排除ASR 9000系列交换矩阵数据路径故障
下载选项
非歧视性语言
此产品的文档集力求使用非歧视性语言。在本文档集中,非歧视性语言是指不隐含针对年龄、残障、性别、种族身份、族群身份、性取向、社会经济地位和交叉性的歧视的语言。由于产品软件的用户界面中使用的硬编码语言、基于 RFP 文档使用的语言或引用的第三方产品使用的语言,文档中可能无法确保完全使用非歧视性语言。 深入了解思科如何使用包容性语言。
关于此翻译
思科采用人工翻译与机器翻译相结合的方式将此文档翻译成不同语言,希望全球的用户都能通过各自的语言得到支持性的内容。 请注意:即使是最好的机器翻译,其准确度也不及专业翻译人员的水平。 Cisco Systems, Inc. 对于翻译的准确性不承担任何责任,并建议您总是参考英文原始文档(已提供链接)。
目录
简介
本文档介绍在思科聚合服务路由器(ASR)9000系列运行期间出现的交换矩阵数据路径故障消息。
该消息以以下格式显示:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
本文档面向希望了解错误消息以及发现问题时应采取的操作的任何人。
先决条件
要求
思科建议您深入了解以下主题:
- ASR 9000线卡
- 交换矩阵卡
- 路由处理器
- 机箱架构
但是,本文档不要求读者熟悉硬件详细信息。在解释错误消息之前,需要提供必需的背景信息。本文档介绍基于Trident和Typhoon的线路卡上的错误。有关这些术语的说明,请参阅了解ASR 9000系列线卡类型。
使用的组件
本文档不限于特定的软件和硬件版本。
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
如何使用本文档
请思考以下有关如何使用本文档以获取基本详细信息并用作故障排除过程中的参考指南的建议:
- 如果不需要急于确定突发交换矩阵数据路径故障的根本原因,请阅读本文档的所有部分。本文档将构建必要的背景,以便在发生此类错误时隔离故障组件。
- 如果您有需要快速回答的特定问题,请使用FAQ部分。如果问题未包括在常见问题部分中,则检查主文档是否解决了该问题。
- 使用Analyze Faults中的所有部分可在路由器出现故障时将问题隔离到故障组件,或检查问题是否为已知问题。
背景信息
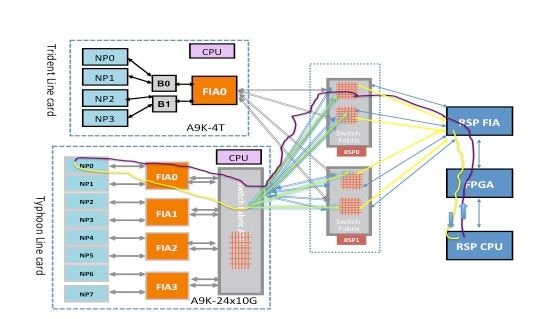
根据线卡类型,数据包可通过交换机交换矩阵经过两跳或三跳。Typhoon Generation线卡添加额外的交换矩阵元素,而基于Trident的线卡仅交换路由处理器卡上交换矩阵的所有流量。下图显示了这两种线卡类型的交换矩阵元素,以及到路由处理器卡的交换矩阵连接:

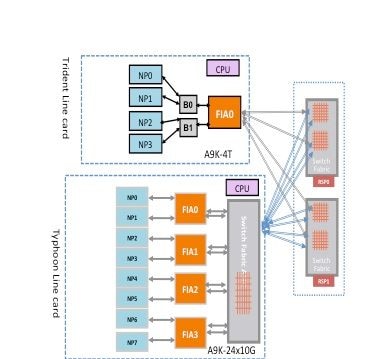
Punt交换矩阵诊断数据包路径
在路由处理器卡CPU上运行的诊断应用程序会定期注入发往每个网络处理器(NP)的诊断数据包。诊断数据包在NP内环回,然后被重新注入产生该数据包的路由处理器卡CPU。通过路由处理器卡上的诊断应用程序对每个NP执行唯一数据包的定期运行状况检查,可针对路由器运行期间数据路径中的任何功能错误发出警报。必须注意,主用路由处理器和备用路由处理器上的诊断应用程序会定期为每个NP注入一个数据包,并维护每个NP的成功或失败计数。当达到丢弃的诊断数据包的阈值时,应用程序会引发故障。
诊断路径的概念视图
在文档介绍基于Trident和Typhoon的线路卡上的诊断路径之前,本节提供从主用和备用路由处理器卡到线路卡上的NP的交换矩阵诊断路径的一般概述。
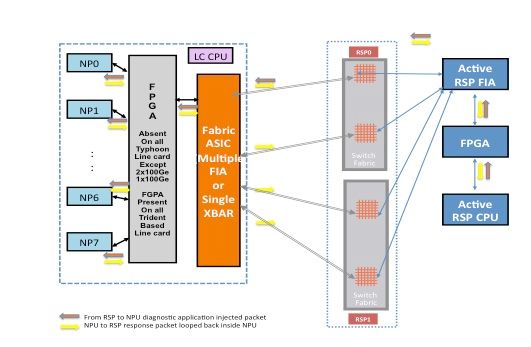
主用路由处理器卡和线路卡之间的数据包路径
从主用路由处理器注入到NP的交换矩阵的诊断数据包被交换矩阵视为单播数据包。对于单播数据包,交换矩阵根据链路的当前流量负载选择传出链路,这有助于将诊断数据包用于路由器上的流量负载。当有多条指向NP的传出链路时,交换矩阵ASIC会选择当前负载最低的链路。
下图描述了源自活动路由处理器的诊断数据包路径。
