Beheer op serviceniveau: Whitepaper over beste praktijken
Inhoud
Inleiding
Dit document beschrijft Service-level Management en Service-level overeenkomsten (SLA’s) voor netwerken met hoge beschikbaarheid. Het omvat kritieke succesfactoren voor het beheer op serviceniveau en prestatie-indicatoren om succes te helpen evalueren. Het document biedt ook belangrijke details voor SLA's die de door het dienstverleningsteam met hoge beschikbaarheid vastgestelde richtsnoeren voor beste praktijken volgen.
Overzicht op serviceniveau
Netwerkorganisaties hebben historisch gezien voldaan aan de groeiende netwerkvereisten door een solide netwerkinfrastructuur te bouwen en actief te werken om individuele servicekwesties aan te pakken. Wanneer een stroomonderbreking plaatsvond, zou de organisatie nieuwe processen, beheermogelijkheden of infrastructuur bouwen die een bepaalde stroomstoring voorkomen. Maar door een hogere veranderingsgraad en stijgende beschikbaarheidsvereisten hebben we nu een verbeterd model nodig om proactief ongeplande onderbreking te voorkomen en snel het netwerk te repareren. Veel serviceproviders en bedrijfsorganisaties hebben getracht het niveau van de dienstverlening die nodig is om bedrijfsdoelstellingen te bereiken beter te definiëren.
Belangrijke succesfactoren
Belangrijke succesfactoren voor SLA's worden gebruikt om sleutelelementen te definiëren voor het met succes bouwen van haalbare serviceniveaus en voor het handhaven van SLA's. Om in aanmerking te komen als kritieke succesfactor, moet een proces- of processtap de kwaliteit van de SLA verbeteren en de beschikbaarheid van het netwerk in het algemeen ten goede komen. Ook de kritische succesfactor moet meetbaar zijn, zodat de organisatie kan bepalen hoe succesvol zij is geweest ten opzichte van de vastgestelde procedure.
Zie Beheer op serviceniveau implementeren voor meer informatie.
Prestatie-indicatoren
Prestatie-indicatoren vormen het mechanisme waarmee een organisatie kritieke succesfactoren meet. U bekijkt deze doorgaans op maandbasis om er zeker van te zijn dat de service-level definities of SLA's goed werken. De groep netwerkbewerkingen en de benodigde gereedschappen kunnen de volgende parameters uitvoeren.
Opmerking: Voor organisaties zonder SLA's raden we u aan om naast de parameters ook de Service-level-definities en de Service-level-beoordelingen uit te voeren.
De prestatie-indicatoren omvatten:
-
Gedocumenteerde service-level definitie of SLA die beschikbaarheid, prestaties, reactieve tijd van de servicereshier, de doelstellingen van de probleemoplossing en het escaleren van problemen omvat.
-
Maandelijkse vergadering voor de herziening van het serviceniveau om de naleving van het serviceniveau te toetsen en verbeteringen door te voeren.
-
Metriek van prestatie-indicatoren, waaronder beschikbaarheid, prestaties, tijd van servicerespons per prioriteit, tijd om op te lossen per prioriteit, en andere meetbare SLA-parameters.
Zie Servicebeheer implementeren voor meer informatie.
Beheer op serviceniveau van Flow
De processtroom op hoog niveau voor het beheer op serviceniveau omvat twee belangrijke groepen:
Klik op de objecten in het volgende diagram om de details voor die stap te bekijken.
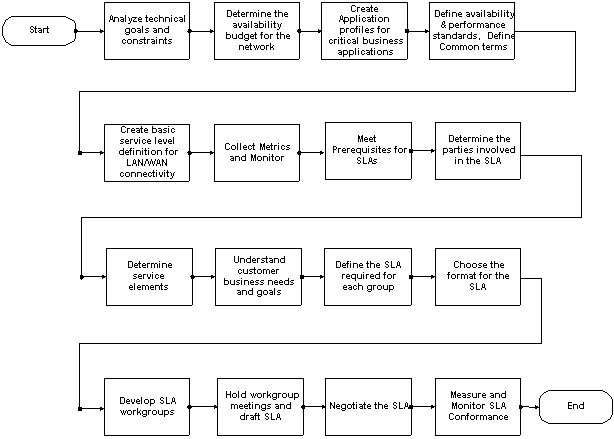
Beheer op serviceniveau uitvoeren
De uitvoering van het beheer op serviceniveau bestaat uit zestien stappen verdeeld in de volgende twee hoofdcategorieën:
Netwerkserviceniveaus definiëren
Netwerkbeheerders moeten de belangrijkste regels definiëren aan de hand waarvan het netwerk wordt ondersteund, beheerd en gemeten. Serviceniveaus bieden doelen voor al het netwerkpersoneel en kunnen worden gebruikt als metrische waarde voor de kwaliteit van de algemene service. U kunt ook definities op serviceniveau gebruiken als een instrument voor het begroten van netwerkbronnen en als bewijs voor de noodzaak om hogere QoS te financieren. Zij bieden ook een manier om de prestaties van verkopers en vervoerders te beoordelen.
Zonder een definitie en meting op serviceniveau heeft de organisatie geen duidelijke doelstellingen. De tevredenheid over de service kan worden bepaald door gebruikers met weinig verschil tussen toepassingen, server-/client-bewerkingen of netwerkondersteuning. Het budgetteren kan moeilijker worden omdat het eindresultaat voor de organisatie niet duidelijk is en tenslotte, de netwerkorganisatie neigt er reactiever en niet pro-actief te zijn in het verbeteren van het netwerk en het ondersteuningsmodel.
We raden de volgende stappen aan voor het bouwen en ondersteunen van een serviceniveau-model:
-
Toepassingsprofielen maken met de netwerkkenmerken van kritieke toepassingen.
-
Bepaal de beschikbaarheid en prestatienormen en definieer gemeenschappelijke termen.
-
Verzamel parameters en controleer de definitie op serviceniveau.
Stap 1: Technische doelstellingen en beperkingen analyseren
De beste manier om technische doelen en beperkingen te analyseren is om te brainstormen of technische doelen en vereisten voor onderzoek te formuleren. Soms helpt het om andere IT technische collega's in deze discussie uit te nodigen omdat deze individuen specifieke doelen hebben die verband houden met hun diensten. Technische doelen omvatten niveaus van beschikbaarheid, doorvoersnelheid, jitter, vertraging, responstijd, schaalbaarheidsvereisten, nieuwe functies introducties, nieuwe applicaties, beveiliging, beheerbaarheid en zelfs kosten. De organisatie zou dan beperkingen om deze doelen te bereiken moeten onderzoeken gezien de beschikbare middelen. U kunt voor elk doel werkbladen maken met een verklaring van beperkingen. In eerste instantie lijkt het erop dat de meeste doelstellingen niet bereikbaar zijn. Begin dan met het prioriteren van de doelen of het verlagen van de verwachtingen die nog steeds aan de zakelijke vereisten kunnen voldoen.
Bijvoorbeeld, je zou een beschikbaarheid van 99.999 procent kunnen hebben, of 5 minuten van inlevertijd per jaar. Er zijn talloze beperkingen om dit doel te bereiken, zoals enkele punten van falen in hardware, gemiddelde tijd om defecte hardware op afgelegen locaties te repareren (MTTR), betrouwbaarheid van transportbedrijven, proactieve mogelijkheden voor foutdetectie, hoge wisselkoersen en huidige beperkingen van netwerkcapaciteit. Als resultaat hiervan kunt u het doel aanpassen naar een bereikbaar niveau. Het beschikbaarheidsmodel in de volgende sectie kan u helpen realistische doelen te stellen.
U kunt ook denken aan het bieden van een hogere beschikbaarheid in bepaalde gebieden van het netwerk die minder beperkingen hebben. Wanneer de netwerkorganisatie servicenormen voor beschikbaarheid publiceert, kunnen bedrijfsgroepen binnen de organisatie het niveau onacceptabel vinden. Dit is dan een natuurlijk punt om in het kader van de SLA-besprekingen of financieringsmodellen/budgettaire modellen te starten die aan de zakelijke behoeften kunnen voldoen.
Werkzaamheden om alle beperkingen of risico's te identificeren die bij het bereiken van het technische doel betrokken zijn. Prioritaire beperkingen in termen van het grootste risico of de grootste impact op het gewenste doel. Dit helpt de organisatie om prioriteit te geven aan initiatieven voor netwerkverbetering en om te bepalen hoe makkelijk de beperking kan worden aangepakt. Er zijn drie soorten beperkingen:
-
Netwerktechnologie, veerkracht en configuratie
-
Levenscycluspraktijken, waaronder planning, ontwerp, implementatie en werking
-
Huidige verkeersbelasting of toepassingsgedrag
Netwerktechnologie, veerkracht en configuratie zijn alle beperkingen of risico's verbonden aan de huidige technologie, hardware, koppelingen, ontwerp of configuratie. De technologische beperkingen bestrijken alle beperkingen die de technologie zelf oplegt. Bijvoorbeeld, geen huidige technologie staat voor sub-seconde convergentietijden in overtollige netwerkomgevingen toe, die cruciaal kunnen zijn voor het volhouden van spraakverbindingen over het netwerk. Een ander voorbeeld kan de rauwe snelheid zijn die data kunnen verplaatsen op aardse verbindingen, die ongeveer 100 mijl per milliseconde is.
De onderzoeken naar de veerkracht van de hardware van het netwerk moeten zich op de topologie van de hardware, hiërarchie, modulariteit, overtolligheid, en MTBF volgens bepaalde paden in het netwerk concentreren. De beperkingen van de netwerklink moeten zich concentreren op netwerkverbindingen en dragerconnectiviteit voor ondernemersorganisaties. De beperkingen van de verbinding kunnen verbindingsredundantie en diversiteit, mediabeperkingen, bedradingsinfrastructuur, aansluitnetconnectiviteit, en lange-afstand connectiviteit omvatten. De beperkingen van het ontwerp hebben betrekking op het fysieke of logische ontwerp van het netwerk en omvatten alles van beschikbare ruimte voor apparatuur tot schaalbaarheid van de routingprotocol implementatie. Alle protocol- en mediaontwerpen dienen te worden overwogen met betrekking tot configuratie, beschikbaarheid, schaalbaarheid, prestaties en capaciteit. Netwerkservicetekens zoals Dynamic Host Configuration Protocol (DHCP), Domain Name System (DNS), firewalls, protocolvertalers en netwerkadresvertalers moeten ook worden overwogen.
Levenscycluspraktijken definiëren de processen en het beheer van het netwerk dat wordt gebruikt om oplossingen op consistente wijze in te zetten, problemen op te sporen en te repareren, capaciteitsproblemen of prestatiesproblemen te voorkomen en het netwerk te configureren voor consistentie en modulariteit. U moet dit gebied in overweging nemen, omdat expertise en processen doorgaans de grootste bijdrage tot niet-beschikbaarheid zijn. De levenscyclus van het netwerk verwijst naar de cyclus van planning, ontwerp, implementatie en werking. Binnen elk van deze gebieden moet u de functionaliteit voor netwerkbeheer begrijpen zoals prestatiemanagement, configuratiebeheer, foutbeheer en beveiliging. Een evaluatie van het netwerkleven van de cyclus is beschikbaar van de diensten van de Hoge beschikbaarheid van Cisco NSA (HAS) die de huidige beperkingen van de netwerkbeschikbaarheid verbonden aan de praktijken van het netwerkleven tonen.
De huidige belasting van het verkeer of de beperkingen van de toepassing verwijzen eenvoudigweg naar de impact van het huidige verkeer en de huidige toepassingen.
Helaas hebben veel toepassingen belangrijke beperkingen die een zorgvuldig beheer vereisen. Jitter, vertraging, doorvoersnelheid en bandbreedtevereisten voor huidige toepassingen hebben doorgaans veel beperkingen. De manier waarop de toepassing is geschreven kan ook tot beperkingen leiden. Toepassingsprofilering helpt u deze problemen beter te begrijpen; in het volgende hoofdstuk wordt deze functie besproken . Het onderzoeken van huidige beschikbaarheid, verkeer, capaciteit, en prestaties over het geheel genomen helpt netwerkmanagers ook om de huidige verwachtingen en risico's op het serviceniveau te begrijpen. Dit wordt meestal bereikt met een proces dat netwerkbasisindeling wordt genoemd, wat helpt om netwerkprestaties, beschikbaarheid of capaciteitsgemiddelden voor een bepaalde tijdsperiode te definiëren, normaal ongeveer een maand. Deze informatie wordt normaal gebruikt voor capaciteitsplanning en trending, maar kan ook worden gebruikt om kwesties op serviceniveau te begrijpen.
Het volgende werkblad gebruikt de bovenstaande doelstelling/beperkingsmethode voor het voorbeelddoel van het voorkomen van een veiligheidsaanval of de ontkenning van-service (DoS) aanval. U kunt dit werkblad ook gebruiken om de servicedekking te bepalen voor het minimaliseren van beveiligingsaanvallen.
| Risico of beperking | Type beperking | Potentiele impact |
|---|---|---|
| Beschikbare DoS-detectiegereedschappen kunnen niet alle typen DOS-aanvallen detecteren. | Technologie/veerkracht | Hoog |
| U hoeft niet het vereiste personeel te hebben en de juiste procedure in te stellen om op waarschuwingen te reageren. | Levenscycluspraktijken | Hoog |
| Het huidige beleid voor netwerktoegang is niet van kracht. | Levenscycluspraktijken | Gemiddeld |
| De huidige verbinding van het Internet met lagere bandbreedte kan een factor zijn als de bandbreedte congestie voor aanval wordt gebruikt. | Netwerkcapaciteit | Gemiddeld |
| Mogelijk is de huidige beveiligingsconfiguratie om aanvallen te helpen voorkomen niet grondig. | Technologie/veerkracht | Gemiddeld |
Stap 2: Bepaal de beschikbare begroting
Een beschikbaarheidsbudget is de verwachte theoretische beschikbaarheid van het netwerk tussen twee gedefinieerde punten. Nauwkeurige theoretische informatie is op verschillende manieren nuttig:
-
De organisatie kan dit als doel voor interne beschikbaarheid gebruiken en afwijkingen kunnen snel worden gedefinieerd en gecorrigeerd.
