Lógica de Balanceamento de Carga no Cisco Meeting Server
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve a lógica de balanceamento de carga do Cisco Meeting Server (CMS) (antigo produto Acano) que é abordado no white paper Balanceamento de carga. Este documento visualiza esse processo em um fluxograma e detalha o algoritmo de seleção.
Prerequisites
Requirements
A Cisco recomenda que você tenha conhecimento destes tópicos:
- Componente Call Bridge do Cisco Meeting Server (e sua organização por clusters)
- Configuração da API do Cisco Meeting Server
Componentes Utilizados
As informações neste documento são baseadas no Cisco Meeting Server, Versão 2.4.x.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Qual é o algoritmo de balanceamento de carga do CMS?
O balanceamento de carga foi introduzido na versão 2.1 do CMS para fazer uso eficiente dos recursos de conferência. Ele tenta minimizar o número de chamadas de distribuição entre as Call Bridges que hospedam o mesmo espaço. Esse mecanismo é baseado no cabeçalho Replaces no Session Initiation Protocol (SIP) e é suportado no Cisco Unified Communications Manager (CUCM) como o controle de chamadas. Também é suportado com a versão X8.11 do Expressway (ou posterior), em combinação com uma versão 2.4 do CMS ou posterior. As chamadas CMA (cliente thick e tipo WebRTC) podem ter balanceamento de carga, bem como a partir do CMS versão 2.3.
Observação: o balanceamento de carga de chamadas do Lync/Skype não é suportado em nenhuma versão do CMS no momento e, portanto, este fluxograma não se aplica.
Observação: a lógica do Balanceamento de Carga só se aplica a chamadas para espaços do CMS e, portanto, não a chamadas de gateway (chamadas P2P) ou chamadas dual-home neste momento.
O processo de balanceamento de carga é destacado no white paper na seção Como o balanceamento de carga usa as configurações em Configurando Call Bridges para balanceamento de carga de chamadas recebidas. Ele é mostrado em formato de texto e é visualizado aqui no fluxograma (download ).
O fluxograma utiliza algumas abreviações e terminologia:
- CB = Call Bridge
- ExistingConferenceLoadLimit = existingConferenceLoadLimitBasisPoints * loadLimit
(por padrão, o valor de existingConferenceLoadLimitBasisPoints é igual a 8000, o que corresponde a 80%) - NewConferenceLoadLimit = newConferenceLoadLimitBasisPoints * loadLimit
(por padrão, o newConferenceLoadLimitBasisPoints é igual a 5000, o que corresponde a 50%)
Se MediaProcessingLoad for referenciado, ele será visto em relação a essa Call Bridge específica onde a chamada aterrissou. Esse valor de carga pode ser verificado com uma API GET em /system/load em tempo real e fornece uma representação da carga real processada por essa Call Bridge nesse momento.

Se você terminar sua chamada na caixa inferior mais à direita, ela será redirecionada para o servidor com a prioridade mais alta. Ele pode ser o próprio servidor Call Bridge ou outro servidor dentro do Grupo Call Bridge no qual a chamada foi aterrada. Caso nenhuma decisão seja tomada com base na carga e se o espaço já estiver ativo em uma Call Bridge, há um vínculo com várias Call Bridges. Nesse caso, a decisão final é tomada com base na preferência de Call Bridge padrão atribuída a cada espaço. Essa preferência de Call Bridge é alocada na criação do espaço automaticamente e não é configurável, pois se baseia nos valores de hash de vários atributos. Isso resulta em uma distribuição uniforme (aleatória) para espaços diferentes em todas as Call Bridges.
Para ver a preferência de Call Bridge para um espaço específico, você precisaria verificar isso no registro de eventos do CMS, como mostrado nesses exemplos.
Exemplos do algoritmo de balanceamento de carga
Esta seção contém exemplos de possíveis cenários e como o registro de eventos do CMS onde a chamada aterrada mostra o processo de balanceamento de carga como abordado no fluxograma.
Para esses exemplos, uma configuração de laboratório foi usada com um grupo de três Call Bridges. As configurações existingConferenceLoadLimitBasisPoints e newConferenceLoadLimitBasisPoints foram definidas com seus valores padrão correspondentes a 80% e 50%, respectivamente, do valor de loadLimit.
Para verificar o MediaProcessingLoad atual em uma Call Bridge específica, você pode navegar para https://<ip-or-fqdn-of-callbridge>:<webadmin-port>/api/v1/system/load e fazer login com uma API ou conta de administrador conforme exibido na imagem.
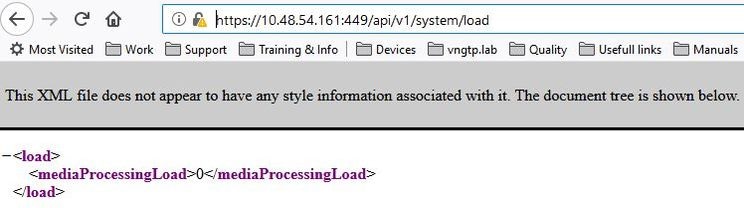
Exemplo 1: Sem carga em qualquer Call Bridge
Neste exemplo, não há chamadas ativas em nenhuma das Call Bridges. Assim, MediaProcessingLoad de todos os servidores é igual a zero.