注:对于发往NP的数据包,始终会选择将线卡上的交换矩阵接口ASIC(FIA)连接到路由处理器卡上的交叉开关(XBAR)的第一条链路。来自NP的响应数据包采用链路负载分配算法(如果线路卡基于Typhoon)。这意味着从NP到活动路由处理器的响应数据包可以根据交换矩阵链路负载选择将线卡连接到路由处理器卡的任何交换矩阵链路。
备用路由处理器卡和线路卡之间的数据包路径
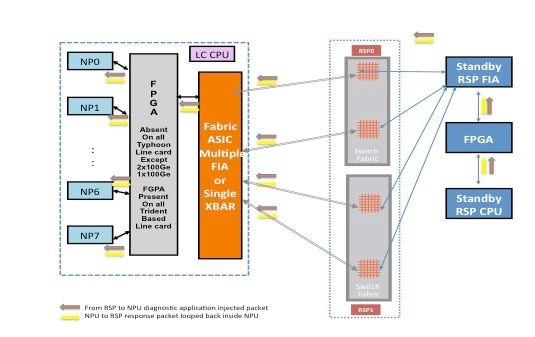
从备用路由处理器注入到NP的交换矩阵的诊断数据包被交换矩阵视为组播数据包。虽然它是组播数据包,但交换矩阵内没有复制。来自备用路由处理器的每个诊断数据包每次仍仅到达一个NP。从NP到路由处理器的响应数据包也是通过交换矩阵的组播数据包,不进行复制。因此,备用路由处理器上的诊断应用程序从NP接收单个响应数据包,一次一个数据包。诊断应用程序跟踪系统中的每个NP,因为它会为每个NP注入一个数据包,并期望每个NP的响应,一次一个数据包。对于组播数据包,交换矩阵根据数据包报头中的字段值选择传出链路,这有助于将诊断数据包注入路由处理器卡和线卡之间的每个交换矩阵链路。备用路由处理器跟踪路由处理器卡和线卡插槽之间连接的每个交换矩阵链路上的NP运行状况。
上图描述了源自备用路由处理器的诊断数据包路径。请注意,与活动路由处理器机箱不同,所有将线卡连接到路由处理器上的XBAR的链路都会被激活。来自NP的响应数据包采用路由处理器中数据包到线卡方向所用的相同的交换矩阵链路。此测试可确保持续监控连接备用路由处理器和线卡的所有链路。
基于Trident的线卡上的分支交换矩阵诊断数据包路径
下图描述从诊断数据包发往环回路由处理器的NP的路由处理器。请务必注意所有NP共有的数据路径链路和ASIC,以及特定于一组NP的链路和组件。例如,网桥ASIC 0(B0)对NP0和NP1通用,而FIA0对所有NP通用。在路由处理器端,所有链路、数据路径ASIC和现场可编程门阵列(FPGA)对于所有线卡都是通用的,因此对于机箱中的所有NP也是通用的。
基于台风的线路卡上的交换矩阵诊断数据包路径
下图描述了源自路由处理器卡的诊断数据包,这些数据包发往环回路由处理器的NP。请务必注意所有NP通用的数据路径链路和ASIC,以及特定于一组NP的链路和组件。例如,FIA0对于NP0和NP1是通用的。在路由处理器卡端,所有链路、数据路径ASIC和FGPA对于所有线卡都是通用的,因此对于机箱中的所有NP也是通用的。
基于Tomahawk、Lightspeed和LightspeedPlus的线卡上的交换矩阵诊断数据包路径
在Tomahawk线卡上,FIA和NP之间有1:1连接。
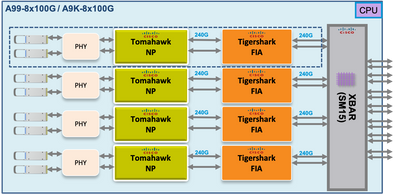
在Lightspeed和LightspeedPlus线卡上,FIA集成在NP芯片中。

接下来的几节将尝试描述通向每个NP的数据包路径。这对于了解punt交换矩阵数据路径错误消息以及定位故障点非常必要。
Punt交换矩阵诊断警报和故障报告
在基于ASR 9000的路由器中,未能从NP获取响应会导致警报。当连续发生三次故障时,路由处理器上执行的在线诊断应用程序发出警报的决策就会发生。诊断应用程序为每个NP维护一个三数据包故障窗口。主用路由处理器和备用路由处理器独立并行地进行诊断。主用路由处理器、备用路由处理器或两个路由处理器卡可能会报告该错误。故障和丢包的位置决定了哪个路由处理器报告警报。
指向每个NP的诊断数据包的默认频率为每60秒一个数据包或每分钟一个数据包。
以下是警报消息格式:
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 1) (0/7/CPU0, 2) (0/7/CPU0, 3) (0/7/CPU0, 4) (0/7/CPU0, 5)
(0/7/CPU0, 6) (0/7/CPU0, 7)
该消息显示从路由处理器0/rsp0/cpu0到达线卡0/7/cpu0上的NP 1、2、3、4、5、6和7失败。
从联机诊断测试列表中,可以使用以下命令查看punt交换矩阵环回测试的属性:
RP/0/RSP0/CPU0:iox(admin)#show diagnostic content location 0/RSP0/CPU0
