Introduction
Este documento descreve as etapas que você pode usar para solucionar problemas de montagem do Hyperflex Datastore.
Prerequisites
Requirements
Não existem requisitos específicos para este documento.
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio:
Por padrão, os datastores Hyperflex são montados no NFS v3.
NFS (Network File System) é um protocolo de compartilhamento de arquivos usado pelo hipervisor para se comunicar com um servidor NAS (Network Attached Storage, Armazenamento conectado à rede) em uma rede TCP/IP padrão.
Aqui está uma descrição dos componentes NFS usados em um ambiente vSphere:
- Servidor NFS - um dispositivo de armazenamento ou um servidor que usa o protocolo NFS para disponibilizar arquivos na rede. No mundo Hyperflex, cada VM controlador executa uma instância de servidor NFS. O IP do servidor NFS para os datastores é o IP da interface eth1:0.
- Armazenamento de dados NFS - uma partição compartilhada no servidor NFS que pode ser usada para armazenar arquivos de máquina virtual.
- Cliente NFS - O ESXi inclui um cliente NFS incorporado usado para acessar dispositivos NFS.
Além dos componentes NFS regulares, há um VIB instalado no ESXi chamado IOVisor. Este VIB fornece um ponto de montagem NFS (Network File System, sistema de arquivos de rede) para que o hipervisor ESXi possa acessar as unidades de disco virtuais conectadas a máquinas virtuais individuais. Do ponto de vista do hipervisor, ele é simplesmente anexado a um sistema de arquivos de rede.
Problema
Os sintomas de problemas de montagem podem aparecer no host ESXi como um armazenamento de dados inacessível.
Datastores inacessíveis no vCenter
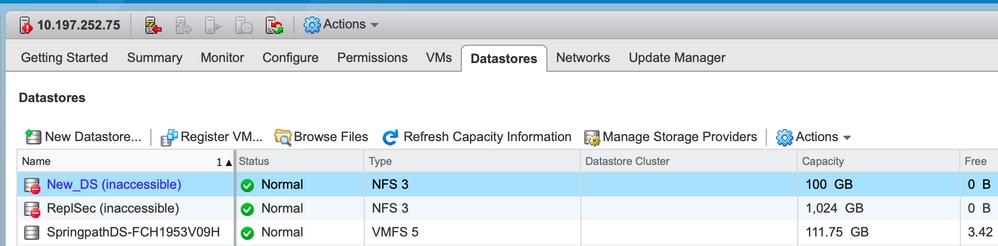
Note: Quando seus datastores aparecem como inacessíveis no vCenter, eles são vistos como montados indisponíveis na CLI do ESX. Isso significa que os datastores foram montados anteriormente no host.
Verifique os Datastores via CLI:
- SSH para o host ESXi e insira o comando:
[root@node1:~] esxcfg-nas -l
test1 is 10.197.252.106:test1 from 3203172317343203629-5043383143428344954 mounted unavailable
test2 is 10.197.252.106:test2 from 3203172317343203629-5043383143428344954 mounted unavailable
Os datastores não estão disponíveis no vCenter/CLI
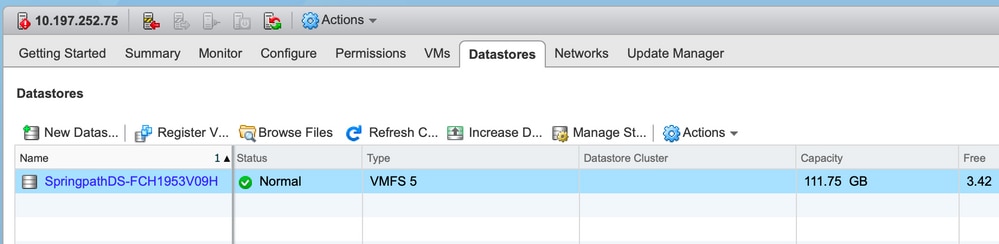
Note: Quando os datastores não estiverem presentes no vCenter ou na CLI. Isso indica que o Datastore nunca foi montado com êxito no host anteriormente.
- Verifique os datastores via CLI
SSH para o host ESXi e insira o comando:
[root@node1:~] esxcfg-nas -l
[root@node1:~]
Solução
Os motivos para o problema de montagem podem ser diferentes. Verifique a lista de verificações para validar e corrigir, se houver.
Verificação de acessibilidade da rede
A primeira coisa a verificar em caso de problemas com o armazenamento de dados é se o host pode acessar o IP do servidor NFS.
O IP do servidor NFS no caso do Hyperflex é o IP atribuído à interface virtual eth1:0, que está presente em um dos SCVMs.
Se os hosts ESXi não puderem fazer ping no IP do servidor NFS, isso fará com que os datastores fiquem inacessíveis.
Localize o IP eth1:0 com o comando ifconfig em todos os SCVMs.
