Entendimento de atraso em redes de voz de pacote
Contents
Introduction
Ao projetar redes que transportam infraestruturas de célula, frame ou voz sobre pacote, é importante compreender e explicar os componentes de atraso na rede. Se você explicar corretamente todos os atrasos potenciais, terá a garantia de que o desempenho geral da rede será aceitável. A qualidade geral de voz é uma função de muitos fatores que incluem o algoritmo de compactação, os erros e a perda de frame, o cancelamento de eco e o atraso. Este documento explica as origens do atraso ao usar o roteador/gateway da Cisco em redes de pacote de informação. Embora os exemplos sejam concebidos inicialmente para Frame Relay, os conceitos são aplicáveis também às redes VoIP (Voice over IP) e VoATM (Voice over ATM).
Fluxo de voz básico
O fluxo de um circuito de voz compactada é mostrado neste diagrama. O sinal analógico a partir do telefone é digitalizado em sinais de modulação de códigos de pulso (PCM) pelo decodificador/codificador de voz (codec). As amostras de PCM são aprovadas para o algoritmo de compressão que comprime a voz em um formato de pacote para transmissão na WAN. Na extremidade da nuvem, as mesmas funções são executadas na ordem inversa. Todo o fluxo é mostrado na figura 2-1.
Figura 2-1 – Fluxo de voz de ponta a ponta 
Com base em como a rede é configurada, o roteador/gateway pode executar as funções de compactação e codec ou somente uma delas. Por exemplo, se um sistema de voz análogo for utilizado, o roteador/gateway executa a função CODEC e a função de compressão conforme mostrado na figura 2-2.
Figura 2-2 Função do codec no roteador/gateway 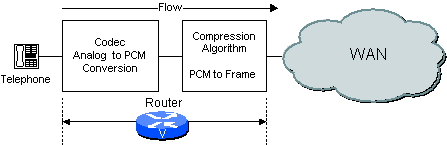
Se um PBX digital for usado, ele executará a função de codec, e o roteador processará as amostras de PCM enviadas a ele pelo PBX. Um exemplo é mostrado na Figura 2-3.
Figura 2-3 Função de codec no PBX 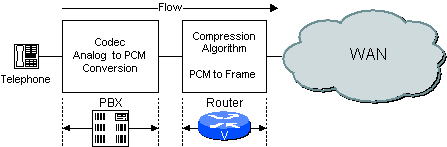
Como a compressão de voz funciona
Os algoritmos de compactação da alta complexidade usados no roteador/gateway da Cisco analisam um bloco de amostras de PCM enviado pelo codec de voz. O comprimento desses blocos varia com base no codificador. Por exemplo, o tamanho de bloco básico utilizado por um algoritmo G.729 é de 10 ms, considerando que o tamanho de bloco básico utilizado pelos algoritmos G.723.1 é de 30 ms. Um exemplo de como um sistema de compressão G.729 funciona é mostrado na figura 3-1.
Figura 3-1 – Compressão de voz 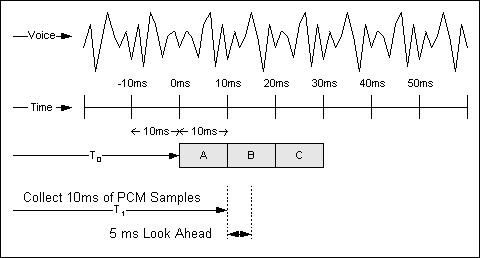
O fluxo de voz analógico é digitalizado em amostras de PCM e entregues ao algoritmo de compactação em incrementos de 10 ms. O look ahead é discutido em Retardo de algoritmo.
Padrões para limites de retardo
A União Internacional de Telecomunicações (ITU, International Telecommunication Union) considera o atraso de rede para aplicativos de voz na Recomendação G.114. Essa recomendação define três faixas de atraso unidirecionais, conforme mostra a Tabela 4.1.
Tabela 4.1 Especificações de Retardo
| Intervalo em Milissegundos | Descrição |
|---|---|
| 0-150 | Aceitável para a maioria dos aplicativos do usuário. |
| 150-400 | Aceitável, contanto que os administradores estejam cientes do tempo de transmissão e do impacto que tem na qualidade de transmissão dos aplicativos de usuário. |
| Acima de 400 | Inaceitável para objetivos gerais de planejamento de rede. Contudo, reconhece-se que, em alguns casos excepcionais, esse limite é excedido. |
Observação: essas recomendações são para conexões com eco adequadamente controlado. Isso implica que canceladores de eco são usados. Os canceladores de eco são necessários quando o retardo de sentido único excede 25 ms (G.131).
Essas recomendações são voltadas para administrações de telecomunicações nacionais. Por isso, são mais rigorosas do que quando são aplicadas normalmente em redes de voz privadas. Quando o programador de rede conhece bem as necessidades locais e comerciais dos usuários finais, um atraso maior pode ser aceitável. Para redes provadas, 200 ms de atraso é uma meta razoável, e 250 ms é o limite. Todas as redes precisam ser projetadas de forma que o atraso máximo esperado da conexão de voz seja conhecido e minimizado.
