Introdução
Este documento descreve as etapas de solução de problemas para lidar com erros de memória em servidores UCS.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos.
- Entendimento básico do UCS.
- Entendimento básico da arquitetura de memória.
Componentes Utilizados
As informações neste documento são baseadas nestas versões de software e hardware:
- Servidores da família UCS M5, M6, M7 e superiores.
- UCS Manager
- Controlador de gerenciamento integrado da Cisco (CIMC)
- Modo gerenciado Cisco Intersight (IMM)
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
Erros de memória
Erros de memória são encontrados quando é feita uma tentativa de ler um local de memória. O valor lido na memória não corresponde ao valor que deveria estar lá. Esses erros são classificados em dois tipos:
1. Erros de software
Os erros de software são transitórios e não continuam a ser repetidos. Eles são temporários e geralmente podem ser corrigidos repetindo a leitura ou regravando o local da memória.
2. Erros Graves
Defeitos físicos permanentes os causam. Regravar o local da memória e tentar novamente o acesso de leitura não elimina um erro de hardware. Como resultado, esse erro de memória não pode ser corrigido e a memória precisa ser substituída, pois o erro continua a se repetir.
Erros corrigíveis
Se forem detectados e corrigidos erros, eles serão considerados corrigíveis. Isso pode ser feito repetindo-se a leitura ou calculando-se o conteúdo correto da memória usando dados ECC (Error Correction Code — Código de Correção de Erros) e gravando-se os dados apropriados de volta na memória. Depois que um erro é detectado e corrigido, o Cisco Integrated Management Controller (IMC) registra o evento no registro de eventos do sistema.
Normalmente, os erros corrigíveis são o resultado de erros de software. Se os erros corrigíveis persistirem no mesmo local de memória por um período prolongado, isso pode indicar um possível erro de hardware.
ADDC (Adaptive Double Device Data Correction, Correção de dados do dispositivo duplo adaptável)
O sobressalente ADDC pode corrigir duas falhas sucessivas de DRAM se elas residirem na mesma região. O ADDC move dinamicamente os dados de bits com falha para a memória sobressalente, evitando que erros corrigíveis se tornem incorrigíveis. É necessário um limite de erros de ECC corrigíveis para acionar o mecanismo.
O ADDC ajuda em alguns cenários em que erros de ECC corrigíveis precedem erros de ECC incorrigíveis.
PPR (Post Package Repair, Reparo pós-pacote)
O PPR (Post Package Repair, Reparo pós-pacote) pode reparar permanentemente regiões de memória com falha dentro de um DIMM aproveitando as linhas de DRAM redundantes. Esse reparo permanente em campo permite uma recuperação rápida de erros de hardware sem a necessidade de substituir o DIMM. Para executar um reparo, o sistema deve passar por um evento ADDC e passar por pelo menos um ciclo de reinicialização. Esta atividade de reparo não afeta o desempenho ou a memória total disponível para o sistema operacional.
O PPR e o ADDC são ativados por padrão, no entanto, podem ser configuráveis. O PPR exige que o modo ADDC Sparing RAS também esteja habilitado. Se a configuração do RAS for diferente de ADDC Sparing ou Platform Default, o PPR não estará operacional. O único modo PPR suportado é PPR Forçada, o que significa que os reparos são permanentes.
Sobressalente de linha de cache parcial (PCLS)
Há um mecanismo de prevenção de erros no controlador da memória. Ele funciona identificando pequenas partes defeituosas de dados na memória. Esses locais defeituosos são registrados em um diretório especial, junto com os dados de backup que podem substituí-los. Quando a memória é acessada, se houver um erro nesses pontos defeituosos, o controlador usa os dados de backup do diretório para garantir que tudo funcione sem problemas.
Observação: os recursos estão disponíveis dependendo da arquitetura da CPU e da versão do firmware em execução no servidor. Verifique se você está na última versão recomendada para lidar melhor com os erros de memória.
Identificar e Solucionar Falhas de RAS
UCS Manager
Geralmente, você vê essas falhas no UCS Manager como um evento RAS.
