Metagegevens gebruiken voor aangepast rapport met API’s en Python
Downloadopties
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
Dit document beschrijft hoe u metagegevens in combinatie met API's kunt gebruiken om op maat rapport in een pythonscript te kunnen uitvoeren.
Voorwaarden
Vereisten
Cisco raadt kennis van de volgende onderwerpen aan:
- CloudCenter
- Python
Gebruikte componenten
Dit document is niet beperkt tot specifieke software- en hardware-versies.
De informatie in dit document is gebaseerd op de apparaten in een specifieke laboratoriumomgeving. Alle apparaten die in dit document worden beschreven, hadden een opgeschoonde (standaard)configuratie. Als uw netwerk live is, moet u de potentiële impact van elke opdracht begrijpen.
Achtergrondinformatie
CloudCenter biedt enige rapportage uit het vak, maar biedt geen mogelijkheid voor meldingen op basis van aangepaste filters. Om API's te gebruiken om de informatie direct van de database te halen, in combinatie met metagegevens die aan de banen zijn gekoppeld, kunt u aangepaste rapporten toestaan.
Stel de metagegevens in
Metagegevens moeten per aanvraagniveau worden toegevoegd, zodat elke toepassing die moet worden gevolgd met het gebruik van het douaneverslag moet worden aangepast.
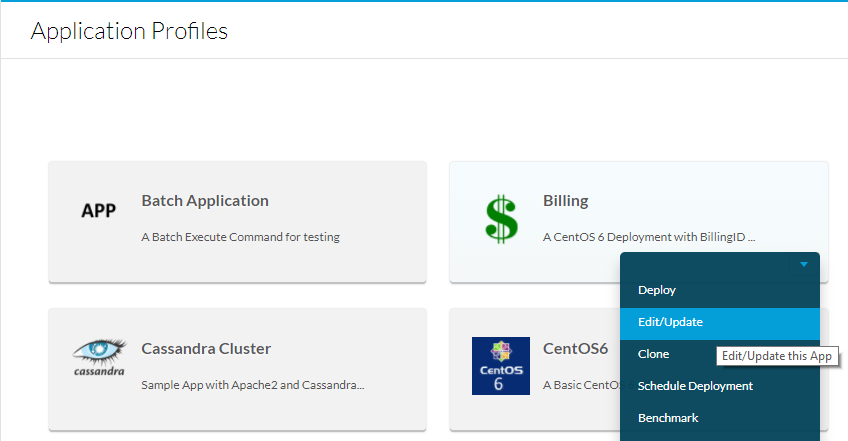
Om dit te doen, navigeer dan naar Toepassingsprofielen, selecteer vervolgens de vervolgkeuzelijst voor de app die moet worden bewerkt en selecteer vervolgens Bewerken/bijwerken zoals in de afbeelding weergegeven.
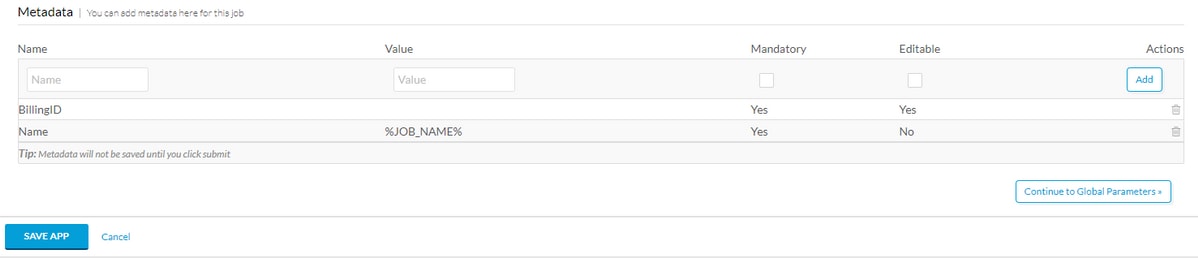
Rol naar de onderkant van de basisinformatie en voeg een tag met metagegevens toe, bijvoorbeeld BillingID, indien deze metagegevens door de gebruiker moeten worden ingevuld, maak deze zowel verplicht als bewerkbaar. Als dit alleen een macro is, vult u de standaardwaarde in en maakt u deze niet bewerkbaar. Nadat u de metadata hebt ingevuld, selecteert u Toevoegen en App opslaan zoals in de afbeelding.
