Solucionar problemas de falhas de caminho de dados do ASR 9000 Series Punt Fabric
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Introdução
Este documento descreve as mensagens de falha de caminho de dados de estrutura de punt vistas durante a operação do Cisco Aggregation Services Router (ASR) 9000 Series.
A mensagem aparece neste formato:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
Este documento destina-se a qualquer pessoa que queira entender a mensagem de erro e as ações a serem tomadas se o problema for visto.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha um conhecimento de alto nível sobre estes tópicos:
- Placas de linha ASR 9000
- Placas de malha
- Processadores de roteamento
- Arquitetura do chassi
No entanto, este documento não exige que os leitores estejam familiarizados com os detalhes do hardware. As informações básicas necessárias são fornecidas antes que a mensagem de erro seja explicada. Este documento descreve o erro em placas de linha baseadas em Trident e Typhoon. Consulte Compreender os tipos de placas de linha do ASR 9000 Series para obter uma explicação desses termos.
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Como usar este documento
Considere estas sugestões sobre como usar este documento para obter detalhes essenciais e como um guia de referência no processo de solução de problemas:
- Quando não houver urgência em fazer com que a raiz cause uma falha no caminho de dados da estrutura de punt, leia todas as seções deste documento. Este documento cria o plano de fundo necessário para isolar um componente defeituoso quando tal erro ocorre.
- Use a seção FAQ se tiver em mente uma pergunta específica para a qual é necessária uma resposta rápida. Se a pergunta não estiver incluída na seção FAQ, verifique se o documento principal aborda a pergunta.
- Use todas as seções de Analisar falhas em para isolar o problema em um componente defeituoso quando um roteador tiver uma falha ou para verificar se é um problema conhecido.
Informações de Apoio
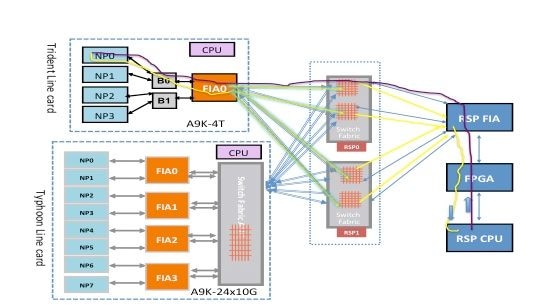
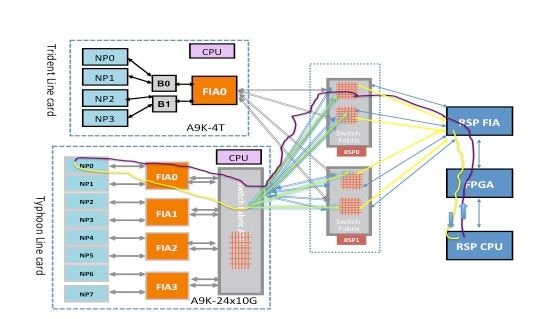
Um pacote pode atravessar dois saltos ou três saltos através da matriz de comutação com base no tipo de placa de linha. As placas de linha de geração de tufão adicionam um elemento de matriz de comutação extra, enquanto as placas de linha baseadas em Trident comutam todo o tráfego com a matriz apenas na placa do processador de rotas. Esses diagramas mostram os elementos de estrutura para ambos os tipos de placas de linha, bem como a conectividade de estrutura para a placa do processador de roteamento:

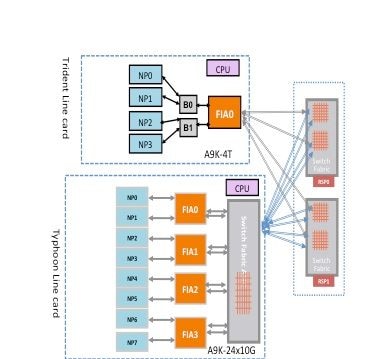
Caminho do Pacote de Diagnóstico de Estrutura Punt
O aplicativo de diagnóstico que é executado na CPU da placa do processador de rotas injeta periodicamente pacotes de diagnóstico destinados a cada processador de rede (NP). O pacote de diagnóstico tem loopback dentro do NP e é injetado novamente na CPU da placa do processador de rotas que originou o pacote. Essa verificação periódica da integridade de cada NP com um pacote exclusivo por NP pelo aplicativo de diagnóstico na placa do processador de rotas fornece um alerta para quaisquer erros funcionais no caminho de dados durante a operação do roteador. É essencial observar que a aplicação de diagnóstico no processador de rota ativo e no processador de rota em standby injeta um pacote por NP periodicamente e mantém uma contagem de êxito ou falha por NP. Quando um limite de pacotes de diagnóstico descartados é atingido, o aplicativo gera uma falha.
Visão Conceitual do Caminho de Diagnóstico
Antes que o documento descreva o caminho de diagnóstico em placas de linha baseadas em Trident e Typhoon, esta seção fornece um esboço geral do caminho de diagnóstico de estrutura das placas do processador de rota ativa e de standby em direção ao NP na placa de linha.
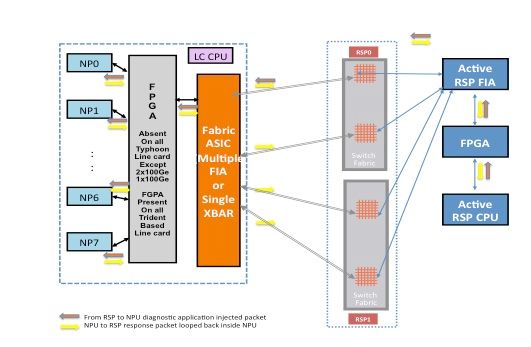
Caminho do pacote entre a placa do processador de rotas ativo e a placa de linha
Os pacotes de diagnóstico injetados do processador de rota ativa na estrutura em direção ao NP são tratados como pacotes unicast pela matriz de comutação. Com pacotes unicast, a matriz de comutação escolhe o link de saída com base na carga de tráfego atual do link, o que ajuda a submeter os pacotes de diagnóstico à carga de tráfego no roteador. Quando há vários links de saída em direção ao NP, o ASIC da matriz de comutação escolhe um link que atualmente é o menos carregado.
Este diagrama representa o caminho do pacote de diagnóstico originado do processador de rota ativo.
Observação: o primeiro link que conecta o ASIC de interface de estrutura (FIA) na placa de linha à barra cruzada (XBAR) na placa do processador de rotas é escolhido o tempo todo para pacotes destinados ao NP. Os pacotes de resposta do NP estão sujeitos a um algoritmo de distribuição de carga de link (se a placa de linha for baseada em tufão). Isso significa que o pacote de resposta do NP em direção ao processador de rota ativo pode escolher qualquer um dos links de estrutura que conectam placas de linha à placa do processador de rota com base na carga do link de estrutura.
Caminho do pacote entre a placa do processador de rotas em standby e a placa de linha
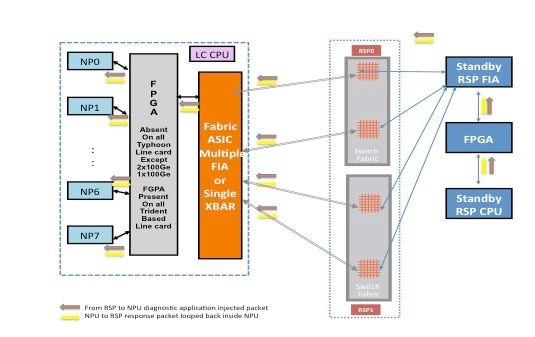
Os pacotes de diagnóstico injetados do processador de rota em standby na estrutura em direção ao NP são tratados como pacotes multicast pela matriz de comutação. Embora seja um pacote multicast, não há replicação dentro da estrutura. Cada pacote de diagnóstico originado do processador de rota em standby ainda alcança apenas um NP de cada vez. O pacote de resposta do NP para o processador de rota também é um pacote multicast sobre a estrutura sem replicação. Portanto, a aplicação de diagnóstico no processador de rota em standby recebe um único pacote de resposta dos NPs, um pacote de cada vez. A aplicação de diagnóstico rastreia cada NP no sistema, porque injeta um pacote por NP, e espera respostas de cada NP, um pacote de cada vez. Com um pacote multicast, a matriz de comutação escolhe o link de saída com base em um valor de campo no cabeçalho do pacote, que ajuda a injetar pacotes de diagnóstico em cada link de estrutura entre a placa do processador de rotas e a placa de linha. O processador de roteamento em standby rastreia a integridade de NP em cada link de estrutura que se conecta entre a placa do processador de roteamento e o slot da placa de linha.