-
De informatie kan door netwerkplanners worden gebruikt bij het bepalen van de beschikbaarheid van het systeem om ervoor te zorgen dat het ontwerp aan de zakelijke vereisten voldoet.
Factoren die tot het niet beschikbaar zijn of de stroomuitval bijdragen omvatten hardwarestoring, softwarefalen, vermogen en milieuproblemen, storing van link of transportbedrijf, netwerkontwerp, menselijke fout of gebrek aan proces. U dient elk van deze parameters nauwkeurig te evalueren bij de evaluatie van het totale beschikbare budget voor het netwerk.
Als de organisatie momenteel de beschikbaarheid meet, hebt u misschien geen budget nodig. Gebruik de beschikbaarheidsmeting als basislijn om het huidige serviceniveau te schatten dat gebruikt wordt voor een definitie op serviceniveau. Het kan echter interessant zijn om de twee te vergelijken om de potentiële theoretische beschikbaarheid te begrijpen in vergelijking met het werkelijk gemeten resultaat.
Beschikbaarheid is de waarschijnlijkheid dat een product of dienst wanneer nodig zal werken. Zie de volgende definities:
-
Beschikbaarheid
-
1 - (totale aansluitingstijd) / (totaal aansluitingstijd tijdens bedrijf)
-
1 - [Sigma(totale verbindingen beïnvloed in stroomuitval i X duur van uitval i)] / (maximaal aangesloten op de bedieningstijd X)
-
-
onbeschikbaarheid
1 - Beschikbaarheid of totale verbindingstijd als gevolg van (hardwarestoring, softwareuitval, problemen met milieu en voeding, storing van link of transportshelf, netwerkontwerp of gebruikersfout en verwerkingsfalen)
-
Hardware beschikbaarheid
Het eerste gebied dat onderzocht wordt is mogelijk hardwarestoring en het effect op onbeschikbaarheid. Om dit te bepalen moet de organisatie de MTBF van alle netwerkcomponenten begrijpen en de MTTR voor hardwareproblemen voor alle apparaten in een pad tussen twee punten. Als het netwerk modulair en hiërarchisch is, zal de hardwarebeschikbaarheid gelijk zijn tussen bijna om het even welke twee punten. MTBF-informatie is beschikbaar voor alle Cisco-componenten en is op verzoek beschikbaar voor een plaatselijke accountmanager. Het Cisco NSA HAS programma gebruikt ook een gereedschap om hardwarebeschikbaarheid langs netwerkpaden te helpen bepalen, zelfs wanneer de moduredundantie, de chassisredundantie en de padredundantie in het systeem aanwezig zijn. Een belangrijke factor voor de betrouwbaarheid van de hardware is de MTTR. Organisaties moeten evalueren hoe snel ze kapotte hardware kunnen repareren. Als de organisatie geen sparend plan heeft en afhankelijk is van een standaard Cisco SMARTnet™-overeenkomst, is de potentiële gemiddelde vervangingstijd ongeveer 24 uur. In een typische LAN-omgeving met kernredundantie en geen toegangsredundantie is de gemiddelde beschikbaarheid 99,99% met een MTTR van 4 uur.
-
Beschikbaarheid software
Het volgende onderzoeksgebied is software-falen. Voor meetdoeleinden, definieert Cisco softwarefouten als apparaten kunnen worden gestart door softwarefouten te maken. Cisco heeft aanzienlijke vooruitgang geboekt op weg naar een beter begrip van de beschikbaarheid van software; er is echter tijd nodig om de nieuwe versies te meten en deze worden als minder beschikbaar beschouwd dan algemene implementatiesoftware . De algemene implementatiesoftware, zoals IOS versie 11.2(18), is gemeten bij meer dan 99.999% beschikbaarheid. Dit wordt berekend op basis van de eigenlijke oude start op Cisco-routers die zes minuten gebruiken als de reparatietijd (tijd voor router om opnieuw te laden). De verwachting is dat organisaties met een verscheidenheid aan versies een iets lagere beschikbaarheid hebben door toegevoegde complexiteit, interoperabiliteit en verhoogde tijden voor het oplossen van problemen. Naar verwachting hebben organisaties met de meest recente softwareversies een hogere niet-beschikbaarheid. De distributie voor de niet-beschikbaarheid is ook vrij breed, wat betekent dat klanten ofwel aanzienlijke onbeschikbaarheid zouden kunnen ervaren, ofwel beschikbaarheid dichtbij een algemene implementatierelease.
-
Beschikbaarheid van milieu en voeding
U moet ook aandacht schenken aan milieu- en energiekwesties die beschikbaar zijn. Milieuproblemen hebben te maken met het uitvallen van koelsystemen die nodig zijn om de apparatuur op een bepaalde bedrijfstemperatuur te houden. Veel apparaten van Cisco zullen eenvoudigweg sluiten wanneer ze aanzienlijk niet meer gespecificeerd zijn dan wanneer ze schade aan alle hardware dreigen te veroorzaken. Met het oog op een beschikbaarheidsbegroting zal macht worden gebruikt, omdat dit de belangrijkste oorzaak is van het ontbreken van beschikbaarheid op dit gebied.
Hoewel stroomuitval een belangrijk aspect is van het bepalen van de beschikbaarheid van het netwerk, is deze discussie beperkt omdat theoretische energieanalyse niet nauwkeurig kan worden uitgevoerd. Wat een organisatie moet evalueren is een benadering van het meten van de beschikbaarheid van vermogen voor haar apparaten op basis van ervaring in haar geografische gebied, reservecapaciteit van het vermogen en proces geïmplementeerd om consistente kwaliteitsstroom voor alle apparaten te garanderen.
Voor een conservatieve evaluatie kunnen we zeggen dat een organisatie met back-upgenerators, UPS-systemen (Unonderbrekable Power-Supply) en UPS-systemen van kwaliteit energieimplementatie zes 9s van beschikbaarheid kan ervaren, of 99.999%, terwijl organisaties zonder deze systemen beschikbaarheid kunnen ervaren van 99,99%, of ongeveer 36 minuten van inleveringstijd per jaar. Natuurlijk kun je deze waarden aanpassen aan meer realistische waarden gebaseerd op de perceptie van de organisatie of op feitelijke gegevens.
-
Link of Carrier FOUT
De verbinding en dragerfouten zijn belangrijke factoren betreffende beschikbaarheid in WAN omgevingen. Houd in gedachten dat WAN-omgevingen simpelweg andere netwerken zijn die onderhevig zijn aan dezelfde beschikbaarheid als het netwerk van de organisatie, inclusief hardwarestoring, softwarefalen, gebruikersfout en stroomuitval.
Veel netwerken hebben al een budget voor beschikbaarheid op hun systemen opgesteld, maar het kan moeilijk zijn deze informatie te verkrijgen. Houd er rekening mee dat de luchtvaartmaatschappijen ook vaak een garantieniveau hebben dat weinig of geen basis heeft op basis van een werkelijk beschikbare begroting. Deze garantieniveaus zijn soms louter marketing- en verkoopmethoden die worden gebruikt om de luchtvaartmaatschappij te promoten. In sommige gevallen publiceren deze netwerken ook beschikbaarheidsstatistieken die extreem goed lijken. Houd in gedachten dat deze statistieken alleen van toepassing kunnen zijn op volledig redundante kernnetwerken en niet een factor in onbeschikbaarheid hebben door toegang tot het aansluitnet, dat een belangrijke bijdrage aan niet-beschikbaarheid in WAN-netwerken is.
Het creëren van een schatting van beschikbaarheid voor WAN-omgevingen zou gebaseerd moeten zijn op feitelijke dragerinformatie en het niveau van redundantie voor WAN-connectiviteit. Als een organisatie meerdere toegangsfaciliteiten voor gebouwen heeft, overbodige lokale aanbieders, Synchronous-Optical-Network (SONET) lokale toegang en redundante langeafstandsluchtvaartmaatschappijen met geografische diversiteit, zal WAN-beschikbaarheid aanzienlijk worden verbeterd.
De telefoondienst is een vrij nauwkeurig beschikbaarheidsbudget voor niet-redundante netwerkconnectiviteit in WAN-omgevingen. End-to-end connectiviteit voor telefoons heeft een ongeveer beschikbare budget van 99.94% door gebruik te maken van een beschikbare begrotingsmethodologie die vergelijkbaar is met die welke in deze sectie wordt beschreven. Deze methodologie is met succes gebruikt in gegevensomgevingen met slechts een geringe variatie, en wordt momenteel gebruikt als doel in de pakketkabelspecificatie voor service-provider-kabelnetwerken. Als we deze waarde toepassen op een volledig overbodig systeem, kunnen we ervan uitgaan dat WAN-beschikbaarheid dicht bij 99.999 procent beschikbaar zal zijn. Natuurlijk hebben zeer weinig organisaties volledig redundante, geografisch verspreide WAN systemen door de kosten en beschikbaarheid, dus gebruik een juist oordeel over deze mogelijkheid.
De tekortkomingen van de verbinding in een LAN omgeving zijn minder waarschijnlijk. Het is echter mogelijk dat planners een klein bedrag aan downtime willen inleveren als gevolg van defecte of losse connectors. Voor LAN-netwerken is een conservatieve schatting ongeveer 99.999 procent beschikbaarheid, of ongeveer 30 seconden per jaar.
-
Netwerkontwerp
Netwerkontwerp levert een andere belangrijke bijdrage aan de beschikbaarheid. Niet-schaalbare ontwerpen, ontwerpfouten, en de tijd van netwerkconvergentie hebben een negatieve invloed op de beschikbaarheid.
Opmerking: Voor de toepassing van dit document worden in de volgende paragraaf niet-schaalbare ontwerp- of ontwerpfouten opgenomen.
Het netwerkontwerp is dan beperkt tot een meetbare waarde gebaseerd op software en hardwarestoring in het netwerk waardoor verkeer opnieuw wordt gerouteerd. Deze waarde wordt gewoonlijk "systeemswitchover-tijd" genoemd en is een factor van de zelfgenezende protocolfuncties binnen het systeem.
Bereken de beschikbaarheid door gebruik te maken van dezelfde methoden voor systeemberekeningen. Dit is echter niet geldig tenzij de netwerkswitchingtijd voldoet aan de eisen van de netwerktoepassing. Als de overschakeltijd acceptabel is, verwijder deze dan uit de berekening. Als de overschakeltijd niet acceptabel is, moet u deze aan de berekeningen toevoegen. Een voorbeeld kan Voice-over-IP (VoIP) zijn in een omgeving waar de geschatte of feitelijke overschakeltijd 30 seconden is. In dit voorbeeld, zullen de gebruikers eenvoudig de telefoon ophangen en misschien opnieuw proberen. De gebruikers zullen deze periode zeker als niet-beschikbaarheid zien, maar deze is niet geschat in het budget voor beschikbaarheid.
Bereken de niet-beschikbaarheid als gevolg van de overschakelingstijd van het systeem door te kijken naar de theoretische software en de beschikbaarheid van hardware langs redundante paden, omdat de overschakeling op dit gebied zal plaatsvinden. U moet weten hoeveel apparaten kunnen falen en overschakeling kunnen veroorzaken in het redundante pad, MTBF van die apparaten en de overschakelingstijd. Een eenvoudig voorbeeld zou een MTBF van 35.433 uur zijn voor elk van twee overtollige identieke apparaten en een overschakelingstijd van 30 seconden. Als we 35.433 in 8766 (gemiddeld uren per jaar met sterftecijfers) verdelen, zien we dat het toestel eens in de vier jaar failliet gaat. Als we 30 seconden gebruiken als overschakelingstijd, kunnen we aannemen dat elk apparaat gemiddeld 7,5 seconden per jaar onbeschikbaarheid zal ervaren door overschakeling. Aangezien gebruikers elk pad kunnen oversteken, wordt het resultaat vervolgens verdubbeld tot 15 seconden per jaar. Wanneer dit wordt berekend in seconden per jaar, kan de hoeveelheid beschikbaarheid als gevolg van de omschakeling worden berekend als 99.99999785% beschikbaarheid in dit eenvoudige systeem. Dit kan hoger zijn in andere omgevingen vanwege het aantal overtollige apparaten in het netwerk waar de overschakeling een potentieel is.
-
Gebruikersfout en -proces
Problemen met de beschikbaarheid van gebruikersfouten en processen zijn de belangrijkste oorzaken van het gebrek aan beschikbaarheid in de ondernemings- en transportnetwerken. Ongeveer 80% van de niet-beschikbaarheid komt voor vanwege problemen zoals het niet detecteren van fouten, fouten bij verandering en prestatiekwesties.
Organisaties zullen bij het bepalen van het beschikbare budget gewoonweg niet viermaal zo veel andere theoretische niet-beschikbaarheid willen gebruiken, maar het bewijs suggereert consequent dat dit in veel omgevingen het geval is. In het volgende hoofdstuk wordt dit aspect van de niet-beschikbaarheid grondiger behandeld.
Aangezien u theoretisch niet kunt de hoeveelheid onbeschikbaarheid berekenen vanwege gebruikersfouten en -proces, raden we u aan deze optie uit het beschikbare budget te verwijderen en de organisaties naar perfectie te streven. Het enige voorbehoud is dat organisaties het huidige risico voor beschikbaarheid in hun eigen processen en niveaus van expertise moeten begrijpen. Zodra u deze risico's en remmers beter begrijpt, kunnen netwerkplanners als gevolg van deze problemen een bepaalde hoeveelheid niet-beschikbaarheid willen afmeten. De Cisco NSA HAS-programma onderzoekt deze kwesties en kan organisaties helpen om mogelijke niet-beschikbaarheid te begrijpen door proces-, gebruikersfout of expertiserekwesties.
