Catalyst 4000/4500 Series 스위치의 Astro/Lemans/NiceR 시간 초과 이해 및 문제 해결
목차
소개
Catalyst 4000/4500 스위치 시리즈는 스위치 아키텍처에서 stub ASIC 설계를 사용합니다.스위치는 내부 관리 제어 프로토콜을 통해 이러한 라인 카드 stub ASIC(Astro/Leman/NiceR)를 관리합니다.이러한 내부 관리 요청 및 응답이 손실되거나 지연되면 콘솔 및 syslog 메시지가 생성됩니다.이러한 통신 손실의 원인은 다양하기 때문에 이러한 오류 메시지와 함께 근본 원인은 명확하지 않습니다.
이 문서의 목적은 Cat4000 플랫폼에서 생성된 Astro/Leman/Nice Timeout 메시지를 이해하고 Cisco TAC의 지원을 받아 문제를 해결하도록 돕기 위한 것입니다.향후 버전의 CatOS 및 Cisco IOS®는 향상된 오류 메시지를 제공하며, 가능한 경우 문제의 근본 원인을 파악합니다.
stub ASIC(Astro/Lemans/Nice) 시간 초과가 발생하면 CatOS 기반 Catalyst 4000/4500 스위치에 다음과 유사한 메시지가 보고됩니다.
%SYS-4-P2_WARN: 1/Astro(4/3) - timeout occurred %SYS-4-P2_WARN: 1/Astro(4/3) - timeout is persisting
소프트웨어 버전에 따라 오류 메시지의 표현이 다를 수 있습니다.아스트로, 레멘 그리고 더 좋은 것은 다른 종류의 stub ASIC를 나타냅니다.자세한 내용은 이 문서의 배경 이론 섹션에서 설명합니다.
Cisco IOS 기반 수퍼바이저(Supervisor II+, III 및 IV)의 경우 다음과 같은 오류 메시지가 나타납니다.
%C4K_LINECARDMGMTPROTOCOL-4-INITIALTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - management request timed out. %C4K_LINECARDMGMTPROTOCOL-4-ONGOINGTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - consecutive management requests timed out.
참고: 이 문서에서는 주로 CatOS 기반 수퍼바이저 또는 스위치의 문제 해결을 다룹니다.일부 정보는 Cisco IOS 기반 수퍼바이저에 적용됩니다.
참고: 이 문서에서는 Astro stub ASIC도 다루지만 대부분의 섹션은 다른 유형의 stub ASIC(Lemans and Nice) 라인 카드에 적용되므로 해당 섹션에 명시됩니다.
이 문서를 읽고 나면 독자는 다음을 이해할 수 있습니다.
-
Catalyst 4000/4500에서 stub ASIC의 기능.
-
내부 관리 패킷 시간 초과 메시지를 초래할 수 있는 조건.
-
이 문제를 해결할 때 Cisco TAC에 대해 수집해야 하는 단계 및 명령입니다.
Astro 시간 초과 및 문제 해결 섹션은 각 문제에 대한 배경 및 자세한 설명을 제공합니다.또는 이 문서의 Simple Ways to Troubleshoot 섹션으로 직접 이동할 수도 있습니다.
시작하기 전에
표기 규칙
문서 규칙에 대한 자세한 내용은 Cisco 기술 팁 표기 규칙을 참조하십시오.
사전 요구 사항
이 문서에 대한 특정 요건이 없습니다.
사용되는 구성 요소
이 문서는 Catalyst 4000/4500 Supervisor 또는 stub ASIC를 사용하는 라인 카드에 대한 것입니다.
배경 이론
Astro stub ASIC는 아래 그림과 같이 10/100 stub ASIC는 백플레인에 기가비트 대역폭 연결을 통해 Supervisor와 통신하는 8개의 인접한 10/100 포트 그룹을 제어합니다.
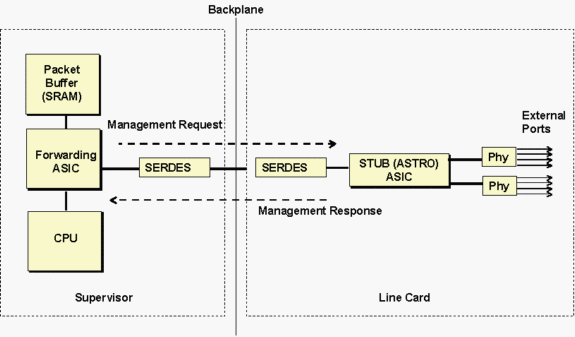
수퍼바이저는 SERDES(SERealizer-DESerializer) 구성 요소를 통해 라인 카드 stub ASIC에 통신합니다.수퍼바이저 쪽에 백플레인에 연결하는 SERDES 구성 요소가 있고 백플레인에 연결하기 위한 각 stub ASIC에 대한 라인 카드에 다른 SERDES가 있습니다.
