基线流程最佳实践白皮书
目录
简介
本文档介绍高可用性网络的基线建立概念和过程。它包括网络基线化和阈值化的关键成功因素,可帮助评估成功情况。它还提供了根据思科高可用性服务(HAS)团队确定的最佳实践指南实施的基准和阈值流程以及实施的重要详细信息。
本文档将逐步介绍基线建立过程。某些当前的网络管理系统(NMS)产品可帮助实现此过程的自动化,但是,无论您使用自动化工具还是手动工具,基线建立过程都保持不变。如果使用这些NMS产品,则必须调整唯一网络环境的默认阈值设置。必须有一个智能选择这些阈值的流程,以便它们有意义且正确。
基线
什么是基线?
基线是一个过程,用于定期研究网络以确保网络的工作情况符合设计意图。它远非记录特定时间点的网络健康状态的一个报告那么简单。通过执行基线流程,您可以获得以下信息:
-
获取有关硬件和软件运行状况的宝贵信息
-
确定网络资源的当前利用率
-
对网络警报阈值做出准确决策
-
确定当前的网络问题
-
预测未来问题
下图说明了另一种查看基线的方法。

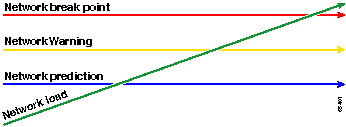
红线,即网络中断点,是网络中断的点,这取决于硬件和软件如何运行的知识。绿线(即网络负载)是指随着新应用的添加和其他此类因素而自然产生的网络负载。
基线的目的是确定:
-
您的网络处于绿色线上
-
网络负载增加速度
-
希望预测两者在哪个时间点交叉
通过定期执行基线,您可以了解当前状态,并推断出故障何时发生并提前做好准备。这还有助于您更明智地决定何时、何地以及如何将预算资金用于网络升级。
为什么要使用基线?
基线流程可帮助您确定网络中的关键资源限制问题并对其进行适当规划。这些问题可描述为控制平面资源或数据平面资源。控制平面资源对于设备内的特定平台和模块来说是唯一的,并且可能受到许多问题的影响,包括:
-
数据利用率
-
启用的功能
-
网络设计
控制平面资源包括以下参数:
-
CPU 利用率
-
内存利用率
-
缓冲区利用率
数据平面资源仅受流量的类型和数量影响,包括链路利用率和背板利用率。通过为关键区域设置资源利用率基准,可以避免严重的性能问题,甚至避免网络崩溃。
随着延迟敏感型应用(如语音和视频)的推出,基线建立现在变得比以往任何时候都重要。传统的传输控制协议/互联网协议(TCP/IP)应用可以容忍一定的延迟。语音和视频是基于用户数据报协议(UDP),不允许重新传输或网络拥塞。
由于应用的新组合,基线化可帮助您了解控制平面和数据平面资源利用率问题,并主动规划更改和升级,以确保持续成功。
数据网络已经存在很多年了。直到最近,保持网络运行一直是一个相当可原谅的过程,其中不乏出错的余地。随着IP语音(VoIP)等延迟敏感型应用日益被接受,网络运行工作变得越来越困难,对精度的要求也越来越高。为了更加准确并为网络管理员提供管理网络的坚实基础,了解网络的运行方式非常重要。为此,您必须完成一个称为基线的过程。
基准目标
基线的目标是:
-
确定网络设备的当前状态
-
将该状态与标准性能准则进行比较
-
设置阈值,以便在状态超过这些准则时发出警报
由于需要大量数据以及分析数据所花费的时间,您必须首先限制基线的范围,以便更轻松地了解该过程。从网络核心处着手,这是最符合逻辑、有时也是最有益的地方。网络的这一部分通常是最小的,而且需要最大的稳定性。
为简单起见,本文档介绍如何对一个非常重要的简单网络管理协议管理信息库(SNMP MIB)进行基线:cpmCPUTotal5min.cpmCPUTotal5min是思科路由器的中央处理器(CPU)的五分钟衰减平均值,是控制平面性能指标。基线将在Cisco 7000系列路由器上执行。
学习该过程后,您可以将其应用到大量SNMP数据库中可用的任何数据,大多数思科设备都可以使用这些数据,例如:
-
综合业务数字网络(ISDN)使用情况
-
异步传输模式(ATM)信元丢失
-
可用系统内存
核心基线流程图
