Procedimento de decluster ASR 9000 nV
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve alguns dos recursos de cluster nV do ASR 9000 e como desagrupar.
O procedimento foi testado em um ambiente real com clientes da Cisco que já decidiram pelo processo de desorganização explicado neste documento.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos:
- IOS XR
- Plataforma ASR 9000
- recurso de cluster nV
Componentes Utilizados
As informações neste documento são baseadas na plataforma ASR 9000 executando IOS XR 5.x.
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
Unidade de negócios de produto (BU) anunciada como fim de venda (EOS) para cluster nV na plataforma ASR 9000: Anúncio de fim das vendas e fim da vida útil do Cisco nV Cluster
Como você pode ler no anúncio, o último dia para solicitar este produto é 15 de janeiro de 2018, e a última versão suportada para cluster nV é IOS-XR 5.3.x.
Os marcos que devem ser considerados estão listados nesta tabela:

Fundamentos e considerações do cluster ASR9k nV
O objetivo desta seção é fornecer uma breve atualização das configurações de cluster e dos conceitos necessários para entender as próximas seções deste documento.

Canal Ethernet fora da banda (EOBC)
O canal Ethernet Out of Band estende o plano de controle entre os dois chassis ASR9k e, idealmente, consiste em 4 interconexões que constroem uma malha entre o Route Switch Processor (RSP) de chassis diferentes. Essa configuração fornece redundância adicional em caso de falha do link EOBC. O Unidirectional Link Detection Protocol (UDLD) garante o encaminhamento de dados bidirecional e detecta rapidamente falhas de link. O mau funcionamento de todos os links EOBC afeta seriamente o sistema de cluster e pode ter consequências graves que são apresentadas mais adiante na seção Cenários de divisão de nó.
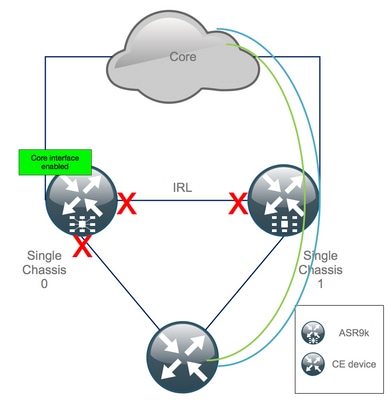
Inter Rack Links (IRL)
Os Inter Rack Links estendem o plano de dados entre os dois chassis ASR9k. Idealmente, somente o protocolo punt e o protocolo injeta pacotes passam pela IRL, exceto para serviços single-homed ou durante falhas de rede. Teoricamente, todos os sistemas finais são dual-homed com um link para ambos os chassis ASR9K. Semelhante aos links EOBC, o UDLD é executado sobre o IRL, bem como para monitorar a integridade do encaminhamento bidirecional dos links.
Um limiar de IRL pode ser definido para evitar que IRL congestionada descarte pacotes no caso de falha de LC, por exemplo. Se o número de links IRL cair abaixo do limite configurado para esse chassi, todas as interfaces do chassi serão desativadas por erro e desativadas. Isso basicamente isola o chassi afetado e garante que todo o tráfego flua pelo outro chassi.
Observação: a configuração padrão é equivalente a nv edge data minimum 1 backup-rack-interfaces, o que significa que se nenhuma IRL estiver no estado forwarding, o DSC (Designated Shelf Controller, Controlador de prateleira designado) de backup será isolado.
Dividir cenários de nó
Nesta subseção, você pode encontrar os diferentes cenários de falha que podem ser encontrados ao lidar com clusters ASR9k:
IRL desativado
Este é o único cenário de Nó Dividido que pode ser esperado durante a desorganização ou se um dos chassis cai abaixo do limiar de IRL e fica isolado como consequência.
EOBC desativado
Os dois chassis do ASR9k não podem atuar como um sem o plano de controle estendido fornecido pelos links EOBC. Há beacons periódicos que são trocados pelos links IRL para que cada chassi esteja ciente de que o outro chassi está ativo. Como consequência, um dos chassis, geralmente o chassi com o Backup-DSC, sai de serviço e é reinicializado. O chassi DSC de backup permanece no loop de inicialização desde que receba os beacons do chassi DSC principal sobre o IRL.
Cérebro Dividido
No cenário de split brain, os links IRL e EOBC foram desativados e cada chassi se declara como Primary-DSC. Os dispositivos de rede vizinhos veem repentinamente IDs de roteador duplicadas para IGP e BGP, o que pode causar problemas graves na rede.