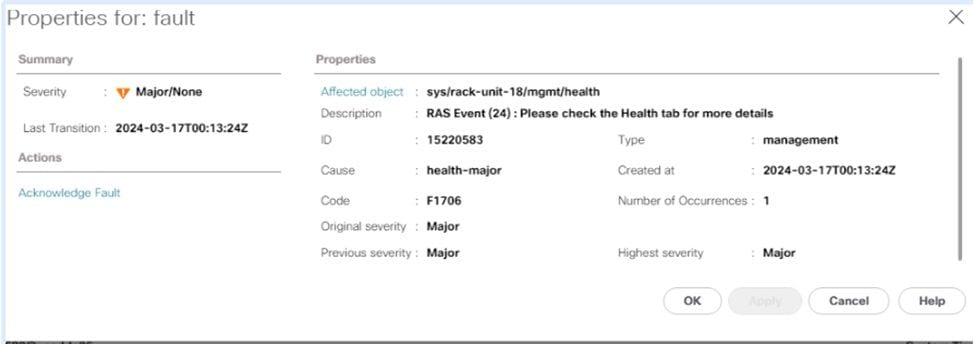
No resumo da integridade, você encontrará mais informações sobre o erro, se PCLS ou PPR foram disparados.
exemplo de PCLS
Em servidores M6 e mais recentes, você tem a opção de habilitar o PCLS (Patrial Cache Line Sparing) como uma opção do BIOS, que é um mecanismo de prevenção de erros. O servidor deve ser reinicializado o mais rápido possível, para que o PPR possa iniciar e reparar o DIMM. Depois que o servidor for reinicializado, monitore se há falhas adicionais do UCS Manager para o mesmo DIMM.
Como o alerta menciona, é recomendável reinicializar o servidor o mais rápido possível, pois há um risco associado de ocorrer um erro incorrigível e, consequentemente, um tempo de inatividade inesperado do servidor.
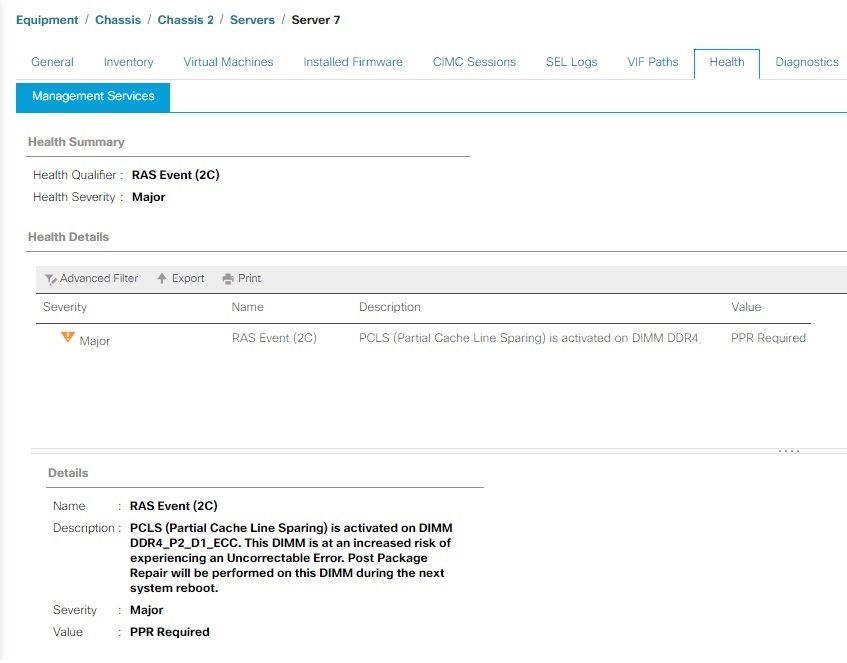
exemplo de PPR
O servidor tem ADDC e PPR habilitados, e ocorreu um evento RAS. A falha sugere a reinicialização do PPR para reparar o DIMM. O servidor precisa ser reinicializado o mais rápido possível para que o PPR inicie e repare o DIMM.
Depois que o servidor for reinicializado, monitore se há falhas adicionais do UCS Manager para o mesmo DIMM.
Como o alerta menciona, é recomendável reinicializar o servidor o mais rápido possível, pois há um risco associado de ocorrer um erro incorrigível e, consequentemente, um tempo de inatividade inesperado do servidor.