Origens de retardo
Há dois tipos distintos de atraso, chamados de fixos e variáveis.
-
Os componentes do atraso fixo são adicionados diretamente ao atraso total na conexão.
-
Retardos de variáveis surgem de retardos de enfileiramento nos buffers do tronco de saída na porta serial conectada à WAN. Estes buffers criam retardos variáveis chamados de tremulações por toda a rede. Os atrasos variáveis são tratados pelo buffer de controle de variação de sinal no roteador/gateway receptor. O buffer de controle de variação de sinal é descrito na seção Atraso de variação de sinal (NDIR) deste documento.
A Figura 5-1 identifica todas as origens de retardo variável e fixo na rede. Cada origem é descrita em detalhes neste documento.
Figura 5-1: Origens de atraso 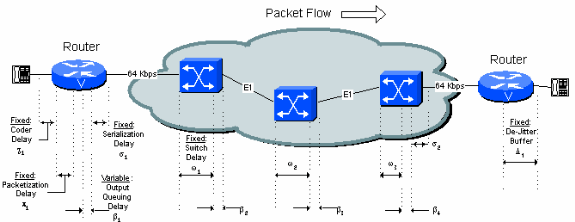
Retardo do codificador (processamento)
O atraso do codificador é o tempo que o Processador de sinal digital (DSP, Digital Signal Processor) leva para compactar um bloco de amostras de PCM. Isso também é chamado de atraso de processamento (χ n). Esse atraso varia com o codificador de voz usado e a velocidade do processador. Por exemplo, os algoritmos de Predição linear por excitação com código algébrico (ACELP, Algebraic Code Excited Linear Prediction) analisam um bloco de 10 ms de amostras de PCM e, em seguida, compactam essas amostras.
O tempo de compactação de um processo de Predição linear por excitação com código algébrico de estrutura conjugada (CS-ACELP, Conjugate Structure Algebraic Code Excited Linear Prediction) varia de 2,5 ms a 10 ms com base na carga do processador DSP. Se o DSP estiver totalmente carregado com quatro canais de voz, o atraso do codificador será de 10 ms. Se o DSP estiver carregado com apenas um canal de voz, o atraso do codificador será de 2,5 ms. Para fins de projeto, use 10 ms, o tempo do pior cenário.
O tempo de descompactação é aproximadamente 10% do tempo de compactação para cada bloco. No entanto, o tempo de descompactação é proporcional ao número de amostras por frame devido à presença de várias amostras. Consequentemente, o tempo de descompactação do pior caso para um frame com três amostras é de 3 x 1 ms ou 3 ms. Geralmente, dois ou três blocos de saída G.729 compactada são postos em um frame enquanto uma amostra de saída G.723.1 compactada é enviada em um único frame.
A melhor e a pior hipótese de atraso do codificador são mostradas na Tabela 5.1.
Tabela 5.1 Retardo do processamento de melhor e pior casos
| Codificador | Taxa | Bloco de Exemplo Obrigatório | Retardo de codificador do melhor caso | Pior caso de retardo de codificador |
|---|---|---|---|---|
| ADPCM, G.726 | 32 Kbps | 10 ms | 2,5 ms | 10 ms |
| CS-ACELP, G.729A | 8,0 Kbps | 10 ms | 2,5 ms | 10 ms |
| MP-MLQ, G.723.1 | 6,3 Kbps | 30 ms | 5 ms | 20 ms |
| MP-ACELP, G.723.1 | 5,3 Kbps | 30 ms | 5 ms | 20 ms |
Atraso algorítmico
O algoritmo de compactação depende de características conhecidas de voz para processar corretamente o bloco N de amostra. O algoritmo deve ter algum conhecimento do que há no bloco N+1 para reproduzir com precisão o bloco N de amostra. Essa previsão, que é, na verdade, um atraso adicional, é chamada de atraso algorítmico. Isso aumenta de forma eficiente o comprimento do bloco de compactação.
Isso acontece repetidamente: o bloco N+1 prevê o bloco N+2, e assim por diante. O efeito na rede é uma adição de 5 ms ao atraso geral no enlace. Isso significa que o tempo total necessário para processar um bloco de informações é de 10 min. com um fator de carga adicional constante de 5 min. Veja a Figura 3-1: Compactação de voz.
-
O Retardo Algorítmico de codificadores G.726 é 0 ms
-
O Retardo Algorítmico para os codificadores G.729 é de 5 ms.
-
O retardo de algoritmo para codificadores G.723.1 é 7,5 ms.
Para os exemplos no restante deste documento, suponha a compactação G.729 com um payload de 30 ms/30 bytes. Para facilitar o projeto e adotar uma abordagem conservadora, as tabelas fornecidas no restante deste documento supõem o pior caso de atraso do codificador. O atraso de codificador, o atraso de descompactação e o atraso de algoritmo são agregados em um fator, chamado de atraso do codificador.
