Introdução
Este documento descreve como gravar e configurar um filtro para detectar e executar ações em conjuntos de caracteres baseados em tipo de conteúdo no Cisco Email Security Appliance (ESA). O documento a seguir pode ser usado para detectar caracteres baseados em idioma estrangeiro vistos em mensagens de spam.
Informações de Apoio
Os administradores do ESA podem receber um influxo de mensagens de correio que contenham idiomas estrangeiros baseados em caracteres que não sejam correio legítimo para sua empresa ou domínio(s). Uma forma de lidar com o ESA é através de três opções:
-
Grave um filtro para detectar o tipo de conteúdo.
-
Escrever um filtro para fazer referência a um dicionário baseado em caracteres em um filtro.
- Grave um filtro usando a condição Idioma da Mensagem. (Esta opção é um novo recurso para o AsyncOS Email Security 10.0.0-203 e mais recente.)
Como bloquear conjuntos de caracteres baseados em tipo de conteúdo
Gravar um filtro para detectar o tipo de conteúdo
A primeira opção é que o administrador grave e configure um filtro e associe-o a uma política de e-mail, conforme necessário.
Observação: escrever e configurar este filtro como um filtro de mensagem pode ser um recurso caro para verificar o corpo de e-mails para os conjuntos de caracteres.
Observação: é altamente recomendável configurar isso como um filtro de conteúdo, pois os filtros de conteúdo ocorrem após a varredura antisspam. No entanto, isso pode ser gravado e configurado como um filtro de mensagens, se necessário.
O exemplo a seguir levará em consideração uma mensagem de correio que contém caracteres baseados em russo (cirílico) através do conjunto de caracteres baseado no Windows-1251. Escrito como um filtro de conteúdo:
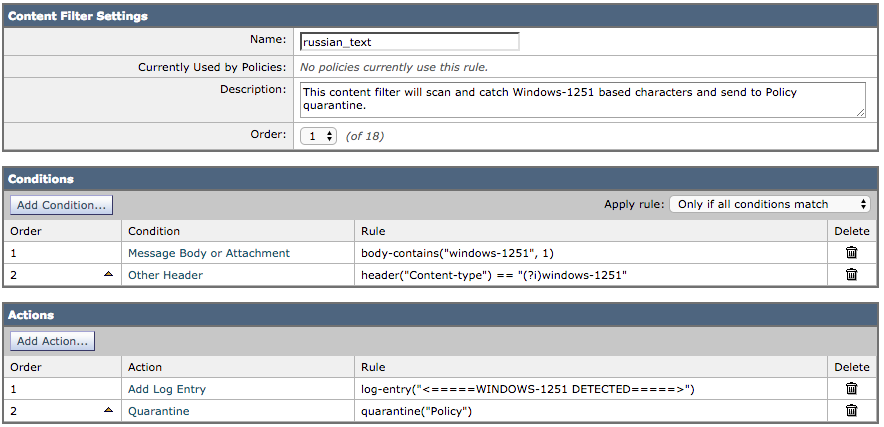
O email de teste usado conterá o seguinte no corpo do email:
Russian uses а, э, ы, у, o, я, е, ё, ю, и as vowels. You could create a message filter set to "Matches any of the following" that test whether "Body" "contains" "и", "Body" "contains" "ё" and so forth until you covered all of the vowels. Ssince English also uses "a" , "e" , "o", and "y" letters don't test for them. The reason for "Matches any of the following" is to logically OR them - you want the action to take place if any of those letters are found.
Com o filtro de conteúdo configurado como acima, os logs de e-mail gravariam semelhante ao seguinte:
Thu Sep 10 14:50:09 2015 Info: Start MID 164993 ICID 266729
Thu Sep 10 14:50:09 2015 Info: MID 164993 ICID 266729 From: <end_user@test.com>
Thu Sep 10 14:50:09 2015 Info: MID 164993 ICID 266729 RID 0 To: <recpient@my_co.com>
Thu Sep 10 14:50:09 2015 Info: MID 164993 using engine: SPF Verdict Cache using cached verdict
Thu Sep 10 14:50:09 2015 Info: MID 164993 Message-ID '<7A961F85-A5F1-413F-87CB-C31D2E5605EC@my_co.com>'
Thu Sep 10 14:50:09 2015 Info: MID 164993 Subject 'russian test'
Thu Sep 10 14:50:09 2015 Info: MID 164993 ready 2302 bytes from <end_user@test.com>
Thu Sep 10 14:50:09 2015 Info: MID 164993 matched all recipients for per-recipient policy DEFAULT in the inbound table
Thu Sep 10 14:50:09 2015 Info: MID 164993 AMP file reputation verdict : CLEAN
Thu Sep 10 14:50:09 2015 Info: MID 164993 using engine: GRAYMAIL negative
Thu Sep 10 14:50:09 2015 Info: MID 164993 Custom Log Entry: <====== WINDOWS-1251 DETECTED ======>
Thu Sep 10 14:50:09 2015 Info: MID 164993 quarantined to "Policy" (content filter:russian_text)
Thu Sep 10 14:50:09 2015 Info: Message finished MID 164993 done
Outros idiomas e conjuntos de caracteres podem ser usados. Consulte a seção Referências para obter informações adicionais.