위의 다이어그램은 일반적으로 서로 다른 유형의 라인 카드 문제를 해결하는 데 사용할 수 있습니다.시간 초과 메시지에서 참조하는 stub ASIC는 라인 카드의 유형에 따라 달라집니다.ASIC 이름 및 설명 목록은 아래 표를 참조하십시오.
| Stub ASIC | 설명 | 예 |
|---|---|---|
| 아스트로 | 8포트 10/100 컨트롤러 stub ASIC | WS-X4148-RJ45V |
| 나이스R | 4포트 1000 컨트롤러 stub ASIC | WS-X4418-GB(포트 3-18) |
| 레먼 | 8포트 10/100/1000 컨트롤러 stub ASIC | WS-X4448-GB-RJ |
내부 관리 트래픽은 일반 데이터 트래픽과 함께 SERDES 구성 요소를 모두 통과합니다.내부 관리 트래픽은 stub ASIC 및 Phy 레지스터를 읽고 쓰는 데 사용됩니다.가장 일반적인 작업에는 읽기 링크 상태 및 통계가 포함됩니다.
간단한 문제 해결 방법
다음 섹션에서는 %SYS-4-P2_WARN의 의미와 가능한 원인을 설명합니다.1/(Stub)(module_number/) Stub_reference - Catalyst 4000/4500에서 시간 초과 오류 메시지가 발생했습니다.
Astro(stub) 시간 초과 메시지는 6.2.3 및 6.3.1부터 시작하여 6.4.4(CSCea73908)에서 향상된 소프트웨어 버전에 추가되어 수퍼바이저가 10/100 라인 카드의 Astro stub ASIC에 통신하는 동안 내부 관리 제어 패킷이 손실되었음을 나타냅니다.아래의 문제 해결 섹션에서 자세히 설명한 대로 이러한 통신 손실에 대한 여러 가지 원인이 있습니다.
다음 문제 해결 흐름도는 가능한 근본 원인 간에 문제를 쉽고 빠르게 격리하는 방법을 제시합니다.
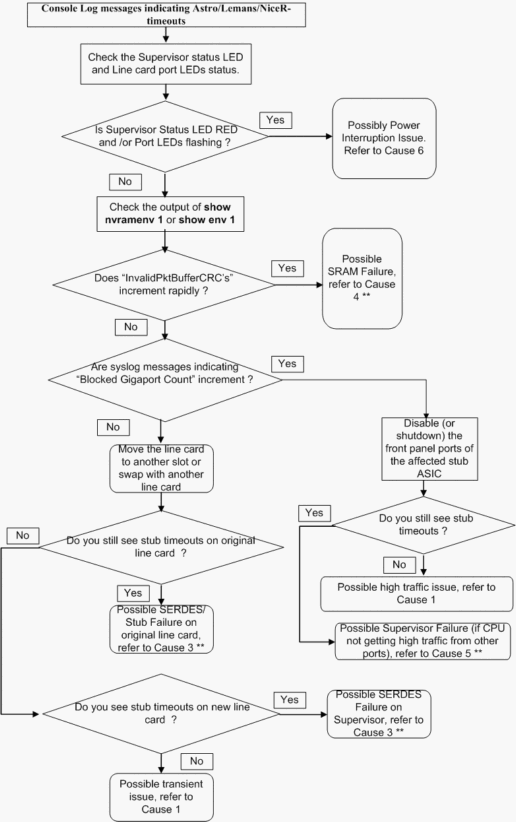
** 다양한 근본 원인은 유사한 증상을 나타낼 수 있습니다.추가 트러블슈팅은 TAC에 문의하십시오.
Stub(Astro/Lemans/NiceR) ASIC 시간 초과
Astro/Lemans/Nice 시간 초과는 Supervisor 소프트웨어가 라인 카드 stub ASIC에서 여러 내부 관리 응답을 받지 못할 경우 보고됩니다.다음과 같은 경우에 발생할 수 있습니다.
