소개
이 문서에서는 Cisco Hyperflex 클러스터에서 오프라인 노드를 재구축하는 프로세스에 대해 설명합니다.
사전 요구 사항
요구 사항
이는 Intersight에서 배포되고 버전 5.0(2b)부터 시작되는 Hyperflex 클러스터에서만 지원됩니다. Hyperflex 설치 프로그램을 통해 배포되고 Intersight로 가져온 클러스터는 아직 이 기능에 대해 지원되지 않습니다.
이 Intersight 기능에 대해 지원되는 시나리오 유형:
- FI/표준 클러스터, 클러스터, 에지 클러스터 및 DC-No-FI 클러스터
- SED(자체 암호화 드라이브)가 있는 클러스터
- Intersight에서만 배포된 클러스터
- ESXi 및 SCVM 재구축
- SCVM만 재구축
지원되지 않는 시나리오
- 1GbE HyperFlex 에지 및 스트레치 클러스터
- Intersight로 가져온 클러스터
라이센싱
HyperFlex 노드 재구축에는 Intersight Essentials 또는 고급 라이센스가 필요합니다. HyperFlex 클러스터의 모든 서버는 Intersight Essentials 또는 상위 라이센스로 클레임되고 구성되어야 합니다.
사용되는 구성 요소
- Cisco Intersight
- Cisco UCSM(선택 사항)
- Cisco UCS 서버
- Cisco Hyperflex Cluster 버전 5.0(2c)
- VMware ESXi
- VMware vCenter
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다. 이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다. 현재 네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 미리 숙지하시기 바랍니다.
배경 정보
여러 가지 이유로 클러스터를 올바르게 유지하는 것이 우선시되지만 가장 중요한 것은 Hypercoverge 스토리지 솔루션의 데이터 무결성을 위한 이중화입니다. 통합 노드에서 부팅 드라이브를 교체하는 것과 같이 ESXi 및 SCVM(Storage Controller Virtual Machine)을 동시에 재구축해야 하는 시나리오가 여러 개 있습니다.
Intersight에서 구축한 클러스터의 경우 SCVM을 재구축하여 Hyperflex 클러스터에 다시 추가할 수 있으며, 이제 Intersight를 통한 TAC 지원 없이 이 활동을 실행할 수 있습니다.
경고: 이 프로세스를 성공적으로 수행하지 않으면 향후 클러스터 업그레이드 실패 및 클러스터 확장 실패와 같은 여러 예기치 않은 문제가 발생할 수 있다는 점을 강조해야 합니다.
설정
이 예에서는 M.2 디스크 장애로 인해 노드 3이 손상된 Medellin이라는 3 노드 에지 클러스터를 사용합니다
Intersight에서 출발점은 몇 가지 측면에 대해 이미 다룬 것으로 가정합니다.