以下流程图显示了核心基线流程的基本步骤。虽然有些产品和工具可用于执行这些步骤,但它们往往缺乏灵活性或易用性。即使您计划使用网络管理系统(NMS)工具执行基线建立,这仍是研究该过程和了解网络实际工作原理的良好练习。此过程可能还会消除一些NMS工具工作方式的一些神秘之处,因为大多数工具基本上都执行相同的操作。
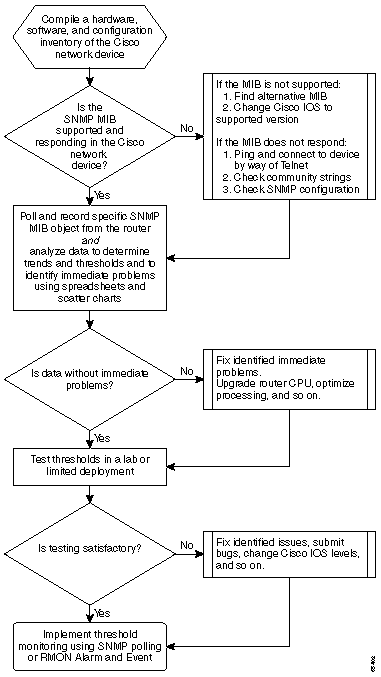
基准程序
步骤 1:编制硬件、软件和配置清单
出于几个原因,编制硬件、软件和配置的清单极其重要。首先,在某些情况下,Cisco SNMP MIB特定于您运行的Cisco IOS版本。有些MIB对象被替换为新对象,或者有时被完全删除。收集数据后硬件资产是最重要的,因为在初始基线之后需要设置的阈值通常基于Cisco设备上的CPU类型、内存量等。配置清单对于确保您了解当前配置也很重要:您可能希望在基线后更改设备配置,以调整缓冲区,等等。
对思科网络来说,这部分基准的最有效方法是使用CiscoWorks2000 Resource Manager Essentials(Essentials)。 如果在网络中正确安装了此软件,则Essentials应在其数据库中列出所有设备的当前清单。您只需查看库存,看看是否存在任何问题。
下表是从Essentials导出,然后在Microsoft Excel中编辑的Cisco路由器类软件清单报告的示例。请注意,您必须使用在12.0x和12.1x Cisco IOS版本中找到的SNMP MIB数据和对象标识符(OID)。
| 设备名 | 路由器类型 | version | 软件版本 |
|---|---|---|---|
| field-2500a.embu-mlab.cisco.com | Cisco 2511 | M | 12.1(1) |
| qdm-7200.embu-mlab.cisco.com | Cisco 7204 | B | 12.1(1)E |
| voip-3640.embu-mlab.cisco.com | Cisco 3640 | 0x00 | 12.0(3c) |
| wan-1700a.embu-mlab.cisco.com | Cisco 1720 | 0x101 | 12.1(4) |
| wan-2500a.embu-mlab.cisco.com | Cisco 2514 | L | 12.0(1) |
| wan-3600a.embu-mlab.cisco.com | Cisco 3640 | 0x00 | 12.1(3) |
| wan-7200a.embu-mlab.cisco.com | Cisco 7204 | B | 12.1(1)E |
| 172.16.71.80 | Cisco 7204 | B | 12.0(5T) |
如果网络中未安装Essentials,则可以从UNIX工作站使用UNIX命令行工具snmpwalk查找IOS版本。如下例所示。如果您不确定此命令如何工作,请在UNIX提示符下键入man snmpwalk以获取详细信息。当您开始选择要基线的MIB OID时,IOS版本非常重要,因为MIB对象与IOS相关。另请注意,通过了解路由器类型,您以后可以确定CPU、缓冲区等应具有哪些阈值。
nsahpov6% snmpwalk -v1 -c private 172.16.71.80 system system.sysDescr.0 : DISPLAY STRING- (ascii): Cisco Internetwork Operating System Software IOS (tm) 7200 Software (C7200-JS-M), Version 12.0(5)T, RELEASE SOFTWARE (fc1) Copyright (c) 1986-2001 by cisco Systems, Inc. Compiled Fri 23-Jul-2001 23:02 by kpma system.sysObjectID.0 : OBJECT IDENTIFIER: .iso.org.dod.internet.private.enterprises.cisco.ciscoProducts.cisco7204
