Introdução
Este documento descreve como solucionar problemas do sessmgr ou aamgr que estão em estado de "aviso" ou "sobre".
Overview
Gerenciador de Sessão (Sessmgr) - É um sistema de processamento de assinante que suporta vários tipos de sessão e é responsável por manipular transações de assinante. O Sessmgr é normalmente emparelhado com AAManagers.
Authorization, Authentication, and Accounting Manager (Aamgr) - É responsável por executar todas as operações e funções do protocolo AAA para assinantes e usuários administrativos no sistema.
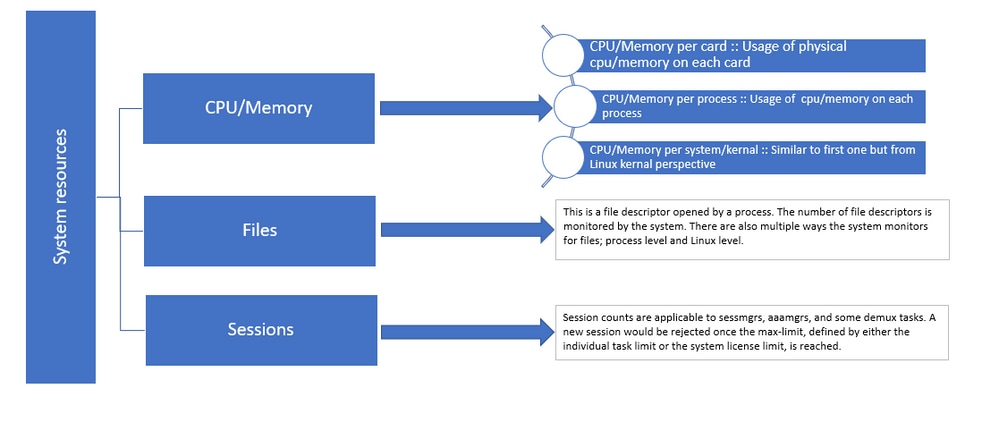 Figura 1 :: Distribuição de recursos Staros
Figura 1 :: Distribuição de recursos Staros
Registros/Verificações básicas
Verificações básicas
Para coletar mais detalhes sobre o problema, você precisa verificar estas informações com o usuário:
- Há quanto tempo o sessmgr/aamgr está no estado "avisar" ou "sobre"?
- Quantos sessmgrs/amgrs são afetados por esse problema?
- Você precisa confirmar se o sessmgr/aamgr está no estado "warn" ou "over" devido à memória ou à CPU.
- Você também precisa verificar se houve um aumento repentino no tráfego, que pode ser avaliado examinando o número de sessões por sessmgr.
Ao obter essas informações, você pode entender melhor e resolver o problema em questão.
Logs
-
Obtenha o Show Support Details (SSD) e os syslogs que capturam o carimbo de data/hora problemático. É recomendável coletar esses registros pelo menos 2 horas antes do início do problema para identificar o ponto de disparo.
-
Capture arquivos principais para o sessmgr/aamgr problemático e não problemático. Mais informações sobre isso podem ser encontradas na seção Análise.
Análise
Etapa 1. Para verificar o status dos comandos sessmgr/aamgr afetados.
show task resources -
--------- to check detail of sessmgr/aamgr into warn/over state and from the same you also get to know current memory/cpu utlization
Output ::
******** show task resources *******
Monday May 29 08:30:54 IST 2023
task cputime memory files sessions
cpu facility inst used alloc used alloc used allc used allc S status
----------------------- ----------- ------------- --------- ------------- ------
2/0 sessmgr 297 6.48% 100% 604.8M 900.0M 210 500 1651 12000 I good
2/0 sessmgr 300 5.66% 100% 603.0M 900.0M 224 500 1652 12000 I good
2/1 aaamgr 155 0.90% 95% 96.39M 260.0M 21 500 -- -- - good
2/1 aaamgr 170 0.89% 95% 96.46M 260.0M 21 500 -- -- - good

Observação: o número de sessões por sessmgr pode ser verificado por esse comando, como mostrado na saída do comando.
Ambos os comandos ajudam a verificar o uso máximo de memória desde que o nó foi recarregado:
show task resources max
show task memory max
******** show task memory max *******
Monday May 29 08:30:53 IST 2023
task heap physical virtual
cpu facility inst max max alloc max alloc status
----------------------- ------ ------------------ ------------------ ------
2/0 sessmgr 902 548.6M 66% 602.6M 900.0M 29% 1.19G 4.00G good
2/0 aaamgr 913 68.06M 38% 99.11M 260.0M 17% 713.0M 4.00G good
Observação: o comando memory max fornece a memória máxima utilizada desde a recarga do nó. Esse comando nos ajuda a identificar quaisquer padrões relacionados ao problema, como se o problema tivesse sido iniciado após um recarregamento recente ou se houvesse um recarregamento recente que nos permitisse verificar o valor máximo de memória. Por outro lado, "show task resources" e "show task resources max" fornecem saídas semelhantes, com a distinção de que o comando max exibe os valores máximos de memória, CPU e sessões utilizadas por um sessmgr/aamgr específico desde o recarregamento.