O diagrama anterior representa o caminho do pacote de diagnóstico originado do processador de rota em standby. Observe que, ao contrário do caso do processador de rota ativo, todos os links que conectam a placa de linha ao XBAR no processador de rota são exercidos. Os pacotes de resposta do NP usam o mesmo link de estrutura que foi usado pelo pacote no processador de rota para a direção da placa de linha. Esse teste garante que todos os links que conectam o processador de rota de standby à placa de linha sejam monitorados continuamente.
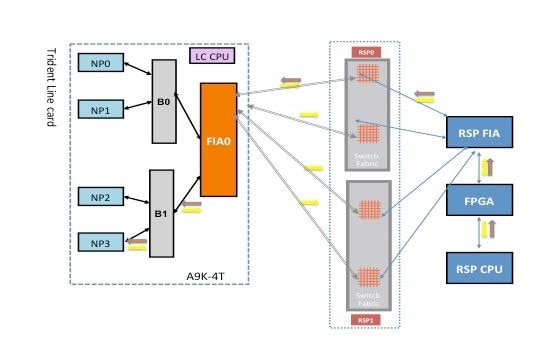
Caminho do Pacote de Diagnóstico de Estrutura Punt na Placa de Linha Baseada em Tridente
Este diagrama representa os pacotes de diagnóstico originados do processador de rota destinados a um NP que tem loopback em direção ao processador de rota. É importante observar os enlaces de caminho de dados e ASICs que são comuns a todos os NPs, bem como enlaces e componentes que são específicos a um subconjunto de NPs. Por exemplo, a Bridge ASIC 0 (B0) é comum a NP0 e NP1, enquanto a FIA0 é comum a todos os NPs. Na extremidade do processador de rotas, todos os links, ASICs de caminho de dados e FPGA (Field-Programmable Gate Array) são comuns a todas as placas de linha e, portanto, a todos os NPs em um chassi.
Caminho do Pacote de Diagnóstico de Estrutura Punt na Placa de Linha Baseada em Tufão
Este diagrama representa os pacotes de diagnóstico originados na placa do processador de rota destinados a um NP que tem loopback em direção ao processador de rota. É importante observar os enlaces de caminho de dados e ASICs que são comuns a todos os NPs, bem como enlaces e componentes que são específicos a um subconjunto de NPs. Por exemplo, FIA0 é comum a NP0 e NP1. Na extremidade da placa do processador de rotas, todos os enlaces, ASICs de caminho de dados e o FGPA são comuns a todas as placas de linha e, portanto, a todos os NPs em um chassi.
Caminho do pacote de diagnóstico de estrutura punt na placa de linha baseada em Tomahawk, Lightspeed e LightspeedPlus
Nas placas de linha Tomahawk há conectividade 1:1 entre o FIA e o NP.
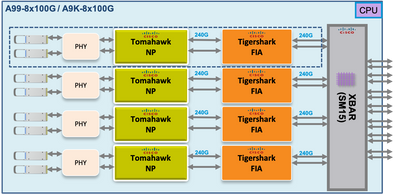
Nas placas de linha Lightspeed e LightspeedPlus, o FIA está integrado no chip NP.

As próximas seções tentam representar o caminho do pacote para cada NP. Isso é necessário para entender a mensagem de erro do caminho de dados da estrutura de punt e também para localizar o ponto de falha.
Alarme de diagnóstico de malha punt e relatório de falha
A falha em obter respostas de um NP em um roteador baseado em ASR 9000 resulta em um alarme. A decisão de acionar um alarme pelo aplicativo de diagnóstico on-line que é executado no processador de rota ocorre quando há três falhas consecutivas. O aplicativo de diagnóstico mantém uma janela de falha de três pacotes para cada NP. O processador de rotas ativo e o processador de rotas em standby fazem diagnósticos independentemente e em paralelo. O processador de rotas ativo, o processador de rotas em standby ou as duas placas do processador de rotas podem relatar o erro. O local da falha e da perda de pacotes determinam qual processador de rota relata o alarme.
A frequência padrão do pacote de diagnóstico em direção a cada NP é um pacote por 60 segundos ou um por minuto.
Aqui está o formato da mensagem de alarme:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
A mensagem mostra uma falha ao acessar NP 1, 2, 3, 4, 5, 6 e 7 na placa de linha 0/7/cpu0 do processador de rota 0/rsp0/cpu0.
Na lista de testes de diagnóstico on-line, você pode ver os atributos do teste de loopback de tela de punt com este comando:
RP/0/RSP0/CPU0:iox(admin)#show diagnostic content location 0/RSP0/CPU0
RP 0/RSP0/CPU0:
Diagnostics test suite attributes:
M/C/* - Minimal bootup level test / Complete bootup level test / NA
B/O/* - Basic ondemand test / not Ondemand test / NA
P/V/* - Per port test / Per device test / NA
D/N/* - Disruptive test / Non-disruptive test / NA
S/* - Only applicable to standby unit / NA
X/* - Not a health monitoring test / NA
F/* - Fixed monitoring interval test / NA
E/* - Always enabled monitoring test / NA
A/I - Monitoring is active / Monitoring is inactive
Test Interval Thre-
ID Test Name Attributes (day hh:mm:ss.ms shold)
==== ================================== ============ ================= =====
1) PuntFPGAScratchRegister ---------- *B*N****A 000 00:01:00.000 1
2) FIAScratchRegister --------------- *B*N****A 000 00:01:00.000 1
3) ClkCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
4) IntCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
5) CPUCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
6) FabSwitchIdRegister -------------- *B*N****A 000 00:01:00.000 1
7) EccSbeTest ----------------------- *B*N****I 000 00:01:00.000 3
8) SrspStandbyEobcHeartbeat --------- *B*NS***A 000 00:00:05.000 3
9) SrspActiveEobcHeartbeat ---------- *B*NS***A 000 00:00:05.000 3
10) FabricLoopback ------------------- MB*N****A 000 00:01:00.000 3
11) PuntFabricDataPath --------------- *B*N****A 000 00:01:00.000 3
12) FPDimageVerify ------------------- *B*N****I 001 00:00:00.000 1
RP/0/RSP0/CPU0:ios(admin)#
A saída mostra que a frequência de teste PuntFabricDataPath é de um pacote a cada minuto e o limite de falha é de três, o que implica que a perda de três pacotes consecutivos não é tolerada e resulta em um alarme. Os atributos de teste mostrados são valores padrão. Para alterar os padrões, insira o comando diagnostic monitor interval e diagnostic monitor threshold no modo de configuração de administração.
Caminho do pacote de diagnóstico da placa de linha baseada em tridente
Falha de diagnóstico NP0
Caminho de diagnóstico de estrutura
Este diagrama representa o caminho do pacote entre a CPU do processador de rotas e a placa de linha NP0. O link que conecta B0 e NP0 é o único link específico para NP0. Todos os outros links estão no caminho comum.
Anote o caminho do pacote do processador de rotas em direção à NP0. Embora existam quatro links a serem usados para pacotes destinados a NP0 do processador de rotas, o primeiro link entre o processador de rotas e o slot da placa de linha é usado para o pacote do processador de rotas em direção à placa de linha. O pacote retornado de NP0 pode ser enviado de volta ao processador de rota ativo por qualquer um dos dois caminhos de link de estrutura entre o slot da placa de linha e o processador de rota ativo. A escolha de qual dos dois links usar depende da carga do link naquele momento. O pacote de resposta de NP0 para o processador de rota em standby usa ambos os links, mas um link por vez. A escolha do link é baseada no campo de cabeçalho que o aplicativo de diagnóstico preenche.

