Entender os erros de verificação de redundância cíclica em switches Nexus
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve os erros de Cyclic Redundancy Check (CRC) observados nos contadores de interface e nas estatísticas dos switches Cisco Nexus.
Pré-requisitos
Requisitos
A Cisco recomenda que você entenda os conceitos básicos de switching Ethernet e a CLI (Command Line Interface, interface de linha de comando) do Cisco NX-OS. Para obter mais informações, consulte um destes documentos aplicáveis:
- Guia de configuração dos princípios do Cisco Nexus 9000 NX-OS, versão 10.2(x)
- Guia de configuração dos princípios do Cisco Nexus 9000 Series NX-OS, versão 9.3(x)
- Guia de configuração dos princípios do Cisco Nexus 9000 Series NX-OS, versão 9.2(x)
- Guia de configuração dos princípios do Cisco Nexus 9000 Series NX-OS, versão 7.x
Componentes Utilizados
As informações neste documento são baseadas nestas versões de software e hardware:
- Switches Nexus 9000 Series, a partir da versão 9.3(8) do software NX-OS
- Switches Nexus 3000 Series, a partir da versão 9.3(8) do software NX-OS
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
Este documento descreve detalhes sobre erros de Cyclic Redundancy Check (CRC) observados em contadores de interface nos switches Cisco Nexus Series. Este documento descreve o que é um CRC, como ele é usado no campo Frame Check Sequence (FCS) dos quadros Ethernet, como os erros de CRC se manifestam nos switches Nexus e como os erros de CRC interagem na comutação Store-and-Forward. Este artigo também descreve cenários de switching cut-through, as causas raiz mais prováveis de erros de CRC e como solucionar problemas e resolver erros de CRC.
Hardware aplicável
As informações neste documento são aplicáveis a todos os switches Cisco Nexus Series. Algumas informações neste documento também podem ser aplicáveis a outras plataformas de roteamento e switching da Cisco, como roteadores e switches Cisco Catalyst.
Definição de CRC
Um CRC é um mecanismo de detecção de erro comumente usado em redes de computador e de armazenamento para identificar dados alterados ou corrompidos durante a transmissão. Quando um dispositivo conectado à rede precisa transmitir dados, o dispositivo executa um algoritmo de computação com base em códigos cíclicos nos dados que resultam em um número de tamanho fixo. Esse número de tamanho fixo é chamado de valor de CRC. No entanto, informalmente, ele é chamado muitas vezes de CRC, para abreviar. Esse valor de CRC é anexado aos dados e transmitido pela rede para outro dispositivo. Esse dispositivo remoto executa o mesmo algoritmo de código cíclico em relação aos dados e compara o valor que resulta com o CRC anexado aos dados. Se ambos os valores corresponderem, o dispositivo remoto supõe que os dados foram transmitidos pela rede sem corrupção. Se os valores não coincidirem, o dispositivo remoto supõe que os dados foram corrompidos na transmissão através da rede. Esses dados corrompidos não são confiáveis e devem ser descartados.
As CRCs são usadas para detecção de erros em várias tecnologias de rede de computador, como Ethernet (variações com e sem fio), Token Ring, ATM (Asynchronous Transfer Mode, modo de transferência assíncrona) e Frame Relay. Os quadros Ethernet têm um campo Frame Check Sequence (FCS) de 32 bits no final do quadro (imediatamente após o payload do quadro) onde um valor de CRC de 32 bits é inserido.
Por exemplo, considere um cenário em que dois hosts, chamados Host-A e Host-B, estão diretamente conectados entre si pelas NICs (Network Interface Cards, placas de interface de rede). O Host-A precisa enviar a frase “Este é um exemplo” para o Host-B pela rede. O Host-A cria um quadro Ethernet destinado ao Host-B com um payload de “Este é um exemplo” e calcula que o valor de CRC do quadro é um valor hexadecimal de 0xABCD. O Host-A insere o valor de CRC de 0xABCD no campo FCS do quadro Ethernet e, em seguida, transmite o quadro Ethernet da placa de rede do Host-A para o Host-B.
