简介
本文档介绍在思科Hyperflex集群中重新部署脱机节点的流程。
先决条件
要求
只有从Intersight部署且从5.0(2b)版本开始的Hyperflex集群支持此功能。此功能尚不支持通过Hyperflex安装程序部署并导入到Intersight的群集。
此Intersight功能支持的方案类型:
- FI/标准集群、流集群、边缘集群和DC-No-FI集群
- 具有SED(自加密驱动器)的群集
- 仅从Intersight部署的群集
- 重新部署ESXi和SCVM
- 仅重新部署SCVM
不支持的场景
- 1GbE HyperFlex Edge和Stretch集群。
- 导入到Intersight的群集
许可
重新部署HyperFlex节点需要Intersight Essentials或高级许可证。HyperFlex群集中的所有服务器都必须申请索赔并配置有Intersight Essentials或高级许可证。
使用的组件
- Cisco Intersight
- Cisco UCSM(可选)
- Cisco UCS服务器
- 思科Hyperflex集群版本5.0(2c)
- VMWare ESXi
- VMware vCenter
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
背景信息
出于多种原因,维护群集的正常运行成为一项首要任务,但最重要的是为保证超覆盖存储解决方案中的数据完整性而提供冗余。有多个方案需要同时重新部署ESXi和SCVM(存储控制器虚拟机),例如替换融合节点中的引导驱动器。
对于从Intersight部署的群集,您可以重新部署SCVM以将其添加回Hyperflex集群,现在无需通过Intersight提供TAC帮助即可执行此活动。
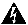
警告:必须强调,不成功完成此过程可能会导致群集出现多个意外问题,例如未来的群集升级失败和群集扩展失败。
配置
在本示例中,我们使用名为Medellin的3节点边缘群集,该群集由于M.2磁盘故障导致节点3损坏
从Intersight来看,我们的起点假设已经涵盖几个方面:
- 已更换M.2存储
- Hyperflex群集仍然运行不正常,因为它使节点脱机
群集节点脱机验证
您可以看到,集群运行不正常,并且您需要恢复已修复M.2问题的离线节点
从Intersight转至Infrastructure Service > Hyperflex Cluster > Overview > Events。您可以看到恢复能力状态
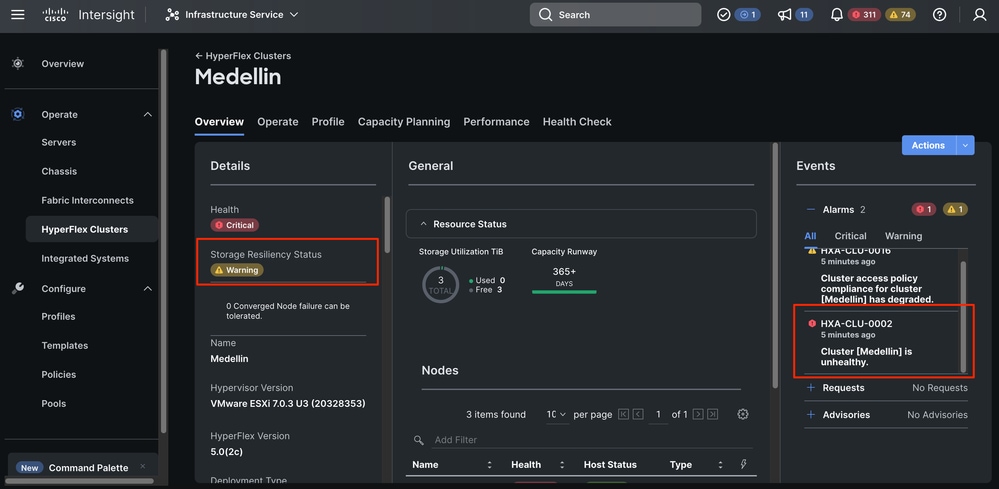