Análise de Falha de Diagnóstico NP0
Cenário de falha única
Se for detectado um único alarme de falha de caminho de dados de malha punt do Platform Fault Manager (PFM) com apenas NP0 na mensagem de falha, a falha estará apenas no caminho de malha que conecta o processador de rota e a placa de linha NP0. Esta é uma falha única. Se a falha for detectada em mais de um NP, consulte a seção Cenário de Falhas Múltiplas.
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 0)
Observação: esta seção do documento se aplica a qualquer slot de placa de linha em um chassi, independentemente do tipo de chassi. Portanto, isso pode ser aplicado a todos os slots de placa de linha.
Como ilustrado no diagrama do caminho de dados anterior, a falha deve estar em um ou mais destes locais:
- Link que conecta NP0 e B0
- Filas B0 internas direcionadas para NP0
- NP0 Interno
Cenário de falha múltipla
Várias falhas NP
Quando outras falhas são observadas em NP0 ou a falha PUNT_FABRIC_DATA_PATH_FAILED também é relatada por outros NPs na mesma placa de linha, então o isolamento de falhas é feito correlacionando todas as falhas. Por exemplo, se a falha PUNT_FABRIC_DATA_PATH_FAILED e a falha LC_NP_LOOPBACK_FAILED ocorrerem em NP0, o NP terá parado de processar pacotes. Consulte a seção Caminho de diagnóstico de loopback NP para entender a falha de loopback. Isso pode ser uma indicação antecipada de uma falha crítica dentro de NP0. No entanto, se apenas uma das duas falhas ocorrer, a falha será localizada no caminho de dados da estrutura punt ou na CPU da placa de linha para o caminho NP.
Se mais de um NP em uma placa de linha tiver uma falha de caminho de dados de tela de punt, então você deve percorrer o caminho de árvore dos links de estrutura para isolar um componente com falha. Por exemplo, se NP0 e NP1 tiverem uma falha, a falha deverá estar em B0 ou no link que conecta B0 e FIA0. É menos provável que tanto NP0 quanto NP1 encontrem um erro interno crítico ao mesmo tempo. Embora seja menos provável, é possível que NP0 e NP1 encontrem uma falha de erro crítico devido ao processamento incorreto de um tipo específico de pacote ou de um pacote inválido.
As duas placas do processador de roteamento relatam uma falha
Se ambas as placas do processador de rota ativa e de standby relatarem uma falha a um ou mais NPs em uma placa de linha, verifique todos os links e componentes comuns no caminho de dados entre os NPs afetados e ambas as placas do processador de rota.
Falha de diagnóstico NP1
Este diagrama representa o caminho do pacote entre a CPU da placa do processador de rotas e a placa de linha NP1. O link que conecta a Ponte ASIC 0 (B0) e NP1 é o único link específico para NP1. Todos os outros links estão no caminho comum.
Anote o caminho do pacote da placa do processador de rotas em direção a NP1. Embora existam quatro links a serem usados para pacotes destinados a NP0 do processador de rotas, o primeiro link entre o processador de rotas e o slot da placa de linha é usado para o pacote do processador de rotas em direção à placa de linha. O pacote retornado de NP1 pode ser enviado de volta ao processador de rota ativo por qualquer um dos dois caminhos de link de estrutura entre o slot da placa de linha e o processador de rota ativo. A escolha de qual dos dois links usar depende da carga do link naquele momento. O pacote de resposta de NP1 para o processador de rota em standby usa ambos os links, mas um link por vez. A escolha do link é baseada no campo de cabeçalho que o aplicativo de diagnóstico preenche.
Caminho de diagnóstico de estrutura
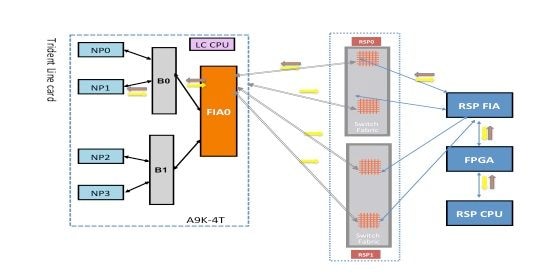
Análise de Falha de Diagnóstico NP1
Consulte a seção Análise de Falha de Diagnóstico NP0, mas aplique o mesmo raciocínio para NP1 (em vez de NP0).
Falha de diagnóstico NP2
Este diagrama representa o caminho do pacote entre a CPU da placa do processador de rotas e a placa de linha NP2. O link que conecta B1 e NP2 é o único link específico para NP2. Todos os outros links estão no caminho comum.
Anote o caminho do pacote da placa do processador de rotas em direção a NP2. Embora existam quatro links a serem usados para pacotes destinados a NP2 do processador de roteamento, o primeiro link entre o processador de roteamento e o slot da placa de linha é usado para o pacote do processador de roteamento em direção à placa de linha. O pacote retornado de NP2 pode ser enviado de volta ao processador de rota ativo por qualquer um dos dois caminhos de link de estrutura entre o slot da placa de linha e o processador de rota ativo. A escolha de qual dos dois links usar depende da carga do link naquele momento. O pacote de resposta de NP2 para o processador de rota em standby usa ambos os links, mas um link por vez. A escolha do link é baseada no campo de cabeçalho que o aplicativo de diagnóstico preenche.
Caminho de diagnóstico de estrutura
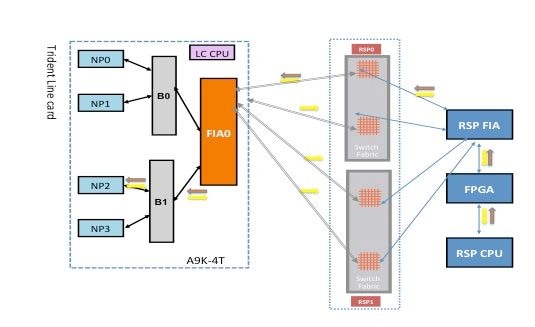
Análise de Falha de Diagnóstico NP2
Consulte a seção Análise de Falha de Diagnóstico NP0, mas aplique o mesmo raciocínio para NP2 (em vez de NP0).
Falha de diagnóstico NP3
Este diagrama representa o caminho do pacote entre a CPU da placa do processador de rotas e a placa de linha NP3. O link que conecta a Ponte ASIC 1 (B1) e NP3 é o único link específico para NP3. Todos os outros links estão no caminho comum.
Anote o caminho do pacote da placa do processador de rotas em direção a NP3. Embora existam quatro links a serem usados para pacotes destinados a NP3 do processador de rotas, o primeiro link entre o processador de rotas e o slot da placa de linha é usado para o pacote do processador de rotas em direção à placa de linha. O pacote retornado de NP3 pode ser enviado de volta ao processador de rota ativo por qualquer um dos dois caminhos de link de estrutura entre o slot da placa de linha e o processador de rota ativo. A escolha de qual dos dois links usar depende da carga do link naquele momento. O pacote de resposta de NP3 para o processador de rota em standby usa ambos os links, mas um link de cada vez. A escolha do link é baseada no campo de cabeçalho que o aplicativo de diagnóstico preenche.
Caminho de diagnóstico de estrutura
Análise de Falha de Diagnóstico NP3
Consulte a seção Análise de Falha de Diagnóstico NP0, mas aplique o mesmo raciocínio para NP3 (em vez de NP0).
Caminho do pacote de diagnóstico da placa de linha baseada em tufão
Esta seção fornece dois exemplos para estabelecer o plano de fundo para pacotes de punt de estrutura com placas de linha baseadas em tufão. O primeiro exemplo usa NP1, e o segundo exemplo usa NP3. A descrição e a análise podem ser estendidas para outros NPs em qualquer placa de linha baseada em tufão.
Falha de diagnóstico do tufão NP1
O próximo diagrama representa o caminho do pacote entre a CPU da placa do processador de rotas e a placa de linha NP1. O link que conecta FIA0 e NP1 é o único link específico para o caminho NP1. Todos os outros links entre o slot da placa de linha e o slot da placa do processador de roteamento estão no caminho comum. Os links que conectam o XBAR ASIC de estrutura na placa de linha aos FIAs na placa de linha são específicos para um subconjunto de NPs. Por exemplo, ambos os links entre FIA0 e a estrutura local XBAR ASIC na placa de linha são usados para tráfego para NP1.