Escrever um filtro para fazer referência a um dicionário baseado em caracteres
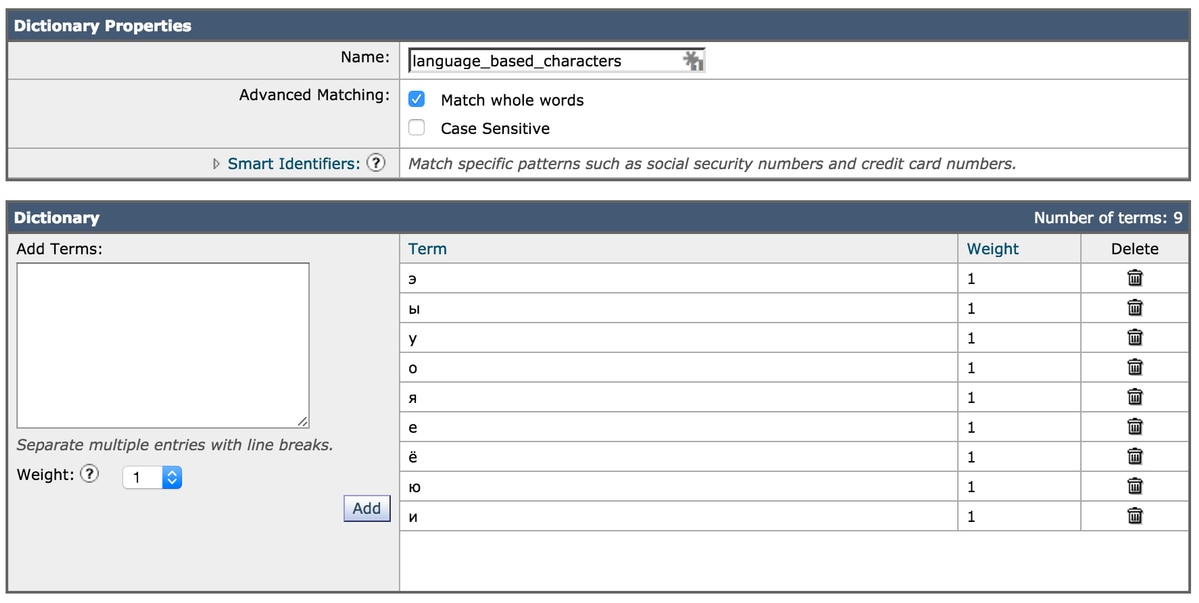
A segunda opção é adicionar a lista de conjuntos de caracteres a um arquivo de texto do dicionário e fazer referência a isso no filtro.