- M.2 스토리지가 이미 교체되었습니다.
- Hyperflex 클러스터는 해당 노드가 오프라인 상태이므로 여전히 비정상 상태입니다.
클러스터 노드 오프라인 검증
설명한 대로 클러스터가 비정상 상태이며 M.2 문제가 해결되었으므로 오프라인 상태인 노드를 복구해야 합니다
Intersight에서 Infrastructure Service(인프라 서비스) > Hyperflex Cluster(Hyperflex 클러스터) > Overview(개요) > Events(이벤트)로 이동합니다. 복원력 상태를 확인할 수 있습니다.
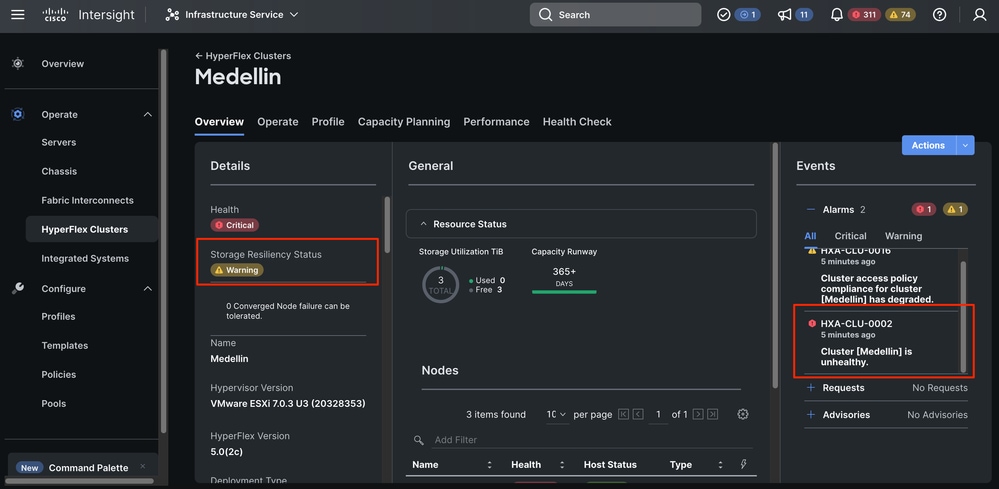
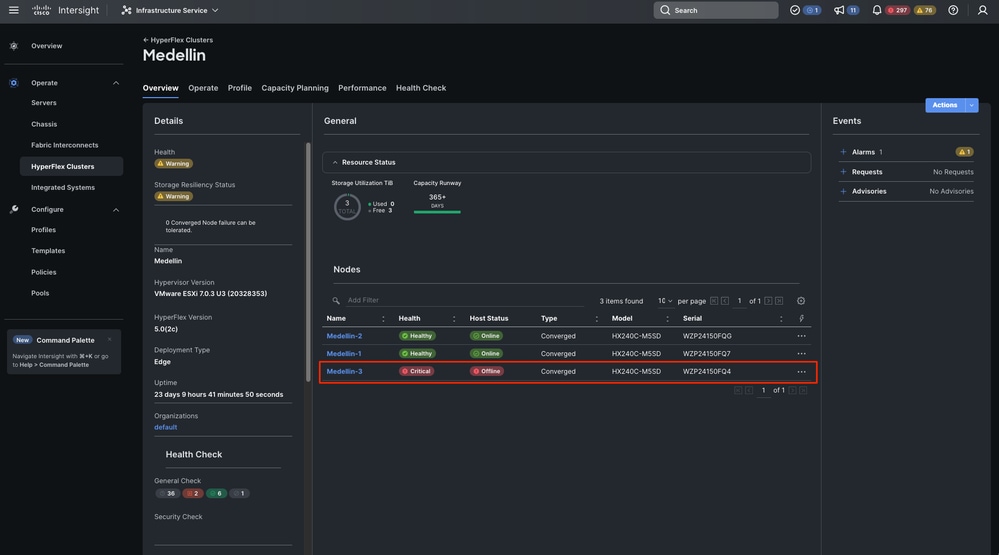
동일한 Overview(개요) 탭에서는 어떤 특정 노드가 오프라인 상태인지도 볼 수 있습니다
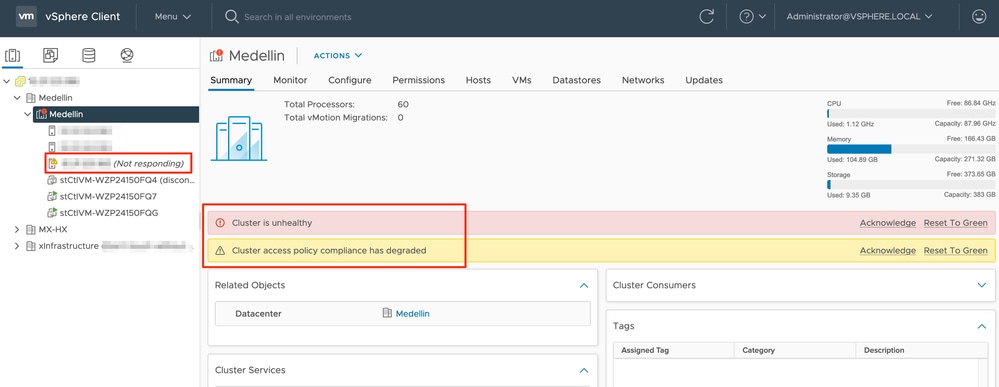
vCenter에서 클러스터의 비정상 상태에 대한 알림도 제공됩니다
마지막으로 CLI에서 클러스터 상태를 평가할 수도 있습니다.
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : WARNING
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 0
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 30.4 GiB
Free Capacity : 3.0 TiB
Compression Savings : 62.06%
Deduplication Savings : 0.00%
Total Savings : 62.06%
# of Nodes Configured : 3
# of Nodes Online : 2
Data IP Address : 169.254.218.1
Resiliency Health : WARNING
Policy Compliance : NON_COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 0
# of persistent device failures tolerable : 1
# of cache device failures tolerable : 1
Zone Type : Unknown
All Flash : No
재구축 단계
1단계. ESXi OS를 다시 설치합니다. 이를 위해 Servers(서버) > Select the Server(서버) > Options (three dots)(옵션(3개 점))> Select the KVM Launch(KVM 실행)로 이동할 수 있습니다.
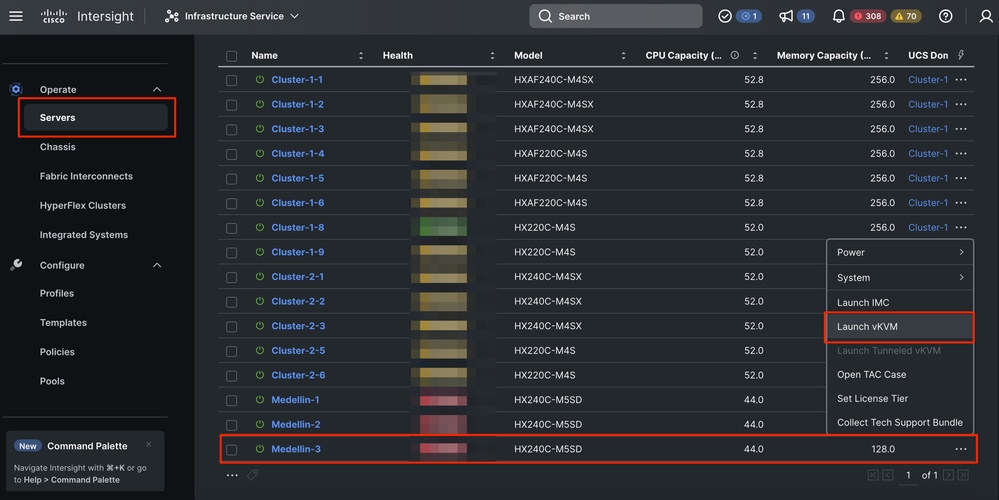
주의: 다른 노드가 클러스터에서 실행 중인 것과 동일한 ESXi 버전에 대해 Cisco Hyperflex 사용자 지정 이미지를 다운로드해야 합니다. 여기서 다운로드할 수 있습니다.