A equação usada para gerar o Parâmetro de Retardo de Codificador agregado é:
Equação 1: Parâmetro de atraso do codificador agregado 
O atraso do codificador agregado para o G.729 que é usado para o restante deste documento é:
Pior caso de tempo de compressão por bloco: 10 ms
Tempo de Descompressão Por Bloco x 3 Blocos 3 ms
Atraso algorítmico de 5 ms---------------------------
Total (χ) de 18 ms
Retardo de empacotamento
O retardo de empacotamento (o) é o tempo gasto para preencher um payload de pacote com discurso codificado/compactado. Esse atraso é uma função do tamanho do bloco de amostra exigido pelo codificador de voz e o número de blocos colocados em um único frame. O atraso de empacotamento também pode ser chamado de atraso de acumulação, porque as amostras de voz são acumuladas em um buffer antes de serem liberadas.
Como regra geral, você precisa se esforçar para obter um atraso de empacotamento inferior a 30 ms. No roteador/gateway da Cisco, você precisa usar estes valores da Tabela 5.2 com base no tamanho do payload configurado:
Tabela 5.2: Empacotamento comum
| Codificador | Tamanho do payload (Bytes) | Retardo de empacotamento (ms) | Tamanho do payload (Bytes) | Retardo de empacotamento (ms) | |
|---|---|---|---|---|---|
| PCM, G.711 | 64 Kbps | 160 | 20 | 240 | 30 |
| ADPCM, G.726 | 32 Kbps | 80 | 20 | 120 | 30 |
| CS-ACELP, G.729 | 8,0 Kbps | 20 | 20 | 30 | 30 |
| MP-MLQ, G.723.1 | 6,3 Kbps | 24 | 24 | 60 | 48 |
| MP-ACELP, G.723.1 | 5,3 Kbps | 20 | 30 | 60 | 60 |
Você deve balancear o retardo de empacotamento no carregamento da CPU. Quanto menor o retardo, maior a taxa do quadro e maior a carga da CPU. Em algumas plataformas mais antigas, payloads de 20 ms podem prejudicar o CPU principal.
Atraso de pipeline no processo de empacotamento
Embora cada amostra de voz apresente atrasos algorítmicos e de empacotamento, na realidade, os processos são sobrepostos e há um efeito benéfico de rede proveniente desse pipelining. Considere o exemplo mostrado na Figura 2-1.
Figura 5-2: Encanamento e empacotamento 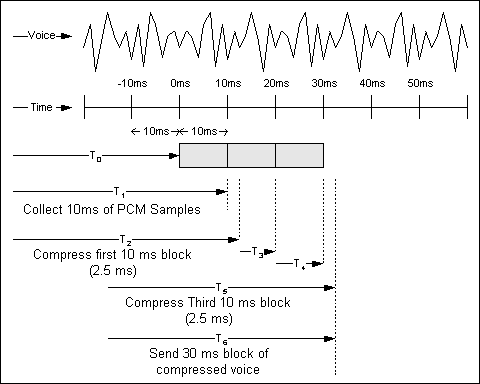
A linha superior da figura demonstra uma amostra de forma de onda de voz. A segunda linha é uma escala de tempo em incrementos de 10 ms. Em T0, o algoritmo CS-ACELP começa a coletar amostras de PCM do codec. Em T1, o algoritmo coletou seu primeiro bloco de amostras de 10 ms e começa a compactá-lo. Em T2, o primeiro bloco de amostras foi compactado. Neste exemplo, o tempo de compactação é de 2,5 ms, conforme indicado por T2-T1.
O segundo e terceiro blocos são coletados em T3 e T4. O terceiro bloco é comprimido em T5. O pacote é montado e enviado (presumivelmente instantâneo) em T6. Devido à natureza de enfileiramento dos processos de compactação e empacotamento, o atraso desde o momento em que o processo se inicia até o momento em que a estrutura de voz é enviada é de T6-T0 ou aproximadamente 32,5 ms.
Para ilustrar, esse exemplo tem como base o atraso da melhor hipótese. Se o atraso da pior hipótese for usado, o valor será de 40 ms, 10 ms para o atraso do codificador e 30 ms para o atraso de empacotamento.
Observe que esses exemplos não incluem o atraso algorítmico.
Retardo de serialização
O retardo de serialização (σ n) é o retardo fixo necessário para fazer o clock de um quadro de voz ou de dados na interface de rede. Está diretamente relacionado ao clock rate no tronco. Em baixas velocidades de clock e tamanhos reduzidos de frame, a flag adicional necessária para separar frames é importante.
A Tabela 5.3 mostra o atraso de serialização exigido para diferentes tamanhos de frame em diferentes velocidades de linha. Essa tabela usa o tamanho total do frame, não o tamanho de payload, para cálculo.
