Introdução
Este documento descreve como solucionar problemas comuns de falha de servidor inacessível que podem ser observados na maioria dos tipos de servidores UCS.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento de gerenciamento de servidores no Unified Computing System Manager (UCSM) e no Intersight Managed Mode (IMM).
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
Há uma falha comum que os usuários podem receber em seus domínios do UCS, que é notificar você de que um servidor está inacessível. Isso pode ocorrer por vários motivos e a falha pode parecer de várias maneiras diferentes, dependendo das ferramentas de monitoramento e das versões do UCSM/IMM.
System Notification from [UCSM Domain Name] - diagnostic:GOLD-minor - 2023-05-25 01:56:41 GMT-04:00 Recovered : Server x/y (service profile: org-root/ls-[service_profile]) inaccessible
Serial number: [Server Serial]
Alert: System Name: [UCSM Domain Name]
Time of Event:2022-08-31 03:15:04 GMT-05:00 Event Description:Server x (service profile: org-root/ls-[service_profile]) inaccessible Severity Level:4
Se o IMM estiver em uso, uma mensagem de conexão com o servidor perdida pode ser vista na GUI. A desconexão de falhas de Intersight também pode ser observada.
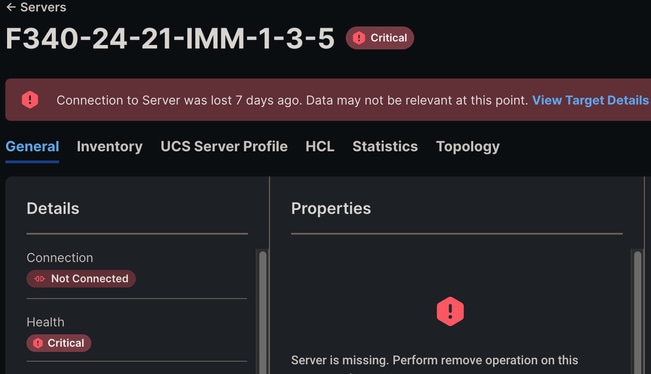 A conexão com o servidor foi perdida IMM
A conexão com o servidor foi perdida IMM
Esse alerta pode ser visto quando o Cisco Integrated Management Controller (CIMC) em um blade encontra um problema e reinicializa ou tenta reinicializar. Isso aciona um alerta de Servidor inacessível porque, enquanto o plano de gerenciamento do blade está sendo reinicializado, o UCSM/IMM não pode se comunicar com o blade, portanto, ele acha que está inacessível. Quando o CIMC for reinicializado, o estado dos blades retornará ao normal.
É por isso que você pode receber esse alerta e, quando você verificar o domínio, o servidor será examinado e estará íntegro.
Referência comum a defeitos
ID de bug da Cisco CSCwe19822 - Aplica-se a servidores M5/M6 após 4.2(2c)/After 5.0(1c) para X series
ID de bug Cisco CSCwa8567 - Aplica-se a servidores M5/M6 entre 4.1(3e) - 4.2(2a) Também inclui X series após 5.0(1b)
ID de bug Cisco CSCvz62711 - Aplica-se a servidores M5/M6 entre 4.1(3d) - 4.2(2a)
ID de bug da Cisco CSCwi50991 - Aplica-se a blades M5/M6 Series no código anterior ao 4.3(2e)
ID de bug da Cisco CSCv79912 - Aplica-se a servidores M5/M6 entre 4.0(4h) e 4.2(1a)/4.1(3d)
ID de bug Cisco CSCvh25786 - Aplica-se a servidores M4/M5 após 2.0(13f) e 3.0(4a)
Troubleshooting
Cenário 1
A primeira e mais comum situação é receber o alerta e, em seguida, ao verificar UCSM/IMM, o servidor parece operável, íntegro e sem falhas (novas). Ao verificar o sistema operacional, ele parece estar ativo e funcionando sem interrupções.