Quando você faz uma chamada para uma das Call Bridges (cluster1 aqui) (com o balanceamento de carga ativado no CMS e nos dispositivos de controle de chamada), você pode ver o registro de eventos na Call Bridge onde a chamada aterrou:
2018-12-29 10:51:29.490 Info call 75: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 10:51:29.565 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 10:51:29.712 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3' 2018-12-29 10:51:29.876 Info call 75: ending; remote SIP cancel (remote cancel) - not connected after 0:00
no qual você pode ver as linhas de consulta de substituição para cada uma das Call Bridges em seu Grupo de Call Bridge que nos mostram o algoritmo de balanceamento de carga que é dividido em três seções:
- priority - a preferência Call Bridge desse espaço
- load level - o nível de carga da Call Bridge nesse momento
- conferência em execução - booliano se o espaço está ativo na ponte de chamada
Como nenhuma chamada foi feita nesse momento para o sistema, não há carga em nenhum dos sistemas (todos 0) e a conferência não está sendo executada em nenhum lugar (todos 0). A este respeito, a decisão final é tomada com base na preferência Call Bridge do espaço. Uma prioridade mais baixa é preferível e, portanto, a chamada é substituída aqui para a Call Bridge chamada cluster3, conforme visto pela linha substituindo chamada.
No cluster Call Bridge3, você pode ver as linhas do log de eventos que indicam essa chamada de substituição (bem como de qual Call Bridge ela veio (cluster1 aqui) e a mesma ID de conferência e ID de chamada):
2018-12-29 10:51:29.784 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' from server 'cluster1' into conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 2018-12-29 10:51:29.787 Info call 193: outgoing SIP call to "1060@steven.lab" from space "Steven Janssens's space" 2018-12-29 10:51:29.792 Info call 193: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 10:51:29.909 Info call 193: compensating for far end not matching payload types 2018-12-29 10:51:29.911 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Caso a chamada já tenha aterrado no Call Bridge com o valor de prioridade mais baixo (cluster3 aqui para este espaço), você ainda poderá ver as mesmas linhas de consulta de substituição no registro de eventos, mas isso indica que agora ele usa o servidor local e que não há nenhuma linha de chamada de substituição:
2018-12-29 11:05:25.202 Info call 194: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:05:25.233 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.376 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.380 Info call 194: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 11:05:25.404 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Exemplo 2: Já há participantes no espaço no grupo de ponte de chamada
Neste exemplo, o espaço já está ativo dentro do Grupo de Call Bridge como endpoint 1060@steven.lab chamado no espaço como mostrado no exemplo 1.
Há duas situações neste caso:
1. O Call Bridge que hospeda esse espaço tem uma carga inferior ao limite de conferência existente e, portanto, é capaz de aceitar a chamada.
2. O Call Bridge que hospeda esse espaço tem uma carga maior que o limite de conferência existente e, portanto, o CMS tenta substituir a chamada para outro Call Bridge.
Cenário 1. Espaço ativo e carga abaixo do limite de conferência existente (80%)
Caso a chamada tenha aterrado em uma Call Bridge em que o espaço ainda não estava ativo, o registro de eventos mostra agora que o espaço está ativo na Call Bridge com o nome cluster3. Como o espaço está ativo e a carga nesse servidor é menor que o limite existente (nível de carga: 0), a chamada é substituída.
2018-12-29 11:48:17.419 Info call 82: incoming SIP call from "sip:800999@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:48:17.477 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replacing call '4c28197eaebba178@10.10.2.250' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3'
A conferência em execução tem preferência à prioridade primeiro; portanto, se houvesse vários candidatos com um nível de carga abaixo do limite de conferência existente, ela desceria para a preferência Call Bridge de acordo com o valor de prioridade. No entanto, não é esse o caso no presente processo.
Cenário 2. Espaço ativo e carga acima do limite de conferência existente (80%)
Nesse caso, a chamada não é substituída por esse Call Bridge, mas procura outro Call Bridge dentro do grupo que tenha alguns recursos ainda disponíveis. Primeiro, ele verifica se há Call Bridges com uma carga inferior a 50% (novo limite de conferência) e carrega essas pontes primeiro. Se não houver nenhum abaixo desse limite, ele verificará se ainda há disponível abaixo de 80% (limite de conferência existente).
Se a carga no cluster Call Bridge3 for verificada após as chamadas dos exemplos 1 e 2 (cenário 1), ela mostrará uma carga de 2000.