-
관리 요청이 손실되거나 지연됨
-
관리 응답이 손실되거나 지연됨
관리 패킷 응답을 기다리는 동안 소프트웨어가 10번 연속으로 시간 초과되면 "timeout occurred..." 메시지가 인쇄됩니다.그 결과 시간 초과로 인해 "연속 관리..."가 인쇄됩니다. 또는 "...시간 초과 지속.." 메시지, 소프트웨어 버전에 따라 다릅니다.
이 로그 메시지는 속도가 10분에 한 번으로 제한됩니다.영향을 받는 stub ASIC에 대한 패킷 전달은 시간 초과가 발생할 때 계속됩니다.그러나 소프트웨어에서 관리 패킷 응답을 받지 못하므로 링크/autoneg 속도/듀플렉스에 대한 변경 사항은 표시되지 않습니다.또한 시간 초과가 발생할 경우 인터페이스 그룹에 대한 트래픽 통계 업데이트 프로세스도 영향을 받습니다.
문제 해결
Astro/Lemans/Nice 시간 초과 메시지가 나타나는 데에는 다양한 원인이 있습니다.각 내용은 아래에 설명되어 있습니다.
원인 1:높은 트래픽 로드, 레이어 2 루프 또는 CPU로 향하는 과도한 네트워크 트래픽
다음은 stub 시간 제한 조건을 일으킬 수 있습니다.
-
네트워크 문제
-
구성 문제
-
인접 디바이스 요소
-
Catalyst 스위치 외부의 기타 요소
트래픽 로드가 높은 레이어 2 루프 또는 브로드캐스트 스톰으로 인해 내부 관리 제어 패킷이 손실될 수 있습니다.일반적으로 CPU가 사용 중(CPU 과다 사용)이고 대기열을 처리할 수 없기 때문에 이러한 현상이 발생합니다.
내부 관리 제어 트래픽은 Astro(또는 기타 Stub 칩)의 일반 데이터 트래픽과 동일한 데이터 경로를 Supervisor에 적용합니다. 따라서 혼잡 때문에 제어 패킷이 손실될 수 있습니다.
Cisco 버그 ID CSCea73908에 대한 수정(등록된 고객만 해당)을 사용하면 CatOS 버전 6.4(4) 이상 릴리스에서 내부 관리 요청 시간 제한 기간이 더 잘 처리됩니다.이러한 개선 사항으로 인해 CPU가 사용 중이어서 일시적으로 제어 패킷 시간 초과가 많은 것을 방지할 수 있습니다.
작업:레이어 2 루프 문제 해결;또는 컨피그레이션을 변경하여 트래픽 패턴을 해결합니다.
해결 방법:CatOS 기반 스위치에서 스위치 관리 인터페이스(sc0)를 비 사용자 트래픽 VLAN으로 이동합니다.set interface sc0 <vlan-id> 명령을 사용하여 인터페이스 sc0의 vlan을 이동합니다.
참고: Cisco IOS 12.1(20)EW부터 Cisco IOS 기반 수퍼바이저는 CPU를 통해 내부 관리 패킷 처리 메커니즘을 더 효과적으로 처리합니다.이 개선 사항은 부주의로 인해 CPU를 과다 사용하는 낮은 우선순위 트래픽으로 인한 내부 관리 제어 패킷의 손실을 방지하는 데 도움이 됩니다.
해결책:위의 해결 방법을 참조하십시오.
원인 2:하프 듀플렉스/유형 1A 케이블
전면 패널 사용자 포트는 반이중으로 구성됩니다.stub ASIC에서 수신 트래픽과 발신 트래픽의 충돌로 인해 stub 버퍼가 매우 느리게 소모될 수 있습니다.이로 인해 수퍼바이저의 tx-queue가 채워지고 새 내부 관리 요청이 삭제되어 시간 초과 오류 메시지가 발생할 수 있습니다.
Type1A 케이블을 사용하는 네트워크도 이 문제를 일으킬 수 있습니다.RJ-45 패치가 있는 Type1A Baluns에 연결된 워크스테이션의 연결이 끊기면 Balun이 내부적으로 다시 루프되고 발신 트래픽이 반환됩니다.이 상황은 전면 패널 포트에서 외부 루프백 연결을 시뮬레이션합니다.포트가 차단 상태로 전환되기 전에 발신 트래픽은 스위치로 다시 루프됩니다.트래픽 속도에 따라 stub 버퍼가 오버플로될 수 있습니다.
작업:해결 방법을 참조하십시오.
