简介
本文档介绍思科快速转发(CEF) switching 以及它如何在Cisco 12000系列互联网路由器中实施。
先决条件
要求
本文档没有任何特定的要求。
使用的组件
本文档不限于特定的软件和硬件版本。
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
规则
有关文档规则的详细信息,请参阅 Cisco 技术提示规则。
概述
思科快速转发(CEF)交换是一种专有的可扩展交换形式,旨在解决与需求缓存相关的问题。使用CEF交换时,通常存储在路由缓存中的信息会拆分到多个数据结构上。CEF代码能够在千兆路由处理器(GRP)中以及在辅助处理器(例如GRP路由器中的线卡)中维护这些12000据结构。为高效的数据包转发提供优化查找的数据结构包括:
-
转发信息库(FIB)表 — CEF使用FIB做出基于IP目标前缀的交换决策。FIB是概念上和路由表或信息库类似。它维护IP路由表中包含的转发信息的镜像。当在网络中更改路由或拓扑结构时,IP路由表更新,且这些变化反映在FIB上。FIB 基于 IP 路由表中的信息维护着下一跳地址信息。 由于FIB条目和路由表条目之间存在一对一相关性,因此FIB包含所有已知路由,并且无需交换路径(如快速交换和最优交换)相关的路由缓存维护。
-
邻接表 — 如果网络中的节点能够通过链路层的一跳到达彼此,则称其为邻接节点。除FIB外,CEF还使用邻接表附加第2层编址信息。邻接表维护着所有 FIB 条目的第 2 层下一跳地址。
CEF可以在以下两种模式之一中启用:
-
中央CEF模式 — 当启用CEF模式时,CEF FIB和邻接表驻留在路由处理器上,并且路由处理器执行快速转发。当线卡不可用于CEF交换,或者需要使用与分布式CEF交换不兼容的功能时,可以使用CEF模式。
-
分布式CEF(dCEF)模式 — 启用dCEF时,线卡维护FIB和邻接表的相同副本。线卡可自行执行快速转发,从而避免主处理器 — 千兆路由处理器(GRP)参与交换操作。这是Cisco 12000系列路由器上唯一可用的交换方法。
dCEF使用进程间通信(IPC)机制确保路由处理器和线卡上FIB和邻接表的同步。
有关CEF交换的详细信息,请参阅思科快速转发(CEF)白皮书。
CEF操作
更新GRP路由表
图1说明了将路由更新数据包发送到千兆路由处理器(GRP)以及产生的转发更新消息发送到线卡上的FIB表的过程。
为清楚起见,后面段落的编号与图1中的编号相对应。
下一个过程发生在路由表初始化过程中,或者网络拓扑发生变化的任何时候(添加、删除或更改路由时)。图1中所示的过程涉及五个主要步骤:
-
将IP数据报放入接收线路卡(入口线路卡)上的输入缓冲区中,L2/L3转发引擎访问数据包中的第2层和第3层信息,并将其发送到转发处理器。转发处理器确定数据包包含路由信息。转发处理器将指针发送到GRP虚拟输出队列(VOQ),并指示必须将缓冲区内存中的数据包发送到GRP。
-
线卡向时钟和调度程序卡(CSC)发出请求。调度程序卡发出授权,数据包通过交换矩阵发送到GRP。
-
GRP处理路由信息。GRP上的R5000(处理器)更新网络路由表。根据数据包中的路由信息,第3层处理器可能必须将链路状态信息泛洪到邻接路由器(如果内部路由协议是开放最短路径优先[OSPF])。处理器生成携带链路状态信息和FIB表内部更新的IP数据包。此外,GRP还会计算当同时支持内部协议和外部网关协议(例如,边界网关协议[BGP])时产生的所有递归路由。
计算的递归路由信息被发送到每个线路卡上的FIB。这显着加快了转发过程,因为线卡上的第3层处理器可以专注于转发数据包,而不计算递归路由。