RP 0/RSP0/CPU0:
Diagnostics test suite attributes:
M/C/* - Minimal bootup level test / Complete bootup level test / NA
B/O/* - Basic ondemand test / not Ondemand test / NA
P/V/* - Per port test / Per device test / NA
D/N/* - Disruptive test / Non-disruptive test / NA
S/* - Only applicable to standby unit / NA
X/* - Not a health monitoring test / NA
F/* - Fixed monitoring interval test / NA
E/* - Always enabled monitoring test / NA
A/I - Monitoring is active / Monitoring is inactive
Test Interval Thre-
ID Test Name Attributes (day hh:mm:ss.ms shold)
==== ================================== ============ ================= =====
1) PuntFPGAScratchRegister ---------- *B*N****A 000 00:01:00.000 1
2) FIAScratchRegister --------------- *B*N****A 000 00:01:00.000 1
3) ClkCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
4) IntCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
5) CPUCtrlScratchRegister ----------- *B*N****A 000 00:01:00.000 1
6) FabSwitchIdRegister -------------- *B*N****A 000 00:01:00.000 1
7) EccSbeTest ----------------------- *B*N****I 000 00:01:00.000 3
8) SrspStandbyEobcHeartbeat --------- *B*NS***A 000 00:00:05.000 3
9) SrspActiveEobcHeartbeat ---------- *B*NS***A 000 00:00:05.000 3
10) FabricLoopback ------------------- MB*N****A 000 00:01:00.000 3
11) PuntFabricDataPath --------------- *B*N****A 000 00:01:00.000 3
12) FPDimageVerify ------------------- *B*N****I 001 00:00:00.000 1
RP/0/RSP0/CPU0:ios(admin)#
输出显示PuntFabricDataPath测试频率为每分钟一个数据包,故障阈值为3,这表示不允许丢失三个连续的数据包,从而导致警报。显示的测试属性是默认值。要更改默认值,请输入 diagnostic monitor interval 和 diagnostic monitor threshold 命令。
基于Trident的线路卡诊断数据包路径
NP0诊断故障
交换矩阵诊断路径
下图描述了路由处理器CPU和线卡NP0之间的数据包路径。连接B0和NP0的链路是唯一特定于NP0的链路。所有其他链路都位于同一路径中。