步骤 2:验证路由器是否支持SNMP MIB
现在您已经拥有要轮询基准设备的清单,您可以开始选择要轮询的特定OID。如果您提前确认您想要的数据确实存在,这可以消除很多疑虑。cpmCPUTotal5min MIB对象位于CISCO-PROCESS-MIB中。
要查找要轮询的OID,需要思科CCO网站上提供的转换表。要从Web浏览器访问此网站,请转到Cisco MIBs页面,然后单击OID链接。
要从FTP服务器访问此网站,请键入ftp://ftp.cisco.com/pub/mibs/oid/。您可以从此站点下载已解码并按OID编号排序的特定MIB。
以下示例从CISCO-PROCESS-MIB.oid表中提取。本示例显示cpmCPUTotal5min MIB的OID为。1.3.6.1.4.1.9.9.109.1.1.1.1.5。
注意:不要忘记添加“”。 到OID的开头,否则尝试轮询它时将会出错。您还需要在OID的末尾添加“。1”以实例化它。这会告知设备您正在查找的OID的实例。在某些情况下,OID有多个特定类型的数据实例,例如路由器有多个CPU时。
ftp://ftp.cisco.com/pub/mibs/oid/CISCO-PROCESS-MIB.oid ### THIS FILE WAS GENERATED BY MIB2SCHEMA "org" "1.3" "dod" "1.3.6" "internet" "1.3.6.1" "directory" "1.3.6.1.1" "mgmt" "1.3.6.1.2" "experimental" "1.3.6.1.3" "private" "1.3.6.1.4" "enterprises" "1.3.6.1.4.1" "cisco" "1.3.6.1.4.1.9" "ciscoMgmt" "1.3.6.1.4.1.9.9" "ciscoProcessMIB" "1.3.6.1.4.1.9.9.109" "ciscoProcessMIBObjects" "1.3.6.1.4.1.9.9.109.1" "ciscoProcessMIBNotifications" "1.3.6.1.4.1.9.9.109.2" "ciscoProcessMIBConformance" "1.3.6.1.4.1.9.9.109.3" "cpmCPU" "1.3.6.1.4.1.9.9.109.1.1" "cpmProcess" "1.3.6.1.4.1.9.9.109.1.2" "cpmCPUTotalTable" "1.3.6.1.4.1.9.9.109.1.1.1" "cpmCPUTotalEntry" "1.3.6.1.4.1.9.9.109.1.1.1.1" "cpmCPUTotalIndex" "1.3.6.1.4.1.9.9.109.1.1.1.1.1" "cpmCPUTotalPhysicalIndex" "1.3.6.1.4.1.9.9.109.1.1.1.1.2" "cpmCPUTotal5sec" "1.3.6.1.4.1.9.9.109.1.1.1.1.3" "cpmCPUTotal1min" "1.3.6.1.4.1.9.9.109.1.1.1.1.4" "cpmCPUTotal5min" "1.3.6.1.4.1.9.9.109.1.1.1.1.5"
有两种常用方法可以轮询MIB OID,以确保其可用且正常运行。最好在开始批量数据收集之前执行此操作,这样您就不会浪费时间轮询某些不存在的内容,从而不会导致数据库为空。一种方法是使用来自NMS平台(如HP OpenView Network Node Manager(NNM)或CiscoWorks Windows)的MIB步行器,并输入要检查的OID。
以下是HP OpenView SNMP MIB walker的一个示例。
