Solucionar problemas de replicação do banco de dados do CUCM
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve como diagnosticar problemas de replicação de banco de dados e fornece as etapas necessárias para solucionar esses problemas.
Etapas para diagnosticar a replicação de banco de dados
Esta seção descreve os cenários nos quais a replicação do banco de dados é interrompida e fornece a metodologia de solução de problemas para diagnosticar e isolar o problema.
Etapa 1. Verificar se a Replicação de Banco de Dados está Quebrada
Para determinar se a replicação de banco de dados foi interrompida, você deve conhecer os vários estados do Real Time Monitoring Tool (RTMT) para a replicação.
| Valor | Significado | Descrição |
|---|---|---|
| 0 |
Estado de inicialização |
A replicação está no processo de configuração. Uma falha de instalação poderá ocorrer se a replicação estiver nesse estado por mais de uma hora. |
| 1 |
O número de repetições está incorreto |
A configuração ainda está em andamento. Esse estado é raramente observado nas versões 6.x e 7.x; na versão 5.x, indica que a configuração ainda está em andamento. |
| 2 |
A replicação está em boas condições |
As conexões lógicas foram estabelecidas e as tabelas são compatíveis com os outros servidores no cluster. |
| 3 |
Tabelas com incompatibilidade |
As conexões lógicas são estabelecidas, mas há uma incerteza se as tabelas correspondem. Nas versões 6.x e 7.x, todos os servidores podem mostrar o estado 3 mesmo se um servidor estiver inativo no cluster. Esse problema pode ocorrer porque os outros servidores não confirmaram se há uma atualização no User Facing Feature (UFF) que não foi passada do assinante para o outro dispositivo no cluster. |
| 4 |
Configuração com falha/descartada |
O servidor não tem mais uma conexão lógica ativa para receber as tabelas de banco de dados na rede. A replicação não ocorre nesse estado. |
Para verificar a replicação do banco de dados, execute o comando utils dbreplication runtimestate na CLI do nó do editor, como mostrado nesta imagem.
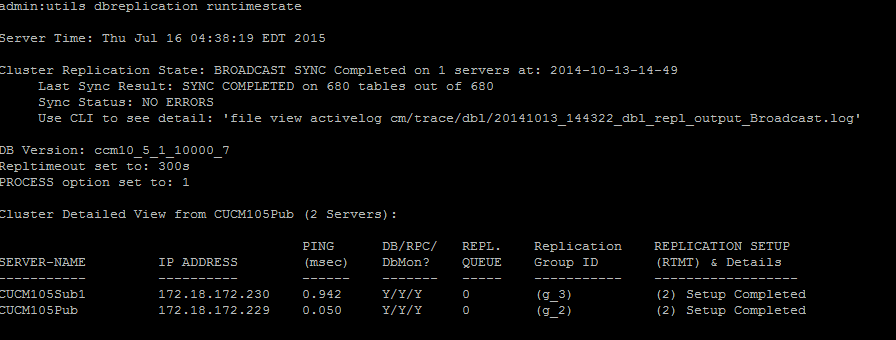
Na saída, verifique se o estado de replicação do cluster não contém as informações de sincronização antigas. Marque a mesma opção e use o Carimbo de data/hora.
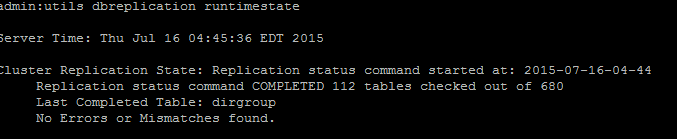
Se a sincronização de transmissão não estiver atualizada com uma data recente, execute o comando utils dbreplication status para verificar todas as tabelas e a replicação. Se erros/incompatibilidades forem encontrados, serão mostrados na saída e o estado do RTMT será alterado de acordo, conforme mostrado nesta imagem.
o
Depois de executar o comando, todas as tabelas serão verificadas quanto à consistência e um status de replicação preciso será exibido.