在同一个Overview选项卡中,您可以看到哪些特定节点也处于脱机状态
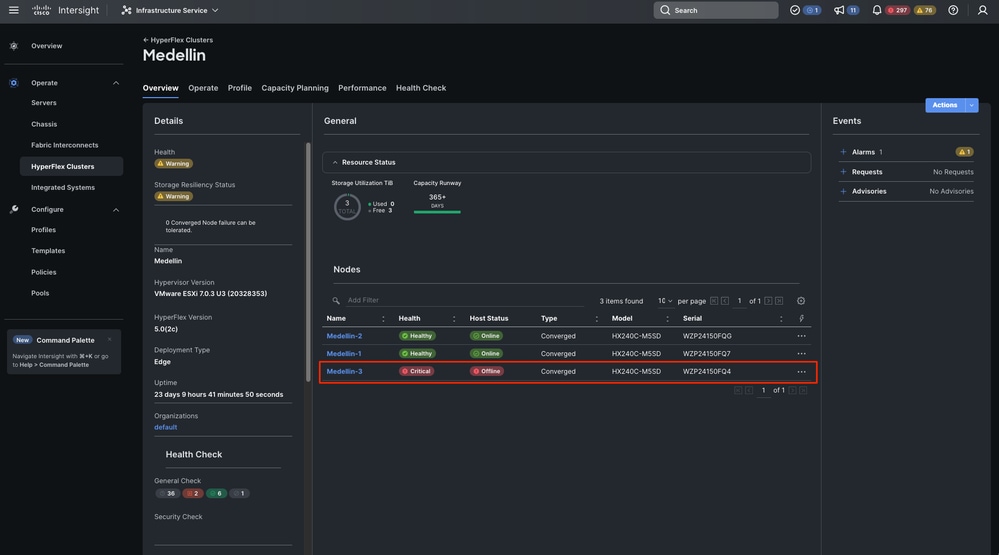
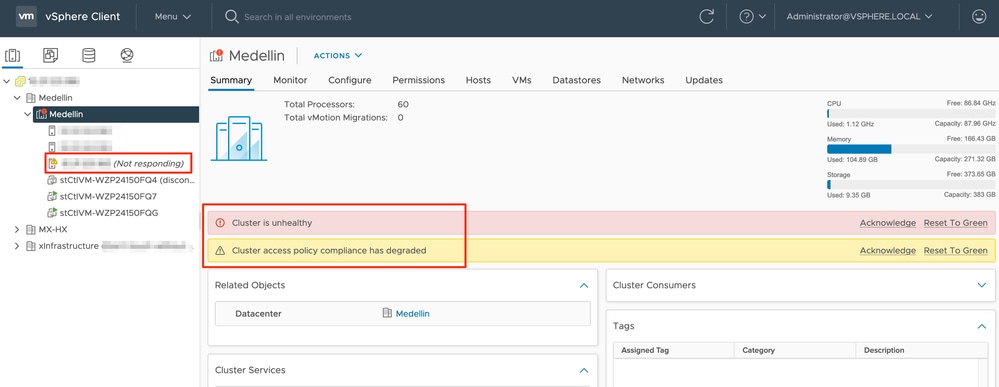
通过vCenter,我们还会收到集群运行状况不正常的警报
最后,您还可以从CLI评估集群状态:
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : WARNING
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 0
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 30.4 GiB
Free Capacity : 3.0 TiB
Compression Savings : 62.06%
Deduplication Savings : 0.00%
Total Savings : 62.06%
# of Nodes Configured : 3
# of Nodes Online : 2
Data IP Address : 169.254.218.1
Resiliency Health : WARNING