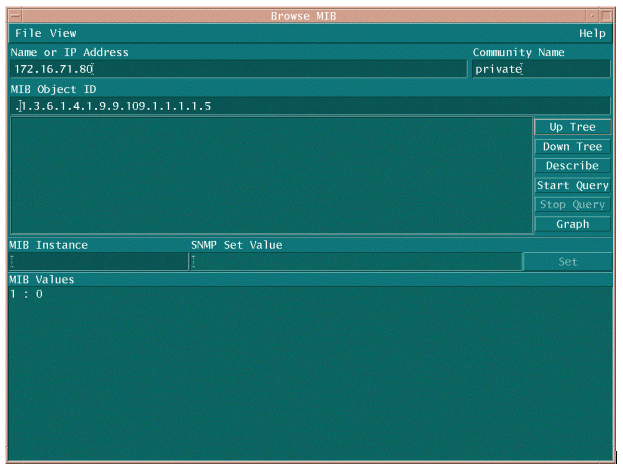
轮询MIB OID的另一种简单方法是使用UNIX命令snmpwalk,如下例所示。
nsahpov6% cd /opt/OV/bin nsahpov6% snmpwalk -v1 -c private 172.16.71.80 .1.3.6.1.4.1.9.9.109.1.1.1.1.5.1 cisco.ciscoMgmt.ciscoProcessMIB.ciscoProcessMIBObjects.cpmCPU.cpmCPUTotalTable.cpmCPUTotalEntry.cpmCPUTotal5min.1 : Gauge32: 0
在这两个示例中,MIB都返回值0,这意味着在该轮询周期中,CPU平均利用率为0%。如果难以让设备响应正确的数据,请尝试ping设备并通过Telnet访问设备。如果仍有问题,请检查SNMP配置和SNMP社区字符串。您可能需要找到备用MIB或IOS的其他版本才能实现此功能。
步骤 3:从路由器轮询并记录特定SNMP MIB对象
有多种方法可以轮询MIB对象并记录输出。现成产品、共享软件产品、脚本和供应商工具均可用。所有前端工具都使用SNMP get过程获取信息。主要区别在于配置的灵活性以及在数据库中记录数据的方式。再次查看处理器MIB,了解这些不同方法的工作原理。
既然您知道路由器支持OID,您需要决定轮询它的频率以及如何记录。Cisco建议以5分钟为间隔轮询CPU MIB。更低的间隔会增加网络或设备上的负载,而且,由于MIB值无论如何都是五分钟平均值,因此轮询它比平均值更频繁无用。通常也建议基线轮询至少有两个星期,以便您能够分析网络上至少两个星期的业务周期。
以下屏幕显示如何使用HP OpenView网络节点管理器6.1版添加MIB对象。从主屏幕中选择选项>数据收集与阈值。
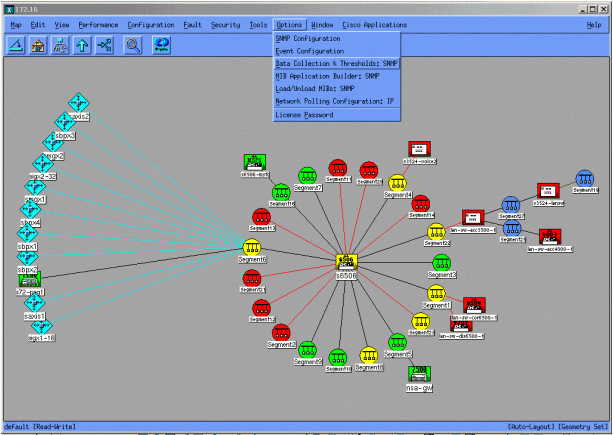
然后选择Edit > Add > MIB Objects。
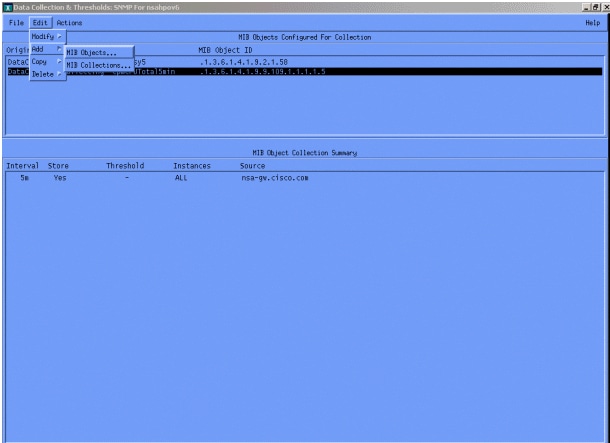
在菜单中,添加OID字符串,然后单击Apply。现在,您已经将MIB对象输入到HP OpenView平台,以便对其进行轮询。
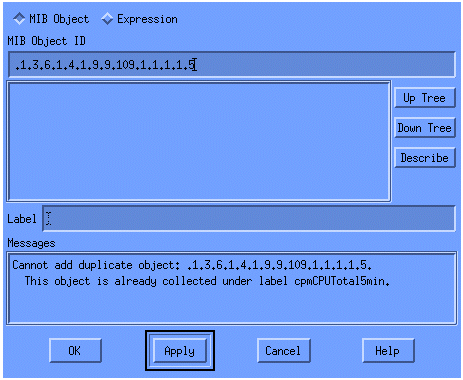
接下来,您必须让HP OpenView知道要为该OID轮询哪个路由器。
从Data Collection(数据收集)菜单中,选择Edit > Add > MIB Collections。
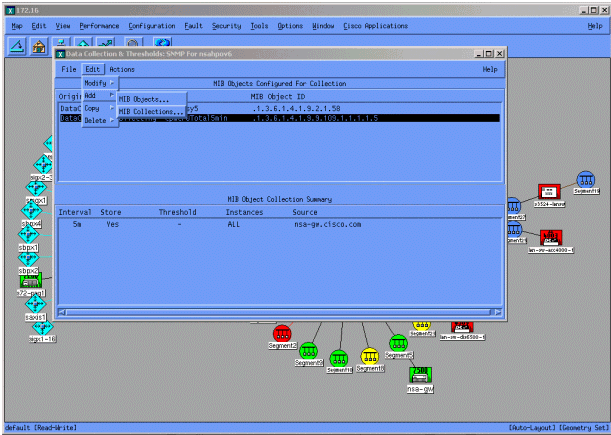
在Source字段中,输入要轮询的路由器的域名系统(DNS)名称或IP地址。
从Set Collection Mode列表中选择Store, No Thresholds。
将Polling Interval(轮询间隔)设置为5m,间隔为5分钟。
单击 Apply。
必须选择文件>保存才能使更改生效。
要验证集合是否设置正确,请突出显示路由器的集合摘要行,然后选择操作>测试SNMP。这将检查社区字符串是否正确并将轮询OID的所有实例。
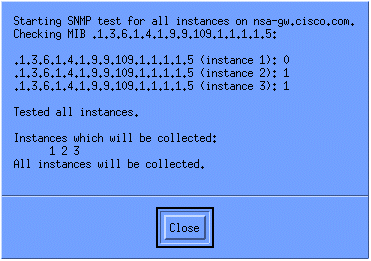
单击Close,让集合运行一周。在每周周期结束时,提取数据进行分析。
如果将数据转储到ASCII文件并将其导入电子表格工具(如Microsoft Excel),则更容易分析数据。要使用HP OpenView NNM执行此操作,您可以使用命令行工具snmpColDump。配置的每个集合都会写入/var/opt/OV/share/databases/snmpCollect/目录中的文件。
使用以下命令将数据提取到名为testfile的ASCII文件中:
snmpColDump /var/opt/OV/share/databases/snmpCollect/cpmCPUTotal5min.1 > testfile
