Introdução
Este documento descreve os problemas do Redundancy Configuration Manager (RCM) e da User Plane Function (UPF) que estão causando o estado do servidor do sessmgr.
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos:
Componentes Utilizados
As informações neste documento são baseadas nestas versões de software e hardware:
- RCM-checkpointmgr
- UPF-sessmgr
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
Ele também fornece um guia detalhado de solução de problemas para problemas de estado do servidor do sessmgr, prejudicando o tráfego e o processamento de chamadas. Além disso, uma seção de testes de laboratório para recuperação.
Visão geral básica
Como mostrado na imagem, você pode observar as conexões diretas entre os gerenciadores de redundância (chamados de checkpointmgrs) no RCM e os sessmgrs em UPFs para o rastreamento de checkpoint.
Mapeamento de Redmgrs e Sessmgrs
1. Cada UP tem um número "N" de sessmgr.
2. O RCM tem um número "M" de redmgrs, em função do número de sessmgrs em UPF.
3. Os redmgrs e os sessmgrs têm um mapeamento 1:1 com base em seus IDs, onde há redmgrs separados para cada sessmgr.
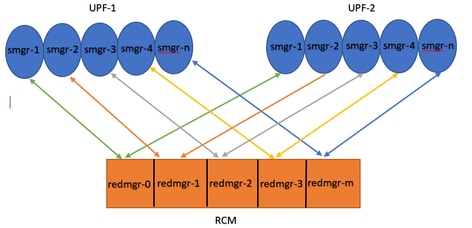
Note :: Redmgr IDs (m) = sessmgr instance ID (n-1)
For example :: smgr-1 is mapped with redmgr 0;smgr-2 is mapped with redmgr-1,
smgr-n is mapped with redmgr(m) = (n-1)
This is important to understand proper IDs of redmgr because we need to have proper logs to be checked
Registros necessários
Registros RCM - Saídas de comando:
rcm show-statistics checkpointmgr-endpointstats
RCM controller and checkpointmgr logs (refer this link)
Log collection
UPF:
Command outputs (hidden mode)
show rcm checkpoint statistics verbose
show session subsystem facility sessmgr all debug-info | grep Mode
If you see any sessmgr in server state check the sessmgr instance IDs and no of sessmgr
show task resources facility sessmgr all
Troubleshooting
Normalmente, há 21 instâncias do sessmgr no UPF, consistindo em 20 sessmgs ativos e uma instância em espera (embora essa contagem possa variar com base no design específico).
Exemplo:
- Para identificar os sessmgrs inativos, você pode usar este comando:
show task resources facility sessmgr all
-
Neste cenário, tentar resolver o problema reiniciando os sessmgrs problemáticos e até mesmo reiniciando sessctrl não leva à restauração dos sessmgrs afetados.
-
Além disso, observa-se que os sessmgrs afetados estão presos no modo de servidor em vez do modo de cliente esperado, uma condição que pode ser verificada usando os comandos fornecidos.
show rcm checkpoint statistics verbose
show rcm checkpoint statistics verbose
Tuesday August 29 16:27:53 IST 2023
smgr state peer recovery pre-alloc chk-point rcvd chk-point sent
inst conn records calls full micro full micro
---- ------- ----- ------- -------- ----- ----- ----- ----
1 Actv Ready 0 0 0 0 61784891 1041542505
2 Actv Ready 0 0 0 0 61593942 1047914230
3 Actv Ready 0 0 0 0 61471304 1031512458
4 Actv Ready 0 0 0 0 57745529 343772730
5 Actv Ready 0 0 0 0 57665041 356249384
6 Actv Ready 0 0 0 0 57722829 353213059
7 Actv Ready 0 0 0 0 61992022 1044821794
8 Actv Ready 0 0 0 0 61463665 1043128178
Here in above command all the connection can be seen as Actv Ready state which is required
show session subsystem facility sessmgr all debug-info | grep Mode
[local]
# show session subsystem facility sessmgr all debug-info | grep Mode
Tuesday August 29 16:28:56 IST 2023
Mode: UNKNOWN State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Aqui, todos os sessmgrs devem, de preferência, estar no modo cliente. No entanto, nesse problema, eles estão no modo de servidor, o que os impede de lidar com o tráfego.
Sessmgr Entrando no Modo de Servidor
-
Para facilitar a comunicação e a transferência de pontos de verificação, cada gerenciador de sessão (sessmgr) estabelece uma conexão de par TCP com o gerenciador de redundância correspondente (redmgr).
