는 8비트로 구성된 바이트입니다.따라서 128kbps는 16KBps와 같습니다.마찬가지로, 1MB는 1,048,576바이트에 해당하며, 1백만 바이트는 아닙니다. 이진수는 항상 2의 제곱을 생성하기 때문입니다. 5MB 파일은 실제로 5 × 8 × 1,048,576 = 41.94Mb이며 예상보다 더 오래 다운로드할 수 있습니다.
처리량 계산
DS 포트 1개와 미국 포트 6개가 있는 CMTS 카드를 사용하고 있다고 가정합니다.하나의 DS 포트가 분할되어 약 12개의 노드를 공급합니다.이 네트워크의 절반은 그림 2에 나와 있습니다.
그림 2 - 네트워크 레이아웃 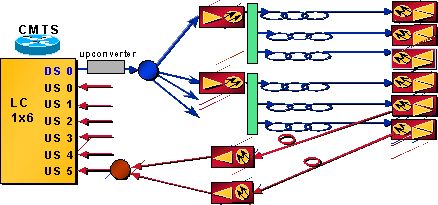
-
노드당 500개 홈 × 80% 케이블 테이크 속도 × 20% 모뎀 테이크 레이트 = 노드당 80개 모뎀
-
노드 12개 × 노드당 모뎀 80개 = DS 포트당 모뎀 960개
참고: 여러 서비스 운영자(MSO)는 이제 노드당 HHP(Conservers Passed)로 시스템을 수량화합니다.이는 DBS(Direct Broadcast Satellite) 가입자가 HSD(High Speed Data) 서비스를 구매하거나 비디오 서비스를 사용하지 않는 텔레포니만 구매할 수 있는 오늘날의 아키텍처에서는 유일하게 지속적인 기능입니다.
참고: 각 노드의 미국 신호는 2:1 비율로 결합되어 두 노드가 하나의 미국 포트를 공급합니다.
-
미국 포트 6개 × 미국당 노드 2개 = 노드 12개
-
노드당 80개의 모뎀 × 미국당 2개의 노드 = 미국 포트당 160개의 모뎀
다운스트림
DS 기호 속도 = 5.057 Msymbols/s 또는 Mbaud.약 18%의 필터 롤오프(알파)는 그림 3과 같이 5.057 × (1 + 0.18) = ~6MHz 폭 "헤스티스택"을 제공합니다.
그림 3 - 디지털 "Haystack" 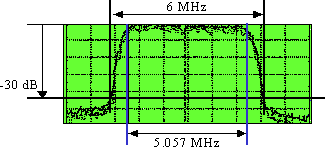
64-QAM을 사용하는 경우 64 = 2에서 6번째 전원(26)으로 이동합니다. 6의 지수는 64-QAM의 기호당 6비트를 의미합니다.5.057 x 6 = 30.3Mbps를 제공합니다.FEC(Forward Error Correction) 및 MPEG(Motion Picture Experts Group) 오버헤드가 계산되면 페이로드에 약 28Mbps가 남게 됩니다.이 페이로드는 DOCSIS 시그널링과 공유되므로 더 줄어듭니다.
참고: ITU-J.83 Annex B는 128/122 코드가 포함된 Reed-Solomon FEC를 나타내며, 이는 128개의 기호마다 오버헤드의 6개 기호를 의미하므로 6 / 128 = 4.7%입니다.Trellis 코딩은 15바이트마다 1바이트, 64QAM은 1바이트, 20바이트당 1바이트는 256-QAM입니다.각각 6.7%와 5%입니다.MPEG-2는 오버헤드가 4바이트(때로는 5바이트)인 188바이트 패킷으로 구성되어 4.5 / 188 = 2.4%를 제공합니다.따라서 속도가 27Mbps, 64QAM의 경우 68Mbps, 256-QAM의 경우 38Mbps로 표시됩니다.1500바이트 패킷이든 46바이트 패킷이든 이더넷 패킷에는 18바이트의 오버헤드가 있습니다.또한 DOCSIS 오버헤드와 IP 오버헤드가 6바이트에 있으며, 이는 총 오버헤드가 1.1~2.8% 정도 추가되고 DOCSIS MAP 트래픽에 오버헤드가 2% 더 발생할 수 있습니다.64QAM에 대해 실제 테스트된 속도는 26Mbps에 가까웠습니다.
960개의 모뎀이 모두 데이터를 동시에 다운로드하는 매우 드문 경우이지만, 각 모뎀은 약 28kbps만 사용하게 됩니다.더 현실적인 시나리오를 보고 피크 사용량이 10%라고 가정하면 가장 바쁜 시간 동안 최악의 시나리오로 이론상 처리량이 280kbps를 얻게 됩니다.온라인 상태인 고객이 한 명뿐이라면 이론적으로 26Mbps를 받게 됩니다.그러나 TCP를 위해 전송해야 하는 미국 응답에서는 DS 처리량이 제한되고 기타 병목 현상이 분명히 드러납니다(예: PC 또는 NIC[Network Interface Card]). 실제로 케이블 회사는 이를 1 또는 2Mbps로 제한하므로, 더 많은 가입자가 가입하면 달성할 수 없는 사용 가능한 처리량에 대한 인식을 형성하지 않습니다.
업스트림
DOCSIS US QPSK의 2비트/기호 변조는 약 2.56Mbps를 제공합니다.이는 1.28 Msymbols/s x 2비트/기호의 기호 속도로 계산됩니다.필터 알파는 25%로, 대역폭(BW)은 1.28 × (1 + 0.25) = 1.6MHz를 제공합니다.FEC를 사용하는 경우 약 8%를 빼십시오.또한 유지 관리, 경합을 위한 예약된 시간 슬롯, 확인("acks") 오버헤드의 약 5~10%가 있습니다. 따라서 미국 포트당 약 2.2Mbps의 잠재 고객이 160명에 달합니다.
참고: DOCSIS 레이어 오버헤드 = 64바이트 ~ 1518바이트 이더넷 프레임당 6바이트(VLAN 태깅을 사용하는 경우 1522바이트 가능) 또한 최대 버스트 크기 및 연결 또는 단편화를 사용할지 여부에 따라 달라집니다.
-
미국 FEC는 다음과 같은 변수입니다.~128/1518 또는 ~12/64 = ~8 또는 ~18%약 10%는 유지 보수, 경합을 위한 예약된 시간 슬롯 및 해킹에 사용됩니다.
-
BPI 보안 또는 확장 헤더 = 0~240바이트(일반적으로 3~7).
-
프리앰블 = 9~20바이트.
-
Guardtime >= 5 기호 = ~2바이트.
피크 사용량이 10%라고 가정하면 2.2Mbps/(160 × 0.1) = 137.5kbps를 가입자당 최악의 페이로드로 제공합니다.일반적인 가정용 데이터 사용량(예: 웹 브라우징)의 경우 DS만큼 미국적인 처리량이 필요하지 않을 수 있습니다.이 속도는 가정용 사용하기에 충분할 수 있지만 상용 서비스 구축에는 충분하지 않습니다.
제한 요소
"실제" 데이터 처리량에 영향을 주는 제한 요인이 너무 많습니다.Request-and-Grant 주기에서 DS 인터리빙에 이르는 다양한 기능을 제공합니다.이러한 한계를 이해하면 기대와 최적화에 도움이 됩니다.
