排除ASR1000系列路由器上CPU使用率过高的故障
下载选项
非歧视性语言
此产品的文档集力求使用非歧视性语言。在本文档集中,非歧视性语言是指不隐含针对年龄、残障、性别、种族身份、族群身份、性取向、社会经济地位和交叉性的歧视的语言。由于产品软件的用户界面中使用的硬编码语言、基于 RFP 文档使用的语言或引用的第三方产品使用的语言,文档中可能无法确保完全使用非歧视性语言。 深入了解思科如何使用包容性语言。
关于此翻译
思科采用人工翻译与机器翻译相结合的方式将此文档翻译成不同语言,希望全球的用户都能通过各自的语言得到支持性的内容。 请注意:即使是最好的机器翻译,其准确度也不及专业翻译人员的水平。 Cisco Systems, Inc. 对于翻译的准确性不承担任何责任,并建议您总是参考英文原始文档(已提供链接)。
目录
简介
本文档介绍如何对ASR1000系列路由器上的高CPU问题进行故障排除。
先决条件
要求
思科建议您了解ASR1000架构,以解释和利用本文档。
描述
思科路由器上的高CPU可定义为路由器上的CPU使用率高于正常使用率的情况。在某些情况下,CPU使用率预计会增加,而在其他情况下,则可能表明存在问题。由于网络更改或配置更改导致路由器的临时高CPU使用率可以忽略,这是预期行为。
但是,路由器在较长时间内CPU使用率较高,而网络或配置没有发生任何更改,因此需要进行分析。因此,当过度使用时,CPU无法主动为所有其他进程提供服务,从而导致命令行缓慢、控制平面延迟、数据包丢包和服务失败。
CPU使用率较高的原因有:
- 控制平面CPU接收的流量过多
- 行为异常并导致CPU过度使用的进程
- 数据平面处理器过度使用/超订用
- 处理器中断过多
CPU使用率高并不总是ASR1000系列路由器问题,因为路由器CPU使用率与路由器负载成正比。 例如,如果网络发生变化,这将导致大量控制平面流量,因为网络将重新收敛。因此,我们需要确定CPU过度使用的根本原因,以确定它是预期行为还是问题。
下图详细说明了如何排除高CPU问题的分步过程:
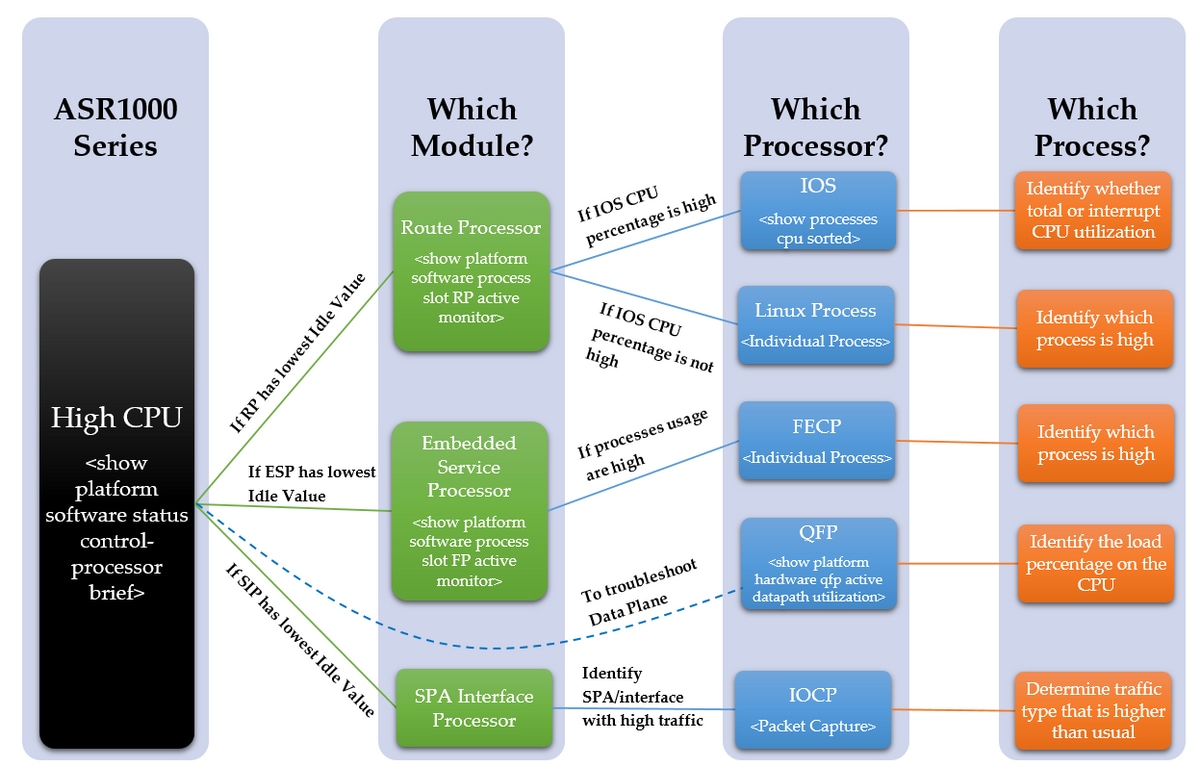
故障排除步骤
第1步 — 确定CPU使用率较高的模块
ASR1000在不同模块上有多个不同的CPU。因此,我们需要查看哪个模块显示的使用率高于正常。这可以通过空闲值(空闲值越低,该模块的CPU利用率越高)来看到。这些不同的CPU都反映了模块的控制平面。
确定设备中哪个模块的CPU使用率较高。是RP、ESP还是SIP,使用以下命令
show platform software status control-processor brief
请参阅以下输出,查看突出显示的列
如果RP的空闲值较低,则继续执行步骤2第1点
如果ESP的空闲值较低,则继续执行步骤3第2点
如果SIP的空闲值较低,则继续执行第4步第3点
Router#show platform software status control-processor brief
平均负载
插槽状态1 — 分钟5 — 分钟15 — 分钟
RP0健康0.00 0.02 0.00
ESP0健康0.01 0.02 0.00
SIP0健康0.00 0.01 0.00
内存(kB)
插槽状态已用总数(PCT)空闲(PCT)已提交(PCT)
RP0健康2009376 1879196(94%)130180(6%)1432748(71%)
ESP0健康2009400 692100(34%)1317300(66%)472536(24%)
SIP0健康471804 284424(60%)187380(40%)193148(41%)
CPU 利用率
插槽CPU用户系统Nice空闲IRQ SIRQ IOwait
RP0 0 2.59 2.49 0.00 94.80 0.00 0.09 0.00
ESP0 0 2.30 17.90 0.00 79.80 0.00 0.00 0.00 0.00
SIP0 0 1.29 4.19 0.00 94.41 0.09 0.00 0.00
如果空闲值都相对较高,则可能不是控制平面问题。要排除数据平面故障,需要观察ESP的QFP。由于QFP过度使用,仍然可以观察到“CPU使用率较高”的症状,这不会导致控制平面处理器上的CPU使用率较高。继续执行步骤 6。
步骤2 — 分析模块
- 路由处理器
在RP中,使用以下命令确认观察到哪个处理器CPU使用率较高。是Linux进程还是IOS?
show platform software process slot RP active monitor