Policy Compliance : NON_COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 0
# of persistent device failures tolerable : 1
# of cache device failures tolerable : 1
Zone Type : Unknown
All Flash : No
重新部署步骤
步骤1: 重新安装ESXi操作系统。 为此,您可以转到Servers >选择Server > Options(三点)>选择Launch the KVM。
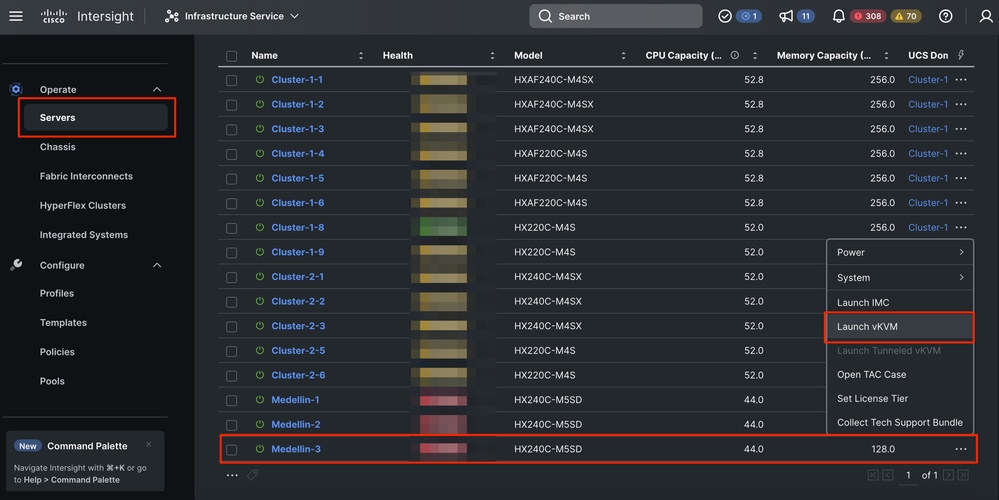
注意:您必须为集群中其他节点运行的完全相同的ESXi版本下载Cisco Hyperflex自定义映像。您可以从此处下载它
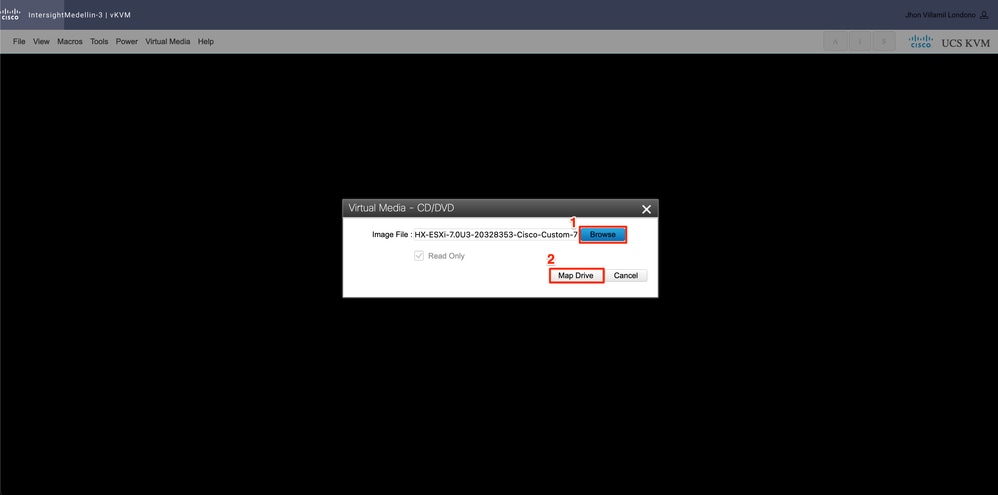
启动KVM后,导航到虚拟媒体>选择激活虚拟设备

然后选择Browse>从本地计算机选择Hyperflex ESXi iso映像>选择映射驱动器
根据服务器的状态,导航到Power>,选择Power on System或Reset System或Power Cycle System 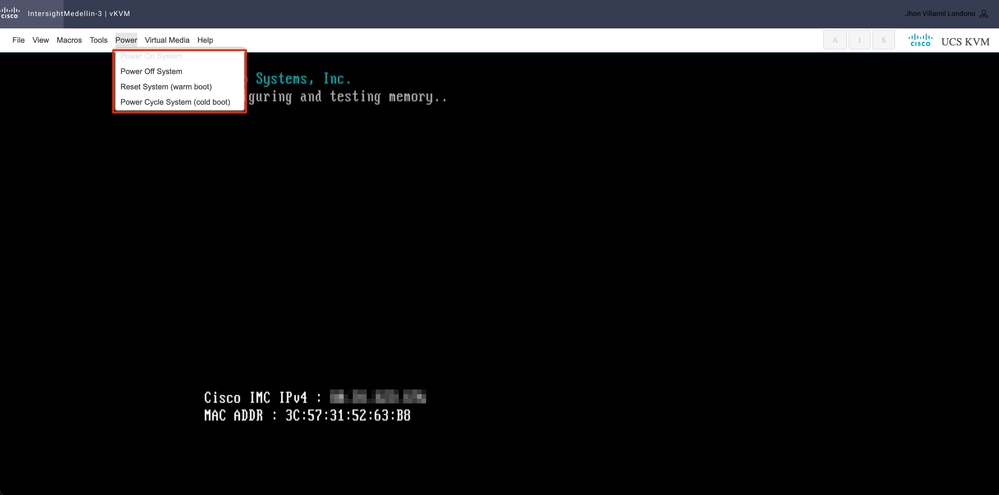