KVM이 시작되면 Virtual Media로 이동 >Activate Virtual Devices(가상 디바이스 활성화) 선택

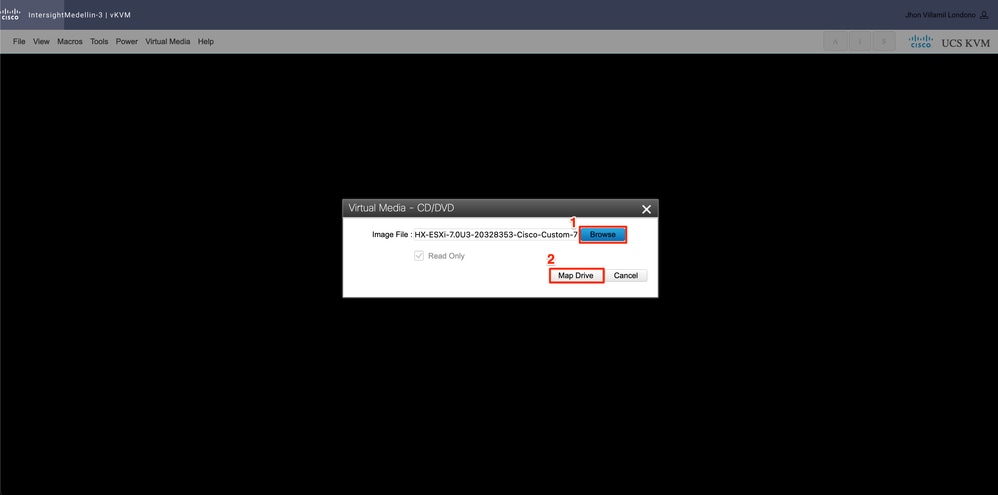
그런 다음 Browse(찾아보기)> 로컬 컴퓨터에서 Hyperflex ESXi iso 이미지를 선택하고 Map Drive(맵 드라이브)를 선택합니다
Power(전원) > 로 이동하여 서버의 상태에 따라 Power on System(시스템 전원 켜기) 또는 Reset System(시스템 재설정) 또는 Power Cycle System(전원 주기 시스템)을 선택합니다. 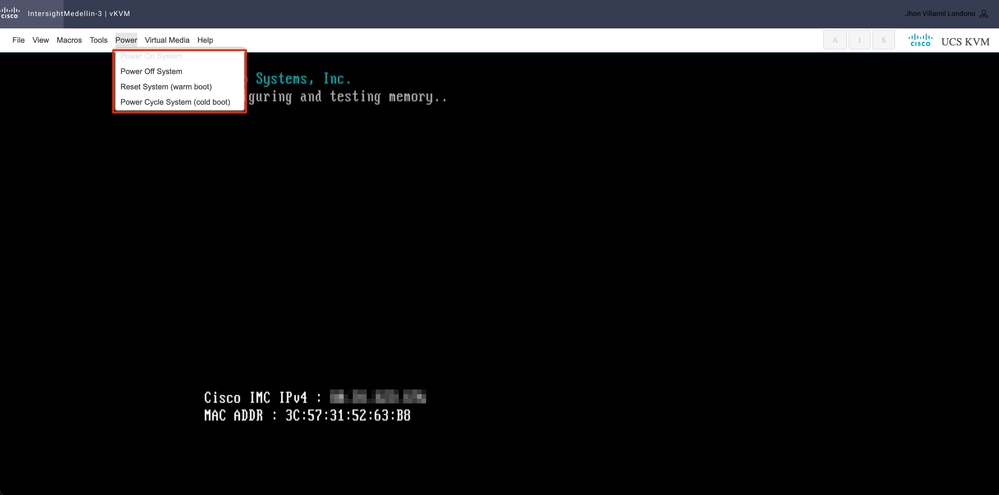
팁: Reset System(웜 부팅)은 전원을 끄지 않고 시스템을 재부팅하는 반면, Power Cycle System(콜드 부팅)은 시스템을 껐다가 다시 켭니다. 이 시나리오에서는 SCVM이 손상되고 ESXi가 재설치되는 경우 두 옵션 모두 동일한 목적을 충족합니다
CD/DVD 가상 디바이스 디바이스로 부팅해야 합니다. Tools(도구) > Select Keyboard(키보드 선택) > When you see Boot Menu prompt(부팅 메뉴 프롬프트가 표시되면 F6 키를 누릅니다.