Anote o caminho do pacote da placa do processador de rotas em direção a NP1. Embora existam oito links a serem usados para pacotes destinados a NP1 a partir da placa do processador de rotas, um único caminho entre a placa do processador de rotas e o slot da placa de linha é usado. O pacote retornado de NP1 pode ser enviado de volta para a placa do processador de roteamento por oito caminhos de link de estrutura entre o slot da placa de linha e o processador de roteamento. Cada um desses oito links é testado um de cada vez quando o pacote de diagnóstico é destinado de volta à CPU da placa do processador de rotas.
Caminho de diagnóstico de estrutura

Falha de Diagnóstico do Tufão NP3
Este diagrama representa o caminho do pacote entre a CPU da placa do processador de rotas e a placa de linha NP3. O link que conecta FIA1 e NP3 é o único link específico para o caminho NP3. Todos os outros links entre o slot da placa de linha e o slot da placa do processador de roteamento estão no caminho comum. Os links que conectam o XBAR ASIC de estrutura na placa de linha aos FIAs na placa de linha são específicos para um subconjunto de NPs. Por exemplo, ambos os links entre FIA1 e a estrutura local XBAR ASIC na placa de linha são usados para tráfego para NP3.
Anote o caminho do pacote da placa do processador de rotas em direção a NP3. Embora existam oito links a serem usados para pacotes destinados a NP3 a partir da placa do processador de rotas, um único caminho entre a placa do processador de rotas e o slot da placa de linha é usado. O pacote retornado de NP1 pode ser enviado de volta para a placa do processador de roteamento por oito caminhos de link de estrutura entre o slot da placa de linha e o processador de roteamento. Cada um desses oito links é testado um de cada vez quando o pacote de diagnóstico é destinado de volta à CPU da placa do processador de rotas.
Caminho de diagnóstico de estrutura

Caminho do pacote de diagnóstico da placa de linha baseada em Tomahawk
Devido à conectividade 1:1 entre o FIA e o NP, o único tráfego que atravessa o FIA0 é de/para NP0.
Caminho de pacote de diagnóstico de placa de linha com base em Lightspeed e LightspeedPlus
Como o FIA está integrado no chip NP, o único tráfego que atravessa o FIA0 é de/para NP0.
Analisar falhas
Esta seção categoriza as falhas em casos de hardware e transientes e lista as etapas usadas para identificar se uma falha é de hardware ou transitória. Uma vez determinado o tipo de falha, o documento especifica os comandos que podem ser executados no roteador para entender a falha e quais ações corretivas são necessárias.
Falha transitória
Se uma mensagem PFM definida for seguida por uma mensagem PFM limpa, então ocorreu uma falha e o roteador corrigiu a falha. Falhas transitórias podem ocorrer devido a condições ambientais e falhas recuperáveis em componentes de hardware. Às vezes, pode ser difícil associar falhas transitórias a qualquer evento em particular.
Um exemplo de uma falha de malha transitória é listado aqui para maior clareza:
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
RP/0/RSP0/CPU0:Feb 5 05:05:46.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Ações de Correção de Falhas Transitórias
A abordagem sugerida para erros transitórios é monitorar somente a ocorrência futura de tais erros. Se uma falha transitória ocorrer mais de uma vez, trate a falha transitória como uma falha física e use as recomendações e etapas para analisar tais falhas descritas na próxima seção.
Falha de hardware
Se uma mensagem PFM definida não for seguida por uma mensagem PFM clara, ocorreu uma falha e o roteador não corrigiu a falha em si pelo código de tratamento de falhas ou a natureza da falha de hardware não é recuperável. Falhas graves podem ocorrer devido a condições ambientais e falhas irrecuperáveis em componentes de hardware. A abordagem sugerida para falhas graves é usar as diretrizes mencionadas na seção Analisar falhas graves.
Um exemplo de falha de malha de hardware é listado aqui para maior clareza. Para esta mensagem de exemplo, não há uma mensagem PFM clara correspondente.
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
Ações corretivas de falha grave
Em um cenário de falha grave, colete todos os comandos mencionados na seção Dados a Serem Coletados Antes da Criação da Solicitação de Serviço e abra uma solicitação de serviço. Em casos urgentes, depois de coletar toda a saída do comando de identificação e solução de problemas, inicie uma placa do processador de rotas ou uma recarga da placa de linha com base no isolamento de falha. Após o recarregamento, se o erro não for recuperado, inicie uma RMA (Return Material Authorization, Autorização para devolução de materiais).
Analisar Falhas Transitórias
Conclua estas etapas para analisar falhas transitórias.
- Digite o
show logging | inc “PUNT_FABRIC_DATA_PATH"para descobrir se o erro ocorreu uma ou várias vezes. - Digite o
show pfm location allpara determinar o status atual (SET ou CLEAR). O erro está pendente ou foi apagado? Se o status do erro mudar entre SET e CLEAR, uma ou mais falhas no caminho de dados da estrutura ocorrerão repetidamente e serão corrigidas por software ou hardware. - Provisione interceptações SNMP (Simple Network Management Protocol) ou execute um script que colete
show pfm location alle pesquisa a string de erro periodicamente para monitorar a ocorrência futura da falha (quando o último status do erro for CLEAR e não ocorrerem novas falhas).
Comandos a serem usados
Insira estes comandos para analisar falhas transitórias:
show logging | inc “PUNT_FABRIC_DATA_PATH”show pfm location all
Analisar Falhas Graves
Se você visualizar os links do caminho de dados da estrutura em uma placa de linha como uma árvore (onde os detalhes são descritos na seção Informações de fundo), então você deve inferir - com base no ponto de falha - se um ou mais NPs estão inacessíveis. Quando várias falhas ocorrerem em vários NPs, use os comandos listados nesta seção para analisar falhas.
Comandos a serem usados
Insira estes comandos para analisar falhas de hardware:
show logging | inc “PUNT_FABRIC_DATA_PATH”
A saída pode conter um ou mais NPs (por exemplo: NP2, NP3).show controller fabric fia link-status location
Como NP2 e NP3 (na seção Falha de diagnóstico de tufão NP3) recebem e enviam através de um único FIA, é razoável inferir que a falha está em um FIA associado no caminho.show controller fabric crossbar link-status instance <0 and 1> location
Se todos os NPs na placa de linha não estiverem acessíveis para o aplicativo de diagnóstico, é razoável inferir que os links que conectam o slot da placa de linha à placa do processador de rota podem ter uma falha em qualquer um dos ASICs que encaminham o tráfego entre a placa do processador de rota e a placa de linha.show controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 0 location 0/rsp1/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp1/cpu0show controller fabric fia link-status location 0/rsp*/cpu0show controller fabric fia link-status location 0/rsp0/cpu0show controller fabric fia link-status location 0/rsp1/cpu0show controller fabric fia bridge sync-status location 0/rsp*/cpu0show controller fabric fia bridge sync-status location 0/rsp0/cpu0show controller fabric fia bridge sync-status location 0/rsp1/cpu0show tech fabric terminal
Observação: se todos os NPs em todas as placas de linha relatarem uma falha, é mais provável que a falha esteja na placa do processador de rota (placa do processador de rota ativa ou placa do processador de rota de standby). Consulte o link que conecta a CPU da placa do processador de roteamento ao FPGA e ao FIA da placa do processador de roteamento na seção Informações de Segundo Plano.
Falhas Passadas
Historicamente, 99% das falhas são recuperáveis e, na maioria dos casos, a ação de recuperação iniciada por software as corrige. No entanto, em casos muito raros, são vistos erros irrecuperáveis que só podem ser corrigidos com a RMA das placas.
As próximas seções identificam algumas falhas encontradas no passado para servir como orientação se erros semelhantes forem observados.
Erro Transitório Devido a Excesso de Assinatura NP
Essas mensagens serão exibidas se o erro for devido à assinatura excedente de NP.