Tabela 5.3: Atraso de serialização em milissegundos para tamanhos de frame diferentes
| Tamanho do Quadro (bytes) | Velocidade da Linha (Kbps) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 19.2 | 56 | 64 | 128 | 256 | 384 | 512 | 768 | 1024 | 1544 | 2048 | |
| 38 | 15.83 | 5.43 | 4.75 | 2.38 | 1.19 | 0.79 | 0.59 | 0.40 | 0.30 | 0.20 | 0.15 |
| 48 | 20.00 | 6.86 | 6.00 | 3.00 | 1.50 | 1.00 | 0.75 | 0.50 | 0,38 | 0.25 | 0.19 |
| 64 | 26.67 | 9.14 | 8.00 | 4.00 | 2.00 | 1.33 | 1.00 | 0.67 | 0.50 | 0.33 | 0.25 |
| 128 | 53.33 | 18.29 | 16.00 | 8.00 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 | 0.66 | 0.50 |
| 256 | 106.67 | 36.57 | 32.00 | 16.00 | 8.00 | 5.33 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 |
| 512 | 213.33 | 73.14 | 64.00 | 32.00 | 16.00 | 10.67 | 8.00 | 5.33 | 4.00 | 2.65 | 2.00 |
| 1024 | 426.67 | 149.29 | 128.00 | 64.00 | 32.00 | 21.33 | 16.00 | 10.67 | 8.00 | 5.31 | 4.00 |
| 1500 | 625.00 | 214.29 | 187.50 | 93.75 | 46.88 | 31.25 | 23.44 | 15.63 | 11.72 | 7.77 | 5.86 |
| 2048 | 853.33 | 292.57 | 256.00 | 128.00 | 64.00 | 42.67 | 32.00 | 21.33 | 16.00 | 10.61 | 8.00 |
Na tabela, em uma linha de 64 Kbps, um frame de voz de CS-ACELP com um comprimento de 38 bytes (flag 37+1) tem um atraso de serialização de 4,75 ms.
Observação: o atraso de serialização para uma célula ATM de 53 bytes (T1: 0.275ms, E1: 0,207ms) é desprezível devido à velocidade alta de linha e ao tamanho reduzido de célula.
Retardo de enfileiramento/colocação em buffer
Depois que o payload de voz comprimida é construído, um cabeçalho é adicionado e o quadro é enfileirado para transmissão pela conexão da rede. A voz precisa ter prioridade absoluta no roteador/gateway. Por isso, um frame de voz deve apenas esperar por um frame de dados que já foi usado ou outros frames de voz à frente. Essencialmente, o frame de voz espera o atraso de serialização de qualquer frame precedente na fila de saída. Retardo de enfileiramento (ßn) é um retardo variável dependente da velocidade do tronco e do estado da fila. Existem elementos aleatórios associados com o atraso de enfileiramento.
Por exemplo, suponha que você esteja em uma linha de 64 Kbps enfileirado atrás de um frame de dados (48 bytes) e de um frame de voz (42 bytes). Porque há uma natureza aleatória a respeito de quanto do frame de 48 bytes foi usado, é possível supor com segurança que, em média, metade do frame de dados foi usada. Com base nos dados da tabela de serialização, seu componente do frame de dados é 6 ms * 0,5 = 3 ms. Ao adicionar o tempo de outro frame à frente na fila (5,25 ms), o tempo total de atraso de enfileiramento é de 8,25 ms.
Como caracterizar o retardo da fila é tarefa para o engenheiro de rede. Geralmente, é preciso criar um projeto considerando o pior cenário e ajustar o desempenho depois que a rede for instalada. Quanto maior for o número de linhas de voz disponíveis para os usuário, maior será a probabilidade de o pacote de voz médio esperar na fila. O frame de voz, devido à estrutura de prioridade, nunca espera atrás de mais de um frame de dados.
Retardo de switching de rede
A rede de ATM ou o frame relay público que interconecta os locais de ponto de extremidade é a fonte dos maiores atrasos das conexões de voz. Atrasos de comutação de rede (ω n) também são os mais difíceis de quantificar.
Se a conectividade de área ampla for fornecida por equipamentos Cisco, ou por alguma outra rede privada, é possível identificar os componentes individuais do atraso. Geralmente, os componentes fixos são provenientes dos atrasos de propagação nos troncos dentro da rede, e os atrasos variáveis são originados dos atrasos de enfileiramento que cronometram os frames que entram e saem dos switches intermediários. Para estimar o atraso de propagação, uma estimativa popular de 10 microssegundos/milha ou 6 microssegundos/km (G.114) é muito utilizada. Contudo, o equipamento de multiplexação intermediário, o transporte do tráfego de voz e dados, os links de micro-ondas e outros fatores encontrados nas redes da portadora criam muitas exceções.
O outro componente significativo do retardo é o enfileiramento dentro da rede de área ampla. Em uma rede privada, pode ser possível medir atrasos de enfileiramento existentes ou fazer uma estimativa de orçamento por salto dentro da rede de longa distância.
Os atrasos típicos da portadora para conexões de frame relay dos EUA são de 40 ms fixos e 25 ms para um atraso total de 65 ms da pior hipótese. Para simplificar, nos exemplos 6-1, 6-2 e 6-3, qualquer atraso de serialização de baixa velocidade no atraso fixo de 40 ms é incluído.