Quando o Host-B recebe esse quadro, ele pode calcular o valor de CRC do quadro com o uso do mesmo algoritmo exato do Host-A. O Host-B calcula que o valor de CRC do quadro é um valor hexadecimal de 0xABCD, o que indica para o Host-B que o quadro Ethernet não foi corrompido durante a transmissão para o Host-B.
Definição de erro de CRC
Um erro de CRC ocorre quando um dispositivo (um dispositivo de rede ou um host conectado à rede) recebe um quadro Ethernet com um valor de CRC no campo FCS do quadro que não corresponde ao valor de CRC calculado pelo dispositivo para o quadro.
Esse conceito é melhor demonstrado por meio de um exemplo. Considere um cenário em que dois hosts, chamados Host-A e Host-B, estão diretamente conectados entre si pelas NICs. O Host-A precisa enviar a frase “Este é um exemplo” para o Host-B pela rede. O Host-A cria um quadro Ethernet destinado ao Host-B com um payload de “Este é um exemplo” e calcula que o valor de CRC do quadro é o valor hexadecimal 0xABCD. O Host-A insere o valor de CRC de 0xABCD no campo FCS do quadro Ethernet e, em seguida, transmite o quadro Ethernet da placa de rede do Host-A para o Host-B.
No entanto, danos na mídia física que conecta o Host-A ao Host-B corrompem o conteúdo do quadro de modo que a frase no quadro muda para “Este foi um exemplo”, em vez do payload desejado de “Este é um exemplo”.
Quando o Host-B recebe esse quadro, ele pode calcular o valor de CRC do quadro e incluir o payload corrompido no cálculo. O Host-B calcula que o valor de CRC do quadro é um valor hexadecimal de 0xDEAD, que é diferente do valor de CRC 0xABCD no campo FCS do quadro Ethernet. Essa diferença nos valores de CRC informa ao Host-B que o quadro Ethernet foi corrompido durante a transmissão para o Host-B. Como resultado, o Host-B não pode confiar no conteúdo desse quadro Ethernet, portanto, pode descartá-lo. O Host-B pode, em geral, incrementar algum tipo de contador de erros em sua placa de rede (NIC), como os contadores de "erros de entrada", "erros de CRC" ou "erros de RX".
Sintomas comuns de erros de CRC
Os erros de CRC normalmente se expressam de duas maneiras:
- Contadores de erro com incrementação ou diferentes de zero nas interfaces dos dispositivos conectados à rede.
- Perda de pacote/quadro para tráfego que atravessa a rede devido a dispositivos conectados à rede que descartam quadros corrompidos.
Esses erros se manifestam de maneiras ligeiramente diferentes, dependendo do dispositivo com o qual você trabalha no momento. Estas subseções detalham cada tipo de dispositivo.
Erros recebidos nos hosts do Windows
Os erros de CRC nos hosts do Windows normalmente se apresentam como um contador de Erros Recebidos diferente de zero exibido na saída do comando netstat -e no prompt de comando. Este é um exemplo de um contador de Erros Recebidos diferente de zero no prompt de comando de um host do Windows:
>netstat -e
Interface Statistics
Received Sent
Bytes 1116139893 3374201234
Unicast packets 101276400 49751195
Non-unicast packets 0 0
Discards 0 0
Errors 47294 0
Unknown protocols 0
A NIC e o respectivo driver devem ser compatíveis com a contabilização dos erros de CRC recebidos pela NIC para que o número de erros recebidos relatados pelo comando netstat -e seja preciso. A maioria das NICs modernas e os respectivos drivers são compatíveis com uma contabilização precisa dos erros de CRC recebidos pela NIC.