Note: Permita que todas as tabelas sejam verificadas e continue com a solução de problemas.

Quando um status de replicação preciso for exibido, verifique a configuração de replicação (RTMT) e os detalhes, conforme mostrado na primeira saída. Você deve verificar o status de cada nó. Se qualquer nó tiver um estado diferente de 2, continue a solucionar problemas.
Etapa 2. Colete o status do banco de dados CM na página do Cisco Unified Reporting no CUCM
- Depois de concluir a Etapa 1, escolha a opção Cisco Unified Reporting na lista suspensa Navegação no editor do Cisco Unified Communications Manager (CUCM), como mostrado nesta imagem.
2. Navegue até Relatórios do sistema e clique em Status do banco de dados do Unified CM, como mostrado nesta imagem.
3. Gerar um novo relatório, clique no ícone Gerar novo relatório como mostrado nesta imagem.

4. Aguarde até que o novo relatório seja gerado com êxito.

5. Uma vez gerado, clique no ícone para fazer o download do relatório e salvá-lo para que ele possa ser fornecido a um engenheiro do TAC caso uma solicitação de serviço (SR) precise ser aberta.

Etapa 3. Revisar o Relatório de Banco de Dados do Unified CM de qualquer Componente Sinalizado como Erro
Se houver erros nos componentes, eles serão sinalizados com um ícone X vermelho, como mostrado nesta imagem.
-
Verifique se os bancos de dados Local e do Publicador estão acessíveis.
- Em caso de erro, verifique a conectividade de rede entre os nós. Verifique se o serviço A Cisco DB é executado a partir da CLI do nó e usa o comando utils service list.
- Se o serviço A Cisco DB estiver inativo, execute o comando utils service start A Cisco DB para iniciar o serviço. Se isso falhar, entre em contato com o TAC da Cisco.
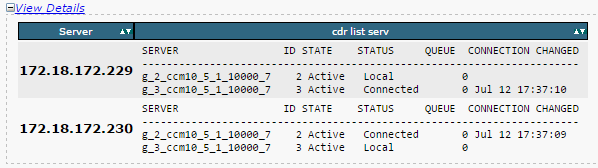
- Verifique se a lista de servidores de replicação (cdr list serv) foi preenchida para todos os nós.
Esta imagem ilustra uma saída ideal.
Se a lista do Cisco Database Replicator (CDR) estiver vazia para alguns nós, consulte a Etapa 8.
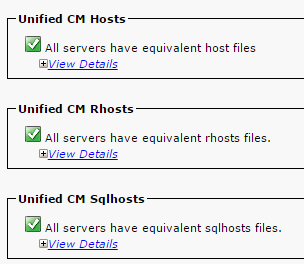
- Verifique se os Hosts, Rhosts e Sqlhosts do Unified CM são equivalentes em todos os nós.
Essa é uma etapa importante. Conforme mostrado nesta imagem, os Hosts, Rhosts e Sqlhosts do Unified CM são equivalentes em todos os nós.
Os arquivos de Hosts apresentam incompatibilidade:
Existe a possibilidade de uma atividade incorreta quando um endereço IP é alterado ou atualizado para o nome de host no servidor.
Consulte este link para alterar o endereço IP para o nome de host do CUCM.
Alterações de endereço IP e nome de host
Reinicie esses serviços a partir do CLI do servidor do editor e verifique se a incompatibilidade foi eliminada. Se sim, vá para a Etapa 8. Se não, entre em contato com o TAC da Cisco. Gere um novo relatório toda vez que você fizer uma alteração na GUI/CLI para verificar se as alterações estão incluídas.
Cluster Manager ( utils service restart Cluster Manager)
A Cisco DB ( utils service restart A Cisco DB)
Os arquivos de Rhosts apresentam incompatibilidade:
Se os arquivos de Rhosts apresentarem incompatibilidade com os arquivos de Hosts, siga as etapas mencionadas em Os arquivos de Hosts apresentam incompatibilidade. Se apenas os arquivos de Rhosts apresentarem incompatibilidade, execute os comandos na CLI:
A Cisco DB ( utils service restart A Cisco DB ) Cluster Manager ( utils service restart Cluster Manager)
Gere um novo relatório e verifique se os arquivos de Rhost são equivalentes em todos os servidores. Se sim, vá para a Etapa 8. Se não, entre em contato com o TAC da Cisco.