提示: Reset System(warm boot)在不关闭电源的情况下重新启动系统,而Power Cycle System(cold boot)关闭系统,然后重新打开。在此方案中,SCVM损坏并重新安装ESXi时,两个选项均满足相同目的
您需要引导至CD/DVD虚拟设备设备。导航到工具>选择键盘>当看到引导菜单提示时按F6
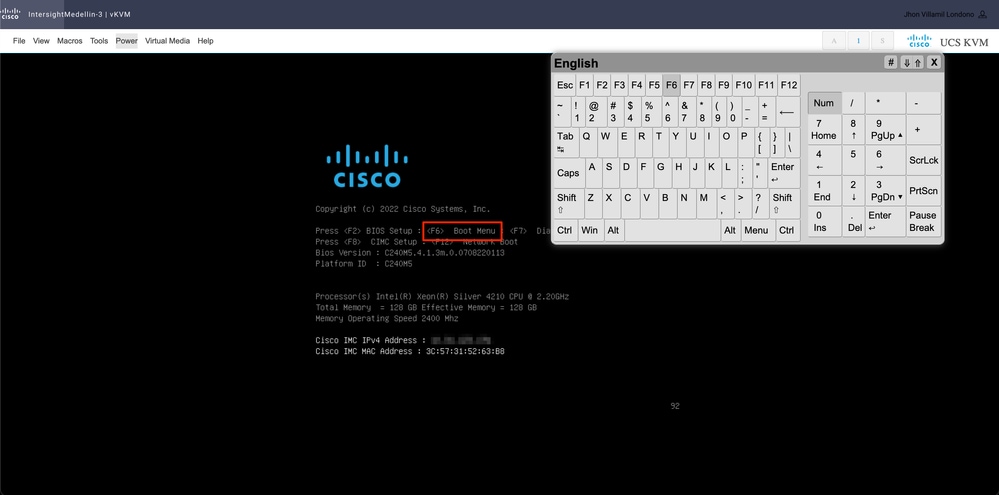
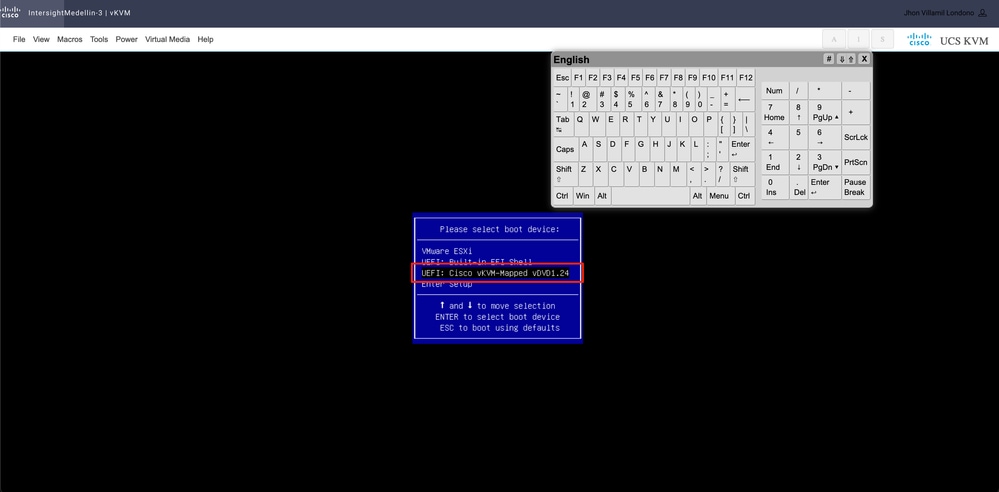
进入启动菜单,选择Cisco vKVM-Mapped vDVD1.24并按Enter
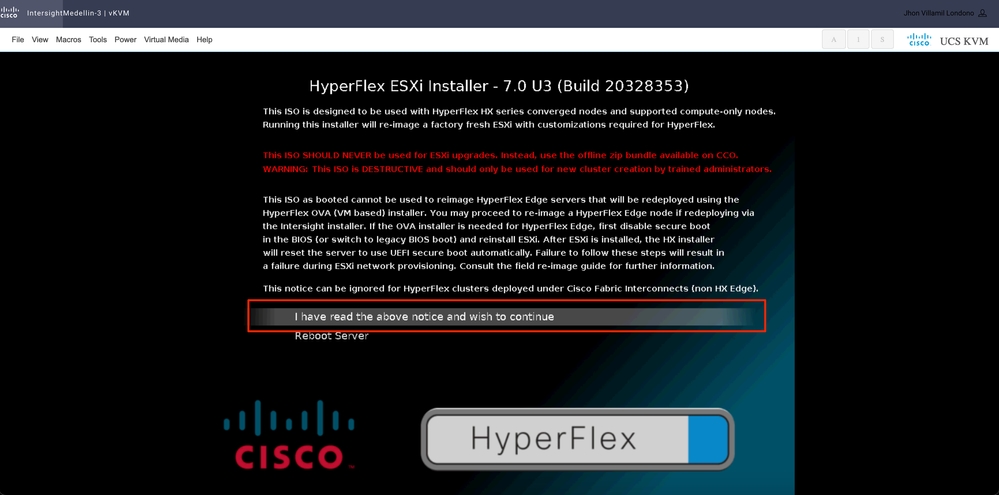
选择我已阅读上述通知,并且希望继续并按Enter键
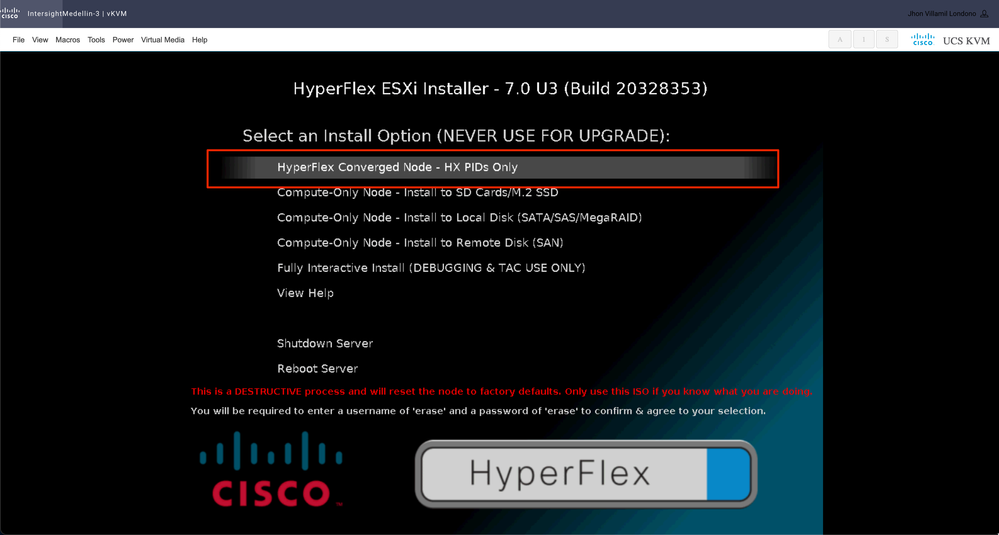
根据使用的特定启动设备,您会定期看到计算节点的不同选项,以及收敛节点的另一个选项,您在此处必须选择
之后,系统会提示您输入用户名和密码。键入username erase >按Enter > 键入password erase > hit 输入
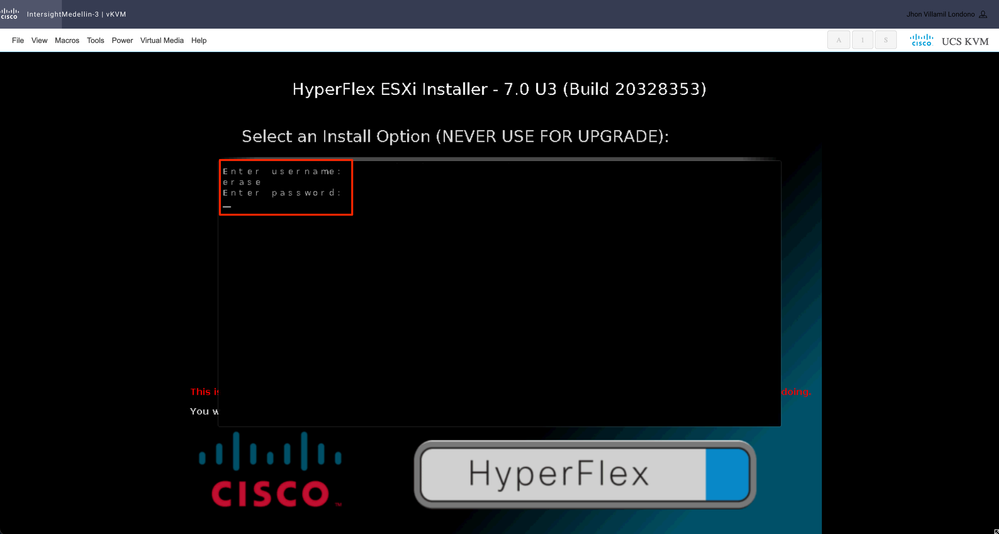
