QoS에 관한 FAQ
목차
소개
이 문서에서는 QoS(Quality of Service)와 관련된 자주 묻는 질문(FAQ)에 대해 설명합니다.
일반
Q. QoS(Quality of Service)란 무엇입니까?
A. QoS는 프레임 릴레이, ATM(Asynchronous Transfer Mode), 이더넷 및 802.1 네트워크, SONET 및 IP 라우팅 네트워크를 비롯한 다양한 기본 기술을 통해 선택된 네트워크 트래픽에 더 나은 서비스를 제공하는 네트워크의 기능을 의미합니다.
QoS는 애플리케이션이 데이터 처리량 용량(대역폭), 레이턴시 변화(지터) 및 지연 측면에서 예측 가능한 서비스 레벨을 요청하고 수신할 수 있도록 하는 기술 모음입니다. 특히 QoS 기능은 다음과 같은 방법으로 더 나은 예측 가능한 네트워크 서비스를 제공합니다.
전용 대역폭 지원.
손실 특성 개선.
네트워크 혼잡 방지 및 관리.
네트워크 트래픽 형성.
네트워크 전체에서 트래픽 우선순위 설정.
IETF(Internet Engineering Task Force)는 QoS에 대해 다음 두 가지 아키텍처를 정의합니다.
통합 서비스(IntServ)
차등화 서비스(DiffServ)
IntServ는 RSVP(Resource Reservation Protocol)를 사용하여 네트워크를 통해 엔드 투 엔드 경로에 있는 디바이스를 따라 애플리케이션 트래픽의 QoS 요건을 명시적으로 시그널링합니다. 경로를 따라 모든 네트워크 디바이스가 필요한 대역폭을 예약할 수 있는 경우, 원래 애플리케이션이 전송을 시작할 수 있습니다. RFC(Request for Comment) 2205는 RSVP를 정의하고, RFC 1633은 IntServ를 정의합니다.
DiffServ는 집계 및 프로비저닝된 QoS에 중점을 둡니다. DiffServ는 애플리케이션의 QoS 요건을 시그널링하는 대신 IP 헤더의 DSCP(DiffServ Code Point)를 사용하여 필요한 QoS 레벨을 표시합니다. Cisco IOS® 소프트웨어 릴리스 12.1(5)T에서는 Cisco 라우터에 DiffServ 컴플라이언스를 도입했습니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. 혼잡, 지연 및 지터란 무엇입니까?
A. 인터페이스에서 처리할 수 있는 것보다 많은 트래픽이 제공되면 혼잡이 발생합니다. 네트워크 혼잡 지점은 QoS(Quality of Service) 메커니즘의 강력한 후보입니다. 다음은 일반적인 혼잡 지점의 예시입니다.

네트워크 혼잡으로 인해 지연이 발생합니다. 패킷 음성 네트워크의 지연 이해에서 설명하는 것과 같이 네트워크와 네트워크 디바이스는 여러 종류의 지연을 발생시킵니다. 패킷 음성 네트워크의 지연 이해(Cisco IOS 플랫폼)에서 설명하는 것과 같이 지연의 변동을 지터라고 합니다. 실시간 및 대화형 트래픽을 지원하려면 지연과 지터를 모두 제어하고 최소화해야 합니다.
Q. MQC란 무엇입니까?
A. MQC는 모듈형 QoS(Quality of Service) 명령줄 인터페이스(CLI)를 의미합니다. 플랫폼 전체에서 공통 명령 구문과 그에 따른 QoS 동작 세트를 정의하여 Cisco 라우터 및 스위치에서 QoS의 설정을 간소화하도록 설계되었습니다. 이 모델은 각 QoS 기능 및 플랫폼에 대한 고유 구문 정의의 이전 모델을 대체합니다.
MQC에는 다음 3단계가 포함됩니다.
class-map 명령을 실행하여 트래픽 클래스를 정의합니다.
policy-map 명령을 실행하여 트래픽 클래스를 하나 이상의 QoS 기능과 연결하여 트래픽 정책을 생성합니다.
service-policy 명령을 실행하여 트래픽 정책을 인터페이스, 하위 인터페이스 또는 가상 회선(VC)에 연결합니다.
참고: DiffServ의 트래픽 조절 기능(예: 마킹 및 형성)은 MQC 구문을 사용하여 구현합니다.
자세한 내용은 모듈형 QoS(Quality of Service) 명령줄 인터페이스를 참조하십시오.
Q. service-policy가 DCEF 활성화 메시지가 있는 VIP 인터페이스에서만 지원되는 것은 무엇을 의미합니까?
A. Cisco 7500 Series의 VIP(Versaile Interface Processor)인 경우, Cisco IOS 12.1(5)T, 12.1(5)E 및 12.0(14)S부터는 분산형 QoS(Quality of Service) 기능만 지원됩니다. 분산형 Cisco Express Forwarding(dCEF)을 활성화하면 분산형 QoS가 자동으로 활성화됩니다.
레거시 인터페이스 프로세서(IP)라고도 하는 비 VIP 인터페이스는 RSP(Route Switch Processor)에서 활성화된 중앙 QoS 기능을 지원합니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. QoS(Quality of Service) 정책은 몇 개의 클래스를 지원합니까?
A. 12.2 이전의 Cisco IOS 버전에서는 최대 256개의 클래스만 정의할 수 있으며, 각기 다른 정책에 동일한 클래스가 재사용되는 경우 최대 256개의 클래스를 정의할 수 있습니다. 두 개의 정책이 있는 경우 두 정책의 총 클래스 수가 256개를 초과해서는 안 됩니다. 정책에 CBWFQ(Class-Based Weighted Fair Queueing)가 포함된 경우(임의의 클래스 내에 bandwidth[또는 priority] 명령문이 포함된 것을 의미함), 지원되는 총 클래스 수는 64개입니다.
Cisco IOS 버전 12.2(12),12.2(12)T 및 12.2(12)S에서는 256개의 글로벌 class-map에 대한 제한이 변경되었으며, 이제 최대 1,024개의 글로벌 class-map을 설정하고 동일한 policy-map 내부에서 256개의 class-map을 사용할 수 있습니다.
