了解 DOCSIS 环境中的数据吞吐量
目录
简介
在尝试测量有线网络的性能之前,应该将一些限制因素纳入考虑范围。要设计并部署具有高可用性和高可靠性的网络,必须了解有线网络性能的基本原理和测量参数。本文档将介绍其中一些限制因素,然后讨论如何真正优化并限定您部署的系统的吞吐量和可用性。
先决条件
要求
本文档的读者应掌握以下这些主题的相关知识:
-
有线电缆数据服务接口规范 (DOCSIS)
-
无线电射频 (RF) 技术
-
思科 IOS® 软件命令行界面 (CLI)
使用的组件
本文档不限于特定的软件或硬件版本。
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您使用的是真实网络,请确保您已经了解所有命令的潜在影响。
规则
有关文件规则的更多信息请参见“ Cisco技术提示规则”。
背景信息
比特、字节和波特
此部分介绍位、字节与波特之间的区别。bit(位)这个词是BInary digiT(二进制数字)的缩写形式,通常以小写的 b 表示。二进制数字表示两种电子状态:状态“开”或状态“关”,有时也称为“1”或“0”。
字节以大写的 B 表示,其长度通常为 8 位。字节可以超过 8 位,因此可以将 8 个二进位的组合更精确地称为八位组。此外,一个字节中有两个半字节。半字节被定义为一个长度为 4 位的词,它是一个字节的一半。
比特率(或吞吐量)按每秒位数 (bps) 来测量,它与通过特定介质的信号的速度相关。例如,此信号可能是基带数字信号,也可能是经调整处理用于表示数字信号的调制模拟信号。
正交相移键控 (QPSK) 也是一种调制模拟信号。 这是一种调制技术,它将信号的相位操纵90度,以创建四个不同的签名,如图1所示。这些签名称为符号,其速率称为波特率。波特相当于每秒符号数。
图 1 - QPSK 示意图 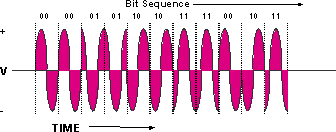
QPSK 信号有四个不同的符号;4等于22。该指数给出了可表示的每个周期(符号)的理论位数,在本例中为2。这四个符号代表二进制数00、01、10和11。因此,如果使用2.56 Msymbols/s的符号速率来传输QPSK载波,则它称为2.56 Mbaud,而理论比特率为2.56 Msymols/s × 2 bits/symbol = 5.12 Mbps。本文档的后续部分将对此做进一步介绍。
此外,您可能对每秒数据包数 (PPS) 这个词也比较熟悉。 这是一种根据数据包数量(不管数据包中包含的是 64 字节还是 1518 字节的以太帧)来限定设备吞吐量的方法。有时,网络的“瓶颈”在于 CPU 处理一定数量 PPS 的能力,而不一定在于总 bps。
什么是吞吐量?
数据吞吐量首先要计算最大理论吞吐量,然后计算有效吞吐量。一项服务可供用户使用的有效吞吐量总是小于最大理论值,而且前者才是您应该尝试计算的值。
吞吐量取决于许多因素:
-
用户总数
-
瓶颈速度
-
访问的服务类型
-
缓存和代理服务器使用情况
-
MAC 层效率
-
有线设备上的噪音和错误
-
许多其他因素
本文档旨在说明如何在 DOCSIS 环境中优化吞吐量和可用性,并解释影响性能的固有协议限制。如果您想测试或排除性能问题,请参阅在电缆调制解调器网络中排除性能不佳故障。有关上行 (US) 或下行 (DS) 端口上建议的最大用户数的准则,请参阅每个 CMTS 的最大用户数是多少?。
传统有线网络依靠轮询或载波侦听多路访问冲突检测 (CSMA/CD),将其作为 MAC 协议。如今的 DOCSIS 调制解调器则依靠预留方案,在该方案中,调制解调器请求传输时间而 CMTS 根据可用性授权时隙。系统会为电缆调制解调器分配一个已映射到服务类别 (CoS) 或服务质量 (QoS) 参数的服务 ID (SID)。
在具有突发性的时分多址 (TDMA) 网络中,如果要保证为所有发出请求的用户提供一定的接入速度,则必须限制可同时进行传输的电缆调制解调器 (CM) 总数。并发用户总数根据统计概率算法 - 泊松分布来计算。
流量工程是基于电话的网络中的一项统计数据,表示约 10% 的高峰使用率。此计算不在本文档说明范围之内。另一方面,数据流量与语音流量不同;当用户更精通计算机后,或者在 IP 语音 (VoIP) 和视频点播 (VoD) 服务的视频更容易获取之后,数据流量会发生变化。为简单起见,假设 50% 的高峰用户数 × 20% 的实际同时下载用户数,其结果也等于 10% 的高峰使用率。
所有并发用户争用 US 和 DS 接入。初始轮询时可以有许多调制解调器处于活动状态,但是在任意给定瞬间却只有一个调制解调器可在 US 方向处于活动状态。这在噪音影响方面是好事,因为某一时间只有一个调制解调器的噪音能够计入整体影响中。
当前标准的固有限制是,当有许多调制解调器与一个电缆调制解调器终端系统 (CMTS) 关联时,需要将一些吞吐量用于维护和调配。 这些吞吐量要从活动客户的实际负载中扣除。这称为保持连接轮询,在 DOCSIS 环境中通常每 20 秒发生一次,但也可能更加频繁。此外,正如本文档后续部分所述,每个调制解调器的 US 速度可以通过请求和授权机制加以限制。
注意: 请注意,对文件大小的引用以由 8 个位组成的字节为单位。因此,128 kbps 等于 16 KBps。同样,1 MB实际上等于1,048,576字节,而不是100万字节,因为二进制数总是产生一个2的幂的数字。5 MB的文件实际上是5 × 8 × 1,048,576 = 41.94 Mb,下载时间可能比预期长。
吞吐量计算
假设某个 CMTS 卡使用一个 DS 端口和六个 US 端口。这一个 DS 端口被拆分,用于为大约 12 个节点馈送流量。此网络的一半如图 2 所示。
图 2 - 网络布局 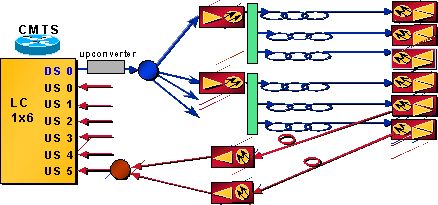
-
每个节点 500 户 × 80% 的有线线路占用率 × 20% 的调制解调器占用率 = 每个节点 80 个调制解调器
-
12 个节点 × 每个节点 80 个调制解调器 = 每个 DS 端口 960 个调制解调器
注意:许多多个服务运营商(MSO)现在将其系统量化为每个节点的家庭通过(HHP)。在如今的架构中,直播卫星 (DBS) 用户可能会购买高速数据 (HSD) 服务,也可能只购买电话服务而不含视频服务,而 HHP 是这种架构中的唯一常量。
注意:来自每个节点的US信号可能会以2:1的比率组合,以便两个节点向一个US端口馈送。
-
6 个 US 端口 × 每个 US 端口 2 个节点 = 12 个节点
-
每个节点 80 个调制解调器 × 每个 US 端口 2 个节点 = 每个 US 端口 160 个调制解调器。
下行
DS 符号速率 = 5.057 Msymbols/s 或 Mbaud。滤波器滚降系数 (α) 约为 18%,可得出 5.057 × (1 + 0.18) = ~6 MHz 宽的“占有带宽”,如图 3 所示。
图 3 - 数字“占有带宽” 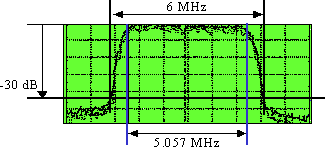
