Compreensão e Troubleshooting de Tempo Limite Esgotado de Astro/Lemans/NiceR nos Catalyst 4000/4500 Series Switches
Contents
Introduction
The Catalyst 4000/4500 Switch series uses a stub ASIC design in the Switch architecture. Switch manages these linecard stub ASICs (Astro/Leman/NiceR) through internal management control protocol. Quando essas solicitações e respostas desse gerenciamento interno são perdidas ou atrasadas, são geradas mensagens do console e do syslog. Como os motivos dessas perdas de comunicação variam, a causa principal não fica evidente com essas mensagens de erro.
A intenção deste documento é ajudar a compreender a mensagem Astro/Leman/Nicer Timeout gerada na plataforma Cat4000 e a resolvê-los com a assistência do TAC da Cisco. As versões futuras do CatOS e do Cisco IOS® oferecerão mensagens de erro aprimoradas e, se possível, identificarão a causa raiz do problema.
Quando ocorre o tempo limite de ASIC de stub (Astro/Lemans/Nicer), mensagens semelhantes às seguintes são relatadas em um switch Catalyst 4000/4500 baseado em CatOS:
%SYS-4-P2_WARN: 1/Astro(4/3) - timeout occurred %SYS-4-P2_WARN: 1/Astro(4/3) - timeout is persisting
Observe que, dependendo das versões do software, o teor da mensagem de erro pode variar. Astro, Lemans e Nicer referem-se a diferentes tipos de ASIC de stub. Mais detalhes estão descritos na seção Material de Suporte deste documento.
Em Supervisores baseados em Cisco IOS (Supervisor II+, III e IV), a mensagem de erro aparece da seguinte maneira:
%C4K_LINECARDMGMTPROTOCOL-4-INITIALTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - management request timed out. %C4K_LINECARDMGMTPROTOCOL-4-ONGOINGTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - consecutive management requests timed out.
Observação: este documento aborda principalmente a solução de problemas em supervisores ou switches baseados em CatOS. Algumas das informações se aplicam ao Supervisor baseado no Cisco IOS quando observado.
Observação: este documento também aborda o Astro stub ASIC, mas a maioria das seções é aplicável a outros tipos de placas de linha stub ASIC (Lemans and Nicer) e, como tal, será observado nas seções apropriadas.
Depois de ler este documento, o leitor terá uma compreensão do seguinte:
-
A função de ASICs de stub no Catalyst 4000/4500.
-
As condições que podem levar às mensagens de timeout dos pacotes de gerenciamento interno.
-
As etapas a serem executadas e os comandos a serem reunidos para o Cisco TAC ao Troubleshoot essa condição.
As seções de Troubleshooting e de Intervalo Astro, oferecem explicações e informações detalhadas sobre cada problema. Como alternativa, é possível saltar diretamente para a seção Formas Simples de Fazer Troubleshooting, neste documento.
Antes de Começar
Conventions
Para obter mais informações sobre convenções de documento, consulte as Convenções de dicas técnicas Cisco.
Prerequisites
Não existem requisitos específicos para este documento.
Componentes Utilizados
Este documento é específico do Catalyst 4000/4500 Supervisor ou das placas de linha que usam ASICs stub.
Material de Suporte
ASIC de stub Astro, que consulta os ASICs de stub 10/100, controla um grupo de oito portas 10/100 adjacentes que se comunicam com o Supervisor por meio de uma conexão de largura de banda Gigabit com o backplane, conforme mostra a figura abaixo.
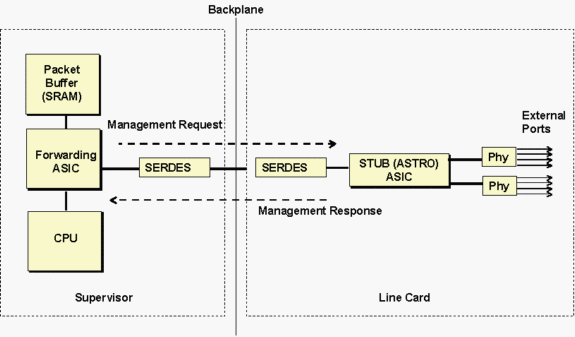
Os supervisores se comunicam com o ASIC do stub da placa de linha por meio do componente SERDES (SERealizer-DESerializer). Há um componente no lado do Supervisor que se conecta ao painel traseiro e outro SERDES na placa de linha de cada ASIC de stub para se conectar ao painel traseiro.