Pacotes
Muitos clientes usam pacotes no lado da borda e do núcleo para simplificar a configuração do cluster ASR9K e para facilitar aumentos de largura de banda no futuro. Isso pode causar problemas ao desagrupar devido a diferentes membros do pacote que se conectam a diferentes chassis. Essas abordagens são possíveis:
- Crie novos pacotes para todas as interfaces conectadas ao chassi 1 (Backup-DSC).
- Apresente o MCLAG (Multichassis Link Aggregation).
Domínio L2
Dividir o cluster poderia potencialmente separar o domínio L2, se não houver nenhum switch no acesso que interconecte os dois chassis autônomos. Para não interromper o tráfego, você precisa estender o domínio L2, o que pode ser feito se você configurar conexões locais L2 na IRL anterior, Pseudo-Fios (PW) entre o chassi ou usar qualquer outra tecnologia de Rede Virtual Privada (L2VPN) de Camada 2. À medida que a topologia de domínio de bridge muda com o descluster, lembre-se da possível criação de loop ao selecionar a tecnologia L2VPN de sua escolha.
O roteamento estático no acesso em direção a uma interface de interface virtual de grupo de ponte (BVI) no cluster ASR9K provavelmente se transformará em uma solução baseada no Hot Standby Router Protocol (HSRP) usando o endereço IP BVI anterior como IP virtual.
Serviços single-homed
Os serviços single-homed têm um tempo de inatividade estendido durante o procedimento de desorganização.
Acesso de gerenciamento
Durante o processo de desorganização por clusters, há um curto período de tempo em que ambos os chassis são isolados, pelo menos durante a transição do roteamento estático (BVI) para o roteamento estático (HSRP) para não ter um roteamento inesperado e assimétrico.
Você deve verificar como o console e o acesso de gerenciamento Fora de Banda funcionam, antes de bloquear-se.
Procedimento de descluster do ASR9000
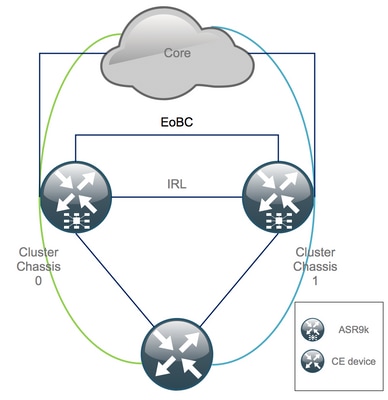
O Estado Inicial
Suponha que, no estado inicial, o chassi 0 esteja ativo, enquanto o chassi 1 é de backup (por uma questão de simplicidade). Na vida real, pode ser o contrário ou até mesmo o RSP1 no chassi 0 pode estar ativo.
Lista de verificação antes da janela de manutenção (MW)
- Prepare as novas configurações dos chassis 0 e 1 do ASR9K (Admin-Config + Config).
- Prepare as novas configurações do sistema final (borda do cliente (CE), firewall (FW), switches, etc.).
- Prepare as novas configurações do sistema central (nós P, nós PE (Provider Edge), refletor de rota (RR) etc.).
- Verifique as novas configurações, armazene-as no dispositivo e remotamente em um servidor Trivial File Transfer Protocol (TFTP).
- Definir testes de acessibilidade que devem ser executados antes/durante/depois da MW.
- Colete saídas de plano de controle para IGP (Interior Gateway Protocol), BGP (Border Gateway Protocol), MPLS (Multiprotocol Label Switching), LDP (Label Distribution Protocol) etc. para comparação antes/depois.
- Abra uma solicitação de serviço proativa com a Cisco.