Verzamel API-toetsen
Om de API-oproepen te kunnen verwerken, zijn gebruikersnaam en API-toetsen vereist. Deze toetsen bieden hetzelfde toegangsniveau als de gebruiker, dus als alle gebruikersimplementaties in het rapport moeten worden toegevoegd, wordt het aanbevolen om de beheerder van de huurders-API-toetsen in te schakelen. Als meerdere onderhuurders samen moeten worden geregistreerd, heeft de huurder toegang tot alle inzetomgevingen nodig, of de API-toetsen van alle onderhuurdirecteuren zijn vereist.
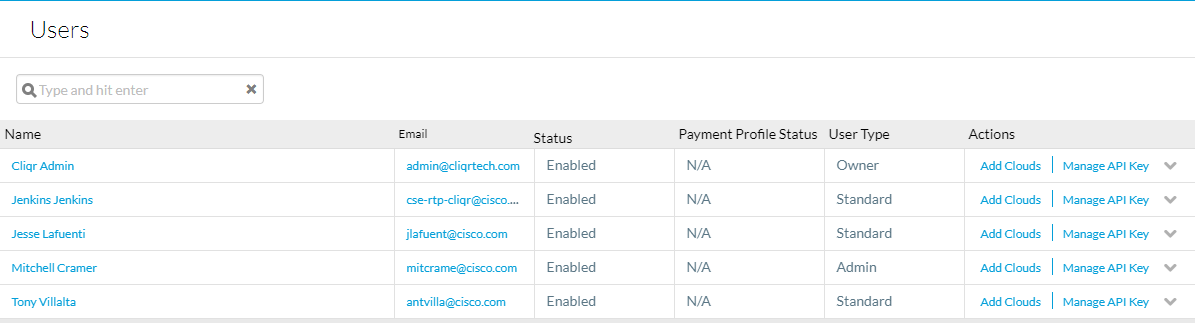
Om de API-toetsen naar Admin > Gebruikers > API-toets te laten beheren, kopieert u de gebruikersnaam en -toets voor de benodigde gebruikers.
Het aangepaste rapport maken
Voordat u het python script maakt dat het rapport maakt, zorg er dan voor dat python en pip erop zijn geïnstalleerd. Vervolgens installeert de dop tabulering, tabulering is een bibliotheek die het rapport automatisch opmaakt.
Aan deze handleiding worden twee voorbeeldrapporten toegevoegd; de eerste verzamelt simpelweg informatie over alle implementaties en vervolgens outputs in een tabel. De tweede gebruikt de zelfde informatie om een douanerapport met het gebruik van meta-gegevens BillingID te maken. Dit script wordt uitvoerig uitgelegd en kan als richtlijn worden gebruikt.
import datetime import json import sys import requests ##pip install tabulate from tabulate import tabulate from operator import itemgetter from decimal import Decimal
de datetime wordt gebruikt om de datum nauwkeurig te berekenen, dit wordt gedaan om een rapport van de meest recente X dagen te maken.
json wordt gebruikt om json data te parseren , de output van api aanroepen .
sys wordt gebruikt voor systeemaanroepen.
verzoeken worden gebruikt om het maken van webverzoeken voor de API-oproepen te vereenvoudigen.
tabuleren wordt gebruikt om de tabel automatisch op te maken.
Item dat als iterator wordt gebruikt om een 2D-tabel te sorteren.
Decimal wordt gebruikt om de kosten tot op twee decimalen terug te draaien.
if(len(sys.argv)==1):
days = -1
elif(len(sys.argv)==2):
try:
days = int(sys.argv[1])
if(days < 1):
raise ValueError('Less than 1')
start=datetime.datetime.now()+datetime.timedelta(days*-1)
except ValueError:
print("Number of days must be an integer greater than 0")
exit()
else:
print("Enter number of days to report on, or leave blank to report all time")
exit()
Dit gedeelte wordt gebruikt om de opdrachtregel parameter van aantal dagen te parseren.
Als er geen opdrachtregel parameters zijn (sys.argv ==1), dan zal de rapportage gedurende alle tijd plaatsvinden.
Als er één opdrachtregel parameter check is als het een integer is dat groter is dan of gelijk aan 1, als het wordt gerapporteerd op dat aantal dagen, als het niet, retourneert een fout.