show subscriber summary apn <apn name> smgr-instance <instance ID> | grep Total
-------------- to check no of subscribers for that particular APN in sessmg
Plano de ação
Cenário 1. Devido à alta utilização de memória
1. Colete o SSD antes de reiniciar/eliminar a instância do sessmgr.
2. Colete o dump central para qualquer um dos sessmgr afetados.
task core facility sessmgr instance <instance-value>
3. Colete a saída de heap usando esses comandos no modo oculto para o mesmo sessmgr e aamgr afetados.
show session subsystem facility sessmgr instance <instance-value> debug-info verbose
show task resources facility sessmgr instance <instance-value>
Heap outputs:
show messenger proclet facility sessmgr instance <instance-value> heap depth 9
show messenger proclet facility sessmgr instance <instance-value> system heap depth 9
show messenger proclet facility sessmgr instance <instance-value> heap
show messenger proclet facility sessmgr instance <instance-value> system
show snx sessmgr instance <instance-value> memory ldbuf
show snx sessmgr instance <instance-value> memory mblk
4. Reinicie a tarefa do sessmgr usando este comando:
task kill facility sessmgr instance <instance-value>

Cuidado: se houver vários smgrs no estado "avisar" ou "acima", é recomendável reiniciar os smgrs com um intervalo de 2 a 5 minutos. Comece reiniciando apenas 2 a 3 sessmgrs inicialmente e espere até 10 a 15 minutos para observar se esses sessmgrs retornam ao estado normal. Essa etapa ajuda a avaliar o impacto da reinicialização e a monitorar o progresso da recuperação.
5. Verifique o status do sessmgr.
show task resources facility sessmgr instance <instance-value> -------- to check if sessmgr is back in good state
6. Colete outro SSD.
7. Colete a saída de todos os comandos CLI mencionados na Etapa 3.
8. Colete o dump central para qualquer uma das instâncias íntegras do sessmgr usando o comando mencionado na Etapa 2.
Observação: para obter arquivos principais para recursos problemáticos e não problemáticos, você tem duas opções. Primeiro, você pode coletar o arquivo do núcleo do mesmo sessmgr depois que ele retornar ao normal após uma reinicialização. Como alternativa, você pode capturar o arquivo principal de um sessmgr saudável diferente. Ambas as abordagens fornecem informações valiosas para análise e solução de problemas.
Depois de coletar as saídas de heap, entre em contato com o TAC da Cisco para encontrar a tabela exata de consumo de heap.
A partir dessas saídas de heap, você precisa verificar a função que está utilizando mais memória. Com base nisso, o TAC investiga a finalidade pretendida da utilização da função e determina se sua utilização se alinha com o aumento do volume de tráfego/transação ou qualquer outro motivo problemático.
As saídas de pilha podem ser classificadas usando uma ferramenta acessada pelo link fornecido como Memory-CPU-data-sorting-tool.
Observação: nesta ferramenta, há várias opções para diferentes recursos. No entanto, você precisa selecionar "Tabela de consumo de pilha" onde você carrega saídas de pilha e executa a ferramenta para obter a saída em um formato classificado.
Cenário 2. Devido à alta utilização da CPU
1. Colete o SSD antes de reiniciar ou eliminar a instância do sessmgr.
2. Colete o dump central para qualquer um dos sessmgr afetados.
task core facility sessmgr instance <instance-value>
3. Colete a saída de heap desses comandos no modo oculto para o mesmo sessmgr/aamgr afetado.
show session subsystem facility sessmgr instance <instance-value> debug-info verbose
show task resources facility sessmgr instance <instance-value>
show cpu table
show cpu utilization
show cpu info ------ Display detailed info of CPU.
show cpu info verbose ------ More detailed version of the above
Profiler output for CPU
This is the background cpu profiler. This command allows checking which functions consume
the most CPU time. This command requires CLI test command password.
show profile facility <facility instance> instance <instance ID> depth 4
show profile facility <facility instance> active facility <facility instance> depth 8
4. Reinicie a tarefa do sessmgr com este comando:
task kill facility sessmgr instance <instance-value>
5. Verifique o status do sessmgr.
show task resources facility sessmgr instance <instance-value> -------- to check if sessmgr is back in good state
6. Colete outro SSD.
7. Colete a saída de todos os comandos CLI mencionados na Etapa 3.
8. Colete o dump central para qualquer uma das instâncias íntegras do sessmgr usando o comando mencionado na Etapa 2.
Para analisar cenários de alta memória e CPU, examine bulkstats para determinar se há um aumento legítimo nas tendências de tráfego.
Além disso, verifique bulkstats para estatísticas no nível de placa/CPU.
 Feedback
Feedback