如果IOS CPU百分比较高(linux_iosd-imag),则是RP IOS。继续执行步骤3
如果其他进程的CPU百分比较高,则可能是Linux进程。继续执行步骤4
- 嵌入式服务处理器
在ESP中确认是否观察到控制平面处理器具有高CPU利用率。是FECP吗?
show platform software process slot FP active monitor
如果进程高,则是FECP,然后继续步骤5
如果它不是FECP,则它不是ESP内处理相关问题的控制平面。如果仍然观察到网络延迟或队列丢弃等症状,则可能需要检查数据平面是否过度使用。继续执行步骤6
- SPA接口处理器
如果观察到SIP的CPU使用率较高,则会观察到IOCP的CPU使用率较高。确定IOCP中观察到哪些进程或进程具有高CPU利用率。
执行数据包捕获并确定哪些流量比正常流量高以及哪些进程与此类型的流量关联。请继续步骤7
第3步 — IOS进程
请参阅以下输出,第一个百分比是总CPU利用率,第二个百分比是中断CPU利用率,即用于处理已传送数据包的CPU的量。
如果中断百分比较高,则表示大量流量被传送到RP,(这可以通过命令show platform software infrastructure punt来确认)
如果中断百分比较低,但总CPU较高,则会观察到一个进程或进程,以在较长的时间段内使用CPU。
在IOS中,使用以下命令确认观察到哪些进程或进程具有高CPU利用率。
show processes cpu sorted
确定哪个百分比较高(总CPU或中断CPU),然后根据需要确定各个进程/进程。继续执行步骤7
Router#show processes cpu sorted
5秒的CPU利用率:0%/0%;one minute:1%;five minutes:1%
PID运行时(ms)调用秒数5秒1分钟5分钟TTY进程
PID运行时(ms)调用秒数5秒1分钟5分钟TTY进程
188 8143 434758 18 0.15% 0.18% 0.19% 0以太网MSEC Ti
515 380 7050 53 0.07% 0.00% 0.00% 0 SBC主流程
3 2154 215 10018 0.07% 0.00% 0.19% 0执行
380 1783 55002 32 0.07% 0.06% 0.06% 0 MMA数据库计时器
63 3132 11143 281 0.07% 0.07% 0.07% 0.07% 0 IOSD ipc task
5 1 2 500 0.00% 0.00% 0.00% 0.00% 0 IPC ISSU调度
6 19 12 1583 0.00% 0.00% 0.00% 0 RF从主机
8 0 1 0 0.00% 0.00% 0.00% 0.00% 0 RO通知计时器
7 0 1 0 0.00% 0.00% 0.00% 0.00% 0 EDDRI_MAIN
10 6 75 80 0.00% 0.00% 0.00% 0池管理器
9 5671 538 10540 0.00% 0.14% 0.12% 0检查堆
第4步 — Linux进程
如果观察到IOS过度使用了CPU,则我们需要观察单个linux进程的CPU利用率。这些进程是从show platform software process slot RP活动监控器中列出的其他进程。确定观察到哪些进程或进程出现高CPU使用率,然后继续步骤7。
第5步 — FECP流程
如果某个进程或进程高,则可能是FECP中的进程导致CPU使用率过高,请继续执行步骤7
第6步 — QFP利用率
量子流处理器是转发ASIC。要确定转发引擎上的负载,可以监控QFP。以下命令以每秒数据包数和每秒位数为单位列出输入和输出数据包(优先级和非优先级)。最后一行以百分比显示由数据包转发引起的CPU负载总量。
show platform hardware qfp active datapath utilization
确定输入或输出是否高,并查看进程负载,然后继续执行步骤7
Router#show platform hardware qfp active datapath utilization
CPP 0:Subdev 0 5秒1分钟5分钟60分钟
输入: 优先级(pps)0 0 0 0
(bps)208 176 176 176
非优先级(pps)0 2 2 2
(bps)64 784 784 784
总计(pps)0 2 2 2
(bps)272 960 960 960
输出:优先级(pps)0 0 0 0
(bps)192 160 160 160