如果使用 64-QAM,则 64 = 2 的 6 次幂 (26)。 指数为 6 意味着 64-QAM 的每个符号为 6 位;因此得出 5.057 × 6 = 30.3 Mbps。计算全部前向纠错 (FEC) 和运动图像专家组 (MPEG) 开销后,这会为负载留下大约 28 Mbps。此负载会进一步减少,因为还要与 DOCSIS 信令共享此负载。
注意:ITU-J.83 Annex B使用128/122代码表示Reed-Solomon FEC,这意味着每128个符号有6个开销符号,因此6 / 128 = 4.7%。格码的开销为每 15 个字节 1 个字节 (64-QAM) 和每 20 个字节 1 个字节 (256-QAM),分别占 6.7% 和 5%。MPEG-2 由 188 字节的数据包组成,其中有 4 个字节的开销(有时为 5 个字节),可得出 4.5/188 = 2.4%。因此,您会看到列出的速度是 64-QAM 为 27 Mbps,256-QAM 为 38 Mbps。请注意,以太网数据包还有 18 个字节的开销,无论是 1500 字节的数据包还是 46 字节的数据包都是如此。此外还有 6 个字节的 DOCSIS 开销和 IP 开销,总计约 1.1% 到 2.8 % 的额外开销,而且 DOCSIS MAP 流量可能还会增加另外 2% 的开销。实际测得的 64-QAM 速度已接近 26 Mbps。
在全部 960 个调制解调器完全同步下载数据这种几乎不太可能出现的情况下,每个调制解调器只能达到大约 28 kbps 的速度。如果考虑一个更现实些的场景,假设高峰使用率为 10%,则可得出最繁忙时段最坏场景下的理论吞吐量为 280 kbps。如果只有一个客户在线,该客户理论上将达到 26 Mbps 的速度;但是,TCP 必须传输的 US 确认消息限制了 DS 吞吐量,而其他瓶颈则变得比较明显(例如 PC 或网络接口卡 [NIC])。 实际上,有线网络服务提供商会将此速率限制为 1 或 2 Mbps,以免在更多用户注册时造成永远也达不到可用吞吐量的感觉。
上行
按 2 位/符号计算,QPSK 的 DOCSIS US 调制可提供约 2.56 Mbps 的速度。其计算方法为:1.28 Msymbols/s 的符号速率 × 2 位/符号。滤波器 α 系数为 25%,可得出带宽 (BW) 为 1.28 × (1 + 0.25) = 1.6 MHz。如果使用了 FEC,则减去约 8%。还有大约 5% 到 10% 的开销用于维护、为争用保留的时隙和确认消息(“确认”)。 因此,还剩大约 2.2 Mbps,此速度需要在每个 US 端口的 160 个潜在客户之间共享。
注意:DOCSIS层开销=每64字节到1518字节以太网帧6字节(如果使用VLAN标记,可能为1522字节)。 这还取决于最大数据突发大小和是否使用了串联或分段技术。
-
US FEC 是变量:~128/1518 或 ~12/64 = ~8% 或 ~18%。大约 10% 用于维护、为争用保留的时隙和确认消息。
-
BPI 安全或扩展报头 = 0 到 240 个字节(通常为 3 到 7 个字节)。
-
前导码 = 9 到 20 个字节。
-
保护时间 >= 5 个符号 = ~2 个字节。
假设高峰使用率为 10%,这可得出每个用户在最差情况下的负载为 2.2 Mbps/(160 × 0.1) = 137.5 kbps。对于典型的住宅数据使用情况(例如网络浏览),US 吞吐量可能并不需要与 DS 吞吐量一样多。此速度可能足以供住宅使用,但对商业服务部署却还不够。
限制因素
有大量限制因素会影响“实际”数据吞吐量。这些因素从请求和授权周期到 DS 交织不等。了解这些限制有助于达成期望和实现优化。
下行性能 - MAP
传输发送到调制解调器的 MAP 消息会减少 DS 吞吐量。在 DS 端口上发送时间 MAP,可以让调制解调器请求 US 传输时间。如果每 2 毫秒发送一次 MAP,就意味着 1/0.002 秒 = 500 MAP/秒。如果 MAP 占用 64 个字节,就等于 64 个字节 × 每字节 8 位 × 500 MAP/秒 = 256 kbps。如果 CMTS 机箱中的一台刀片服务器上有六个 US 端口和一个 DS 端口,这表示有 6 × 256000 bps = ~1.5 Mbps DS 吞吐量用于支持所有调制解调器的 MAP 消息。这假设MAP为64字节,实际每2毫秒发送一次。实际上,MAP大小可能稍大一些,具体取决于调制方案和使用的US带宽量。这样一来,开销很容易就会达到 3% 到 10%。此外,DS 信道中还会传输其他系统维护消息。这些消息也会增加开销;不过,其影响通常可以忽略不计。MAP 消息会给中央处理单元 (CPU) 和 DS 吞吐量性能增加负担,因为 CPU 需要跟踪所有 MAP。
当您将任何 TDMA 和标准码分多址 (S-CDMA) 信道放到同一个 US 端口上时,CMTS 必须为每个物理端口发送“双 MAP”。因此,DS MAP 带宽消耗会翻倍。这是 DOCSIS 2.0 规范的一部分,也是实现互通的要求。除此之外,US 信道描述消息和其他 US 控制消息也会翻倍。
上行性能 - DOCSIS 延迟
在 US 路径中,根据往返时间 (RTT)、MAP 的长度和 MAP 预见时间,CMTS 与 CM 之间的请求和授权周期至多只能间隔一个地利用 MAP。这是因为 RTT 受到三个因素的影响:DS 交织;DOCSIS 在任何给定时间只允许调制解调器有一个未处理请求这一事实;以及与该请求相关联的“请求到授权延迟”。此延迟是由 CM 与 CMTS 之间的通信造成的,与协议相关。简而言之,CM 必须先请求 CMTS 准许发送数据。CMTS 必须为这些请求提供服务,检查 MAP 调度程序的可用性,并将其放到队列中等候下一个单播传输机会。作为 DOCSIS 协议的强制性要求,这种来回通信会生成此类延迟。调制解调器可能会错过间隔一个的 MAP,因为它正在等待 DS 方向返回上次请求的授权。
2 毫秒的 MAP 间隔会导致每秒 500 个 MAP/2 = 每秒 ~250 个 MAP 机会,因此 PPS 为 250。500 个 MAP 要除以 2,因为在“实际”设备中,请求与授权之间的 RTT 远远大于 2 毫秒。它可能超过 4 毫秒,因此 MAP 机会是间隔一个地出现。如果以 250 的 PPS 发送由 1518 字节以太帧组成的典型数据包,由于每字节有 8 位,则结果约等于 3 Mbps。这是对一个调制解调器的 US 吞吐量的实际限制。假设 PPS 限制为 250 左右,如果数据包很小(64 个字节),结果会怎么样?届时速度只有 128 kbps。串联技术可在此发挥作用;请参阅本文档的串联和分段技术的作用部分。
根据 US 信道使用的符号速率和调制方案,发送一个 1518 字节的数据包可能需要 5 毫秒以上。如果发送数据包到 CMTS 的时间超过 5 毫秒,CM 就会错过 DS 方向大约三个 MAP 机会。现在,PPS 只有 165 个左右。如果缩短 MAP 时间,MAP 消息的数量可能会增加,但代价是 DS 开销也会增加。MAP 消息增加将为 US 传输提供更多机会,但在真正的混合同轴光纤 (HFC) 设备中,无论如何您仍然只会错过更多机会。