Os arquivos de Sqlhosts apresentam incompatibilidade:
Se os arquivos de Sqlhosts apresentarem incompatibilidade com os arquivos de Hosts, siga as etapas mencionadas em Os arquivos de Hosts apresentam incompatibilidade. Se apenas os arquivos de Sqlhosts apresentarem incompatibilidade, execute o comando na CLI:
utils service restart A Cisco DB
Gere um novo relatório e verifique se os arquivos de Sqlhosts são equivalentes em todos os servidores. Se sim, vá para a Etapa 8. Se não, entre em contato com o TAC da Cisco
-
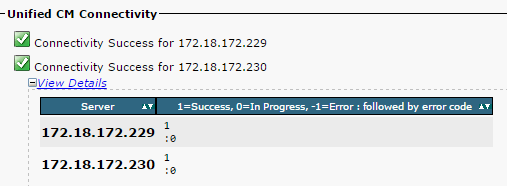
Verifique se o hello do Database Layer Remote Procedural Call (DBL RPC) foi executado com sucesso, conforme mostrado nesta imagem.
Se o hello do RPC não funcionar em um nó específico:
- Verifique a conectividade de rede entre o nó específico e o editor.
- Verifique se o número da porta 1515 é permitido na rede.
Consulte este link para obter detalhes sobre o uso da porta TCP/UDP:
Uso das portas TCP e UDP do Cisco Unified Communications Manager
- Verifique se a conectividade de rede foi estabelecida com sucesso entre os nós, conforme mostrado nesta imagem:

Se a conectividade de rede falhar para os nós:
- Verifique se a acessibilidade da rede está presente entre os nós.
- Verifique se os devidos números da porta TCP/UDP são permitidos na rede.
Gere um novo relatório e verifique se uma conexão foi estabelecida com sucesso. Se uma conexão não foi estabelecida com sucesso, vá para a Etapa 8.
Etapa 4. Verificar os componentes individuais que usam o comando de teste de diagnóstico Utils
O comando utils diagnose test verifica todos os componentes e retorna um valor aprovado/reprovado. Os componentes essenciais para o funcionamento adequado da replicação de banco de dados são:
-
Conectividade de rede:
O comando validate_network verifica todos os aspectos da conectividade de rede com todos os nós no cluster. Se houver um problema com a conectividade, um erro será exibido com frequência nos servidores DNS/RDNS. O comando validate_network conclui a operação em 300 segundos. As mensagens de erro comuns observadas nos testes de conectividade de rede:
1. Erro "A comunicação dentro do cluster está interrompida", conforme mostrado nesta imagem.

- Causa
Esse erro é causado quando um ou mais nós no cluster têm um problema de conectividade de rede. Verifique se todos os nós têm acessibilidade de ping.
- Efeito
Se a comunicação intra-cluster foi interrompida, ocorrerão problemas de replicação de banco de dados.
2. Falha na pesquisa de DNS reverso.
- Causa
Esse erro é causado quando há uma falha na pesquisa de RDNS em um nó. No entanto, você pode verificar se o DNS está configurado e funciona corretamente ao usar estes comandos:
utils network eth0 all - Shows the DNS configuration (if present) utils network host <ip address/Hostname> - Checks for resolution of ip address/Hostname
- Efeito
Se o DNS não funcionar corretamente, ele poderá causar problemas de replicação de banco de dados quando os servidores forem definidos e usarem os nomes de host.
-
Acessibilidade do Network Time Protocol (NTP):
O NTP é responsável por manter o horário do servidor em sincronia com o relógio de referência. O editor sempre sincroniza a hora com o dispositivo cujo IP está listado como servidores NTP; enquanto que os assinantes sincronizam a hora com o editor.