다운스트림 성능 - MAP
모뎀으로 전송되는 MAP 메시지의 전송은 DS 처리량을 줄입니다.모뎀이 미국 전송을 위해 시간을 요청할 수 있도록 DS에 시간 지도가 전송됩니다.MAP이 2ms마다 전송되면 최대 1/0.002s = 500개의 MAPs/s가 추가됩니다.MAP이 64바이트를 차지하는 경우, 64바이트 × 바이트당 8비트 × 500MAP/s = 256kbps.CMTS 섀시의 단일 블레이드에 미국 포트 6개와 DS 포트 1개가 있는 경우, 이는 6 x 256000bps = 모든 모뎀의 MAP 메시지를 지원하는 데 사용되는 DS 처리량 ~1.5Mbps입니다.이는 MAP이 64바이트이며 실제로 2ms마다 전송된다고 가정합니다.실제로 MAP 크기는 변조 체계 및 사용되는 미국 대역폭의 양에 따라 약간 더 클 수 있습니다.이는 3~10%의 오버헤드가 될 수 있습니다.또한 DS 채널에서 전송되는 다른 시스템 유지 보수 메시지가 있습니다.또한 오버헤드가 증가합니다.그러나 이러한 효과는 일반적으로 무시해도 됩니다.CPU가 모든 MAP을 추적해야 하기 때문에 MAP 메시지는 DS 처리량 성능뿐만 아니라 CPU(Central Processing Unit)에도 부담이 될 수 있습니다.
TDMA 및 표준 코드 분할 다중 액세스(S-CDMA) 채널을 동일한 미국 국가에 배치할 경우 CMTS는 각 물리적 포트에 대해 "이중 맵"을 보내야 합니다.따라서 DS MAP 대역폭 소비량은 두 배로 증가합니다.이 사양은 DOCSIS 2.0 사양의 일부이며 상호 운용성을 위해 필요합니다.또한 미국 채널 설명자와 기타 미국 제어 메시지도 두 배가 됩니다.
업스트림 성능 - DOCSIS 레이턴시
미국 경로에서는 CMTS와 CM 간의 요청-허가 주기는 RTT(Round Trip Time), MAP의 길이 및 MAP 고급 시간에 따라 다른 모든 맵만 활용할 수 있습니다.이는 DS 인터리빙의 영향을 받는 RTT와 DOCSIS가 모뎀이 특정 시간에 단일 요청 미해결 상태를 유지할 수 있도록 허용하며 이와 관련된 "Request-to-Grant latency"를 허용하기 때문입니다.이 레이턴시는 프로토콜에 따라 CM과 CMTS 간의 통신에 기인합니다.간단히 말해, CM은 먼저 CMTS에서 데이터 전송 권한을 요청해야 합니다.CMTS는 이러한 요청을 서비스하고, MAP 스케줄러의 가용성을 확인한 다음, 다음 유니캐스트 전송 기회에 대해 대기해야 합니다.DOCSIS 프로토콜에 의해 의무화된 이러한 백오프-오프 커뮤니케이션은 이러한 레이턴시를 생성합니다.마지막 요청에서 DS에 대한 권한 부여가 반환되기를 기다리고 있으므로 모뎀에서 다른 모든 MAP을 놓칠 수 있습니다.
MAP 간격이 2ms이면 초당 MAP 500개/2 = 초당 ~250개의 MAP 오퍼튜니티를 생성하므로 250개의 PPS가 발생합니다.500 MAP은 "실제" 플랜트에서 요청과 보조금 간의 RTT가 2ms보다 훨씬 길기 때문에 2로 나누어집니다.4ms가 넘을 수 있으며 이는 다른 모든 MAP 기회가 될 것입니다.1518바이트 이더넷 프레임으로 구성된 일반적인 패킷이 250PPS로 전송될 경우, 바이트에 8비트가 있기 때문에 약 3Mbps가 됩니다.이는 단일 모뎀의 미국 처리량에 대한 실질적인 제한입니다.약 250PPS의 제한이 있는 경우 패킷이 작은 경우(64바이트) 어떻게 됩니까?그것은 단지 128kbps입니다.연결(concatenation)이 도움이 되는 부분입니다.이 문서의 연결 및 조각화 효과 섹션을 참조하십시오.
미국 채널에 사용되는 기호 속도 및 변조 체계에 따라 1518바이트 패킷을 전송하는 데 5ms 이상이 걸릴 수 있습니다.패킷 US를 CMTS로 전송하는 데 5ms가 넘는 시간이 소요되면 CM은 DS에서 약 3개의 MAP 기회를 놓쳤습니다.이제 PPS는 165개 정도에 불과합니다.MAP 시간을 줄이면 DS 오버헤드가 더 많이 발생하여 MAP 메시지가 더 많이 발생할 수 있습니다.MAP 메시지가 늘어나면 미국 전송에 더 많은 기회를 얻을 수 있지만, 진정한 하이브리드 HFC(Fiber-Coaxial) 플랜트에서는 이러한 기회를 놓치게 됩니다.
다행히 DOCSIS 1.1에는 음성 트래픽이 이 요청 및 허가 주기를 피할 수 있도록 하는 UGS(Unsolicited Grant Service)가 추가되었습니다.대신 음성 패킷은 통화가 끝날 때까지 10ms 또는 20ms마다 예약됩니다.
참고: CM에서 대용량 데이터 블록(예: 20MB 파일)을 전송할 경우, 개별 요청을 사용하는 대신 데이터 패킷에서 대역폭 요청을 피시백하지만 모뎀은 요청 및 허가 주기를 수행해야 합니다.Piggybacking을 사용하면 충돌 슬롯 대신 전용 시간 슬롯의 데이터와 함께 요청을 보내 충돌 및 손상된 요청을 제거할 수 있습니다.
TCP 또는 UDP?
처리량 성능을 테스트할 때 자주 간과되는 점은 사용 중인 실제 프로토콜입니다.TCP와 같은 연결 지향 프로토콜 또는 UDP(User Datagram Protocol)와 같은 연결 없는 프로토콜입니까?UDP는 수신한 품질에 관계없이 정보를 전송합니다.이를 종종 "최선형" 전달이라고 합니다.일부 비트가 오류로 수신되면 작업을 수행하고 다음 비트로 이동합니다.TFTP는 이 최선의 프로토콜의 또 다른 예입니다.이것은 실시간 오디오 또는 스트리밍 비디오에 대한 일반적인 프로토콜입니다.반면 TCP는 전송된 패킷이 올바르게 수신되었음을 확인하기 위해 승인을 요구합니다.FTP는 이를 예로 들 수 있습니다.네트워크가 잘 유지되면 프로토콜이 동적이므로 확인 응답을 요청하기 전에 추가 패킷을 연속적으로 전송할 수 있습니다.이를 전송 제어 프로토콜의 표준 부분인 "윈도우 크기 증가"라고 합니다.
참고: TFTP에 대해 주목해야 할 한 가지는 UDP를 사용하므로 오버헤드를 덜 사용하지만 일반적으로 스텝 랙 접근 방식을 사용하므로 처리량이 매우 어렵습니다.즉, 두 개 이상의 미처리 데이터 패킷이 있을 수 없습니다.따라서 실제 처리량에 대한 좋은 테스트는 아닐 것입니다.
여기서 요점은 DS 트래픽이 더 많은 감사의 형태로 미국 트래픽을 생성한다는 것입니다.또한 미국을 잠시 중단하면 TCP 확인 응답이 삭제될 경우 TCP 흐름의 속도가 느려집니다.이는 UDP에서는 발생하지 않습니다.미국 경로가 끊기면 CM은 약 30초 후에 keepalive 폴링에 실패하고 DS를 다시 스캔하기 시작합니다.TCP 패킷은 대기되거나 손실되고 DS UDP 트래픽은 유지되기 때문에 TCP와 UDP 모두 짧은 중단에서 살아남을 수 있습니다.
미국의 처리량은 DS 처리량도 제한할 수 있습니다.예를 들어, DS 트래픽이 동축 또는 위성을 통해 이동하는 경우 미국 트래픽이 전화선을 통해 이동할 경우, 최대 10Mbps로 광고되었을 수도 있지만 28.8kbps의 미국 처리량은 DS 처리량을 1.5Mbps 미만으로 제한할 수 있습니다.이는 저속 링크가 승인 US 흐름에 레이턴시를 추가함으로써 TCP가 DS 플로우의 속도를 낮추기 때문입니다.이러한 병목 문제를 해결하기 위해 Telco Return은 PPP(Point-to-Point Protocol)를 활용하고 승인을 훨씬 작게 만듭니다.