Q. 서비스 정책이 적용될 때 라우팅 업데이트 및 PPP(Point-to-Point Protocol)/HDLC(High-Level Data Link Control) keepalive는 어떻게 처리됩니까?
A. Cisco IOS 라우터는 다음 두 가지 메커니즘을 사용하여 제어 패킷의 우선순위를 지정합니다.
IP 우선 순위
pak_priority
두 메커니즘은 모두 아웃바운드 인터페이스가 혼잡한 경우 라우터와 대기열 처리 시스템에서 중요 제어 패킷이 삭제되지 않거나 마지막에 삭제되도록 설계됩니다. 자세한 내용은 라우팅 업데이트 및 제어 패킷이 QoS 서비스 정책을 사용하는 인터페이스에 대기되는 방식 이해를 참조하십시오.
Q. 통합 라우팅 및 브리징(IRB)으로 설정된 인터페이스에서 QoS(Quality of Service)가 지원됩니까?
A. 아니요. IRB에 대해 인터페이스가 설정된 경우 QoS 기능을 설정할 수 없습니다.
분류 및 마킹
Q. QoS(Quality of Service) 사전 분류란 무엇입니까?
A. QoS 사전 분류를 사용하면 터널 캡슐화 및/또는 암호화를 수행하는 패킷의 원래 IP 헤더 내용을 일치시키고 분류할 수 있습니다. 이 기능은 원래 패킷 헤더에서 터널 헤더로 ToS(Type of Service) 바이트의 원래 값을 복사하는 프로세스를 설명하지 않습니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. 어떤 패킷 헤더 필드를 다시 마킹할 수 있습니까? 어떤 값을 사용할 수 있습니까?
A. 클래스 기반 마킹 기능을 사용하면 패킷의 레이어 2, 레이어 3 또는 MPLS(Multiprotocol Label Switching) 헤더를 설정하거나 마킹할 수 있습니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. URL을 기준으로 트래픽의 우선순위를 지정할 수 있습니까?
A. 예. NBAR(Network Based Application Recognition)을 사용하면 애플리케이션 레이어의 필드에서 일치를 통해 패킷을 분류할 수 있습니다. NBAR이 도입되기 전에 가장 세부적인 분류는 레이어 4 TCP(Transmission Control Protocol) 및 UDP(User Datagram Protocol) 포트 번호였습니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. NBAR(Network Based Application Recognition)을 지원하는 플랫폼 및 Cisco IOS 소프트웨어 버전은 무엇입니까?
A. NBAR 지원은 다음 Cisco IOS 소프트웨어 버전에서 도입되었습니다.
플랫폼 최소 Cisco IOS 소프트웨어 버전 7200 12.1(5)T 7100 12.1(5)T 3660 12.1(5)T 3640 12.1(5)T 3620 12.1(5)T 2600 12.1(5)T 1700 12.2(2)T 참고: NBAR을 사용하려면 CEF(Cisco Express Forwarding)를 활성화해야 합니다.
DNBAR(Distributed NBAR)은 다음 플랫폼에서 사용할 수 있습니다.
플랫폼 최소 Cisco IOS 소프트웨어 버전 7500 12.2(4)T, 12.1(6)E FlexWAN 12.1(6)E 참고: NBAR은 Catalyst 6000 MSFC(Multilayer Switch Feature Card) VLAN 인터페이스, Cisco 12000 Series 또는 Catalyst 5000 Series용 RSM(Route Switch Module)에서 지원되지 않습니다. 위에 나열된 특정 플랫폼이 보이지 않는 경우 Cisco 기술 담당자에게 문의하십시오.
대기열 배치 및 혼잡 관리
Q. 대기열 처리의 목적은 무엇입니까?
A. 대기열 처리는 대역폭이 사용 가능해질 때까지 초과 패킷을 버퍼에 저장하여 네트워크 디바이스의 인터페이스에서 일시적인 혼잡을 수용하도록 설계되었습니다. Cisco IOS 라우터는 다양한 애플리케이션의 다양한 대역폭, 지터 및 지연 요건을 충족하기 위한 여러 대기열 처리 방법을 지원합니다.
대부분의 인터페이스에서 기본 메커니즘은 FIFO(First In First Out)입니다. 일부 트래픽 유형의 경우 지연/지터 요건이 더 까다롭습니다. 따라서 다음 대체 대기열 처리 메커니즘 중 하나를 설정하거나 기본적으로 활성화해야 합니다.
WFQ(Weighted Fair Queueing)
CBWFQ(Class-Based Weighted Fair Queueing)
LLQ(Low Latency Queuing), 실제로 우선순위 대기열(PQ)을 사용하는 CBWFQ로, PQCBWFQ라고 함
PQ(Priority Queuing)
CQ(Custom Queueing)
대기열 처리는 일반적으로 아웃바운드 인터페이스에서만 발생합니다. 라우터는 인터페이스로 발신되는 패킷을 대기열에 추가합니다. 인바운드 트래픽을 폴리싱할 수 있지만, 일반적으로 인바운드 트래픽은 대기시킬 수 없습니다(단, 분산된 dCEF(Cisco Express Forwarding)를 사용하는 Cisco 7500 Series 라우터에서 수신 측 버퍼링을 사용하여 인그레스(ingress)에서 이그레스(egress) 인터페이스로 패킷을 전달하는 경우는 예외입니다. 자세한 내용은 VIP CPU Running at 99% and Rx-Side Buffering(VIP CPU 99%에서 실행 중인 VIP CPU 이해) 및 Rx 측 버퍼링을 참조하십시오. Cisco 7500 및 12000 Series와 같은 하이엔드 분산형 플랫폼에서는 인바운드 인터페이스가 자체 패킷 버퍼를 사용하여 인바운드 인터페이스의 스위칭 결정에 따라 혼잡한 아웃바운드 인터페이스로 전환된 초과 트래픽을 저장할 수 있습니다. 드문 경우이지만 일반적으로 인바운드 인터페이스가 더 느린 아웃바운드 인터페이스를 제공할 때 인바운드 인터페이스는 패킷 메모리가 부족하면 무시됨 오류가 증가할 수 있습니다. 과도한 혼잡은 출력 대기열 삭제로 이어질 수 있습니다. 입력 대기열 삭제의 근본 원인은 대부분 다릅니다. 삭제 문제 해결에 대한 자세한 내용은 다음 문서를 참조하십시오.