É extremamente importante que o NTP esteja totalmente funcional para evitar problemas de replicação de banco de dados.
É essencial que o stratum do NTP (Número de saltos para o relógio de referência pai) seja menor que 5, caso contrário, ele não será considerado confiável.
Conclua estas etapas para verificar o status do NTP:
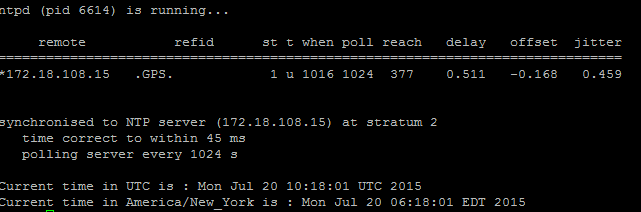
- Use o comando utils diagnose test para verificar a saída, conforme mostrado nesta imagem.
2. Além disso, você pode executar este comando:
utils ntp status
Etapa 5. Verificar o Status de Conectividade de todos os Nós e Garantir que eles sejam Autenticados
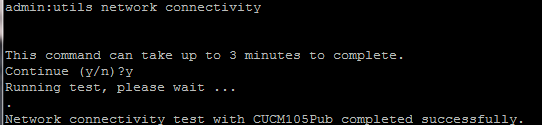
- Depois de concluir a Etapa 4, se não houver relatório de problemas, execute o comando utils network connectivity em todos os nós, para verificar se a conectividade com os bancos de dados foi estabelecida com sucesso, conforme mostrado nesta imagem.

2. Se você receber a mensagem de erro "Não é possível enviar pacotes TCP/UDP", verifique se há retransmissões na rede ou bloqueie as portas TCP/UDP. O comando show network cluster verifica a autenticação de todos os nós.
3. Se o status do nó não for autenticado, certifique-se de que a conectividade de rede e a senha de segurança sejam iguais em todos os nós, como mostrado nesta imagem.
Consulte os links para alterar/recuperar as senhas de segurança:
Recuperação de senha do administrador do sistema operacional do CUCM
Etapa 6. O Comando Utils Replicplication Runtimestate Mostra os Status fora de Sincronia ou não Solicitado
É importante entender que a replicação de banco de dados é uma tarefa com uso intensivo de rede, pois envia as tabelas reais para todos os nós no cluster. Assegure que:
-
Os nós estão no mesmo data center/local: Todos os nós são acessíveis com um RTT reduzido. Se o RTT estiver excepcionalmente alto, verifique o desempenho da rede.
-
Os nós estão distribuídos pela rede de longa distância (WAN): Verifique se os nós têm conectividade de rede bem abaixo de 80 ms. Se alguns nós não puderem ingressar no processo de replicação, aumente o valor do parâmetro, conforme mostrado.
utils dbreplication setprocess <1-40>
Note: Quando você altera esse parâmetro, ele melhora o desempenho da configuração de replicação, mas consome recursos adicionais do sistema.
-
O limite de tempo da replicação é baseado no número de nós no cluster: O limite de tempo de replicação (padrão: 300 segundos) é o tempo que o editor espera por todos os assinantes para enviar as mensagens definidas. Calcule o limite de tempo da replicação de acordo com o número de nós no cluster.
Server 1-5 = 1 Minute Per Server Servers 6-10 = 2 Minutes Per Server Servers >10 = 3 Minutes Per Server.
Example: 12 Servers in Cluster : Server 1-5 * 1 min = 5 min, + 6-10 * 2 min = 10 min, + 11-12 * 3 min = 6 min, Repltimeout should be set to 21 Minutes.
Comandos para verificar/definir o limite de tempo de replicação:
show tech repltimeout ( To check the current replication timeout value ) utils dbreplication setrepltimeout ( To set the replication timeout )
As etapas 7 e 8 devem ser executadas após o preenchimento da lista de verificação:
Lista de verificação:
- Todos os nós têm conectividade entre si. Consulte a Etapa 5.