-
Quando a conexão do peer TCP é estabelecida, o redmgr pode fazer o checkpoint de todos os contextos do assinante do sessmgr e salvá-los. Isso permite uma comutação perfeita, pois os pontos de verificação podem ser transferidos para outras UPFs (User Plane Functions) com suas respectivas instâncias do sessmgr.
-
É crucial que o sessmgr esteja sempre no modo CLIENTE. Se, por algum motivo, o sessmgr for detectado no modo de servidor, ele indicará uma conexão TCP peer interrompida com o redmgr associado. Neste cenário, o ponto de verificação não ocorrerá.
-
Quando os sessmgr ficam presos nesse estado dentro da UPF, a execução de um switchover não planejado para outra UPF sem considerar o estado do sessmgr resulta no mesmo problema. O sessmgr não consegue lidar com o tráfego nessa situação.

Note: Há alguns problemas em que o próprio checkpoint mgr está aguardando o ponto de verificação em que o RCM iniciou o ponto de verificação e está aguardando a resposta do UPF. Mas quando não há resposta, o próprio checkpointmgr não consegue se comunicar, o que leva a um atraso na conclusão do procedimento de switchover que atravessa o valor do temporizador de switchover. Nesses casos, o UP fica preso no estado PendActive.
Isso pode ser verificado nas estatísticas do RCM e nos logs do redmgr. Além disso, com esse comando, você pode saber qual checkpointmgr tem um problema com qual UPF.
rcm show-statistics checkpointmgr-endpointstats
4. Pode haver vários motivos para o sessmgr entrar no modo de servidor localmente, mas um dos principais motivos para isso é como explicado aqui.
Motivo para o Sessmgr Entrar no Modo de Servidor
1. Com base no número de gerenciadores de sessão no User Plane Function (UPF), as réplicas são criadas para o Redundancy Manager (redmgr) e configuradas no Resource Control Manager (RCM). Essa configuração garante que cada redmgr esteja conectado a uma instância do gerenciador de sessões.
2. Se houver um mapeamento 1:1 entre o redmgr e o sessmgr, o que ocorre quando o ID da instância do gerenciador de sessões ultrapassa um valor superior ao número de gerenciadores de sessões?
For example :::
Sessmgr instance ID :: 1 to 20
Redmgr IDs :: 0 to 19
In this example somehow if my sessmgr instance ID goes beyond the mentioned limit i.e say 21/22/23/24/25 so in this case redmgr is already mapped with instance IDs 0 to 19 and would be unaware about this new sessmgr instance ID created by UPF from 21 to 25 and in such a case sessmgr with this instance IDs :: 21/22/23/24/25 will not be able to form any TCP peer connection with RCM redmgr leading to no checkpoint sync and since there won’t be any checkpoint sync sessmgr will get stuck into server mode and won’t take any traffic.
Refer this diagram
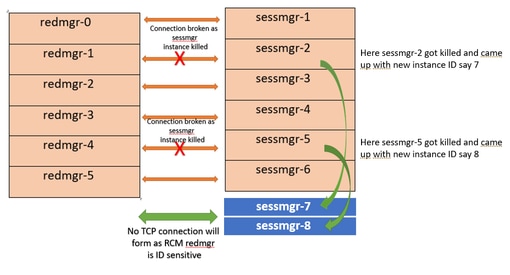
Both this sessmgr instance-7/8 have no TCP peer connection since for RCM redmgr-1 was
connected with instance-2 and redmgr-2 was connected to instance-5 so even though sessmgr
came up with new instance ID value which is beyond defined limit it wont have connection
back with redmgrs which is still just pointing to previous instance but connection is broken
Solução
A solução para esse problema é limitar o número de IDs de instância do sessmgr para corresponder ao número de sessmgrs em UPF e o número de redmgrs em RCM, conforme especificado pelo comando mencionado.
Max value of sessmgr instance ID = no of checkpointmgr – 1
De acordo com essa lógica, o número de sessmgrs precisa ser definido, incluindo sessmgrs em espera.
task facility sessmgr max <no of max sessmgrs>
Note :: Implementation of this command needs node reload to enable full functionality of this command
Ao executar esse comando, independentemente de quantas vezes o sessmgr está sendo eliminado, ele sempre apresenta um valor de ID de instância igual ou menor que a contagem máxima do sessmgr. Isso ajuda a evitar problemas de ponto de verificação com o RCM e impede que o sessmgr entre no modo de servidor por esse motivo.
 Feedback
Feedback