-
De definitieve beschikbaarheid bepalen
U kunt het algemene beschikbare budget bepalen door de beschikbaarheid voor elk van de eerder gedefinieerde gebieden te vermenigvuldigen. Dit gebeurt doorgaans voor homogene omgevingen waar de connectiviteit tussen twee punten vergelijkbaar is, zoals een hiërarchische modulaire LAN-omgeving of een hiërarchische standaard WAN-omgeving.
In dit voorbeeld, wordt het beschikbaarheidsbudget gedaan voor een hiërarchisch modulair LAN milieu. De omgeving maakt gebruik van back-upgeneratoren en UPS-systemen voor alle netwerkonderdelen en beheert de voeding op de juiste manier. De organisatie gebruikt VoIP niet en wenst geen rekening te houden met de overschakeltijd van de software. De schattingen zijn:
-
Beschikbaarheid hardwarepad tussen twee eindpunten = 99,99% beschikbaarheid
-
Beschikbaarheid software door gebruik van GD software betrouwbaarheid als referentie = 99,999% beschikbaarheid
-
Beschikbaarheid van milieu- en stroombronnen met reservesystemen = 99,999% beschikbaarheid
-
Link-storing in LAN-omgeving = 99.999% beschikbaarheid
-
Systeemswitchingtijd niet meegerekend = 100% beschikbaarheid
-
Gebruiker fout en beschikbaarheid proces verondersteld perfect = 100% beschikbaarheid
Het definitieve budget voor beschikbaarheid dat de organisaties voor gelijke kansen moeten nastreven is 0,9999 X 0,99999 X 0,99999 X 0,999999 = 0,999896, of 99,9896% beschikbaarheid. Als we een factor zijn in mogelijke niet-beschikbaarheid door gebruiker- of procesfouten en aannemen dat niet-beschikbaarheid 4X beschikbaarheid is door technische factoren, kunnen we aannemen dat het beschikbare budget 99,95% is.
Deze voorbeeldanalyse laat dan zien dat de LAN beschikbaarheid gemiddeld tussen 99.95 en 99.989% zou dalen. Deze getallen kunnen nu worden gebruikt als doelstelling voor het serviceniveau voor de netwerkorganisatie. U kunt een additionele waarde verkrijgen door de beschikbaarheid in het systeem te meten en te bepalen welk percentage van de niet-beschikbaarheid het gevolg was van elk van de bovengenoemde zes gebieden. Dit stelt de organisatie in staat om verkopers, vervoerders, processen en personeel naar behoren te evalueren. Het aantal kan ook worden gebruikt om verwachtingen binnen het bedrijf te bepalen. Als het aantal onacceptabel is, dan worden extra middelen uitgetrokken om het gewenste niveau te bereiken.
Het kan nuttig zijn voor netwerkbeheerders om de hoeveelheid downtime op een bepaald beschikbaarheidsniveau te begrijpen. De hoeveelheid downtime in minuten voor een periode van één jaar, gegeven het beschikbare niveau, is:
Notulen van de onderbreking in één jaar = 525600 - (Beschikbaarheidsniveau X 5256)
Als je 99,95% van de beschikbare tijd gebruikt, zal dit blijken gelijk te zijn aan 525600 - (99,95 X 5256) of 262,8 minuten van downtime. Voor de bovengenoemde definitie van beschikbaarheid is dit gelijk aan de gemiddelde hoeveelheid downtime voor alle verbindingen in dienst binnen het netwerk.
-
Stap 3: Toepassingsprofielen maken
Toepassingsprofielen helpen de netwerkorganisatie de eisen voor het niveau van netwerkservice voor afzonderlijke toepassingen te begrijpen en definiëren. Dit helpt ervoor te zorgen dat het netwerk individuele toepassingsvereisten en netwerkdiensten in het algemeen ondersteunt. Toepassingsprofielen kunnen ook dienen als een gedocumenteerde basislijn voor netwerkservice wanneer de toepassing of servergroepen naar het netwerk wijzen als het probleem. Uiteindelijk helpen toepassingsprofielen om netwerkservicedoelstellingen aan te passen aan toepassing- of bedrijfsvereisten door toepassingsvereisten zoals prestaties en beschikbaarheid te vergelijken met realistische netwerkservicedoelstellingen of huidige beperkingen. Dit is niet alleen belangrijk voor het beheer van het serviceniveau, maar ook voor het algemene top-down netwerkontwerp.
Maak toepassingsprofielen wanneer u nieuwe toepassingen in het netwerk invoert. Mogelijk hebt u een overeenkomst nodig tussen de IT-toepassingsgroep, serverbeheergroepen en netwerknetwerken om de creatie van toepassingsprofielen voor nieuwe en bestaande services te helpen uitvoeren. Complete toepassingsprofielen voor bedrijfstoepassingen en systeemtoepassingen. De zakelijke toepassingen kunnen e-mail, bestandsoverdracht, Web browsing, medische beeldvorming of productie omvatten. De systeemtoepassingen kunnen softwaredistributie, gebruikersverificatie, netwerkback-up en netwerkbeheer omvatten.
Een netwerkanalist en een toepassing voor toepassing of serverondersteuning moeten het toepassingsprofiel maken. Voor nieuwe toepassingen kan het nodig zijn een protocol-analyzer en WAN-emulator met vertraging te gebruiken om de toepassingsvereisten correct te karakteriseren. Dit helpt de gewenste bandbreedte te identificeren, maximale vertraging voor applicatie bruikbaarheid en jittervereisten. Dit kan worden gedaan in een labomgeving zolang u de benodigde servers hebt. In andere gevallen, zoals met VoIP, worden de netwerkvereisten waaronder jitter, vertraging, en bandbreedte goed gepubliceerd en laboratoriumtesten zijn niet nodig. Een aanvraagprofiel dient de volgende punten te bevatten:
-
Toepassingsnaam
-
Type toepassing
-
Nieuwe toepassing?
-
Bedrijfsbelang
-
Beschikbaarheidsvereisten
-
Gebruikte protocollen en poorten
-
Geschatte gebruikersbandbreedte (kbps)
-
Aantal en plaats van de gebruikers
-
Vereisten voor bestandsoverdracht (inclusief tijd, volume en endpoints)
-
Invloed op netwerkuitval
-
Vertraging, documentatie en beschikbaarheid
Het doel van het toepassingsprofiel is om bedrijfsvereisten voor de toepassing, bedrijfs kritiek, en netwerkvereisten zoals bandbreedte, vertraging, en jitter te begrijpen. Bovendien zou de netwerkorganisatie het effect van netwerkdowntime moeten begrijpen. In sommige gevallen moet u de toepassing opnieuw starten of de server opnieuw starten, wat aanzienlijk bijdraagt aan de algemene downtime van de toepassing. Wanneer u het toepassingsprofiel voltooit, kunt u algemene netwerkmogelijkheden vergelijken en helpen om netwerkserviceniveaus aan te passen aan bedrijfs- en toepassingsvereisten.
Stap 4: Beschikbaarheid en prestatienormen definiëren
Beschikbaarheid- en prestatienormen stellen de serviceverwachtingen voor de organisatie in. Deze kunnen worden gedefinieerd voor verschillende gebieden van het netwerk of specifieke toepassingen. Prestaties kunnen ook worden gedefinieerd in termen van vertraging, jitter, maximale doorvoersnelheid, bandbreedteverplichtingen en algemene schaalbaarheid. Naast het vaststellen van de serviceverwachtingen dient de organisatie er ook voor te zorgen dat elk van de servicenormen wordt gedefinieerd, zodat gebruikers en IT-groepen die met netwerken werken de servicestandaard volledig begrijpen en hoe deze zich verhoudt tot hun applicatie- of serverbeheervereisten. Gebruikers- en IT-groepen moeten ook begrijpen hoe de servicenorm gemeten kan worden.
Resultaten van eerdere stappen in de definitie van het serviceniveau helpen de standaard te maken. Op dit punt moet de netwerkorganisatie een duidelijk begrip hebben van de huidige risico's en beperkingen in het netwerk, een begrip van toepassingsgedrag en een theoretische beschikbaarheidsanalyse of beschikbaarheidsbasislijn.
-
Bepaal de geografische of toepassingsgebieden waar servicenormen zullen worden toegepast.
Dit kan gebieden zoals het campus LAN, binnenlands WAN, extranet of partnerconnectiviteit omvatten. In sommige gevallen kan de organisatie verschillende serviceniveaus hebben binnen één gebied. Dit gebeurt niet ongewoon voor ondernemingen of organisaties van dienstverleners. In deze gevallen zou het niet ongebruikelijk zijn om op basis van individuele dienstverleningsvereisten verschillende dienstverleningsnormen te hanteren. Deze normen kunnen worden ingedeeld als goud-, zilver- en bronzen servicenormen binnen één geografisch gebied of in een servicegebied.
-
Defineert de servicestandaardparameters.
Beschikbaarheid en retourvertraging zijn de meest gebruikelijke netwerkservicenormen. Max. doorvoersnelheid, minimale bandbreedte-inspanning, scherpte, acceptabele foutsnelheden en schaalbaarheidsmogelijkheden kunnen ook indien nodig worden meegeleverd. Let op bij het beoordelen van de onderhoudsparameter voor meetmethoden. Of de parameter zich al dan niet naar een SLA beweegt, de organisatie zou moeten nadenken over hoe de service parameter kan worden gemeten of gerechtvaardigd wanneer er problemen zijn of wanneer er serviceverschillen zijn.
Nadat u de servicegebieden en serviceparameters hebt gedefinieerd, gebruikt u de informatie uit eerdere stappen om een matrix van servicenormen te maken. De organisatie zal ook gebieden moeten definiëren die verwarrend kunnen zijn voor gebruikers en IT-groepen. De maximale responsietijd is bijvoorbeeld heel anders voor een retourvlucht dan voor het indrukken van de ENTER-toets op een afgelegen locatie voor een specifieke toepassing. In de volgende tabel worden de prestatiedoelstellingen in de Verenigde Staten weergegeven.
| Netwerkgebied | Beschikbaarheidsdoel | Meetmethode | Doelstelling gemiddelde netwerkresponstijd | Max. responstijd geaccepteerd | Meetmethode voor responsietijd |
|---|---|---|---|---|---|
| LAN | 99.99% | Ingesloten gebruikersminuten | Minder dan 5 ms | 10 ms | Reactie tijdens een retourvlucht |
| WAN | 99.99% | Ingesloten gebruikersminuten | Minder dan 100 ms (retourvluchten) | 150 ms | Reactie tijdens een retourvlucht |
| Kritisch WAN en extranet | 99.99% | Ingesloten gebruikersminuten | Minder dan 100 ms (retourvluchten) | 150 ms | Reactie tijdens een retourvlucht |
Stap 5: Netwerkservice definiëren
Dit is de laatste stap in de richting van het beheer van basisserviceniveaus; het definieert de reactieve en proactieve processen en netwerkbeheermogelijkheden die u toepast om de doelstellingen van het serviceniveau te bereiken . Het definitieve document wordt gewoonlijk een plan voor operationele ondersteuning genoemd. De meeste steunplannen voor toepassingen bevatten alleen reactieve ondersteuningsvereisten. In omgevingen met een hoge beschikbaarheid moet de organisatie ook rekening houden met proactieve beheerprocessen die gebruikt zullen worden om netwerkproblemen te isoleren en op te lossen voordat de gebruikersservice oproepen gestart worden. In het algemeen moet het definitieve document:
-
Beschrijf het reactieve en proactieve proces dat wordt gebruikt om het doel van het serviceniveau te bereiken
-
Hoe het dienstenproces wordt beheerd
-
Hoe het servicedoel en het servicetechnisch proces worden gemeten.
Dit deel bevat voorbeelden voor reactieve dienstendefinities en pro-actieve dienstendefinities die voor veel dienstverleners en bedrijfsorganisaties in aanmerking moeten worden genomen. Het doel bij het opbouwen van de definities van serviceniveaus is het creëren van een dienst die aan de beschikbaarheid en de prestatiedoelen zal voldoen. Om dit te bereiken moet de organisatie de service bouwen met de huidige technische beperkingen, het beschikbare budget en toepassingsprofielen in gedachten. In het bijzonder zou de organisatie een dienst moeten definiëren en bouwen die constant en snel problemen identificeert en oplost binnen tijden die door het beschikbaarheidsmodel worden toegewezen. De organisatie moet ook een service definiëren die snel potentiële servicekwesties kan identificeren en oplossen die de beschikbaarheid en prestaties beïnvloeden als ze worden genegeerd.
U haalt het gewenste serviceniveau niet 's nachts. Tekortkomingen zoals lage expertise, huidige procesbeperkingen of ontoereikende personeelsniveaus kunnen de organisatie ervan weerhouden de gewenste standaarden of doelstellingen te bereiken, zelfs na de vorige stappen in het kader van de dienstenanalyse. Er is geen nauwkeurige methode om het vereiste serviceniveau exact aan de gewenste doelen te laten beantwoorden. Om hieraan tegemoet te komen moet de organisatie de servicenormen meten en de dienstparameters meten die worden gebruikt om de dienstverleningsnormen te ondersteunen. Als de organisatie niet voldoet aan de servicedoelen, moet ze dan naar servicemetrieken kijken om het probleem te begrijpen. In veel gevallen kunnen begrotingsverhogingen worden doorgevoerd om de ondersteunende diensten te verbeteren en verbeteringen aan te brengen die nodig zijn om de gewenste dienstendoelstellingen te verwezenlijken. In de loop der tijd kan de organisatie verschillende aanpassingen doorvoeren, hetzij aan het servicedoel, hetzij aan de servicedefinitie, om netwerkservices en bedrijfsvereisten op elkaar af te stemmen.
Een organisatie zou bijvoorbeeld 99 procent beschikbaarheid kunnen bereiken toen het doel veel hoger was met 99,9 procent beschikbaarheid. Wanneer vertegenwoordigers van de organisatie naar service- en ondersteuningsparameters keken, ontdekten ze dat de vervanging van hardware ongeveer 24 uur duurde, veel langer dan de oorspronkelijke schatting, omdat de organisatie slechts vier uur had begroot. Bovendien stelde de organisatie vast dat proactieve beheercapaciteiten werden genegeerd en dat overbodige netwerkapparaten niet werden gerepareerd. Ze ontdekten ook dat ze niet over het personeel beschikten om verbeteringen aan te brengen. Als resultaat hiervan heeft de organisatie, na te hebben overwogen de huidige servicedoelstellingen te verlagen, begroot voor extra middelen die nodig waren om het gewenste serviceniveau te bereiken.
