Solução de problemas de descoberta de blade UCS
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve as etapas para solucionar um problema em que o blade não é descoberto devido ao erro de MC de estado de energia do servidor.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha um conhecimento prático destes tópicos:
- Cisco Unified Computing System (UCS)
- Interconexão de estrutura (FI) da Cisco
Componentes Utilizados
As informações neste documento são baseadas nestas versões de software e hardware:
- UCS B420-M3
- UCS B440-M3
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
- Atualização do firmware do blade, o servidor caiu após a reinicialização da política de tempo de atividade.
- Algum evento de energia no data center.
O item acima pode ser o possível acionador do problema.
Problema
Esta mensagem de erro ocorre em uma reinicialização ou durante a descoberta.
"Unable to change the blade power state" (Não é possível alterar o estado de energia do blade)
O UCSM relata este alerta para um blade que não consegue ser ligado
O blade reinicializado como parte da atualização do firmware ou qualquer outra manutenção falha ao detectar/ativar com a mensagem abaixo no FSM:
"Não é possível alterar o estado de energia do servidor - Erro MC(-20): o controlador de gerenciamento não pode processar ou falhou no processamento da solicitação (sam:dme:ComputePhysicalTurnup:Execute)"
Os registros SEL mostram entradas de erro como abaixo:
CIMC | Alerta de plataforma POWER_ON_FAIL #0xde | Falha preditiva desconfirmada | Desafirmado
CIMC | Alerta de plataforma POWER_ON_FAIL #0xde | Falha preditiva declarada | Declarado
Troubleshooting
No shell CLI do UCSM, conecte-se ao cimc do blade e verifique o status de energia do blade usando o comando power
- ssh FI-IP-ADDR
- connect cimc X
- alimentação
Failure Scenario # 1 OP:[ status ] Power-State: [ on ] VDD-Power-Good: [ inactive ] Power-On-Fail: [ active ] Power-Ctrl-Lock: [ unlocked ] Power-System-Status: [ Good ] Front-Panel Power Button: [ Enabled ] Front-Panel Reset Button: [ Enabled ] OP-CCODE:[ Success ]
Failure Scenario #2 OP:[ status ] Power-State: [ off ] VDD-Power-Good: [ inactive ] Power-On-Fail: [ inactive ] Power-Ctrl-Lock: [ permanent lock ] <<<---------------- Power-System-Status: [ Bad ] <<<--------------- Front-Panel Power Button: [ Disabled ] Front-Panel Reset Button: [ Disabled ] OP-CCODE:[ Success ]