值得庆幸的是,DOCSIS 1.1 添加了主动授权服务 (UGS),让语音流量得以避开此请求和授权周期。而语音数据包每 10 或 20 毫秒调度一次,直至呼叫结束。
注意:当CM传输大块数据US(例如,20 MB文件)时,它将在数据包中携带带宽请求,而不是使用离散请求,但调制解调器仍必须执行请求和授权周期。通过携带带宽请求,就能在专门的时隙中随数据发送请求而不必争用时隙,从而消除冲突并避免请求损坏。
TCP 还是 UDP?
人们在测试吞吐量性能时常常会忽视一个问题,那就是实际使用的协议。实际使用的是 TCP 之类面向连接的协议还是用户数据报协议 (UDP) 这样的无连接协议?UDP 只负责发送信息而不关心收到的质量。这通常称为“尽力”传输。如果收到的某些位存在错误,您只能将就使用并继续接收后面的位。TFTP 是这种尽力而为协议的另一个例子。这是一种典型的实时音频或视频流协议。另一方面,TCP 则需要用确认消息来证明正确收到了发送的数据包。FTP 就是一个例子。如果网络得到良好维护,该协议的动态调整能力足以在连续发送较多数据包之后再请求确认。这称为“增加窗口大小”,是传输控制协议的标准组成部分。
注:关于TFTP,需要注意的一点是,尽管由于使用UDP,它使用的开销较少,但它通常使用步骤确认方法,这对吞吐量非常不利。这意味着永远不会有多个未处理的数据包。因此,它也就永远无法成为测试真正吞吐量的好办法。
此处的重点是,DS 流量将以更多确认消息的形式生成 US 流量。此外,如果 US 短暂中断导致丢弃 TCP 确认消息,则 TCP 流将变慢。在使用 UDP 时就不会发生这种情况。如果 US 路径断开,CM 最终将在约 30 秒后判定保持连接轮询失败,并重新开始扫描 DS。TCP 和 UDP 都能在短暂中断后来继续存活,因为 TCP 数据包会排队或丢失,而 DS UDP 流量会保留。
US 吞吐量也可以限制 DS 吞吐量。例如,如果 DS 流量经由同轴电缆或通过卫星传输,US 流量通过电话线路传输,则 28.8 kbps US 吞吐量可将 DS 吞吐量限制为低于 1.5 Mbps,即使其可能已经通告最大吞吐量为 10 Mbps。这是因为低速链路会增加确认 US 流的延迟,进而导致 TCP 降低 DS 流的速度。为帮助缓解此瓶颈问题,Telco Return 利用点对点协议 (PPP) 并大幅缩小了确认消息的大小。
在 DS 方向生成 MAP 会影响 US 方向的请求和授权周期。处理 TCP 流量时,确认消息也必须经历请求和授权周期。如果未在 US 方向串联确认消息,DS 可能受到严重阻碍。例如,“游戏玩家”可能会以 512 字节数据包在 DS 方向发送流量。如果 US 方向被限制为 234 PPS 而 DS 方向的每个确认消息有 2 个数据包,则结果等于 512 × 8 × 2 × 234 = 1.9 Mbps。
Windows 的 TCP/IP 协议栈
典型的 Windows 速率是下载速度 2.1 到 3 Mbps。UNIX 或 Linux 设备通常执行效果更佳,因为它们的 TCP/IP 协议栈已改进,无需每隔一个收到的 DS 数据包就发送一个确认消息。您可以验证 Windows TCP/IP 驱动程序内部是否存在性能限制。通常,此驱动程序在确认性能受到限制时表现不佳。您可以使用从网上下载的协议分析工具。这是一种旨在显示您的互联网连接参数的程序,参数是直接从您发送到服务器的 TCP 数据包中提取的。协议分析工具可以用作专门的 Web 服务器。不过,它不会提供不同网页;而是用同一个页面响应所有请求。它会根据您的请求方客户端的 TCP 设置修改值。然后,将控制权转移到进行实际分析并显示结果的 CGI 脚本。协议分析工具可以帮助您检查下载的数据包长度是否为 1518 个字节(DOCSIS 最大传输单位 [MTU]),并检查 US 确认消息的 PPS 是否接近 160 至 175。如果数据包低于这些速率,请更新 Windows 驱动程序并调整 UNIX 或 Windows NT 主机。
您可以更改注册表中的设置来调整 Windows 主机。首先,您可以增加 MTU。数据包大小称为 MTU,是网络上一个物理帧中可以传输的最大数据量。对以太网,MTU 为 1518 个字节;PPPoE 为 1492;而拨号连接通常为576。区别在于,当使用较大的数据包时,开销会更小,路由决策更少,而客户端的协议处理和设备中断更少。
每个传输单位都包括报头和实际数据。实际数据称为最大报文段长度 (MSS),用于定义可以传输的最大 TCP 数据段。基本上,MTU = MSS + TCP/IP 报头。因此,您可能需要将 MSS 调整为 1380,以反映每个数据包中的最大有用数据量。此外,您还可以在调整当前 MTU 和 MSS 设置后优化默认接收窗口 (RWIN):协议分析工具会建议最合适的值。协议分析工具还可以帮助您确保以下设置:
不同的网络协议可从 Windows 注册表中的不同网络设置中受益。电缆调制解调器的最佳 TCP 设置似乎与 Windows 中的默认设置不同。因此,每个操作系统有其特定的注册表优化方法信息。例如,Windows 98 及更高版本在 TCP/IP 协议栈方面做出了一些改进。这些新发展包括:
-
大窗口支持,如 RFC1323 中所述

-
选择性确认 (SACK) 支持
-
快速重传和快速恢复支持
适用于 Windows 95 的 WinSock 2 更新支持 TCP 大窗口和时间戳,这意味着如果您将原始的 Windows 套接字更新到版本 2,就可以使用 Windows 98 的建议设置。Windows NT 对 TCP/IP 的处理方式与 Windows 9x 稍有不同。请注意,如果应用 Windows NT 的小改进,其性能的增加不如在 Windows 9x 中,这只是因为 NT 面向网络进行了更好的优化。
但是,要更改 Windows 注册表,则需要对 Windows 自定义达到一定的熟练程度。如果您不能得心应手地编辑注册表,就需要从互联网下载“即时可用的”修补程序,它可以在注册表中自动设置最优值。要编辑注册表,您必须使用编辑器,例如 Regedit(依次选择开始 > 运行并在“打开”字段中选择类型 Regedit)。
提高性能的因素
吞吐量的确定
可能影响数据吞吐量的因素有许多:
-
用户总数
-
瓶颈速度
-
访问的服务类型
-
缓存服务器使用情况
-
MAC 层效率
-
有线设备上的噪音和错误
-
许多其他因素,例如 Windows TCP/IP 驱动程序内部的限制
共享“通道”的用户越多,服务速度就越慢。此外,瓶颈可能在于您访问的网站而不是您的网络。当您将使用的服务纳入考虑范围之内时,随着时间的推移,正常的邮件和网上冲浪效率也非常低。如果使用视频流,此类服务需要的时隙更多。
您可以使用代理服务器将一些经常下载的站点缓存到局域网中的计算机上,帮助缓解整个互联网上的流量。
虽然“预留和授权”是 DOCSIS 调制解调器的首选方案,对每个调制解调器的速度仍然存在限制。与用于轮询或纯 CSMA/CD 相比,此方案供住宅使用的效率要高得多。