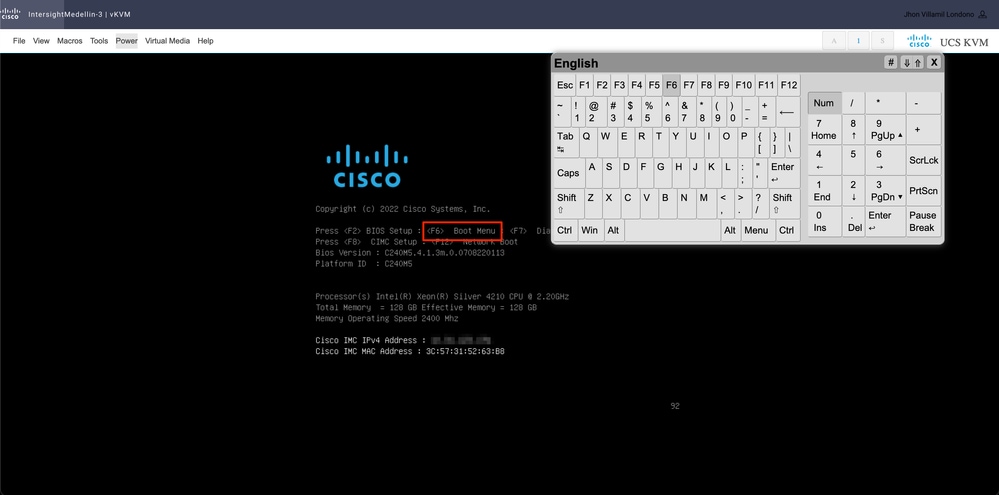
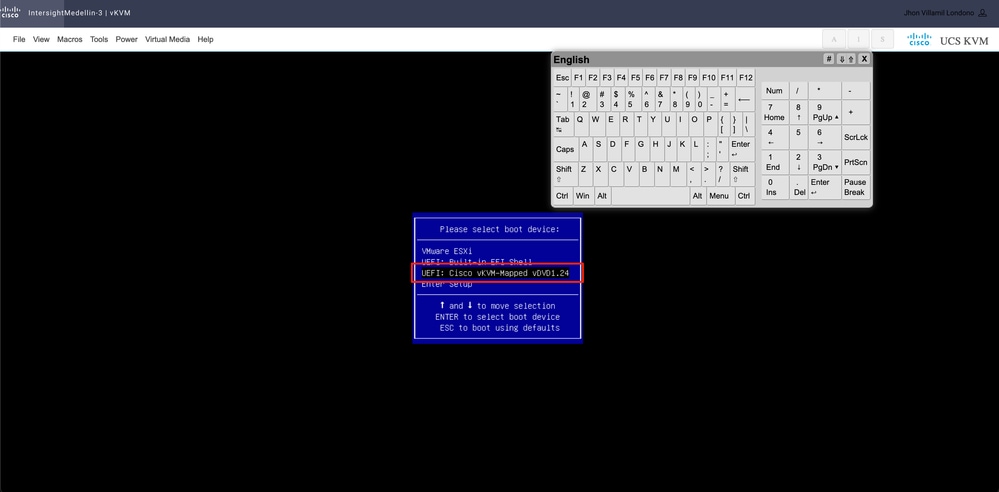
부팅 메뉴가 표시되면 Cisco vKVM-Mapped vDVD1.24를 선택하고 Enter를 누릅니다
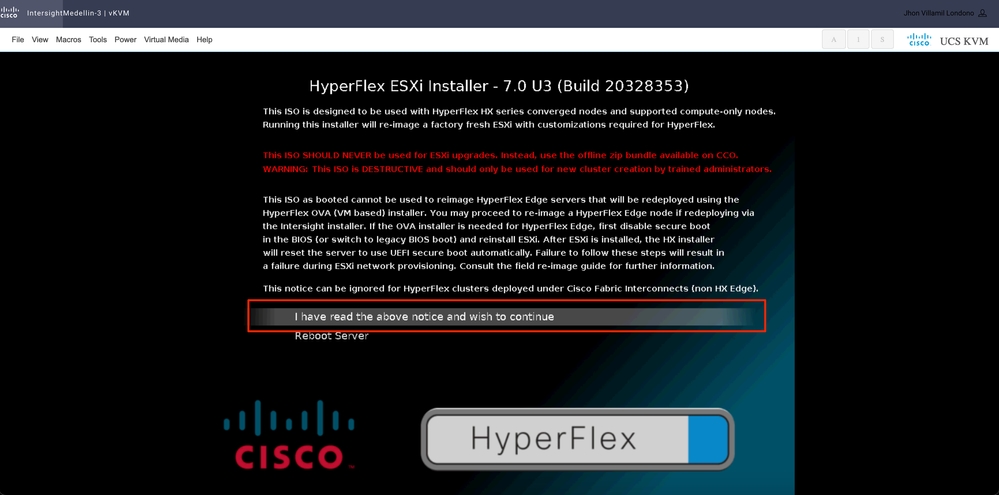
I have read the above notice and wish to continue(위 공지 사항을 읽었으며 계속하려면 선택)를 선택하고 Enter 키를 누릅니다
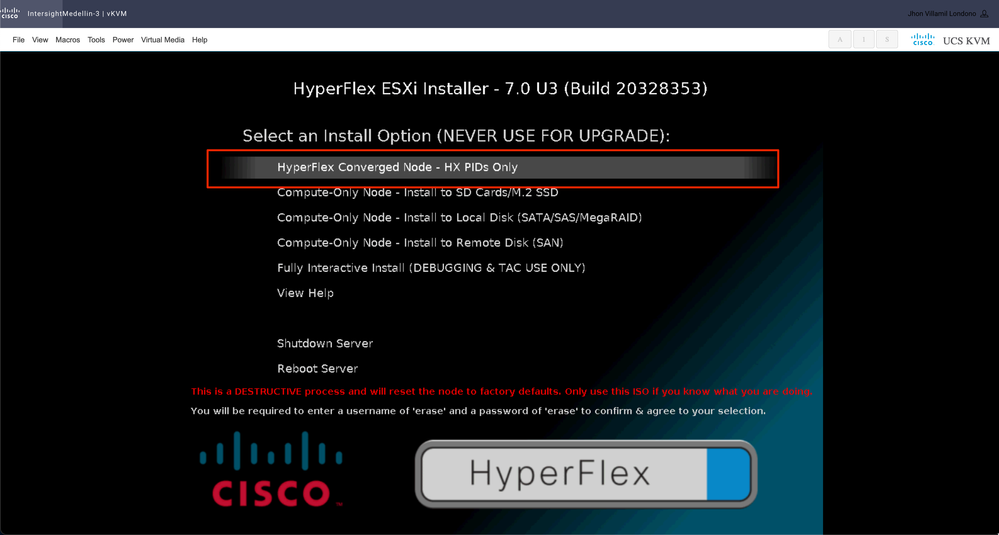