Resultado do cenário de trabalho #
[ help ]# power OP:[ status ] Power-State: [ on ] VDD-Power-Good: [ active ] Power-On-Fail: [ inactive ] Power-Ctrl-Lock: [ unlocked ] Power-System-Status: [ Good ] Front-Panel Power Button: [ Enabled ] Front-Panel Reset Button: [ Enabled ] OP-CCODE:[ Success ] [ power ]#
Verifique o valor do sensor #
POWER_ON_FAIL | disco -> | discreto | 0x0200 | na | na | na | na | na | na | >>> Não funcional
Valor do sensor#
POWER_ON_FAIL | disco -> | discreto | 0x0100 | na | na | na | na | na | na | >>> Trabalhando
Execute o comando sensors e verifique os valores dos sensores de energia e voltagem. Compare a saída com o mesmo modelo do blade que está ligado.
Se as colunas Reading ou Status forem NA para determinados sensores, isso pode não ser a falha de hardware o tempo todo.
Logs snippet#
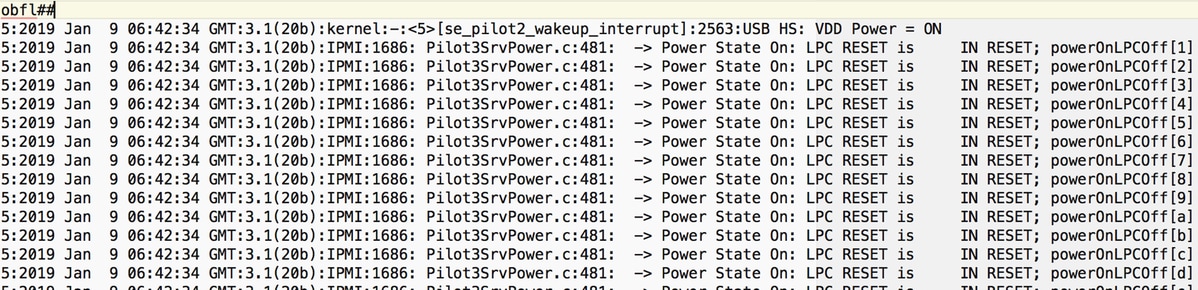
Sel.log#
CIMC | Alerta de plataforma POWER_ON_FAIL #0xde | Falha preditiva declarada | Declarado
power-on-fail.hist dentro do diretório tmp/techsupport_pidXXXX/CIMCX_TechSupport-nvram.tar.gz)
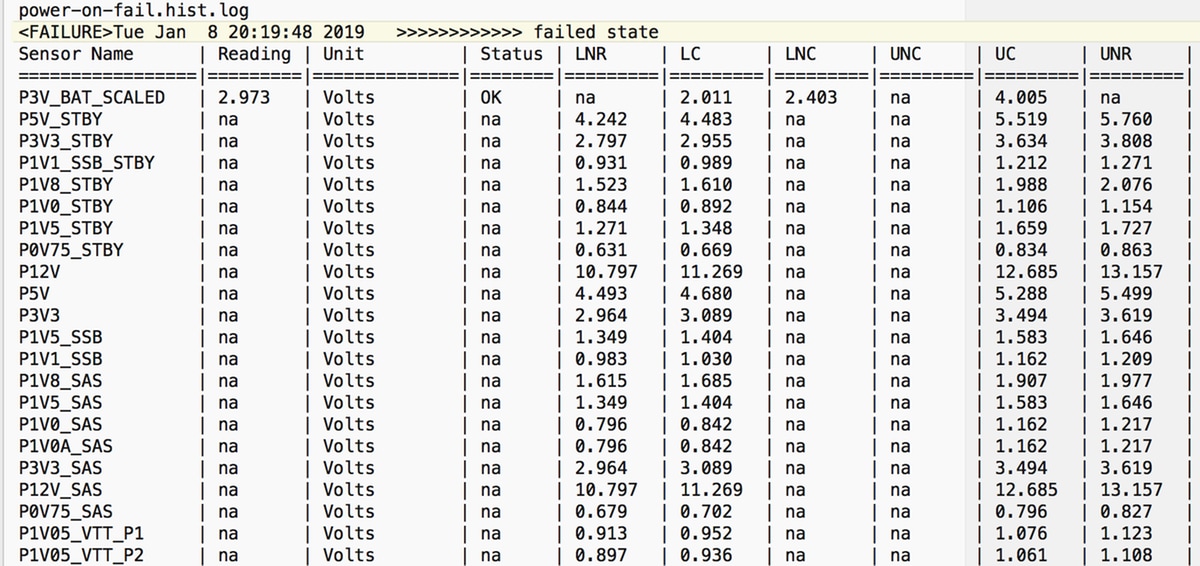
Se isso não ajudar e como próxima etapa, reúna o pacote de log UCSM e suporte técnico do chassi.
Isso ajuda a investigar melhor o problema.
Com os sintomas mencionados anteriormente, tente executar estas etapas para recuperar o problema.
Etapa 1: Verifique se o status do FSM do blade é "Failed" (Com falha) com a descrição "state-MC Error(-20)".
Navegue até Equipment > Chassis X > Server Y > FSM

Etapa 2: anote o número de série do blade afetado e desative o blade.
<<< IMP: anote o número de série do blade Problema na guia Geral antes de descomissioná-lo. Isso será necessário posteriormente na Etapa 4 >>>
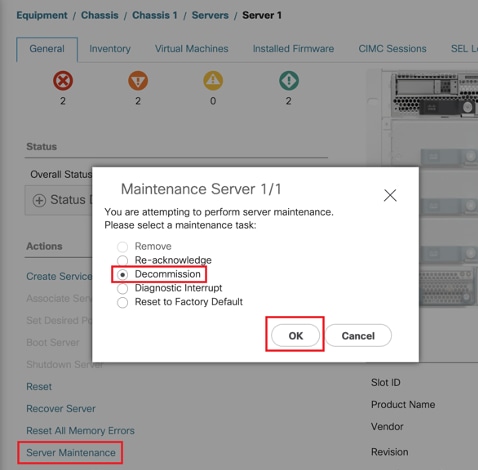
Navegue até Equipment > Chassis X > Server Y > General > Server Maintenance > Decommission > Ok.
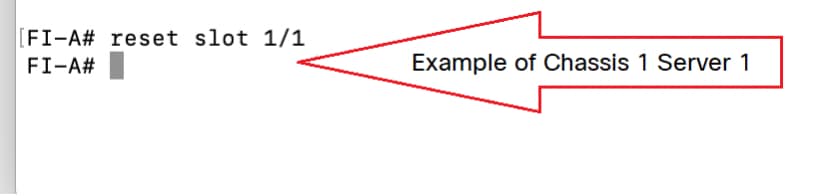
Etapa 3. FI-A/B#reset slot x/y
Por exemplo, o #Chassis2-Server 1 é afetado.
FI-A#reset slot 2/1
Aguarde de 30 a 40 segundos após executar o comando acima
Etapa 4: recomissionar o blade que foi descomissionado.