注意:cpmCPUTotal5min.1是HP OpenView NNM在OID轮询开始时创建的数据库文件。
生成的测试文件类似于以下示例。
03/01/2001 14:09:10 nsa-gw.cisco.com 1 03/01/2001 14:14:10 nsa-gw.cisco.com 1 03/01/2001 14:19:10 nsa-gw.cisco.com 1 03/01/2001 14:24:10 nsa-gw.cisco.com 1 03/01/2001 14:29:10 nsa-gw.cisco.com 1 03/01/2001 14:34:10 nsa-gw.cisco.com 1 03/01/2001 14:39:10 nsa-gw.cisco.com 1 03/01/2001 14:44:10 nsa-gw.cisco.com 1 03/01/2001 14:49:10 nsa-gw.cisco.com 1 03/01/2001 14:54:10 nsa-gw.cisco.com 1 03/01/2001 14:59:10 nsa-gw.cisco.com 1 03/………
在UNIX工作站上输出测试文件后,可以使用文件传输协议(FTP)将其传输到PC。
您还可以使用自己的脚本收集数据。为此,请每五分钟对CPU OID执行snmpget,并将结果转储到.csv文件中。
步骤 4:分析数据以确定阈值
现在您拥有了一些数据,您可以开始分析它。基线的这一阶段确定您可以使用的准确性能或故障衡量指标的阈值设置,并且在启用阈值监视时不会引起太多警报。最简单的方法之一是将数据导入电子表格(如Microsoft Excel)并绘制散点图。这种方法可以非常轻松地查看特定设备创建异常警报的次数(如果监控它达到特定阈值)。不执行基线操作就打开阈值是不明智的,因为这可能从超过您所选阈值的设备创建警报风暴。
要将测试文件导入Excel电子表格,请打开Excel并选择文件>打开,然后选择数据文件。
然后,Excel应用程序会提示您导入文件。
完成后,导入的文件应类似于以下屏幕。
通过散点图,您可以更轻松地查看各种阈值设置在网络上的工作方式。
要创建散点图,请在导入的文件中突出显示C列,然后单击“图表向导”图标。然后按照图表向导中的步骤创建散点图。
在“图表向导”第1步中(如下所示),选择标准类型(Standard Types)选项卡,然后选择XY(散点图)类型。然后,单击下一步。
在“图表向导”第2步中(如下所示),选择数据范围选项卡,然后选择数据范围和列选项。单击 Next。
在“图表向导”第3步中(如下所示),输入图表标题以及X轴和Y轴值,然后单击下一步。
在“图表向导”第4步中,选择是希望散点图位于新页面上,还是希望散点图作为现有页面中的对象。
单击完成将图表放置在所需的位置。
“如果呢?” 分析
现在,您可以使用散点图进行分析。但是,在继续之前,您需要询问以下问题:
-
作为此MIB变量的阈值,供应商(在本例中供应商为Cisco)推荐什么?
一般来说,思科建议核心路由器的CPU平均利用率不超过60%。之所以选择60%,是因为路由器需要一些开销,以备遇到问题或网络出现故障时使用。思科估计核心路由器需要大约40%的CPU开销,以防路由协议必须重新计算或重新收敛。这些百分比取决于您使用的协议以及网络的拓扑和稳定性。
-
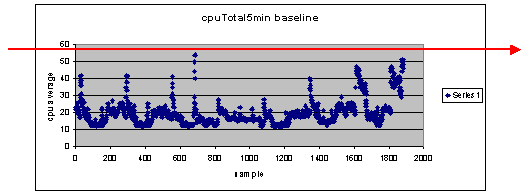
如果使用60%作为阈值设置呢?
如果您在散点图水平方向画一条线(60),您会发现没有任何数据点超过60%的CPU利用率。因此,在网络管理系统(NMS)站点上设置的阈值60不会在轮询期间触发阈值警报。此路由器可以接受百分比60。但是,请注意,在散点图中,有些数据点接近60。最好知道路由器何时接近60%的阈值,这样您就可以提前知道CPU接近60%的阈值,并规划在达到该阈值时如何操作。
-
如果我将阈值设置为50%会怎样?