자세한 내용은 다음 문서를 참조하십시오.
Q. WFQ(Weighted Fair Queueing)와 CBWFQ(Class Based Weighted Fair Queueing)는 어떻게 작동합니까?
A. 공정한 대기열 처리는 활성화 상태 대화 또는 IP 플로우 간에 인터페이스 대역폭의 공정한 지분을 할당하려고 합니다. IP 헤더의 여러 필드와 패킷 길이를 기반으로 해싱 알고리즘을 사용하여 대화 식별 번호에 의해 식별되는 하위 대기열로 패킷을 분류합니다. 다음은 가중치를 계산하는 방법입니다.
W=K/(우선순위 +1)
K=4096(Cisco IOS 12.0(4)T 이전 릴리스), 32384(12.0(5)T 이후 릴리스).
가중치가 낮을수록 대역폭의 우선순위 및 지분이 높아집니다. 가중치 외에도 패킷의 길이도 고려됩니다.
CBWFQ를 사용하면 트래픽의 클래스를 정의하고 최소 대역폭 보장을 할당할 수 있습니다. 이 메커니즘의 기본 알고리즘은 이름을 설명하는 WFQ입니다. CBWFQ를 설정하려면 map-class 명령문에서 특정 클래스를 정의합니다. 그런 다음 policy-map의 각 클래스에 정책을 할당합니다. 그러면 이 policy-map이 아웃바운드 인터페이스에 연결됩니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. CBWFQ(Class Based Weighted Fair Queueing)의 클래스에서 대역폭을 사용하지 않는 경우 다른 클래스에서 대역폭을 사용할 수 있습니까?
A. 예. bandwidth 및 priority 명령을 실행하여 제공되는 대역폭 보장이 "예약됨" 및 "별도로 대역폭 설정"과 같은 단어로 설명되었지만 두 명령 모두 실제 예약을 구현하지 않습니다. 즉, 트래픽 클래스가 설정된 대역폭을 사용하지 않는 경우 사용되지 않은 대역폭은 다른 클래스 간에 공유됩니다.
대기열 처리 시스템은 우선순위 클래스가 있는 이 규칙에 중요한 예외를 적용합니다. 위에서 언급한 것처럼 우선순위 클래스의 제공된 로드는 트래픽 폴리서에 의해 측정됩니다. 혼잡 상태에서는 우선순위 클래스가 초과 대역폭을 사용할 수 없습니다. 자세한 내용은 QoS 서비스 정책의 bandwidth 및 priority 명령 비교를 참조하십시오.
Q. CBWFQ(Class Based Weighted Fair Queueing)가 하위 인터페이스에서 지원됩니까?
A. Cisco IOS 논리적 인터페이스는 기본적으로 혼잡 상태를 지원하지 않으며 대기열 처리 방법을 적용하는 서비스 정책의 직접 적용을 지원하지 않습니다. 대신 먼저 GTS(Generic Traffic Shaping) 또는 클래스 기반 쉐이핑을 사용하여 하위 인터페이스에 쉐이핑을 적용해야 합니다. 자세한 내용은 이더넷 하위 인터페이스에 QoS 기능 적용을 참조하십시오.
Q. policy-map에서 priority와 bandwidth 명령문의 차이점은 무엇입니까?
A. priority 및 bandwidth 명령은 기능과 일반적으로 지원하는 애플리케이션이 서로 다릅니다. 다음 표에는 이러한 차이점이 요약되어 있습니다.
기능 bandwidth 명령 priority 명령 최소 대역폭 보장 예 예 최대 대역폭 보장 아니요 예 내장 폴리서 아니요 예 낮은 레이턴시 제공 아니요 예 자세한 내용은 QoS 서비스 정책의 bandwidth 및 priority 명령 비교를 참조하십시오.
Q. FlexWAN 및 VIP(Versaile Interface Processor)에서 대기열 제한은 어떻게 계산됩니까?
A. VIP 또는 FlexWAN에서 충분한 SRAM을 가정할 때 대기열 제한은 평균 패킷 크기 250바이트에서 최대 지연 500밀리초를 기준으로 계산됩니다. 다음은 대역폭이 1Mbps인 클래스의 예시입니다.
대기열 제한 = 1000000 / (250 x 8 x 2) = 250
사용 가능한 패킷 메모리의 양이 감소하고 가상 회선(VCS)의 수가 더 많을수록 더 작은 대기열 제한이 할당됩니다.
다음 예시에서 PA-A3은 Cisco 7600 Series용 FlexWAN 카드에 설치되며 2MB의 영구 가상 회선(PVC)이 포함된 여러 하위 인터페이스를 지원합니다. 서비스 정책은 각 VC에 적용됩니다.
class-map match-any XETRA-CLASS match access-group 104 class-map match-any SNA-CLASS match access-group 101 match access-group 102 match access-group 103 policy-map POLICY-2048Kbps class XETRA-CLASS bandwidth 320 class SNA-CLASS bandwidth 512 interface ATM6/0/0 no ip address no atm sonet ilmi-keepalive no ATM ilmi-keepalive ! interface ATM6/0/0.11 point-to-point mtu 1578 bandwidth 2048 ip address 22.161.104.101 255.255.255.252 pvc ABCD class-vc 2048Kbps-PVC service-policy out POLICY-2048KbpsATM(Async Transfer Mode) 인터페이스는 전체 인터페이스에 대한 대기열 제한을 가져옵니다. 이 제한은 사용 가능한 총 버퍼, FlexWAN의 물리적 인터페이스 수, 인터페이스에서 허용되는 최대 대기열 처리 지연의 함수입니다. 각 PVC는 SCR(Sustained Cell Rate) 또는 MCR(Minimum Cell Rate)을 기반으로 인터페이스 제한의 일부분을 가져오고, 각 클래스는 대역폭 할당을 기반으로 한 PVC 제한의 일부분을 가져옵니다.