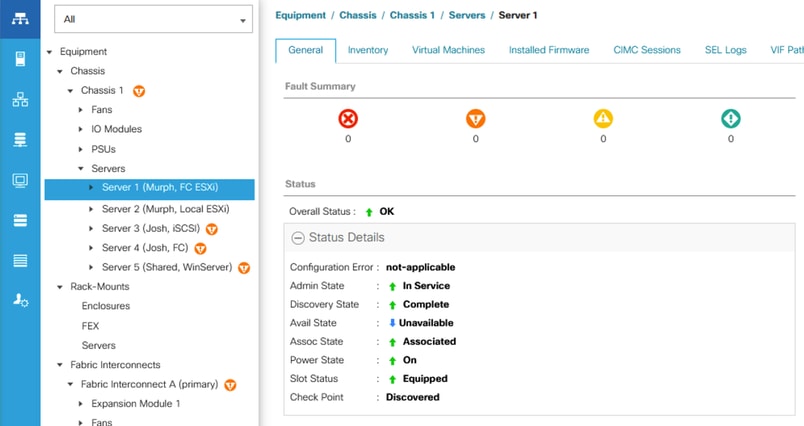 Servidor íntegro no UCSM
Servidor íntegro no UCSM
Os pacotes de log mostram essa mensagem em um dos logs OBFL que podem ser encontrados em CIMCx_TechSupport.tar.gz > obfl > obfl-log.
3:2022 Sep 8 10:54:33 UTC:+0000:(4.2(2d)):kernel:-:[watchdog_init]:976:BMC Watchdog resetted BMC.
Isso nos diz que o CIMC falhou e foi reinicializado sozinho.
Nesse cenário, nenhuma ação adicional é necessária, pois o CIMC foi reinicializado com êxito e não há problemas com o servidor.
Cenário 2
A próxima situação é receber o alerta e, ao verificar UCSM/IMM, o servidor ainda aparece como inacessível se estiver usando UCSM ou desconectado se estiver usando IMM. Ao verificar o sistema operacional, ele parece estar ativo e funcionando sem interrupções.
Como o SO está ativo e em execução, mas o UCSM/IMM não pode se comunicar com o blade, isso significa que o CIMC não reinicializou ou parou no processo.
A primeira etapa neste cenário é usar SSH ou Console para as interconexões de estrutura (FI) e executar este comando substituindo x/y pelo chassi/blade afetado. Há três resultados diferentes.
1) A conexão com o CIMC foi bem-sucedida.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
Trying 127.5.1.1...
Connected to 127.5.1.1.
Escape character is '^]'.
CIMC Debug Firmware Utility Shell [ support ]
[ help ]#
Se essa saída for vista, ainda haverá vida útil no CIMC e você poderá tentar redefinir o CIMC para recuperar o blade.
Se o UCSM estiver em uso, navegue até Equipment > Chassis > Chassis Number > Servers > Server Number > Recover Server > Reset CIMC.
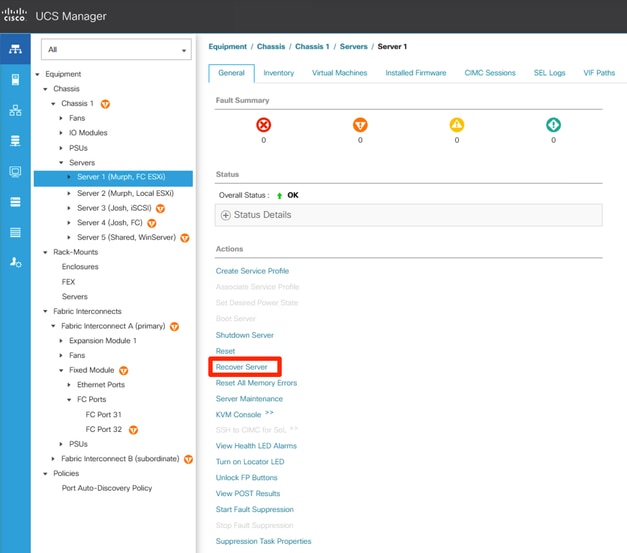 Local do servidor de recuperação para blade
Local do servidor de recuperação para blade
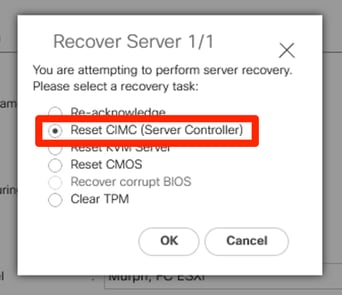 Redefinir CIMC
Redefinir CIMC
Se o IMM estiver em uso, navegue até o servidor afetado e selecione Ações > Sistema > Reinicializar controlador de gerenciamento.