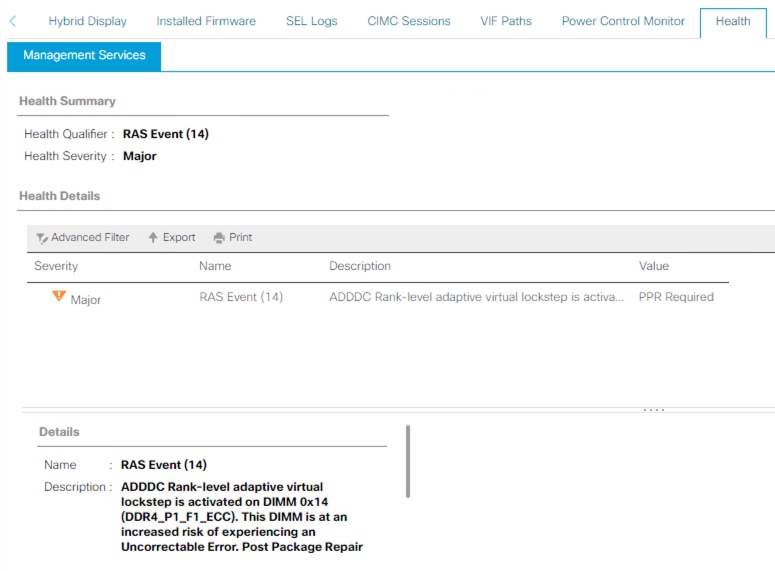
Modo Gerenciado de Intervisão
O servidor tem ADDC habilitado e ocorreu um evento BANK VLS, criando a falha exibida. Neste cenário, a próxima etapa é executar uma reinicialização do servidor o mais rápido possível para permitir que o PPR seja executado.

Controlador de gerenciamento integrado da Cisco (CIMC)
A falha aparece como mostrado ao usar o Cisco Integrated Management Controller. Se o servidor tiver um ADDC e um evento VLS tiver ocorrido, isso estará funcionando conforme planejado para evitar erros incorrigíveis.
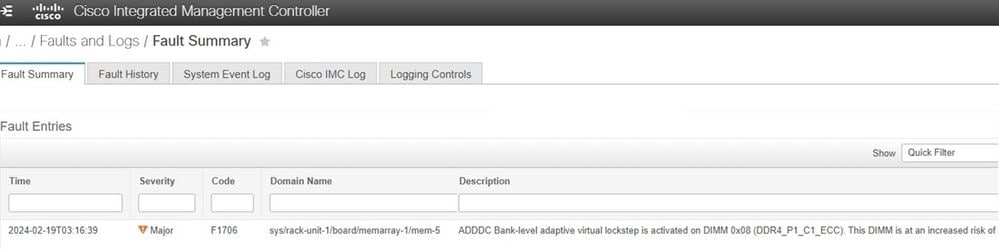
Passos de Troubleshooting
- Verifique se não há outras falhas de DIMM presentes, por exemplo, e erro incorrigível.
- Programe uma janela de manutenção.
- Coloque um host no modo de manutenção e reinicialize o servidor para tentar reparar permanentemente o DIMM usando o PPR (Post Package Repair, reparo pós-pacote).
Etapas de reinicialização do UCSM
Observação: você também pode reinicializar o servidor a partir do SO. Este exemplo usa a opção de reinicialização da interface do usuário do servidor.
Navegue até a interface da Web do UCS Manager.
Servidor blade
Navegue até Equipment > Chassis > Server X.
Servidor integrado
Navegue até Equipment > Rack-Mounts > Server X.
Clique em KVM console.