Als er meer dan één parameter is, retourneert deze fout.
departments = [] users = ['user1','user2','user3'] passwords = ['user1Key','user2Key','user3Key']
de diensten zijn de lijst die de uiteindelijke resultaten zal houden .
gebruikers is een lijst van alle gebruikers die de API-oproepen zullen maken, als er meerdere sub-huurders zijn, zou elke gebruiker de beheerder van een verschillende sub-huurder zijn.
wachtwoorden zijn een lijst met de API-toetsen, de volgorde van gebruikers en toetsen moet identiek zijn zodat de juiste toets kan worden gebruikt.
for j in xrange(0,len(users)):
jobs = []
r = requests.get('https://ccm2.cisco.com/v1/jobs', auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data = r.json()
for i in xrange(0,len(data["jobs"])):
test = datetime.datetime.strptime((data["jobs"][i]["startTime"]), '%Y-%m-%d %H:%M:%S.%f')
if(days != -1):
if(start < test):
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
else:
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
for id in jobs:
q = requests.get('https://ccm2.cisco.com/v1/jobs/'+id[0], auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data2 = q.json()
id[2]=round(id[2],2)
for i in xrange(0,len(data2["metadatas"])):
if('BillingID' == data2["metadatas"][i]["name"]):
id[1]=data2["metadatas"][i]["value"]
added=0
for i in xrange(0,len(departments)):
if(departments[i][0]==id[1]):
departments[i][1]+= 1
departments[i][2]+=id[2]
added=1
if(added==0):
departments.append([id[1],1,id[2]])
voor j in xrange (0,len(gebruikers)): is voor loop om door elke gebruiker te herhalen die in de vorige codetabel is gedefinieerd, dit is de hoofdlijn die alle API oproepen behandelt.
banen zijn een tijdelijke lijst die zal worden gebruikt om de informatie voor banen te bewaren terwijl deze op de lijst wordt gezet .
r = request.get..... is het eerste API-telefoontje, dit is een lijst van alle banen, voor meer informatie zie List Jobs.
De resultaten worden dan in gegevensformaat opgeslagen.
voor i in xrange (0,len(data["jobs"]): herhaalt alle banen die werden teruggegeven van de vorige API-oproep.
De tijd voor elke taak wordt uit de tekst gehaald en naar een datetime object geconverteerd. Vervolgens wordt de parameter van de opdrachtregel vergeleken om te zien of hij binnen grenzen valt.
Als dat zo is, dan is het deze informatie van de json die aan de banenlijst is toegevoegd: id, totaalKostprijs, status, naam, begintijd. Niet al deze informatie wordt gebruikt, noch is dit alle informatie die kan worden teruggegeven. List Jobs laat alle informatie zien die kan worden toegevoegd op dezelfde manier.
Nadat je alle banen hebt herhaald die van die gebruiker zijn teruggegeven, verhuist je naar ID in banen: die alle banen die na de controle van de aanvangsdatum zijn overgenomen, nog eens doorkruist.
q = request.get(..... is de tweede API-oproep, deze bevat alle informatie met betrekking tot de taak-ID die is afgeleid van de eerste API-oproep. Zie Functiegegevens voor meer informatie.
Het bestand wordt vervolgens opgeslagen in data2.
De kosten, die in id[2] worden opgeslagen, worden afgerond op twee decimalen.
voor i in xrange(0,len(data2["metadatas"]): herhaalt door alle metagegevens die aan de taak gekoppeld zijn.
Als er metagegevens zijn die BillingID worden genoemd, dan wordt deze opgeslagen in de taakinformatie.
toegevoegd is een vlag die wordt gebruikt om vast te stellen of de facturatie-ID al of niet aan de departementenlijst is toegevoegd.
voor i in xrange ( 0 , len ( afdelingen ) ) : herhaalt door alle toegevoegde diensten .
Als deze baan deel uitmaakt van een afdeling die al bestaat, dan wordt het aantal banen met één vermenigvuldigd en worden de kosten opgeteld bij de totale kosten voor die afdeling.
Zo niet, dan wordt een nieuwe begrotingslijn toegevoegd aan afdelingen met een aantal banen van 1 en totale kosten die gelijk zijn aan de kosten van deze ene baan.
departments = sorted(departments, key=itemgetter(1)) print(tabulate(departments,headers=['Department','Number of Jobs','Total Cost']))
afdelingen = gesorteerd(afdelingen, key=itemgetter(1)) sorteert de afdelingen naar het aantal banen.
printen (tabuleren(afdelingen, headers=['Department', 'Number of Jobs', 'Total Cost')) drukt een tabel af die is gemaakt door tabuleren met drie kopregels.
Gerelateerde informatie
Bijgedragen door Cisco-engineers
- Jesse LafuentiCisco TAC-ingenieur
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)