记下从路由处理器到NP0的数据包路径。虽然有四个链路可用于从路由处理器发往NP0的数据包,但路由处理器和线卡插槽之间的第一个链路用于从路由处理器发往线卡的数据包。从NP0返回的数据包可以通过线卡插槽与活动路由处理器之间的两个交换矩阵链路路径中的任何一条发送回活动路由处理器。选择使用哪一条链路取决于当时的链路负载。从NP0到备用路由处理器的响应数据包使用两条链路,但每次仅使用一条链路。根据诊断应用程序填充的报头字段来选择链路。

NP0诊断故障分析
单一故障场景
如果检测到单个平台故障管理器(PFM)在故障消息中仅显示NP0的交换矩阵数据路径故障警报,则故障仅发生在连接路由处理器和线路卡NP0的交换矩阵路径上。这是单一故障。如果检测到多个NP故障,请参阅“多个故障场景”部分。
RP/0/RSP0/CPU0:Sep 3 13:49:36.595 UTC: pfm_node_rp[358]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED: Set|online_diag_rsp[241782]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/7/CPU0, 0)
注:本文档的此部分适用于机箱中的任何线卡插槽,与机箱类型无关。因此,这可以应用于所有线卡插槽。
如之前的数据路径图所示,故障必须位于以下一个或多个位置:
- 连接NP0和B0的链路
- 指向NP0的内部B0队列
- 内部NP0
多个故障场景
多个NP故障
当在NP0上观察到其他故障,或者同一线卡上的其他NP也报告了故障PUNT_FABRIC_DATA_PATH_FAILED,则通过关联所有故障来进行故障隔离。例如,如果PUNT_FABRIC_DATA_PATH_FAILED故障和LC_NP_LOOPBACK_FAILED故障都出现在NP0上,则NP已停止处理数据包。要了解环回故障,请参阅NP环回诊断路径部分。这可能是NP0内部出现严重故障的早期迹象。但是,如果仅发生两个故障之一,则故障会定位到分支交换矩阵数据路径或线卡CPU上的NP路径。
如果线卡上的多个NP存在分支交换矩阵数据路径故障,则必须沿交换矩阵链路的树路径向上走才能隔离故障组件。例如,如果NP0和NP1都有故障,则故障必须位于B0或连接B0和FIA0的链路中。NP0和NP1不太可能同时遇到严重内部错误。虽然不太可能,但NP0和NP1可能会遇到由于不正确处理特定类型的数据包或错误数据包导致的严重错误故障。
两个路由处理器卡都报告故障
如果主用和备用路由处理器卡都向线路卡上的一个或多个NP报告故障,则检查受影响的NP与两个路由处理器卡之间的数据路径上的所有公共链路和组件。
NP1诊断故障
下图描述了路由处理器卡CPU和线卡NP1之间的数据包路径。连接网桥ASIC 0(B0)和NP1的链路是唯一特定于NP1的链路。所有其他链路都位于同一路径中。
记下从路由处理器卡到NP1的数据包路径。虽然有四个链路可用于从路由处理器发往NP0的数据包,但路由处理器和线卡插槽之间的第一个链路用于从路由处理器发往线卡的数据包。从NP1返回的数据包可以通过线卡插槽与活动路由处理器之间的两个交换矩阵链路路径中的任何一条发送回活动路由处理器。选择使用哪一条链路取决于当时的链路负载。从NP1到备用路由处理器的响应数据包使用两条链路,但每次仅使用一条链路。根据诊断应用程序填充的报头字段来选择链路。
交换矩阵诊断路径
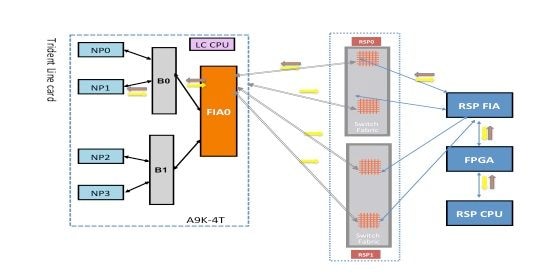
NP1诊断故障分析
请参阅NP0诊断故障分析部分,但对NP1(而不是NP0)应用相同的推理。
NP2诊断故障
下图描述了路由处理器卡CPU和线卡NP2之间的数据包路径。连接B1和NP2的链路是唯一特定于NP2的链路。所有其他链路都位于同一路径中。
记下从路由处理器卡到NP2的数据包路径。虽然有四个链路可用于从路由处理器发往NP2的数据包,但路由处理器和线卡插槽之间的第一个链路用于从路由处理器发往线卡的数据包。从NP2返回的数据包可以通过线卡插槽与活动路由处理器之间的两个交换矩阵链路路径中的任何一条发送回活动路由处理器。选择使用哪一条链路取决于当时的链路负载。从NP2到备用路由处理器的响应数据包使用两条链路,但每次仅使用一条链路。根据诊断应用程序填充的报头字段来选择链路。