Erros de RX nos hosts do Linux
Os erros de CRC nos hosts do Linux normalmente se apresentam como um contador de “erros de RX” diferente de zero exibido na saída do comando ifconfig. Este é um exemplo de um contador de erros de RX diferente de zero em um host do Linux:
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.0.2.10 netmask 255.255.255.128 broadcast 192.0.2.255
inet6 fe80::10 prefixlen 64 scopeid 0x20<link>
ether 08:62:66:be:48:9b txqueuelen 1000 (Ethernet)
RX packets 591511682 bytes 214790684016 (200.0 GiB)
RX errors 478920 dropped 0 overruns 0 frame 0
TX packets 85495109 bytes 288004112030 (268.2 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Os erros de CRC nos hosts do Linux também podem se apresentar como um contador de “erros de RX” diferente de zero exibido na saída do comando ip -s link show. Este é um exemplo de um contador de erros de RX diferente de zero em um host do Linux:
$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 08:62:66:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
A NIC e o respectivo driver devem ser compatíveis com a contabilização dos erros de CRC recebidos pela NIC para que o número de erros de RX relatados pelos comandos ifconfig ou ip -s link show seja preciso. A maioria das NICs modernas e os respectivos drivers são compatíveis com uma contabilização precisa dos erros de CRC recebidos pela NIC.
Erros de CRC nos dispositivos de rede
Os dispositivos de rede operam em um dos dois modos de encaminhamento:
- Modo de encaminhamento Store-and-Forward
- Modo de encaminhamento Cut-Through
A maneira como um dispositivo de rede lida com um erro CRC recebido difere dependendo dos modos de encaminhamento. As subseções aqui descrevem o comportamento específico de cada modo de encaminhamento.
Erros de entrada nos dispositivos de rede Store-and-Forward
Quando um dispositivo de rede que opera em um modo de encaminhamento Store-and-Forward recebe um quadro, o dispositivo de rede pode armazenar em buffer o quadro inteiro ("Store") antes que você valide o valor de CRC do quadro, tome uma decisão de encaminhamento sobre o quadro e transmita o quadro para fora de uma interface ("Forward"). Portanto, quando um dispositivo de rede que opera em um modo de encaminhamento Store-and-Forward recebe um quadro corrompido com um valor de CRC incorreto em uma interface específica, ele pode descartar o quadro e incrementar o contador de "Erros de Entrada" na interface.
Em outras palavras, os quadros Ethernet corrompidos não são encaminhados pelos dispositivos de rede que operam em um modo de encaminhamento Store-and-Forward. Eles são descartados na entrada.
Os switches Cisco Nexus 7000 e 7700 Series operam em um modo de encaminhamento Store-and-Forward. Este é um exemplo de um contador de Erros de Entrada diferente de zero e um contador de CRC/FCS diferente de zero de um switch Nexus 7000 ou 7700 Series:
switch# show interface
<snip>
Ethernet1/1 is up
RX
241052345 unicast packets 5236252 multicast packets 5 broadcast packets
245794858 input packets 17901276787 bytes
0 jumbo packets 0 storm suppression packets
0 runts 0 giants 579204 CRC/FCS 0 no buffer
579204 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
Os erros de CRC também podem se apresentar como um contador de “FCS-Err” diferente de zero na saída de show interface counters errors. O contador "Rcv-Err" na saída desse comando também pode ter um valor diferente de zero, que é a soma de todos os erros de entrada (CRC ou outro) recebidos pela interface. Um exemplo disso é mostrado abaixo:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 579204 0 579204 0 0
Erros de entrada e saída nos dispositivos de rede Cut-Through
Quando um dispositivo de rede que opera em um modo de encaminhamento Cut-Through começa a receber um quadro, o dispositivo de rede pode tomar uma decisão de encaminhamento no cabeçalho do quadro e começar a transmitir o quadro para fora de uma interface assim que receber o suficiente do quadro para tomar uma decisão de encaminhamento válida. Como o quadro e os cabeçalhos de pacote estão no início do quadro, essa decisão de encaminhamento geralmente é tomada antes que o payload do quadro seja recebido.
