Utilizar metadados para relatório personalizado com APIs e Python
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve como usar metadados em conjunto com APIs para personalizar o relatório em um script python.
Prerequisites
Requirements
A Cisco recomenda que você tenha conhecimento destes tópicos:
- CloudCenter
- Python
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Informações de Apoio
O CloudCenter oferece alguns relatórios prontos para uso, mas não permite uma maneira de relatórios com base em filtros personalizados. Para usar APIs para capturar as informações diretamente do banco de dados, juntamente com metadados anexados aos trabalhos, você pode permitir relatórios personalizados.
Configurar os metadados
Os metadados devem ser adicionados em um nível por aplicativo, de modo que cada aplicativo que precisa ser rastreado com o uso do relatório personalizado deverá ser modificado.
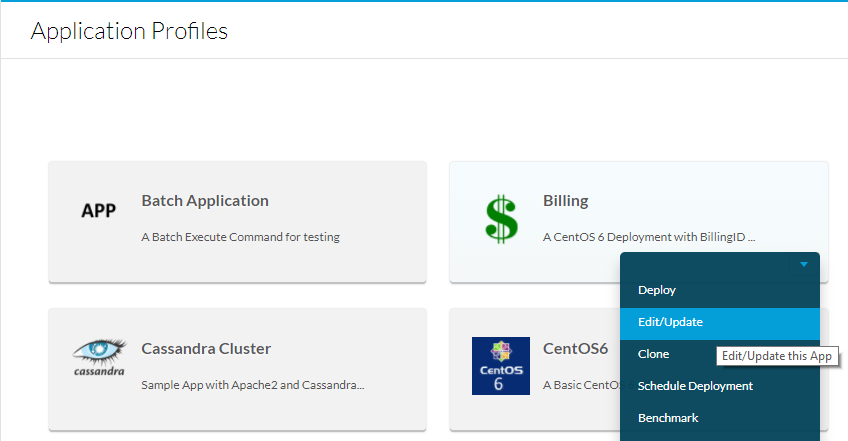
Para fazer isso, navegue até Perfis de aplicativo, selecione o menu suspenso do aplicativo a ser editado e selecione Editar/atualizar como mostrado na imagem.
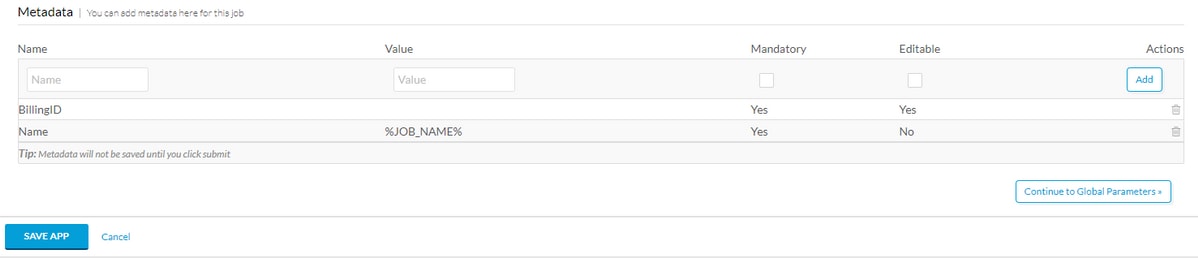
Role até a parte inferior de Informações Básicas e adicione uma marca de Metadados, por exemplo ID de Cobrança, se esses metadados devem ser preenchidos pelo usuário tornando-o obrigatório e editável. Se for apenas uma macro, preencha o valor padrão e não torne-o editável. Depois de preencher os metadados, selecione Adicionar e Salvar aplicativo conforme mostrado na imagem.
Coletar chaves de API
Para processar as chamadas da API, serão necessárias chaves de nome de usuário e de API. Essas chaves fornecem o mesmo nível de acesso que o usuário, portanto, se todas as implantações de usuários forem adicionadas no relatório, é recomendável obter o administrador das chaves API dos espaços. Se vários sublocatários forem gravados juntos, o locatário raiz precisará de acesso a todos os ambientes de implantação ou as chaves API de todos os administradores de sublocatários serão necessárias.