정기적으로 어떤 특정 부팅 디바이스가 사용되느냐에 따라 컴퓨팅 노드에 대해 다른 옵션이 표시되고, 여기에서 선택해야 하는 통합 노드에 대해 다른 옵션이 표시됩니다
그런 다음 사용자 이름과 비밀번호를 입력하라는 프롬프트가 표시됩니다. Type username erase(사용자 이름 지우기) > hit Enter(히트) > Type password erase(비밀번호 지우기) > hit 입력 사항
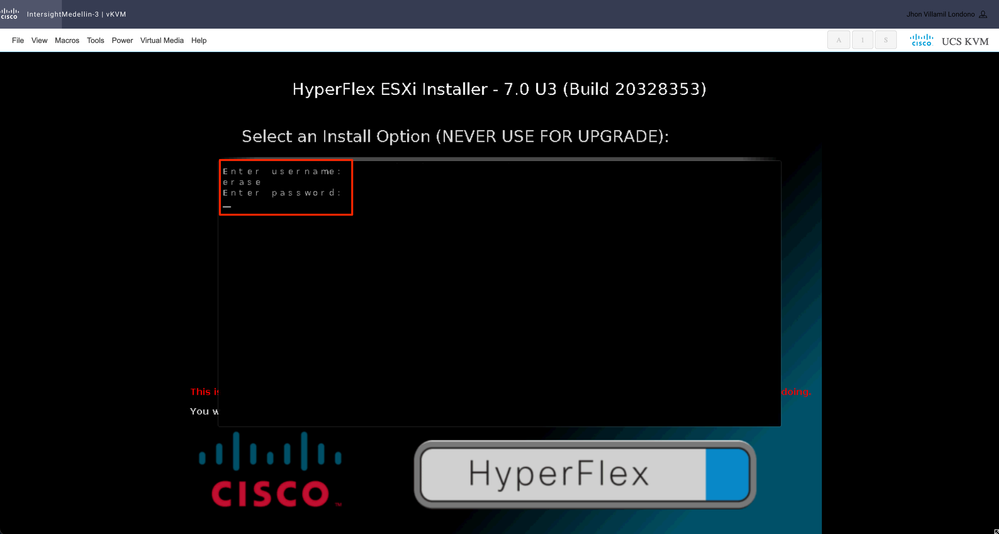
참고: 잘못된 비밀번호/사용자 이름을 입력하면 한 단계 뒤로 물러난 다음 다시 시도할 수 있습니다
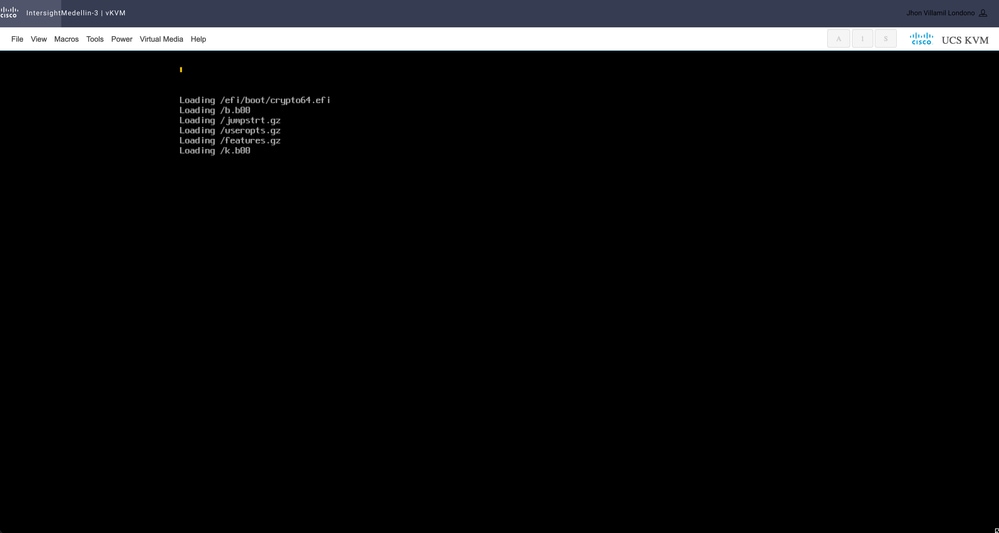
이 시점에서 설치가 시작되며 vKVM을 통해 모니터링할 수 있습니다.