交换矩阵诊断路径
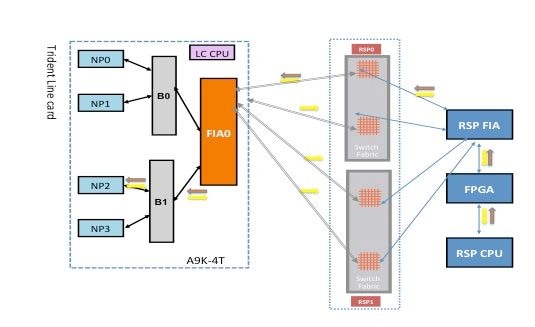
NP2诊断故障分析
请参阅NP0诊断故障分析部分,但对NP2(而不是NP0)应用相同的推理。
NP3诊断故障
下图描述了路由处理器卡CPU和线卡NP3之间的数据包路径。连接网桥ASIC 1(B1)和NP3的链路是唯一特定于NP3的链路。所有其他链路都位于同一路径中。
记下从路由处理器卡到NP3的数据包路径。虽然有四个链路可用于从路由处理器发往NP3的数据包,但路由处理器和线卡插槽之间的第一个链路用于从路由处理器发往线卡的数据包。从NP3返回的数据包可以通过线卡插槽与活动路由处理器之间的两个交换矩阵链路路径中的任何一条发送回活动路由处理器。选择使用哪一条链路取决于当时的链路负载。从NP3到备用路由处理器的响应数据包使用两条链路,但每次只使用一条链路。根据诊断应用程序填充的报头字段来选择链路。
交换矩阵诊断路径
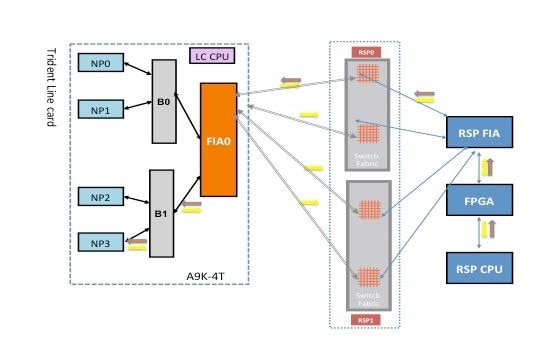
NP3诊断故障分析
请参阅NP0诊断故障分析部分,但对NP3(而不是NP0)应用相同的推理。
基于台风的线路卡诊断数据包路径
本部分提供两个示例,以使用基于台风的线路卡建立交换矩阵分支数据包的背景。第一个示例使用NP1,第二个示例使用NP3。描述和分析可以扩展到任何基于台风的线路卡上的其他NP。
台风NP1诊断故障
下图描述了路由处理器卡CPU和线卡NP1之间的数据包路径。连接FIA0和NP1的链路是唯一特定于NP1路径的链路。线卡插槽和路由处理器卡插槽之间的所有其他链路均位于公共路径中。将线卡上的交换矩阵XBAR ASIC连接到线卡上的FIA的链路特定于NP的子集。例如,线卡上FIA0和本地交换矩阵XBAR ASIC之间的两个链路都用于发往NP1的流量。
记下从路由处理器卡到NP1的数据包路径。虽然有八个链路可用于从路由处理器卡发往NP1的数据包,但路由处理器卡和线卡插槽之间使用一条路径。从NP1返回的数据包可以通过线卡插槽和路由处理器之间的八个交换矩阵链路路径发送回路由处理器卡。当诊断数据包发回路由处理器卡CPU时,每条链路都会执行一条链路。
交换矩阵诊断路径

台风NP3诊断故障
下图描述了路由处理器卡CPU和线卡NP3之间的数据包路径。连接FIA1和NP3的链路是唯一特定于NP3路径的链路。线卡插槽和路由处理器卡插槽之间的所有其他链路均位于公共路径中。将线卡上的交换矩阵XBAR ASIC连接到线卡上的FIA的链路特定于NP的子集。例如,FIA1和线卡上的本地交换矩阵XBAR ASIC之间的两个链路都用于发往NP3的流量。
记下从路由处理器卡到NP3的数据包路径。虽然有八个链路可用于从路由处理器卡发往NP3的数据包,但路由处理器卡和线卡插槽之间使用一条路径。从NP1返回的数据包可以通过线卡插槽和路由处理器之间的八个交换矩阵链路路径发送回路由处理器卡。当诊断数据包发回路由处理器卡CPU时,每条链路都会执行一条链路。
交换矩阵诊断路径

基于Tomahawk的线卡诊断数据包路径
由于FIA和NP之间为1:1连接,通过FIA0的唯一流量是来自NP0。
基于Lightspeed和LightspeedPlus的线卡诊断数据包路径
由于FIA集成到NP芯片中,通过FIA0的唯一流量是往返NP0。
分析故障
本节将故障分为硬故障和瞬变故障,并列出用于识别故障是硬故障还是瞬变故障的步骤。一旦确定故障类型,文档将指定可在路由器上执行的命令,以便了解故障以及需要哪些纠正措施。
瞬时故障
如果一条set PFM消息后跟一条clear PFM消息,则表明发生了故障,并且路由器自行纠正了故障。瞬变故障可能由于环境条件和硬件组件中的可恢复故障而发生。有时,可能很难将瞬时故障与任何特定事件相关联。
为清楚起见,此处列出了一个临时交换矩阵故障的示例:
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