해결 방법:반이중 컨피그레이션을 사용하지 마십시오.Type1A 케이블의 경우 Type 1A Balun에서 RJ-45 패치 코드를 플러딩하지 않도록 하여 Balun에서 내부 루프백이 형성되지 않도록 합니다.
해결책:해결 방법을 참조하십시오.
원인 3:SERDES 구성 요소 오류
한 모듈의 한 Astro(또는 다른 stub ASIC)에서만 오류가 표시되고 레이어 2 루프가 발생하지 않는 경우 수퍼바이저 또는 라인 카드의 SERDES 구성 요소에 문제가 발생할 가능성이 높습니다.예를 들어, 오류 메시지가 아래와 같이 모듈 3의 Astro 4에 항상 표시되면 모듈 3의 SERDES 구성 요소나 수퍼바이저의 SERDES 구성 요소에 오류가 있는 것입니다.
%SYS-4-P2_WARN: 1/Astro(3/4) – timeout occurred
위 오류 메시지에서 괄호 안의 숫자 "4"는 실제 포트 3/4가 아니라 Astro 번호를 나타냅니다. 이 숫자는 모듈 3에 네 번째 Astro이므로 8개 포트(3/33-3/40)의 그룹을 참조합니다.
결함이 있는 SERDES 구성 요소는 제어 트래픽 및 Astro/Lemans/NiceR에 대한 데이터 트래픽에 대한 간헐적인 연결을 유발하여 시간 초과가 발생할 수 있습니다.그러나 일반적으로 SERDES에 결함이 있는 경우 오류 메시지가 계속 표시됩니다.
작업:어떤(수퍼바이저 또는 라인 카드) SERDES가 불량인지 확인하려면 다음 단계를 수행하십시오.
-
라인 카드를 섀시 또는 다른 섀시의 예비 슬롯으로 이동합니다.사용 가능한 슬롯이 있는 경우 슬롯을 알려진 작동 모듈로 바꿉니다.
-
같은 Astro/Lemans/Nice 타임아웃을 새 슬롯에 계속 가져오면, SERDES 또는 Astro/Lemans/Nice가 실패하여 라인 카드를 교체해야 할 가능성이 높습니다.
참고: 예비 슬롯에 모듈을 다시 삽입하면 라인 카드에서 온라인 진단 프로그램이 수행됩니다.결함이 있는 SERDES 또는 Astro/Lemans/Nice가 발견되면 스위치에서 해당 포트를 결함이 있는 것으로 표시합니다.
-
원래 라인 카드인 Astro/Lemans/Nice에서 시간 초과가 계속 발생하지 않을 경우 수퍼바이저 SERDES에 결함이 있을 수 있습니다.이를 확인하려면 정상 작동이 확인된 모듈을 원래 슬롯에 삽입하고 새 모듈에서 시간 제한이 발생하는지 확인합니다.
SERDES가 작동하면 SERDES가 수퍼바이저에 있을 수 있습니다.결함이 있는 SERDES 구성 요소와 관련된 일련 번호 목록은 Catalyst WS-X4013 Supervisor Extents Partial Loss of Connectivity(일부 연결 손실) 필드 알림을 참조하십시오.
해결 방법:없음
해결책:추가 트러블슈팅은 TAC에 문의하십시오.
원인 4:임시/하드 SRAM 오류
Supervisor I, II, III 또는 IV 엔진 또는 Catalyst 2948G를 사용하여 Catalyst 4000에 연결된 디바이스는 네트워크 연결의 일부 또는 전체 손실을 경험할 수 있습니다.일부 또는 모든 포트에 영향을 줄 수 있습니다.이러한 증상에는 CatOS 기반 Supervisor 및 stub ASIC 시간 초과 오류 메시지에서 Invalid CRC dropped 패킷이 빠르게 증가하는 결과로 이어집니다.
문제는 하드 또는 일시적인 유형인 SRAM(Packet Buffer Memory) 장애로 인해 발생합니다.
작업:아래 두 개의 일시적 패킷 버퍼 메모리 실패 시그니처가 발생한 것에 따라 작업 과정을 선택합니다.
-
SUP I, SUP II, 2948G, 2980G의 일시적 패킷 버퍼 메모리 실패 서명
다음은 이 문제의 증상입니다.
-
InvalidPktBufferCRC는 다음과 유사한 메시지와 함께 빠르게 증가합니다.