-
GRP向所有线路卡上的FIB表发送内部更新,包括位于GRP上的更新。对线卡的FIB更新进行监控并予以限制。GRP具有每个线卡FIB表的副本,因此,如果将新的线卡插入机箱,一旦该卡变为活动状态,GRP就会将最新的转发信息下载到新卡。
-
每当新邻居路由器连接到GRP路由器时,都会从线卡通知12000。线卡上的处理器向GRP发送数据包,其中包含新的第2层信息(通常为点对点协议(PPP)报头信息)。GRP使用此第2层信息更新位于GRP和线卡上的邻接表。当数据包从路由器发送时,每个线卡都会将此第2层信息添加到每个12000据包。邻接表的副本在GRP上维护,用于初始化。
图1:路径确定和第3层交换图
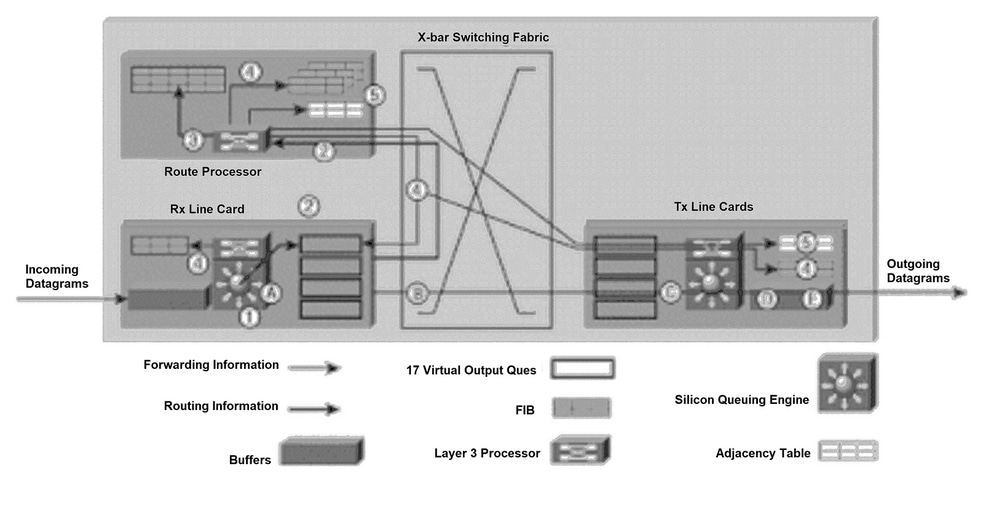 路径确定和第3层交换图
路径确定和第3层交换图
除OC48和QOC12外的所有线卡的数据包转发
一旦线卡有足够的转发信息来确定通过交换矩阵的路径(例12000,下一跳的目标),路由器就可以转发数据包了。以下步骤概述了IP路由器使用的简单快速12000发技术(请参见图1)。为清楚起见,各段落的字母与图1中的字母相对应。
-
A.将IP数据报置于接收线卡(Rx线卡)上的输入缓冲区中,L2/L3转发引擎访问数据包中的第2层和第3层信息,并将其发送到转发处理器。转发处理器确定数据包包含数据,而不是路由更新。根据FIB表中的第2层和第3层信息,转发处理器将指针发送到适当的线卡VOQ,指示缓冲区内存中的数据包将发送到该线卡。
-
B.线卡调度程序向调度程序发出请求。调度程序发出授权,数据包通过交换矩阵从缓冲存储器发送到线路卡(Tx线路卡)。
-
C.Tx线卡缓冲传入的数据包。
-
D.第3层处理器和Tx线卡上的相关专用集成电路(ASIC)将第2层信息(PPP地址)附加到每个传输的数据包。线卡上的每个端口都会复制数据包(如果需要)。
-
E.Tx线卡发射器通过光纤接口发送数据包。
此简单转发过程的优势在于大多数数据传输任务可在ASIC中完成,并且允许以12000兆速率进行操作。此外,数据包不会发送到GRP。
OC48和QOC12线卡的数据包转发
当线卡有足够的转发信息来确定通过交换矩阵的路径(例如,下一跳的目标)时,路由器就可以转发数据12000。后续步骤将构成路由器使用的简单和超快速转发12000术(请参见图2)。为清楚起见,各段落的字母与图2中的字母相对应。
-
A.将IP数据报(不是路由更新、互联网控制消息协议(ICMP)和带选项的IP数据包)接收到线卡并经过第2层处理。根据本地FIB表中的第2层和第3层信息,快速数据包处理器确定数据包的目标并修改数据包报头。然后根据目的地将数据包放入适当的线卡VOQ中。
-
B.在快速数据包处理器无法正确转发数据包的极少数情况下,数据包由转发处理器处理。转发处理器基于其本地FIB表的第2层和第3层信息,将指针发送到适当的线卡VOQ,指示缓冲区内存中的数据包将发送到该线卡。
-
C.一旦数据包处于适当的VOQ中,线卡调度程序就会向调度程序发出请求。调度程序发出授权,数据包通过交换矩阵从缓冲存储器发送到线路卡(Tx线路卡)。
-
D. Tx线卡缓冲传入的数据包。
-
E.第3层处理器和Tx线卡上的相关ASIC将第2层信息(PPP地址)附加到每个传输的数据包。线卡上的每个端口都会复制数据包(如果需要)。
-
F. Tx线卡发射器通过光纤接口发送数据包。
新转发过程的优势在于它专门为更快的速度优化了卡,例如OC48/STM16。
图2:用于速度更快的线卡的分组交换
 用于速度更快的线卡的数据包交换
用于速度更快的线卡的数据包交换
相关信息
 反馈
反馈