注:如果输入了错误的密码/用户名,您将返回一个步骤,然后您可以重试
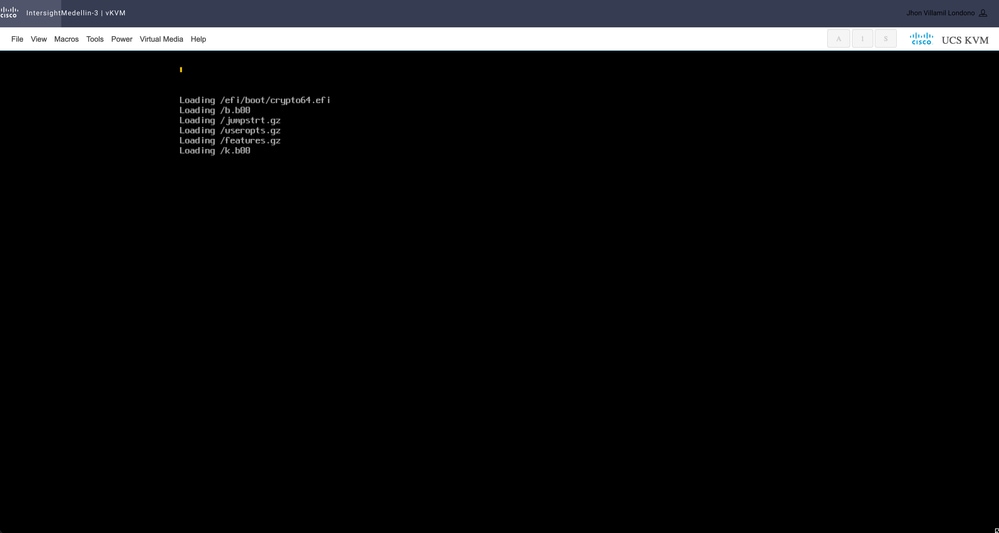
此时开始安装,您可以通过vKVM对其进行监控
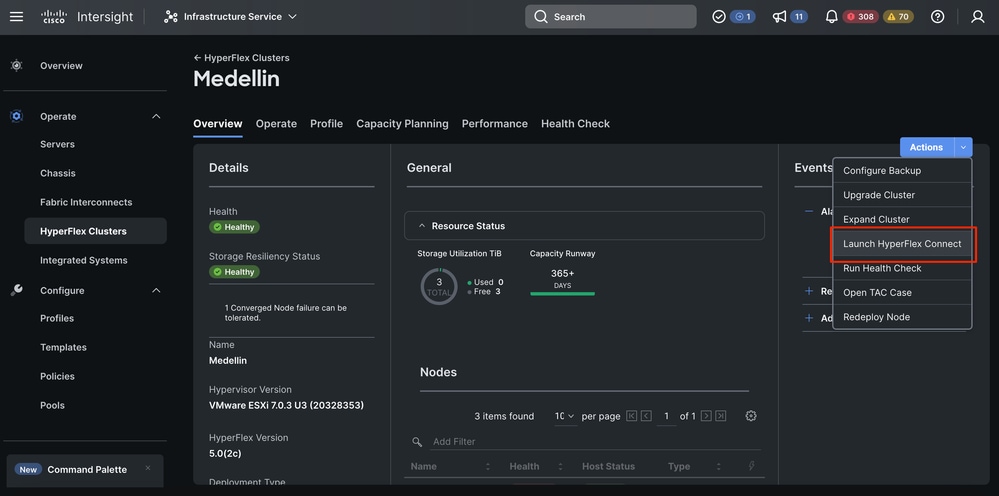
第二步:导航到Infrastructure Service > Hypeflex Clusters >选择Hyperflex集群>选择操作>选择重新部署节点
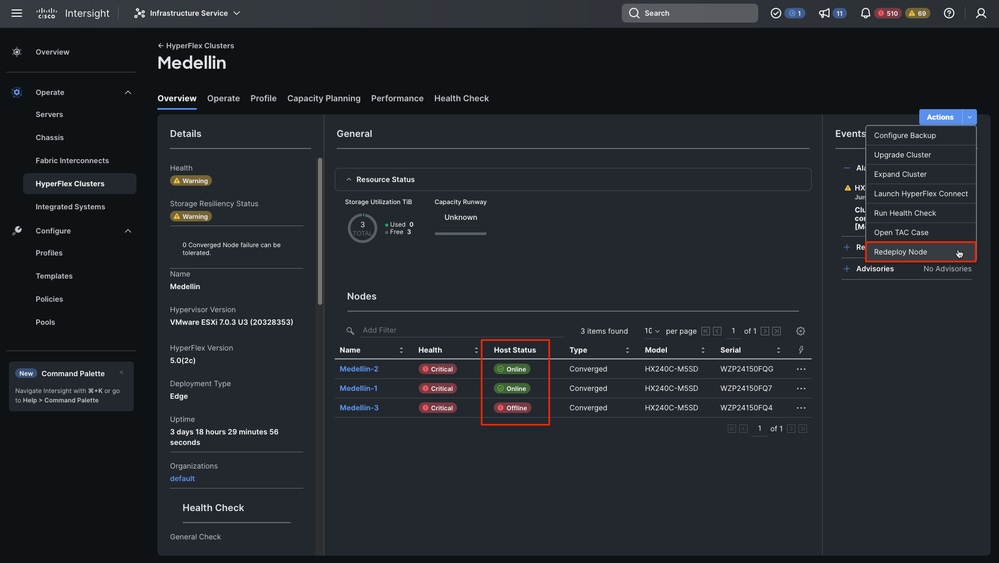

提示:如果只有SCVM损坏且需要重新安装,则如果不运行,则必须关闭服务器电源才能选择“重新部署”,否则会遇到错误“由于此群集中没有脱机主机,无法触发重新部署节点”。
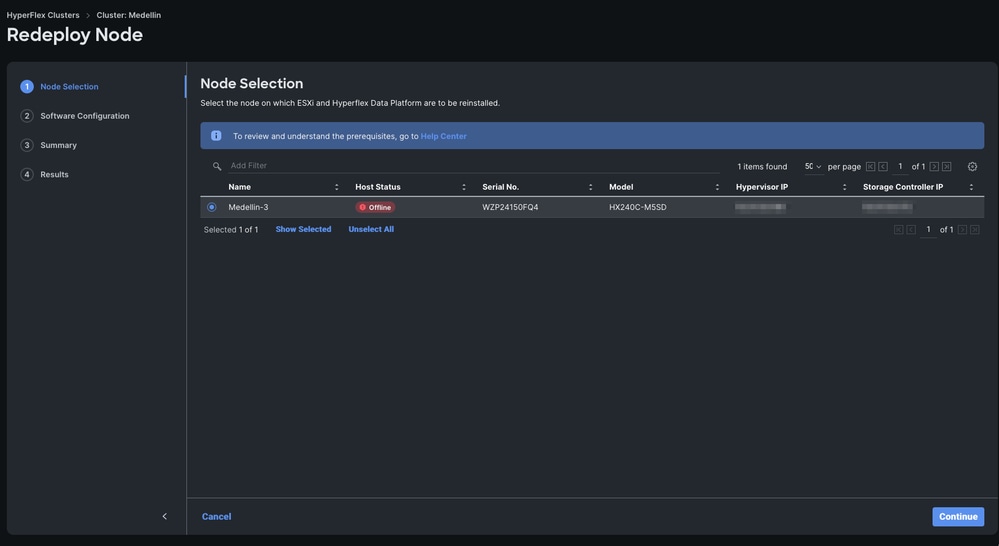
第三步:脱机选择节点>选择继续
第四步:验证安全、vCenter和代理设置策略是否与同一群集对应,然后选择“下一步”
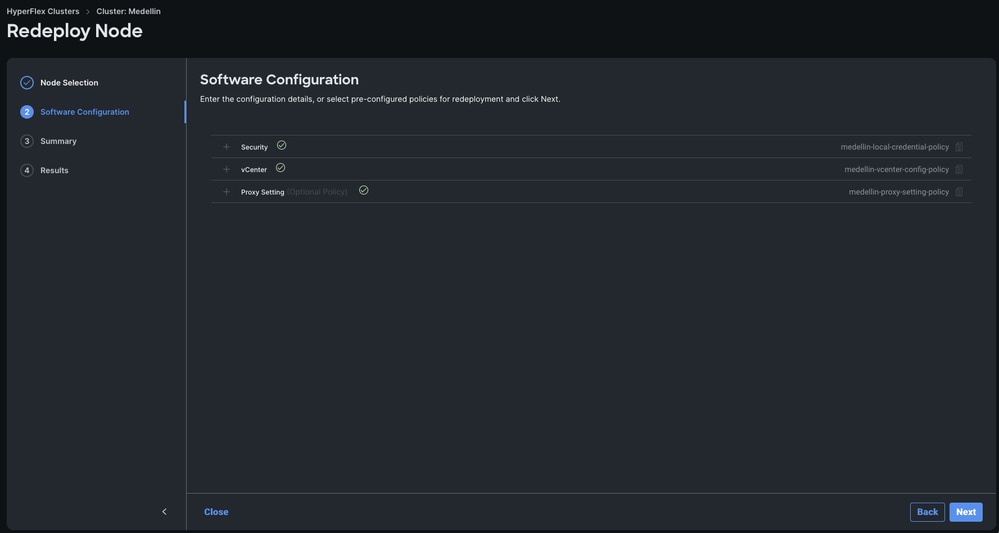
但是,如果仅重新部署SCVM且ESXi完整,则您必须从安全策略取消选择“此节点上的虚拟机监控程序使用出厂默认密码”选项,并确保当前的ESXi密码在此更新,然后再选择下一步