Note: A Eth1:0 é uma interface virtual e está presente em apenas um dos SCVMs.
root@SpringpathControllerGDAKPUCJLE:~# ifconfig eth1:0
eth1:0 Link encap:Ethernet HWaddr 00:50:56:8b:62:d5
inet addr:10.197.252.106 Bcast:10.197.252.127 Mask:255.255.255.224
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Para o host ESXi com problemas de montagem de datastore e verifique se ele consegue acessar o IP do servidor NFS.
[root@node1:~] ping 10.197.252.106
PING 10.197.252.106 (10.197.252.106): 56 data bytes
64 bytes from 10.197.252.106: icmp_seq=0 ttl=64 time=0.312 ms
64 bytes from 10.197.252.106: icmp_seq=1 ttl=64 time=0.166 m
Se você conseguir fazer ping, continue com as etapas para solucionar problemas na próxima seção.
Se não conseguir fazer ping, você deve verificar seu ambiente para corrigir o alcance. há alguns indicadores que podem ser vistos:
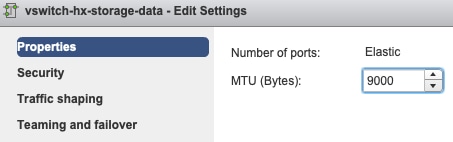
- hx-storage-data vSwitch Settings:
Note: Por padrão, toda a configuração é feita pelo instalador durante a implantação do cluster. Se ele tiver sido alterado manualmente depois disso, verifique as configurações
Configurações de MTU - Se você habilitou a MTU jumbo durante a implantação de cluster, a MTU no vSwitch também deve ser 9000. Caso não use MTU jumbo, deve ser 1500.
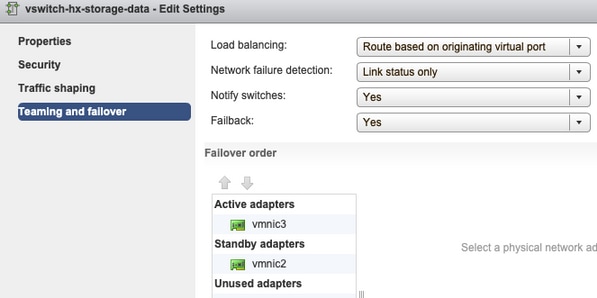
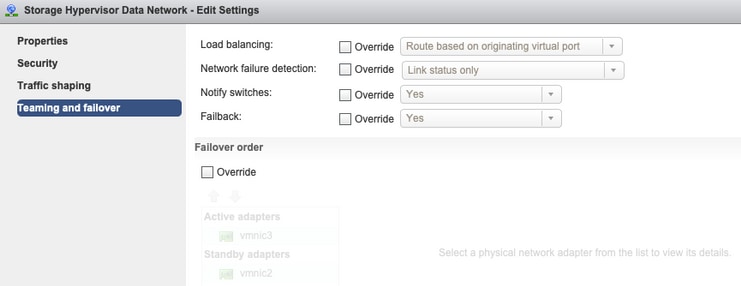
Agrupamento e failover - Por padrão, o sistema tenta garantir que o tráfego de dados de armazenamento seja comutado localmente pelo FI. Portanto, os adaptadores ativos e em standby em todos os hosts devem ser os mesmos.
Configurações de VLAN de grupo de portas - A VLAN de dados de armazenamento deve ser especificada nos grupos de portas de rede de dados do controlador de armazenamento e de rede de dados do hipervisor de armazenamento.
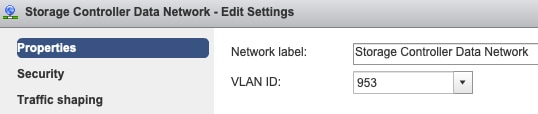
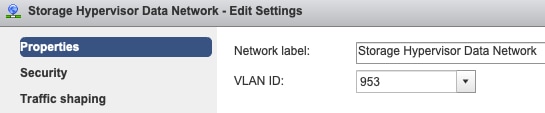
Sem substituições no nível do Grupo de Portas - As configurações de Agrupamento e Failover feitas no nível do vSwitch são aplicadas aos grupos de portas por padrão, portanto é recomendável não substituir as configurações no nível do grupo de portas.
- Configurações do UCS vNIC:
Note: Por padrão, toda a configuração é feita pelo instalador durante a implantação do cluster. Se ele tiver sido alterado manualmente depois disso, verifique as configurações
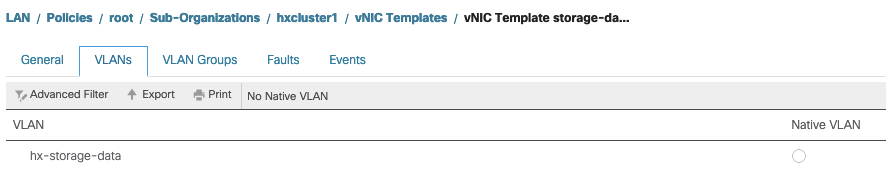
Configurações de MTU - verifique se o tamanho da MTU e a política de QoS estão configurados corretamente no modelo de vnic de dados de armazenamento. Os vnics de dados de armazenamento usam a política de QoS Platinum e a MTU deve ser configurada de acordo com seu ambiente.