DS의 MAP 생성은 미국의 Request-and-Grant 주기에 영향을 미칩니다.TCP 트래픽이 처리되면 승인 또한 요청 및 부여 주기를 거쳐야 합니다.미국 내에서 감사의 내용이 연결되지 않을 경우, DS는 크게 저해될 수 있습니다.예를 들어, "게이머"는 512바이트 패킷으로 DS에서 트래픽을 전송할 수 있습니다.미국이 234PPS로 제한되고 DS가 승인당 2패킷인 경우 512 × 8 × 2 × 234 = 1.9Mbps입니다.
창의 TCP/IP 스택
일반적인 윈도우 속도는 2.1~3Mbps 다운로드입니다.UNIX 또는 Linux 디바이스는 TCP/IP 스택이 향상되고 수신되는 다른 모든 DS 패킷에 대해 ACK를 보낼 필요가 없으므로 성능이 더 좋은 경우가 많습니다.성능 제한이 Windows TCP/IP 드라이버 내에 있는지 확인할 수 있습니다.이 드라이버는 제한된 ACK 성능 동안 동작하는 경우가 많습니다.인터넷에서 프로토콜 분석기를 사용할 수 있습니다.이 프로그램은 인터넷 연결 매개변수를 표시하도록 설계되었으며, 서버로 전송하는 TCP 패킷에서 직접 추출됩니다.프로토콜 분석기는 특수 웹 서버로 작동합니다.그러나 다른 웹 페이지는 제공하지 않습니다.동일한 페이지로 모든 요청에 응답합니다.이 값은 요청 클라이언트의 TCP 설정에 따라 수정됩니다.그런 다음 실제 분석을 수행하는 CGI 스크립트로 제어를 전송하고 결과를 표시합니다.프로토콜 분석기를 사용하면 다운로드한 패킷의 길이가 1518바이트(DOCSIS MTU[Maximum Transmission Unit])인지 확인하고 미국 승인이 약 160~175PPS에 실행되는지 확인할 수 있습니다.패킷이 이러한 속도 이하인 경우 Windows 드라이버를 업데이트하고 UNIX 또는 Windows NT 호스트를 조정합니다.
레지스트리에서 설정을 변경하여 Windows 호스트를 조정할 수 있습니다.먼저 MTU를 늘릴 수 있습니다.MTU라고 하는 패킷 크기는 네트워크의 한 물리적 프레임에서 전송할 수 있는 최대 데이터 양입니다.이더넷의 경우 MTU는 1518바이트입니다.PPPoE의 경우 1492입니다.다이얼업 연결의 경우 576입니다. 이러한 차이점은 패킷이 더 큰 경우 오버헤드가 작을수록 라우팅 결정을 덜 내리고, 클라이언트에서 프로토콜 처리 및 디바이스 인터럽트를 덜 받는다는 점입니다.
각 전송 단위는 헤더와 실제 데이터로 구성됩니다.실제 데이터를 MSS(Maximum Segment Size)라고 하며, 이는 전송할 수 있는 TCP 데이터의 가장 큰 세그먼트를 정의합니다.기본적으로 MTU = MSS + TCP/IP 헤더.따라서 MSS를 1380으로 조정하여 각 패킷의 최대 유용한 데이터를 반영할 수 있습니다.또한 현재 MTU 및 MSS 설정을 조정한 후 기본 수신 창(RWIN)을 최적화할 수 있습니다.프로토콜 분석기가 최상의 가치를 제시합니다.프로토콜 분석기를 사용하면 다음 설정을 확인할 수도 있습니다.
Windows 레지스트리에서 서로 다른 네트워크 설정을 사용하면 네트워크 프로토콜이 달라집니다.케이블 모뎀의 최적 TCP 설정은 Windows의 기본 설정과 다른 것 같습니다.따라서 각 운영 체제에는 레지스트리를 최적화하는 방법에 대한 구체적인 정보가 있습니다.예를 들어, Windows 98 이상 버전에서는 TCP/IP 스택이 일부 개선되었습니다.여기에는 다음이 포함됩니다.
-
RFC1323에 설명된 대로 대형 창 지원

-
SACK(Selective Acknowledgment) 지원
-
신속한 재전송 및 빠른 복구 지원
Windows 95용 WinSock 2 업데이트는 TCP 대용량 창과 타임스탬프를 지원합니다. 즉, 원래 Windows 소켓을 버전 2로 업데이트하면 Windows 98 권장 사항을 사용할 수 있습니다. Windows NT는 TCP/IP 처리 방식에서 Windows 9x와 약간 다릅니다.Windows NT 조정 기능을 적용하면 NT가 네트워킹에 더 최적화되어 있기 때문에 Windows 9x보다 성능이 더 낮아집니다.
그러나 Windows 레지스트리를 변경하려면 Windows 사용자 지정에 몇 가지 숙련도가 필요합니다.레지스트리 편집이 불편할 경우 인터넷에서 "사용 가능" 패치를 다운로드해야 합니다. 그러면 레지스트리에서 최적의 값을 자동으로 설정할 수 있습니다.레지스트리를 편집하려면 Regedit와 같은 편집기를 사용해야 합니다(START > Run을 선택하고 Open 필드에 Regedit를 입력합니다).
성능 개선 요인
처리량 결정
데이터 처리량에 영향을 줄 수 있는 요인은 다음과 같습니다.
-
총 사용자 수
-
병목 속도
-
액세스한 서비스 유형
-
캐시 서버 사용
-
MAC 레이어 효율성
-
케이블 플랜트의 소음 및 오류
-
Windows TCP/IP 드라이버 내부의 제한 사항 등 여러 가지 다른 요소
"파이프"를 공유하는 사용자가 많을수록 서비스 속도가 느려집니다.또한 병목 현상은 네트워크가 아니라 액세스하는 웹 사이트일 수 있습니다.사용 중인 서비스를 고려할 때, 시간이 흐르면 일반 이메일과 웹 서핑은 매우 비효율적입니다.비디오 스트리밍을 사용하는 경우 이러한 유형의 서비스에 더 많은 시간 슬롯이 필요합니다.
프록시 서버를 사용하여 자주 다운로드되는 일부 사이트를 로컬 영역 네트워크에 있는 컴퓨터에 캐시하여 전체 인터넷 트래픽의 완화에 도움을 줄 수 있습니다.
DOCSIS 모뎀의 기본 구성표는 "예약 및 허용"이지만 모뎀당 속도는 제한됩니다.이 계획은 폴링 또는 순수 CSMA/CD에 비해 가정용 사용에 훨씬 더 효과적입니다.
액세스 속도 향상
많은 시스템이 노드당 홈 비율을 1000~500~250에서 PON(Passive Optical Network) 또는 FTTH(Fiber-to-Home)로 줄이고 있습니다.PON이 올바르게 설계되면 연결된 활성 없이 노드당 최대 60명을 전달할 수 있습니다.FTTH는 일부 지역에서 테스트되고 있지만, 대부분의 사용자에게 여전히 매우 비용이 많이 듭니다.노드당 홈 수를 줄이지만 헤드엔드에 수신기를 결합하면 실제로 더 나빠질 수 있습니다.파이버수신기 2개가 1개보다 심각하지만 파이버당 홈이 적을수록 인그레스(ingress)에서 레이저 클리핑을 경험할 가능성이 적습니다.
가장 분명한 세그멘테이션 기법은 더 많은 광섬유 장비를 추가하는 것입니다.일부 새로운 설계는 노드당 홈 수를 50~150HHP로 줄입니다.HE(Headend)에서 다시 결합하면 노드당 홈을 줄이는 것은 좋지 않습니다.노드당 500개의 홈으로 구성된 광 링크 두 개를 HE에 결합하고 동일한 CMTS 미국 포트를 공유한다면, 현실적으로 노드당 1000개의 홈으로 구성된 광 링크 한 개를 사용했을 때보다 더 악화될 수 있습니다.