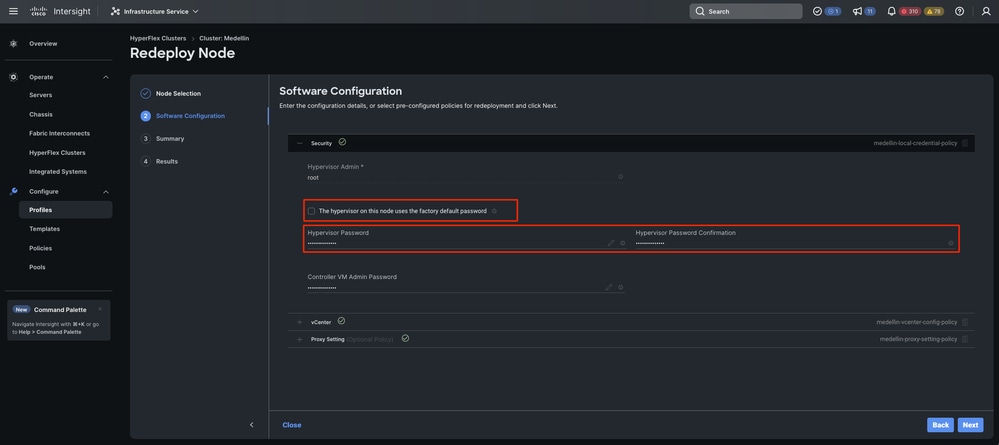
第五步:选择Validate and Redeploy
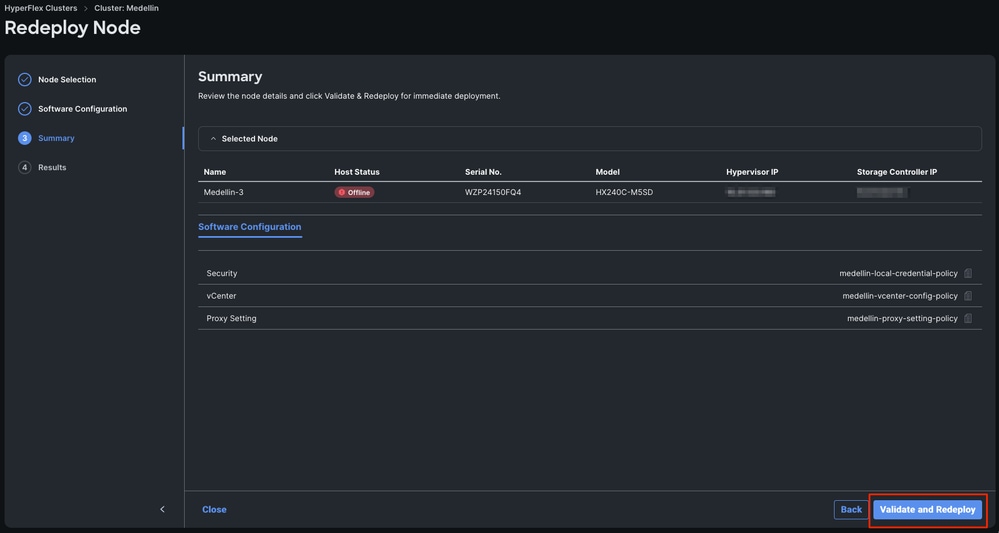
第六步:等待工作流完成
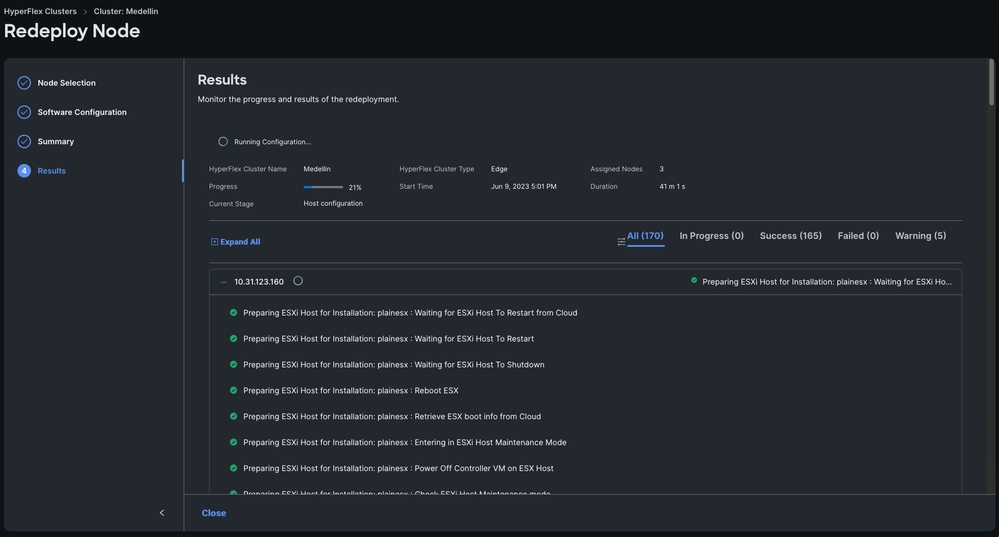
注意: 您可以监控进度,但通常需要几小时
最终重新部署已完成,Medellin群集恢复正常状态
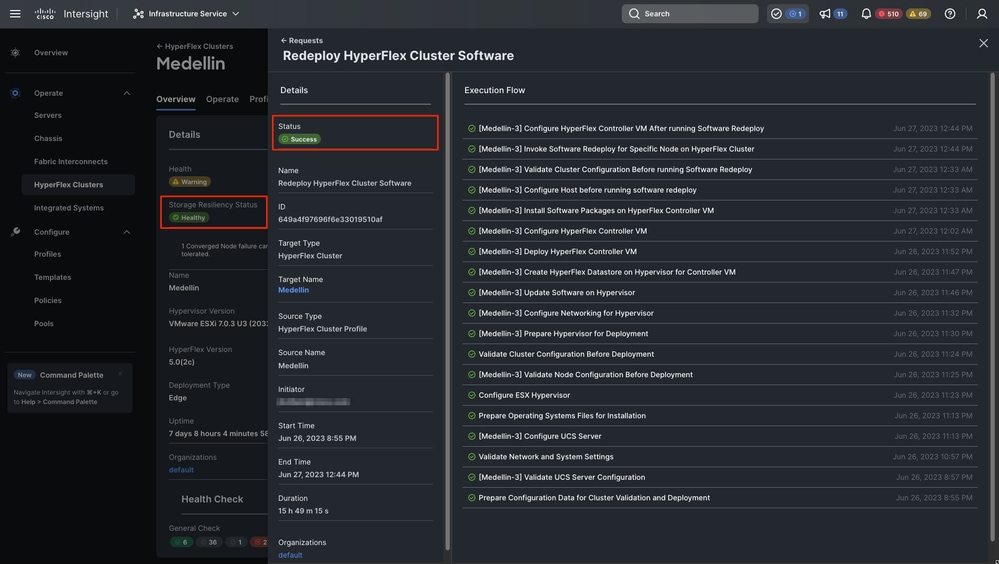
群集正常状态验证
从Intersight验证
导航到Hyperflex集群>选择集群>选择概述选项卡
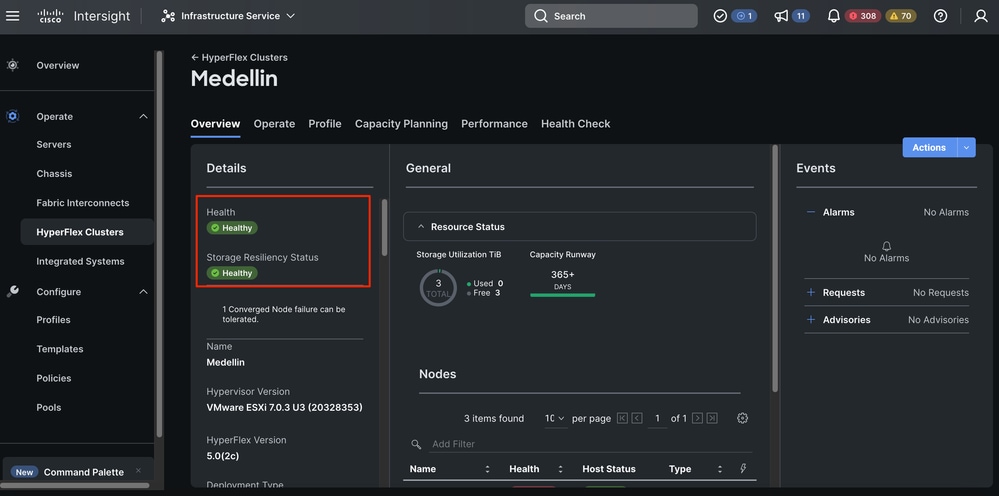
通过Hyperflex Connect进行验证
从Intersight与HXDP共进午餐,以验证其状态
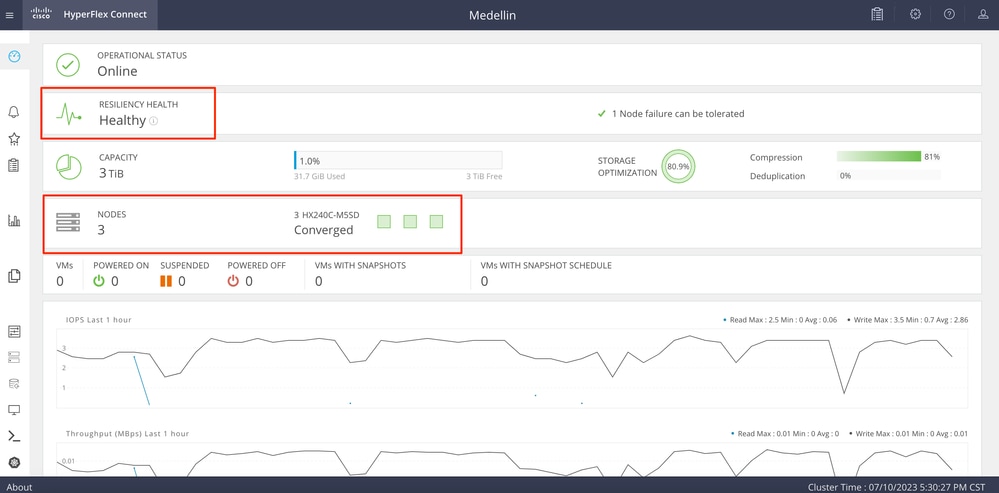
从CLI验证
从CLI,您可以使用命令,例如hxcli cluster status、hxcli cluster info、hxcli cluster health、hxcli node list
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : HEALTHY
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 1
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 31.7 GiB
Free Capacity : 3.0 TiB
Compression Savings : 80.90%
Deduplication Savings : 0.00%
Total Savings : 80.90%
# of Nodes Configured : 3
# of Nodes Online : 3
Data IP Address : 169.254.218.1
Resiliency Health : HEALTHY
Policy Compliance : COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 1
# of persistent device failures tolerable : 2
# of cache device failures tolerable : 2
Zone Type : Unknown
All Flash : No
相关信息
HyperFlex节点重新部署工作流
 反馈
反馈