다음 show policy-map interface 명령 샘플 출력은 3,687개의 글로벌 버퍼가 있는 FlexWAN에서 파생됩니다. 이 값을 보려면 show buffer 명령을 실행합니다. 각 2Mbps PVC는 2Mbps의 PVC 대역폭(2047/149760 x 3687 = 50)을 기준으로 50개의 패킷이 할당됩니다. 다음 출력에 표시된 것과 같이 각 클래스에는 50의 일부가 할당됩니다.
service-policy output: POLICY-2048Kbps class-map: XETRA-CLASS (match-any) 687569 packets, 835743045 bytes 5 minute offered rate 48000 bps, drop rate 6000 BPS match: access-group 104 687569 packets, 835743045 bytes 5 minute rate 48000 BPS queue size 0, queue limit 7 packets output 687668, packet drops 22 tail/random drops 22, no buffer drops 0, other drops 0 bandwidth: kbps 320, weight 15 class-map: SNA-CLASS (match-any) 2719163 packets, 469699994 bytes 5 minute offered rate 14000 BPS, drop rate 0 BPS match: access-group 101 1572388 packets, 229528571 bytes 5 minute rate 14000 BPS match: access-group 102 1146056 packets, 239926212 bytes 5 minute rate 0 BPS match: access-group 103 718 packets, 245211 bytes 5 minute rate 0 BPS queue size 0, queue limit 12 packets output 2719227, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 bandwidth: kbps 512, weight 25 queue-limit 100 class-map: class-default (match-any) 6526152 packets, 1302263701 bytes 5 minute offered rate 44000 BPS, drop rate 0 BPS match: any 6526152 packets, 1302263701 bytes 5 minute rate 44000 BPS queue size 0, queue limit 29 packets output 6526840, packet drops 259 tail/random drops 259, no buffer drops 0, other drops 0트래픽 스트림이 큰 패킷 크기를 사용하는 경우, 대기열 제한에 도달하기 전에 버퍼가 부족할 수 있으므로 show policy-map 인터페이스 명령 출력에서 no buffer drops 필드의 값이 증가할 수 있습니다. 이 경우 우선순위가 아닌 클래스에서 queue-limit을 수동으로 조정해 보십시오. 자세한 내용은 IP-ATM CoS를 통한 전송 대기열 제한 이해를 참조하십시오.
Q. queue-limit 값을 어떻게 확인합니까?
A. 비분산형 플랫폼에서 대기열 제한은 기본적으로 64패킷입니다. 다음 출력 예시는 Cisco 3600 Series 라우터에서 캡처되었습니다.
november# show policy-map interface s0 Serial0 Service-policy output: policy1 Class-map: class1 (match-all) 0 packets, 0 bytes 5 minute offered rate 0 BPS, drop rate 0 BPS Match: ip precedence 5 Weighted Fair Queueing Output Queue: Conversation 265 Bandwidth 30 (kbps) Max Threshold 64 (packets) !--- Max Threshold is the queue-limit. (pkts matched/bytes matched) 0/0 (depth/total drops/no-buffer drops) 0/0/0 Class-map: class2 (match-all) 0 packets, 0 bytes 5 minute offered rate 0 BPS, drop rate 0 BPS Match: ip precedence 2 Match: ip precedence 3 Weighted Fair Queueing Output Queue: Conversation 266 Bandwidth 24 (kbps) Max Threshold 64 (packets) (pkts matched/bytes matched) 0/0 (depth/total drops/no-buffer drops) 0/0/0 Class-map: class-default (match-any) 0 packets, 0 bytes 5 minute offered rate 0 BPS, drop rate 0 BPS Match: any
Q. 클래스 내에서 페어 대기열 처리를 활성화할 수 있습니까?
A. 분산형 QoS(Quality of Service)를 사용하는 Cisco 7500 Series는 클래스별로 페어 대기열 처리를 지원합니다. Cisco 7200 Series 및 Cisco 2600/3600 Series를 비롯한 다른 플랫폼은 클래스 기본 클래스에서 WFQ(Weighted Fair Queueing)를 지원하며 모든 대역폭 클래스는 FIFO(First In First Out)를 사용합니다.
Q. 대기열 처리를 모니터링하는 데 어떤 명령을 사용할 수 있습니까?
A. 다음 명령을 사용하여 대기열 처리를 모니터링합니다.
show queue{interface}{interface number} - Cisco 7500 Series 이외의 Cisco IOS 플랫폼에서 이 명령은 활성 대기열 또는 대화를 표시합니다. 인터페이스 또는 가상 회선(VC)이 혼잡하지 않으면 대기열이 나열되지 않습니다. Cisco 7500 Series에서는 show queue 명령이 지원되지 않습니다.
show queueing interface interface-number [vc [[vpi/] vci] - 인터페이스 또는 VC의 대기열 처리 통계를 표시합니다. 혼잡이 없는 경우에도 여기에서 일부 히트를 확인할 수 있습니다. 프로세스 전환 패킷이 혼잡이 있는지와 무관하게 항상 계산되기 때문입니다. CEF(Cisco Express Forwarding) 및 빠른 전환 패킷은 혼잡이 없으면 계산되지 않습니다. PQ(Priority Queuing), CQ(Custom Queuing) 및 WFQ(Weighted Fair Queueing)와 같은 레거시 대기열 처리 메커니즘은 분류 통계를 제공하지 않습니다. 12.0(5)T 이상의 이미지에서는 모듈형 Quality of Service 명령줄 인터페이스(MQC) 기반 기능에서만 이러한 통계를 제공합니다.
show policy interface{interface}{interface number} - 패킷 카운터가 클래스 기준과 일치하는 패킷 수를 계산합니다. 이 카운터는 인터페이스의 혼잡 여부에 따라 증가합니다. 패킷 일치 카운터는 인터페이스가 혼잡했을 때 클래스의 기준과 일치하는 패킷 수를 나타냅니다. 패킷 카운터에 대한 자세한 내용은 다음 문서를 참조하십시오.