Etapa 1. Faça login no cluster ASR9000 e verifique a configuração atual
1. Verifique o local de Principal - Chassi de backup. Neste exemplo, o chassi principal é 0:
RP/0/RSP0/CPU0:Cluster(admin)# show dsc --------------------------------------------------------- Node ( Seq) Role Serial# State --------------------------------------------------------- 0/RSP0/CPU0 ( 1279475) ACTIVE FOX1441GPND PRIMARY-DSC <<< Primary DSC in Ch1 0/RSP1/CPU0 ( 1223769) STANDBY FOX1432GU2Z NON-DSC 1/RSP0/CPU0 ( 0) ACTIVE FOX1432GU2Z BACKUP-DSC 1/RSP1/CPU0 ( 1279584) STANDBY FOX1441GPND NON-DSC
2. Verifique se todas as Line Cards (LC)/RSPs estão no estado "IOS XR RUN":
RP/0/RSP0/CPU0:Cluster# sh platform Node Type State Config State ----------------------------------------------------------------------------- 0/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 0/RSP1/CPU0 A9K-RSP440-TR(Standby) IOS XR RUN PWR,NSHUT,MON 0/0/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 0/0/0 A9K-MPA-4X10GE OK PWR,NSHUT,MON 0/0/1 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/1/CPU0 A9K-MOD80-TR IOS XR RUN PWR,NSHUT,MON 0/1/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 0/2/CPU0 A9K-40GE-E IOS XR RUN PWR,NSHUT,MON 1/RSP0/CPU0 A9K-RSP440-TR(Active) IOS XR RUN PWR,NSHUT,MON 1/RSP1/CPU0 A9K-RSP440-SE(Standby) IOS XR RUN PWR,NSHUT,MON 1/1/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/1/1 A9K-MPA-2X10GE OK PWR,NSHUT,MON 1/2/CPU0 A9K-MOD80-SE IOS XR RUN PWR,NSHUT,MON 1/2/0 A9K-MPA-20X1GE OK PWR,NSHUT,MON 1/2/1 A9K-MPA-4X10GE OK PWR,NSHUT,MON
Etapa 2. Configurar o limite mínimo de IRL para o chassi em standby
O chassi em standby é o chassi com o BACKUP-DSC e é retirado de serviço e desagrupado primeiro. Neste exemplo, o BACKUP-DSC está localizado no chassi 1.
Com essa configuração, se o número de IRLs cair abaixo do limite mínimo configurado (1 neste caso), todas as interfaces no rack especificado (rack de backup - chassi 1 neste caso) serão desligadas:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data min 1 spec rack 1 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
Etapa 3. Desligue toda a IRL e verifique as interfaces de desativação de erro no chassi 1
1. Feche todos os IRLs existentes. Neste exemplo, você pode ver um desligamento de interface manual em ambos os chassis (Ten0/x/x/x ativo e Ten1/x/x/x standby):
RP/0/RSP0/CPU0:Cluster(config)# interface Ten0/x/x/x shut interface Ten0/x/x/x shut […] interface Ten1/x/x/x shut interface Ten1/x/x/x shut […] commit
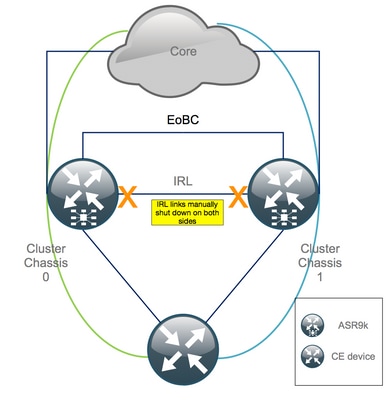
2. Verifique se todos os IRLs configurados estão desativados:
RP/0/RSP0/CPU0:Cluster# show nv edge data forwarding location
Um exemplo de <location> é 0/RSP0/CPU0.
Após o desligamento de todos os IRLs, o chassi 1 deve ser totalmente isolado do plano de dados, movendo todas as interfaces externas para o estado desativado por erro.
3. Verifique se todas as interfaces externas no chassi 1 estão no estado err-disabled e se todo o tráfego flui pelo chassi 0:
RP/0/RSP0/CPU0:Cluster# show error-disable
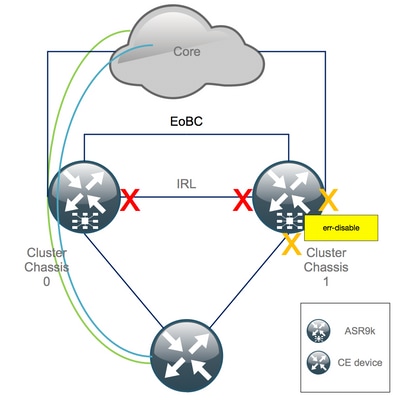
Etapa 4. Desligar todos os links EOBC e verificar seu status

1. Feche os links EOBC em todos os RSPs:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge control control-link disable 0 loc 0/RSP0/CPU0 nv edge control control-link disable 1 loc 0/RSP0/CPU0 nv edge control control-link disable 0 loc 1/RSP0/CPU0 nv edge control control-link disable 1 loc 1/RSP0/CPU0 nv edge control control-link disable 0 loc 0/RSP1/CPU0 nv edge control control-link disable 1 loc 0/RSP1/CPU0 nv edge control control-link disable 0 loc 1/RSP1/CPU0 nv edge control control-link disable 1 loc 1/RSP1/CPU0 commit
2. Verifique se todos os links EOBC estão desativados:
RP/0/RSP0/CPU0:Cluster# show nv edge control control-link-protocols location 0/RSP0/CPU0
Após essa etapa, o chassi do cluster é totalmente isolado um do outro em termos de controle - e plano de dados. O chassi 1 tem todos os seus links no estado err-disable.