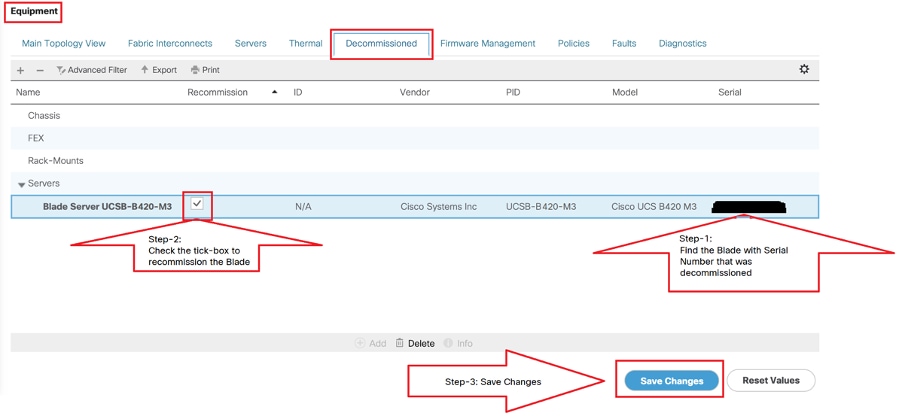
Navegue para Equipment > Decommissioning > Servers > Procure o servidor que descomissionamos (Localize o blade correto com o número de série indicado na Etapa 2 antes do descomissionamento) > Marque a caixa de marca de recomissionamento em relação ao blade correto (Validar com número de série) > Salvar alterações.
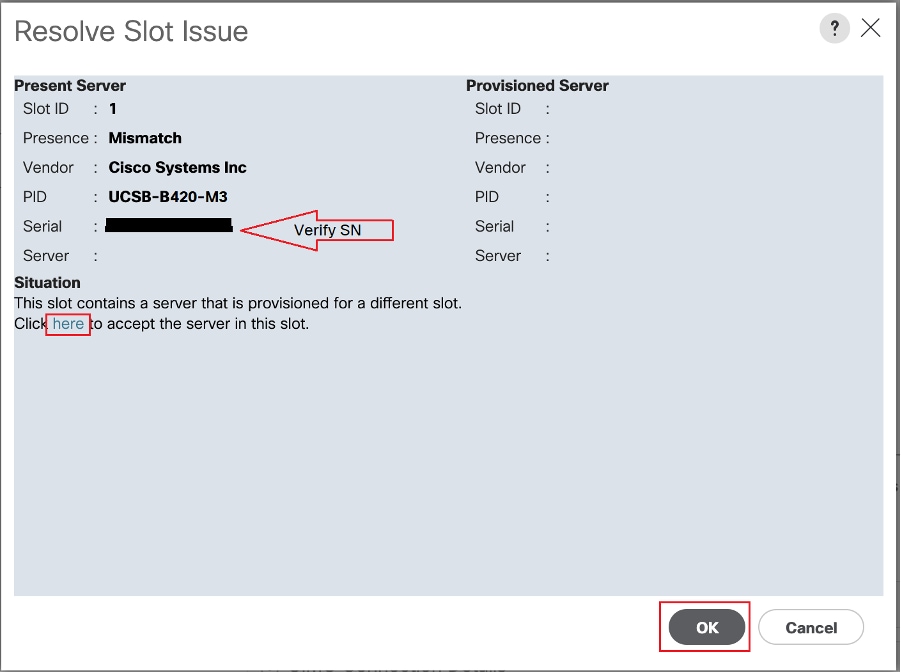
Etapa 5: Resolva o slot, se observado.
Navegue até Equipment > Chassis X > Server Y.
Se aparecer o pop-up "Resolver problema de slot" para o blade que você recomissionou, verifique seu número de série e clique em "aqui" para aceitar o servidor no slot.
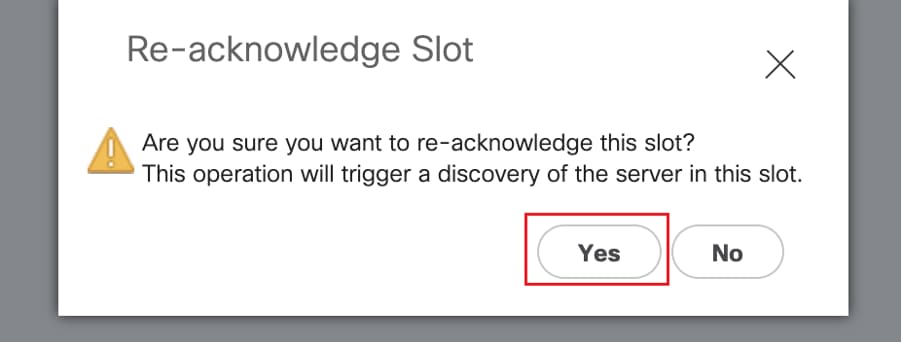
A descoberta do blade deve começar agora.
Aguarde até que a Descoberta de Servidor seja concluída. Monitore o progresso na guia FSM do servidor.
Etapa 6. Se as etapas de um a cinco não ajudarem e o FSM falhar novamente, desative o blade e tente RECOLOCÁ-lo fisicamente.
Se ainda assim o servidor não puder descobrir, entre em contato com o Cisco TAC se esse for um problema de hardware.
NOTE: If you have B200 M4 blade and notice failure scenario #2 , please refer following bug and Contact TAC
CSCuv90289
B200 M4 fails to power on due to POWER_SYS_FLT
Informações Relacionadas
Colaborado por engenheiros da Cisco
- Richita GajjarTAC da Cisco
- Afroj AhmadTAC da Cisco
- Sivakumar SukumarTAC da Cisco
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)