提高接入速度
许多系统正在将每节点住户比从 1000 户降到 500 户降到 250 户再到无源光纤网络 (PON) 或光纤到户 (FTTH)。PON 如果设计正确,每个节点最多可在不连接有源设备的情况下通过 60 人。FTTH 在一些地区正在进行测试,但它对大多数用户而言仍然成本高昂,难以付诸使用。事实上,如果减少每个节点的住户数但仍在前端合并接收器,情况可能会更糟。两个光纤接收器不如一个光纤接收器,但是每根光纤连接的住户越少,就越不可能遇到来自入口的激光器削波。
最明显的分段技术是添加更多光纤设备。一些较新的设计将每个节点的住户数减少到 50 至 150 HHP。如果不管怎样仍要在前端 (HE) 重新合并接收器,则减少每个节点的住户数并没有任何好处。如果每个节点 500 户的两条光纤链路在前端合并,共享同一个 CMTS US 端口,这种情况实际上可能还不如使用每个节点 1000 户的一条光纤链路。
很多时候,即使有大量有源设备汇集,光纤链路也会发出噪音,限制性能。您必须对服务分段,而不仅仅是减少每个节点的住户数。减少每个 CMTS 端口或服务的住户数耗资更多,但它能特别缓解这种瓶颈。每个节点的住户数较少也有好的一面,那就是噪音和可能导致激光器削波的入口更少,而且以后对更少的 US 端口进行分段也更容易。
DOCSIS 已指定适用于 DS 和 US 的两种调制方案和应在 US 路径中使用的五种不同带宽。不同的符号速率分别为 0.16、0.32、0.64、1.28 和 2.56 Msymbols/s,并使用不同的调制方案,例如 QPSK 或 16-QAM。这样就可以对比正在使用的回传系统所需的稳健性,灵活选择所需的吞吐量。DOCSIS 2.0 甚至进一步提高了灵活性,本文档的后续部分将进行详述。
还有一种可能是跳频,该技术可以让“无法通信者”切换(跳)到不同的频率。此处做出的让步是必须分配更多带宽冗余,并且但愿“其他”频率在跳频前没有用户。有些制造商将其调制解调器设置为“跳频前查看”。
随着技术变得更加高级,人们会找到办法提高压缩效率,或者使用更高级的协议(功能更强大或占用的带宽更少)发送信息。这可能需要使用 DOCSIS 1.1 QoS 调配、负载报头抑制 (PHS) 或 DOCSIS 2.0 功能。
稳健性与吞吐量之间始终存在一种互相迁就的关系。您从网络中获得的速度通常与使用的带宽、分配的资源、抗干扰的稳健性或成本相关。
信道宽度和调制
由于前文介绍的 DOCSIS 延迟,US 吞吐量似乎被限制为 3 Mbps 左右。而且,您将 US 带宽增加到 3.2 MHz 还是将调制方案调整为 16-QAM(理论吞吐量为 10.24 Mbps)似乎也不重要。增加信道带宽和调制并不会显著提高每个调制解调器的传输速率,但却能让更多调制解调器使用信道进行传输。请注意,US 是基于 TDMA 的时隙争用介质,时隙由 CMTS 授权使用。增加信道带宽意味着增加 US bps,也就意味着可以支持更多调制解调器。因此,增加 US 信道带宽并非无关紧要的事情。此外,前文曾提到,1518 字节的数据包在 US 端口上只占用 1.2 毫秒的线路时间,有助于缩短 RTT 延迟。
您也可以将 DS 调制更改为 256-QAM,让 DS 方向的总吞吐量增加 40%,并缩短 US 性能的交织延迟。不过请注意,进行此更改时需要临时断开系统上的所有调制解调器。
 注意:在更改DS调制之前,应格外小心。您应该对 DS 频谱进行深入分析,以便验证您的系统是否支持 256-QAM 信号。如果不这样做,则可能严重降低有线网络性能。
注意:在更改DS调制之前,应格外小心。您应该对 DS 频谱进行深入分析,以便验证您的系统是否支持 256-QAM 信号。如果不这样做,则可能严重降低有线网络性能。
注意:发出电缆下行调制{64qam | 256qam}命令,将DS调制更改为256-QAM:
VXR(config)# interface cable 3/0 VXR(config-if)# cable downstream modulation 256qam
有关 US 调制配置文件和返回路径优化的详细信息,请参阅如何提高返回路径可用性和吞吐量。另请参阅在思科 CMTS 上配置电缆调制配置文件。在默认混合配置文件中,将 uw8 更改为 uw16 用于短和长间隔使用代码 (IUC)。
注意:在增加信道宽度或更改US调制之前,应格外小心。您应该使用频谱分析仪对 US 频谱进行深入分析,找到足够宽的频带,具有足以支持 16-QAM 的载噪比 (CNR)。如果不这样做,则可能严重降低有线网络性能或导致 US 完全中断。
注意:发出cable upstream channel-width命令以增加US信道宽度:
VXR(config-if)# cable upstream 0 channel-width 3200000
请参阅高级频谱管理。
交织作用
来自 DS 路径上的放大器电源和公用电源电噪声爆发会导致错误集中出现。这种情况引起的吞吐量质量问题可能比因为热噪声而扩散开的错误更严重。为了将突发错误的影响降到最低,人们使用一种称为交织的技术来慢慢地逐渐传播数据。由于符号在传输端混杂,然后在接收端重组,因此错误会分散出现。FEC 对付分散的错误非常有效。使用交织技术时,持续时间相对较长的突发干扰所导致的错误仍可通过 FEC 来纠正。由于大多数错误是突然爆发的,这是一种降低错误率的有效方式。
注意:如果增加FEC交织值,则会增加网络延迟。
DOCSIS 指定了五个不同的交织深度(EuroDOCSIS 只有一个)。128:1 是最深的交织,8:16 最浅。128:1 表示各由 128 个符号组成的 128 个代码字按一对一的基础混杂。8:16 表示每个代码字的 16 个符号排成一行,并与另外 7 个代码字中的 16 个符号混杂。
下行交织器延迟的值可能如下所示,单位为微秒(µs 或 uSec):
| I(抽头数) | J(增量) | 64-QAM | 256-QAM |
|---|---|---|---|
| 8 | 16 | 220 | 150 |
| 16 | 8 | 480 | 330 |
| 32 | 4 | 980 | 680 |
| 64 | 2 | 2000 | 1400 |
| 128 | 1 | 4000 | 2800 |
交织不会增加开销位,例如 FEC;但是,它会增加延迟,进而可能影响语音和实时视频。它还会增加请求和授权 RTT,这可能会导致间隔一个出现的 MAP 机会变成每隔两个或三个 MAP 出现一次。这是副效应,也正是这种效应可能导致 US 数据吞吐量峰值下降。因此,将该值设置为低于典型默认值 32 的数字时,可以略微增加 US 吞吐量(以每个调制解调器的 PPS 的方式)。
作为冲激噪声问题的解决方法,交织值可以增加到64或128。但是,当您增加此值时,性能(吞吐量)可能会降低,但DS中的噪声稳定性会提高。换言之,必须正确维护设备;否则,DS 路径中将出现更多无法纠正的错误(数据包丢失),直到调制解调器开始丢失连接并且重传现象增加。