非优先级(pps)0 1 1 1 1
(bps)0 6488 6496 6488
总计(pps)0 1 1 1
(bps)192 6648 6656 6648
处理:负载(pct)0 0 0 0
第7步 — 确定根本原因并确定修复
由于观察到的进程已识别出CPU过度使用,因此可以更清楚地了解为什么出现高CPU。要继续,请研究确定的流程所执行的功能。这有助于确定如何解决问题的行动计划。例如 — 如果进程负责特定协议,则您可能希望查看与此协议相关的配置。
如果您仍遇到与CPU相关的问题,建议联系TAC,以便工程师帮助您进一步排除故障。上述故障排除步骤将帮助工程师更高效地隔离问题。
故障排除示例
在本例中,我们将运行故障排除过程,并尝试最好地确定路由器CPU使用率较高的可能根本原因。首先,确定观察到哪个模块出现CPU使用率较高的情况,我们会得到以下输出:
Router#show platform software status control-processor brief
平均负载
插槽状态1 — 分钟5 — 分钟15 — 分钟
RP0健康0.66 0.15 0.05
ESP0健康0.00 0.00 0.00
SIP0健康0.00 0.00 0.00
内存(kB)
插槽状态已用总数(PCT)空闲(PCT)已提交(PCT)
RP0健康2009376 1879196(94%)130180(6%)1432756(71%)
ESP0健康2009400 692472(34%)1316928(66%)472668(24%)
SIP0健康471804 284556(60%)187248(40%)193148(41%)
CPU 利用率
插槽CPU用户系统Nice空闲IRQ SIRQ IOwait
RP0 0 57.11 14.42 0.00 0.00 28.25 0.19 0.00
ESP0 0 2.10 17.91 0.00 79.97 0.00 0.00 0.00 0.00
SIP0 0 1.20 6.00 0.00 92.80 0.00 0.00 0.00 0.00
由于RP0中的空闲量非常低,这表明路由处理器中存在CPU高问题。因此,为了进一步排除故障,我们将确定观察到RP中哪个处理器CPU使用率较高。
Router#show processes cpu sorted
5秒的CPU利用率:84%/36%;one minute:34%;five minutes:9%
PID运行时(ms)调用秒数5秒1分钟5分钟TTY进程
107 303230 50749 5975 46.69% 18.12% 4.45% 0 IOSXE-RP Punt Se
63 105617 540091 195 0.23% 0.10% 0.08% 0 IOSD工作任务
159 74792 2645991 28 0.15% 0.06% 0.06% 0 VRRS主线程
116 53685 169683 316 0.15% 0.05% 0.01% 0/秒就业
9 305547 26511 11525 0.15% 0.28% 0.16% 0检查堆
188 362507 20979154 17 0.15% 0.15% 0.19% 0以太网MSEC Ti
3 147 186 790 0.07% 0.08% 0.02% 0执行
2 32126 33935 946 0.07% 0.03% 0.00% 0负荷表
446 416 33932 12 0.07% 0.00% 0.00% 0 VDC流程
164 59945 5261819 11 0.07% 0.04% 0.02% 0 IP ARP重试时间
43 1703 16969 100 0.07% 0.00% 0.00% 0 IPC Keep Alive M
从此输出中可以观察到,总CPU百分比和中断百分比高于预期。利用CPU的最高进程是“IOSXE-RP Punt Se”,该进程处理RP CPU的流量,因此我们可以进一步查看传送到RP的流量。
Router#show platform software infrastructure punt
LSMPI接口内部统计信息:
enabled=0, disabled=0, throttled=0, unthrottled=0,状态就绪
输入缓冲区= 90100722
输出缓冲区= 100439
rxdone count = 90100722
txdone count = 100436
Rx无特定类型计数= 0
Tx无特定类型计数= 0
阴影计数的Txbuf = 0
无数据包开始= 0
数据包的无结尾= 0