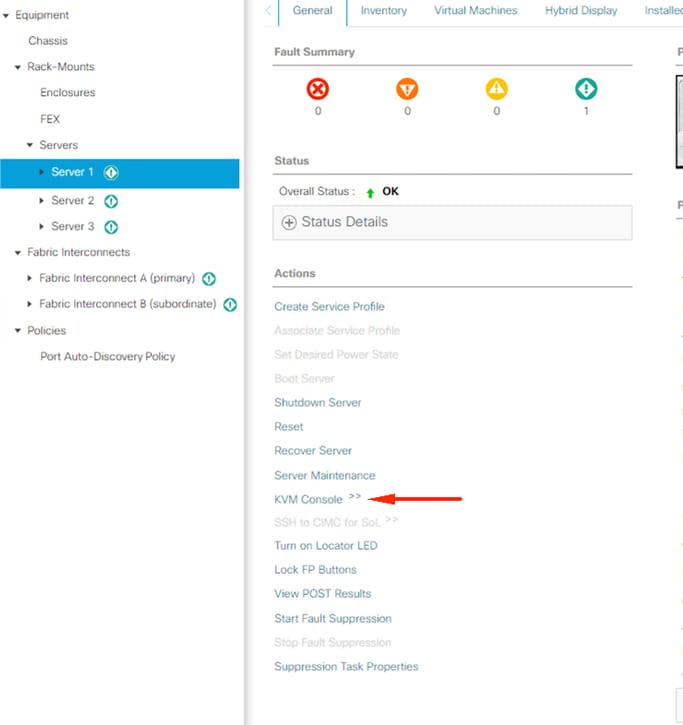
nas janelas KVM, clique em ações do servidor, selecione Redefinir e clique em OK.
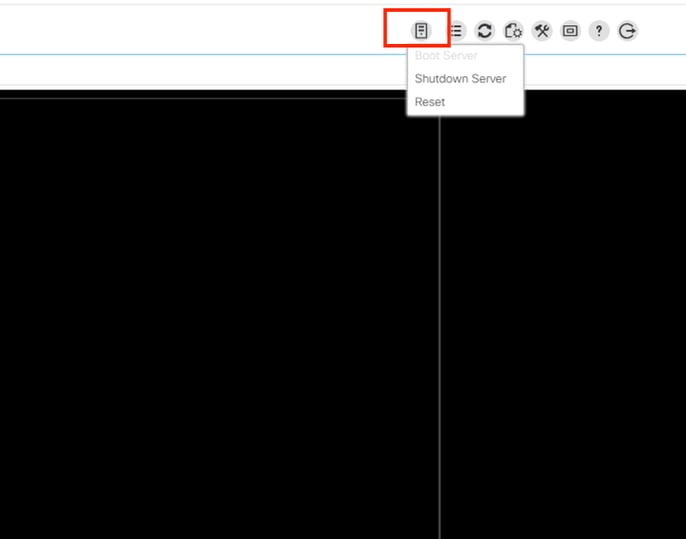
Monitore no KVM o processo de reinicialização e certifique-se de que o sistema operacional inicialize corretamente.
Etapas de reinicialização do IMM
Navegue até a guia Servers, identifique o servidor e clique no menu Action (três pontos).
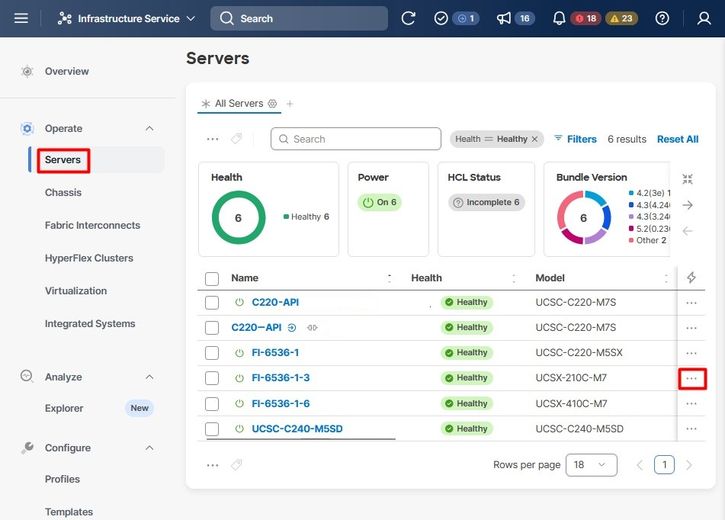
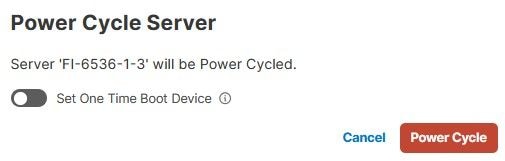
Em seguida, selecione o menu Power e a opção Power Cycle.