Observação: de agora em diante, as configurações devem ser feitas no chassi 1 através do console RSP e afetam apenas o chassi local!
Etapa 5. Faça login no RSP ativo do chassi 1 e remova a configuração antiga
Limpe a configuração existente no chassi 1:
RP/1/RSP0/CPU0:Cluster(config)# commit replace RP/1/RSP0/CPU0:Cluster(admin-config)# commit replace
Observação: você precisa substituir primeiro a configuração da configuração atual e só depois limpar a configuração atual admin. Isso ocorre porque a remoção do limite de IRL na configuração atual do administrador faz "no shut" em todas as interfaces externas. Isso pode causar problemas devido a IDs de roteador duplicadas, etc.
Etapa 6. Inicialize o chassi 1 no modo ROMMON
1. Defina o registro de configuração para inicializar no ROMMON:
RP/1/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Verifique as variáveis de inicialização:
RP/1/RSP0/CPU0:Cluster(admin)# show variables boot
3. Recarregue ambos os RSPs do chassi 1:
RP/1/RSP0/CPU0:Cluster# admin reload location all
Após essa etapa, normalmente, o chassi 1 inicializa no ROMMON.
Passo 7. Desmarque as variáveis de cluster no chassi 1 no ROMMON em ambos os RSPs
Aviso: o técnico de campo deve remover todos os links EOBC antes de prosseguir.
Dica: também há uma alternativa para definir as variáveis de cluster do sistema. Verifique a seção Apêndice 2: Definir a variável Cluster sem inicializar o sistema no rommon.
1. O procedimento padrão requer a conexão do cabo de console ao RSP ativo no chassi 1 e a desativação e sincronização da variável ROMMON do cluster:
unset CLUSTER_RACK_ID sync
2. Redefina os registros de configuração para 0x102:
confreg 0x102 reset
O RSP ativo está definido.
3. Conecte o cabo do console ao RSP em standby do chassi 1. Idealmente, todos os 4 RSPs do cluster têm acesso ao console durante a janela de manutenção.
Observação: as ações descritas nesta etapa precisam ser feitas em ambos os RSPs do chassi 1. O RSP ativo deve ser inicializado primeiro.
Etapa 8. Inicialize o chassi 1 como um sistema independente e configure-o de acordo
Idealmente, a nova configuração ou vários fragmentos de configuração são armazenados em cada chassi ASR9k e carregados após a desorganização. A sintaxe de configuração correta deve ser testada no laboratório anteriormente. Caso contrário, configure primeiro o console e as interfaces de gerenciamento antes de concluir a configuração no chassi 1 por meio de copiar e colar no Virtual Teletype (VTY) ou carregar a configuração remotamente de um servidor TFTP.
Observação: os comandos load config e commit mantêm todas as interfaces desligadas, o que permite um aumento de serviço controlado. load config e commit replace, substitui totalmente a configuração e ativa as interfaces. Portanto, é recomendável usar load config e commit.
Adaptar a configuração de sistemas finais conectados (FW, Switches, etc.) e dispositivos de núcleo (P, PE, RR, etc.) ao chassi 1.
Etapa 9. Restaure os serviços principais no chassi 1
- Desligue manualmente as interfaces principais primeiro.
- Verifique o LDP, o sistema intermediário para o sistema intermediário (IS-IS ou ISIS), adjacências/correspondentes BGP.
- Verifique as tabelas de roteamento e certifique-se de que todos os prefixos tenham sido trocados.
Aviso: Cuidado com os temporizadores, como o bit OL (ISIS Overload), o atraso de HSRP, o atraso de atualização de BGP, etc., antes de passar para o failover!