Dienstdefinities dienen zowel reactieve ondersteuningsdefinities als proactieve definities te omvatten. Reactieve definities definiëren hoe de organisatie op problemen zal reageren nadat deze zijn geïdentificeerd aan de hand van gebruikersklachten of netwerkbeheermogelijkheden. Proactieve definities beschrijven hoe de organisatie potentiële netwerkproblemen zal identificeren en oplossen, inclusief reparatie van kapotte "standby"-netwerkcomponenten, foutmelding en capaciteitsdrempels en upgrades. De volgende paragrafen geven voorbeelden van zowel reactieve als proactieve definities van serviceniveaus.
Definities op serviceniveau
De volgende gebieden op serviceniveau worden doorgaans gemeten met behulp van helpdesk-databases en periodieke audits. Deze tabel geeft een voorbeeld van de ernst van problemen voor een organisatie. Merk op dat de grafiek niet omvat hoe te om verzoeken voor nieuwe dienst te behandelen, die door een SLA of extra toepassing profileren en prestaties wat-als analyse kunnen worden verwerkt. Doorgaans is ernst 5 een verzoek om nieuwe service indien deze via hetzelfde ondersteuningsproces wordt verwerkt.
| Ernst 1 | Ernst 2 | Ernst 3 | Ernst 4 |
|---|---|---|---|
| Ernstige zakelijke impact LAN-gebruiker of serversegment onderaan de kritische WAN-site | een hoog bedrijfseffect door verlies of aantasting, mogelijk werk rondom de plaats van Campus LAN-down; 5-99 gebruikers beïnvloed Binnenlandse WAN-site door internationale WAN-site naar beneden Kritische prestatieklaring | Sommige specifieke netwerkfunctionaliteit is verloren of aangetast, zoals het verlies van redundantie Campus LAN-prestaties die zijn beïnvloed door LAN-redundantie | Een functionele query of fout die geen zakelijke impact heeft voor de organisatie |
Wanneer de ernst van het probleem is gedefinieerd, definieer of onderzoek het ondersteuningsproces om de definities van de servicerespons te maken. In het algemeen vereisen de definities van serviceresresponsen een gelaagde ondersteuningsstructuur, gekoppeld aan een helpdesk software-ondersteuningssysteem om problemen op te sporen door middel van probleemtickets. Metriek moet ook beschikbaar zijn op de responsietijd en de resolutie-tijd voor elke prioriteit, het aantal oproepen per prioriteit en de kwaliteit van de respons/resolutie. Om het ondersteuningsproces te definiëren, helpt het de doelstellingen van elke steunlaag in de organisatie en hun rol en verantwoordelijkheden te definiëren. Dit helpt de organisatie de behoeften aan middelen en de niveaus van deskundigheid voor elk ondersteuningsniveau te begrijpen. De volgende tabel geeft een voorbeeld van een organisatie die ondersteuning op verschillende niveaus biedt en richtlijnen voor probleemoplossing geeft.
| Ondersteuningsniveau | Verantwoordelijkheid | Doelstellingen |
|---|---|---|
| Ondersteuning van Tier 1 | Ondersteuning van helpdesk voor volledige beantwoording en ondersteuning voor beantwoording, plaatsen probleemkaartjes, werk aan probleem tot 15 minuten, documentticket en escalatie naar de juiste niveau 2 ondersteuning | Resolutie van 40% van de inkomende oproepen |
| Ondersteuning van niveau 2 | Controle van wachtrijen, netwerkbeheer, bewaking van stations Plaats probleemkaartjes voor softwaregeïdentificeerde problemen Uitvoeren Neem gesprekken van niveau 1, verkoper en stap 3 escalatie Aannemen van eigendom van de oproep tot oplossing | Resolutie van 100% van de oproepen op niveau 2 |
| Ondersteuning van Tier 3 | Voor alle prioriteitsproblemen van prioriteit 1 moet onmiddellijke steun aan lijst 2 worden verleend. | Geen rechtstreeks probleemeigendomsrecht |
De volgende stap is het maken van de matrix voor de service respons en de service resolutie-definitie. Dit stelt doelen vast voor hoe snel problemen worden opgelost, waaronder hardwarevervanging. Het is belangrijk om doelen op dit gebied te stellen omdat de tijd van de servicerespons en de hersteltijd direct van invloed zijn op de beschikbaarheid van het netwerk. De termijnen voor het oplossen van problemen moeten ook worden afgestemd op de beschikbare begroting. Als grote aantallen ernstige problemen niet in het beschikbaarheidsbudget zijn opgenomen, kan de organisatie dan werken om de bron van deze problemen en een mogelijke oplossing te begrijpen. Zie de volgende tabel:
| Ernst van probleem | Respons Help-bureaublad | Reactie op niveau 2 | Onsite Tier 2 | Hardware vervanging | Probleemoplossing |
|---|---|---|---|---|---|
| 1 | Directe escalatie tot niveau 2, netwerkoperationele beheerder | 5 minuten | 2 uur | 2 uur | 4 uur |
| 2 | Directe escalatie tot niveau 2, netwerkoperationele beheerder | 5 minuten | 4 uur | 4 uur | 8 uur |
| 3 | 15 minuten | 2 uur | 12 uur | 24 uur | 36 uur |
| 4 | 15 minuten | 4 uur | 3 dagen | 3 dagen | 6 dagen |
Maak naast de servicerespons en de serviceresolutie een matrix voor escalatie. De escalatiematrix helpt ervoor te zorgen dat de beschikbare bronnen zijn gericht op problemen die de service ernstig beïnvloeden. Als analisten zich in het algemeen richten op het repareren van problemen, richten ze zich zelden op het aanwenden van extra middelen voor het probleem. Het vaststellen van de termijn voor de kennisgeving van extra middelen draagt bij tot de bewustwording van problemen in het beheer en kan in het algemeen bijdragen tot toekomstige proactieve of preventieve maatregelen. Zie de volgende tabel:
| Verlopen tijd | Ernst 1 | Ernst 2 | Ernst 3 | Ernst 4 |
|---|---|---|---|---|
| 5 minuten | Netwerkoperationele beheerder, steun van niveau 3, directeur netwerk | |||
| 1 uur | Update naar de beheerder van de netwerkactiviteiten, de steun van niveau 3, de directeur netwerk | Update naar de beheerder van de netwerkactiviteiten, de steun van niveau 3, de directeur netwerk | ||
| 2 uur | Escaleren tot VP, bijwerken tot regisseur, bedrijfsleider | |||
| 4 uur | Analyse van de worteloorzaak aan VP, directeur, operationele manager, steun van niveau 3 vereist onopgeloste CEO-kennisgeving | Escaleren tot VP, bijwerken tot regisseur, bedrijfsleider | ||
| 24 uur | Netwerkbeheerder | |||
| 5 dagen | Netwerkbeheerder |
Tot dusverre hebben de definities van serviceniveaus zich toegespitst op de wijze waarop de operationele ondersteunende organisatie reageert op problemen nadat deze zijn geïdentificeerd. Operationele organisaties hebben al jaren operationele steunplannen opgesteld met informatie die vergelijkbaar is met de bovenstaande informatie. Wat in deze gevallen echter ontbreekt, is hoe de organisatie problemen zal identificeren en welke problemen zij zal vaststellen. Verfijndere netwerkorganisaties hebben getracht dit probleem op te lossen door simpelweg doelen te stellen voor het percentage problemen dat proactief wordt geïdentificeerd, in plaats van problemen die reactief worden geïdentificeerd door gebruikersproblemenrapport of klacht.
De volgende tabel laat zien hoe een organisatie proactieve ondersteuningsvermogens en proactieve ondersteuning in het algemeen zou willen meten.
| Netwerkgebied | Verhouding pro-actieve probleemidentificatie | Verhouding reactief probleem |
|---|---|---|
| LAN | 80 % | 20 % |
| WAN | 80 % | 20 % |
Dit is een goede start bij het definiëren van meer pro-actieve steundefinities omdat het eenvoudig en vrij makkelijk meetbaar is, vooral als proactieve gereedschappen automatisch probleemkaartjes genereren. Dit helpt ook netwerkbeheertools/informatie te concentreren op het proactief oplossen van problemen in plaats van te helpen met de basisoorzaak. Het belangrijkste punt van deze methode is echter dat er geen proactieve ondersteuningsvereisten worden gedefinieerd. Dit schept over het algemeen lacunes in de proactieve mogelijkheden voor ondersteuningsbeheer en leidt tot extra beschikbaarheidsrisico's.
Definities op serviceniveau
Een uitgebreidere methodologie voor het creëren van definities van serviceniveaus omvat meer details over hoe het netwerk wordt bewaakt en hoe de operationele organisatie reageert op bepaalde NMS-drempels op een 7 x 24-basis. Dit kan een onmogelijke taak lijken gezien het pure aantal variabelen van de Management Information Base (MIB) en de hoeveelheid beschikbare netwerkbeheerinformatie die relevant is voor de netwerkgezondheid. Het zou ook extreem duur en grondstoffenintensief kunnen zijn. Helaas verhinderen deze bezwaren dat velen een proactieve dienstendefinitie implementeren die van nature eenvoudig, vrij gemakkelijk te volgen zou moeten zijn en alleen van toepassing zou zijn op de grootste beschikbaarheid of prestatierisico's in het netwerk. Als een organisatie dan waarde ziet in basis pro-actieve dienstendefinities, kunnen in de loop der tijd meer variabelen worden toegevoegd zonder significante impact, zolang u een gefaseerde benadering toepast.
Opnemen van het eerste gebied van proactieve dienstendefinities in alle operationele steunplannen. In de definitie van de dienstverlening wordt alleen aangegeven hoe de operatiegroep actief de voorwaarden van het netwerk zal identificeren en erop zal reageren of deze zal koppelen in verschillende gebieden van het netwerk. Zonder deze definitie (of beheerondersteuning) kan de organisatie variabele ondersteuning, onrealistische verwachtingen van gebruikers en uiteindelijk een lagere netwerkbeschikbaarheid verwachten.
De volgende tabel toont hoe een organisatie een servicedefinitie voor link/apparaatvoorwaarden kan maken. Het voorbeeld toont een ondernemersorganisatie die verschillende kennisgevings- en responseisen kan hebben op basis van het tijdstip en het gebied van het netwerk.
| Netwerkapparaat of -link | Detectiemethode | 5 x 8 melding | 7 x 24 melding | 5 x 8 Resolutie | 7 x 24 Resolutie |
|---|---|---|---|---|---|
| Core LAN | SNMP-apparaat en -link, stempels | NOC creëert problemen met uw ticket, pagina LAN-plicht | Automatische pagina LAN-taakpagina's, LAN-taakpersoon creëert een probleemticket voor kern LAN-wachtrij | LAN-analist die binnen 15 minuten door NOC is toegewezen, reparatie volgens de definitie van serviceresources | Prioriteiten 1 en 2 onmiddellijk onderzoek en oplossing Prioriteiten 3 en 4 in de rij voor het oplossen in de ochtend |
| Huiselijk WAN | SNMP-apparaat en -link, stempels | NOC creëert problemen met uw ticket, pagina WAN-taakpagina | Automatische pagina WAN-taakpagina's, WAN-taakpersoon maakt probleemticket voor WAN-wachtrij | WAN-analist die binnen 15 minuten door NOC is toegewezen, reparatie volgens de definitie van serviceresources | Prioriteiten 1 en 2 onmiddellijk onderzoek en oplossing Prioriteiten 3 en 4 in de rij voor het oplossen in de ochtend |
| Extranet | SNMP-apparaat en -link, stempels | NOC creëert problemen, paginapartner | Functionaris van de partner van de auto, de partner van de dienstplicht creëert problemenlot voor de partnerrij | Partneranalist toegewezen binnen 15 minuten door NOC, reparatie volgens de definitie van servicerespons | Prioriteiten 1 en 2 onmiddellijk onderzoek en oplossing; Prioriteiten 3 en 4 in de rij voor een ochtendresolutie |
De resterende proactieve definities van serviceniveaus kunnen in twee categorieën worden onderverdeeld: problemen met netwerkfouten en capaciteit/prestaties. Slechts een klein percentage van de netwerkorganisaties heeft op deze gebieden definities van serviceniveaus. Als gevolg daarvan worden deze kwesties sporadisch genegeerd of behandeld. Dit kan fijn zijn in sommige netwerkomgevingen, maar hoge beschikbaarheid omgevingen zullen over het algemeen consistent pro-actief servicemanagement vereisen.
Netwerkorganisaties hebben de neiging om om verschillende redenen te worstelen met pro-actieve servicedefinities. Dit komt vooral doordat zij geen behoeftenanalyse hebben uitgevoerd voor pro-actieve dienstendefinities op basis van beschikbaarheidsrisico's, de beschikbare begroting en toepassingskwesties. Dit leidt tot onduidelijke vereisten voor pro-actieve dienstendefinities en onduidelijke voordelen, vooral omdat wellicht extra middelen nodig zijn.
De tweede reden is het in evenwicht brengen van de hoeveelheid pro-actief beheer die kan worden bereikt met bestaande of nieuw gedefinieerde middelen. Alleen signaleringen genereren die een ernstige invloed kunnen hebben op de beschikbaarheid of prestaties. U moet ook rekening houden met beheer van de correlatie tussen gebeurtenissen of processen om te verzekeren dat meerdere proactieve problemen geen gegenereerd worden voor hetzelfde probleem. De laatste reden dat organisaties ermee kunnen worstelen is dat het maken van een nieuwe reeks proactieve waarschuwingen vaak een eerste stroom berichten kan genereren die eerder niet zijn gedetecteerd. De operationele groep moet worden voorbereid op deze eerste reeks problemen en extra kortetermijnmiddelen om deze voorheen onopgespoorde omstandigheden op te lossen.