O campo FCS de um quadro Ethernet está no final do quadro, imediatamente após o payload do quadro. Portanto, um dispositivo de rede operando em um modo de encaminhamento Cut-Through já pode ter começado a transmitir o quadro para fora de outra interface quando pode calcular o CRC do quadro. Se a CRC calculada pelo dispositivo de rede para o quadro não corresponder ao valor de CRC presente no campo FCS, isso significa que o dispositivo de rede encaminhou um quadro corrompido para a rede. Quando isso acontece, o dispositivo de rede pode incrementar dois contadores:
- O contador de "Erros de Entrada" na interface em que o quadro corrompido foi recebido originalmente.
- O contador de "Erros de Saída" em todas as interfaces em que o quadro corrompido foi transmitido. Para o tráfego unicast, isso pode ser tipicamente uma única interface - no entanto, para o tráfego broadcast, multicast ou unicast desconhecido, isso pode ser uma ou mais interfaces.
Um exemplo disso é mostrado abaixo, em que a saída do comando show interface indica que vários quadros corrompidos foram recebidos na Ethernet1/1 do dispositivo de rede e transmitidos pela Ethernet1/2 devido ao modo de encaminhamento Cut-Through do dispositivo de rede:
switch# show interface
<snip>
Ethernet1/1 is up
RX
46739903 unicast packets 29596632 multicast packets 0 broadcast packets
76336535 input packets 6743810714 bytes
15 jumbo packets 0 storm suppression bytes
0 runts 0 giants 47294 CRC 0 no buffer
47294 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
Ethernet1/2 is up
TX
46091721 unicast packets 2852390 multicast packets 102619 broadcast packets
49046730 output packets 3859955290 bytes
50230 jumbo packets
47294 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Os erros de CRC também podem se apresentar como um contador de “FCS-Err” diferente de zero na interface de entrada e contadores de "Xmit-Err" diferentes de zero nas interfaces de saída na saída de show interface counters errors. O contador "Rcv-Err" na interface de entrada na saída desse comando também pode ter um valor diferente de zero, que é a soma de todos os erros de entrada (CRC ou outro) recebidos pela interface. Um exemplo disso é mostrado abaixo:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 47294 0 47294 0 0
Eth1/2 0 0 47294 0 0 0
O dispositivo de rede também pode modificar o valor de CRC no campo FCS do quadro de uma maneira específica que significa para os dispositivos de rede upstream que esse quadro está corrompido. Esse comportamento é conhecido como "stomping" de CRC. A maneira precisa em que o CRC é modificado varia de uma plataforma para outra, mas geralmente, ele calcula o valor de CRC do quadro corrompido, inverte esse valor e o insere no campo FCS do quadro. Aqui está um exemplo disso:
Original Frame's CRC: 0xABCD (1010101111001101)
Corrupted Frame's CRC: 0xDEAD (1101111010101101)
Corrupted Frame's Stomped CRC: 0x2152 (0010000101010010)
Como resultado desse comportamento, os dispositivos de rede que operam em um modo de encaminhamento Cut-Through podem propagar um quadro corrompido por toda a rede. Se uma rede for composta por vários dispositivos de rede que operam em um modo de encaminhamento Cut-Through, um único quadro corrompido pode fazer com que os contadores de erro de entrada e de erro de saída incrementem em vários dispositivos de rede na rede.
Rastrear e isolar os erros de CRC
A primeira etapa para identificar e resolver a causa raiz dos erros de CRC é isolar a origem dos erros de CRC em um link específico entre dois dispositivos na rede. Um dispositivo conectado a esse link pode ter um contador de erros de saída de interface com um valor zero ou não está incrementando, enquanto o outro dispositivo conectado a esse link pode ter um contador de erros de entrada de interface diferente de zero ou incrementando. Isso sugere que o tráfego sai da interface de um dispositivo intacto é corrompido no momento da transmissão para o dispositivo remoto e é contado como um erro de entrada pela interface de entrada do outro dispositivo no link.