O diagrama acima pode ser usado em geral para solucionar problemas de diferentes tipos de placas de linha. O ASIC de stub mencionado nas mensagens de timeout seria diferente dependendo do tipo de placa de linha. Consulte a tabela abaixo para obter uma lista de nomes ASIC e sua descrição.
| ASICs stub | Descrição | Exemplo |
|---|---|---|
| Astro | ASIC stub do controlador 10/100 de 8 portas | WS-X4148-RJ45V |
| NiceR | ASIC de stub de controlador 1000 de 4 portas | WS-X4418-GB (portas 3 a 18) |
| Lemans | ASIC stub do controlador 10/100/1000 de 8 portas | WS-X4448-GB-RJ |
O tráfego de gerenciamento interno flui através do componente SERDES junto com o tráfego de dados normal. O tráfego de gerenciamento interno é usado para ler/gravar os registros ASIC e Phy de stub. As operações mais comuns incluem a leitura de estado de enlace e estatísticas.
Maneiras Simples de Analisar Falhas
As seções a seguir explicam o significado e as possíveis causas de %SYS-4-P2_WARN: 1/(Stub)(module_number/) Stub_reference - mensagem de erro timeout ocorreu no Catalyst 4000/4500.
As mensagens do intervalo Astro (stub) foram adicionadas à versão de software começando pela 6.2.3 e 6.3.1 e aprimoradas posteriormente na versão 6.4.4 (CSCea73908) para indicar que o Supervisor perdeu os pacotes de controle de gerenciamento interno na comunicação com o Astro stub ASIC em placas de ingresso 10/100. Há várias causas para essa perda de comunicação, conforme explicado em detalhes abaixo na seção Troubleshooting.
O fluxograma de Troubleshooting a seguir apresenta uma maneira rápida e fácil de isolar o problema dentre as diversas causas principais possíveis:
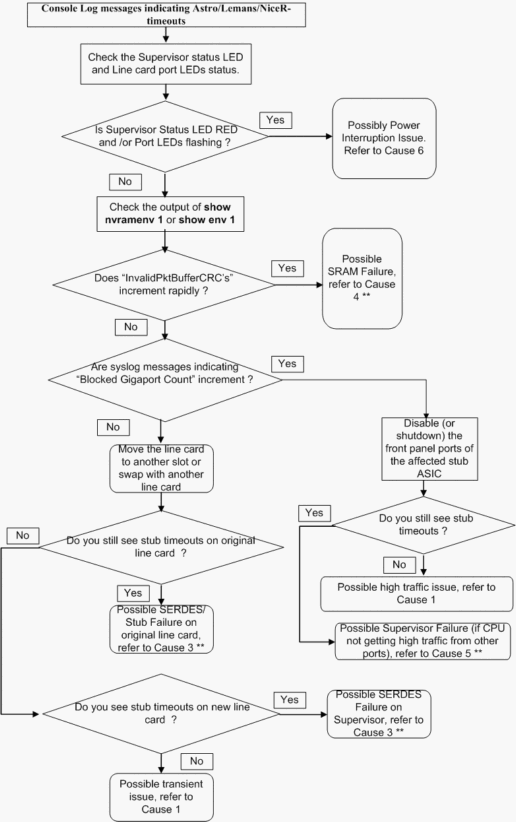
** Várias causas raiz podem apresentar sintomas semelhantes. Entre em contato com o TAC para obter mais soluções de problemas.