Configurações de VLAN - A VLAN hx-storage-data criada durante a implantação do cluster deve ser permitida no modelo vnic. certifique-se de que não esteja marcado como nativo
Verificação de status do proxy IOvisor/ SCVMclient/ NFS
O vib do cliente SCVM no ESXI atua como o Proxy NFS. Ele intercepta o I/O da Máquina Virtual, o envia para o respectivo SCVM e os serve de volta com as informações necessárias.
Certifique-se de que o VIB esteja instalado em nossos hosts, para esse ssh em um dos ESXI e execute os comandos:
[root@node1:~] esxcli software vib list | grep -i spring
scvmclient 3.5.2b-31674 Springpath VMwareAccepted 2019-04-17
stHypervisorSvc 3.5.2b-31674 Springpath VMwareAccepted 2019-05-20
vmware-esx-STFSNasPlugin 1.0.1-21 Springpath VMwareAccepted 2018-11-23
Verifique o status do scvmclient no esxi agora e certifique-se de que ele esteja em execução; se ele for interrompido, inicie-o com o comando /etc/init.d/scvmclient start
[root@node1:~] /etc/init.d/scvmclient status
+ LOGFILE=/var/run/springpath/scvmclient_status
+ mkdir -p /var/run/springpath
+ trap mv /var/run/springpath/scvmclient_status /var/run/springpath/scvmclient_status.old && cat /var/run/springpath/scvmclient_status.old |logger -s EXIT
+ exec
+ exec
Scvmclient is running
UUID do cluster resolvível para o IP de loopback ESXI
O Hyperflex mapeia o UUID do cluster para a interface de loopback do ESXi, de modo que o ESXI passe as solicitações do NFS para seu próprio cliente scvm. Se isso não estiver lá, você poderá enfrentar problemas com a montagem dos datastores no host. Para verificar isso, faça ssh para o host que tem datastores montados, e ssh para o host com problemas, e selecione o arquivo /etc/hosts
Se você vir que o host não funcional não tem a entrada em /etc/hosts, você pode copiá-la de um host funcional para os /etc/hosts do host não funcional.
Host não funcional
[root@node1:~] cat /etc/hosts
# Do not remove these lines, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
10.197.252.75 node1
Host Funcional
[root@node2:~] cat /etc/hosts
# Do not remove these lines, or various programs
# that require network functionality will fail.
127.0.0.1 localhost.localdomain localhost
::1 localhost.localdomain localhost
10.197.252.76 node2
127.0.0.1 3203172317343203629-5043383143428344954.springpath 3203172317343203629-5043383143428344954
Entradas De Armazenamento De Dados Em /etc/vmware/esx.conf
Se o cluster HX tiver sido recriado sem a reinstalação do ESXI, talvez você tenha entradas antigas do datastore no arquivo esx.conf.
Isso não permite montar os novos datastores com o mesmo nome. Você pode verificar todos os datastores HX em esx.conf do arquivo:
[root@node1:~] cat /etc/vmware/esx.conf | grep -I nas
/nas/RepSec/share = "10.197.252.106:RepSec"
/nas/RepSec/enabled = "true"
/nas/RepSec/host = "5983172317343203629-5043383143428344954"
/nas/RepSec/readOnly = "false"
/nas/DS/share = "10.197.252.106:DS"
/nas/DS/enabled = "true"
/nas/DS/host = "3203172317343203629-5043383143428344954"
/nas/DS/readOnly = "false"
se estiver na saída, você verá que o armazenamento de dados antigo que está mapeado e usa o UUID do cluster antigo, portanto, o ESXi não permite montar o mesmo datastore com o novo UUID.
Para resolver isso, é necessário remover a entrada antiga do datastore com o comando - esxcfg-nas -d RepSec
Depois de removido, repita a montagem do armazenamento de dados do HX-Connect
Verificar regras de firewall no ESXi
Verificar configurações de ativação do firewall
Está definido como Falso, causa problemas.
[root@node1:~] esxcli network firewall get
Default Action: DROP
Enabled: false
Loaded: true
Ative-o com os comandos:
[root@node1:~] esxcli network firewall set –e true
[root@node1:~] esxcli network firewall get
Default Action: DROP
Enabled: true
Loaded: true
Verifique as configurações da regra de conexão:
Está definido como Falso, causa problemas.
[root@node1:~] esxcli network firewall ruleset list | grep -i scvm
ScvmClientConnectionRule false
Ative-o com os comandos:
[root@node1:~] esxcli network firewall ruleset set –e true –r ScvmClientConnectionRule
[root@node1:~] esxcli network firewall ruleset list | grep -i scvm
ScvmClientConnectionRule true
Verifique as regras de importação no SCVM
Verifique e combine o número de regras em todos os SCVMs. Se não houver correspondência, abra um caso do TAC para corrigi-lo.
root@SpringpathControllerI51U7U6QZX:~# iptables -L | wc -l
48
Informações Relacionadas
 Feedback
Feedback