Identificar esse link em uma rede que consiste em dispositivos de rede operando em um modo de encaminhamento Store-and-Forward é uma tarefa simples. No entanto, se você identificar esse link em uma rede que consiste em dispositivos de rede operando em um modo de encaminhamento Cut-Through, será mais difícil, pois muitos dispositivos de rede podem ter contadores de erro de entrada e saída diferentes de zero. Um exemplo desse fenômeno pode ser visto na topologia aqui, onde o link destacado em vermelho é danificado de forma que o tráfego atravessa o link é corrompido. As interfaces marcadas com um "I" vermelho indicam as interfaces que podem ter erros de entrada diferentes de zero, enquanto as interfaces marcadas com um "O" azul indicam as interfaces que podem ter erros de saída diferentes de zero.

Este documento descreve os erros de Cyclic Redundancy Check (CRC) observados nos contadores de interface e nas estatísticas dos switches Cisco Nexus.
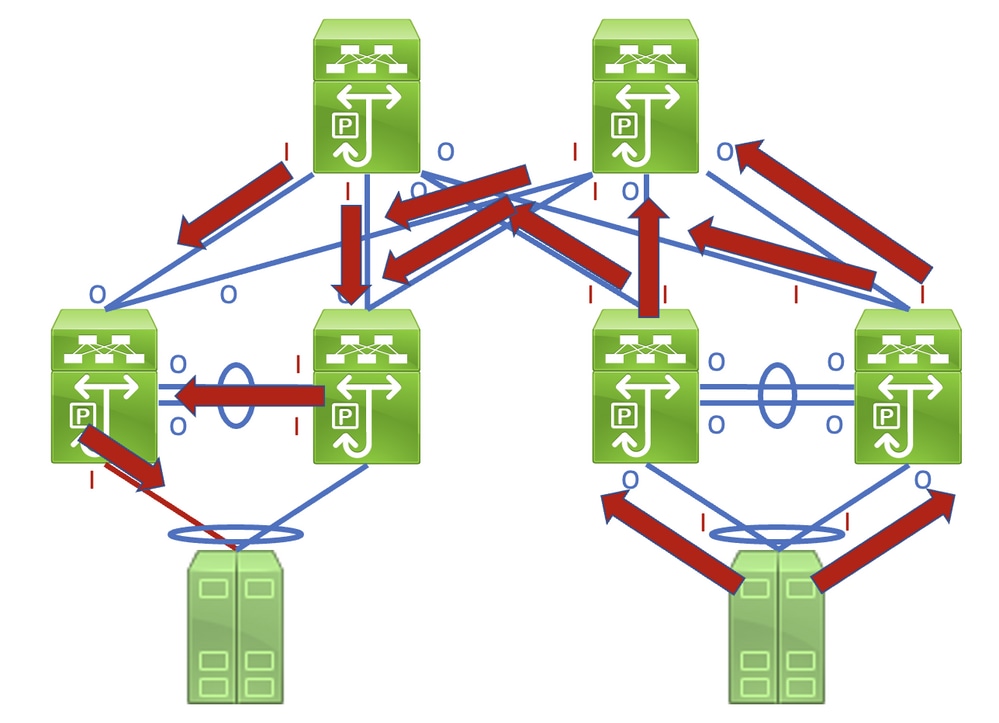
Um processo detalhado para rastrear e identificar um link danificado é melhor demonstrado através de um exemplo. Considere esta topologia:

Nesta topologia, a interface Ethernet1/1 de um switch Nexus chamado Switch-1 está conectada a um host chamado Host-1 por meio da NIC eth0 do Host-1. A interface Ethernet1/2 do Switch-1 está conectada a um segundo switch Nexus, denominado Switch-2, por meio da interface Ethernet1/2 do Switch-2. A interface Ethernet1/1 do Switch-2 está conectada a um host denominado Host-2 através da NIC eth0 do Host-2.