여러 번 옵티컬 링크를 통해 다양한 액티브가 다시 풀링되더라도 노이즈 발생률이 제한됩니다.노드당 홈 수가 아니라 서비스를 세그먼트화해야 합니다.CMTS 포트 또는 서비스당 주택 수를 줄이는 데 더 많은 비용이 들겠지만, 특히 병목현상을 완화시킬 것입니다.노드당 집수가 적다는 것은 더 적은 소음과 인그레스(ingress)로 인해 레이저 클리핑이 발생할 수 있으며, 나중에 더 적은 수의 미국 포트로 분할하기가 더 쉽다는 점입니다.
DOCSIS는 DS와 미국, 미국 경로에 사용할 5개의 서로 다른 변조 체계를 지정했습니다.서로 다른 기호 속도는 QPSK 또는 16-QAM과 같은 다른 변조 체계를 가진 0.16, 0.32, 0.64, 1.28 및 2.56 Msymbols/s입니다.이를 통해 반환 시스템을 사용하는 데 필요한 견고성과 비교하여 필요한 처리량을 유연하게 선택할 수 있습니다.DOCSIS 2.0은 더 많은 유연성을 추가했으며, 이 문서의 뒷부분에서 확장될 예정입니다.
또한 주파수 호핑의 가능성이 있어 "비 communicator"에서 다른 주파수로 전환(hop)할 수 있습니다.여기서 타협점을 찾는다면 더 많은 대역폭 이중화를 할당해야 하며, 희망적으로, 홉이 만들어지기 전에 "기타" 주파수가 깨끗합니다.일부 제조업체에서는 모뎀을 "도약 전에 살펴보기"로 설정합니다.
기술이 더욱 발전함에 따라 더 효율적으로 압축하거나 더 강력한 프로토콜이나 대역폭 사용량이 적은 고급 프로토콜로 정보를 전송하는 방법이 발견됩니다.DOCSIS 1.1 QoS 프로비저닝, PHS(Payload Header Suppression) 또는 DOCSIS 2.0 기능을 사용해야 할 수 있습니다.
견고함과 처리량 사이에는 항상 확실한 관계가 있습니다.네트워크에서 나가는 속도는 일반적으로 사용되는 대역폭, 할당된 리소스, 간섭 방지 견고성 또는 비용과 관련되어 있습니다.
채널 폭 및 변조
앞서 설명한 DOCSIS 레이턴시로 인해 미국 처리량은 약 3Mbps로 제한되는 것으로 보입니다.또한 미국 대역폭을 3.2MHz로 늘리거나 16-QAM으로 변조하면 이론상 처리량이 10.24Mbps인 것처럼 보일 수 있습니다.채널 BW와 변조가 증가해도 모뎀당 전송 속도는 크게 증가하지 않지만 채널에서 더 많은 모뎀을 전송할 수 있습니다.미국은 TDMA 기반의 슬롯 경합 매체이며, CMTS에서 시간 슬롯을 부여한다는 점을 기억하십시오.채널 BW가 많을수록 USbps가 늘어납니다. 즉 더 많은 모뎀이 지원될 수 있습니다.따라서 미국 채널 대역폭을 늘리는 것이 중요합니다.또한 1518바이트 패킷은 미국에서 1.2ms의 유선 시간만 사용하고 RTT 레이턴시를 지원합니다.
또한 DS 변조를 256-QAM으로 변경하여 DS의 총 처리량을 40% 늘리고 미국 성능의 인터리브 지연을 줄일 수 있습니다.그러나 변경 시 시스템의 모든 모뎀을 일시적으로 끊는다는 점에 유의하십시오.
 주의: DS 변조를 변경하기 전에 매우 주의해야 합니다.시스템이 256-QAM 신호를 지원할 수 있는지 확인하려면 DS 스펙트럼을 철저하게 분석해야 합니다.이렇게 하지 않으면 케이블 네트워크 성능이 크게 저하될 수 있습니다.
주의: DS 변조를 변경하기 전에 매우 주의해야 합니다.시스템이 256-QAM 신호를 지원할 수 있는지 확인하려면 DS 스펙트럼을 철저하게 분석해야 합니다.이렇게 하지 않으면 케이블 네트워크 성능이 크게 저하될 수 있습니다.
주의: 케이블 다운스트림 변조 {64qam을 실행합니다. DS 변조를 256-QAM으로 변경하려면 | 256qam} 명령을 입력합니다.
VXR(config)# interface cable 3/0 VXR(config-if)# cable downstream modulation 256qam
미국 변조 프로필 및 반환 경로 최적화에 대한 자세한 내용은 How to Increase Return Path Availability and Throughput을 참조하십시오.또한 Cisco의 CMTS에서 케이블 변조 프로필 구성을 참조하십시오.기본 믹스 프로필에서 IUC(Short and Long Interval Usage Codes)의 uw8을 uw16으로 변경합니다.
주의: 채널 폭을 늘리거나 미국 변조를 변경하기 전에 각별히 주의해야 합니다.스펙트럼 분석기를 사용하여 미국 스펙트럼을 철저히 분석하여 16-QAM을 지원하는 적절한 CNR(Carrier-to-Noise Ratio)을 갖춘 넓은 범위의 밴드를 찾아야 합니다.이렇게 하지 않으면 케이블 네트워크 성능이 심각하게 저하되거나 총 미국 가동 중단이 발생할 수 있습니다.
주의: 미국 채널 폭을 높이려면 cable upstream channel-width 명령을 실행합니다.
VXR(config-if)# cable upstream 0 channel-width 3200000
고급 스펙트럼 관리를 참조하십시오.
인터리빙 효과
증폭기 전원 공급 장치 및 DS 경로에 전원을 공급하는 유틸리티에서 발생하는 전기 버스트 소음으로 인해 블록 오류가 발생할 수 있습니다.이로 인해 열 소음으로 분산되는 오류보다 처리량 품질에 문제가 발생할 수 있습니다.버스트 오류의 영향을 최소화하려는 시도에서 인터리빙이라고 하는 기술이 사용되며 시간이 지남에 따라 데이터를 분산합니다.전송 끝의 기호는 혼합되어 수신 끝에 리어셈블되므로 오류가 분산되어 나타납니다.FEC는 분산된 오류에 매우 효과적입니다.인터리빙을 사용할 경우 상대적으로 긴 간섭 버스트로 인해 발생하는 오류는 FEC에서 수정할 수 있습니다.대부분의 오류가 버스트될 때 발생하므로 오류 속도를 높일 수 있습니다.
참고: FEC 인터리브 값을 늘리면 네트워크에 레이턴시를 추가합니다.
DOCSIS는 5가지 인터리빙 레벨을 지정합니다(EuroDOCSIS에는 1개만 있음).128:1은 인터리빙의 가장 큰 금액이며 8시 16분이 가장 낮습니다.128:1은 128개의 기호로 구성된 128개의 코드워드가 1을 기준으로 혼용됨을 나타냅니다.8:16은 16개의 기호가 코드워드당 한 줄에 유지되며 7개의 다른 코드 워드에서 16개의 심볼과 혼합됨을 나타냅니다.
다운스트림 인터리버 지연에 사용할 수 있는 값은 마이크로초(마이크로초)입니다.
| I(탭 수) | J(증분) | 64-QAM | 256-QAM |
|---|---|---|---|
| 8 | 16 | 220 | 150 |
| 16 | 8 | 480 | 330 |
| 32 | 4 | 980 | 680 |
| 64 | 2 | 2000 | 1400 |
| 128 | 1 | 4000 | 2800 |
인터리빙은 FEC와 같은 오버헤드 비트를 추가하지 않습니다.하지만 레이턴시가 추가되어 음성 및 실시간 비디오에 영향을 미칠 수 있습니다.또한 Request-and-Grant RTT가 증가하므로 다른 모든 MAP 오퍼튜니티에서 세 번째 또는 네 번째 MAP으로 이동할 수 있습니다.이는 2차 효과이며, 이는 미국 내 최대 데이터 처리량을 줄일 수 있는 효과입니다.따라서 값이 일반 기본값인 32보다 낮은 숫자로 설정된 경우 미국 처리량(모뎀당 PPS)을 약간 늘릴 수 있습니다.
