Controleer de gezondheid van een ratinganalysekluster
Downloadopties
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
In dit document wordt beschreven hoe de gezondheid van een cluster voor testanalyses wordt geverifieerd.
Voorwaarden
Vereisten
Cisco raadt kennis van de volgende onderwerpen aan:
- Aanmelden bij een cluster
- Basiservaring van gebruikersinterface (UI)
Gebruikte componenten
De informatie in dit document is gebaseerd op de volgende software- en hardware-versies:
- versie 2.2.1.x
- 39RU-transceivermodules
De informatie in dit document is gebaseerd op de apparaten in een specifieke laboratoriumomgeving. Alle apparaten die in dit document worden beschreven, hadden een opgeschoonde (standaard)configuratie. Als uw netwerk live is, moet u de potentiële impact van elke opdracht begrijpen.
Achtergrondinformatie
Een energiecluster bestaat uit honderden processen (programma's) die over meerdere VM's [Vitual Machines] op meerdere UCS C220-M4-servers lopen. Er zijn verschillende diensten en functies aanwezig om de activiteiten van het cluster te helpen bewaken en de beheerder te waarschuwen wanneer het cluster mogelijk niet volledig functioneel is.
Dit document geeft een beeld van wat te controleren is bij het controleren van de gezondheid van het cluster. Terwijl het toepassingsgebied van dit document het controleren van de gezondheid omvat, als er actie nodig is om te helpen iets aan te pakken dat blijkbaar niet goed werkt, verzamelt u een snapshot en opent u een case met het TAC-team voor ondersteuning van Cisco-softwareoplossing.
Twee gemeenschappelijke instrumenten die worden gebruikt om de gezondheid van het cluster te controleren zijn de pagina's Cluster Status en Service Status die in dit document samen met een paar andere systeemtools worden bestreken. Hoewel Bosun-kritische e-mailwaarschuwingen vaak een van de eerste indicaties zijn voor een beheerder dat er iets in de cluster optreedt, is het controleren van de gezondheid van de cluster doorgaans het beste gedaan via de pagina's Cluster Status en Service Status.
Hoewel waarschuwingstekens van Boson syslog-achtige functies bieden, zijn in sommige transcriptieversies een aantal kritische waarschuwingen van Bozon geactiveerd in een normaal functionerend cluster. Een zoekgereedschap van cisco.com voor zoekdoeleinden voor het product van de harmonisatie met het metrieke sleutelwoord zal helpen om mogelijke kwesties voor een specifieke metriek te identificeren.
Wanneer u de gezondheid van het cluster wilt controleren:
Normaal gesproken hoeft de beheerder van het cluster de functionaliteit van het cluster niet te controleren. Er zijn echter bepaalde momenten waarop het nodig kan zijn. Hier worden een paar voorbeelden gegeven:
- Wanneer de gebruiker onverwacht gedrag in de gebruikersinterface (UI) ziet. Dit is deels gebaseerd op de kennis en ervaring van de gebruiker met betrekking tot de wijze waarop het cluster moet functioneren, maar sommige voorbeelden worden in deze sectie Operationele display-parameters getoond.
- Wanneer sommige gegevens verwacht worden te zien maar niet in de UI weergegeven. Bijvoorbeeld, stroomgegevens van een software of een hardwareagent (sensor) wanneer u het juiste bereik en tijdbereik bekijkt waar gegevens verwacht worden te worden weergegeven.
- Voor en na een geplande service, upgrade of belangrijke actie van het cluster. Het is de beste praktijk om een momentopname te vergaren vóór en na elk onderhoud en deze beschikbaar te houden voor het geval een TAC-case wordt geopend. Hierdoor kan TAC het probleem isoleren door te zoeken naar wijzigingen die tijdens het onderhoud zijn aangebracht.
Opmerking: Sommige verstoringen van de dienstverlening zijn normaal gedurende een periode onmiddellijk na systeemonderhoud op het cluster. In het voorbeeld van een serververvanging kan de tijdsduur tot 24 uur bedragen wanneer een datanode VM op die server draait. Normale systeemredundantie in de cluster vermindert doorgaans de negatieve effecten van één serververvanging.
Verschillende manieren om de operationele status van een ratingcluster te controleren
Operationele display-parameters
Een beheerder die kennis en ervaring van de exploitatie van het cluster heeft, kan herkennen hoe de normale werking van het cluster er in zijn omgeving uitziet. Dit zijn een paar voorbeelden van waar je naar op moet zoeken wanneer je controleert of het cluster normaal functioneert.
Voorbeeld 1: De laatste beschikbare stroomtijd is binnen 10 minuten na de huidige tijd

Voorbeeld 2: De meest recente beschikbare tijd voor Application Workspace is binnen 10 uur na de huidige tijd:

Voorbeeld 3: De inhoud van het dashboard is gevuld.

