Introdução
Este documento descreve o Cisco Express Forwarding (CEF) switching e como ele é implementado no Cisco 12000 Series Internet Router.
Pré-requisitos
Requisitos
Não existem requisitos específicos para este documento.
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Conventions
Para obter mais informações sobre convenções de documento, consulte as Convenções de dicas técnicas Cisco.
Overview
O switching Cisco Express Forwarding (CEF) é uma forma proprietária de switching escalável destinada a resolver os problemas associados ao cache de demanda. Com a switching de CEF, as informações convencionalmente armazenadas em um cache de rota são divididas em diversas estruturas de dados. O código CEF é capaz de manter essas estruturas de dados no GRP (Gigabit Route Processor) e também em processadores secundários, como as placas de linha nos roteadores 12000. As estruturas de dados que fornecem consulta otimizada para encaminhamento eficiente de pacotes incluem:
-
Uma tabela de Base de informações de encaminhamento (FIB) - CEF usa uma FIB para tomar decisões de switching com base em prefixos de IP de destino. O FIB é conceitualmente similar a uma tabela de roteamento ou banco de informações. Ele mantém uma imagem de espelho das informações de encaminhamento contidas na tabela de IP Routing. Quando ocorrem alterações de roteamento ou de topologia na rede, a tabela de IP Routing é atualizada, e essas alterações são refletidas no FIB. O FIB mantém informações de endereço do próximo salto baseadas nas informações na tabela de IP Routing. Devido ao fato de haver uma correlação de um para um entre as entradas de FIB e as entradas da tabela de roteamento, o FIB contém todas as rotas conhecidas e elimina a necessidade da manutenção de cache de rota que é associada a caminhos de switching, como, por exemplo, switching rápida ou ótima.
-
Tabela de adjacências – Os nós na rede são considerados adjacentes se puderem ser alcançados entre si com um único salto em uma camada do enlace. Além da FIB, o CEF usa tabelas de adjacência para anexar informações de endereçamento da Camada 2. A tabela de adjacência mantém os endereços Layer 2 Next-Hop para todas as entradas de FIB.
O CEF pode ser habilitado em um de dois modos:
-
Modo CEF central - Quando o modo CEF estiver ativado, o FIB CEF e as tabelas adjacentes residirão no processador do roteador e o processador da rota executará o express forwarding. Você pode utilizar o modo CEF quando não há placas de linha disponíveis para switching CED ou quando você precisa utilizar recursos que não são compatíveis com switching CEF distribuída.
-
Modo CEF distribuído (dCEF) quando o dCEF está ativado, as placas de linha mantêm cópias idênticas das tabelas da FIB e de adjacências. As placas de linha podem executar o encaminhamento expresso sozinhas e isso libera o processador principal - o GRP (Gigabit Route Processor) - do envolvimento na operação de switching. Este é o único método de switching disponível no Cisco 12000 Series Router.
O dCEF utiliza um mecanismo de Comunicação Inter-Processo (IPC) para garantir a sincronização de FIBs e das tabelas da adjacência no processador da rota e nas placas de linha.
Para obter mais informações sobre o switching do CEF, consulte o white paper do Cisco Express Forwarding (CEF).
Operações de CEF
Atualizar as tabelas de roteamento GRPs
A Figura 1 ilustra o processo pelo qual um pacote de atualização de roteamento é enviado ao GRP (Gigabit Route Processor) e as mensagens de atualização de encaminhamento resultantes são enviadas para tabelas FIB nas placas de linha.
Por motivos de clareza, a numeração dos parágrafos seguintes corresponde à numeração da figura 1.
O próximo processo ocorre durante a inicialização da tabela de rotas ou sempre que a topologia da rede é alterada (quando as rotas são adicionadas, removidas ou alteradas). O processo exibido na Figura 1 envolve cinco passos principais:
-
Um datagrama de IP é colocado nos buffers de entrada da placa de ingresso de recebimento (placa de ingresso de entrada) e o mecanismo de encaminhamento L2/L3 acessa as informações da Camada 2 e da Camada 3 no pacote e as envia ao processador de encaminhamento. O processador de encaminhamento determina se o pacote contém informações de roteamento. O processador de encaminhamento envia o ponteiro para a fila de saída virtual (VOQ) do GRP e indica que o pacote na memória do buffer deve ser enviado para o GRP.