- O RPC está acessível. Consulte a Etapa 3.
- Consulte o Cisco TAC antes de prosseguir com as etapas 7 e 8 no caso de nós maiores que 8.
- Realize o procedimento fora do horário comercial.
Etapa 7. Reparar Todas as Tabelas/Tabelas Seletivas para Replicação de Banco de Dados
Se o comando utils dbreplication runtimestate mostrar que há tabelas com erro/incompatibilidade, execute o comando:
Utils dbreplication repair all
Execute o comando utils dbreplication runtimestate para verificar o status novamente.
Passe para a Etapa 8, se o status não for alterado.
Etapa 8. Redefinir a Replicação do Banco de Dados do Zero
Consulte a sequência para redefinir a replicação do banco de dados e iniciar o processo do zero.
utils dbreplication stop all (Only on the publisher) utils dbreplication dropadmindb (First on all the subscribers one by one then the publisher) utils dbreplication reset all ( Only on the publisher )
Para monitorar o processo, execute o comando RTMT/utils dbreplication runtimestate.
Consulte a sequência para redefinir a replicação de banco de dados para um nó específico:
utils dbreplication stop <sub name/IP> (Only on the publisher) utils dbreplcation dropadmindb (Only on the affected subscriber) utils dbreplication reset <sub name/IP> (Only on the publisher )
Caso você entre em contato com o TAC da Cisco para obter assistência adicional, certifique-se de que estas saídas e os relatórios sejam fornecidos:
utils dbreplication runtimestate utils diagnose test utils network connectivity
Relatórios:
- O relatório do banco de dados do Cisco Unified Reporting CM (consulte a Etapa 2).
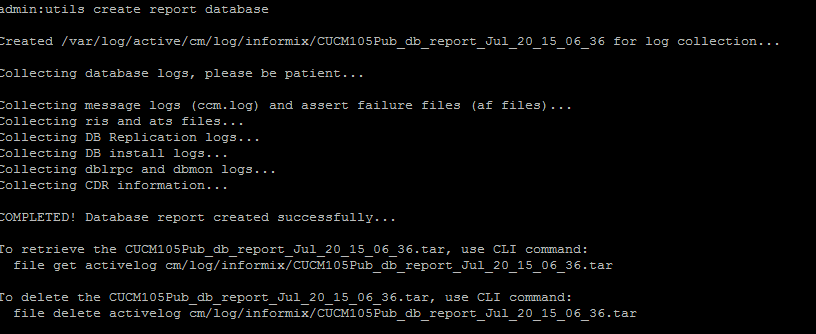
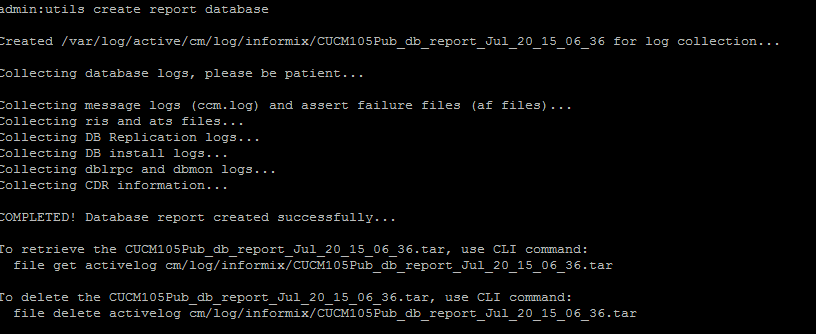
- O comando utils create report database na CLI. Baixe o arquivo .tar e use um servidor SFTP.
Informações Relacionadas
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
4.0 |
12-Nov-2024 |
Texto Alt, tradução automática e formatação atualizados. |
1.0 |
13-Aug-2021 |
Versão inicial |
Colaborado por engenheiros da Cisco
- Kaustubh AcharekarEngenheiro do Cisco TAC
- Jose Pablo Villalobos UrenaEngenheiro do Cisco TAC
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)