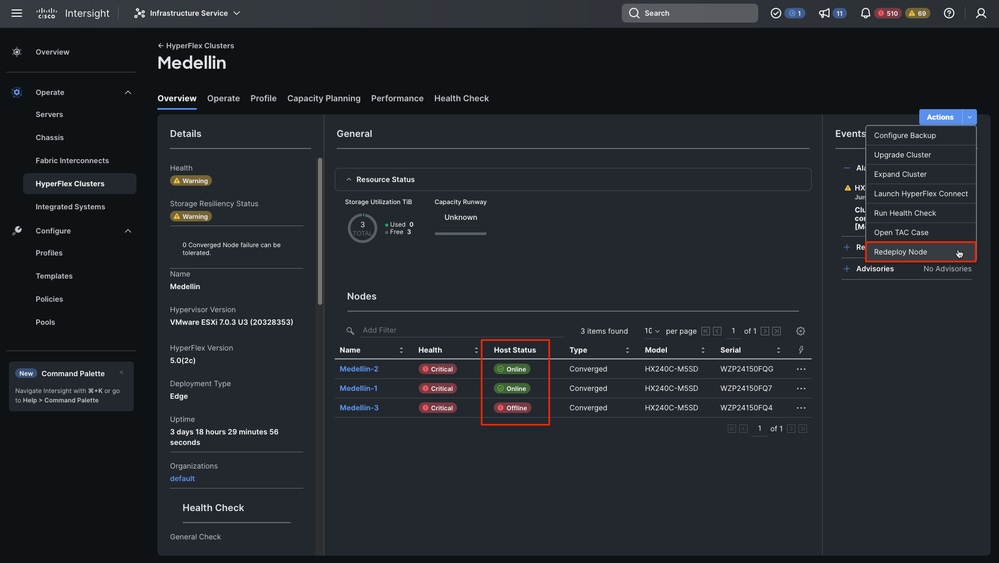
2단계. Infrastructure Service(인프라 서비스) > Hyperflex Clusters(Hyperflex 클러스터) > Select your Hyperflex cluster(Hyperflex 클러스터 선택) > Select Actions(작업 선택) > Select Redeploy Node(노드 재구축 선택)로 이동합니다.

팁: SCVM만 손상되어 다시 설치해야 하는 경우 Redeploy(재구축)를 선택하기 전에 서버의 전원을 끈 다음 "이 클러스터에 오프라인 호스트가 없기 때문에 Redeploy Node(노드 재구축)를 트리거할 수 없습니다."라는 오류가 발생합니다.
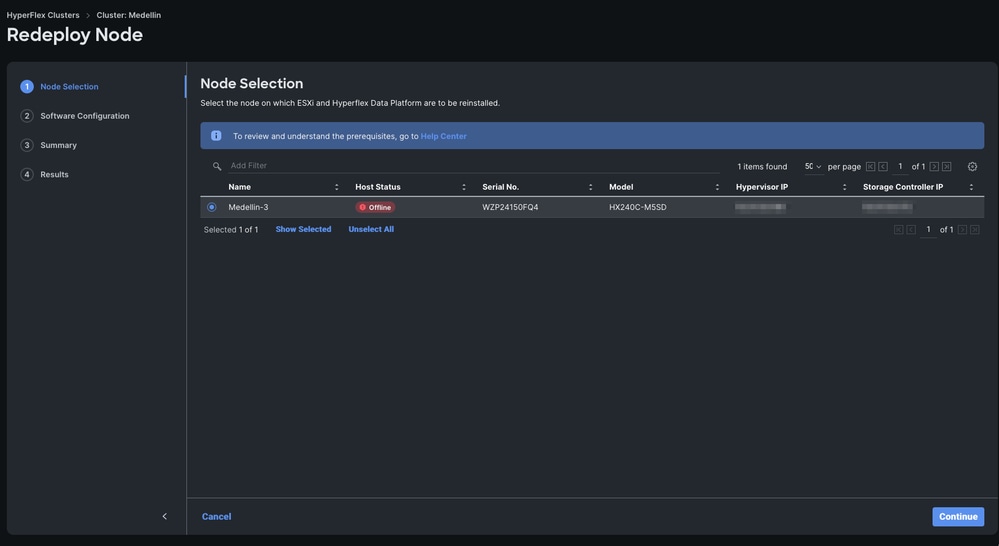
3단계. 노드를 오프라인으로 선택하고 Continue를 선택합니다
4단계. 보안, vCenter 및 프록시 설정 정책이 동일한 클러스터에 해당하는지 확인하고 다음을 선택합니다.
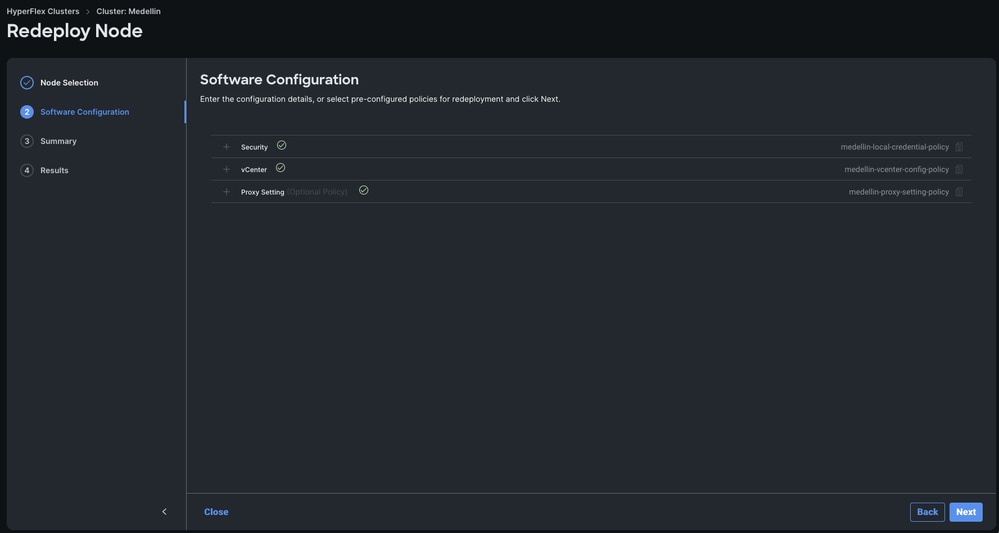
그러나 SCVM만 재배포되고 ESXi는 그대로 있는 경우 보안 정책에서 "이 노드의 하이퍼바이저가 공장 기본 비밀번호를 사용합니다." 옵션의 선택을 취소하고 현재 ESXi 비밀번호를 업데이트한 후 다음을 선택해야 합니다
5단계. Validate and Redeploy(검증 및 재구축)를 선택합니다.