Cluster status
Een cluster voor testanalyses bestaat uit 6 (8RU) of 36 (39RU) servers, afhankelijk van het clustertype. De Cluster Status-pagina geeft de status van de servers en andere informatie over de metalen server.
De Cluster Status-pagina bevindt zich in het onderhoudmenu dat beschikbaar is in de vervolgkeuzemogelijkheden voor de instellingen (Instellingen > Onderhoud; Cluster Status in linkerkolom.)
Opmerking: Alleen het pictogram is zichtbaar totdat u op de linkerkolom klikt.
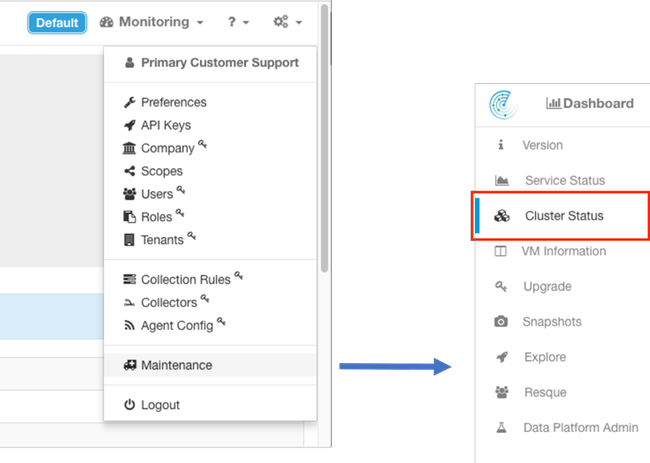
Opmerking: Afbeelding wordt ingekort tot de eerste 6 van de 36 servers (39RU-cluster).

- Instanties (virtuele machines) die op een metalen server lopen.
- Private IP-adres binnen de cluster.
- CIMC IP-adres binnen het cluster.
- Firmware versies (geprogrammeerd, CIMC, RAID Controller) die op de server actief zijn.

Servicestatus
Het ServiceStatus Alle pagina's worden weergegeven diensts die in Cisco Tidal Analytics-cluster worden gebruikt met hun afhankelijkheden en gezondheid status.
De pagina Service Status bevindt zich in het Onderhoudsmenu dat beschikbaar is in de vervolgkeuzelijst Instellingen. (Instellingen > Onderhoud; Servicestatus in linkerkolom.)
Opmerking: Alleen het pictogram is zichtbaar totdat u op de linkerkolom klikt.

Standaard geeft de servicestatus pagina de clusterfuncties en gebiedsdelen in een grafische weergave weer. Als de pictogrammen allemaal groen zijn, wordt er geen fout gedetecteerd.

Als er een service is die rood of oranje weergeeft, wordt in de boomweergave de lijst met services weergegeven. Hierbij kunt u boor maken over de afhankelijkheden van de service en over andere details die de functie Servicestatus heeft gedetecteerd. Deze gebiedsfoutinformatie is met name belangrijk om bij het openen van een case met de TAC rekening te houden en op te nemen.
Bijvoorbeeld, dit is hoe het lijstdisplay eruitziet wanneer een van de virtuele machines van HDFS DataNode in het cluster omlaag is
Opmerking: Het is mogelijk dat er geen merkbare impact is op het cluster als gevolg van redundantie die is ontworpen in het draaiingscluster.
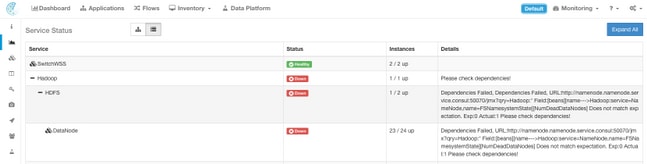
Opmerking: Er kan enige vertraging optreden bij het terugkeren van bepaalde diensten naar een functionerende staat nadat het onderhoud is uitgevoerd. Een server waarop een DataNode virtuele machine-instantie actief is die wordt uitgeschakeld en aanbevolen voor het RMA-onderhoud, kan bijvoorbeeld tot 24 uur duren voordat de gedetecteerde kwestie is opgehelderd.
Hoewel details in de servicestatus aangeven wat er kan gebeuren in het geval van een gedetecteerd probleem, is de aanbeveling gericht om een TAC-case te openen als er vragen zijn over de betekenis en/of mogelijke maatregelen om dit te verhelpen.
Bosun Alerts
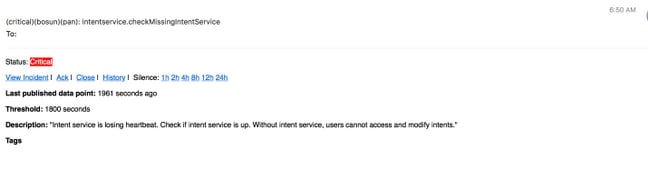