Cisco 클래스 기반 QoS 설정 및 통계 MIB - 간단한 SNMP(Simple Network Management Protocol) 모니터링 기능을 제공합니다.
Q. RSVP는 CBWFQ(Class Based Weighted Fair Queuing)와 함께 사용할 수 있습니다. RSVP(Resource Reservation Protocol) 및 CBWFQ가 모두 인터페이스에 대해 설정된 경우, RSVP와 CBWFQ는 독립적으로 작동하고 각각 독립적으로 실행되는 경우와 동일한 동작을 보입니까? RSVP는 대역폭 가용성, 평가 및 할당과 관련하여 CBWFQ가 설정되지 않은 것처럼 동작합니다.
A. Cisco IOS 소프트웨어 릴리스 12.1(5)T 이상에서 RSVP 및 CB-WFQ를 사용하는 경우, 라우터는 RSVP 플로우와 CBWFQ 클래스가 초과 서브스크립션 없이 인터페이스 또는 PVC에서 사용 가능한 대역폭을 공유하도록 작동할 수 있습니다.
IOS 소프트웨어 릴리스 12.2(1)T 이상에서는 RSVP가 자체 "ip rsvp 대역폭" 풀을 사용하여 접근 제어를 수행할 수 있는 반면, CBWFQ는 RSVP 패킷의 분류, 폴리싱 및 예약을 수행합니다. 여기서는 발신자가 사전에 마킹한 패킷을 가정하고, 비 RSVP 패킷은 다르게 마킹됩니다.
혼잡 방지 WRED(Weighted Random Early Detection)
Q. WRED(Weighted Random Early Detection) 및 LLQ(Low Latency Queuing), 또는 CBWFQ(Class Based Weighted Fair Queuing)를 동시에 활성화할 수 있습니까?
A. 예. 대기열 처리는 대기열에서 나가는 패킷의 순서를 정의합니다. 즉, 패킷 예약 메커니즘을 정의합니다. 또한 적절한 대역폭 할당 및 최소 대역폭 보장을 제공하는 데에도 사용할 수 있습니다. 반면 RFC(Request for Comment) 2475는 삭제를 "지정된 규칙에 따라 패킷을 폐기하는 프로세스"로 정의합니다. 기본 삭제 메커니즘은 종단 삭제로, 대기열이 가득 차면 인터페이스가 패킷을 삭제합니다. 다른 삭제 메커니즘은 RED(Random Early Detection) 및 Cisco의 WRED로, 대기열이 가득 차기 전에 무작위로 패킷 삭제를 시작하고 일관된 평균 대기열 깊이를 유지하려고 합니다. WRED는 패킷의 IP 우선순위 값을 사용하여 차별화된 삭제 결정을 내립니다. 자세한 내용은 WRED(Weighted Random Early Detection)를 참조하십시오.
Q. WRED(Weighted Random Early Detection)를 어떻게 모니터링하고 실제로 적용되는지 확인할 수 있습니까?
A. WRED는 평균 대기열 깊이를 모니터링하고 계산된 값이 최소 임계값을 초과할 때 패킷 삭제를 시작합니다. 다음 예시에서와 같이 show policy-map interface 명령을 실행하고 평균 대기열 깊이 값을 모니터링합니다.
Router# show policy interface s2/1 Serial2/1 output : p1 Class c1 Weighted Fair Queueing Output Queue: Conversation 265 Bandwidth 20 (%) (pkts matched/bytes matched) 168174/41370804 (pkts discards/bytes discards/tail drops) 20438/5027748/0 mean queue depth: 39 Dscp Random drop Tail drop Minimum Maximum Mark (Prec) pkts/bytes pkts/bytes threshold threshold probability 0(0) 2362/581052 1996/491016 20 40 1/10 1 0/0 0/0 22 40 1/10 2 0/0 0/0 24 40 1/10 [output omitted]
폴리싱 및 쉐이핑
Q. 폴리싱과 쉐이핑의 차이점은 무엇입니까?
A. 다음 다이어그램은 주요 차이점을 보여줍니다. 트래픽 쉐이핑은 대기열에서 초과 패킷을 유지한 다음 시간이 지남에 따라 나중에 전송하기 위해 초과 패킷을 예약합니다. 트래픽 쉐이핑의 결과는 평활화된 패킷 출력 속도입니다. 반면 트래픽 폴리싱은 버스트를 전파합니다. 트래픽 속도가 설정된 최대 속도에 도달하면 초과 트래픽은 삭제(또는 다시 마킹)됩니다. 그 결과, 출력 속도는 톱니 모양으로 표시됩니다.
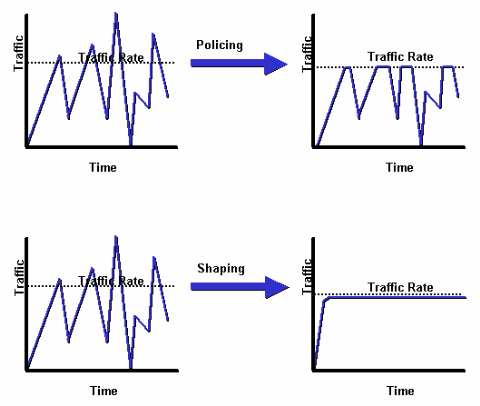
자세한 내용은 폴리싱 및 쉐이핑 개요를 참조하십시오.
Q. 토큰 버킷이란 무엇이며 알고리즘은 어떻게 작동합니까?
A. 토큰 버킷 자체에는 폐기 또는 우선순위 정책이 없습니다. 다음은 토큰 버킷 메타포가 작동하는 방식의 예시입니다.
토큰이 일정한 속도로 버킷에 담깁니다.
각 토큰은 소스에서 일정한 수의 비트를 전송하도록 허용하는 것입니다.
패킷 하나를 전송하려면 트래픽 조절기는 해당 패킷 크기에 대해 표시된 것과 동등한 수의 토큰을 버킷에서 제거할 수 있어야 합니다.