-
A placa de linha emite uma solicitação para a CSC (Placa escalonadora de relógio). A placa programadora emite uma concessão e o pacote é enviado através da matriz de comutação para o GRP.
-
O GRP processa as informações de roteamento. O R5000 (processador) no GRP atualiza a tabela de roteamento da rede. Dependendo das informações de roteamento no pacote, o processador de Camada 3 pode ter que inundar informações de link-state para roteadores adjacentes (se o protocolo de roteamento interno for Open Shortest Path First [OSPF]). O processador gera os pacotes de IP que transportam as informações do estado de enlace e a atualização interna das tabelas de FIB. Além disso, o GRP calcula todas as rotas recursivas que ocorrem quando o suporte é fornecido para um protocolo interno e protocolos de gateway externo (por exemplo, Border Gateway Protocol [BGP]).
As informações de rota recursiva calculada são enviadas para os FIBs em cada placa de linha. Isso acelera significativamente o processo de encaminhamento, porque o processador da camada 3 na placa de linha pode se concentrar no encaminhamento do pacote e não calcula a rota recursiva.
-
O GRP envia atualizações internas para tabelas FIB em todas as placas de linha e inclui aquelas localizadas no GRP. As atualizações de FIB nas placas de linha são monitoradas e suspensas, se necessário. O GRP tem uma cópia de cada tabela FIB de placa de linha, portanto, se uma nova placa de linha for inserida no chassi, o GRP fará o download das informações de encaminhamento mais recentes para a nova placa assim que ela se tornar ativa.
-
O GRP é notificado, a partir das placas de ingresso, sempre que um novo roteador vizinho é conectado ao roteador 12000. O processador na placa de linha envia um pacote para o GRP que contém as novas informações da camada 2 (normalmente informações de cabeçalho do Protocolo Ponto a Ponto (PPP - Point-to-Point Protocol)). O GRP utiliza as informações da Camada 2 para atualizar a tabela de adjacência localizada no GRP e nas placas de linha. Cada placa de linha adiciona essas informações da camada 2 a cada pacote à medida que os pacotes são enviados do roteador 12000. Uma cópia da tabela de adjacências é mantida no GRP para fins de inicialização.
Figura 1: Determinação de caminho e diagrama de switching de camada 3
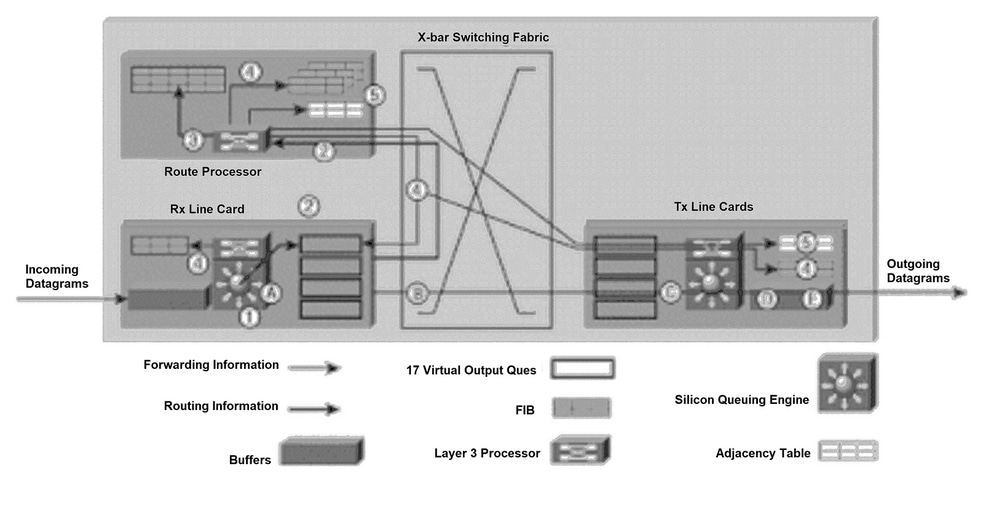 Diagrama de determinação de caminho e switching da Camada 3
Diagrama de determinação de caminho e switching da Camada 3
Encaminhamento de pacotes para todas as placas de linha, exceto OC48 e QOC12
Quando as placas de linha tiverem informações de encaminhamento suficientes para determinar o caminho através da tela de switching (por exemplo, o destino do próximo salto), o roteador 12000 estará pronto para encaminhar os pacotes. As próximas etapas descrevem a técnica de encaminhamento simples e rápido usada pelo roteador 12000 (consulte a Figura 1). Por questões de clareza, o espaçamento das letras dos parágrafos corresponde ao espaçamento das letras na Figura 1.