增加交织深度来补偿噪音很大的 DS 路径时,必须考虑 CM US 吞吐量峰值下降的因素。在大多数住宅使用情况下,这并不是问题,但最好能了解其得失。如果选择最大深度,即 4 毫秒时的 128:1,将对 US 吞吐量造成显著的负面影响。
注意:64-QAM与256-QAM的延迟不同。
您可以发出 cable downstream interleave-depth {8 | 16 | 32 | 64 | 128}命令。以下是将交织深度减到 8 的示例:
VXR(config-if)# cable downstream interleave-depth 8
注意:实施此命令后,将断开系统上的所有调制解调器。
对于 US 对噪音的稳健性,DOCSIS 调制解调器允许使用变量或不使用 FEC。关闭 US FEC 时,可以免除一些开销并传递更多数据包,但是要以对噪音的稳健性为代价。将不同的 FEC 量与流量突发类型相关联也有好处。流量突发是为了实际数据还是为了站点维护?数据包是由 64 个字节组成还是由 1518 个字节组成?您可能需要为较大的数据包提供更多保护。还有一个收益递减的临界点;例如,FEC 从 7% 更改为 14% 可能只会将稳健性提高 0.5 dB。
US 方向目前尚无交织,因为其传输是突然爆发的,而突发的传输没有足以支持交织的延迟。有些芯片制造商准备在 DOCSIS 2.0 支持中添加此功能,如果考虑到来自家用电器的所有脉冲噪音,此功能可能会造成巨大的影响。US 交织可以提高 FEC 的工作效率。
动态预先映射
Dynamic Map Advance 在 MAP 中使用动态预见时间,可以显著提高每个调制解调器的 US 吞吐量。Dynamic Map Advance 是一种算法,它根据与特定 US 端口相关联的最远 CM 自动调整 MAP 中的预见时间。
请参阅Cable Map Advance(动态还是静态?),了解对 MAP Advance 的详细说明。
要知道 MAP Advance 是不是动态的,请发出 show controllers cable slot/port upstream port 命令:
Ninetail# show controllers cable 3/0 upstream 1 Cable3/0 Upstream 1 is up Frequency 25.008 MHz, Channel Width 1.600 MHz, QPSK Symbol Rate 1.280 Msps Spectrum Group is overridden BroadCom SNR_estimate for good packets - 28.6280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2809 Ranging Backoff automatic (Start 0, End 3) Ranging Insertion Interval automatic (60 ms) Tx Backoff Start 0, Tx Backoff End 4 Modulation Profile Group 1 Concatenation is enabled Fragmentation is enabled part_id=0x3137, rev_id=0x03, rev2_id=0xFF nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 8 Minislot Size in Symbols = 64 Bandwidth Requests = 0xE224 Piggyback Requests = 0x2A65 Invalid BW Requests= 0x6D Minislots Requested= 0x15735B Minislots Granted = 0x15735F Minislot Size in Bytes = 16 Map Advance (Dynamic) : 2454 usecs UCD Count = 568189 DES Ctrl Reg#0 = C000C043, Reg#1 = 17
如果如前所述选择交织深度 8,则可以进一步缩短 MAP Advance,因为它的 DS 延迟更短。
串联和分段技术的作用
DOCSIS 1.1 和目前的一些 1.0 设备支持称为串联的新功能。DOCSIS 1.1也支持分段。串联允许将多个较小的DOCSIS帧合并为一个较大的DOCSIS帧,并与一个请求一起发送。
由于请求的字节数最多有 255 个微时隙,并且每个微时隙通常有 8 或 16 个字节,所以一个 US 传输间隔内可以传输的最大字节数约为 2040 或 4080 个字节。此数量包括所有 FEC 和物理层开销。因此,以太帧的真正最大数据突发大小更接近该数量的 90%,并且与分段授权无关。如果以 2 个单位的微时隙在 3.2 MHz 带宽下使用 16-QAM,微时隙将为 16 个字节。由此可得出限制为 16 × 255 = 4080 个字节 - 10% 的物理层开销 = ~3672 个字节。要进行更多串联,可以将微时隙更改为 4 或 8 个单位并将最大串联突发设置为 8160 或 16,320。
有一点需要注意的是,曾经发送的最小数据突发为 32 或 64 个字节,而在按照微时隙大小裁剪数据包时,这种比较粗糙的粒度会出现更多舍入错误。
除非使用分段,否则对 VXR 机箱中的 MC28C 或 MC16x 卡,应将最大 US 数据突发设置为小于 4000 个字节。此外,如果进行 VoIP 传输,请将 DOCSIS 1.0 调制解调器的最大数据突发设置为 2000 个字节。这是因为 1.0 调制解调器无法进行分段,2000 字节太长,UGS 流无法正常传输,所以语音会出现抖动。
由此可见,虽然串联对大型数据包可能不太有用,但对所有短 TCP 确认消息却是非常理想的工具。如果每个传输机会可以传输多个数据包,那么传输几个数据包串联就能让基本 PPS 值增加几倍。
串联数据包时,比较大的数据包序列化时间更长,并会影响 RTT 和 PPS。因此,如果 1518 字节数据包的 PPS 正常为 250,那么当您进行串联时,它难免会下降;但是,现在每个串联数据包有更多的总字节数。如果您可以串联四个 1518 字节数据包,则在 3.2 MHz 带宽下使用 16-QAM 发送至少需要 3.9 毫秒。DS 交织和处理造成的延迟会另外加上去,并且 DS MAP 只能每 8 毫秒左右发送一个。PPS 降到 114,但现在您串联了 4 个数据包,似乎使 PPS 变成了 456;这样,吞吐量就是 456 × 8 × 1518 = 5.5 Mbps。我们以“游戏”为例,串联可以只用一个请求发送许多 US 确认消息,这会让 DS TCP 流变快。假设此 CM 的 DOCSIS 配置文件的最大 US 数据突发设置为 2000 个字节,同时假设调制解调器支持串联:CM 理论上可以串联三十一个 64 字节的确认消息。因为这个大型总数据包需要一些时间从 CM 传输到 CMTS,PPS 将相应减小。它将更接近大数据包的 92 PPS,而不是小数据包的 234 PPS。可能 92 PPS × 31 个确认消息 = 2852 PPS。这相当于约 512 字节的 DS 数据包 × 每字节 8 位 × 每个确认消息 2 个数据包 × 每秒 2852 个确认消息 = 23.3 Mbps。不过,大多数 CM 将受到速率限制,远远低于此值。