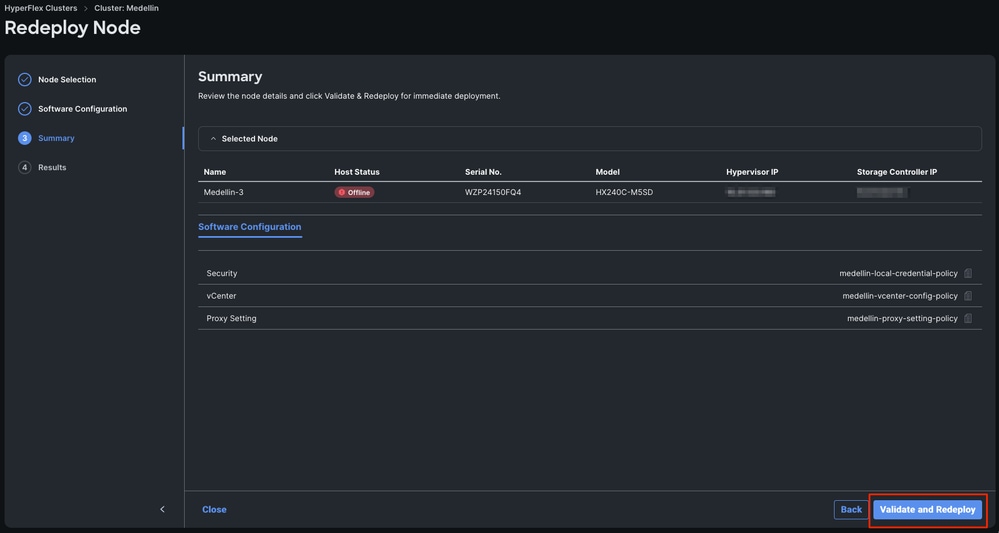
6단계. 워크플로가 완료될 때까지 대기
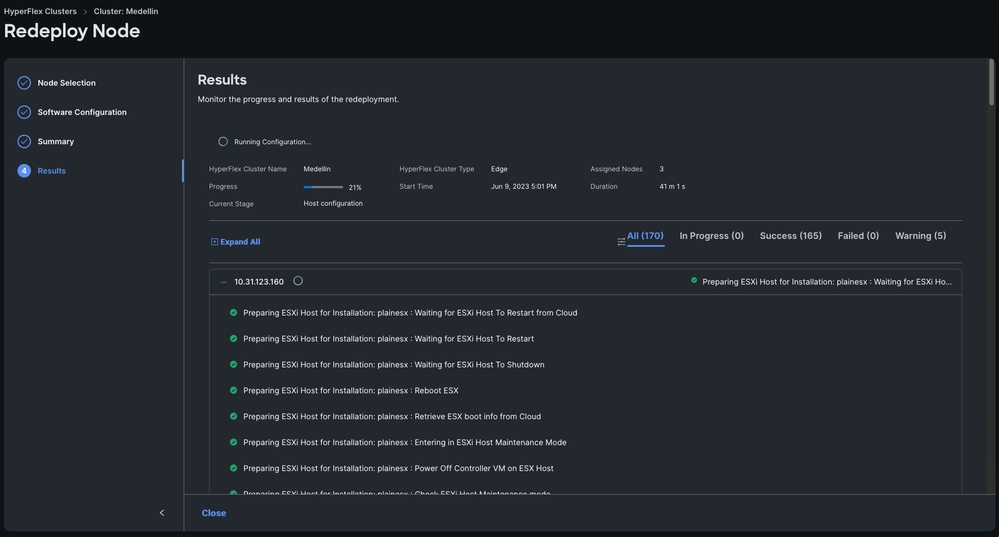
참고: 진행 상황을 모니터링할 수 있지만 보통 몇 시간이 걸립니다
마지막으로 재구축이 완료되었으며 Medellin 클러스터가 정상 상태로 돌아왔습니다.