RP/0/RSP0/CPU0:Feb 5 05:05:46.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
瞬时故障纠正措施
对于瞬态误差,建议的方法是仅监控此类误差是否进一步出现。如果瞬变故障出现不止一次,则将瞬变故障视为硬故障,并使用建议和步骤分析下一节中描述的此类故障。
硬故障
如果一条set PFM消息后面没有一条clear PFM消息,则会发生故障,并且路由器本身没有通过故障处理代码纠正故障,或者硬件故障的性质无法恢复。硬故障可能由于环境条件和硬件组件中的不可恢复故障而发生。针对硬故障的建议方法是使用分析硬故障部分中提到的准则。
此处列出了硬交换矩阵故障的示例,以方便查看。对于此示例消息,没有相应的清除PFM消息。
RP/0/RSP0/CPU0:Feb 5 05:05:44.051 : pfm_node_rp[354]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/2/CPU0, 0)
硬故障纠正措施
在硬故障场景下,收集创建服务请求之前要收集的数据部分中提到的所有命令,然后打开服务请求。在紧急情况下,在收集所有故障排除命令输出后,根据故障隔离启动路由处理器卡或重新加载线路卡。重新加载后,如果未恢复错误,请启动退货许可(RMA)。
分析瞬时故障
完成以下步骤以分析瞬时故障。
- 输入
show logging | inc “PUNT_FABRIC_DATA_PATH"命令,以发现错误是否发生一次或多次。 - 输入
show pfm location all命令以确定当前状态(SET或CLEAR)。错误是否尚未解决或已清除?如果错误状态在SET和CLEAR之间更改,则交换矩阵数据路径中的一个或多个故障会重复发生,并通过软件或硬件进行纠正。 - 调配简单网络管理协议(SNMP)陷阱或运行收集
show pfm location all命令输出,并定期搜索错误字符串,以便监视将来出现的故障(当错误的最后状态为CLEAR且未发生新故障时)。
要使用的命令
输入以下命令以分析瞬时故障:
show logging | inc “PUNT_FABRIC_DATA_PATH”show pfm location all
分析硬故障
如果将线卡上的交换矩阵数据路径链路作为树查看(详细信息在背景信息部分中描述),则必须根据故障点推断是否可以访问一个或多个NP。当多个NP上出现多个故障时,请使用本节中列出的命令来分析故障。
要使用的命令
输入以下命令以分析硬故障:
show logging | inc “PUNT_FABRIC_DATA_PATH”
输出可以包含一个或多个NP(例如:NP2、NP3)。show controller fabric fia link-status location
由于NP2和NP3(在“台风NP3诊断故障”部分)都通过单个FIA接收和发送,因此可以合理地推断故障在路径上的相关FIA中。show controller fabric crossbar link-status instance <0 and 1> location
如果无法到达诊断应用的线卡上的所有NP,则有理由推断将线卡插槽连接到路由处理器卡的链路可能在路由处理器卡和线卡之间转发流量的任何ASIC上发生故障。show controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp0/cpu0show controller fabric crossbar link-status instance 0 location 0/rsp1/cpu0show controller fabric crossbar link-status instance 1 location 0/rsp1/cpu0show controller fabric fia link-status location 0/rsp*/cpu0show controller fabric fia link-status location 0/rsp0/cpu0show controller fabric fia link-status location 0/rsp1/cpu0show controller fabric fia bridge sync-status location 0/rsp*/cpu0show controller fabric fia bridge sync-status location 0/rsp0/cpu0show controller fabric fia bridge sync-status location 0/rsp1/cpu0show tech fabric terminal