Exemplo de adição de caracteres ao dicionário:
Os caracteres agora são atribuídos ao dicionário e o próprio dicionário é referenciado nos itens de condição do filtro:
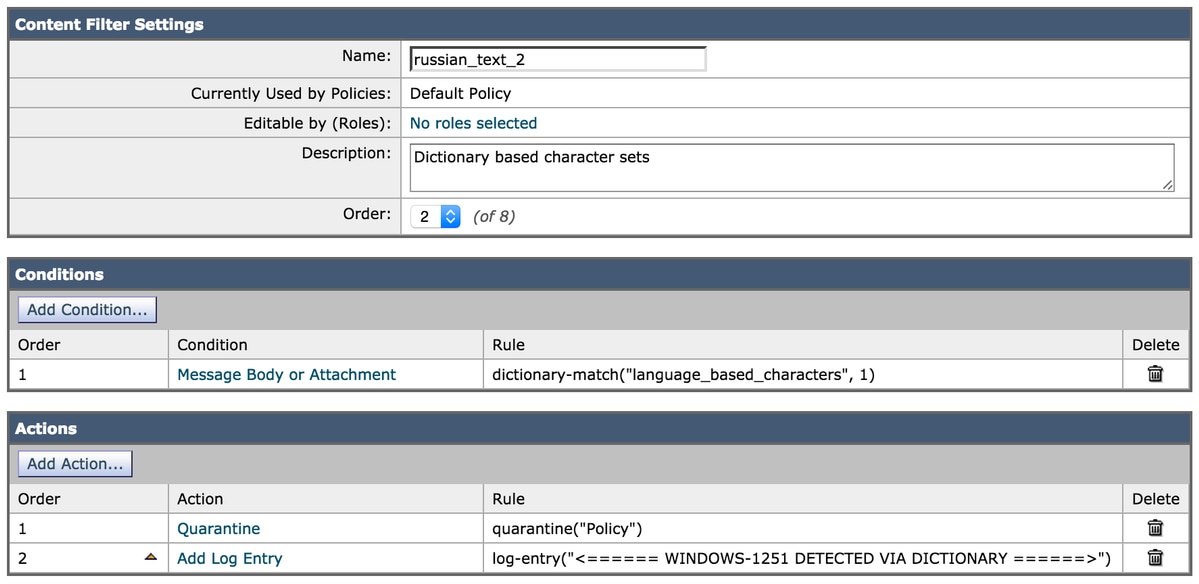
Usando o mesmo email de teste acima, ele contém o seguinte no corpo do email:
Russian uses а, э, ы, у, o, я, е, ё, ю, и as vowels. You could create a message filter set to "Matches any of the following" that test whether "Body" "contains" "и", "Body" "contains" "ё" and so forth until you covered all of the vowels. Ssince English also uses "a" , "e" , "o", and "y" letters don't test for them. The reason for "Matches any of the following" is to logically OR them - you want the action to take place if any of those letters are found.
Com o filtro de conteúdo configurado como acima usando a condição de correspondência de dicionário, os logs de e-mail gravariam semelhante ao seguinte:
Thu Sep 10 15:26:08 2015 Info: Start MID 164995 ICID 266737
Thu Sep 10 15:26:08 2015 Info: MID 164995 ICID 266737 From: <end_user@test.com>
Thu Sep 10 15:26:08 2015 Info: MID 164995 ICID 266737 RID 0 To: <recpient@my_co.com>
Thu Sep 10 15:26:08 2015 Info: MID 164995 using engine: SPF Verdict Cache using cached verdict
Thu Sep 10 15:26:08 2015 Info: SPF Verdict Cache cache status: hits = 6, misses = 4, expires = 1, adds = 4, seconds saved = 0.50, total seconds = 0.85
Thu Sep 10 15:26:08 2015 Info: MID 164995 Message-ID '<BCC88307-EB91-476E-8732-334E9EE84EC8@my_co.com>'
Thu Sep 10 15:26:08 2015 Info: MID 164995 Subject 'russian test 3'
Thu Sep 10 15:26:08 2015 Info: MID 164995 ready 2316 bytes from <end_user@test.com>
Thu Sep 10 15:26:08 2015 Info: MID 164995 matched all recipients for per-recipient policy DEFAULT in the inbound table
Thu Sep 10 15:26:08 2015 Info: MID 164995 AMP file reputation verdict : CLEAN
Thu Sep 10 15:26:08 2015 Info: MID 164995 using engine: GRAYMAIL negative
Thu Sep 10 15:26:08 2015 Info: MID 164995 Custom Log Entry: <====== WINDOWS-1251 DETECTED VIA DICTIONARY ======>
Thu Sep 10 15:26:08 2015 Info: MID 164995 quarantined to "Policy" (content filter:russian_text_2)
Thu Sep 10 15:26:08 2015 Info: Message finished MID 164995 done
Gravar um filtro de conteúdo usando a condição "Idioma da mensagem"
A terceira opção é usar a condição "linguagem de mensagem". O ESA usa o mecanismo de detecção de idioma integrado para detectar o idioma em uma mensagem. O equipamento extrai o assunto e o corpo da mensagem e o passa para o mecanismo de detecção de idioma.
O mecanismo de detecção de idioma determina a probabilidade de cada idioma no texto extraído e o repassa ao equipamento. O equipamento considera o idioma com maior probabilidade como o idioma da mensagem. O equipamento considera o idioma da mensagem como "indeterminado" em um dos seguintes cenários:
- Se o ESA não oferecer suporte ao idioma detectado
- Se o equipamento não puder detectar o idioma da mensagem
- Se o tamanho total do texto extraído enviado ao mecanismo de detecção de idioma for menor que 50 bytes.
Observação: Esta opção é um novo recurso para o AsyncOS Email Security 10.0.0-203 e mais recente.