충동 노이즈 문제를 해결하려면 인터리빙 값을 64 또는 128로 늘릴 수 있습니다. 그러나 이 값을 늘리면 성능(처리량)이 저하될 수 있지만 DS에서 노이즈 안정성이 증가합니다.다시 말해, 그 발전소는 적절하게 유지되어야 합니다.DS에서 수정 불가능한 오류(패킷 손실)가 나타날 경우, 모뎀의 연결이 끊기기 시작하고 재전송이 더 많은 시점까지 발생할 수 있습니다.
DS 경로의 노이즈를 보완하기 위해 인터리브 깊이를 높일 경우, CM의 최대 처리량이 감소하는 것을 고려해야 합니다.대부분의 주거지에서, 그것은 문제가 아니지만, 절충을 이해하는 것은 좋습니다.128:1(4ms)의 최대 인터리버 깊이로 이동하면 미국 처리량에 심각한 부정적 영향을 미칩니다.
참고: 64-QAM과 256-QAM의 지연은 다릅니다.
케이블 다운스트림 인터레브 깊이 {8을(를) 발급할 수 있습니다. | 16 | 32 | 64 | 128} 명령다음은 인터리브 깊이를 8로 낮추는 예입니다.
VXR(config-if)# cable downstream interleave-depth 8
주의: 이 명령은 구현될 때 시스템의 모든 모뎀을 분리합니다.
미국의 소음으로 견고하기 때문에 DOCSIS 모뎀은 FEC를 변경하거나 사용하지 않습니다.미국 FEC를 끄면 오버헤드가 제거되고 더 많은 패킷이 전달되도록 허용하지만, 소음에 대한 견고성 때문에 비용이 듭니다.또한 버스트 유형과 관련하여 서로 다른 양의 FEC를 갖는 것이 유리합니다.실제 데이터를 위한 버스트입니까, 아니면 스테이션 유지 관리를 위한 버스트입니까?데이터 패킷은 64바이트 또는 1518바이트로 구성됩니까?더 큰 패킷에 대해 더 많은 보호가 필요할 수 있습니다.또한 감소되는 반향의 지점이 있습니다.예를 들어 7%에서 14%로 변경하면 0.5dB의 견고성만 향상될 수 있습니다.
현재 미국에는 인터리빙이 없습니다. 전송이 버스트되고 버스트 내에 인터리빙을 지원할 충분한 레이턴시가 없기 때문입니다.일부 칩 제조업체는 DOCSIS 2.0 지원을 위해 이 기능을 추가하며, 가정 어플라이언스에서 발생하는 모든 충동 소음을 고려할 경우 큰 영향을 미칠 수 있습니다.미국 인터리빙은 FEC가 더 효과적으로 작업할 수 있도록 할 것입니다.
동적 MAP 고급
Dynamic Map Advance는 MAP에서 동적 미리 보기 시간을 사용하여 모뎀당 미국 처리량을 크게 개선할 수 있습니다.Dynamic Map Advance는 특정 미국 포트와 연결된 가장 먼 CM을 기반으로 MAP에서 미리 보는 시간을 자동으로 조정하는 알고리즘입니다.
맵 고급에 대한 자세한 설명은 케이블 맵 고급(동적 또는 고정?)을 참조하십시오.
Map Advance(맵 고급)가 Dynamic(동적)인지 확인하려면 show controllers cable slot/port upstream port 명령을 실행합니다.
Ninetail# show controllers cable 3/0 upstream 1 Cable3/0 Upstream 1 is up Frequency 25.008 MHz, Channel Width 1.600 MHz, QPSK Symbol Rate 1.280 Msps Spectrum Group is overridden BroadCom SNR_estimate for good packets - 28.6280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2809 Ranging Backoff automatic (Start 0, End 3) Ranging Insertion Interval automatic (60 ms) Tx Backoff Start 0, Tx Backoff End 4 Modulation Profile Group 1 Concatenation is enabled Fragmentation is enabled part_id=0x3137, rev_id=0x03, rev2_id=0xFF nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 8 Minislot Size in Symbols = 64 Bandwidth Requests = 0xE224 Piggyback Requests = 0x2A65 Invalid BW Requests= 0x6D Minislots Requested= 0x15735B Minislots Granted = 0x15735F Minislot Size in Bytes = 16 Map Advance (Dynamic) : 2454 usecs UCD Count = 568189 DES Ctrl Reg#0 = C000C043, Reg#1 = 17
앞에서 설명한 대로 인터리브 깊이가 8인 경우 DS 레이턴시가 줄어들기 때문에 Map Advance를 더욱 줄일 수 있습니다.
연결 및 단편화 효과
DOCSIS 1.1 및 일부 현재 1.0 장비는 연결이라는 새로운 기능을 지원합니다.DOCSIS 1.1에서도 단편화가 지원됩니다. 연결을 통해 여러 개의 작은 DOCSIS 프레임을 하나의 큰 DOCSIS 프레임으로 결합하고 하나의 요청과 함께 보낼 수 있습니다.
요청 중인 바이트 수는 최대 255개의 미니슬롯을 가지며, 일반적으로 미니슬롯당 8 또는 16바이트가 있기 때문에, 미국 내 전송 간격 중 전송할 수 있는 최대 바이트 수는 약 2040 또는 4080바이트입니다.이 금액에는 모든 FEC 및 물리적 레이어 오버헤드가 포함됩니다.따라서 이더넷 프레이밍의 실제 최대 버스트는 그 중 90%에 더 가깝고 단편화된 그랜트와는 상관이 없습니다.2-tick 미니슬롯에서 3.2MHz에서 16-QAM을 사용하는 경우 미니슬롯은 16바이트가 됩니다.이렇게 하면 제한이 16 × 255 = 4080바이트 - 10% 물리적 레이어 오버헤드 = ~3672바이트가 됩니다.더 많이 연결하려면 미니슬롯을 4 또는 8 틱으로 변경하고 최대 오목 버스트 설정 8160 또는 16,320을 설정할 수 있습니다.
한 가지 주의 사항은 전송된 최소 버스트는 32 또는 64바이트이며, 미니슬롯으로 패킷을 자르는 경우 이 보다 강력한 세분화 때문에 더 많은 라운드 오프 오류가 발생합니다.
프래그먼트화를 사용하지 않는 한 VXR 섀시에서 MC28C 또는 MC16x 카드에 대해 최대 미국 버스트를 4000바이트 미만으로 설정해야 합니다.또한 VoIP를 사용하는 경우 DOCSIS 1.0 모뎀의 최대 버스트를 2000바이트 미만으로 설정합니다.왜냐하면 1.0 모뎀은 프래그먼트화를 수행할 수 없고 2000바이트는 UGS 플로우가 제대로 전송하기에 너무 길기 때문에 음성 지터를 얻을 수 있기 때문입니다.
따라서 연결(concatenation)은 큰 패킷에 그다지 유용하지 않을 수 있지만, 이 모든 짧은 TCP 승인을 위한 훌륭한 툴입니다.전송 오퍼튜니티당 여러 패킷을 허용하는 경우 연결은 기본 PPS 값을 그 배수로 늘립니다.