De eerste categorie van pro-actieve definities van serviceniveau is netwerkfouten. Netwerkfouten kunnen verder worden onderverdeeld in systeemfouten, zoals softwarefouten of hardwarefouten, protocolfouten, mediacontrolefouten, nauwkeurigheidsfouten en milieuwaarschuwingen. Het ontwikkelen van een definitie van serviceniveau begint met een algemeen begrip van hoe deze problematische omstandigheden zullen worden gedetecteerd, wie ze zal bekijken en wat er zal gebeuren wanneer ze zich voordoen. Voeg indien nodig specifieke berichten of kwesties toe aan de definitie van serviceniveau. Daarnaast kunt u op de volgende gebieden extra werk nodig hebben om succes te boeken:
-
Niveau 1-, tier 2- en tier 3-ondersteuningsverantwoordelijkheden
-
Het in evenwicht brengen van de prioriteit van de netwerkbeheerinformatie met de hoeveelheid proactief werk die de transactiegroep effectief kan verwerken
-
Trainingsvereisten om ervoor te zorgen dat ondersteunend personeel de gedefinieerde signaleringen effectief kan aanpakken
-
Relay-methodologieën van gebeurtenis om te verzekeren dat er geen meerdere problemen met tickets worden gegenereerd voor dezelfde bron-oorzaak probleem
-
Documentatie over specifieke berichten of signaleringen die helpen bij de identificatie van gebeurtenissen op het niveau van de eerste ondersteuning
De volgende tabel toont een definitie van het serviceniveau van een voorbeeld voor netwerkfouten die een duidelijk begrip biedt van wie verantwoordelijk is voor proactieve netwerkfoutmeldingen, hoe het probleem zal worden geïdentificeerd en wat er zal gebeuren wanneer het probleem zich voordoet. Mogelijk heeft de organisatie nog steeds extra inspanningen nodig zoals hierboven gedefinieerd om succes te garanderen
s.
| Categorie fout | Detectiemethode | Drempel | Handeling |
|---|---|---|---|
| Softwarefouten (crashes die door de software worden gedwongen) | Dagelijkse evaluatie van syslog-berichten met behulp van syslog-kijker Door steun op niveau 2 | Elke voorval bij prioriteit 0, 1 en 2 Meer dan 100 voorvallen van niveau 3 of hoger | Review-probleem, maak problemen met uw ticket en stuur een e-mail als er een nieuw probleem optreedt of als er een probleem is dat de aandacht vereist |
| Hardware fouten (crashes gedwongen door hardware) | Dagelijkse evaluatie van syslog-berichten met behulp van syslog-kijker Door steun op niveau 2 | Elke voorval bij prioriteit 0, 1 en 2 Meer dan 100 voorvallen van niveau 3 of hoger | Review-probleem, maak problemen met uw ticket en stuur een e-mail als er een nieuw probleem optreedt of als er een probleem is dat de aandacht vereist |
| Protocolfouten (alleen IP-routingprotocollen) | Dagelijkse evaluatie van syslog-berichten met behulp van syslog-kijker Door steun op niveau 2 | Tien berichten per dag van de prioriteiten 0, 1 en 2 Meer dan 100 voorvallen van niveau 3 of meer | Review-probleem, maak problemen met uw ticket en stuur een e-mail als er een nieuw probleem optreedt of als er een probleem is dat de aandacht vereist |
| Media Control Fouten (alleen FDDI, POS en Fast Ethernet) | Dagelijkse evaluatie van syslog-berichten met behulp van syslog-kijker Door steun op niveau 2 | Tien berichten per dag van de prioriteiten 0, 1 en 2 Meer dan 100 voorvallen van niveau 3 of meer | Review-probleem, maak problemen met uw ticket en stuur een e-mail als er een nieuw probleem optreedt of als er een probleem is dat de aandacht vereist |
| Milieuberichten (vermogen en temp) | Dagelijkse evaluatie van syslog-berichten met behulp van syslog-kijker Door steun op niveau 2 | Enig bericht | Problemen oplossen en verzenden voor nieuwe problemen |
| Nauwkeurige fouten (link invoerfouten) | SNMP-stemming met tussenpozen van 5 minuten Drempelgebeurtenissen ontvangen door NOC | Invoerfouten of uitvoerfouten Eén fout in een interval van 5 minuten op een willekeurige link | Problemen oplossen voor nieuwe problemen en verzenden naar niveau 2-ondersteuning |
De andere categorie van proactieve dienstenniveaus is van toepassing op prestaties en capaciteit. Echte prestaties en capaciteitsbeheer omvatten het beheer van uitzonderingen, het baselineren en trending, en wat-als analyse. De definitie van serviceniveaus definieert slechts de niveaus van prestatie en capaciteit en de gemiddelde drempels die een onderzoek of een upgrade zullen starten. Deze drempelwaarden kunnen dan op één of andere manier op alle drie de processen voor prestatie- en capaciteitsbeheer van toepassing zijn.
De definities van capaciteit en prestatieniveau kunnen in verschillende categorieën worden onderverdeeld: netwerkverbindingen, netwerkapparaten, end-to-end prestaties en toepassingsprestaties. Het ontwikkelen van definities van serviceniveaus op deze gebieden vereist diepgaande technische kennis met betrekking tot specifieke aspecten van de capaciteit van apparatuur, mediacapaciteit, QoS-kenmerken en toepassingsvereisten. Om deze reden bevelen we netwerkarchitecten aan om prestatiekracht en capaciteitsgerelateerde serviceniveaus te ontwikkelen met een input van leveranciers.
Net als netwerkfouten begint het ontwikkelen van een serviceniveau-definitie voor capaciteit en prestaties met een algemeen begrip van hoe deze problematische omstandigheden gedetecteerd zullen worden, wie er naar ze zal kijken en wat er zal gebeuren als ze zich voordoen. U kunt indien nodig specifieke eventdefinities aan de definitie van het serviceniveau toevoegen. Daarnaast kunt u op de volgende gebieden extra werk nodig hebben om succes te boeken:
-
Een duidelijk inzicht in de prestatie-eisen van de toepassing
-
grondig technisch onderzoek naar de drempelwaarden die voor de organisatie zinvol zijn, op basis van bedrijfsvereisten en totale kosten
-
Begrotingscyclus en eisen voor het opwaarderen van de cyclus
-
Niveau 1-, tier 2- en tier 3-ondersteuningsverantwoordelijkheden
-
Prioriteit en kritiek van de netwerkbeheerinformatie, afgewogen tegen de hoeveelheid proactief werk die de operationele groep effectief kan verwerken
-
Trainingseisen om ervoor te zorgen dat ondersteunend personeel de berichten of signaleringen begrijpt en doeltreffend kan omgaan met de vastgestelde voorwaarde
-
Methoden voor correlatie van gebeurtenissen of processen om te verzekeren dat er geen meerdere problemen worden gegenereerd voor dezelfde oorzaak probleem
-
Documentatie over specifieke berichten of signaleringen die helpen bij de identificatie van gebeurtenissen op het niveau van de eerste ondersteuning
De volgende tabel toont een definitie van het serviceniveau van een voorbeeld voor gebruik van een link die een duidelijk begrip biedt van wie verantwoordelijk is voor proactieve netwerkfoutmeldingen, hoe het probleem zal worden geïdentificeerd en wat er zal gebeuren wanneer het probleem zich voordoet. De organisatie heeft misschien nog meer inspanningen nodig zoals hierboven gedefinieerd om succes te garanderen.
| Netwerkgebied/media | Detectiemethode | Drempel | Handeling |
|---|---|---|---|
| Campus LAN-backbone en distributielinks | SNMP-opiniepeiling met intervallen van 5 minuten RMON - uitzonderingen op kern- en distributieketens | 50% van het gebruik in intervallen van 5 minuten 90% van het gebruik via een uitzondering-val | Bericht per e-mail aan prestatiegerichte e-mail-alias-groep om de QoS-eis te evalueren of een upgrade te plannen voor terugkerende kwesties |
| Binnenlandse WAN-links | SNMP-stemming met tussenpozen van 5 minuten | 75% gebruik met intervallen van 5 minuten | Bericht per e-mail aan prestatiegerichte e-mail-alias-groep om de QoS-eis te evalueren of een upgrade te plannen voor terugkerende kwesties |
| Extranet WAN-links | SNMP-stemming met tussenpozen van 5 minuten | 60% gebruik met intervallen van 5 minuten | Bericht per e-mail aan prestatiegerichte e-mail-alias-groep om de QoS-eis te evalueren of een upgrade te plannen voor terugkerende kwesties |
In de volgende tabel worden de definities van serviceniveaus voor de capaciteit van de apparatuur en de prestatiedrempels gedefinieerd. Zorg ervoor dat u drempels maakt die betekenisvol en nuttig zijn in het voorkomen van netwerkproblemen of beschikbaarheidskwesties. Dit is een zeer belangrijk gebied omdat de niet-gecontroleerde kwesties van het controlevliegtuig van apparaten ernstige netwerkimpact kunnen hebben.
| Cisco 7500 router | CPU, geheugen, buffers | SNMP-stemming met tussenpozen van 5 minuten RMON-kennisgeving voor CPU | CPU met tussenpozen van 5 minuten, 99% via RMON - waarschuwing Geheugen met tussenpozen van 50% tijdens intervallen van 5 minuten bij gebruik van 99% | Bericht per e-mail naar prestaties en capaciteit e-mailalias groep om problemen op te lossen of een upgrade van RMON CPU op 99% te plannen, een probleem-ticket te plaatsen en pagina 2-ondersteuningspagina |
| Cisco 2600-software | CPU, geheugen | SNMP-stemming met tussenpozen van 5 minuten | CPU met intervallen van 5 minuten bij 75% Geheugen met intervallen van 50% gedurende 5 minuten | Bericht per e-mail aan de alias-groep voor prestaties en capaciteit om problemen op te lossen of een upgrade te plannen |
| Catalyst 5000 | Backplane gebruik, geheugen | SNMP-stemming met tussenpozen van 5 minuten | Backplane bij 50% gebruik Geheugen bij 75% gebruik | Bericht per e-mail aan de alias-groep voor prestaties en capaciteit om problemen op te lossen of een upgrade te plannen |
| LightStream® 1010 ATM switch | CPU, geheugen | SNMP-stemming met tussenpozen van 5 minuten | CPU bij 65% gebruik van geheugen bij 50% gebruik | Bericht per e-mail aan de alias-groep voor prestaties en capaciteit om problemen op te lossen of een upgrade te plannen |
In de volgende tabel worden de definities van serviceniveaus voor end-to-end prestaties en capaciteit gedefinieerd. Deze drempels zijn in het algemeen gebaseerd op toepassingsvereisten, maar kunnen ook worden gebruikt om aan te geven dat er sprake is van een soort netwerkprestatie of capaciteitsprobleem. De meeste organisaties met dienstenniveau definities voor prestaties creëren slechts een handvol prestatiedefinities omdat het meten van prestaties van elk punt in het netwerk aan elk ander punt significante middelen vereist en een hoge hoeveelheid netwerk overhead creëert. Deze end-to-end prestatiekwesties kunnen ook gevangen worden in de drempels voor link- of apparaatcapaciteit. We bevelen algemene definities aan per geografisch gebied. Indien nodig kunnen er kritische sites of links worden toegevoegd.
| Netwerkgebied/media | Meetmethode | Drempel | Handeling |
|---|---|---|---|
| Campus LAN | Geen probleem verwacht moeilijk om de gehele LAN-infrastructuur te meten | 10-milliseconden-responstijd voor retourvluchten of minder op elk moment | Bericht per e-mail aan de alias-groep voor prestaties en capaciteit om problemen op te lossen of een upgrade te plannen |
| Binnenlandse WAN-links | Huidige meting van SF naar NY en SF naar Chicago alleen met behulp van IPM-echo (Internet Performance Monitor) | 75-milliseconden-responstijd voor retourvluchten gemiddeld over een periode van 5 minuten | Bericht per e-mail aan de prestatiegerichte e-mailalias-groep om de QoS-eis te evalueren of een upgrade te plannen voor terugkerende kwesties |
| San Francisco aan Tokyo | Huidige meting van San Francisco naar Brussel met behulp van IPM en ICMP-echo | 250-milliseconden-responsietijd voor retourvluchten gemiddeld over een periode van 5 minuten | Bericht per e-mail aan de prestatiegerichte e-mailalias-groep om de QoS-eis te evalueren of een upgrade te plannen voor terugkerende kwesties |
| San Francisco aan Brussel | Huidige meting van San Francisco naar Brussel met behulp van IPM en ICMP-echo | 175-milliseconden-responsietijd voor retourvluchten gemiddeld over een periode van 5 minuten | Bericht per e-mail aan de prestatiegerichte e-mailalias-groep om de QoS-eis te evalueren of een upgrade te plannen voor terugkerende kwesties |
Het laatste gebied voor de definities van serviceniveaus is voor de prestaties van de toepassingen. De definities van prestatieniveau van toepassingen worden normaal gecreëerd door de applicatie- of serverbeheergroep, omdat de prestaties en capaciteit van de servers zelf waarschijnlijk de grootste factor zijn in de toepassingsprestaties. Netwerkorganisaties kunnen een enorm voordeel realiseren door de definitie van serviceniveau te definiëren voor de prestaties van netwerktoepassingen, omdat:
-
definities en metingen van serviceniveaus kunnen conflicten tussen groepen helpen voorkomen .
-
definities van serviceniveaus voor individuele toepassingen zijn belangrijk indien QoS is ingesteld voor belangrijke toepassingen en ander verkeer als optioneel wordt beschouwd.
Als u ervoor kiest om toepassingsprestaties te creëren en te meten, is het waarschijnlijk best als u geen prestaties aan de server zelf meet. Dit helpt dan onderscheid te maken tussen netwerkproblemen en toepassing- of serverproblemen. Gebruik sondes voor de software voor systeembeschikbaarheid die op Cisco-routers en Cisco IPM wordt uitgevoerd die het pakkettype en de meetfrequentie controleren.