O link entre o Host-1 e o Switch-1 através da interface Ethernet1/1 do Switch-1 está danificado e faz com que o tráfego que atravessa o link seja corrompido intermitentemente. No entanto, não se sabe se o link está danificado neste ponto. Você deve rastrear o caminho que os quadros corrompidos deixam na rede através de contadores de erro de entrada e saída diferentes de zero ou incrementados para localizar o link danificado nessa rede.
Neste exemplo, a placa de rede Host-2 relata que está recebendo erros de CRC.
Host-2$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
Você sabe que a NIC do Host-2 se conecta ao Switch-2 através da interface Ethernet1/1. Você pode confirmar se a interface Ethernet1/1 tem um contador de erros de saída diferente de zero com o comando show interface.
Switch-2# show interface
<snip>
Ethernet1/1 is up
admin state is up, Dedicated Interface
RX
30184570 unicast packets 872 multicast packets 273 broadcast packets
30185715 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
444907944 unicast packets 932 multicast packets 102 broadcast packets
444908978 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Como o contador de erros de saída da interface Ethernet1/1 é diferente de zero, provavelmente há outra interface do Switch-2 com um contador de erros de entrada diferente de zero. Você pode usar o comando show interface counters errors non-zero para identificar se alguma interface do Switch-2 tem um contador de erros de entrada diferente de zero.
Switch-2# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 0 478920 0 0 0 Eth1/2 0 478920 0 478920 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
Você pode ver que a Ethernet1/2 do Switch-2 tem um contador de erros de entrada diferente de zero. Isso indica que o Switch-2 está recebendo o tráfego corrompido nessa interface. Você pode confirmar qual dispositivo está conectado a Ethernet1/2 do Switch-2 usando os recursos Cisco Discovery Protocol (CDP) ou Link Local Discovery Protocol (LLDP). Um exemplo disso é mostrado abaixo com o comando show cdp fields.
Switch-2# show cdp neighbors
<snip>
Capability Codes: R - Router, T - Trans-Bridge, B - Source-Route-Bridge
S - Switch, H - Host, I - IGMP, r - Repeater,
V - VoIP-Phone, D - Remotely-Managed-Device,
s - Supports-STP-Dispute
Device-ID Local Intrfce Hldtme Capability Platform Port ID
Switch-1(FDO12345678)
Eth1/2 125 R S I s N9K-C93180YC- Eth1/2
Agora você sabe que o Switch-2 está recebendo tráfego corrompido em sua interface Ethernet1/2 da interface Ethernet1/2 do Switch-1, mas você ainda não sabe se o link entre a Ethernet1/2 do Switch-1 e a Ethernet1/2 do Switch-2 está danificado e causa a corrupção, ou se o Switch-1 é um switch cut-through encaminhando tráfego corrompido que está recebendo. Você deve fazer login no Switch-1 para verificar isso.
Você pode confirmar se a interface Ethernet1/2 do Switch-1 tem um contador de erros de saída diferente de zero com o comando show interfaces.
Switch-1# show interface
<snip>
Ethernet1/2 is up
admin state is up, Dedicated Interface
RX
30581666 unicast packets 178 multicast packets 931 broadcast packets
30582775 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
454301132 unicast packets 734 multicast packets 72 broadcast packets
454301938 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Você pode ver que a Ethernet1/2 do Switch-1 tem um contador de erros de saída diferente de zero. Isso sugere que o link entre a Ethernet1/2 do Switch-1 e a Ethernet1/2 do Switch-2 não está danificado; em vez disso, o Switch-1 é um switch cut-through que encaminha tráfego corrompido que recebe em alguma outra interface. Como demonstrado anteriormente com o Switch-2, você pode usar o comandoshow interface counters errors non-zeropara identificar se qualquer interface do Switch-1 tem um contador de erros de entrada diferente de zero.