패킷을 전송하기에 충분한 토큰이 버킷에 없는 경우, 패킷은 버킷에 충분한 토큰이 있거나(쉐이퍼의 경우) 패킷이 폐기 또는 마크 다운(폴리서의 경우)될 때까지 기다립니다.
버킷 자체에는 지정된 용량이 있습니다. 버킷의 용량이 차면 새로 도착하는 토큰은 폐기되고 향후 패킷을 사용할 수 없게 됩니다. 따라서 언제든지 소스가 네트워크로 전송할 수 있는 최대 버스트는 버킷의 크기와 거의 비례합니다. 토큰 버킷은 버스트를 허용하지만 이를 제한합니다.
Q. 클래스 기반 폴리싱과 같은 트래픽 폴리서를 사용하는 경우 BC(Committed Burst) 및 Be(Excess Burst)는 무엇은 의미하며 이러한 값을 어떻게 선택해야 합니까?
A. 트래픽 폴리서는 쉐이퍼와 마찬가지로 초과 패킷을 버퍼링하지 않고 나중에 전송하지 않습니다. 대신 폴리서는 간단한 전송을 실행하거나 버퍼링 없이 정책을 전송하지 않습니다. 혼잡 기간에는 버퍼링할 수 없으므로 확장된 버스트를 올바르게 설정하여 적극적으로 패킷을 삭제하는 것이 최선의 방법입니다. 따라서 설정된 CIR(Committed Information Rate)에 도달하도록 폴리서에서 일반 버스트 및 확장 버스트 값을 사용하는 것을 이해하는 것이 중요합니다.
버스트 매개변수는 라우터의 일반 버퍼링 규칙에서 느슨하게 모델링됩니다. 이 규칙에서는 혼잡 시간에 모든 연결의 미해결 TCP(Transmission Control Protocol) 기간을 수용하도록 왕복 시간 비트 전송률과 같은 버퍼링을 설정할 것을 권장합니다.
다음 표에서는 normal burst 및 extended burst 값의 용도 및 권장 공식에 대해 설명합니다.
버스트 매개변수 목적 권장 공식 normal burst
표준 토큰 버킷을 구현합니다.
토큰 버킷의 최대 크기를 설정합니다(Be가 BC보다 큰 경우 토큰을 대여할 수 있음).
새로 도착하는 토큰이 폐기되고 버킷 용량이 가득 차면 향후 패킷을 사용할 수 없으므로 토큰 버킷의 크기를 결정할 수 있습니다.
참고: 일반적인 왕복 시간은 1.5초입니다.
extended burst
확장 버스트 기능을 사용하여 토큰 버킷을 구현합니다.
BC = Be를 설정하여 비활성화됩니다.
BC가 Be와 같은 경우 트래픽 조절기는 토큰을 대여할 수 없으며 사용 가능한 토큰이 충분하지 않으면 패킷을 삭제합니다.
모든 플랫폼이 폴리서에 대해 동일한 값 범위를 사용하거나 지원하지는 않습니다. 특정 플랫폼에서 지원되는 값을 확인하려면 다음 문서를 참조하십시오.
Q. CAR(Committed Access Rate) 또는 클래스 기반 폴리싱은 패킷이 CIR(Committed Information Rate)을 준수 또는 초과하는지 여부를 어떻게 결정합니까? 준수 속도가 설정된 CIR보다 낮더라도 라우터가 패킷을 삭제하고 초과 속도를 보고합니다.
A. 트래픽 폴리서가 normal burst 및 extended burst 값을 사용하여 설정된 CIR에 도달하는지 확인합니다. 양호한 처리량을 보장하려면 버스트 값을 충분히 높게 설정하는 것이 중요합니다. 버스트 값을 너무 낮게 설정하면 달성 속도가 설정 속도보다 훨씬 낮을 수 있습니다. 임시 버스트를 처리하면 TCP(Transmission Control Protocol) 트래픽의 처리량에 부정적인 영향을 미칠 수 있습니다. CAR을 사용하는 경우 show interface rate-limit 명령을 실행하여 현재 버스트를 모니터링하고 표시된 값이 제한(BC) 및 확장 제한(Be) 값과 일관적으로 가까운지 확인합니다.
rate-limit 256000 7500 7500 conform-action continue exceed-action drop rate-limit 512000 7500 7500 conform-action continue exceed-action drop router# show interfaces virtual-access 26 rate-limit Virtual-Access26 Cable Customers Input matches: all traffic params: 256000 BPS, 7500 limit, 7500 extended limit conformed 2248 packets, 257557 bytes; action: continue exceeded 35 packets, 22392 bytes; action: drop last packet: 156ms ago, current burst: 0 bytes last cleared 00:02:49 ago, conformed 12000 BPS, exceeded 1000 BPS Output matches: all traffic params: 512000 BPS, 7500 limit, 7500 extended limit conformed 3338 packets, 4115194 bytes; action: continue exceeded 565 packets, 797648 bytes; action: drop last packet: 188ms ago, current burst: 7392 bytes last cleared 00:02:49 ago, conformed 194000 BPS, exceeded 37000 BPS자세한 내용은 다음 문서를 참조하십시오.
Q. 버스트 및 대기열 제한이 서로 독립적입니까?
A. 예. 폴리서 버스트와 대기열 제한은 서로 다르며 독립적입니다. 폴리서는 특정 수의 패킷(또는 바이트)을 허용하는 게이트로 볼 수 있고 대기열은 네트워크에서 전송하기 전에 허용된 패킷을 보유하는 크기 대기열 제한의 버킷으로 볼 수 있습니다. 게이트(폴리서)에서 허용하는 바이트/패킷 버스트를 저장할 수 있는 충분한 크기의 버킷을 사용하는 것이 가장 좋습니다.
QoS(Quality of Service) 프레임 릴레이
Q. CIR(Committed Information Rate), BC(Committed Burst), Be(Excess Burst) 및 MinCIR(Minimum CIR)에 대해 어떤 값을 선택해야 합니까?
A. frame-relay traffic-shaping 명령을 실행하여 활성화하는 FRTS(Frame Relay Traffic Shaping)는 설정 가능한 몇 가지 매개변수를 지원합니다. 이러한 매개변수로는 frame-relay cir, frame-relay mincir, frame-relay BC가 있습니다. 이러한 값을 선택하고 관련 show 명령을 이해하는 방법에 대한 자세한 내용은 다음 문서를 참조하십시오.