In de volgende tabel is een eenvoudige definitie van serviceniveau voor de prestaties van de toepassing opgenomen.
| Toepassing | Meetmethode | Drempel | Handeling |
|---|---|---|---|
| Enterprise Resource Planning (ERP) Application TCP-poort 1529 Brussel naar SF | Brussel naar San Francisco door gebruik van IPM-meethaven 1529 Ronde-uitgangen Brussel-poort naar SFO-poort 2 | 175-milliseconden-responsietijd voor retourvluchten gemiddeld over een periode van 5 minuten | Bericht per e-mail aan prestatiegerichte e-mailalias-groep om problemen te evalueren of een upgrade te plannen voor terugkerende kwesties |
| ERP-toepassing TCP-poort 1529 Tokyo naar SF | Brussel naar San Francisco door gebruik van IPM-meethaven 1529 Ronde-uitgangen Brussel-poort naar SFO-poort 2 | 200-milliseconden-responsietijd voor retourvluchten gemiddeld over een periode van 5 minuten | Bericht per e-mail aan prestatiegerichte e-mailalias-groep om problemen te evalueren of een upgrade te plannen voor terugkerende kwesties |
| Customer Support Application TCP-poort 1702 Sydney naar SF | Sydney naar San Francisco met behulp van IPM-meetpoort 1702 rotatieprestatie Sydney-gateway naar SFO-poort 1 | 250-milliseconden-responsietijd voor retourvluchten gemiddeld over een periode van 5 minuten | Bericht per e-mail aan prestatiegerichte e-mailalias-groep om problemen te evalueren of een upgrade te plannen voor terugkerende kwesties |
Stap 6: Metriek en monitor verzamelen
definities van serviceniveaus zijn op zich waardeloos tenzij de organisatie meetkunde verzamelt en op succes toegeziet . Bij het creëren van een kritieke definitie van het serviceniveau, definieer hoe het serviceniveau zal worden gemeten en gerapporteerd. Het meten van het serviceniveau bepaalt of de organisatie aan de doelstellingen voldoet en identificeert ook de fundamentele oorzaak van beschikbaarheid of prestatiekwesties. Bedenk ook het doel bij het kiezen van een methode om de definitie van serviceniveau te meten. Zie SLA's maken en onderhouden voor meer informatie.
Het toezicht op de dienstniveaus houdt in dat er een periodieke vergadering wordt gehouden, gewoonlijk elke maand, om de periodieke dienst te bespreken. Bespreek alle parameters en of zij met de doelstellingen in overeenstemming zijn. Als ze zich niet schikken naar de diepere oorzaak van het probleem en verbeteringen doorvoeren. U moet ook de lopende initiatieven en de vooruitgang bij het verbeteren van individuele situaties bespreken.
SLA’s maken en onderhouden
definities van serviceniveaus zijn een uitstekende bouwsteen in die zin dat zij helpen een consistente QoS te creëren in de gehele organisatie en de beschikbaarheid te verbeteren. De volgende stap is SLA's, die een verbetering zijn omdat zij de bedrijfsdoelstellingen en kostenvereisten direct op de servicekwaliteit afstemmen. De goed geconstrueerde SLA dient dan als model voor efficiëntie, kwaliteit en synergie tussen de gebruikersgemeenschap en de steungroep door duidelijke processen en procedures voor netwerkproblemen of -problemen te handhaven.
SLA’s bieden verschillende voordelen:
-
SLA's zetten bidirectionele verantwoordelijkheid op voor de service, wat betekent dat gebruikers en toepassingsgroepen ook verantwoordelijk zijn voor de netwerkservice. Als ze geen SLA maken voor een specifieke service en zakelijke impact communiceren met de netwerkgroep, dan kunnen ze eigenlijk verantwoordelijk zijn voor het probleem.
-
SLA's helpen de standaardgereedschappen en hulpmiddelen te bepalen die nodig zijn om aan de zakelijke vereisten te voldoen. Het beslissen hoeveel mensen en welke instrumenten zonder SLA's moeten worden gebruikt is vaak een begrotingsraming. De dienstverlening kan worden overopgezet, wat leidt tot overmatige bestedingen of een gebrek aan opzet, wat leidt tot onvervulde bedrijfsdoelstellingen. Een afstemming van de SLA's helpt om dat evenwichtige optimale niveau te bereiken.
-
De gedocumenteerde SLA creëert een duidelijker instrument voor het bepalen van de verwachtingen ten aanzien van het serviceniveau.
Wij bevelen de volgende stappen aan voor het bouwen van SLA's nadat de definities van serviceniveaus zijn opgesteld: Wij bevelen de volgende stappen aan voor het bouwen van SLA's nadat de definities van serviceniveaus zijn opgesteld:
7. Voldoen aan de voorwaarden voor SLA's.
8. Bepaal de bij de SLA betrokken partijen.
10. Ga in op de zakelijke behoeften en doelstellingen van klanten
11. Bepaal de SLA die voor elke groep vereist is.
12. Kies het formaat van de SLA
13. Werkgroepen SLA ontwikkelen
14. Houd werkgroepvergaderingen en ontwerp de SLA.
16. Meten en bewaken de conformiteit van de SLA.
Stap 7: Voldoen aan voorwaarden voor SLA’s
Deskundigen in de ontwikkeling van IT-SLA hebben drie voorwaarden voor een succesvolle SLA vastgesteld. Helaas kunnen organisaties die deze doelstellingen niet halen problemen verwachten met het SLA-proces en moeten zij rekening houden met de mogelijke problemen die het SLA-proces met zich meebrengt. Het niet implementeren van SLA's is niet schadelijk als de netwerkorganisatie dienstenniveau definities kan bouwen die aan algemene zakelijke vereisten voldoen. De volgende voorwaarden zijn een voorwaarde voor het SLA-proces:
-
Je bedrijf moet een service-georiënteerde cultuur hebben.
De organisatie moet eerst de behoeften van de klanten plaatsen. U hebt een prioriteitsverplichting van bovenaf nodig voor de service, resulterend in een compleet begrip van de behoeften en percepties van de klant. Gedraag klanttevredenheidsenquêtes en door klanten aangestuurde diensteninitiatieven.
Een andere indicator van de dienstverlening kan zijn dat de organisatiestaten als bedrijfsdoel tevredenheid onderhouden of ondersteunen. Dit is niet ongewoon omdat IT-organisaties nu kritisch zijn verbonden met het succes van de organisatie in haar geheel.
De servicecultuur is belangrijk omdat het SLA-proces fundamenteel gericht is op het maken van verbeteringen op basis van de behoeften van de klant en zakelijke vereisten. Als organisaties dit in het verleden niet gedaan hebben, zullen ze het SLA-proces moeilijk vinden.
-
De initiatieven van klanten/bedrijven moeten alle IT-activiteiten aansturen.
De bedrijfsvisie- of bedrijfsverklaringen moeten worden afgestemd op de initiatieven van klanten en bedrijven, die vervolgens alle IT-activiteiten, met inbegrip van SLA's, sturen. Te vaak wordt een netwerk opgezet om een bepaald doel te bereiken, maar de netwerkgroep verliest zicht op dat doel en de daaropvolgende zakelijke vereisten. In deze gevallen wordt een vastgesteld budget toegewezen aan het netwerk, dat kan overreageren op de huidige behoeften of de behoefte ernstig onderschatten, wat tot mislukking kan leiden.
Wanneer initiatieven van klanten/bedrijven zijn afgestemd op IT-activiteiten, kan de netwerkorganisatie gemakkelijker worden afgestemd op nieuwe toepassingen, nieuwe diensten of andere zakelijke vereisten. De relatie en de gezamenlijke algemene focus op het bereiken van bedrijfsdoelen zijn aanwezig en alle groepen voeren als team uit.
-
Je moet je engageren aan het SLA proces en contract.
In de eerste plaats moet men zich ertoe verbinden het SLA-proces te leren om effectieve afspraken te maken. Ten tweede moet je voldoen aan de servicevereisten van het contract. Verwacht niet om krachtige SLA's te creëren zonder aanzienlijke input en engagement van alle betrokken individuen. Dit engagement moet ook van de directie komen en van alle personen die bij het SLA-proces betrokken zijn.
Stap 8: Bepaal de bij de SLA betrokken partijen
NetwerkSLA's op ondernemingsniveau zijn sterk afhankelijk van netwerkelementen, elementen voor serverbeheer, helpdesk-ondersteuning, toepassingselementen en zakelijke of gebruikersvereisten. Normaal gesproken zal het beheer van elk gebied betrokken zijn bij het SLA-proces. Dit scenario werkt goed wanneer de organisatie basisreactieve SLAs bouwt. Enterprise-organisaties met vereisten voor een hogere beschikbaarheid hebben tijdens het SLA-proces wellicht technische ondersteuning nodig om te helpen met kwesties als budgettering voor beschikbaarheid, prestatiemaxima, toepassingsprofielen of proactieve beheermogelijkheden. Voor meer pro-actieve beheer SLA aspecten, wij adviseren een technisch team van netwerkarchitecten en toepassingsarchitecten. Technische bijstand kan de beschikbaarheid en de prestatiecapaciteit van het netwerk veel beter op elkaar afstemmen en wat nodig is om specifieke doelstellingen te bereiken.
De SLA's van de dienstverlener omvatten doorgaans geen gebruikersinvoer omdat zij uitsluitend worden gecreëerd om een concurrentievoordeel op andere dienstverleners te behalen. In sommige gevallen zal het hogere management deze SLA's creëren met zeer hoge beschikbaarheid of hoge prestatieniveaus om hun service te bevorderen en interne doelen voor interne werknemers te bieden. Andere dienstverleners zullen zich concentreren op de technische aspecten van het verbeteren van de beschikbaarheid door sterke definities van serviceniveaus op te stellen die intern worden gemeten en beheerd. In andere gevallen vinden beide inspanningen gelijktijdig plaats, maar niet noodzakelijk samen of met dezelfde doelen.
De keuze van de bij de SLA betrokken partijen moet dan gebaseerd zijn op de doelstellingen van de SLA. Enkele mogelijke doelstellingen zijn:
-
Doelstellingen voor reactieve ondersteuning
-
Het hoogste niveau van beschikbaarheid bieden door proactieve SLA's te definiëren
-
Bevordering of verkoop van een dienst
Stap 9: Serviceelementen bepalen
De SLA's voor primaire diensten/ondersteuning zullen doorgaans vele componenten hebben, waaronder het niveau van ondersteuning, hoe deze zal worden gemeten, het escalatiepad voor SLA-verzoening en algemene begrotingsproblemen. Serviceelementen voor omgevingen met een hoge beschikbaarheid dienen proactieve servicemethoden en reactieve doelstellingen te omvatten. De volgende aanvullende gegevens zijn onder meer:
-
Werkuren en procedures voor ondersteuning buiten de werktijd
-
Prioritaire definities, met inbegrip van het type probleem, maximale tijd om met de werkzaamheden aan het probleem te beginnen, maximale tijd om het probleem op te lossen en escalatieprocedures
-
Producten of diensten die moeten worden ondersteund, gerangschikt naar bedrijfskrioriteit
-
Ondersteuning van expertises, verwachtingen op prestatieniveau, statusrapportage en gebruikersverantwoordelijkheden voor probleemoplossing
-
kwesties en vereisten op het niveau van ondersteuning door geografische of bedrijfseenheden
-
Methodiek en procedures voor probleembeheer (call-tracking-systeem)
-
Doelstellingen van het helpdesk
-
Netwerkfoutdetectie en -serviceresereactie
-
Meting van netwerkbeschikbaarheid en rapportage
-
Meting van de netwerkcapaciteit en prestatie-rapportage
-
Procedures voor conflictoplossing
-
Financiering van de uitgevoerde SLA
Netwerkapplicatie- of serviceprovider-SLA’s kunnen extra behoeften hebben op basis van gebruikersgroepvereisten en bedrijfskrioriteit. De netwerkorganisatie moet goed naar deze zakelijke vereisten luisteren en gespecialiseerde oplossingen ontwikkelen die in de algemene ondersteuningsstructuur passen. Het is van cruciaal belang in de algemene ondersteuningscultuur te integreren omdat het belangrijk is geen primaire dienst te creëren die alleen bestemd is voor bepaalde individuen of groepen. In veel gevallen kunnen deze aanvullende vereisten worden ondergebracht in categorieën "oplossing". Een voorbeeld kan een platina, goud en zilver oplossing zijn, gebaseerd op bedrijfsbehoeften. Zie de volgende voorbeelden van SLA - vereisten voor specifieke bedrijfsbehoeften.
Opmerking: De ondersteuningsstructuur, het escalatiepad, de helpdesk-procedures, de meting en prioriteitsdefinities moeten grotendeels hetzelfde blijven om een consistente servicecultuur te onderhouden en te verbeteren.