Switch-1# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 478920 0 478920 0 0 Eth1/2 0 0 478920 0 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
Você pode ver que a Ethernet1/1 do Switch-1 tem um contador de erros de entrada diferente de zero. Isso indica que o Switch-1 está recebendo o tráfego corrompido nessa interface. Você sabe que essa interface se conecta à placa de rede eth0 do Host-1. Você pode revisar as estatísticas da interface da NIC eth0 do Host-1 para confirmar se o Host-1 envia quadros corrompidos para fora dessa interface.
Host-1$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
73146816142 423112898 0 0 0 437368817
TX: bytes packets errors dropped carrier collsns
3312398924 37942624 0 0 0 0
altname enp11s0
As estatísticas da placa de rede eth0 do Host-1 sugerem que o host não transmite tráfego corrompido. Isso indica que o link entre a eth0 do Host-1 e a Ethernet1/1 do Switch-1 está danificado e é a origem desse tráfego corrompido. Você precisa solucionar esse link para identificar e substituir o componente defeituoso que causa o corrompimento.
Causas dos erros de CRC
A causa do problema mais comum dos erros de CRC é um componente danificado ou com defeito de um link físico entre dois dispositivos. Por exemplo:
- Mídia física com falha ou danificada (cobre ou fibra) ou DACs (Direct Attach Cables, cabos de conexão direta).
- Transceptores/óticas com falha ou danificados.
- Portas do patch panel com falha ou danificadas.
- Hardware de dispositivo de rede defeituoso (isso inclui portas específicas, ASICs [Application-Specific Integrated Circuits] de placa de linha, MACs [Media Access Controls], módulos de estrutura, etc.).
- Placa de interface de rede com defeito inserida em um host.
Também é possível que um ou mais dispositivos configurados de forma incorreta causem erros de CRC inadvertidamente em uma rede. Um exemplo disso é uma incompatibilidade de configuração de MTU (Unidade máxima de transmissão) entre dois ou mais dispositivos na rede que faz com que pacotes grandes sejam truncados incorretamente. Quando você identifica e resolve esse problema de configuração, ele também pode corrigir erros de CRC em uma rede.
Resolver os erros de CRC
Você pode identificar o componente específico com defeito por meio de um processo de eliminação:
- Substitua a mídia física (cobre ou fibra) ou o DAC por uma mídia física em boas condições do mesmo tipo.
- Substitua o transceptor inserido em uma interface de dispositivo por um transceptor em boas condições do mesmo modelo. Se isso não resolver os erros de CRC, substitua o transceptor inserido na interface do outro dispositivo por um transceptor em boas condições do mesmo modelo.
- Se algum patch panel for usado como parte do link danificado, mova o link para uma porta em boas condições no patch panel. Como alternativa, elimine o patch panel como uma possível causa raiz conectando o link sem o patch panel, se possível.
- Mova o link danificado para uma porta diferente e em boas condições em cada dispositivo. Você pode precisar testar várias portas diferentes para isolar uma falha de placa de linha, MAC ou ASIC.
- Se o link danificado envolver um host, mova o link para uma NIC diferente no host. Como alternativa, conecte o link danificado a um host em boas condições para isolar uma falha da placa de rede do host.
Se o componente com defeito for um produto da Cisco (como um dispositivo de rede ou transceptor da Cisco) coberto por um contrato de suporte ativo, você poderá abrir um caso de suporte no Cisco TAC, incluir os detalhes do problema e substituir o componente com defeito através de uma RMA (Autorização de devolução de material).
Informações Relacionadas
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
3.0 |
10-Nov-2021 |
Melhorar a formatação secundária do documento |
2.0 |
10-Nov-2021 |
Versão inicial |
1.0 |
10-Nov-2021 |
Versão inicial |
Colaborado por engenheiros da Cisco
- Christopher HartEngenheiro do Cisco TAC
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)