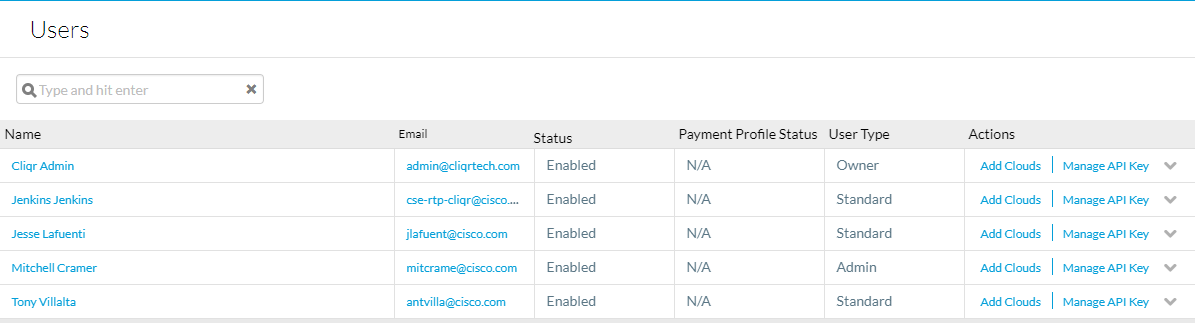
Para obter as chaves da API, navegue para Admin > Users > Manage API Key, copie o nome de usuário e a chave para os usuários necessários.
Crie o relatório personalizado
Antes de criar o script python que cria o relatório, verifique se python e pip foram instalados nele. Em seguida, execute pip install tabulate, tabulate é uma biblioteca que manipula a formatação automática do relatório.
Dois exemplos de relatórios são anexados a este guia, o primeiro simplesmente coleta informações sobre todas as implantações e, em seguida, as envia em uma tabela. O segundo usa as mesmas informações para criar um relatório personalizado com o uso de metadados de ID de cobrança. Este script é explicado em detalhes para ser usado como um guia.
import datetime import json import sys import requests ##pip install tabulate from tabulate import tabulate from operator import itemgetter from decimal import Decimal
datetime é usado para calcular com precisão a data, isso é feito para criar um relatório dos últimos X dias.
json é usado para ajudar a analisar dados json, a saída de chamadas api.
sys é usado para chamadas do sistema.
solicitações são usadas para simplificar a realização de solicitações da Web para as chamadas da API.
tabular é usado para formatar automaticamente a tabela.
itemgetter é usado como um iterador para classificar uma tabela 2D.
O decimal é usado para arredondar o custo para duas casas decimais.
if(len(sys.argv)==1):
days = -1
elif(len(sys.argv)==2):
try:
days = int(sys.argv[1])
if(days < 1):
raise ValueError('Less than 1')
start=datetime.datetime.now()+datetime.timedelta(days*-1)
except ValueError:
print("Number of days must be an integer greater than 0")
exit()
else:
print("Enter number of days to report on, or leave blank to report all time")
exit()
Esta parte é usada para analisar o parâmetro de linha de comando do número de dias.
Se não houver parâmetros de linha de comando (sys.argv ==1), os relatórios serão feitos para todo o tempo.
Se houver um parâmetro de linha de comando, verifique se é um inteiro maior ou igual a 1, se for relatado nesse número de dias, se não for, retorne um erro.