Limites de tempo esgotado de ASIC de stub (Astro/Lemans/NiceR)
Os tempos limite Astro/Lemans/Nicer são relatados quando o software Supervisor não recebe várias respostas de gerenciamento interno do ASIC de stub de placa de linha. Isto pode ocorrer se:
-
A solicitação de gerenciamento está perdida ou atrasada
-
Resposta de gerenciamento perdida ou atrasada
Uma mensagem "timeout..." é impressa depois que o software expira 10 vezes consecutivas enquanto aguarda a resposta do pacote de gerenciamento. O consequente tempo limite resulta na impressão de "gerenciamento consecutivo..." ou "..timeout persistindo..." , dependendo da versão do software.
Essa mensagem de registro é limitada por taxa para uma vez a cada 10 minutos. O encaminhamento de pacotes para os ASICs de stub afetados continua quando os tempos limite estão ocorrendo. No entanto, quaisquer alterações na velocidade do link/autoneg/duplex não são vistas porque o software não recebe as respostas do pacote de gerenciamento. Além disso, o processo de atualização das estatísticas de tráfego do grupo de interfaces é afetado quando ocorrem intervalos.
Troubleshooting
Há várias causas para a exibição das mensagens de tempo limite Astro/Lemans/Nicer. Cada um deles é descrito abaixo.
Causa 1: Carga de tráfego intenso, loop de camada 2 ou tráfego excessivo na rede em direção à CPU
O seguinte pode causar condições de tempo limite de stub:
-
Problemas de rede
-
Problemas de configuração
-
Elementos vizinhos
-
Outros fatores externos a um Switch Catalyst
Um loop da camada 2 ou uma tempestade de broadcast que resulte em uma alta carga de tráfego pode causar perda de pacotes de controle de gerenciamento interno. Em geral, isto acontece por causa da CPU estar ocupada (hog de CPU) e não ser possível processar as filas).
O tráfego de controle de gerenciamento interno usa o mesmo caminho de dados para o Supervisor que o tráfego normal de dados no Astro (ou qualquer outro chip de Stub). Assim, os pacotes de controle podem se perder devido a congestionamento.
Com a correção para o ID de bug Cisco CSCea73908 (somente clientes registrados), o período de timeout de requisição de gerenciamento interno é melhor manipulado na versão de CatOS 6.4(4) e versões mais recentes. Esse aprimoramento pode evitar muitos timeouts de pacotes de controles temporários causados pelo fato de a CPU estar ocupada.
Ação: Solucionar problemas do loop da camada 2; ou alterar a configuração para resolver padrões de tráfego.
Solução: Move the Switch management interface (sc0) to non-user traffic VLAN on CatOS based Switches. Use o comando set interface sc0 <vlan-id> para mover a vlan da interface sc0.
Observação: começando com o Cisco IOS 12.1(20)EW, os supervisores baseados no Cisco IOS apresentam um aprimoramento no tratamento do mecanismo de gerenciamento interno de pacotes pela CPU. Este aperfeiçoamento ajudará a evitar perda de pacotes de controle de gerenciamento internos, devido a tráfego de prioridade baixa que ocupa desnecessariamente a CPU.
Solução: Consulte a solução temporária acima.
Causa 2: Cabeamento semi-duplex/ tipo 1A
As portas de usuário do painel frontal estão configuradas em semi-duplex. As colisões do tráfego de saída com o tráfego de entrada no ASIC de stub podem fazer com que o buffer do stub seja esvaziado muito lentamente. Esse problema pode fazer com que as filas TX no Supervisor sejam completadas e que novas requisições de gerenciamento interno sejam descartadas, o que pode resultar em mensagens de erro de intervalo de parada.
Uma rede com cabeamento Type1A também pode provocar esse problema. Quando uma estação de trabalho conectada a um Tipo1A Baluns com um patch RJ-45 é desconectada, o Balun faz loops de volta internamente e faz com que o tráfego de saída retorne. Esta situação simula a conexão de um loopback externo na porta do painel frontal. Before the port moves to blocking state, outgoing traffic is looped back into the Switch. Isso pode fazer com que os buffers de stub sobrecarreguem, dependendo da taxa de tráfego.
Ação: Consulte solução.
Solução: Evite a configuração semi-duplex. No caso do cabeamento Tipo1A, evite conectar o patch cable RJ-45 do Balun Tipo 1A para evitar formar um loopback interno no Balun.
Solução: Consulte solução.