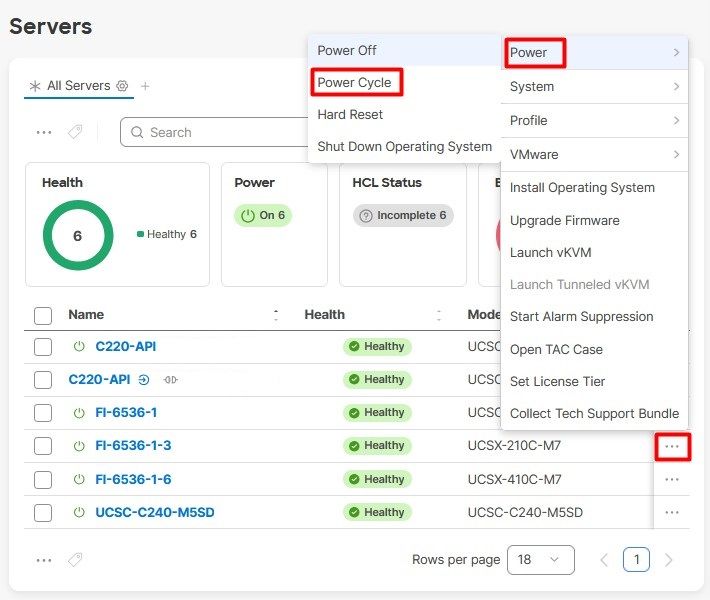
Clique no botão Power Cycle para confirmar a ação.
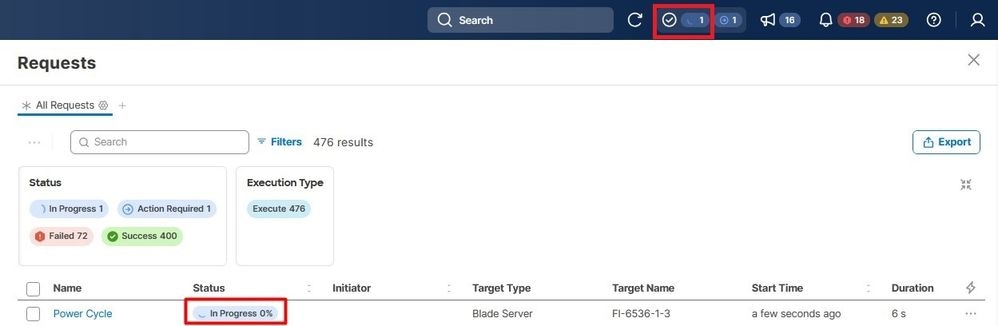
Valide o progresso no menu Solicitações.
Etapas de reinicialização do CIMC
Navegue até a opção Host Power e selecione Power Cycle.
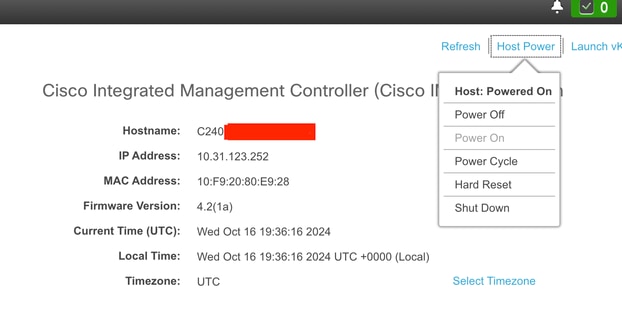
Inicie o KVM para monitorar o processo de reinicialização e verifique se o SO é inicializado corretamente.
Monitorar novas falhas
Se nenhum erro ocorrer após a reinicialização, significando que não há nenhum outro evento RAS ou falha relacionada ao DIMM, o PPR foi bem-sucedido e o servidor pode ser colocado novamente em uso.
Se ocorrerem novos eventos ADDC, repita o processo de reinicialização descrito nas etapas anteriores para executar reparos permanentes adicionais com o PPR.