Esses são valores publicados por portadoras de frame relay dos EUA para suportar cobertura total no país. Deve-se esperar que dois lugares geograficamente mais próximos do que a pior hipótese tenham melhor desempenho de atraso, mas as portadoras normalmente documentam apenas a pior hipótese.
As portadoras de frame relay às vezes oferecem serviços premium. Esses serviços são geralmente de tráfego de Arquitetura de rede de sistemas (SNA, Systems Network Architecture) ou voz, onde o atraso de rede é garantido e menor que o nível de serviço padrão. Por exemplo, uma portadora americana anunciou recentemente esse serviço com um limite de retardo geral de 50 ms, em vez dos 65 ms do serviço padrão.
Retardo de controle de variação de sinal
Como a voz é um serviço de taxa de bits constante, o controle de variação de sinal de todos os retardos variáveis deve ser removido antes que o sinal saia da rede. Em roteadores/gateways Cisco, isso é feito com um buffer de controle de variação (NDIR) no roteador/gateway da extremidade oposta (receptor). O buffer de controle de variação de sinal transforma o atraso variável em um atraso fixo. Ele preserva a primeira amostra recebida por um período antes de usá-la. Esse período de espera é conhecido como retardo de playout inicial.
Figura 5- 3: Operação de buffer de controle de variação de sinal 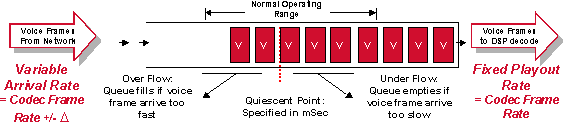
É essencial tratar o buffer de controle de variação de sinal da forma apropriada. Se as amostras forem preservadas por um tempo muito curto, as variações no atraso poderão fazer com que o buffer seja interrompido e causar falhas de voz. Se a amostra for preservada por um tempo muito longo, o buffer poderá sofrer saturação e os pacotes descartados poderão causar falhas de voz. Por fim, se os pacotes forem preservados por um tempo muito longo, o atraso geral na conexão poderá aumentar aos níveis inaceitáveis.
O atraso de uso inicial ideal do buffer de controle de variação de sinal é igual ao atraso variável total ao longo da conexão. Isso é mostrado na Figura 5-4.
Observação: os buffers de controle de variação de sinal podem ser adaptáveis, mas o atraso máximo é fixo. Quando os buffers adaptáveis são configurados, o atraso trona-se um valor variável. Contudo, o atraso máximo pode ser usado como pior hipótese para fins de projeto.
Para obter mais informações sobre buffers adaptáveis, consulte Melhorias de atraso de uso para voz sobre IP.
Figura 5-4: Atraso variável e buffer de controle de variação de sinal 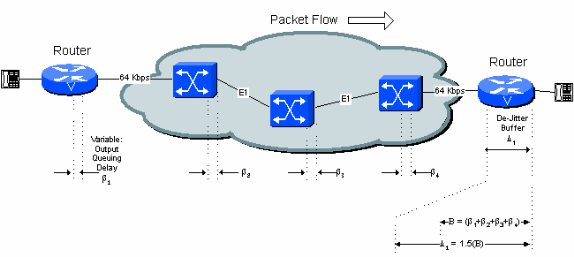
O atraso de uso inicial é configurável. A profundidade máxima do buffer antes que seja sobrecarregado é normalmente ajustada para 1,5 ou 2 vezes esse valor.
Se a configuração de atraso nominal for usada, a primeira amostra de voz recebida quando o buffer de controle de variação de sinal está vazio é preservada por 40 ms antes de ser usada. Isto implica que um pacote subsequente recebido da rede poderá apresentar atraso de até 40 ms (em relação ao primeiro pacote) sem nenhuma perda de continuidade de voz. Se for atrasado por mais de 40 ms, o buffer de controle de variação de sinal é esvaziado e o próximo pacote recebido é preservado por 40 ms antes de ser usado para restaurar o buffer. Isso resulta em uma falha de voz de aproximadamente 40 ms.
A contribuição real do buffer de controle de variação de sinal é seu atraso de uso inicial mais a quantidade real que o primeiro pacote sofreu buffer na rede. A pior hipótese é duas vezes o atraso inicial do buffer de controle de variação de sinal (a suposição é que o primeiro pacote enviado pela rede tenha sofrido somente atraso mínimo de buffer). Na prática, em vários saltos de switch de rede, provavelmente não é necessário supor a pior hipótese. Os cálculos nos exemplos no restante deste documento aumentam o atraso do uso inicial em um fator de 1,5 para permitir esse efeito.
Observação: no roteador/gateway receptor há atraso na função de descompressão. Contudo, isso é levado em consideração agregando-o com o retardo de processamento da compactação, conforme discutido anteriormente.