%SYS-4-P2_WARN: 1/Invalid crc, dropped packet, count = xxxx
-
reset 명령을 사용하여 소프트 리셋을 수행하면 수퍼바이저가 POST에 실패합니다.
-
하드 리셋(전원 주기)을 수행하면 수퍼바이저가 POST를 통과하며 더 이상 오류가 발생하지 않습니다.
참고: Supervisor I, II, 2948G, 2980G에 대한 하드 패킷 버퍼 메모리 장애가 발생할 경우 하드 리셋으로 문제가 해결되지 않으며 Supervisor 또는 스위치가 POST에 여전히 실패합니다.
이 문제에 대한 자세한 내용은 Supervisor II용 Cisco Bug ID CSCdy46288(등록된 고객만 해당), Cisco Bug ID CSCeb56266(등록된 고객만 해당)를 참조하십시오. WS-C2980G-A의 CSCeb56325(등록된 고객만 해당)
-
-
SUP III, SUP IV의 일시적 패킷 버퍼 메모리 실패 서명
다음은 이 문제의 증상입니다.
-
VlanZeroBadCrc 카운터는 빠르게 증가하며 다음 명령의 출력에 표시됩니다.
show platform cpuport all (prior to 12.1(11b)EW1 ) or show platform cpu packet statistics all (Since 12.1(11b)EW1) depending upon the software version. Starting from 12.1(19)EW, you should also see the following error message rapidly incrementing errors: %C4K_SWITCHINGENGINEMAN-2-PACKETMEMORYERROR3: Persistent Errors in Packet Memory xxxx
-
소프트 리셋으로 인해 수퍼바이저가 POST에 실패합니다.show diagnostics power-on 명령을 사용하여 오류를 확인합니다.
-
하드 리셋(전원 주기)이 Supervisor를 복구하며 POST를 통과합니다.
참고: Supervisor III / IV에 대한 하드 SRAM 장애가 발생한 경우, 하드 재설정은 Supervisor를 복구하지 않으며 POST를 실패합니다.
Supervisor III/IV에 대한 자세한 내용은 Cisco 버그 ID CSCdz57255(등록된 고객만 해당)를 참조하십시오.
-
해결 방법:일시적인 SRAM 문제가 발생할 경우 전원 주기 또는 하드 리셋하드 SRAM 문제에는 해결 방법이 없습니다.
해결책:추가 트러블슈팅은 TAC에 문의하십시오.
원인 5:수퍼바이저 클럭 실패
Astro/Lemans/NiceR 시간 초과 오류 메시지가 여러 모듈 번호 또는 여러 개의 Astro/Lemans/Nice를 참조하는 것으로 표시되면 수퍼바이저의 클럭 오류가 발생할 수 있습니다.일반적으로 클럭 장애가 발생하면 아래와 같이 Astro/Lemans/Nice 시간 초과 오류 메시지와 BlockTXQueue 및 BlockedGigapport 오류 메시지가 함께 발생합니다.
%SYS-4-P2_WARN: 1/Blocked queue on gigaport ...
작업:자세한 트러블슈팅은 Cisco 버그 ID CSCdp89537(등록된 고객만 해당) 및 CSCdp93187(등록된 고객만 해당)을 참조하여 TAC에 문의하십시오.
해결 방법:없음
해결책:추가 트러블슈팅은 TAC에 문의하십시오.
원인 6:짧은 전원 중단
Supervisor II(WS-X4013)가 있는 Catalyst 4000 Series 스위치는 수퍼바이저와 라인 카드가 서로 제대로 통신할 수 없는 상태로 들어갈 수 있습니다.스위치가 이 상태로 전환되면 모듈 상태 LED가 빨간색(깜박이지 않음)으로 켜지거나 포트 LED가 모듈 또는 스위치 재설정 과정과 비슷하게 차례로 깜박입니다.이 메시지는 Astro/Lemans/NiceR 시간 초과 메시지와 함께 제공됩니다.
이 문제는 스위치에 일시적인 전원 장애(500ms 미만)로 인해 발생합니다. 프로덕션 환경에서 전원 피드가 불안정하기 때문에 일시적인 전원 중단이 발생할 수 있습니다.
작업:아래의 해결 방법을 참조하십시오.
해결 방법:스위치를 재설정합니다(소프트 또는 하드(전원 사이클).
해결책:Cisco 버그 ID CSCea14710(등록된 고객만 해당) 이상 릴리스의 수정을 사용하여 소프트웨어 이미지로 업그레이드합니다.
 피드백
피드백