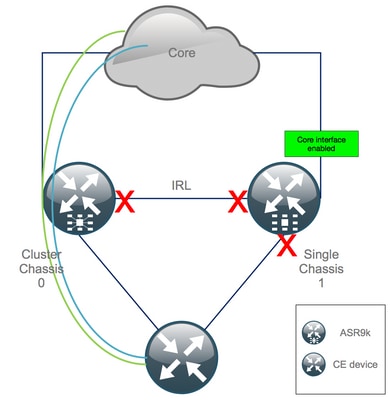
Etapa 10. Failover - Efetue login no RSP ativo do chassi 0 e coloque todas as interfaces no estado Error-Disable
Cuidado: as próximas etapas causam a interrupção do serviço. As interfaces de saída do chassi 1 ainda estão desativadas, enquanto o chassi 0 está isolado

O hold-time padrão é igual a 180s (3x60s) e representa o pior caso para a convergência BGP. Há várias opções de design e recursos de BGP que permitem um tempo de convergência muito mais rápido, como o Rastreamento de próximo salto de BGP. Suponha que existam diferentes fornecedores de terceiros presentes no núcleo que se comportam de forma diferente do Cisco IOS XR, você eventualmente precisa acelerar a convergência do BGP manualmente com um software desligado das vizinhanças de BGP entre o chassi 0 e o RR, ou similar, antes de acionar o failover:
RP/0/RSP0/CPU0:Cluster(admin-config)# nv edge data minimum 1 specific rack 0 RP/0/RSP0/CPU0:Cluster(admin-config)# commit
Como todos os IRL estão desativados, o chassi 0 deve ser isolado e todas as interfaces externas devem ser movidas para o estado error-disabled.
Verifique se todas as interfaces externas no chassi 0 estão no estado err-disabled:
RP/0/RSP0/CPU0:Cluster# show error-disable
O chassi 1 foi reconfigurado como uma caixa autônoma, portanto não deve haver nenhuma interface com erro desativado. A única coisa que resta fazer no chassi 1 é ativar as interfaces na borda.
Etapa 11. Restaure o lado sul do chassi 1
1. no shut all access interfaces.

Mantenha o link de interconexão (IRL anterior) desligado por enquanto.
2. Verificar adjacências/peers/DB de IGP e BGP. Enquanto os IGPs e o BGP convergem, você espera ver alguma perda de tráfego em seus pings do PE remoto.
Etapa 12. Faça login no RSP ativo do chassi 0 e remova a configuração
Limpe a configuração existente no chassi ativo:
RP/0/RSP0/CPU0:Cluster(config)# commit replace RP/0/RSP0/CPU0:Cluster(admin-config)# commit replace
Observação: você deve primeiro substituir a configuração da configuração atual e somente depois limpar a configuração atual admin. Isso se deve ao fato de que a remoção do limite de IRL na configuração atual do administrador não fecha todas as interfaces externas. Isso pode causar problemas devido a IDs de roteador duplicadas, etc.
Etapa 13. Inicialize o chassi 0 no ROMMON
1. Defina o registro de configuração para inicializar no ROMMON:
RP/0/RSP0/CPU0:Cluster(admin)# config-register boot-mode rom-monitor location all
2. Verifique as variáveis de inicialização:
RP/0/RSP0/CPU0:Cluster# admin show variables boot
3. Recarregue ambos os RSPs do Chassi de Standby:
RP/0/RSP0/CPU0:Cluster# admin reload location all
Após essa etapa, normalmente, o chassi 0 inicializa no modo ROMMON.
Etapa 14. Remova a definição de variáveis de cluster no chassi 0 em ROMMON em ambos os RSPs
1. Conecte o cabo do console ao RSP ativo no chassi 0.
2. Desmarque e sincronize a variável ROMMON do Cluster:
unset CLUSTER_RACK_ID sync
3. Redefina os registros de configuração para 0x102:
confreg 0x102 reset
O RSP ativo está definido.
4. Conecte o cabo do console ao RSP em standby no chassi 0.
Observação: as ações descritas nesta etapa precisam ser feitas em ambos os RSPs do chassi 1. O RSP ativo deve ser inicializado primeiro.
Etapa 15. Inicialize o chassi 0 como um sistema independente e configure-o de acordo
Idealmente, a nova configuração ou vários fragmentos de configuração são armazenados em cada chassi ASR9k e carregados após a desorganização. A sintaxe de configuração correta deve ser testada no laboratório anteriormente. Caso contrário, configure primeiro as interfaces de console e de MGMT, antes de concluir a configuração no chassi 0 por meio de VTY (Copiar e Colar) ou carregue a configuração remotamente de um servidor TFTP.
Observação: os comandos load config e commit mantêm todas as interfaces desligadas, o que permite um aumento de serviço controlado. load config e commit replace, substitui totalmente a configuração e ativa as interfaces. Portanto, é recomendável usar load config e commit.
Adaptar a configuração de sistemas finais conectados (FW, Switches, etc.) e dispositivos de núcleo (P, PE, RR, etc.) ao chassi 0.