Criação do orçamento de atraso
O limite geralmente aceito de atraso na conexão de voz de boa qualidade é de 200 ms unidirecionais (ou 250 ms como limite). Como os atrasos aumentam nessa figura, as pessoas que falam e as que escutam ficam sem sincronização e normalmente falam ao mesmo tempo ou ambas esperam o outro falar. Essa condição é geralmente chamada de sobreposição do interlocutor. Apesar da qualidade geral de voz ser aceitável, os usuários às vezes acham a natureza artificial da conversa inaceitavelmente irritante. A sobreposição do interlocutor pode ser observada em chamadas telefônicas internacionais que viajam por conexões via satélite (o atraso do satélite é de 500 ms, 250 ms a mais e 250 ms a menos).
Esses exemplos ilustram várias configurações de rede e os atrasos que o programador de rede precisa levar em consideração.
Conexão de salto único
Figura 6-1: Exemplo de conexão de um único salto 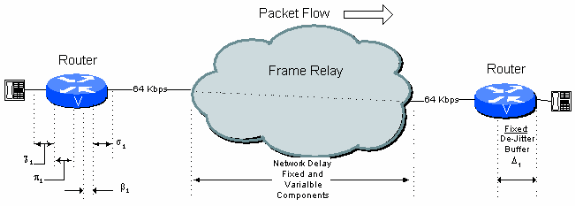
Nesta figura, uma conexão típica de um salto em uma conexão de frame relay público pode ter o orçamento de atraso mostrado na Tabela 6.1.
Tabela 6.1: Cálculo de atraso de salto único
| Tipo de retardo | Fixo (ms) | Variável (ms) |
|---|---|---|
| Retardo de codificador, χ1 | 18 | |
| Retardo de empacotamento, π1 | 30 | |
| Enfileiramento/buffering, ß1 | 8 | |
| Retardo de serialização (64 kbps), σ1 | 5 | |
| Retardo de rede (estrutura pública), ω1 | 40 | 25 |
| Retardo de buffer de tremulação, Δ1 | 45 | |
| Totais | 138 | 33 |
Observação: como o retardo de enfileiramento e o componente variável do retardo da rede já são contabilizados nos cálculos do buffer de controle de variação de sinal, o retardo total é efetivamente apenas a soma de todo o retardo fixo. Nesse caso, o atraso total é de 138 ms.
Dois saltos em uma rede pública com um C7200 que atua como um switch em tandem
Figura 6-2: Exemplo de rede pública de dois nós com tandem de roteador/gateway 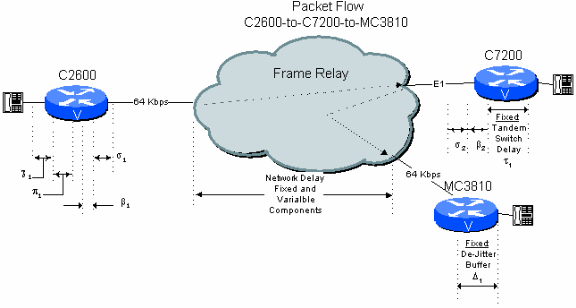
Considere agora uma conexão de filial a filial em uma rede de topologia em estrela na qual o C7200 no local da matriz liga a chamada à filial de destino. Neste caso, o sinal fica em formato compactado até o C7200 central. Isso resulta em economias consideráveis no orçamento de atraso no que diz respeito ao próximo exemplo: conexão de dois saltos em uma rede pública com um switch PBX em tandem.
Tabela 6.2: Cálculo do atraso da rede pública de dois saltos com roteador/gateway em tandem
| Tipo de retardo | Fixo (ms) | Variável (ms) |
|---|---|---|
| Retardo de codificador, χ1 | 18 | |
| Retardo de empacotamento, π1 | 30 | |
| Enfileiramento/buffering, ß1 | 8 | |
| Retardo de serialização (64 kbps), σ1 | 5 | |
| Retardo de rede (estrutura pública), ω1 | 40 | 25 |
| Atraso de Tandem na MC3810, τ1 | 1 | |
| Enfileiramento/colocação em buffer, ß2 | 0,2 | |
| Retardo de serialização (2 Mbps) σ2 | 0,1 | |
| Retardo de rede (Quadro público), ω2 | 40 | 25 |
| Retardo de buffer de tremulação, Δ1 | 75 | |
| Totais | 209.1 | 58.2 |
Observação: como o retardo de enfileiramento e o componente variável do retardo da rede já são contabilizados nos cálculos do buffer de controle de variação de sinal, o retardo total é efetivamente apenas a soma de todo o retardo fixo. Nesse caso, o atraso total é de 209,1 ms.