Causa 3: Falha do componente SERDES
Se os erros forem vistos somente em um Astro (ou outro ASIC stub) em um módulo, e um loop da camada 2 não estiver ocorrendo, o problema provavelmente será um componente SERDES defeituoso no Supervisor ou na Placa de linha. Por exemplo, se a mensagem de erro estiver sempre no Astro 4 no Módulo 3 como mostrado abaixo, o componente SERDES no módulo 3 ou o componente SERDES no Supervisor está com defeito.
%SYS-4-P2_WARN: 1/Astro(3/4) – timeout occurred
Na mensagem de erro acima, o número "4" entre parênteses refere-se ao Astro # e não à porta real 3/4. Esse número faz referência a um grupo de oito portas (3/3-3/40), pois é o quarto Astro no módulo 3.
Um componente SERDES defeituoso pode gerar conectividade intermitente para o tráfego de controle e de dados para Astro/Lemans/NiceR, o que resultará em timeouts. Normalmente, no entanto, a mensagem de erro será exibida continuamente se o SERDES estiver com defeito.
Ação: Para determinar qual SERDES (Supervisor ou placa de linha) é inválido, execute as seguintes etapas:
-
Move a placa de linha para um slot reserva no chassi ou para outro chassi. Se houver um slot livre disponível, troque os slots por um módulo em funcionamento conhecido.
-
Se você continuar a obter os tempos limite Astro/Lemans/Nicer no mesmo Astro/Lemans/Nicer no novo slot, provavelmente os SERDES ou Astro/Lemans/Nicer na placa de linha falharam e a placa de linha precisa ser substituída
Observação: ao reinserir o módulo em um slot sobressalente, o diagnóstico on-line é executado na placa de linha. Se um SERDES ou Astro/Lemans/Nicer com falha for encontrado, o switch marcará a porta como defeituosa.
-
Se os tempos limites não continuarem a ocorrer na placa de linha original Astro/Lemans/Nicer, é possível que o Supervisor SERDES esteja com defeito. Para verificar isso, insira módulo em bom estado de operação no slot original e veja se os tempos limites ocorrem com o novo módulo.
Se funcionar, é possível que um SERDES esteja no Supervisor. Consulte o aviso do campo Catalyst WS-X4013 Supervisor exibe perda parcial de conectividade para obter uma lista dos números de série afetados com o componente SERDES com falha.
Solução: Nenhum
Solução: Entre em contato com o TAC para o Troubleshooting de outras falhas.
Causa 4: Falha transitória/SRAM de hardware
Os dispositivos conectados a um Catalyst 4000 com um Supervisor I ou II ou III ou IV Engine ou Catalyst 2948G, Cat2980G podem sofrer perda parcial ou total de conectividade de rede. Algumas ou todas as portas podem ser afetadas. Esses sintomas serão acompanhados de um rápido aumento das mensagens de erro de pacotes descartados por CRC inválido no Supervisor baseado em CatOS, e das mensagens de erro de intervalo do ASIC de stub.
O problema é devido a uma falha de memória de buffer de pacote (SRAM), que é um tipo de hardware ou transitório.
Ação: Selecione o curso de ação dependendo de qual das duas assinaturas de falha de memória de buffer de pacote transitório abaixo ocorreu:
-
Assinatura de falha da memória de buffer do pacote transitório para SUP I , SUP II, 2948G, 2980G
A seguir, estão os sintomas deste problema:
-
InvalidPktBufferCRC é incrementado rapidamente com uma mensagem semelhante à seguinte
%SYS-4-P2_WARN: 1/Invalid crc, dropped packet, count = xxxx
-
Uma reinicialização de software com uso do comando reset provocaria falha do Supervisor em passar o POST.
-
Se uma reinicialização difícil (desligar/religar) for executada, o Supervisor passará POST e não sofrerá mais falha.
Observação: no caso de uma falha de memória de buffer de pacote rígido para o Supervisor I, II, 2948G, 2980G, uma redefinição de hardware não resolveria o problema e o Supervisor ou switch ainda falharia no POST.