RP/0/RP1/CPU0:Jun 26 13:08:28.669 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0, 0)
RP/0/RP1/CPU0:Jun 26 13:09:28.692 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0,0)
Falhas transitórias podem ser mais difíceis de confirmar. Um método para determinar se um NP está atualmente com excesso de assinaturas ou tem excesso de assinaturas no passado é verificar um certo tipo de queda dentro do NP e para quedas de cauda no FIA. As quedas IFDMA (Front Direct Memory Access) de entrada dentro do NP ocorrem quando o NP está com excesso de assinaturas e não consegue acompanhar o tráfego de entrada. Os descartes traseiros de FIA ocorrem quando um NP de saída declara controle de fluxo (solicita que a placa de linha de entrada envie menos tráfego). No cenário de controle de fluxo, o FIA de entrada tem descartes traseiros.
Aqui está um exemplo:
RP/0/RSP0/CPU0:RP/0/RSP0/CPU0:ASR9006-C#show controllers np counters all
Wed Feb 19 13:10:11.848 EST
Node: 0/1/CPU0:
----------------------------------------------------------------
Show global stats counters for NP0, revision v3
Read 93 non-zero NP counters:
Offset Counter FrameValue Rate (pps)
-----------------------------------------------------------------------
22 PARSE_ENET_RECEIVE_CNT 46913080435 118335
23 PARSE_FABRIC_RECEIVE_CNT 40175773071 5
24 PARSE_LOOPBACK_RECEIVE_CNT 5198971143966 0
<SNIP>
Show special stats counters for NP0, revision v3
Offset Counter CounterValue
----------------------------------------------------------------------------
524032 IFDMA discard stats counters 0 8008746088 0 <<<<<
Aqui está um exemplo:
RP/0/RSP0/CPU0:ASR9006-C#show controllers fabric fia drops ingress location 0/1/cPU0
Wed Feb 19 13:37:27.159 EST
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 0
Tail Drop-0 0 <<<<<<<
Tail Drop-1 0 <<<<<<<
Tail Drop-2 0 <<<<<<<
Tail Drop-3 0 <<<<<<<
Tail Drop DE-0 0
Tail Drop DE-1 0
Tail Drop DE-2 0
Tail Drop DE-3 0
Hard Drop-0 0
Hard Drop-1 0
Hard Drop-2 0
Hard Drop-3 0
Hard Drop DE-0 0
Hard Drop DE-1 0
Hard Drop DE-2 0
Hard Drop DE-3 0
WRED Drop-0 0
WRED Drop-1 0
WRED Drop-2 0
WRED Drop-3 0
WRED Drop DE-0 0
WRED Drop DE-1 0
WRED Drop DE-2 0
WRED Drop DE-3 0
Mc No Rep 0
Falha grave devido à redefinição NP Fast
Quando PUNT_FABRIC_DATA_PATH_FAILED ocorre, e se a falha é devido a uma reinicialização NP rápida, os registros semelhantes ao que está listado aqui são exibidos para uma placa de linha baseada no Typhoon. O mecanismo de monitoramento de integridade está disponível em placas de linha baseadas em Typhoon, mas não em placas de linha baseadas em Trident.
LC/0/2/CPU0:Aug 26 12:09:15.784 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:18.798 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:21.812 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST:
prm_server_ty[303]: NP-DIAG health monitoring failure on NP0
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST: pfm_node_lc[291]:
%PLATFORM-NP-0-NP_DIAG : Set|prm_server_ty[172112]|
Network Processor Unit(0x1008000)| NP diagnostics warning on NP0.
LC/0/2/CPU0:Aug 26 12:09:40.492 CEST: prm_server_ty[303]:
Starting fast reset for NP 0 LC/0/2/CPU0:Aug 26 12:09:40.524 CEST:
prm_server_ty[303]: Fast Reset NP0 - successful auto-recovery of NP
Para placas de linha baseadas em Trident, esse registro é visto com uma reinicialização rápida de um NP:
LC/0/1/CPU0:Mar 29 15:27:43.787 test:
pfm_node_lc[279]: Fast Reset initiated on NP3
Falhas entre os processadores de roteamento RSP440 e as placas de linha Typhoon
A Cisco corrigiu um problema em que raramente os links de estrutura entre o Route Switch Processor (RSP) 440 e as placas de linha baseadas em tufão no painel traseiro são treinados novamente. Os links de estrutura são treinados novamente porque a intensidade do sinal não é a ideal. Esse problema está presente nos Cisco IOS® XR Software Releases 4.2.1, 4.2.2, 4.2.3, 4.3.0, 4.3.1 e 4.3.2. Uma atualização de manutenção de software (SMU) para cada uma dessas versões é publicada no Cisco Connection Online e rastreada com o bug da Cisco ID CSCuj10837 e o bug da Cisco ID CSCul39674.
Quando esse problema ocorre no roteador, qualquer um destes cenários pode ocorrer:
- O link fica inativo e é ativado. (Transitório)
- O link fica permanentemente inativo.
ID de bug Cisco CSCuj10837 - Retreinamento de estrutura entre RSP e LC (direção TX)
Para confirmar, colete as saídas ltrace do LC e dos RSPs (show controller fabric crossbar ltrace location <>) e verifique se esta saída é vista em rastreamentos RSP:
SMU já disponível
Aqui está um exemplo:
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain:
destslot:0 fmlgrp:3 rc:0
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (2,0,7) initiated
Oct 1 08:22:58.969 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (2,1,0),(2,2,0),0.
O termo direção de TX se refere à direção do ponto de vista da interface de matriz de barras cruzadas de RSPs em direção a uma interface de matriz de barras cruzadas em uma placa de linha baseada em tufão.
O bug da Cisco ID CSCuj10837 é caracterizado pela detecção de um problema na placa de linha Typhoon no link RX do RSP e pelo início de um novo treinamento de link. Qualquer um dos lados (LC ou RSP) pode iniciar o evento de reciclagem. No caso do bug da Cisco ID CSCuj10837, o LC inicia o retrain e pode ser detectado pela mensagem init xbar_trigger_link_retrain: nos rastreamentos no LC.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain: destslot:
0 fmlgrp:3 rc:0
Quando o LC inicia o retrain, o RSP relata um rcvd link_retrain na saída do trace.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
ID de bug Cisco CSCul39674 - Retreinamento de estrutura entre RSP e LC (direção RX)
Para confirmar, colete as saídas ltrace da placa de linha e dos RSPs (show controller fabric crossbar ltrace location <>) e verifique se esta saída é vista em rastreamentos RSP:
Aqui está um exemplo:
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain:
destslot:4 fmlgrp:3 rc:0
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (5,1,11) initiated
Jan 8 17:28:39.256 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (5,1,1),(0,1,0),0.
O termo direção RX refere-se à direção do ponto de vista da interface de matriz de barras cruzadas RSPs a partir de uma interface de matriz de barras cruzadas em uma placa de linha baseada em tufão.
O bug da Cisco ID CSCul39674 é caracterizado pela detecção de um problema no enlace RX da placa de linha Typhoon e pelo início de um novo treinamento de enlace por parte do RSP. Qualquer um dos lados (LC ou RSP) pode iniciar o evento de reciclagem. No caso do bug da Cisco ID CSCul39674, o RSP inicia o retrain e pode ser detectado pela mensagem init xbar_trigger_link_retrain: nos rastreamentos no RSP.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain: destslot:4 fmlgrp:
3 rc:0
Quando o RSP inicia o retrain, o LC relata um evento rcvd link_retrain na saída do trace.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
Diferenças de reciclagem de estrutura na versão 4.3.2 e posterior
Foi feito um trabalho significativo para diminuir o tempo necessário para treinar novamente um link de estrutura no Cisco IOS XR Release 4.3.2 e posterior. A reciclagem da estrutura agora ocorre em menos de um segundo e é imperceptível para os fluxos de tráfego. No Cisco IOS XR Release 4.3.2, somente essas mensagens do syslog são vistas quando ocorre um novo treinamento do link de estrutura.
%PLATFORM-FABMGR-5-FABRIC_TRANSIENT_FAULT : Fabric backplane crossbar link
underwent link retraining to recover from a transient error: Physical slot 1
Falha devido a estouro de ASIC FIFO de malha
A Cisco corrigiu um problema em que o ASIC de estrutura (FIA) poderia ser redefinido devido a uma condição de estouro FIFO (First In First Out, primeiro a entrar, primeiro a sair) irrecuperável. Isso é solucionado com o bug da Cisco ID CSCul6510. Esse problema afeta apenas as placas de linha baseadas em Trident e só é encontrado em casos raros com congestionamento de caminho de entrada pesado. Se esse problema for encontrado, essa mensagem do Syslog será exibida antes que a placa de linha seja redefinida para se recuperar da condição.