Conexão de dois saltos em uma rede pública com um Switch em tandem PBX
Figura 6-3: Exemplo de rede pública de dois saltos com PBX em tandem 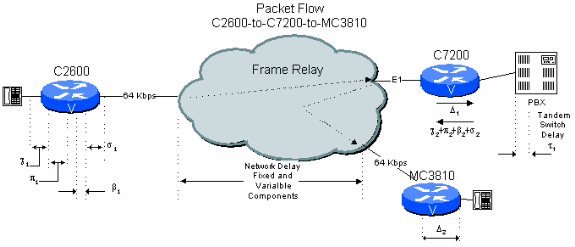
Considere uma conexão de filial-a-filial em uma rede filial-a-matriz na qual o C7200 na estação da matriz passa a conexão pelo PBX da matriz para switching. Aqui o sinal de voz precisa ser descompactado e ter sua variação de atraso medida e, em seguida, recompactado e ter sua variação de atraso medida novamente. Isso resulta em atrasos adicionais em relação ao exemplo anterior. Além disso, os ciclos de compactação de CS-ACELP reduzem a qualidade de voz (consulte Efeitos de Vários Ciclos de Compactação).
Tabela 6.3: Cálculo de atraso da rede pública de dois saltos com PBX em tandem
| Tipo de retardo | Fixo (ms) | Variável (ms) |
|---|---|---|
| Retardo de codificador, χ1 | 18 | |
| Retardo de empacotamento, π1 | 30 | |
| Enfileiramento/buffering, ß1 | 8 | |
| Retardo de serialização (64 kbps), σ1 | 5 | |
| Retardo de rede (estrutura pública), ω1 | 40 | 25 |
| Retardo de buffer de tremulação, Δ1 | 40 | |
| Atraso do codificador,2 | 15 | |
| Atraso de empacotamento, 2 | 30 | |
| Enfileiramento/colocação em buffer, ß2 | 0,1 | |
| Retardo de serialização (2 Mbps) σ2 | 0,1 | |
| Retardo de rede (Quadro público), ω2 | 40 | 25 |
| Retardo de buffer de controle de variação de sinal, Δ2 | 40 | |
| Totais | 258.1 | 58.1 |
Observação: como o atraso do enfileiramento e o componente variável do atraso da rede já são contabilizados nos cálculos do buffer de controle de variação de sinal, o atraso total é efetivamente apenas a soma de todo o atraso fixo mais o atraso do buffer de controle de variação de sinal. Nesse caso, o atraso total é de 258,1 ms.
Se você usar o PBX no local central como um switch, ele aumentará o atraso da conexão unidirecional de 206 ms para 255 ms. Isso é próximo aos limites da ITU de atraso unidirecional. Esse tipo de configuração de rede exige que o engenheiro preste muita atenção ao projetar para atraso mínimo.
A pior hipótese é presumida para o atraso variável (embora ambos os segmentos na rede pública não apresentem atrasos máximos simultaneamente). Se você fizer suposições mais otimistas para os atrasos variáveis, a situação sofrerá apenas uma melhora mínima. Contudo, com melhores informações sobre os atrasos fixos e variáveis na rede de frame relay da portadora, o atraso calculado pode ser reduzido. Conexões locais (por exemplo, entre estados) podem apresentar características de atraso muito melhores, mas as portadores muitas vezes relutam em dar limites de atraso.
Conexão de dois saltos em uma rede privada com um Switch tandem PBX
Figura 6-4: Exemplo de rede privada de dois saltos com tandem PBX 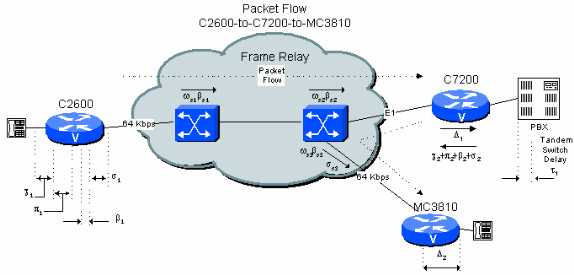
O exemplo 4.3 mostra que, com a suposição da pior hipótese de atrasos, é muito difícil manter o atraso calculado abaixo de 200 ms quando a conexão de filial a filial inclui um salto com PBX em tandem no local central com conexões públicas de frame relay de cada lado. Contudo, se a topologia de rede e o tráfego forem conhecidos, é possível reduzir substancialmente o valor calculado. Isso acontece porque os valores geralmente fornecidos pelas portadoras são limitados pela pior hipótese de atraso de transmissão e enfileiramento em uma área ampla. É muito mais fácil estabelecer limites mais razoáveis em uma rede privada.