Suponha que o loadLimit para o cluster3 da Call Bridge tenha sido definido como 2250 (apenas como exemplo), então essa Call Bridge está acima do limite de conferência existente, pois é calculado como 0,80 * 2250 = 1800
Ainda há dois casos a serem diferenciados nesse cenário.
Caso 1: Vários servidores no grupo ainda com carga menor que o limite da nova conferência (50%)
Os outros dois servidores no grupo não têm nenhuma chamada tratada ainda, portanto, a carga ainda está em 0 e, portanto, ambos podem lidar com a chamada. A decisão final, portanto, é feita com base na preferência de Call Bridge para esse espaço. Como Call Bridge cluster3 já está cheio, os sistemas escolhem a prioridade mais baixa de cluster1 e cluster2, que é cluster1 neste caso.
2018-12-29 12:11:03.211 Info call 86: incoming encrypted SIP audio call from "sip:2001@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:11:03.263 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.405 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.415 Info call 86: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:11:03.434 Info participant "2001@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Observe que o nível de carga: 2 no Call Bridge cluster3 indica que ele ultrapassou o limite de conferência existente, portanto, mesmo que o espaço estivesse ativo lá, a chamada não tem balanceamento de carga para esse servidor. Em vez disso, ele examina a menor prioridade de espaço das outras Call Bridges com um nível de carga: 0 (que significa menos de 50% de uso), que é cluster1 neste caso.
Caso 2: Somente um servidor em um grupo com carga menor que o limite para novas conferências (50%) ou o limite para conferências existentes (80%)
Após a última chamada (e chamadas para outro espaço para cluster2), as cargas descritas foram vistas nas Call Bridges:
- cluster 1 - 1200
- cluster 2 - 400
- cluster 3 - 4000
Suponha que agora o loadLimit definido no cluster1 Call Bridge seja 1300, então esse Call Bridge está acima do novo limite de conferência, pois é calculado como 0,50 * 1300 = 650, bem como sobre o limite de conferência existente de 0,80 * 1300 = 1040.
No caso de uma nova chamada WebRTC entrar agora no cluster3 de Call Bridge para esse mesmo espaço, o espaço estará ativo no cluster1 e no cluster3, mas ambos estão acima do limite de conferência existente e, portanto, ele procura outro servidor abaixo do novo limite de conferência (50%) ou do limite de conferência existente (80%). Nesse caso, somente cluster2 ainda estaria abaixo do limite de conferência existente, mas já está acima do novo limite de conferência devido a outra chamada para outro espaço manipulado na Ponte de Chamada do cluster2.
2018-12-29 12:45:33.162 Info instantiating user "guest1685904798@cluster.steven.lab" 2018-12-29 12:45:33.162 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster2' (priority: 2, load level: 1, conference is running: 0)
Cluster2 foi configurado com um valor loadLimit de 600 aqui. Com 400 como a carga atual antes da entrada da nova chamada, ele está acima do novo limite de conferência de 0,5 * 600 = 300, mas ainda está abaixo do limite de conferência existente de 0,8 * 600 = 480. Assim, isso aparece na consulta de substituição como nível de carga: 1 (em vez de 2 quando o Call Bridge está acima do limite de 80%).
Exemplo 3: Desembarque de chamada em ponte de chamada acima do limite de conferência existente
Nesse caso, o algoritmo de balanceamento de carga não ocorre, pois seria melhor enviar uma Resposta 488 de volta para o dispositivo de controle de chamada que pode então decidir tentar rotear a chamada para uma Call Bridge diferente dentro do grupo (que pode estar abaixo do limite de 80%) ou até mesmo roteá-la para um grupo de Call Bridge diferente se o grupo atual estiver sem recursos (como uma opção de fallback).
O registro de eventos não mostra explicitamente essa parte com muitos detalhes, pois apenas relata que ela ultrapassou a capacidade:
2018-12-29 12:49:13.352 Info call 88: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:49:13.399 Info call 88: ending; local teardown, system participant limit reached - not connected after 0:00
Quando a chamada é enviada para uma Call Bridge diferente que possa lidar com a carga (cluster2, por exemplo), o mesmo algoritmo de balanceamento de carga é mostrado:
2018-12-29 12:49:13.434 Info call 624: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab"
2018-12-29 12:49:13.475 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.618 Info call 624: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:49:13.621 Info call 624: starting DTLS UDT media negotiation (as initiator) 2018-12-29 12:49:13.640 Info participant "2020@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Observação: no caso de chamadas de gateway, o CMS retorna uma mensagem de erro SIP 486. Por padrão, o CUCM interrompe o roteamento de acordo com o parâmetro de serviço de Parar o roteamento no sinalizador de usuário ocupado, portanto, talvez você queira alterar essa configuração para permitir o fallback para chamadas de gateway para suas outras callbridges.
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
1.0 |
30-Apr-2019 |
Versão inicial |
Colaborado por engenheiros da Cisco
- Steven JanssensEngenheiro do Cisco TAC
- Nart OmatEngenheiro do Cisco TAC
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)