O exemplo a seguir levará em conta uma mensagem de correio que contém um conjunto de caracteres baseado em chinês/Taiwan. Escrito como um filtro de conteúdo:
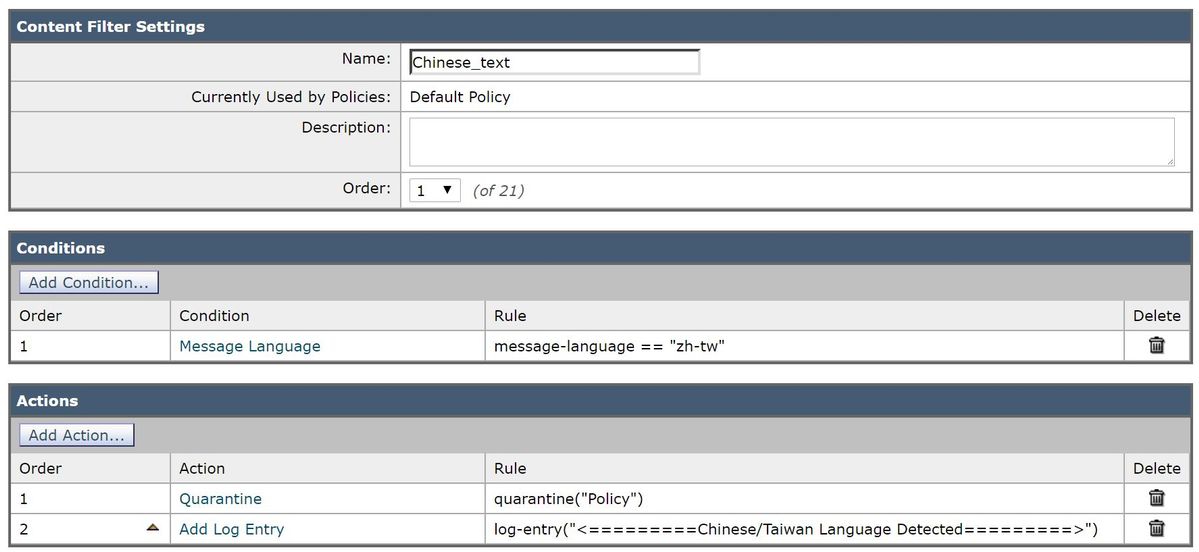
Com o filtro de conteúdo configurado como acima, os logs de e-mail gravariam semelhante ao seguinte:
Tue Feb 28 06:53:18 2017 Info: Start MID 481 ICID 27
Tue Feb 28 06:53:18 2017 Info: MID 481 ICID 27 From: <end_user@test.com>
Tue Feb 28 06:53:18 2017 Info: MID 481 ICID 27 RID 0 To: <recipient@my_co.com>
Tue Feb 28 06:53:18 2017 Info: MID 481 Subject 'Chinese text test'
Tue Feb 28 06:53:18 2017 Info: MID 481 ready 1047 bytes from <end_user@test.com>
Tue Feb 28 06:53:18 2017 Info: MID 481 matched all recipients for per-recipient policy DEFAULT in the inbound table
Tue Feb 28 06:53:18 2017 Info: MID 481 interim verdict using engine: CASE spam negative
Tue Feb 28 06:53:18 2017 Info: MID 481 using engine: CASE spam negative
Tue Feb 28 06:53:18 2017 Info: MID 481 interim AV verdict using Sophos CLEAN
Tue Feb 28 06:53:18 2017 Info: MID 481 antivirus negative
Tue Feb 28 06:53:18 2017 Info: MID 481 using engine: GRAYMAIL negative
Tue Feb 28 06:53:18 2017 Info: MID 481 Message language: 'Chinese/Taiwan'
Tue Feb 28 06:53:18 2017 Info: MID 481 Custom Log Entry: <=========Chinese/Taiwan Language Detected=========>
Tue Feb 28 06:53:18 2017 Info: MID 481 Outbreak Filters: verdict negative
Tue Feb 28 06:53:18 2017 Info: MID 481 quarantined to "Policy" (content filter:Chinese_text)
Tue Feb 28 06:53:18 2017 Info: Message finished MID 481 done
Referências
Observação: as páginas de código ANSI podem ser diferentes em diferentes computadores ou podem ser alteradas para um único computador, levando à corrupção de dados. Para obter os resultados mais consistentes, os aplicativos devem usar Unicode, como UTF-8 ou UTF-16, em vez de uma página de código específica.
- Mozilazina fornece detalhes detalhados para o tipo de conteúdo: cabeçalho, letras estrangeiras, palavras estrangeiras e muito mais no artigo para Spam em idioma estrangeiro
Informações Relacionadas
 Feedback
Feedback