在 US 方向,CM 理论上有 512 字节 × 每字节 8 位 × 110 PPS × 3 个串联数据包 = 1.35 Mbps。这些数据比未串联时获得的原始数据要漂亮得多。但是,分段时的微时隙舍入问题甚至更严重,因为每一个分段都会舍入。
注意:有一个较旧的Broadcom问题,它不能连接两个数据包,但可以连接三个数据包。
要利用串联功能,您需要运行思科 IOS 软件版本 12.1(1)T 或 12.1(1)EC 或更高版本。请尽可能争取使用基于 Broadcom 3300 设计的调制解调器。要确保 CM 支持串联,请在 CMTS 上发出 show cable modem detail、show cable modem mac 或 show cable modem verbose 命令。
VXR# show cable modem detail Interface SID MAC address Max CPE Concatenation Rx SNR Cable6/1/U0 2 0002.fdfa.0a63 1 yes 33.26
要开启或关闭串联功能,请发出 [no] cable upstream n concatenation 命令,其中 n 用于指定 US 端口号。有效值从 0 开始,代表电缆接口线卡上的第一个 US 端口。
注意:有关DOCSIS 1.0与1.1以及最大突发大小设置的串联问题的详细信息,请参阅最大上游突发参数的历史记录。另请注意,必须重新启动调制解调器以使更改生效。
单个调制解调器速度
如果目标是串联大型帧并尽可能让每个调制解调器实现最高速度,您可以将微时隙更改为 32 个字节以允许 8160 的最大数据突发。此方法的缺陷在于,这意味着曾经发送的最小数据包为 32 个字节。对小型 US 数据包而言,例如对长度只有 16 个字节的请求,此方法的效率不是非常高。由于请求属于争用范畴之内,如果它变大,就会增加发生冲突的隐患。在按照微时隙大小切割数据包时,它还会增加更多微时隙舍入错误。
此调制解调器的 DOCSIS 配置文件需要将最大流量突发和最大串联突发设置为 6100 左右。这样就可以串联四个 1518 字节的帧。调制解调器还需要支持分段,以便将其分解成更易于管理的分段。由于下一个请求通常由数据包携带并包含在第一分段中,调制解调器的 PPS 速率甚至有可能超过预期。每个分段所需的序列化时间少于 CM 尝试发送一个长串联数据包时所需的序列化时间。
有几个设置可能会影响每个调制解调器的速度,必须加以说明。最大流量突发用于 1.0 CM,应设置为 1522。有些 CM 需要此设置大于 1600,因为它们包含其他不应包含的开销。最大串联突发会影响到同样能分段的 1.1 调制解调器,因此它们可以将许多帧与一个请求串联,但仍然会出于 VoIP 方面的考虑而分段为 2000 字节的数据包。您可能需要将最大流量突发和最大串联突发设置为彼此相等,否则某些 CM 就不会联机。
CMTS 中一个有可能产生影响的命令是 cable upstream n rate-limit token-bucket shaping 命令。此命令可以帮助那些无法进行自我管制的 CM,按照其配置文件设置中的指示对其进行管制。管制可能导致数据包延迟,因此,如果您怀疑此功能限制了吞吐量,请将其关闭。这可能与最大流量突发与最大串联突发设置相同有关,所以可能有必要进行更多测试。
Toshiba 在没有串联或分段的情况下也表现良好,因为它未在 CM 中使用 Broadcom 芯片集。它使用Libit,现在使用TI,CM高于PCX2200。Toshiba还在授权前发送下一个请求,以实现更高的PPS。除了请求并非由数据包携带而需要争用时隙这一事实之外,此方法效果不错;当同一个 US 端口上有许多 CM 时,PPS 可能会下降。
使用 cable default-phy-burst 命令,可以将 CMTS 从 DOCSIS 1.0 IOS 软件升级到 1.1 代码,且 CM 注册不会失败。通常,在 DOCSIS 配置文件中,最大流量突发的默认值为 0 或空,这会导致调制解调器在注册时遭到拒绝而失败。这是一个拒绝 CoS,因为 0 表示不受限制的最大数据突发,这是 1.1 代码不允许使用的设置(原因是 VoIP 服务和最大延迟、延迟和抖动)。 cable default-phy-burst 命令会覆盖 DOCSIS 配置文件设置 0,并以两个数字中较小者优先。默认设置为 2000,最大值现在是 8000,这样就可以串联五个 1518 字节的帧。可将其设置为 0 以将其关闭:
cable default-phy-burst 0
有关每个调制解调器速度测试的一些建议
-
在 US 方向的 6.4 MHz 信道上将高级时分多址 (A-TDMA) 用于 64-QAM。
-
使用2的微时隙大小。DOCSIS限制是每个突发255微时隙,因此每个微时隙255 × 48字节= 12240最大突发× 90% = ~11,000字节。
-
使用可以分段和串联并有全双工 FastEthernet 连接的 CM。
-
将 DOCSIS 配置文件设置为无最小值,但上行和下行最大值均为 20 MB。
-
关闭 US 速率限制令牌桶整形。
-
将最大流量突发和最大串联突发设置为 11000 个字节。
-
在 DS 方向使用 256-QAM 和交织深度 16(也试一下 8)。 这可以缩短 MAP 的延迟。
-
使用正确分片的IOS软件版本15(BC2)映像,并发出cable upstream n fragment-force 2000 5命令。
-
将 UDP 流量推送到 CM 并增加其数量,直至找到最大值。
-
如果您要推送 TCP 流量,请通过一个 CM 使用多台 PC。
结果
-
Terayon TJ735 的结果为 15.7 Mbps。这个速度可能是一个好结果,因为每个串联帧的字节数更少,CPU 使用率降低。似乎第一个帧是 13 字节串联报头,其后是 6 字节报头,还有 16 字节分段报头和内部 8200 字节最大数据突发。
-
Motorola SB5100 的结果为 18 Mbps。当 DS 方向上为 1418 字节数据包和交织深度 8 时,还可得出 19.7 Mbps 的结果。
-
Toshiba PCX2500 的结果为 8 Mbps,因为它似乎有 4000 个字节的内部最大数据突发限制。
-
Ambit 的结果与 Motorola 相同:18 Mbps。
-
在与其他 CM 流量争用的情况下,上述这些速率中部分可能会下降。
-
请确保 1.0 CM (无法分段)的最大数据突发设置小于 2000。
-
Motorola 和 Ambit CM 可在 98% US 利用率下实现 27.2 Mbps 的速率。