Se houver mais de um parâmetro, retorne um erro.
departments = [] users = ['user1','user2','user3'] passwords = ['user1Key','user2Key','user3Key']
departamentos é a lista que terá a saída final.
usuários é uma lista de todos os usuários que farão as chamadas à API, se houver vários sub-espaços, cada usuário será o administrador de um sub-espaço diferente.
senhas é uma lista de chaves de API dos usuários, a ordem dos usuários e chaves precisa ser idêntica para que a chave correta seja usada.
for j in xrange(0,len(users)):
jobs = []
r = requests.get('https://ccm2.cisco.com/v1/jobs', auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data = r.json()
for i in xrange(0,len(data["jobs"])):
test = datetime.datetime.strptime((data["jobs"][i]["startTime"]), '%Y-%m-%d %H:%M:%S.%f')
if(days != -1):
if(start < test):
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
else:
jobs.append([data["jobs"][i]["id"],'None', data["jobs"][i]["cost"]["totalCost"],data["jobs"][i]["status"],data["jobs"][i]["displayName"],data["jobs"][i]["startTime"]])
for id in jobs:
q = requests.get('https://ccm2.cisco.com/v1/jobs/'+id[0], auth=(users[j], passwords[j]), headers={'Accept': 'application/json'})
data2 = q.json()
id[2]=round(id[2],2)
for i in xrange(0,len(data2["metadatas"])):
if('BillingID' == data2["metadatas"][i]["name"]):
id[1]=data2["metadatas"][i]["value"]
added=0
for i in xrange(0,len(departments)):
if(departments[i][0]==id[1]):
departments[i][1]+= 1
departments[i][2]+=id[2]
added=1
if(added==0):
departments.append([id[1],1,id[2]])
para j no xrange(0,len(users)): é um loop para iterar através de cada usuário definido no bloco de código anterior, esse é o loop principal que lida com todas as chamadas de API.
jobs é uma lista temporária que será usada para manter as informações de jobs enquanto elas forem agrupadas na lista.
r = solicitações.get.... é a primeira chamada de API, esta lista todos os trabalhos, para obter mais informações, consulte Listar Trabalhos.
Os resultados são então armazenados em formato json em dados.
para i in xrange(0,len(data["jobs"]): repete todos os trabalhos retornados da chamada de API anterior.
O tempo de cada trabalho é extraído do json e convertido em um objeto datetime, em seguida, é comparado ao parâmetro de linha de comando inserido para ver se está dentro dos limites.
Se estiver, são essas informações do json que são anexadas à lista de trabalhos: id, custo total, status, nome, hora de início. Nem todas essas informações são usadas, nem todas as informações que podem ser devolvidas. Tarefas de lista mostra todas as informações retornadas que podem ser adicionadas da mesma maneira.
Depois de repetir todos os trabalhos retornados desse usuário, você vai para para id em trabalhos: que repete todos os trabalhos que foram realizados após você verificar a data de início.
q = request.get(..... é a segunda chamada de API, esta lista todas as informações relacionadas à ID de trabalho que foi obtida da primeira chamada de API. Para obter mais informações, consulte Obter detalhes do trabalho.
O arquivo json é armazenado em data2.
O custo, que é armazenado na id[2], é arredondado para duas casas decimais.
para i no xrange(0,len(data2["metadatas"]): repete todos os metadados associados ao trabalho.
Se houver metadados chamados BillingID, eles serão armazenados nas informações do trabalho.
adicionado é um sinalizador usado para determinar se a ID de cobrança já foi adicionada à lista de departamentos ou não.
para i no xrange(0,len(departamentos)): repete todos os departamentos que foram adicionados.
Se esse trabalho for parte de um departamento que já existe, a contagem de trabalhos será iterada por um, e o custo será adicionado ao custo total desse departamento.
Caso contrário, uma nova linha será acrescentada aos departamentos com uma contagem de tarefas de 1 e custo total igual ao custo dessa tarefa.
departments = sorted(departments, key=itemgetter(1)) print(tabulate(departments,headers=['Department','Number of Jobs','Total Cost']))
departamentos = classificados(departamentos, key=itemgetter(1)) classifica os departamentos pelo Número de Trabalhos.
print(tabela(departamentos,cabeçalhos=['Departamento','Número de Trabalhos', 'Custo Total']) imprime uma tabela criada por tabulação com três cabeçalhos.
Informações Relacionadas
Colaborado por engenheiros da Cisco
- Jesse LafuentiCisco TAC Engineer
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)