클러스터 정상 상태 검증
Intersight에서 검증
Hyperflex Clusters(Hyperflex 클러스터) > Select the cluster(클러스터 선택) > Select Overview(개요) 탭으로 이동합니다
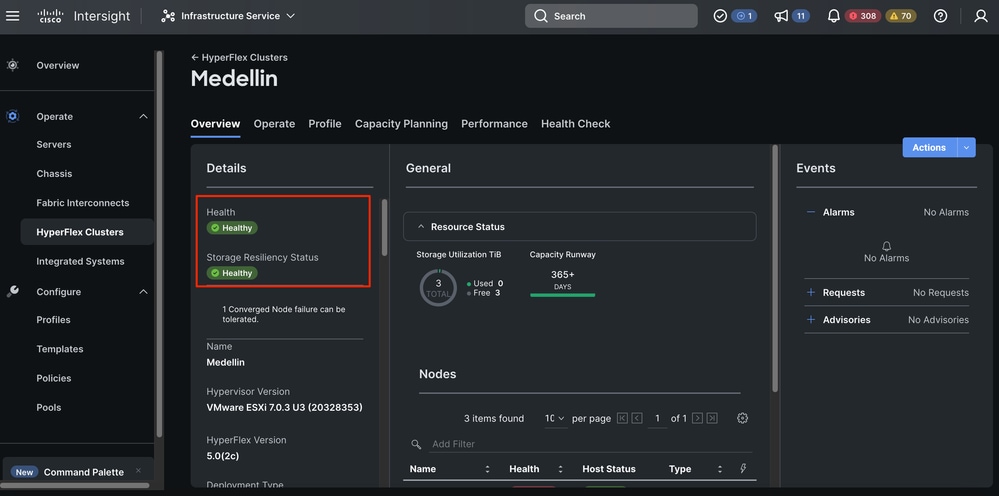
Hyperflex Connect에서 검증
Intersight에서 HXDP를 런치(Lunch)하여 상태를 확인합니다.
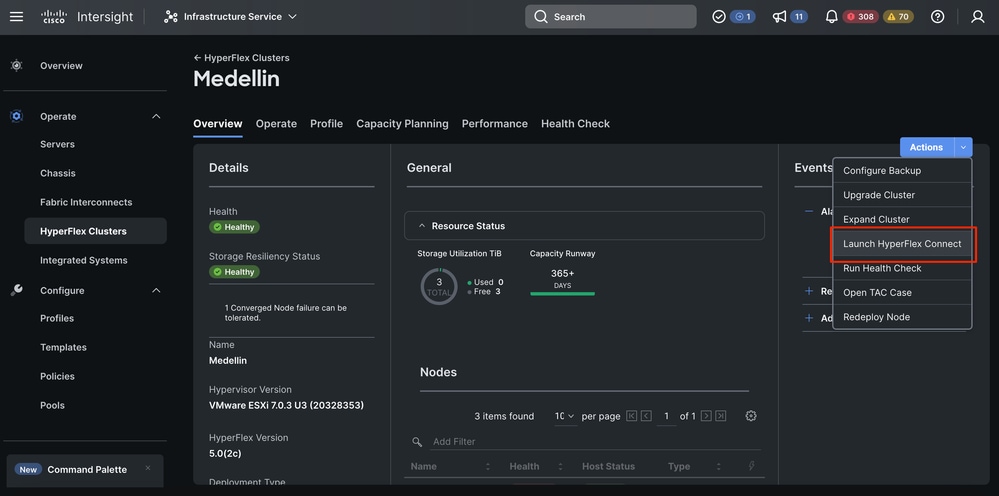
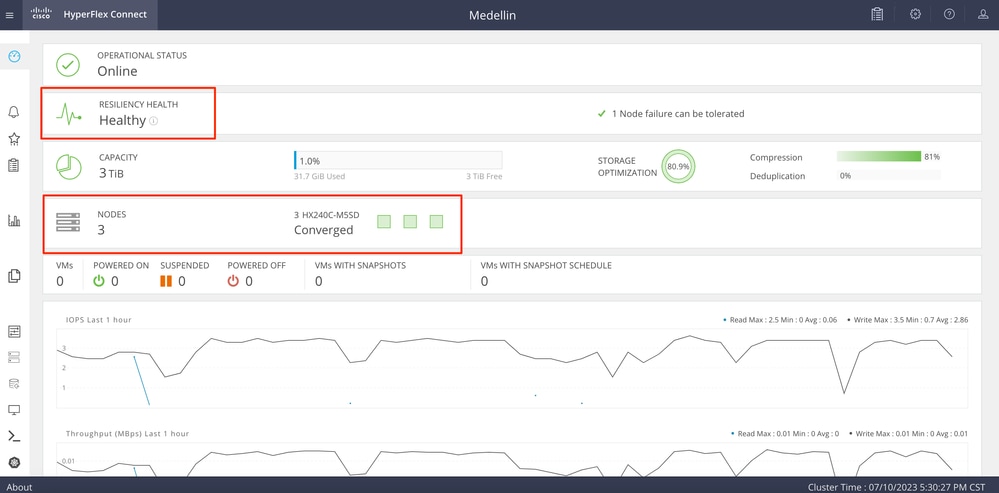
CLI에서 검증
CLI에서 hxcli cluster status, hxcli cluster info, hxcli cluster health, hxcli node list와 같은 명령을 사용할 수 있습니다.
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : HEALTHY
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 1
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 31.7 GiB
Free Capacity : 3.0 TiB
Compression Savings : 80.90%
Deduplication Savings : 0.00%
Total Savings : 80.90%
# of Nodes Configured : 3
# of Nodes Online : 3
Data IP Address : 169.254.218.1
Resiliency Health : HEALTHY
Policy Compliance : COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 1
# of persistent device failures tolerable : 2
# of cache device failures tolerable : 2
Zone Type : Unknown
All Flash : No
관련 정보
HyperFlex 노드 재배포 워크플로
 피드백
피드백