Se um erro incorrigível ou uma falha inoperável ocorrer após a reinicialização, a falha indica que uma memória precisa ser substituída.
Nota: Abra um caso no Cisco TAC para substituir o DIMM se você encontrar alguma dessas falhas.
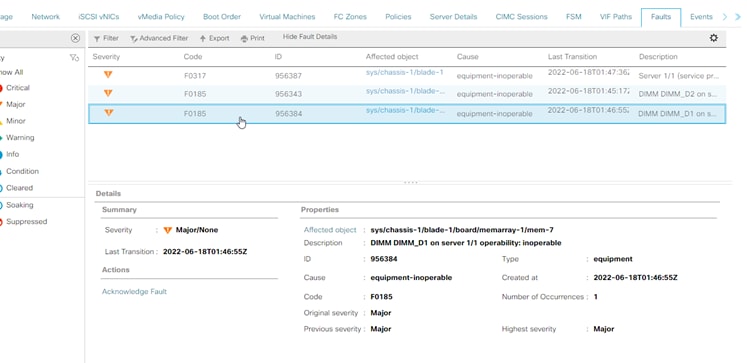
Erro de memória incorrigível do UCS Manager
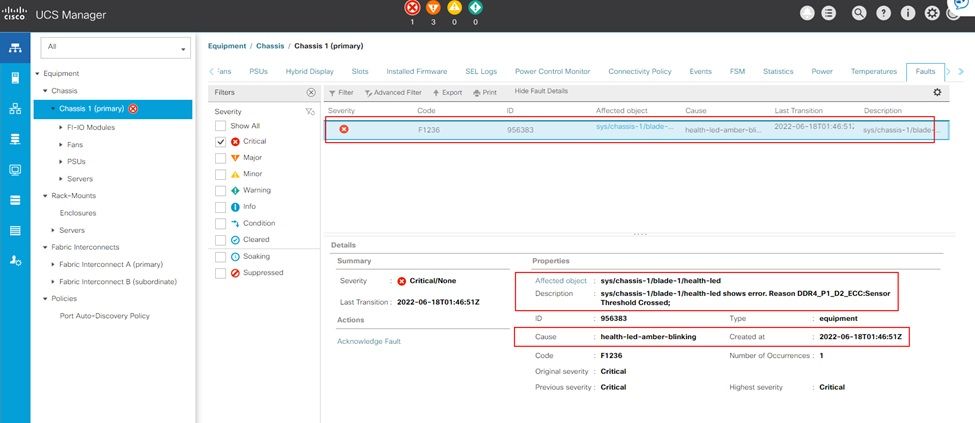
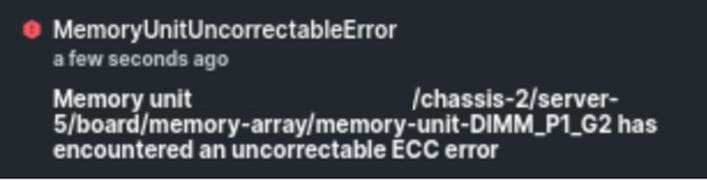
Erro incorrigível de memória IMM
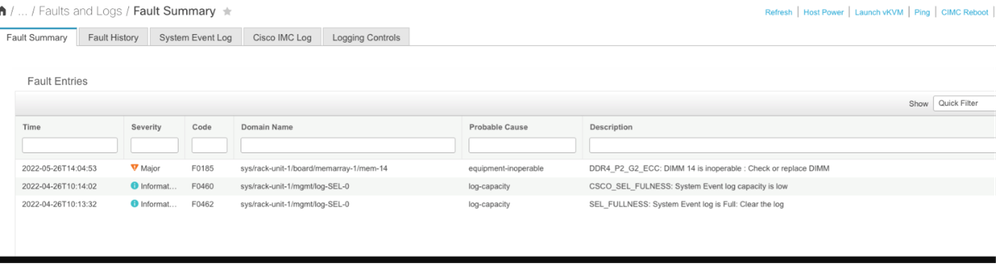
Falha de erro incorrigível. A falha indica que o DIMM tem um erro incorrigível e precisa ser substituído.
Erro de memória incorrigível do CIMC
Informações Relacionadas
 Feedback
Feedback