新的 Fragment 命令
cable upstream n fragment-force fragment-threshold number-of-fragments
| 参数 | 描述 |
|---|---|
| n | 指定上行端口号。有效值从 0 开始,代表电缆接口线卡上的第一个上行端口。 |
| fragment-threshold | 触发分段的字节数。有效范围为 0 至 4000,默认值为 2000 个字节。 |
| number-of-fragments | 将每个分段帧拆分为相同大小分段的数量。有效范围为 1 至 10,默认值为 3 个分段。 |
DOCSIS 2.0 的优势
DOCSIS 2.0 未添加任何对 DS 的更改,但添加了许多对 US 的更改。DOCSIS 2.0 中的高级物理层规范添加了以下规范:
-
8-QAM、32-QAM 和 64-QAM 调制方案
-
6.4 MHz 信道宽度
-
最多 16 T 字节的 FEC
它还允许在调制解调器和 US 交织中使用 24 个预均衡抽头。这可以增加对反射、信道中倾斜、组延迟和 US 噪音爆发的稳健性。此外,CMTS 中的 24 抽头均衡对较旧的 DOCSIS 1.0 调制解调器也有帮助。除 A-TDMA 外,DOCSIS 2.0 还添加了 S-CDMA 的使用。
64-QAM 的频谱效率更高,能够更好地利用现有信道并提高容量。这可以在 US 方向提供更大的吞吐量,并以更高的 PPS 稍微提高每个调制解调器的速度。在 6.4 MHz 带宽下使用 64-QAM 有助于比正常速度快得多地将大数据包发送到 CMTS,因此序列化时间将缩短,PPS 也会提高。更宽的信道可以实现更出色地统计复用。
使用 A-TDMA 可以达到的理论最高 US 速率是大约 27 Mbps 左右(汇聚)。 这取决于开销、数据包大小等等。请注意,改为更高吞吐总量可以让更多人共享,但不一定会提高每个调制解调器的速度。
如果在 US 方向运行 A-TDMA,数据包的速度会快得多。在 US 方向的 6.4 MHz 带宽下使用 64-QAM 可以更快完成 US 方向的串联数据包序列化,并提高 PPS。如果使用 2 个单位的微时隙和 A-TDMA,则每个微时隙 48 个字节,即每个请求的最大数据突发为 48 × 255 = 12240。64-QAM、6.4 MHz、2 个单位的微时隙、10000 最大串联突发和 300 动态 MAP 预见安全的结果为 ~15 Mbps。
所有当前的DOCSIS 2.0芯片实施都采用入口取消,尽管这不是DOCSIS 2.0的一部分。这使服务能够抵御最坏情况下的工厂损坏,打开频谱的未使用部分,并为生命线服务添加一项保险措施。
其它因素
有一些其他因素也可以直接影响有线网络的性能:QoS 配置文件、噪音、速率限制、节点合并、过度使用等等。在电缆调制解调器网络中排除性能不佳故障中对其中大部分因素进行了详细讨论。
还有一些电缆调制解调器限制可能并不明显。电缆调制解调器可能有 CPU 限制或与 PC 之间使用半双工以太网连接。根据数据包大小和双向流量,这可能是一个被忽视的瓶颈。
验证吞吐量
对调制解调器所在的接口发出 show cable modem 命令。
ubr7246-2# show cable modem cable 6/0
MAC Address IP Address I/F MAC Prim RxPwr Timing Num BPI
State Sid (db) Offset CPE Enb
00e0.6f1e.3246 10.200.100.132 C6/0/U0 online 8 -0.50 267 0 N
0002.8a8c.6462 10.200.100.96 C6/0/U0 online 9 0.00 2064 0 N
000b.06a0.7116 10.200.100.158 C6/0/U0 online 10 0.00 2065 0 N
发出 show cable modem mac 命令,查看调制解调器的功能。此命令将显示调制解调器可以实现的功能,而不一定是正在执行的功能。
ubr7246-2# show cable modem mac | inc 7116
MAC Address MAC Prim Ver QoS Frag Concat PHS Priv DS US
State Sid Prov Saids Sids
000b.06a0.7116 online 10 DOC2.0 DOC1.1 yes yes yes BPI+ 0 4
发出 show cable modem phy 命令,查看调制解调器的物理层属性。此信息中有一部分只有在 CMTS 上配置 remote-query 后才会显示。
ubr7246-2# show cable modem phy
MAC Address I/F Sid USPwr USSNR Timing MicroReflec DSPwr DSSNR Mode
(dBmV)(dBmV) Offset (dBc) (dBmV)(dBmV)
000b.06a0.7116 C6/0/U0 10 49.07 36.12 2065 46 0.08 41.01 atdma
发出 show controllers cable slot/port upstream port 命令,查看调制解调器的当前 US 设置。
ubr7246-2# show controllers cable 6/0 upstream 0 Cable6/0 Upstream 0 is up Frequency 33.000 MHz, Channel Width 6.400 MHz, 64-QAM Sym Rate 5.120 Msps This upstream is mapped to physical port 0 Spectrum Group is overridden US phy SNR_estimate for good packets - 36.1280 dB Nominal Input Power Level 0 dBmV, Tx Timing Offset 2066 Ranging Backoff Start 2, Ranging Backoff End 6 Ranging Insertion Interval automatic (312 ms) Tx Backoff Start 3, Tx Backoff End 5 Modulation Profile Group 243 Concatenation is enabled Fragmentation is enabled part_id=0x3138, rev_id=0x02, rev2_id=0x00 nb_agc_thr=0x0000, nb_agc_nom=0x0000 Range Load Reg Size=0x58 Request Load Reg Size=0x0E Minislot Size in number of Timebase Ticks is = 2 Minislot Size in Symbols = 64 Bandwidth Requests = 0x7D52A Piggyback Requests = 0x11B568AF Invalid BW Requests= 0xB5D Minislots Requested= 0xAD46CE03 Minislots Granted = 0x30DE2BAA Minislot Size in Bytes = 48 Map Advance (Dynamic) : 1031 usecs UCD Count = 729621 ATDMA mode enabled