Etapa 16. Restaure os serviços principais no chassi 0
- Desligue manualmente as interfaces principais primeiro.
- Verifique adjacências/peers LDP, ISIS e BGP.
- Verifique se as tabelas de roteamento e certifique-se de que todos os prefixos foram trocados.
Aviso: Cuidado com os temporizadores, como ISIS OL-Bit, atraso de HSRP, atraso de atualização de BGP, etc., antes de passar para o failover!
Etapa 17. Restaure South-Side no chassi 0
1. no shut all access interfaces.
2. Verificar adjacências/peers/DB de IGP e BGP
3. Verifique se o link entre chassis (IRL anterior) está ativado, se necessário para a extensão L2, etc.

Apêndice 1: Configuração de chassi único
Alterações gerais de configuração
Essa configuração do roteador precisa ser modificada em um dos chassis:
- Endereços de Interface de Loopback.
- Numeração da interface (por exemplo, Te1/x/x/x -> Te0/x/x/x).
- Descrições de interface.
- Endereçamento de interface (ao dividir pacotes existentes).
- Novas BVIs (quando o domínio L2 é dual-homed).
- Extensão L2 (quando o domínio L2 é dual-homed).
- HSRP para roteamento estático no acesso.
- ID do roteador BGP/Open Shortest Path First (OSPF)/LDP.
- BGP Route-Distinguishers.
- Pares BGP.
- Tipo de rede OSPF.
- Identificações de Protocolo de Gerenciamento de Rede Simples (SNMP - Simple Network Management Protocol), etc.
- Lista de Controle de Acesso (ACL - Access Control List), Conjuntos de Prefixos, Protocolo de Roteamento para LLN (Low-Power and Lossy Networks) (RPL), etc.
- Hostname.
Visão geral do pacote
Verifique se todos os pacotes foram revisados e aplicados à nova configuração de PE duplo. Talvez você não precise mais de pacotes e os dispositivos dual homed customer-premises equipment (CPE) se encaixem na sua configuração ou você precise de MCLAG em dispositivos PE e mantenha os pacotes em relação aos CPEs.
Apêndice 2: Definir a variável de cluster sem inicializar o sistema no ROMMON
Há também uma alternativa para definir as variáveis de cluster. As variáveis de cluster podem ser definidas antecipadamente usando este procedimento:
RP/0/RSP0/CPU0:xr#run Wed Jul 5 10:19:32.067 CEST # cd /nvram: # ls cepki_key_db classic-rommon-var powerup_info.puf sam_db spm_db classic-public-config license_opid.puf redfs_ocb_force_sync samlog sysmgr.log.timeout.Z # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , CLUSTER_RACK_ID = 1, TFTP_RETRY_COUNT = 4, confreg = 0x2102 # nvram_rommonvar CLUSTER_RACK_ID 0 <<<<<<< to set CLUSTER_RACK_ID=0 # more classic-rommon-var PS1 = rommon ! > , IOX_ADMIN_CONFIG_FILE = , ACTIVE_FCD = 1, TFTP_TIMEOUT = 6000, TFTP_CHECKSUM = 1, TFTP_MGMT_INTF = 1, TFTP_MGMT_BLKSIZE = 1400, TURBOBOOT = , ? = 0, DEFAULT_GATEWAY = 127.1.1.0, IP_SUBNET_MASK = 255.0.0.0, IP_ADDRESS = 127.0.1.0, TFTP_SERVER = 127.1.1.0, CLUSTER_0_DISABLE = 0, CLUSTERSABLE = 0, CLUSTER_1_DISABLE = 0, TFTP_FILE = disk0:asr9k-os-mbi-5.3.4/0x100000/mbiasr9k-rp.vm, BSS = 4097, BSI = 0, BOOT = disk0:asr9k-os-mbi-6.1.3/0x100000/mbiasr9k-rp.vm,1;, CLUSTER_NO_BOOT = , BOOT_DEV_SEQ_CONF = , BOOT_DEV_SEQ_OPER = , TFTP_RETRY_COUNT = 4, CLUSTER_RACK_ID = 0, confreg = 0x2102 #exit RP/0/RSP0/CPU0:xr#
Recarregue o roteador e ele será inicializado como uma caixa independente. Com esta etapa, você pode pular para inicializar o roteador a partir do ROMMON.
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
1.0 |
05-Apr-2019 |
Versão inicial |
Colaboração de
- Robert VerlicServiços avançados
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)