O número geralmente aceito para atraso de transmissão entre Switches é da ordem de 10 microssegundos/milha. Com base no equipamento, o atraso trans-switch em uma rede de frame relay precisa ser de 1 ms fixo e 5 ms variável para enfileiramento. Esses números dependem do tráfego e do equipamento. O valor de atraso dos Switches WAN MGX da Cisco é de menos de 1 ms por switch no total, caso troncos E1/T1 sejam usados. Supondo 500 milhas de distância, com 1 ms fixo e 5 ms variável para cada salto, o cálculo do atraso será:
Tabela 6.4: Cálculo de atraso da rede privada de dois saltos com PBX em tandem
| Tipo de retardo | Fixo (ms) | Variável (ms) |
|---|---|---|
| Retardo de codificador, χ1 | 18 | |
| Retardo de empacotamento, π1 | 30 | |
| Enfileiramento/buffering, ß1 | 8 | |
| Retardo de serialização (64 kbps), σ1 | 5 | |
| Atraso da Rede (Quadro Privado), SinalS1 + ßS1 + SomS2 + ßS2 | 2 | 10 |
| Retardo de buffer de tremulação, Δ1 | 40 | |
| Atraso do codificador,2 | 15 | |
| Atraso de empacotamento, 2 | 30 | |
| Enfileiramento/colocação em buffer, ß2 | 0,1 | |
| Retardo de serialização (2 Mbps) σ2 | 0,1 | |
| Atraso da Rede (Quadro Privado), SomS3 + ßS3 | 1 | 8 |
| Atraso de serialização (64 kbps), S3 | 5 | |
| Retardo de buffer de controle de variação de sinal, Δ2 | 40 | |
| Retardo de transmissão/distância (sem interrupção) | 5 | |
| Totais | 191.1 | 26.1 |
Observação: como o atraso do enfileiramento e o componente variável do atraso da rede já são contabilizados nos cálculos do buffer de controle de variação de sinal, o atraso total é apenas a soma de todo o atraso fixo. Nesse caso, o atraso total é de 191,1 ms.
Ao trabalhar com uma rede de frame relay privada, é possível fazer uma conexão ponto a ponto através do PBX no local de hub e manter-se no limite de 200 ms.
Efeitos de vários ciclos de compactação
Os algoritmos de compactação CS-ACELP não são deterministas. Isso significa que o fluxo de dados de entrada não é exatamente o mesmo que o fluxo de dados da saída. Uma pequena quantidade de distorção é introduzida com cada ciclo de compactação, conforme mostra a Figura 7-1.
Figura 7-1: Efeitos da compactação 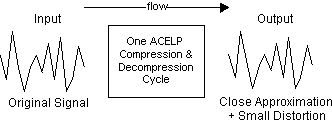
Consequentemente, vários ciclos de compactação CS-ACELP introduzem rapidamente níveis significativos de distorção. Esse efeito de distorção aditiva não é como o pronunciado com algoritmos de compressão digital de ondas sonoras (ADPCM).
O impacto dessa característica é que, além dos efeitos do atraso, o programador de rede deve considerar o número de ciclos de compactação CS-ACELP no caminho.
A qualidade de voz é subjetiva. A maioria dos usuários descobre que dois ciclos de compactação ainda fornecem qualidade de voz adequada. Um terceiro ciclo de compactação geralmente resulta em degradação notável, o que pode ser inaceitável para alguns usuários. Geralmente, o programador de rede precisa limitar a dois o número de ciclos de compactação CS-ACELP em um caminho. Se mais ciclos precisarem ser usados, deixe o cliente ouvir primeiro.
Nos exemplos anteriores, foi mostrado que quando uma conexão de filial a filial é comutada em tandem através do PBX (em forma de PCM) no local da matriz, ela apresenta atraso significativamente maior do que se fosse comutada em tandem nas matrizes C7200. É claro que, quando o PBX é usado para comutar, há dois ciclos de compactação CS-ACELP no caminho em vez do ciclo único de quando a voz em frame é comutada pelo C7200 central. A qualidade de voz é melhor com o exemplo comutado pelo C7200 (4.2), embora possa haver outras razões, como o gerenciamento do plano de chamada, que pode exigir que o PBX seja incluído no caminho.
Se uma conexão de filial a filial for feita através de um PBX central, e a partir da segunda filial a chamada for estendida pela rede de voz pública e terminar em uma rede de telefone celular, haverá três ciclos de compactação CS-ACELP no caminho, bem como um atraso significativamente mais alto. Nesse cenário, a qualidade é notadamente afetada. Além disso, o programador de rede deve considerar o caminho de chamada da pior hipótese e decidir se é aceitável, dados os requisitos comerciais, a rede de usuários e as expectativas.
Considerações sobre conexões de longo atraso
É relativamente fácil projetar redes de voz de pacote de informação que excedem o limite de atraso unidirecional de 150 ms geralmente aceito pela ITU.
Ao projetar redes de voz de pacote de informação, o engenheiro precisa considerar a frequência com a qual a conexão é usada, o que o usuário exige e que tipo de atividade comercial está envolvida. Não é raro que tais conexões sejam aceitáveis em determinadas circunstâncias.
Se as conexões de frame relay não atravessarem uma grande distância, é bastante provável que o desempenho de atraso da rede seja melhor do que o mostrado nos exemplos.
Se o atraso total apresentado pelas conexões de roteador/gateway em tandem passar a ser muito grande, uma alternativa é frequentemente configurar Circuitos virtuais permanentes (PVC, Permanent Virtual Circuits) adicionais diretamente entre os MC3810 de destino. Isso acrescenta custos recorrentes à rede, visto que as portadoras geralmente cobram por PVC, mas pode ser necessário em alguns casos.
Informações Relacionadas
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)