发出 show interface cable slot/port service-flow 命令,查看调制解调器的服务流。
ubr7246-2# show interface cable 6/0 service-flow
Sfid Sid Mac Address QoS Param Index Type Dir Curr Active
Prov Adm Act State Time
18 N/A 00e0.6f1e.3246 4 4 4 prim DS act 12d20h
17 8 00e0.6f1e.3246 3 3 3 prim US act 12d20h
20 N/A 0002.8a8c.6462 4 4 4 prim DS act 12d20h
19 9 0002.8a8c.6462 3 3 3 prim US act 12d20h
22 N/A 000b.06a0.7116 4 4 4 prim DS act 12d20h
21 10 000b.06a0.7116 3 3 3 prim US act 12d20h
发出show interface cable slot/port service-flow sfid verbose 命令,查看该特定调制解调器的具体服务流。此命令将显示 US 或 DS 流的当前吞吐量,以及调制解调器的配置文件设置。
ubr7246-2# show interface cable 6/0 service-flow 21 verbose Sfid : 21 Mac Address : 000b.06a0.7116 Type : Primary Direction : Upstream Current State : Active Current QoS Indexes [Prov, Adm, Act] : [3, 3, 3] Active Time : 12d20h Sid : 10 Traffic Priority : 0 Maximum Sustained rate : 21000000 bits/sec Maximum Burst : 11000 bytes Minimum Reserved Rate : 0 bits/sec Admitted QoS Timeout : 200 seconds Active QoS Timeout : 0 seconds Packets : 1212466072 Bytes : 1262539004 Rate Limit Delayed Grants : 0 Rate Limit Dropped Grants : 0 Current Throughput : 12296000 bits/sec, 1084 packets/sec Classifiers : NONE
确保不存在延迟或丢弃的数据包。
发出 show cable hop 命令,验证没有任何无法纠正的 FEC 错误。
ubr7246-2# show cable hop cable 6/0
Upstream Port Poll Missed Min Missed Hop Hop Corr Uncorr
Port Status Rate Poll Poll Poll Thres Period FEC FEC
(ms) Count Sample Pcnt Pcnt (sec) Errors Errors
Cable6/0/U0 33.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U1 admindown 1000 * * * frequency not set * * * 0 0
Cable6/0/U2 10.000 Mhz 1000 * * *set to fixed frequency * * * 0 0
Cable6/0/U3 admindown 1000 * * * frequency not set * * * 0 0
如果调制解调器正在丢弃数据包,则表示物理设备正在影响吞吐量,必须解决这个问题。
摘要
本文档前面的部分强调了对性能数据断章取义而不了解对其他功能的影响的弊病。虽然您可以微调系统来达到某个特定的性能指标或解决某个网络问题,但肯定要以另一个变量为代价。更改 MAP/秒和交织的值可能会提高 US 速率,但其代价是 DS 速率或稳健性。缩短 MAP 间隔在实际网络中并不会带来多大区别,只会增加 CMTS 和 CM 的 CPU 和带宽开销。包含更多 US FEC 会增加 US 开销。吞吐量、复杂性、稳健性和成本之间始终存在一种权衡与折衷的关系。
如果在 US 端口上使用准入控制,则当分配总量用完后,有些调制解调器将无法注册。例如,如果 US 总吞吐量为 2.56 Mbps 可用且最小保证吞吐量设置为 128k,则当准入控制设置为 100% 时,该 US 端口上只会允许 20 个调制解调器注册。
结论
您必须知道预期吞吐量是多少,才能确定用户的数据传输速度和性能如何。一旦确定理论上可能达到的数值,就可以设计并管理网络,从而满足有线系统不断变化的要求。然后,您必须监控实际流量负载,以确定传输内容以及需要额外容量来缓解瓶颈的时候。
在有线网络行业中,如果网络得到正确部署和管理,服务和感知到的可用性是创造竞争优势的关键机会。随着有线网络服务提供商向多业务过渡,用户对服务完整性的期望更加接近旧版语音服务已经确立的模式。在这种变化下,有线网络服务提供商需要采取新的方法和战略来确保网络符合这种新范式。我们现在已涉足电信行业,而不再仅仅是娱乐提供商,因此面临着更高的期望和要求。
虽然 DOCSIS 1.1 包含用于确保 VoIP 等高级服务质量等级的规范,但能否部署符合此规范的服务仍然是个难题。因此,有线网络运营商有必要深入了解这些问题。必须制定一种全面的方法来选择系统组件和网络策略,确保成功部署真正的服务完整性。
其目标是让更多用户能够注册,但又不会危及当前用户的服务。如果提供了服务级别协议 (SLA) 来保证每个用户的最小吞吐量,则支持此保证的基础设施必须到位。整个行业也希望为商业客户提供服务并增加语音服务。随着这些新市场的提出和网络的构建,需要新的方法:用更多端口、现场外更远端的分布式 CMTS 或介乎于两者之间的方法(例如添加 10baseF 到住宅中)来增加 CMTS 密度。
无论未来会发生什么,可以肯定的是网络将变得更加复杂,技术挑战也会增加。有线网络行业只有采用可以及时提供最高级别服务完整性的架构和支持程序,才能应对这些挑战。
 反馈
反馈