-
Bandbreedtevereisten en mogelijkheden voor uitbarsting
-
Prestatievereisten
-
QoS-vereisten en -definities
-
Beschikbaarheidsvereisten en redundantie om een matrixprinter voor de oplossing te maken
-
Verplichtingen inzake bewaking en rapportage, methodologie en procedures
-
Upgradecriteria voor toepassing-/servicemodule
-
Financiering van niet-budgettaire vereisten of van een kruiskostenberekeningsmethode
U kunt bijvoorbeeld oplossingscategorieën maken voor WAN-plaatsconnectiviteit. De platina-oplossing zou worden geleverd met twee T1-diensten naar de locatie. Een andere luchtvaartmaatschappij zou elke T1-lijn leveren. De site zou twee routers hebben geconfigureerd, zodat als er een T1- of routerprobleem is, de site geen storing ervaart. De goudservice zou twee routers hebben, maar Frame Relay zou als back-up worden gebruikt. Deze oplossing kan een beperkte bandbreedte hebben voor de duur van de stroomuitval. De zilveroplossing zou slechts één router en één transportdienst hebben. Al deze oplossingen zouden worden overwogen voor verschillende prioriteitsniveaus voor probleemkaartjes. Sommige organisaties kunnen een platina- of goudoplossing vereisen als voor een defect een prioritair ticket van 1 of 2 nodig is. Klantenorganisaties kunnen dan het door hen gewenste serviceniveau financieren. De volgende tabel toont een voorbeeld van een organisatie die drie serviceniveaus biedt, afhankelijk van de zakelijke behoefte aan extranet.
| Oplossing | platina | goud | Zilver |
|---|---|---|---|
| Apparaten | Redundante routers voor WAN-connectiviteit | Redundant router voor back-up op kernlocatie | Geen redundantie van apparaat |
| WAN | Redundant T1-connectiviteit, meerdere dragers | T1-connectiviteit met back-up van Frame Relay | Geen WAN-redundantie |
| Bandbreedtevereisten en branding | Redundant T1 met taakverdeling voor barsten | Non-load sharing, Frame Relay back-up voor alleen kritieke toepassingen; Frame Relay 64K alleen CIR | Tot T1 |
| Prestaties | Consistente responsietijd van 100 ms of minder | Response time 100 ms of minder verwacht 99,9% | Response time 100 ms of minder verwacht 99% |
| Beschikbaarheidsvereiste | 99.99% | 99.95% | 99.9% |
| Help-desk prioriteit bij omlaag | Prioriteit 1: service die kritiek is | Prioriteit 2: service tegen bedrijfseffecten | Prioriteit 3: onderbreking van zakelijke connectiviteit |
Stap 10: Heb begrip voor de behoeften en doelstellingen van klantbedrijven
Deze stap biedt de SLA-ontwikkelaar veel geloofwaardigheid. Door de behoeften van de verschillende bedrijfsgroepen te begrijpen, zal het eerste SLA-document veel dichter bij de bedrijfsvereisten en het gewenste resultaat komen te liggen. Probeer de kosten van downtime voor de service van de klant te begrijpen. Schatting in termen van verloren productiviteit, inkomsten en goodwill van klanten. Houd in gedachten dat zelfs eenvoudige connecties met een paar mensen inkomsten ernstig kunnen beïnvloeden. In dit geval, help de klant de beschikbaarheid en prestatierisico's te begrijpen die mogelijk kunnen voorkomen, zodat de organisatie het niveau van de service beter begrijpt dat ze nodig heeft. Als je deze stap mist, krijg je veel klanten die gewoon 100 procent beschikbaarheid willen.
De SLA-ontwikkelaar moet ook de bedrijfsdoelstellingen en de groei van de organisatie begrijpen om netwerkupgrades, werkbelasting en budgettering te kunnen realiseren. Het is ook behulpzaam om de toepassingen te begrijpen die zullen worden gebruikt. Hopelijk heeft de organisatie toepassingsprofielen voor elke toepassing, maar als dat niet het geval is, overweegt ze een technische evaluatie van de toepassing om netwerkgerelateerde kwesties te bepalen.
Stap 11: Bepaal de SLA die voor elke groep vereist is
Primaire SLA's voor ondersteuning dienen kritische bedrijfseenheden en functionele groeprepresentatie te omvatten, zoals netwerkbewerkingen, serverbewerkingen en groepen voor toepassingsondersteuning. Deze groepen moeten worden erkend op basis van de bedrijfsbehoeften en hun rol in het steunproces. Een vertegenwoordiging van vele groepen helpt ook een rechtvaardige oplossing voor de totale steun te creëren, zonder individuele voorkeur of prioriteit. Dit kan een ondersteunende organisatie ertoe aanzetten primaire diensten aan individuele groepen te leveren, een scenario dat de algemene dienstencultuur van de organisatie kan ondermijnen. Een klant zou er bijvoorbeeld op kunnen aandringen dat zijn applicatie de meest cruciale is binnen het bedrijf wanneer de kosten van downtime voor die applicatie in werkelijkheid aanzienlijk lager zijn dan andere klanten in termen van verloren gegane inkomsten, verloren productiviteit en verloren goodwill.
Verschillende bedrijfseenheden binnen de organisatie zullen verschillende vereisten hebben. Eén doel van de SLA van het netwerk zou overeenstemming moeten zijn over één algemeen formaat dat verschillende serviceniveaus omvat. Deze vereisten zijn in het algemeen beschikbaarheid, QoS, prestaties en MTTR. In de netwerk SLA, worden deze variabelen verwerkt door aan zakentoepassingen voor mogelijke QoS-tuning voorrang te geven, helpdesk prioriteiten te definiëren voor MTTR van verschillende netwerk-beïnvloedende kwesties, en een oplossing matrix te ontwikkelen die verschillende beschikbaarheid en prestatie-eisen zal helpen aan te pakken. Een voorbeeld van een eenvoudige matrixprinter voor een bedrijf in de fabrieksmatige productie kan er in de volgende tabel uitzien. U kunt informatie toevoegen over beschikbaarheid, QoS en prestaties.
| Business Unit | Toepassingen | Kosten van downtime | Probleemprioriteit bij instellen | Server/netwerkvereisten |
|---|---|---|---|---|
| Industrie | ERP | Hoog | 1 | Hoogste redundantie |
| Klantenondersteuning | Klantenservice | Hoog | 1 | Hoogste redundantie |
| techniek | Bestandsserver, ASIC-ontwerp | Gemiddeld | 2 | LAN-kernredundantie |
| Marketing | Bestandsserver | Gemiddeld | 2 | LAN-kernredundantie |
Stap 12: Kies het formaat van SLA
Het SLA-formaat kan variëren al naar gelang de wensen van de groep of de organisatie. Het volgende is een aanbevolen voorbeeldomlijn voor het netwerk SLA:
-
Doel van de overeenkomst
-
Partijen bij de overeenkomst
-
Doelstellingen en doelstellingen van de overeenkomst
-
-
Ondersteunde diensten en producten
-
Help-desk-service en tracering van oproepen
-
Omschrijving van de ernst van problemen op basis van het effect op het bedrijfsleven voor MTTR - definities
-
Serviceprioriteiten voor QoS-definities voor bedrijven
-
Gedefinieerde oplossingscategorieën op basis van beschikbaarheid- en prestatievereisten
-
Opleidingsvereisten
-
Vereisten inzake capaciteitsplanning
-
Escalatievereisten
-
Rapportage
-
Beschikbare netwerkoplossingen
-
Nieuwe verzoeken om een oplossing
-
Niet-ondersteunde producten of toepassingen
-
-
Bedrijfsbeleid
-
Ondersteuning tijdens werkdagen
-
Definities van ondersteuning na een uur
-
Vakantie
-
Contacttelefoonnummers
-
Werklastprognoses
-
Resolutie over grieven
-
Servicecriteria
-
Gebruikers- en groepsbeveiligingsverantwoordelijkheden
-
-
Procedures voor probleembeheer
-
Gespreksinitiatie (gebruiker en geautomatiseerd)
-
Reactie op het eerste niveau en reparatie
-
Gesprekstracering en registratie
-
Kiezerverantwoordelijkheden
-
Eisen inzake probleemdiagnose en afsluiting van oproepen
-
Probleemdetectie en -servicereactie voor netwerkbeheer
-
Categorieën of definities van probleemoplossing
-
Chronische probleembehandeling
-
Kritisch probleem/uitzondering, gespreksbeheer
-
-
Servicekwaliteitsdoelstellingen
-
Kwaliteitsdefinities
-
Meetdefinities
-
Kwaliteitsdoelstellingen
-
Gemiddelde tijd om probleemoplossing bij voorrang op te lossen
-
Tijd om probleem op te lossen per probleemprioriteit
-
Gemiddelde tijd om hardware door probleemprioriteit te vervangen
-
Beschikbaarheid en prestaties van netwerken
-
Beheerscapaciteit
-
Groei beheren
-
Kwaliteitsrapportage
-
-
Personeel en begroting
-
Personeelsmodellen
-
Operationele begroting
-
-
Onderhoud overeenkomst
-
Conformiteitsbeoordelingsschema
-
Prestatierapportage en -evaluatie
-
Verzoening van rapportageparameters
-
Periodieke SLA updates
-
-
Goedkeuring
-
Attachments en exposities
-
Gespreksstroomdiagrammen
-
Escalatiematrix
-
matrix voor netwerkoplossing
-
Voorbeelden melden
-
Stap 13: SLA-werkgroepen ontwikkelen
De volgende stap is het identificeren van deelnemers aan de SLA-werkgroep, inclusief een groepsleider. De werkgroep kan gebruikers of managers van bedrijfseenheden of functionele groepen of vertegenwoordigers van een geografische basis omvatten. Deze individuen communiceren SLA-kwesties aan hun respectieve werkgroepen. Managers en besluitvormers die het eens kunnen worden over de belangrijkste SLA-elementen moeten deelnemen. Deze personen kunnen zowel leidinggevende als technische personen omvatten die kunnen helpen bij het definiëren van technische kwesties die verband houden met de SLA en besluiten op IT-niveau nemen (d.w.z. helpdesk manager, manager van serveroperaties, toepassingsmanagers en beheerder van netwerkoperaties).
De SLA-werkgroep van het netwerk zou ook moeten bestaan uit brede toepassing en bedrijfsvertegenwoordiging om overeenstemming te bereiken over één netwerk SLA die veel toepassingen en diensten omvat. De werkgroep moet de bevoegdheid hebben om bedrijfskritische processen en diensten voor het netwerk te rangschikken, evenals de beschikbaarheid en prestatie-eisen voor individuele diensten. Deze informatie zal worden gebruikt om prioriteiten te creëren voor verschillende zaken-beïnvloedende probleemtypes, voorrang te geven aan handel-kritisch verkeer op het netwerk en toekomstige standaard voorzien van een netwerk oplossingen te creëren op basis van bedrijfsvereisten.
Stap 14: Werkgroepvergaderingen vasthouden en SLA-ontwerpen
De werkgroep zou in eerste instantie een werkgroephandvest moeten opstellen. Het handvest moet de doelstellingen, initiatieven en tijdlijnen van de SLA tot uitdrukking brengen. Daarna moet de groep specifieke taakplannen ontwikkelen en tijdschema's en tijdschema's vaststellen voor de ontwikkeling en uitvoering van de SLA. De groep moet ook het rapportageproces ontwikkelen voor het meten van het steunniveau aan de hand van steuncriteria. De laatste stap is het creëren van de ontwerp SLA-overeenkomst.
De netwerk SLA-werkgroep zou in eerste instantie eens per week moeten bijeenkomen om de SLA te ontwikkelen. Nadat de SLA is gecreëerd en goedgekeurd, kan de groep maandelijks of zelfs driemaandelijks vergaderen voor SLA - updates.
Stap 15: Onderhandelen met de SLA
De laatste stap in het creëren van de SLA is eindonderhandeling en aftekening. Deze stap omvat:
-
Het ontwerp bekijken
-
Onderhandelingen over de inhoud
-
Het document bewerken en bewerken
-
Definitieve goedkeuring verkrijgen
Deze cyclus van herziening van het ontwerp, onderhandelingen over de inhoud en herzieningen kan meerdere cycli duren voordat de definitieve versie ter goedkeuring aan het management wordt toegezonden.
Vanuit het gezichtspunt van de netwerkbeheerder is het belangrijk te onderhandelen over haalbare resultaten die meetbaar zijn. Probeer prestatiecontracten en beschikbaarheidsovereenkomsten te ondersteunen met die van andere verwante organisaties. Dit kan kwaliteitsdefinities, meetdefinities en kwaliteitsdoelstellingen omvatten. Onthoud dat de extra dienst gelijk is aan extra uitgaven. Zorg ervoor dat gebruikersgroepen begrijpen dat extra serviceniveaus meer kosten en de beslissing laten nemen als dat een kritieke zakelijke vereiste is. U kunt eenvoudig een kostenanalyse uitvoeren op vele aspecten van de SLA zoals de tijd van de hardwarevervanging.
Stap 16: SLA-conformiteit meten en bewaken
Het meten van de SLA-conformiteit en de resultaten van de rapportage zijn belangrijke aspecten van het SLA-proces die bijdragen tot consistentie en resultaten op lange termijn. Wij bevelen in het algemeen aan om alle belangrijke componenten van een SLA meetbaar te maken en een meetmethode in te stellen vóór de SLA-implementatie. Daarna houden maandelijkse vergaderingen tussen gebruikers en ondersteuningsgroepen om de metingen te bekijken, de oorzaken van de problemen te identificeren en oplossingen aan te bevelen om aan de eisen van het serviceniveau te voldoen of deze te overschrijden. Dit helpt het SLA-proces gelijk te maken aan een modern kwaliteitsverbeteringsprogramma.
In het volgende deel wordt nader ingegaan op de wijze waarop het beheer binnen een organisatie zijn SLA's en het algemene beheer van het serviceniveau kan evalueren.
Prestatie-indicatoren voor serviceniveau
De prestatie-indicatoren voor het beheer van serviceniveaus bieden een mechanisme om de serviceniveaus te bewaken en te verbeteren als maatstaf voor succes. Dit stelt de organisatie in staat om sneller te reageren op serviceproblemen en om problemen die van invloed zijn op de service of de kosten van de omlaag in de omgeving beter te begrijpen. Het niet meten van de definities van serviceniveaus betekent ook niet dat er positief pro-actief werk wordt verricht, omdat de organisatie gedwongen is een reactieve houding aan te nemen. Niemand zal zeggen dat de service goed werkt, maar veel gebruikers zullen zeggen dat de service niet aan hun eisen voldoet.
De prestatie-indicatoren voor het beheer van serviceniveaus zijn derhalve een primaire eis voor het beheer van serviceniveaus, omdat zij de middelen bieden om de bestaande serviceniveaus volledig te begrijpen en aanpassingen te maken op basis van de huidige problemen. Dit is de basis voor het bieden van proactieve steun en het verbeteren van de kwaliteit. Als de organisatie fundamentele analyses van de kwesties maakt en kwaliteitsverbeteringen maakt, kan dit dan de beste methodologie zijn om de beschikbaarheid, prestaties en de beschikbare servicekwaliteit te verbeteren.