RP/0/RSP0/CPU0:asr9k-2#show log
LC/0/3/CPU0:Nov 13 03:46:38.860 utc: pfm_node_lc[284]:
%FABRIC-FIA-0-ASIC_FATAL_FAULT Set|fialc[159814]
|Fabric Interface(0x1014000)|Fabric interface asic ASIC1 encountered fatal
fault 0x1b - OC_DF_INT_PROT_ERR_0
LC/0/3/CPU0:Nov 13 03:46:38.863 utc: pfm_node_lc[284]:
%PLATFORM-PFM-0-CARD_RESET_REQ : pfm_dev_sm_perform_recovery_action,
Card reset requested by: Process ID:159814 (fialc), Fault Sev: 0, Target node:
0/3/CPU0, CompId: 0x10, Device Handle: 0x1014000, CondID: 2545, Fault Reason:
Fabric interface asic ASIC1 encountered fatal fault 0x1b - OC_DF_INT_PROT_ERR_0
Falha devido ao acúmulo de fila de saída virtual pesada (VOQ) devido ao congestionamento da estrutura
A Cisco corrigiu um problema em que o congestionamento intenso estendido poderia levar à exaustão dos recursos de estrutura e à perda de tráfego. A perda de tráfego pode até ocorrer em fluxos não relacionados. Esse problema é solucionado com o bug da Cisco ID CSCug90300 e é resolvido no Cisco IOS XR Release 4.3.2 e posterior. A correção também é fornecida no Cisco IOS XR Release 4.2.3 CSMU#3, ID de bug Cisco CSCui33805. Esse problema raro pode ser encontrado em placas de linha baseadas em Trident ou Typhoon.
Comandos relevantes
Colete a saída destes comandos:
show tech-support fabricshow controller fabric fia bridge flow-control location<=== Obter esta saída para todos os LCsshow controllers fabric fia q-depth location
Aqui estão alguns exemplos de saída:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia q-depth location 0/6/CPU0
Sun Dec 29 23:10:56.307 UTC
********** FIA-0 **********
Category: q_stats_a-0
Voq ddr pri pktcnt
11 0 2 7
********** FIA-0 **********
Category: q_stats_b-0
Voq ddr pri pktcnt
********** FIA-1 **********
Category: q_stats_a-1
Voq ddr pri pktcnt
11 0 0 2491
11 0 2 5701
********** FIA-1 **********
Category: q_stats_b-1
Voq ddr pri pktcnt
RP/0/RSP0/CPU0:asr9k-1#
RP/0/RSP0/CPU0:asr9k-1#show controllers pm location 0/1/CPU0 | in "switch|if"
Sun Dec 29 23:37:05.621 UTC
Ifname(2): TenGigE0_1_0_2, ifh: 0x2000200 : <==Corresponding interface ten 0/1/0/2
iftype 0x1e
switch_fabric_port 0xb <==== VQI 11
parent_ifh 0x0
parent_bundle_ifh 0x80009e0
RP/0/RSP0/CPU0:asr9k-1#
Em condições normais, é muito improvável ver um VOQ com pacotes enfileirados. Esse comando é um instantâneo rápido em tempo real das filas FIA. É comum que esse comando não mostre nenhum pacote enfileirado.
Impacto no tráfego devido a erros de software de bridge/FPGA em placas de linha baseadas em tridente
Erros suaves são erros não permanentes que fazem com que a máquina de estado fique fora de sincronia. Eles são vistos como Cyclic Redundancy Check (CRC), Frame Check Sequence (FCS) ou pacotes com erros no lado da estrutura do NP ou no lado de entrada do FIA.
Aqui estão alguns exemplos de como esse problema pode ser visto:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia drops ingress location 0/3/CPU0
Fri Dec 6 19:50:42.135 UTC
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 32609856 <=== Errors
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia errors ingress location 0/3/CPU0
Fri Dec 6 19:50:48.934 UTC
********** FIA-0 **********
Category: in_error-0
DDR Rx CRC-0 0
DDR Rx CRC-1 32616455 <=== Errors
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/0/CPU0
Ingress Drop Stats (MC & UC combined)
**************************************
PriorityPacket Error Threshold
Direction Drops Drops
--------------------------------------------------
LP NP-3 to Fabric 0 0
HP NP-3 to Fabric 1750 0
RP/0/RSP1/CPU0:asr9k-1#
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/6/CPU0
Sat Jan 4 06:33:41.392 CST
********** FIA-0 **********
Category: bridge_in-0
UcH Fr Np-0 16867506
UcH Fr Np-1 115685
UcH Fr Np-2 104891
UcH Fr Np-3 105103
UcL Fr Np-0 1482833391
UcL Fr Np-1 31852547525
UcL Fr Np-2 3038838776
UcL Fr Np-3 30863851758
McH Fr Np-0 194999
McH Fr Np-1 793098
McH Fr Np-2 345046
McH Fr Np-3 453957
McL Fr Np-0 27567869
McL Fr Np-1 12613863
McL Fr Np-2 663139
McL Fr Np-3 21276923
Hp ErrFrNp-0 0
Hp ErrFrNp-1 0
Hp ErrFrNp-2 0
Hp ErrFrNp-3 0
Lp ErrFrNp-0 0
Lp ErrFrNp-1 0
Lp ErrFrNp-2 0
Lp ErrFrNp-3 0
Hp ThrFrNp-0 0
Hp ThrFrNp-1 0
Hp ThrFrNp-2 0
Hp ThrFrNp-3 0
Lp ThrFrNp-0 0
Lp ThrFrNp-1 0
Lp ThrFrNp-2 0
Lp ThrFrNp-3 0
********** FIA-0 **********
Category: bridge_eg-0
UcH to Np-0 779765
UcH to Np-1 3744578
UcH to Np-2 946908
UcH to Np-3 9764723
UcL to Np-0 1522490680
UcL to Np-1 32717279812
UcL to Np-2 3117563988
UcL to Np-3 29201555584
UcH ErrToNp-0 0
UcH ErrToNp-1 0
UcH ErrToNp-2 129 <==============
UcH ErrToNp-3 0
UcL ErrToNp-0 0
UcL ErrToNp-1 0
UcL ErrToNp-2 90359 <==========
Comandos a serem reunidos para erros de software de bridge/FPGA em placas de linha baseadas em tridente
Colete a saída destes comandos:
show tech-support fabricshow tech-support npshow controller fabric fia bridge stats location <>(obtenha várias vezes)
Recuperação de erros de software de Bridge/FPGA
O método de recuperação é recarregar a placa de linha afetada.
RP/0/RSP0/CPU0:asr9k-1#hw-module location 0/6/cpu0 reload
Relatório de Teste de Diagnóstico Online
O show diagnostic result location
fornece um resumo de todos os testes de diagnóstico on-line e falhas, bem como o último carimbo de data/hora quando um teste foi aprovado. O Test-ID para a falha do caminho de dados da estrutura de punt é dez. Uma lista de todos os testes, juntamente com a frequência dos pacotes de teste, pode ser vista com o comando show diagnostic content location
comando.
A saída do resultado do teste de caminho de dados da estrutura de punt é semelhante a esta saída de exemplo:
RP/0/RSP0/CPU0:ios(admin)#show diagnostic result location 0/rsp0/cpu0 test 10 detail
Current bootup diagnostic level for RP 0/RSP0/CPU0: minimal
Test results: (. = Pass, F = Fail, U = Untested)
___________________________________________________________________________
10 ) FabricLoopback ------------------> .
Error code ------------------> 0 (DIAG_SUCCESS)
Total run count -------------> 357
Last test execution time ----> Sat Jan 10 18:55:46 2009
First test failure time -----> n/a
Last test failure time ------> n/a
Last test pass time ---------> Sat Jan 10 18:55:46 2009
Total failure count ---------> 0
Consecutive failure count ---> 0
Aprimoramentos de recuperação automática
Conforme descrito no bug da Cisco ID CSCuc04493, agora há uma maneira de fazer com que o roteador desligue automaticamente todas as portas associadas aos erros PUNT_FABRIC_DATA_PATH gerados no RP/RSP Ativo.