패킷이 연결되면 더 큰 패킷의 직렬화 시간이 더 오래 걸리고 RTT 및 PPS에 영향을 줍니다.따라서 1518바이트 패킷에 대해 일반적으로 250개의 PPS를 사용할 경우 연결 시 해당 패킷이 불가피하게 삭제됩니다.이제 연결된 패킷당 총 바이트 수가 늘어납니다.4개의 1518바이트 패킷을 연결할 수 있는 경우 3.2MHz의 16-QAM으로 전송하는 데 최소 3.9ms가 소요됩니다.DS 인터리빙과 프로세싱의 지연 시간이 추가되며 DS 맵은 8ms에 한할 수 있습니다.PPS는 114로 감소하지만 이제 PPS를 456으로 보이게 하는 4개의 연결이 연결되었습니다.처리량이 456 × 8 × 1518 = 5.5Mbps입니다.연결(concatenation)을 통해 다수의 미국 해킹을 하나의 요청만으로 전송할 수 있는 "게임" 예를 들어, DS TCP 플로우를 더욱 빠르게 만들 수 있습니다.이 CM에 대한 DOCSIS 구성 파일에 최대 US 버스트 설정 2000바이트가 있고 모뎀이 연결을 지원한다고 가정합니다.CM은 이론적으로 31개의 64바이트 해킹을 연결할 수 있습니다.이 큰 총 패킷은 CM에서 CMTS로 전송하는 데 다소 시간이 걸리기 때문에 PPS가 그에 따라 감소합니다.234개의 PPS가 소형 패킷 대신 더 큰 패킷의 경우 92PPS에 더 가깝습니다.92 PPS × 31 acks = 2852 PPS, 잠재적으로이는 약 512바이트 DS 패킷 × 바이트당 8비트 × ACK당 2패킷 × 초당 2852 랙 = 23.3Mbps입니다.그러나 대부분의 CM은 이보다 훨씬 낮은 속도로 제한될 것입니다.
미국에서는 CM이 이론적으로 512바이트 × 바이트당 8비트 × 110PPS × 3패킷 연결 = 1.35Mbps를 가질 수 있습니다.이 수치는 연결 없이 얻은 원래 수치보다 훨씬 더 좋다.그러나 프래그먼트화 시 프래그먼트화 시 더 심각합니다. 각 프래그먼트가 라운드오프되기 때문입니다.
참고: 두 개의 패킷을 연결하지 못하는 오래된 Broadcom 문제가 있었지만, 세 가지 방법으로 연결할 수 있었습니다.
연결을 활용하려면 Cisco IOS Software 릴리스 12.1(1)T 또는 12.1(1)EC 이상을 실행해야 합니다.가능하면 Broadcom 3300 기반 설계에서 모뎀을 사용해 보십시오.CM에서 연결을 지원하려면 CMTS에서 show cable modem detail, show cable modem mac 또는 show cable modem verbose 명령을 실행합니다.
VXR# show cable modem detail Interface SID MAC address Max CPE Concatenation Rx SNR Cable6/1/U0 2 0002.fdfa.0a63 1 yes 33.26
연결을 설정하거나 해제하려면 [no] cable upstream n concatenation 명령을 실행합니다. 여기서 n은 미국 포트 번호를 지정합니다.유효한 값은 0(케이블 인터페이스 라인 카드의 첫 번째 US 포트)으로 시작합니다.
참고: DOCSIS 1.0 대 1.1 및 최대 버스트 크기 설정의 연결 문제에 대한 자세한 내용은 최대 업스트림 버스트 매개변수의 기록을 참조하십시오.변경 사항을 적용하려면 모뎀을 재부팅해야 합니다.
단일 모뎀 속도
큰 프레임을 연결하고 모뎀 당 가능한 최고의 속도를 달성하는 것이 목표인 경우 미니슬롯을 32바이트로 변경하여 최대 버스트를 8160까지 허용할 수 있습니다.이것이 바로 전송한 패킷 중 가장 작은 패킷은 32바이트입니다.이는 길이가 16바이트밖에 되지 않는 Requests와 같은 작은 US 패킷에 대해 매우 효율적이지 않습니다.요청이 경합 영역에 있기 때문에 더 큰 요청이 발생하면 충돌이 발생할 가능성이 높습니다.또한 미니슬롯에 패킷을 슬라이싱할 때 더 많은 미니슬롯 라운드 오프 오류를 추가합니다.
이 모뎀의 DOCSIS 구성 파일에는 최대 트래픽 버스트 및 최대 오목 버스트 설정이 약 6100이어야 합니다.이렇게 하면 4개의 1518바이트 프레임을 연결할 수 있습니다.또한 모뎀은 프래그먼트화를 지원해야 하여 더 관리하기 쉬운 조각으로 분할할 수 있습니다.다음 요청은 대개 piggybacked이며 첫 번째 프래그먼트에 있기 때문에 모뎀이 예상보다 더 나은 PPS 속도를 얻을 수 있습니다.각 프래그먼트는 CM이 하나의 긴 연결 패킷을 보내려고 시도한 경우보다 직렬화하는 데 시간이 적게 걸립니다.
모뎀당 속도에 영향을 줄 수 있는 몇 가지 설정을 설명해야 합니다.Max Traffic Burst(최대 트래픽 버스트)는 1.0CM에 사용되며 1522에 대해 설정해야 합니다.일부 CM은 포함해서는 안 되는 다른 오버헤드를 포함했기 때문에 1600보다 커야 합니다.Max Concat Burst는 프래그먼트할 수 있는 1.1 모뎀에 영향을 미치므로 하나의 요청으로 여러 프레임을 연결할 수 있지만 VoIP 고려 사항을 위해 2000바이트 패킷으로 프래그먼트할 수 있습니다.일부 CM은 온라인 상태가 되지 않으므로 Max Traffic Burst 및 Max Concat Burst를 서로 동일하게 설정해야 할 수도 있습니다.
CMTS의 한 가지 명령은 케이블 업스트림 n rate-limit token-bucket shaping 명령입니다.이 명령은 컨피그레이션 파일 설정에 지시된 대로 자신을 감시하지 않는 경찰 CM을 도와줍니다.폴리싱이 패킷을 지연시킬 수 있으므로, 처리량을 조절한다고 의심되는 경우 이 기능을 해제합니다.이는 Max Concat Burst와 동일한 최대 트래픽 버스트를 설정하는 것과 관련이 있으므로 더 많은 테스트를 보증할 수 있습니다.
Toshiba는 CM에 Broadcom 칩셋을 사용하지 않았기 때문에 연결이나 단편화를 하지 않고 잘 작동했습니다.Cisco는 Libit를 사용했고 이제 PCX2200보다 높은 CM에서 TI를 사용합니다. Toshiba는 또한 PPS를 더 높이기 위해 다음 요청을 보조금 앞에 보냅니다.이 기능은 Request가 Piggybacked가 아니며 Request가 Contention Slot에 있다는 점을 제외하면 잘 작동합니다.많은 CM이 동일한 미국에 있을 때 삭제될 수 있습니다.
cable default-phy-burst 명령을 사용하면 CM 등록 실패 없이 CMTS를 DOCSIS 1.0 IOS 소프트웨어에서 1.1 코드로 업그레이드할 수 있습니다.일반적으로 DOCSIS 컨피그레이션 파일은 Max Traffic Burst에 대해 기본값인 0을 가지거나 비어 있습니다. 이 경우 모뎀이 등록될 때 reject(c)로 오류가 발생합니다.이는 거부 CoS입니다. 0은 1.1 코드로 허용되지 않는 무제한 최대 버스트를 의미하기 때문입니다(VoIP 서비스 및 최대 지연, 레이턴시, 지터 때문). cable default-phy-burst 명령은 DOCSIS 구성 파일 설정(0)을 재정의하며, 두 숫자 중 하단이 우선합니다.기본 설정은 2000이고 최대 크기는 8000입니다. 이 경우 5개의 1518바이트 프레임을 연결할 수 있습니다.0으로 설정하여 해제할 수 있습니다.
cable default-phy-burst 0
모뎀당 속도 테스트에 대한 권장 사항
-
64-QAM(6.4MHz 채널)의 경우 미국에서 A-TDMA(Advanced Time-Division Multiple Access)를 사용합니다.
-
미니슬롯 크기 2를 사용합니다. DOCSIS 한도는 버스트당 255개 미니슬롯이므로 미니슬롯당 255 x 48바이트 = 12240 최대 버스트 × 90% = ~11,000바이트.
-
프래그먼트화 및 연결할 수 있고 전이중 FastEthernet 연결이 있는 CM을 사용합니다.