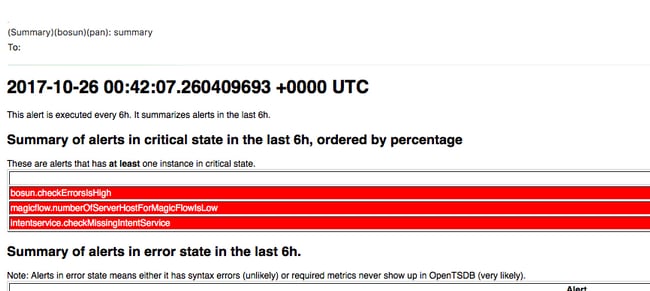
Verzamel Snapshot en Open TAC-case
Het team van de de Oplossing van Cisco van de Startoplossing van Cisco specialiseert en steunt de klanten van de Analyse van de Tetatie. Eén van de gemeenschappelijke items die TAC helpen om het meest te ontwerpen met hun probleemoplossing-proces is een snapshot-verzameling logbestanden uit het cluster. Soms is alleen de informatie in de logbestanden van de snapshot voldoende om het probleem te begrijpen. Als dit niet het geval is, biedt een momentopname het beginpunt in het proces voor het oplossen van problemen in veel gevallen.
Een snapshot in een trainingscluster is vergelijkbaar met technische ondersteuning in andere Cisco-producten. Het is een gecomprimeerd tarbalbestand of logbestanden van alle servers en virtuele machines en omvat:
- Logs
- Hadoop/YARN-aanvraag en -stammen
- Waarschuwingsgeschiedenis
- Talrijke STDB-statistieken
De snapshot-pagina bevindt zich in het onderhoudmenu beschikbaar via de instellingenlijst. (Instellingen > Onderhoud; Snapshots in linkerkolom.)
Opmerking: Alleen het pictogram is zichtbaar totdat u op de linkerkolom klikt.

De snapshot-pagina biedt verschillende opties om te selecteren, maar tenzij u instructies hebt van een TAC-engineer, kunnen de standaardwaarden gebruikt worden om de momentopname te verzamelen.
Een belangrijk gebied dat moet worden gewijzigd, is Comments. Opmerkingen moeten informatie verstrekken om aan te geven waarom de momentopname is verzameld wanneer er meerdere snapshots zijn verzameld van het cluster en de toegevoegde opmerking ook beschikbaar is in de momentopname tijdens analyse door Cisco TAC.

Wanneer op de knop Maken is gedrukt, wordt het snapshot-proces gestart. Er kan slechts één momentopname tegelijk worden gemaakt en het duurt enkele minuten voordat het proces is voltooid. Een voortgangsbalk voor de verzameling foto's vindt u boven op de pagina met een momentopname.
U kunt de momentopname vervolgens downloaden naar het lokale systeem van de gebruiker zodra u op de juiste link met de downshot-pagina hebt gedrukt, zoals in de afbeelding wordt weergegeven:

Opmerking: Het snapshot-bestand kan zo groot zijn als enkele honderden megabytes in grootte. Dit bestand kan vervolgens in de open TAC-case worden geüpload.
Gerelateerde informatie
Bijgedragen door Cisco-engineers
- Bryan DeaverCisco TAC-motor
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)