Neem bijvoorbeeld het volgende reële scenario in overweging. Bedrijf X kreeg talrijke klachten van gebruikers dat het netwerk vaak voor langere tijd was ingekort. Door de beschikbaarheid te meten, vond het bedrijf het belangrijkste probleem een paar WAN-sites. Nauwere onderzoeken van die inzichten toonden aan dat de meeste problemen zich op een paar WAN-sites bevonden. De oorzaak werd gevonden en de organisatie loste het probleem op. De organisatie stelt vervolgens serviceniveaus voor beschikbaarheid in en sluit overeenkomsten met gebruikersgroepen. Toekomstige metingen hebben problemen snel aan het licht gebracht door niet-overeenstemming met de SLA. De netwerkgroep werd vervolgens beschouwd als een groep met hogere professionaliteit, expertise en een overkoepelende troef voor de organisatie. De groep heeft zich van reactief naar proactief in de natuur verplaatst en de onderneming geholpen bij de bedrijfsresultaten.
Helaas hebben de meeste netwerkorganisaties vandaag de dag beperkte definities van serviceniveaus en geen prestatie-indicatoren. Als resultaat hiervan besteden ze het grootste gedeelte van hun tijd aan het reageren op klachten of problemen van gebruikers in plaats van het proactief identificeren van de grondoorzaak en het bouwen van een netwerkservice die aan zakelijke vereisten voldoet.
Gebruik de volgende SLA-prestatie-indicatoren om het succes van het beheersproces op serviceniveau te bepalen:
-
Gedocumenteerde definitie van serviceniveau voor SLA die beschikbaarheid, prestaties, reactieve tijd voor serviceresources, doelstellingen voor probleemoplossing en probleemescalatie omvat
-
Metriek van prestatie-indicatoren, waaronder beschikbaarheid, prestaties, tijd van servicerespons per prioriteit, tijd om op te lossen per prioriteit, en andere meetbare SLA-parameters
-
Maandelijkse netwerkvergaderingen voor vergaderingen op serviceniveau om de naleving van het serviceniveau te toetsen en verbeteringen door te voeren
Gedocumenteerde overeenkomst op serviceniveau of definitie van serviceniveau
De eerste prestatie-indicator is slechts een document waarin de SLA of de serviceniveaus definitie worden uiteengezet. De primaire doelstellingen van de definitie van het serviceniveau dienen de beschikbaarheid en de prestaties te zijn, omdat dit de primaire gebruikersvereisten zijn.
Secundaire doelstellingen zijn belangrijk omdat ze helpen definiëren hoe de beschikbaarheid of prestatieniveaus zullen worden bereikt. Als de organisatie bijvoorbeeld agressieve beschikbaarheid en prestatiedoelen heeft, is het belangrijk om problemen te voorkomen en om problemen snel op te lossen als ze zich voordoen. De secundaire doelstellingen helpen de processen te definiëren die nodig zijn om de gewenste beschikbaarheid en prestatieniveaus te bereiken.
Reactieve secundaire doelen omvatten:
-
Reactieve de antwoordtijd van de dienst door vraag prioriteit
-
Doelstellingen voor probleemoplossing voor MTTR
-
Procedures voor escalatie van problemen.
Proactieve secundaire doelen zijn onder meer:
-
Detectie apparaat of link-down
-
Netwerkfoutdetectie
-
Capaciteit of prestatie probleemdetectie.
De definitie van het serviceniveau voor primaire doelstellingen, beschikbaarheid en prestaties moet omvatten:
Het doel
-
Hoe het doel wordt gemeten
-
Partijen die verantwoordelijk zijn voor het meten van beschikbaarheid en prestaties
-
Partijen verantwoordelijk voor de beschikbaarheid- en prestatiedoelstellingen
-
Niet-conformatieprocessen
Indien mogelijk bevelen wij de voor de meting verantwoordelijke partijen en de voor de resultaten verantwoordelijke partijen aan om een belangenconflict te voorkomen. Van tijd tot tijd kunt het ook nodig zijn de beschikbaarheid van getallen aan te passen vanwege fouten toevoegen/verplaatsen/wijzigen, niet-gedetecteerde fouten of problemen met de beschikbaarheid-meting. De definitie van serviceniveau kan ook een proces omvatten voor het wijzigen van resultaten om de nauwkeurigheid te verbeteren en oneigenlijke aanpassingen te voorkomen. Zie de volgende paragraaf voor methodologieën om de beschikbaarheid en prestaties te meten.
De definitie van serviceniveau voor reactieve secundaire doelstellingen definieert hoe de organisatie zal reageren op netwerkproblemen of IT-brede problemen nadat zij zijn geïdentificeerd, waaronder:
-
Definities van probleemprioriteit
-
Reactieve de antwoordtijd van de dienst door vraag prioriteit
-
Doelstellingen voor probleemoplossing, of MTTR
-
Procedures voor escalatie van problemen
In het algemeen definiëren deze doelstellingen wie te allen tijde verantwoordelijk zal zijn voor de problemen en in welke mate de verantwoordelijken hun huidige taken moeten laten vallen om aan de gedefinieerde problemen te werken. Net als andere definities van serviceniveaus moet in het document op serviceniveau worden beschreven hoe de doelstellingen zullen worden gemeten, welke partijen verantwoordelijk zijn voor metingen en welke niet-conformatieprocessen.
De dienstdefinitie voor proactieve secundaire doelstellingen definieert hoe de organisatie proactieve ondersteuning biedt, inclusief de identificatie van netwerk down, link-down of device-down voorwaarden, netwerk error condities en netwerk capaciteit drempelwaarden. Stel doelen in die pro-actief beheer bevorderen omdat kwaliteitsproactief beheer helpt problemen te elimineren en problemen sneller helpt oplossen. Dit wordt normaal bereikt door een doel vast te stellen van hoeveel pro-actieve zaken gecreëerd en opgelost worden zonder gebruikersbericht. Veel organisaties zetten een vlag op in helpdesk software om pro-actieve gevallen versus reactieve zaken voor dit doel te identificeren. Het document op het niveau van de dienstverlening moet ook informatie bevatten over de wijze waarop het doel zal worden gemeten, de voor de meting verantwoordelijke partijen en de non-conformatieprocessen.
Metriek van prestatieindicator
We adviseren altijd om elk gedefinieerd doel van het serviceniveau meetbaar te maken, wat de organisatie in staat stelt om serviceniveaus te meten, wortel-oorzaak servicekwesties te identificeren die het primaire doel van beschikbaarheid en prestaties remmen, en verbeteringen aan te brengen die gericht zijn op specifieke doelen. Over het geheel genomen zijn metriek slechts een instrument dat netwerkmanagers in staat stelt om de consistentie van het serviceniveau te beheren en verbeteringen aan te brengen overeenkomstig bedrijfsvereisten.
Helaas verzamelen veel organisaties geen beschikbaarheid, prestaties en andere parameters. Organisaties leggen dit vast aan het onvermogen om volledige nauwkeurigheid, kosten, overhead van het netwerk en beschikbare middelen te bieden. Deze factoren kunnen van invloed zijn op het vermogen om serviceniveaus te meten, maar de organisatie moet zich richten op de algemene doelstellingen om serviceniveaus te beheren en te verbeteren. Veel organisaties zijn erin geslaagd om goedkope, goedkope, overheadparameters te creëren die misschien geen volledige nauwkeurigheid bieden, maar wel deze primaire doelen halen.
Het meten van beschikbaarheid en prestaties is één gebied dat vaak verwaarloosd wordt in de maatstaven voor serviceniveau. Organisaties die met deze parameters succesvol zijn, gebruiken twee vrij simpele methoden. Eén methode is om ICMP-pakketten (Internet Control Message Protocol) van een kernlocatie in het netwerk naar randen te verzenden. U kunt ook prestaties verkrijgen met deze methode. Organisaties die met deze methode succesvol zijn, groeperen zich ook als apparaten in "beschikbaarheidsgroepen," zoals LAN apparaten of binnenlandse veldbureaus. Dit is ook aantrekkelijk omdat organisaties meestal verschillende serviceniveaus hebben voor verschillende geografische of bedrijfskritische gebieden van het netwerk. Dit stelt de metrieke groep in staat om alle apparaten met de beschikbaarheidsgroep te gemiddeld om een redelijk resultaat te bereiken.
Een andere methode om de beschikbaarheid te berekenen is het gebruik van probleemtickets en een meting genaamd impactane gebruikersminuten (IUM). Deze methode stelt het aantal gebruikers in dat door een stroomuitval is beïnvloed en vermenigvuldigt het aantal minuten van de stroomuitval. Indien uitgedrukt als een percentage van het totaal aantal minuten in de tijdsperiode, kan dit gemakkelijk worden omgezet in beschikbaarheid. In beide gevallen kan het ook behulpzaam zijn om de diepere oorzaak van de dalingstijd te identificeren en te meten, zodat verbetering makkelijker doelgericht kan worden gemaakt. Categorieën van de oorzaak van wortel omvatten hardwareproblemen, softwareproblemen, link of dragerproblemen, energie- of omgevingsproblemen, tekortkomingen van de verandering, en gebruikersfout.
Duurzame reactieve ondersteuningsdoelstellingen zijn:
-
Reactieve de antwoordtijd van de dienst door vraag prioriteit
-
Doelstellingen voor probleemoplossing, of MTTR
-
Tijd voor probleemescalatie
Meten van reactieve ondersteuningsdoelstellingen door rapporten te genereren uit helpdesk-databases, met inbegrip van de volgende velden:
-
Het tijdstip waarop een oproep oorspronkelijk werd gemeld (of in de database opgenomen)
-
De tijd dat de oproep werd aanvaard door een persoon die aan het probleem werkte
-
De tijd dat het probleem escaleerde
-
Het tijdstip waarop het probleem is opgelost
Deze parameters kunnen invloed op het beheer vereisen om consequent problemen in het gegevensbestand in te voeren en problemen in real time bij te werken. In sommige gevallen kunnen organisaties automatisch probleemtickets genereren voor netwerkevenementen of e-mailverzoeken. Dit helpt nauwkeurigheid te bieden voor het identificeren van de begintijd van een probleem. Rapporten die van dit soort metingen worden gegenereerd zullen gewoonlijk problemen op prioriteit, werkgroep en individu sorteren om potentiële kwesties te helpen bepalen.
Het meten van pro-actieve ondersteuningsprocessen is moeilijker omdat dit van u vereist om pro-actief werk te controleren en een bepaalde meting van de effectiviteit ervan te berekenen. Op dit gebied is weinig werk verricht. Het is echter duidelijk dat slechts een klein percentage mensen netwerkproblemen aan een helpdesk zal melden, en als zij het probleem melden, zal het duidelijk tijd vergen om het probleem uit te leggen of het als netwerkgerelateerd te isoleren. Niet alle proactieve zaken zullen een onmiddellijk effect hebben op de beschikbaarheid en de prestaties, hetzij door het falen van overbodige apparaten of verbindingen, zal dit weinig effect hebben op de eindgebruikers.
Organisaties die pro-actieve definities of overeenkomsten van serviceniveaus ten uitvoer leggen, doen dit op grond van zakelijke vereisten en potentiële beschikbaarheidsrisico's. Vervolgens wordt gemeten in termen van de kwantiteit of het percentage pro-actieve gevallen, in plaats van in reactieve gevallen die door gebruikers worden gegenereerd. Het is een goed idee om ook de hoeveelheid proactieve gevallen op elk gebied te meten. Deze categorieën zouden apparaten omvatten, down verbindingen, netwerkfouten, en capaciteitsschendingen. Er kan ook werk worden verricht met behulp van de beschikbare modellering en de proactieve gevallen om het effect in beschikbaarheid te bepalen dat wordt bereikt door het toepassen van pro-actieve dienstendefinities.
Beoordeling op serviceniveau
Een andere maatstaf voor succes op het gebied van het beheer van serviceniveaus is de toetsing van het beheer van het serviceniveau. Dit moet worden gedaan of er al dan niet sprake is van SLA's. Het serviceniveau management review uitvoeren in een maandelijkse vergadering met personen die verantwoordelijk zijn voor het meten en leveren van gedefinieerde serviceniveaus. Ook gebruikersgroepen kunnen aanwezig zijn als er SLA's bij betrokken zijn. Het doel van de vergadering is dan de prestaties van de gemeten definities van serviceniveaus te evalueren en verbeteringen aan te brengen.
Elke vergadering moet een welomschreven agenda hebben die de volgende elementen omvat:
-
Evaluatie van de gemeten serviceniveaus voor de betrokken periode
-
Evaluatie van initiatieven ter verbetering van de verschillende gebieden
-
Standaardserviceniveau
-
Een discussie over welke verbeteringen er nodig zijn op basis van de huidige set parameters.
In de loop der tijd kan de organisatie ook de naleving van het serviceniveau beïnvloeden om de effectiviteit van de groep te bepalen. Dit proces is niet anders dan een kwaliteitscirkel of een kwaliteitsverbetering. De vergadering helpt individuele problemen op te lossen en oplossingen te bepalen op basis van grondoorzaak.
Samenvatting van beheer op serviceniveau
Kort samengevat staat het beheer van het serviceniveau een organisatie toe om van een reactief ondersteuningsmodel over te stappen op een proactief ondersteuningsmodel waarbij de netwerkbeschikbaarheid en prestatieniveaus worden bepaald door bedrijfsvereisten, niet door de nieuwste reeks problemen. Het proces draagt bij tot het scheppen van een klimaat van voortdurende verbetering van het serviceniveau en een groter concurrentievermogen van de bedrijven. Het beheer op serviceniveau is ook de belangrijkste beheercomponent voor proactief netwerkbeheer. Om deze reden wordt het beheer van serviceniveaus in elke netwerkplannings- en ontwerpfase sterk aanbevolen en moet het starten met elke nieuw gedefinieerde netwerkarchitectuur. Dit stelt de organisatie in staat om de oplossingen de eerste keer correct toe te passen, met de minste hoeveelheid onderbreking of herwerk.
Gerelateerde informatie
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)