Para obter mais informações sobre esse assunto, consulte Cisco Bug ID CSCdy46288 (somente clientes registrados) para Supervisor II, Cisco Bug ID CSCeb56266 (somente clientes registrados) para Supervisor I/2948G/2980G e Cisco Bug ID CSCeb56325 (somente clientes registrados) para o WS-C2980G-A.
-
-
Assinatura de Falha de Memória de Buffer de Pacotes Transitório para SUP III, SUP IV
A seguir, estão os sintomas deste problema:
-
O contador VlanZeroBadCrc é incrementado rapidamente e exibido na saída do seguinte comando:
show platform cpuport all (prior to 12.1(11b)EW1 ) or show platform cpu packet statistics all (Since 12.1(11b)EW1) depending upon the software version. Starting from 12.1(19)EW, you should also see the following error message rapidly incrementing errors: %C4K_SWITCHINGENGINEMAN-2-PACKETMEMORYERROR3: Persistent Errors in Packet Memory xxxx
-
Uma redefinição parcial faria com que o Supervisor falhasse no POST. Use o comando show diagnostics power-on para verificar a falha.
-
Uma reinicialização total (desligamento e religamento) irá recuperar o Supervisor e aprovará o POST.
Observação: no caso de uma falha de SRAM rígida para o Supervisor III / IV, uma reinicialização forçada não recuperaria o Supervisor e ainda falharia no POST.
Para obter mais informações sobre esse problema no Supervisor III/IV, consulte a ID de bug Cisco CSCdz57255 (apenas clientes registrados).
-
Solução: Power cycle or hard reset the Switch in the case of transient SRAM problem. O problema de SRAM difícil não tem solução alternativa.
Solução: Entre em contato com o TAC para o Troubleshooting de outras falhas.
Causa 5: Falha do relógio do Supervisor
Se forem vistas mensagens de erro de tempo limite Astro/Lemans/NiceR referentes a vários números de módulo ou vários Astro/Lemans/Nicer, isso pode indicar uma possível falha de relógio no Supervisor. Geralmente, uma falha de relógio é acompanhada da mensagem de erro de timeout Astro/Lemans/Nicer e das mensagens de erro BlockTXQueue e BlockedGigaport, conforme indicado abaixo:
%SYS-4-P2_WARN: 1/Blocked queue on gigaport ...
Ação: Entre em contato com o TAC para obter informações de Troubleshooting adicional sobre os IDs de bug CSCdp89537 e CSCdp93187 da Cisco (apenas para clientes registrados).
Solução: Nenhum
Solução: Entre em contato com o TAC para o Troubleshooting de outras falhas.
Causa 6: Interrupção por falta de alimentação
Um switch Catalyst 4000 Series com um Supervisor II (WS-X4013) pode inserir um estado no qual o Supervisor e as placas de linha não podem se comunicar corretamente entre si. Quando o switch entra nesse estado, os LEDs de status do módulo são vermelhos (não piscando) e/ou os LEDs das portas piscarão em sequência semelhante a uma redefinição de módulo ou switch. Isso será acompanhado pelas mensagens de tempo limite esgotado Astro/Lemans/NiceR.
Esse problema é causado por uma interrupção temporária de energia ao Switch (menos que 500 ms). A interrupção temporária de energia pode ser devido a alimentação de energia instável em um ambiente de produção.
Ação: Veja a solução alternativa abaixo.
Solução: Reinicie o switch (suave ou rígido (ciclo de energia)).
Solução: Upgrade para imagem de software com a correção de um ID de bug da Cisco, CSCea14710, (clientes registrados apenas) ou em versões posteriores.
Informações Relacionadas
- Mensagens de erro comuns de CatOS em Switches da série Catalyst 4000
- Hardware de Troubleshooting para Catalyst 4000/4912G/2980G/2948G Series Switches
- Troubleshooting de Hardware e Problemas Relacionados no Catalyst 4000 e 4500 Supervisor III e IV
- Catalyst 4000/4500 Series Switches Support Pages
- Suporte de tecnologia de switching de LAN
- Suporte aos produtos de switches LAN e ATM do Catalyst
- Suporte Técnico e Documentação - Cisco Systems
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)