丢弃统计信息:
错误版本0
错误类型0
具有功能报头0
具有平台标题0
功能报头缺少0
通用报头不匹配0
总长度0错误
数据包长度错误0
网络偏移量0错误
不投入报头0
未知链路类型0
无swidb 1
错误的ESS功能报头0
无ESS功能0
无SSLVPN功能0
Punt For Us类型未知0
Punt原因超出范围0
IOSXE-RP Punt数据包导致:
62 210226第2层控制和传统数据包
147个ARP请求或响应数据包
27801234 For-us数据包
84426 RP<->QFP保活数据包
6个Glean邻接数据包
1647 For-us控制数据包
FOR_US控制IPv4协议统计信息:
1647个OSPF数据包
数据包直方图(500字节/bin),平均大小为92,总大小为56:
PAK大小入计数出计数
0+: 90097805 98790
500+: 0 7
从此输出中,我们可以看到“For-us data packets”中有大量数据包,指示流向路由器的流量,此计数器已确认在几分钟内多次观察命令后递增。这确认了CPU被大量传送流量过度使用,这些流量通常控制平面流量。控制平面流量可以包括ARP、SSH、SNMP、路由更新(BGP、EIGRP、OSPF)等。从此信息中,我们可以确定CPU使用率过高的潜在原因,这有助于排除根本原因。例如,可以实施数据包捕获或监控不同流量,以查看传送到RP的确切流量,从而确定并解决根本原因,防止将来出现类似问题。
数据包捕获完成后,潜在传输流量的一些示例如下:
- ARP:这可能是由于ARP请求数过多所致,如果多个IP地址通过配置IP路由向广播接口发送ARP请求,就会发生这种情况。这也可能是因为ARP表中的已刷新条目,并且必须根据老化的MAC地址条目或启动/关闭的接口重新获取。
- SSH:这可能导致高CPU,原因是show命令(show tech-support)较大,或者启用了许多debug命令,这会强制通过SSH会话发送大量CLI。
- SNMP :这可能是因为SNMP代理处理请求需要很长时间,因此导致CPU使用率较高。通常有两种可能的原因是MIB被轮询,或NMS轮询的路由和/或ARP表。
- 路由更新:路由更新的大量涌入通常是由于网络重新收敛或链路抖动。这可能表示网络中断的路由,或者是迫使网络收敛并重新计算最佳路由的整个设备,具体取决于使用的路由协议。
这突出显示了当CPU使用率高到单个进程级别时,如何通过确定其原因来隔离根本原因。在此,可以单独分析单个进程或协议,以确定它是配置问题、软件问题、网络设计还是预期实践。
其它命令
以下是其他有用命令的列表,这些命令可用于与处理器相关的处理器,并按其排序:
路由处理器
- <show process cpu history>
- 提供过去60秒、分钟和72小时CPU历史记录的图表
- <show process process_ID>
- 有关单个进程内存和CPU分配的详细信息
- <show platform software infrastructure punt>
- 提供有关传送到RP的所有流量的信息
- <show platform software status control-processor brief>
- 详细说明CPU的负载和“运行状况”,并详细说明内存和模块统计信息
- <show platform software process slot r0|r1 monitor>
- 详细说明所选模块上的不同进程及其CPU和内存分配
- <monitor platform software process r0|r1>
- 提供实时源,在进程使用CPU时更新进程
- 需要先在全局配置模式下输入命令“terminal terminal-type”才能正常运行
嵌入式服务处理器
- <show platform software process list fp active summary>
- 详细列出在CPU上运行的所有进程的摘要以及平均负载
- <show platform software process slot f0|f1 monitor>
- 详细说明所选模块上的不同进程及其CPU和内存分配
- <monitor platform software process f0|f1>
- 提供实时源,在进程使用CPU时对进程进行更新
- 需要先在全局配置模式下输入命令“terminal terminal-type”才能正常运行
由思科工程师提供
- Chris CourtelisCisco Systems
 反馈
反馈