Q. Frame Relay 기본 인터페이스의 Priority Queueing이 Cisco IOS 12.1에서 작동합니까?
A. Frame Relay 인터페이스는 인터페이스 대기열 처리 메커니즘과 가상 회선(VC)당 대기열 처리 메커니즘을 모두 지원합니다. Cisco IOS 12.0(4)T부터 인터페이스 대기열은 FRTS(Frame Relay Traffic Shaping)를 설정하는 경우에만 FIFO(First In First Out) 또는 PIPQ(Per Interface Priority Queueing)를 지원합니다. 따라서 Cisco IOS 12.1로 업그레이드하는 경우 다음 설정이 더 이상 작동하지 않습니다.
interface Serial0/0 frame-relay traffic-shaping bandwidth 256 no ip address encapsulation frame-relay IETF priority-group 1 ! interface Serial0/0.1 point-to-point bandwidth 128 ip address 136.238.91.214 255.255.255.252 no ip mroute-cache traffic-shape rate 128000 7936 7936 1000 traffic-shape adaptive 32000 frame-relay interface-dlci 200 IETFFRTS가 활성화되지 않은 경우 CBWFQ(Class Based Weighted Fair Queuing)와 같은 대체 대기열 처리 방법을 단일 대역폭 파이프처럼 작동하는 기본 인터페이스에 적용할 수 있습니다. 또한 Cisco IOS 12.1.1(T)부터는 Frame Relay 기본 인터페이스에서 Frame Relay 영구 가상 회선(PVC) PIPQ(Priority Interface Queueing)를 활성화할 수 있습니다. 다음 예시에서와 같이 높음, 중간, 보통 또는 낮은 우선순위를 정의하고 기본 인터페이스에서 frame-relay interface-queue priority 명령을 실행할 수 있습니다.
interface Serial3/0 description framerelay main interface no ip address encapsulation frame-relay no ip mroute-cache frame-relay traffic-shaping frame-relay interface-queue priority interface Serial3/0.103 point-to-point description frame-relay subinterface ip address 1.1.1.1 255.255.255.252 frame-relay interface-dlci 103 class frameclass map-class frame-relay frameclass frame-relay adaptive-shaping becn frame-relay cir 60800 frame-relay BC 7600 frame-relay be 22800 frame-relay mincir 8000 service-policy output queueingpolicy frame-relay interface-queue priority low
Q. FRTS(Frame Relay Traffic Shaping)는 dCEF(Distributed Cisco Express Forwarding) 및 dCBWFQ(Distributed Class Based Weighted Fair Queuing)에서 작동합니까?
A. Cisco IOS 12.1(5)T부터는 QoS 기능의 분산형 버전만 Cisco 7500 Series의 VIP에서 지원됩니다. Frame Realy 인터페이스에서 트래픽 쉐이핑을 활성화하려면 DTS(Distributed Traffic Shaping)를 사용합니다. 자세한 내용은 다음 문서를 참조하십시오.
ATM(Asynchronous Transfer Mode)을 통한 QoS(Quality of Service)
Q. ATM(Asynchronous Transfer Mode) 인터페이스에서 CBWFQ(Class Based Weighted Fair Queueing) 및 LLQ(Low Latency Queuing)를 사용하여 서비스 정책을 어디에 적용합니까?
A. Cisco IOS 12.2부터 ATM 인터페이스는 기본 인터페이스, 하위 인터페이스, PVC(Permanent Virtual Circuit)의 세 가지 레벨 또는 논리적 인터페이스에서 서비스 정책을 지원합니다. 활성화하는 QoS(Quality of Service) 기능에 정책을 적용합니다. ATM 인터페이스는 VC당 혼잡 레벨을 모니터링하고 VC당 초과 패킷에 대한 대기열을 유지하므로 가상 회선(VC)별로 대기열 처리 정책을 적용해야 합니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. IP에서 ATM(Asynchronous Transfer Mode) CoS(Class of Service) 대기열 처리에 포함되는 바이트 수는 어떻게 됩니까?
A. CBWFQ(Class Based Weighted Fair Queueing) 및 LLQ(Low Latency Queueing)를 각각 활성화하기 위해 서비스 정책에서 설정된 bandwidth 및 priority 명령은 show interface 명령 출력에서 계산하는 것과 동일한 오버헤드 바이트를 세는 Kbps 값을 사용합니다. 특히 레이어 3 대기열 처리 시스템은 LLC/SNAP(Logical Link Control/Subnetwork Access Protocol)를 계산합니다. 다음 사항은 고려하지 않습니다.
AAL5(ATM Adaptation Layer 5) 트레일러
마지막 셀을 48바이트의 짝수 배수로 만들기 위한 패딩
5바이트 셀 헤더
Q. 서비스 정책을 동시에 지원할 수 있는 가상 회선(VCS)은 몇 개입니까?
A. 다음 문서는 지원할 수 있는 ATM(Asynchronous Transfer Mode) VCS의 수에 대한 유용한 지침을 제공합니다. 약 200~300개의 VBR-nrt 영구 가상 회선(PVC)이 안전하게 구축되었습니다.
또한 다음도 고려하십시오.
강력한 프로세서를 사용하십시오. 예를 들어 VIP4-80은 VIP2-50보다 성능이 훨씬 뛰어납니다.
사용 가능한 패킷 메모리의 양. NPE-400에서는 최대 32MB(256MB 시스템)가 패킷 버퍼용으로 별도 설정됩니다. NPE-200의 경우 128MB 시스템에서 최대 16MB의 패킷 버퍼가 별도 설정됩니다.