估计此路由器在此轮询周期中四次达到50%的利用率,并且每次都会生成一个阈值警报。当您查看路由器组时,查看不同的阈值设置会执行什么操作时,此过程变得更为重要。例如,“如果我将整个核心网络的阈值设置为50%会怎样?” 要知道,仅仅选择一个数字是非常困难的。
CPU阈值“假设”分析
您可以用来简化这一流程的一个策略是“就绪”、“设置”、“执行”阈值方法。此方法连续使用三个阈值数字。
-
Ready — 您设置的阈值,用于预测哪些设备将来可能需要注意
-
Set — 用作早期指示器的阈值,用于警告您开始计划修复、重新配置或升级
-
Go — 您和/或供应商认为是故障情况的阈值,需要执行一些操作才能修复它;在本例中,它是60%
下表显示了“就绪”、“设置”、“执行”策略的策略。
| 阈值 | 操作 | 结果 |
|---|---|---|
| 45% | 进一步调查 | 行动计划选项列表 |
| 50% | 制定行动计划 | 行动计划中的步骤列表 |
| 60% | 实施行动计划 | 路由器不再超过阈值。返回就绪模式 |
“就绪”、“设置”、“执行”方法会更改前面讨论的原始基线图表。下图显示更改后的基线图。如果可以识别图表上的其他交点,现在您有更多的时间进行规划和反应。
请注意,在此过程中,注意重点是网络中的异常,而不是其他设备。我们假设只要设备低于阈值,它们就可以正常使用。
如果您从一开始就仔细考虑这些步骤,您将为保持网络正常运行做好充分的准备。执行此类计划对预算计划也非常有用。如果您知道您的前5个go路由器、中间set路由器以及底部ready路由器是什么,您可以根据路由器的类型以及您的行动计划选项轻松规划升级所需的预算。相同的策略可用于广域网(WAN)链路或任何其他MIB OID。
步骤 5:修复确定的即时问题
这是基线流程中比较容易的部分之一。确定哪些设备超过go阈值后,您应制定行动计划,将这些设备重新恢复到阈值之下。
您可以向思科技术支持中心(TAC)提交支持请求,或者联系您的系统工程师获取可用选项。你不应该想当然地认为,让一切回到正常水平需要花钱。通过更改配置以确保所有进程以最有效的方式运行,可以解决某些CPU问题。例如,某些访问控制列表(ACL)可能会使路由器CPU运行非常高,这是因为数据包通过路由器时采用的路径。在某些情况下,您可以实施NetFlow交换来更改数据包交换路径并减少ACL对CPU的影响。无论存在什么问题,都有必要在此步骤中将所有路由器恢复至阈值以下,这样您以后就可以实施阈值,而不会产生向NMS工作站充斥过多阈值警报的风险。
步骤 6:测试阈值监控
此步骤涉及使用将在生产网络中使用的工具测试实验室中的阈值。有两种常用方法来监控阈值。您必须确定哪种方法最适合您的网络。
-
使用SNMP平台或其他SNMP监控工具进行轮询和比较的方法
此方法使用更多的网络带宽来轮询流量,并占用您的SNMP平台上的处理周期。
-
在路由器中使用远程监控(RMON)警报和事件配置,以便只有在超过阈值时才会发送警报
此方法可以降低网络带宽使用率,但也会增加路由器上的内存和CPU使用率。
使用SNMP实施阈值
要使用HP OpenView NNM设置SNMP方法,请选择Options > Data Collection & Thresholds,就像设置初始轮询时一样。但是,这次,请在收集菜单中选择存储,检查阈值而不是存储,无阈值。设置阈值后,可以通过向路由器发送多个ping和/或多次SNMP遍历来提高路由器上的CPU利用率。如果不能强制CPU足够高以触发阈值,则可能需要降低阈值。无论如何,您应确保阈值机制正常工作。
使用此方法的局限性之一是不能同时实施多个阈值。您需要三个SNMP平台来设置三个不同的同时阈值。Concord Network Health![]()
![]() 和Trinagy TREND等工具允许同一OID实例有多个阈值。
和Trinagy TREND等工具允许同一OID实例有多个阈值。
如果您的系统一次只能处理一个阈值,则可以以串行方式考虑“就绪”、“设置”、“执行”策略。即,当持续达到ready阈值时,开始您的调查并将阈值提升到该设备的设置级别。持续达到设置级别后,开始制定您的行动计划,并将该设备的阈值提升到go级别。然后,当持续达到前进阈值时,实施您的行动计划。这应该与三同时阈值法一样有效。更改SNMP平台阈值设置只需要稍许时间。
使用RMON警报和事件实施阈值
使用RMON警报和事件配置,您可以让路由器监控自己的多个阈值。当路由器检测到超出阈值条件时,它会向SNMP平台发送SNMP陷阱。必须在路由器配置中设置SNMP陷阱接收器,才能转发陷阱。警报和事件之间存在关联。警报检查给定阈值的OID。如果达到阈值,警报进程将触发事件进程,该进程可以发送SNMP陷阱消息、创建RMON日志条目,或者同时发送这两者。有关此命令的详细信息,请参阅RMON警报和事件配置命令。
以下路由器配置命令使路由器每300秒监控一次cpmCPUTotal5min。如果CPU使用率超过60%,它将触发事件1;当CPU使用率回落到40%时,将触发事件2。在这两种情况下,SNMP陷阱消息都将使用社区专用字符串发送到NMS工作站。
要使用Ready、Set、Go方法,请使用以下所有配置语句。
rmon event 1 trap private description "cpu hit60%" owner jharp rmon event 2 trap private description "cpu recovered" owner jharp rmon alarm 10 cpmCPUTotalTable.1.5.1 300 absolute rising 60 1 falling 40 2 owner jharp rmon event 3 trap private description "cpu hit50%" owner jharp rmon event 4 trap private description "cpu recovered" owner jharp rmon alarm 20 cpmCPUTotalTable.1.5.1 300 absolute rising 50 3 falling 40 4 owner jharp rmon event 5 trap private description "cpu hit 45%" owner jharp rmon event 6 trap private description "cpu recovered" owner jharp rmon alarm 30 cpmCPUTotalTable.1.5.1 300 absolute rising 45 5 falling 40 6 owner jharp