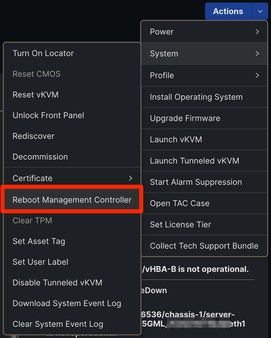 Reinicializar IMM do Controlador de Gerenciamento
Reinicializar IMM do Controlador de Gerenciamento
Se, após a reinicialização do CIMC, o servidor voltar ao normal, o problema será resolvido e nenhuma outra ação será necessária.
Se a falha persistir, continue com as etapas de solução de problemas da próxima saída connect cimc.
2) Falha na conexão com o CIMC.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
Trying 127.5.1.8...
telnet: Unable to connect to remote host: No route to host
3) Conexão com interrupções do CIMC. Nesse caso, nada acontece depois de executar o comando e ao tentar escapar (Ctrl + C) isso é observado.
UCSM-A# connect cimc x (For C Series Rack Mount Server)
UCSM-A# connect cimc x/y (For B/X Series Blade Server)
^C
Console escape. Commands are:
l go to line mode
c go to command mode
z suspend telnet
e exit telent
continuing...
A solução de problemas para qualquer uma das duas últimas saídas é a mesma. Nesses casos, o CIMC está completamente inoperante e não consegue se comunicar com as interconexões em malha. É necessário reinicializar o servidor para recuperar o CIMC. É sempre recomendável obter uma janela de manutenção ao reinicializar blades.
Se o UCSM estiver em uso, você poderá simular a reinstalação física do blade por SSHing para as interconexões de estrutura e executando este comando substituindo x/y pelo chassi/servidor afetado. É imperativo que você insira o chassi/servidor correto, pois esse comando não solicita a confirmação.
UCSM-A# reset slot x/y

Observação: o comando reset slot reinicializa o blade no slot designado x/y imediatamente. Verifique se o servidor pode ser reinicializado com segurança se o sistema operacional ainda estiver em execução.
Esse comando não retorna nada se for bem-sucedido. Se o comando não for executado, uma mensagem será exibida.
Se o IMM estiver em uso ou o comando reset slot não resolveu o problema inacessível, a única outra opção será reinstalar fisicamente a lâmina.
Se, após recolocar fisicamente a lâmina, o problema continuar, entre em contato com o TAC para obter mais soluções de problemas.
Cenário 3
A situação final é receber o alerta e, ao verificar UCSM/IMM, o servidor ainda mostra como inacessível se estiver usando UCSM ou desconectado se estiver usando IMM. Ao verificar o sistema operacional, ele está inoperante e também inacessível.
Nessa situação, tudo o que pode ser feito é uma reinicialização do servidor. Se uma reinicialização não for possível, recoloque fisicamente o servidor.
Se, após recolocar fisicamente a lâmina, o problema continuar, entre em contato com o TAC para obter mais soluções de problemas.
Conclusão
Pode haver muitas razões para receber as falhas inacessíveis do servidor, algumas mais impactantes que outras. As etapas aqui são um bom ponto de partida para avaliar se é necessária alguma solução de problemas ou se o seu domínio está íntegro e nenhuma ação é necessária.
 Feedback
Feedback