최대 200개의 ATM PVC에서 동시에 작동하는 VC당 WRED(Weighted Random Early Detection)가 있는 설정이 광범위하게 테스트되었습니다. VC당 대기열에 사용할 수 있는 VIP2-50의 패킷 메모리 양은 한정되어 있습니다. 예를 들어, 8MB SRAM이 포함된 VIP2-50은 WRED가 작동하는 VC당 IP to ATM CO에 사용 가능한 1,085 개의 패킷 버퍼를 제공합니다. 100개의 ATM PVC가 설정되어 있고 모든 VCS가 동시에 과도한 혼잡을 경험한 경우(비 TCP 플로우 제어 소스를 사용하는 테스트 환경에서 시뮬레이션할 수 있음), 평균적으로 각 PVC는 약 10패킷의 버퍼링을 가지며, 이는 WRED가 작동하기에 너무 짧을 수 있습니다. 따라서 대형 SRAM을 사용하는 VIP2-50 디바이스는 VC당 WRED가 실행되는 ATM PVC 수가 많고 동시에 혼잡을 경험할 수 있는 설계에 적극 권장됩니다.
설정된 활성 PVC의 수가 많을수록 SCR(Sustain Cell Rate)은 더 낮아야 하며, 따라서 WRED가 PVC에서 작동하는 데 필요한 대기열이 짧아집니다. 따라서 IP-ATM CoS(Class of Service) Phase 1 기능의 기본 WRED 프로파일을 사용할 때와 마찬가지로, 수많은 저속 혼잡 ATM에서 PVC에서 VC당 WRED가 활성화될 때 낮은 WRED 삭제 임계값을 설정하면 VIP의 버퍼 부족 위험이 최소화됩니다. VIP의 버퍼 부족으로 인해 오작동이 발생하지 않습니다. VIP에서 버퍼가 부족한 경우 IP-ATM CoS Phase 1 기능이 버퍼 부족 기간 도중 FIFO(First In First Out) 종단 삭제로 저하됩니다(즉, IP-ATM CoS 기능이 이 PVC에서 활성화되지 않은 경우 동일한 정책 삭제가 발생).
합리적으로 지원될 수 있는 최대 동시 VCS 수.
Q. 어떤 ATM(Asynchronous Transfer Mode) 하드웨어가 CBWFQ(Class Based Weighted Fair Queuing) 및 LLQ(Low Latency Queuing)를 포함하여 IP-ATM CoS(Class of Service) 기능을 지원합니까?
A. IP-ATM CoS는 가상 회선(VC) 단위로 활성화되는 기능 세트를 의미합니다. 이 정의에 따르면 AIP(ATM Interface Processor), PA-A1 또는 4500 ATM 네트워크 프로세서에서는 IP-ATM CoS가 지원되지 않습니다. 이 ATM 하드웨어는 PA-A3 및 대부분의 네트워크 모듈(ATM-25 제외)에서 정의하므로 VC당 대기열 처리를 지원하지 않습니다. 자세한 내용은 다음 문서를 참조하십시오.
음성 및 QoS(Quality of Service)
Q. LFI(Link Fragmentation and Interleaving)는 어떻게 작동합니까?
A. Telnet 및 Voice over IP와 같은 인터랙티브 트래픽은 네트워크에서 WAN을 통한 FTP(File Transfer Protocol) 전송과 같은 대용량 패킷을 처리할 때 레이턴시가 증가하기 쉽습니다. 느린 WAN 링크에서 FTP 패킷이 대기열에 있을 때 인터랙티브 트래픽에 대한 패킷 지연이 큽니다. 더 큰 패킷을 프래그먼트화하고 더 큰 패킷의 프래그먼트(FTP) 패킷 간에 더 작은 패킷(음성)을 대기열에 넣기 위한 방법이 고안되었습니다. Cisco IOS 라우터는 여러 레이어 2 프래그먼트화 메커니즘을 지원합니다. 자세한 내용은 다음 문서를 참조하십시오.
Q. Voice over IP 성능을 모니터링하는 데 어떤 툴을 사용할 수 있습니까?
A. Cisco는 현재 Cisco의 Voice over IP 솔루션을 사용하여 네트워크에서 QoS(Quality of Service)를 모니터링하기 위한 여러 옵션을 제공합니다. 이러한 솔루션은 PSQM(Perceptual Speech Quality Measurement) 또는 음성 품질 측정을 위해 새로 제안된 일부 알고리즘을 사용하여 음성 품질을 측정하지 않습니다. Agilent(HP)와 NetIQ의 툴은 이 목적으로 제공됩니다. 하지만 Cisco에서는 지연, 지터 및 패킷 손실을 측정하여 경험하는 음성 품질을 파악할 수 있는 툴을 제공합니다. 자세한 내용은 Cisco Service Assurance Agent 및 Internetwork Performance Monitor를 사용하여 Voice over IP 네트워크에서 Quality of Service 관리를 참조하십시오.
Q. %SW_MGR-3-CM_ERROR_FEATURE_CLASS: 연결 관리자 기능 오류: 클래스 SSS: (QoS) - 설치 오류, 무시
A. 템플릿에 유효하지 않은 설정이 적용된 경우 관찰된 기능 설치 오류는 정상적인 동작입니다. 충돌로 인해 서비스 정책이 적용되지 않았음을 나타냅니다. 일반적으로 계층적 정책 맵에서 하위 정책의 class-default에 쉐이핑을 설정하지 말고 인터페이스의 상위 정책에서 설정해야 합니다. 이 메시지는 역추적(traceback)과 함께 결과로 인쇄됩니다.
세션 기반 정책을 사용하는 경우 class-default에 대한 쉐이핑은 하위 인터페이스 또는 PVC 레벨에서만 수행해야 합니다. 물리적 인터페이스에서의 쉐이핑은 지원되지 않습니다. 설정이 물리적 인터페이스에서 이루어지는 경우 이 오류 메시지의 발생은 정상적인 동작입니다.
LNS의 경우 세션이 시작되었을 때 RADIUS 서버를 통해 서비스 정책을 프로비저닝할 수 있는 또 다른 이유가 있을 수 있습니다. show tech 명령을 실행하여 RADIUS 서버 설정을 확인하고, 세션이 시작되거나 플랩될 때 RADIUS 서버를 통해 설치된 불법 서비스 정책을 확인합니다.
 피드백
피드백