以下示例显示上述语句配置的show rmon alarm命令的输出。
zack#sh rmon alarm Alarm 10 is active, owned by jharp Monitors cpmCPUTotalTable.1.5.1 every 300 second(s) Taking absolute samples, last value was 0 Rising threshold is 60, assigned to event 1 Falling threshold is 40, assigned to event 2 On startup enable rising or falling alarm Alarm 20 is active, owned by jharp Monitors cpmCPUTotalTable.1.5.1 every 300 second(s) Taking absolute samples, last value was 0 Rising threshold is 50, assigned to event 3 Falling threshold is 40, assigned to event 4 On startup enable rising or falling alarm Alarm 30 is active, owned by jharp Monitors cpmCPUTotalTable.1.5.1 every 300 second(s) Taking absolute samples, last value was 0 Rising threshold is 45, assigned to event 5 Falling threshold is 40, assigned to event 6 On startup enable rising or falling alarm
以下示例显示show rmon event命令的输出。
zack#sh rmon event Event 1 is active, owned by jharp Description is cpu hit60% Event firing causes trap to community private, last fired 00:00:00 Event 2 is active, owned by jharp Description is cpu recovered Event firing causes trap to community private, last fired 02:40:29 Event 3 is active, owned by jharp Description is cpu hit50% Event firing causes trap to community private, last fired 00:00:00 Event 4 is active, owned by jharp Description is cpu recovered Event firing causes trap to community private, last fired 00:00:00 Event 5 is active, owned by jharp Description is cpu hit 45% Event firing causes trap to community private, last fired 00:00:00 Event 6 is active, owned by jharp Description is cpu recovered Event firing causes trap to community private, last fired 02:45:47
您可能需要尝试这两种方法,以了解哪种方法最适合您的环境。您甚至可能会发现结合使用多种方法效果不错。无论如何,测试应该在实验室环境中进行,以确保一切正常。在实验室中进行测试后,您只需在一小组路由器上进行有限部署,即可测试向运营中心发送警报的过程。
在这种情况下,您必须降低阈值以测试该过程:建议不要尝试人为提高生产路由器的CPU。您还应确保当警报进入运营中心的NMS工作站时,有一个上报策略,以确保在设备超出阈值时通知您。这些配置已在使用Cisco IOS版本12.1(7)的实验室中进行了测试。 如果您遇到任何问题,应咨询思科工程或系统工程师,了解您的IOS版本中是否存在Bug。
步骤 7:使用SNMP或RMON实施阈值监控
在实验室和有限部署中全面测试阈值监控后,您就可以跨核心网络实施阈值了。现在,您可以系统性地完成网络上其他重要MIB变量的基线过程,例如缓冲区、可用内存、循环冗余校验(CRC)错误、AMT信元丢失等。
如果使用RMON警报和事件配置,现在您可以停止从NMS站进行轮询。这将减少NMS服务器上的负载并减少网络上的轮询数据量。通过系统地完成重要网络运行状况指标的此过程,您可以轻松达到网络设备使用RMON警报和事件监控自己的程度。
其它 MIB
学习此过程后,您可能希望调查要基线化和监视的其他MIB。以下小节提供了一些可能很有用的OID和说明的简要列表。
路由器 MIB
内存特性对于确定路由器的运行状况非常有用。正常运行的路由器几乎始终应该具有可用的缓冲空间。如果路由器开始耗尽缓冲空间,CPU将不得不更加努力地创建新的缓冲区,并尝试为传入和传出数据包找到缓冲区。有关缓冲区的深入讨论不在本文档的讨论范围之内。但是,一般情况下,正常的路由器应该只有很少的缓冲区丢失(如果有),并且不应有任何缓冲区故障或零可用内存条件。