-
DOCSIS 구성 파일을 최소 20MB의 작동 및 작동 중지 상태로 설정합니다.
-
미국 속도 제한 토큰 버킷 셰이핑을 끕니다.
-
cable upstream n data-backoff 3 5 명령을 실행합니다.
-
Max Traffic Burst 및 Max Concat Burst를 11000바이트로 설정합니다.
-
DS에서 256-QAM 및 16 인터리브를 사용합니다(8번 시도). 이렇게 하면 MAP의 지연 시간이 줄어듭니다.
-
올바르게 프래그먼트되는 IOS Software Release 15(BC2) 이미지를 사용하고 n fragment-force 2000 5 명령의 케이블 업스트림을 실행합니다.
-
UDP 트래픽을 CM에 푸시하고 최대값을 찾을 때까지 증가시킵니다.
-
TCP 트래픽을 푸시할 경우 CM을 통해 여러 PC를 사용합니다.
결과
-
Terayon TJ735는 15.7Mbps를 제공했습니다.연결된 프레임당 바이트 수가 줄어들고 CPU가 개선되어 속도가 좋을 수 있습니다.16바이트 조각 헤더와 내부 8200바이트 최대 버스트가 포함된 첫 번째 프레임과 6바이트 헤더의 경우 13바이트 연결 헤더가 있는 것 같습니다.
-
Motorola SB5100은 18Mbps를 제공했습니다.또한 1418바이트 패킷과 8개의 인터리브를 DS에 적용하여 19.7Mbps를 제공했습니다.
-
Toshiba PCX2500은 4,000바이트 내부 최대 버스트 제한을 가지고 있는 것으로 보이기 때문에 8Mbps를 제공했습니다.
-
암비트는 모토로라와 같은 결과를 내놓았다.18Mbps.
-
이러한 속도 중 일부는 다른 CM 트래픽과 경합할 때 감소할 수 있습니다.
-
1.0CM(프래그먼트할 수 없음)에 최대 버스트가 2000 미만이어야 합니다.
-
Motorola 및 Ambit CM을 통해 98%의 미국 사용률이 27.2Mbps로 달성되었습니다.
새 조각 명령
케이블 업스트림 n fragment-force fragment-threshold-of-fragments
| 매개 변수 | 설명 |
|---|---|
| n | 업스트림 포트 번호를 지정합니다.유효한 값은 케이블 인터페이스 라인 카드의 첫 번째 업스트림 포트에 대해 0으로 시작합니다. |
| 프래그먼트 임계값 | 프래그먼트화를 트리거할 바이트 수입니다.유효한 범위는 0~4000이며 기본값은 2000바이트입니다. |
| 프래그먼트 수 | 조각화된 각 프레임이 분할되는 동일한 크기 프래그먼트 수입니다.유효한 범위는 1~10이며 기본값은 3개의 프래그먼트입니다. |
DOCSIS 2.0 혜택
DOCSIS 2.0은 DS에 어떤 변경 사항도 추가하지 않았지만 미국에는 많은 변경 사항이 추가되었습니다.DOCSIS 2.0의 고급 물리적 레이어 사양에는 다음과 같은 추가 사항이 있습니다.
-
8-QAM, 32-QAM 및 64-QAM 모듈화 체계
-
6.4MHz 채널 폭
-
FEC의 최대 16T 바이트
또한 모뎀과 미국 인터리빙에서 24개의 이퀄라이제이션을 사용할 수 있습니다.이렇게 하면 반사, 채널 내 기울기, 그룹 지연 및 미국 버스트 노이즈가 더욱 강력해집니다.또한 CMTS의 24탭 균등화 기능은 이전 버전의 DOCSIS 1.0 모뎀에 도움이 됩니다.DOCSIS 2.0은 A-TDMA와 함께 S-CDMA의 사용도 추가합니다.
64QAM으로 스펙트럼 효율성이 향상되어 기존 채널을 더 효과적으로 사용하고 용량을 늘릴 수 있습니다.따라서 미국 방향에서는 처리량이 더 높고, PPS는 약간 더 나은 모뎀당 속도가 제공됩니다.6.4MHz에서 64QAM을 사용하면 CMTS로 대용량 패킷을 전송하는 데 평소보다 훨씬 빠르게 도움이 되므로 직렬화 시간이 짧아지므로 더 나은 PPS를 만들 수 있습니다.더 넓은 채널로 더 나은 통계 멀티플렉싱을 만들 수 있습니다.
A-TDMA로 얻을 수 있는 이론상의 최고 미국 속도는 약 27Mbps 정도(합계) 정도입니다. 이는 오버헤드, 패킷 크기 등에 따라 달라집니다.더 큰 집계 처리량을 변경해도 더 많은 사용자가 공유할 수 있지만, 모뎀 당 속도를 더 추가할 필요는 없습니다.
미국에서 A-TDMA를 실행하면 해당 패킷이 훨씬 더 빠릅니다.미국에서 6.4MHz의 64-QAM은 연결된 패킷을 미국에서 더 빠르게 직렬화할 수 있으며 더 나은 PPS를 달성할 수 있습니다.A-TDMA와 함께 2틱 미니슬롯을 사용하는 경우 미니슬롯당 48바이트(48 × 255 = 12240)를 요청당 최대 버스트로 얻을 수 있습니다.64-QAM, 6.4MHz, 2틱 미니슬롯, 최대 10,000 Max Concat Burst, 300 동적 맵 고급 안전성은 ~15Mbps를 제공합니다.
현재 모든 DOCSIS 2.0 실리콘 구현에서는 인그레스(ingress) 취소를 사용합니다. 이 기능은 DOCSIS 2.0의 일부가 아니지만 인그레스(ingress) 취소를 사용합니다. 이렇게 하면 최악의 플랜트 장애에 대한 서비스가 견고해지고 스펙트럼의 미사용 부분을 열고, 라이프라인 서비스에 대한 보험 기준을 추가할 수 있습니다.
기타 요소
케이블 네트워크의 성능에 직접적인 영향을 줄 수 있는 기타 요인이 있습니다.QoS 프로파일, 노이즈, 속도 제한, 노드 결합, 과다 사용 등.대부분의 내용은 케이블 모뎀 네트워크의 느린 성능 문제 해결에서 자세히 설명합니다.
케이블 모뎀 제한 사항도 나타나지 않을 수 있습니다.케이블 모뎀에 CPU 제한 또는 PC에 대한 반이중 이더넷 연결이 있을 수 있습니다.패킷 크기 및 양방향 트래픽 흐름에 따라 이는 고려되지 않은 병목 현상이 될 수 있습니다.
처리량 확인
모뎀이 있는 인터페이스에 대해 show cable modem 명령을 실행합니다.
ubr7246-2# show cable modem cable 6/0
MAC Address IP Address I/F MAC Prim RxPwr Timing Num BPI
State Sid (db) Offset CPE Enb
00e0.6f1e.3246 10.200.100.132 C6/0/U0 online 8 -0.50 267 0 N
0002.8a8c.6462 10.200.100.96 C6/0/U0 online 9 0.00 2064 0 N
000b.06a0.7116 10.200.100.158 C6/0/U0 online 10 0.00 2065 0 N
show cable modem mac 명령을 실행하여 모뎀의 기능을 확인합니다.그러면 모뎀이 수행 중인 작업을 수행할 수 있는 작업이 표시됩니다.
ubr7246-2# show cable modem mac | inc 7116
MAC Address MAC Prim Ver QoS Frag Concat PHS Priv DS US
State Sid Prov Saids Sids
000b.06a0.7116 online 10 DOC2.0 DOC1.1 yes yes yes BPI+ 0 4
show cable modem phy 명령을 실행하여 모뎀의 물리적 레이어 특성을 확인합니다.이 정보 중 일부는 CMTS에서 원격 쿼리가 구성된 경우에만 표시됩니다.