O primeiro método é rastreado através da ID de bug Cisco CSCuc04493. Para a versão 4.2.3, isso está incluído no bug da Cisco ID CSCui33805. Nesta versão, ele é configurado para desligar automaticamente todas as portas que estão associadas aos NPs afetados.
Aqui está um exemplo que mostra como os syslogs apareceriam:
RP/0/RSP0/CPU0:Jun 10 16:11:26 BKK: pfm_node_rp[359]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System
Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/1/CPU0, 0)
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/1, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/1, changed state to Down
O controlador indica que a razão para a interface estar inativa é devido a DATA_PATH_DOWN. Aqui está um exemplo:
RP/0/RSP0/CPU0:ASR9006-E#show controllers gigabitEthernet 0/0/0/13 internal
Wed Dec 18 02:42:52.221 UTC
Port Number : 13
Port Type : GE
Transport mode : LAN
BIA MAC addr : 6c9c.ed08.3cbd
Oper. MAC addr : 6c9c.ed08.3cbd
Egress MAC addr : 6c9c.ed08.3cbd
Port Available : true
Status polling is : enabled
Status events are : enabled
I/F Handle : 0x04000400
Cfg Link Enabled : tx/rx enabled
H/W Tx Enable : no
UDLF enabled : no
SFP PWR DN Reason : 0x00000000
SFP Capability : 0x00000024
MTU : 1538
H/W Speed : 1 Gbps
H/W Duplex : Full
H/W Loopback Type : None
H/W FlowCtrl type : None
H/W AutoNeg Enable: Off
H/W Link Defects : (0x00080000) DATA_PATH_DOWN <<<<<<<<<<<
Link Up : no
Link Led Status : Link down -- Red
Input good underflow : 0
Input ucast underflow : 0
Output ucast underflow : 0
Input unknown opcode underflow: 0
Pluggable Present : yes
Pluggable Type : 1000BASE-LX
Pluggable Compl. : (Service Un) - Compliant
Pluggable Type Supp.: (Service Un) - Supported
Pluggable PID Supp. : (Service Un) - Supported
Pluggable Scan Flg: false
Nas versões 4.3.1 e posteriores, esse comportamento deve ser habilitado. Há um novo comando admin-config que é usado para fazer isso. Como o comportamento padrão não é mais encerrar as portas, ele deve ser configurado manualmente.
RP/0/RSP1/CPU0:ASR9010-A(admin-config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
No Cisco IOS XR de 64 bits, o comando de configuração está disponível na VM XR (não na VM Sysadmin):
RP/0/RSP0/CPU0:CORE-TOP(config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
O bug da Cisco ID CSCui15435 aborda os erros de software que são vistos nas placas de linha baseadas em Trident, conforme descrito na seção Impacto de tráfego devido a erros de software de Bridge/FPGA nas placas de linha baseadas em Trident. Isso usa um método de detecção diferente do método de diagnóstico comum descrito na ID de bug Cisco CSCuc04493.
Esse bug também apresentou um novo comando CLI admin-config:
(admin-config)#fabric fia soft-error-monitor <1|2> location
1 = shutdown the ports
2 = reload the linecard
Default behavior: no action is taken.
Quando este erro é encontrado, este syslog pode ser observado:
RP/0/RSP0/CPU0:Apr 30 22:17:11.351 : config[65777]: %MGBL-SYS-5-CONFIG_I : Configured
from console by root
LC/0/2/CPU0:Apr 30 22:18:52.252 : pfm_node_lc[283]:
%PLATFORM-BRIDGE-1-SOFT_ERROR_ALERT_1 : Set|fialc[159814]|NPU
Crossbar Fabric Interface Bridge(0x1024000)|Soft Error Detected on Bridge instance 1
RP/0/RSP0/CPU0:Apr 30 22:21:28.747 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/2/CPU0, 2) (0/2/CPU0, 3)
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINK-3-UPDOWN :
Interface TenGigE0/2/0/2, changed state to Down
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINEPROTO-5-UPDOWN :
Line protocol on Interface TenGigE0/2/0/2, changed state to Down
RP/0/RSP1/CPU0:Apr 30 22:21:35.086 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED :
Set|online_diag_rsp[237646]|System Punt/Fabric/data Path Test(0x2000004)|failure
threshold is 3, (slot, NP) failed: (0/2/CPU0, 2) (0/2/CPU0, 3)
Quando as portas afetadas são desligadas, isso permite que a redundância de rede assuma o controle e evite um buraco negro de tráfego. Para se recuperar, a placa de linha deve ser recarregada.
Perguntas frequentes
P. A placa do processador de rotas principal ou de standby envia os pacotes de keepalives ou de diagnóstico on-line para cada NP no sistema?
R. Sim. Ambas as placas do processador de rotas enviam pacotes de diagnóstico on-line para cada NP.
P. O caminho é o mesmo quando a RSP1 (Route Processor Card one) está ativa?
R. O caminho de diagnóstico é o mesmo para RSP0 ou RSP1. O caminho depende do estado do RSP. Consulte a seção Caminho do Pacote de Diagnóstico de Estrutura Punt deste documento para obter mais detalhes.
P. Com que frequência os RSPs enviam pacotes de diagnóstico e quantos pacotes de diagnóstico devem ser perdidos antes que um alarme seja disparado?
R. Cada RSP envia independentemente um pacote de diagnóstico para cada NP uma vez por minuto. Qualquer RSP pode disparar um alarme se três pacotes de diagnóstico não forem confirmados.
P. Como você determina se um NP tem ou teve excesso de assinaturas?
R. Uma maneira de verificar se um NP está atualmente com excesso de assinaturas ou foi com excesso de assinaturas no passado é verificar se há um certo tipo de queda dentro do NP e para quedas de cauda no FIA. As quedas IFDMA (Front Direct Memory Access) de entrada dentro do NP ocorrem quando o NP está com excesso de assinaturas e não consegue acompanhar o tráfego de entrada. Os descartes traseiros de FIA ocorrem quando um NP de saída declara controle de fluxo (solicita que a placa de linha de entrada envie menos tráfego). No cenário de controle de fluxo, o FIA de entrada tem descartes traseiros.
P. Como você determina se um NP sofre uma falha que requer que ele seja redefinido?
R. Normalmente, uma falha NP é eliminada por uma reinicialização rápida. O motivo de uma redefinição rápida é exibido nos logs.
P. É possível redefinir manualmente um NP?
R. Sim, da placa de linha KSH:
run attach 0/[x]/CPU0 #show_np -e [np#] -d fast_reset
P. O que é exibido se um NP tiver uma falha de hardware não recuperável?
R. Você vê uma falha de caminho de dados de estrutura de punt para aquele NP, bem como uma falha de teste de loopback NP. A mensagem de falha do teste de loopback NP é discutida na seção Apêndice deste documento.
P. Um pacote de diagnósticos originado de uma placa do processador de roteamento voltará para o mesmo pacote?
R. Como os pacotes de diagnóstico são originados de ambas as placas do processador de rotas e rastreados por placa do processador de rotas, um pacote de diagnóstico originado de uma placa do processador de rotas é devolvido ao mesmo cartão do processador de rotas pelo NP.
P. O bug da Cisco ID CSCuj10837 SMU fornece uma correção para o evento de reciclagem do link de estrutura. Essa é a causa e a solução para muitas falhas de caminho de dados de estrutura de punt?
R. Sim, é necessário carregar o SMU de substituição para o bug da Cisco ID CSCul39674 para evitar eventos de reciclagem do link de estrutura.
P. Quanto tempo é necessário para treinar novamente os links de estrutura depois que a decisão é tomada?
R. A decisão de treinar novamente é tomada assim que uma falha de link é detectada. Antes da Versão 4.3.2, o retreinamento poderia levar vários segundos. Após a Versão 4.3.2, o tempo de reciclagem foi significativamente melhorado e leva menos de um segundo.