| 对象 | 描述 | OID |
|---|---|---|
| ciscoMemoryPoolFree | 受管设备上当前未使用的内存池中的字节数 | 1.3.6.1.4.1.9.9.48.1.1.1.6 |
| ciscoMemoryPoolLargestFree | 内存池中当前未使用的连续字节的最大数量 | 1.3.6.1.4.1.9.9.48.1.1.1.7 |
| bufferElMiss | 缓冲区元素未命中数 | 1.3.6.1.4.1.9.2.1.12 |
| bufferFail | 缓冲区分配失败数 | 1.3.6.1.4.1.9.2.1.46 |
| bufferNoMem | 由于无可用内存而导致的缓冲区创建失败数 | 1.3.6.1.4.1.9.2.1.47 |
Catalyst 交换机 MIB
| 对象 | 描述 | OID |
|---|---|---|
| cpmCPUTotal5min | 过去五分钟内的整体CPU繁忙百分比。此对象从OLD-CISCO-SYSTEM-MIB中对avgBusy5对象进行降级 | 1.3.6.1.4.1.9.9.109.1.1.1.5 |
| cpmCPUTotal5sec | 过去五秒期间的整体CPU繁忙百分比。此对象从OLD-CISCO-SYSTEM-MIB中替代busyPer对象 | 1.3.6.1.4.1.9.9.109.1.1.1.3 |
| 系统流量 | 上一个轮询间隔的带宽利用率百分比 | 1.3.6.1.4.1.9.5.1.1.8 |
| sysTrafficPeak | 自上次清除端口计数器或系统启动以来的峰值流量计值 | 1.3.6.1.4.1.9.5.1.1.19 |
| sysTrafficPeaktime | 自峰值流量计量器值出现以来的时间(以百分之一秒为单位) | 1.3.6.1.4.1.9.5.1.1.20 |
| portTopNUtiilization | 系统中端口的利用率 | 1.3.6.1.4.1.9.5.1.20.2.1.4 |
| portTopNBufferOverFlow | 系统中端口的缓冲区溢出数量 | 1.3.6.1.4.1.9.5.1.20.2.1.10 |
串行链路 MIB
| 对象 | 描述 | OID |
|---|---|---|
| locIfInputQueueDrops | 由于输入队列已满而丢弃的数据包数 | 1.3.6.1.4.1.9.2.2.1.1.26 |
| locIfOutputQueueDrops | 由于输出队列已满而丢弃的数据包数 | 1.3.6.1.4.1.9.2.2.1.1.27 |
| locIfInCRC | 出现循环冗余校验和错误的输入数据包的数量 | 1.3.6.1.4.1.9.2.2.1.1.12 |
RMON 报警和事件配置命令
警报
可以使用以下语法配置RMON警报:
rmon alarm number variable interval {delta | absolute} rising-threshold value [event-number] falling-threshold value [event-number] [owner string]
| 元素 | 描述 |
|---|---|
| 号码 | 警报编号,与RMON MIB中alarmTable中的alarmIndex相同。 |
| 变量 | 要监控的MIB对象,转换为RMON MIB的alarmTable中使用的alarmVariable。 |
| 间隔 | 警报监控MIB变量的时间(以秒为单位),与RMON MIB的alarmTable中使用的alarmInterval相同。 |
| 增量 | 测试MIB变量之间的更改,这会影响RMON MIB的alarmTable中的alarmSampleType。 |
| 绝对 | 直接测试每个MIB变量,这会影响RMON MIB的alarmTable中的alarmSampleType。 |
| 上升阈值 | 触发警报的值。 |
| 事件编号 | (可选)当上升或下降阈值超过其限制时要触发的事件编号。该值与RMON MIB的alarmTable中的alarmRisingEventIndex或alarmFallingEventIndex相同。 |
| 下降阈值 | 警报重置时的值。 |
| 所有者字符串 | (可选)指定警报的所有者,该所有者与RMON MIB的alarmTable中的alarmOwner相同。 |
事件
可以使用以下语法配置RMON事件:
rmon event number [log] [trap community] [description string] [owner string]
| 元素 | 描述 |
|---|---|
| 号码 | 分配的事件编号,与RMON MIB中eventTable中的eventIndex相同。 |
| 日志 | (可选)在触发事件时生成RMON日志条目,并将RMON MIB中的eventType设置为log或log-and-trap。 |
| 陷阱社区 | (可选)用于此陷阱的SNMP社区字符串。将此行的RMON MIB中的eventType设置配置为snmp-trap或log-and-trap。此值与RMON MIB中eventTable中的eventCommunityValue相同。 |
| 描述字符串 | (可选)指定事件的说明,该说明与RMON MIB的eventTable中的事件说明相同。 |
| 所有者字符串 | (可选)此事件的所有者,与RMON MIB的eventTable中的eventOwner相同。 |
RMON 警报和事件实现
有关RMON警报和事件实施的详细信息,请阅读网络管理系统最佳实践白皮书的RMON警报和事件实施部分。
相关信息
修订历史记录
| 版本 | 发布日期 | 备注 |
|---|---|---|
1.0 |
03-Oct-2005 |
初始版本 |
 反馈
反馈