ubr7246-2# show cable modem phy
MAC Address I/F Sid USPwr USSNR Timing MicroReflec DSPwr DSSNR Mode
(dBmV)(dBmV) Offset (dBc) (dBmV)(dBmV)
000b.06a0.7116 C6/0/U0 10 49.07 36.12 2065 46 0.08 41.01 atdma
모뎀의 현재 US 설정을 확인하려면 show controllers cable slot/port upstream port 명령을 실행합니다.
ubr7246-2# show controllers cable 6/0 upstream 0 Cable6/0 Upstream 0 is up Frequency 33.000 MHz, Channel Width 6.400 MHz, 64-QAM Sym Rate 5.120 Msps This upstream is mapped to physical port 0 Spectrum Group is overridden US phy SNR_estimate for good packets - 36.1280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2066 Ranging Backoff Start 2, Ranging Backoff End 6 Ranging Insertion Interval automatic (312 ms) Tx Backoff Start 3, Tx Backoff End 5 Modulation Profile Group 243 Concatenation is enabled Fragmentation is enabled part_id=0x3138, rev_id=0x02, rev2_id=0x00 nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 2 Minislot Size in Symbols = 64 Bandwidth Requests = 0x7D52A Piggyback Requests = 0x11B568AF Invalid BW Requests= 0xB5D Minislots Requested= 0xAD46CE03 Minislots Granted = 0x30DE2BAA Minislot Size in Bytes = 48 Map Advance (Dynamic) : 1031 usecs UCD Count = 729621 ATDMA mode enabled
모뎀의 서비스 흐름을 보려면 show interface cable slot/port service-flow 명령을 실행합니다.
ubr7246-2# show interface cable 6/0 service-flow
Sfid Sid Mac Address QoS Param Index Type Dir Curr Active
Prov Adm Act State Time
18 N/A 00e0.6f1e.3246 4 4 4 prim DS act 12d20h
17 8 00e0.6f1e.3246 3 3 3 prim US act 12d20h
20 N/A 0002.8a8c.6462 4 4 4 prim DS act 12d20h
19 9 0002.8a8c.6462 3 3 3 prim US act 12d20h
22 N/A 000b.06a0.7116 4 4 4 prim DS act 12d20h
21 10 000b.06a0.7116 3 3 3 prim US act 12d20h
show interface cable slot/port service-flow sfid verbose 명령을 실행하여 해당 특정 모뎀에 대한 특정 서비스 흐름을 확인합니다.그러면 US 또는 DS 흐름의 현재 처리량과 모뎀의 구성 파일 설정이 표시됩니다.
ubr7246-2# show interface cable 6/0 service-flow 21 verbose Sfid : 21 Mac Address : 000b.06a0.7116 Type : Primary Direction : Upstream Current State : Active Current QoS Indexes [Prov, Adm, Act] : [3, 3, 3] Active Time : 12d20h Sid : 10 Traffic Priority : 0 Maximum Sustained rate : 21000000 bits/sec Maximum Burst : 11000 bytes Minimum Reserved Rate : 0 bits/sec Admitted QoS Timeout : 200 seconds Active QoS Timeout : 0 seconds Packets : 1212466072 Bytes : 1262539004 Rate Limit Delayed Grants : 0 Rate Limit Dropped Grants : 0 Current Throughput : 12296000 bits/sec, 1084 packets/sec Classifiers : NONE
지연되거나 삭제된 패킷이 없는지 확인합니다.
show cable hop 명령을 실행하여 수정 불가능한 FEC 오류가 없는지 확인합니다.
ubr7246-2# show cable hop cable 6/0
Upstream Port Poll Missed Min Missed Hop Hop Corr Uncorr
Port Status Rate Poll Poll Poll Thres Period FEC FEC
(ms) Count Sample Pcnt Pcnt (sec) Errors Errors
Cable6/0/U0 33.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U1 admindown 1000 * * * frequency not set * * * 0 0
Cable6/0/U2 10.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U3 admindown 1000 * * * frequency not set * * * 0 0
모뎀이 패킷을 삭제하는 경우 물리적 플랜트가 처리량에 영향을 미치므로 수정해야 합니다.
요약
이 문서의 이전 섹션에서는 다른 기능에 미치는 영향을 이해하지 않고 문맥에서 성능 번호를 빼낼 때의 단점을 강조합니다.특정 성능 메트릭을 달성하거나 네트워크 문제를 해결하기 위해 시스템을 세부적으로 조정할 수 있지만, 다른 변수를 사용하면 됩니다.MAPs/s 및 인터리브 값을 변경하는 경우 미국 요금이 더 높을 수 있지만 DS 속도 또는 견고성을 희생할 수 있습니다.MAP 간격을 줄이면 실제 네트워크에서 큰 차이가 없으며 CMTS와 CM 모두에서 CPU 및 대역폭 오버헤드가 증가합니다.더 많은 미국 FEC를 통합하면 미국 오버헤드가 증가합니다.처리량, 복잡성, 견고성 및 비용 간에는 항상 절충과 절충이 이루어집니다.
미국에서 입학 통제를 사용할 경우, 전체 배분을 다 쓰면 일부 모뎀이 등록되지 않게 될 것입니다.예를 들어, 미국 총계가 2.56Mbps이고 최소 보장 범위가 128k로 설정된 경우, 입학 제어가 100%로 설정된 경우 해당 미국에서 20개의 모뎀만 등록할 수 있습니다.
결론
어떤 가입자의 데이터 속도와 성능을 기대할 수 있는지 파악해야 합니다.이론적으로 무엇이 가능한지 결정하면 동적으로 변화하는 케이블 시스템 요구 사항을 충족하도록 네트워크를 설계 및 관리할 수 있습니다.그런 다음 실제 트래픽 로드를 모니터링하여 전송 중인 항목과 병목 현상을 완화하는 데 필요한 추가 용량을 확인해야 합니다.
네트워크가 올바르게 구축 및 관리되는 경우 서비스 및 가용성에 대한 인식은 케이블 업계의 주요 차별화 기회가 될 수 있습니다.케이블 회사가 여러 서비스로 전환함에 따라 서비스 무결성에 대한 가입자의 기대치는 레거시 음성 서비스에 의해 설정된 모델에 더 가까워집니다.이러한 변화에 따라 케이블 기업은 새로운 패러다임에 맞게 네트워크를 구축할 수 있는 새로운 접근 방식과 전략을 채택해야 합니다.이제 EMC는 단순한 엔터테인먼트 제공업체가 아니라 통신 업계라는 점에서 더 높은 기대와 요구 사항을 가지고 있습니다.
DOCSIS 1.1에는 VoIP와 같은 고급 서비스의 품질 수준을 보장하는 사양이 포함되어 있지만, 이 사양을 준수하는 서비스를 구축하는 것은 쉽지 않습니다.따라서 케이블 사업자들이 이러한 문제를 철저히 파악하는 것이 중요합니다.진정한 서비스 무결성을 성공적으로 구축하려면 시스템 구성 요소 및 네트워크 전략을 선택하는 포괄적인 접근 방식을 고안해야 합니다.
가입자를 늘리되 현재 가입자에 대한 서비스를 위태롭게 하지는 않는 것이 목표이다.가입자당 최소 처리량을 보장하기 위한 SLA(Service Level Agreements)가 제공되는 경우 이 보증을 지원하는 인프라가 갖춰져 있어야 합니다.업계에서는 또한 상용 고객을 지원하고 음성 서비스를 추가하는 방안을 모색하고 있습니다.이러한 새로운 시장이 다루어지고 네트워크가 구축됨에 따라 새로운 접근 방식이 필요합니다.더 많은 포트, 현장에서 더 멀리 떨어진 곳에 분산된 CMTS 또는 그 사이에 있는 CMTS를 집적시킵니다(예: 집에 10baseF 추가).
미래에 대한 전망이 무엇이든 네트워크는 더욱 복잡해지고 기술적 과제가 증가할 것입니다.케이블 업계는 최고 수준의 서비스 무결성을 적시에 제공할 수 있는 아키텍처 및 지원 프로그램을 채택해야 이러한 과제를 해결할 수 있습니다.
 피드백
피드백