P. Em que ponto é tomada a decisão de treinar novamente um link de estrutura?
R. Assim que a falha do link é detectada, a decisão de reciclagem é tomada pelo driver ASIC da estrutura.
P. É apenas entre o FIA em uma placa de processador de rota ativa e a estrutura que você usa o primeiro link e, em seguida, é o link menos carregado quando há vários links disponíveis?
R. Correto. O primeiro link que se conecta à primeira instância XBAR no processador de rota ativo é usado para injetar tráfego na estrutura. O pacote de resposta do NP pode alcançar de volta a placa do processador de rota ativa em qualquer um dos links que se conectam à placa do processador de rota. A escolha do link depende da carga do link.
P. Durante o novo treinamento, todos os pacotes enviados por esse link de estrutura são perdidos?
R. Sim, mas com os aprimoramentos da versão 4.3.2 e posteriores, o retrain é praticamente indetectável. No entanto, no código anterior, poderia levar vários segundos para treinar novamente, o que resultou em pacotes perdidos para esse período.
P. Com que frequência você espera ver um evento de reciclagem de link de estrutura XBAR depois de atualizar para uma versão ou SMU com a correção para o ID de bug Cisco CSCuj10837?
R. Mesmo com a correção do bug da Cisco ID CSCuj10837, ainda é possível ver retrainings de link de estrutura devido ao bug da Cisco ID CSCul39674. Mas, uma vez que você tenha a correção para o bug da Cisco ID CSCul39674, o novo treinamento de link de estrutura nos links de backplane de estrutura entre o RSP440 e as placas de linha baseadas em tufão nunca deve ocorrer. Em caso afirmativo, envie uma solicitação de serviço ao Cisco Technical Assistance Center (TAC) para solucionar o problema.
P. O bug da Cisco ID CSCuj10837 e o bug da Cisco ID CSCul39674 afetam o RP no ASR 9922 com placas de linha baseadas em tufão?
A. Sim
P. O bug da Cisco ID CSCuj10837 e o bug da Cisco ID CSCul39674 afetam os roteadores ASR-9001 e ASR-9001-S?
A. Não
P. Se você encontrar a falha de um slot que não existe com esta mensagem, "PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System Punt/Fabric/data Path Test(0x2000004)|o limite de falha é 3, (slot, NP) falhou: (8, 0)," em um chassi de 10 slots, qual slot apresenta o problema?
R. Em versões anteriores, você deve considerar os mapeamentos físicos e lógicos como mostrado aqui. Neste exemplo, o slot 8 corresponde a 0/6/CPU0.
For 9010 (10 slot chassis)
L P
#0 --- #0
#1 --- #1
#2 --- #2
#3 --- #3
RSP0 --- #4
RSP1 --- #5
#4 --- #6
#5 --- #7
#6 --- #8
#7 --- #9
For 9006 (6 slot chassis)
L P
RSP0 --- #0
RSP1 --- #1
#0 --- #2
#1 --- #3
#2 --- #4
#3 --- #5
Dados a Serem Coletados Antes da Criação da Solicitação de Serviço
Aqui estão os comandos mínimos para coletar saída antes de qualquer ação ser tomada:
show loggingshow pfm location alladmin show diagn result loc 0/rsp0/cpu0 test 8 detailadmin show diagn result loc 0/rsp1/cpu0 test 8 detailadmin show diagn result loc 0/rsp0/cpu0 test 9 detailadmin show diagn result loc 0/rsp1/cpu0 test 9 detailadmin show diagn result loc 0/rsp0/cpu0 test 10 detailadmin show diagn result loc 0/rsp1/cpu0 test 10 detailadmin show diagn result loc 0/rsp0/cpu0 test 11 detailadmin show diagn result loc 0/rsp1/cpu0 test 11 detailshow controller fabric fia link-status locationshow controller fabric fia link-status locationshow controller fabric fia bridge sync-status locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 1 locationshow controller fabric ltrace crossbar locationshow controller fabric ltrace crossbar locationshow tech fabric locationshow tech fabric locationfile
Comandos de diagnóstico úteis
Aqui está uma lista de comandos que são úteis para fins de diagnóstico:
show diagnostic ondemand settingsshow diagnostic content location < loc >show diagnostic result location < loc > [ test {id|id_list|all} ] [ detail ]show diagnostic statusadmin diagnostic start location < loc > test {id|id_list|test-suite}admin diagnostic stop location < loc >- admin diagnostic ondemand iterations < iteration-count >
admin diagnostic ondemand action-on-failure {continue failure-count|stop}- admin-config#
[ no ] diagnostic monitor location < loc > test {id | test-name} [disable] - admin-config#
[ no ] diagnostic monitor interval location < loc > test {id | test-name} day hour:minute:second.millisec - admin-config#
[ no ] diagnostic monitor threshold location < loc > test {id | test-name} failure count
Conclusão
A partir do cronograma do Cisco IOS XR Software Release 4.3.4, a maioria dos problemas relacionados a falhas de caminho de dados de estrutura de punt são abordados. Para roteadores afetados pelo bug da Cisco ID CSCuj10837 e pelo bug da Cisco ID CSCul39674, carregue o SMU de substituição para o bug da Cisco ID CSCul39674 para evitar eventos de retreinamento do link de estrutura.
A equipe da plataforma instalou o tratamento de falhas de última geração para que o roteador se recupere em subsegundos se e quando ocorrer qualquer falha recuperável do caminho de dados. No entanto, este documento é recomendado para compreender este problema, mesmo que tal falha não seja observada.
Appendix
Caminho de Diagnóstico de Loopback NP
O aplicativo de diagnóstico que é executado na placa de linha da CPU rastreia a integridade de cada NP com verificações periódicas do status de funcionamento do NP. Um pacote é injetado a partir da CPU da placa de linha destinada ao NP local, que o NP deve voltar em loop e retornar à CPU da placa de linha. Qualquer perda nesses pacotes periódicos é sinalizada com uma mensagem de registro da plataforma. Aqui está um exemplo dessa mensagem:
LC/0/7/CPU0:Aug 18 19:17:26.924 : pfm_node[182]:
%PLATFORM-PFM_DIAGS-2-LC_NP_LOOPBACK_FAILED : Set|online_diag_lc[94283]|
Line card NP loopback Test(0x2000006)|link failure mask is 0x8
Essa mensagem de log significa que esse teste falhou ao receber o pacote de loopback de NP3. A máscara de falha do link é 0x8 (o bit 3 está definido), o que indica uma falha entre a CPU da placa de linha para o slot 7 e NP3 no slot 7.
Para obter mais detalhes, colete a saída desses comandos:
admin show diagnostic result location 0//cpu0 test 9 detail show controllers NP counter NP<0-3> location 0//cpu0
Comandos de depuração da estrutura
Os comandos listados nesta seção se aplicam a todas as placas de linha baseadas em Trident, bem como à placa de linha 100GE baseada em Typhoon. O Bridge FPGA ASIC não está presente nas placas de linha baseadas em tufão (exceto para as placas de linha baseadas em tufão 100GE). Então, o show controller fabric fia bridge não se aplicam a placas de linha baseadas em Typhoon, exceto para as versões 100GE.
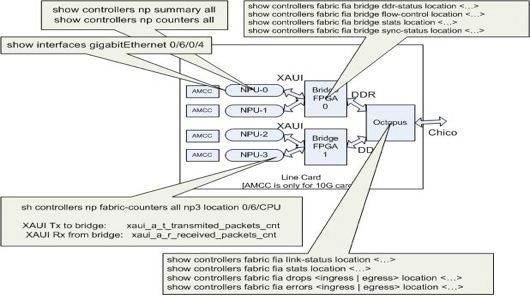
Essa representação gráfica ajuda a mapear cada comando show para o local no caminho de dados. Use estes comandos show para isolar quedas e falhas de pacotes.
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
2.0 |
26-Jun-2023 |
Seção Automatic Recovery Enhancements atualizada para o ID de bug Cisco CSCuc04493 e seção de perguntas frequentes atualizada. |
1.0 |
29-Oct-2013 |
Versão inicial |
Colaborado por engenheiros da Cisco
- Mahesh ShirshyadEngenheiro do Cisco TAC
- David PowersEngenheiro do Cisco TAC
- Jean-Christophe RodeEngenheiro do Cisco TAC
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)