-
R. Um datagrama IP é colocado nos buffers de entrada na placa de linha receptora (placa de linha Rx) e o mecanismo de encaminhamento L2/L3 acessa as informações das Camadas 2 e 3 no pacote e as envia ao processador de encaminhamento. O processador de encaminhamento determina se o pacote contém dados e não é uma atualização de roteamento. Com base nas informações de Camada 2 e Camada 3 na tabela FIB, o processador de encaminhamento envia o ponteiro para a placa de linha VOQ apropriada, indicando que o pacote na memória de buffer deve ser enviado para essa placa de linha.
-
B.O programador da placa de linha emite uma solicitação para o programador. O programador emite uma concessão e o pacote é enviado da memória do buffer à placa de linha (placa de linha de transmissão) pela tela de switching.
-
C.A placa de linha Tx coloca em buffer os pacotes de entrada.
-
D.O processador de Camada 3 e os ASICs (Application-Specific Integrated Circuits) associados na placa de linha Tx anexam as informações de Camada 2 (um endereço PPP) a cada pacote transmitido. O pacote está duplicado em cada porta na placa de linha (se for necessário).
-
E.Os transmissores da placa de linha Tx enviam o pacote pela interface de fibra.
A vantagem desse processo de encaminhamento simples é que a maioria das tarefas de transmissão de dados pode ser feita em ASICs e permite que o 12000 opere em taxas de gigabit. Além disso, os pacotes de dados nunca são enviados ao GRP.
Encaminhamento de pacote para placas de linha OC48 e QOC12
Quando as placas de linha têm informações de encaminhamento suficientes para determinar o caminho através da matriz de comutação (por exemplo, o destino do próximo salto), o roteador 12000 está pronto para encaminhar pacotes. As próximas etapas compõem a técnica de encaminhamento simples e hiperrápida usada pelo 12000 (consulte a Figura 2). Por questões de clareza, o espaçamento das letras dos parágrafos corresponde ao espaçamento das letras na Figura 2.
-
R. Um datagrama IP (não uma atualização de roteamento, Internet Control Message Protocol (ICMP) e pacotes IP com opções) é recebido na placa de linha e passa pelo processamento da camada 2. Com base nas informações das camadas 2 e 3 na tabela FIB local, o Fast Packet Processor determina o destino do pacote e modifica o cabeçalho do pacote. Com base no destino, o pacote é colocado na VOQ da placa de linha apropriada.
-
B. No raro caso em que o Fast Packet Processor não consegue encaminhar o pacote corretamente, o pacote é processado pelo processador de encaminhamento. O processador de encaminhamento, com base nas informações das camadas 2 e 3 da sua tabela FIB local, envia o ponteiro para a placa de linha VOQ apropriada, que indica que o pacote na memória de buffer deve ser enviado para essa placa de linha.
-
C. Quando o pacote estiver na VOQ apropriada, o programador da placa de linha emitirá uma solicitação para o programador. O programador emite uma concessão e o pacote é enviado da memória do buffer à placa de linha (placa de linha de transmissão) pela tela de switching.
-
D. A placa de linha Tx coloca os pacotes de entrada em buffer.
-
E. O processador de Camada 3 e os ASICs associados na placa de linha Tx anexam as informações de Camada 2 (um endereço PPP) a cada pacote transmitido. O pacote está duplicado em cada porta na placa de linha (se for necessário).
-
F. Os transmissores da placa de linha Tx enviam o pacote pela interface de fibra.
A vantagem do novo processo de encaminhamento é que ele otimiza a placa especificamente para velocidades maiores, por exemplo, OC48/STM16.
Figura 2: Comutação de pacotes para placas de linha mais rápidas
 Switching de pacote para placas de linha mais rápidas
Switching de pacote para placas de linha mais rápidas
Informações Relacionadas
 Feedback
Feedback