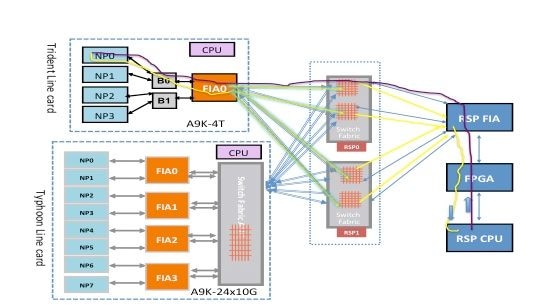
注:如果所有线路卡上的所有NP都报告故障,则故障最可能出现在路由处理器卡(活动路由处理器卡或备用路由处理器卡)上。请参阅背景信息部分中的链接,该链接将路由处理器卡CPU连接到FPGA和路由处理器卡FIA。
过去的故障
过去,99%的故障是可恢复的,在大多数情况下,软件启动的恢复操作会修复这些故障。但是,在极少数情况下,会出现无法恢复的错误,这些错误只能通过卡的RMA进行修复。
以下各节介绍过去遇到的一些故障,以便在发现类似错误时作为指导。
由于NP超订用导致的暂时性错误
如果错误是由于NP超订用,则会显示这些消息。
RP/0/RP1/CPU0:Jun 26 13:08:28.669 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0, 0)
RP/0/RP1/CPU0:Jun 26 13:09:28.692 : pfm_node_rp[349]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Clear|online_diag_rsp[200823]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP)
failed: (0/10/CPU0,0)
瞬时故障可能更难确认。一种确定NP当前是否超订用或过去是否超订用的方法是,检查NP内部是否存在某种类型的丢包和FIA中的尾部丢包。当NP超订用且无法跟上传入流量时,NP内部发生入口前端直接内存访问(IFDMA)丢弃。当出口NP断言流量控制(要求入口线卡发送较少的流量)时,就会发生FIA尾部丢弃。在流量控制场景下,入口FIA有尾部丢弃。
例如:
RP/0/RSP0/CPU0:RP/0/RSP0/CPU0:ASR9006-C#show controllers np counters all
Wed Feb 19 13:10:11.848 EST
Node: 0/1/CPU0:
----------------------------------------------------------------
Show global stats counters for NP0, revision v3
Read 93 non-zero NP counters:
Offset Counter FrameValue Rate (pps)
-----------------------------------------------------------------------
22 PARSE_ENET_RECEIVE_CNT 46913080435 118335
23 PARSE_FABRIC_RECEIVE_CNT 40175773071 5
24 PARSE_LOOPBACK_RECEIVE_CNT 5198971143966 0
<SNIP>
Show special stats counters for NP0, revision v3
Offset Counter CounterValue
----------------------------------------------------------------------------
524032 IFDMA discard stats counters 0 8008746088 0 <<<<<
例如:
RP/0/RSP0/CPU0:ASR9006-C#show controllers fabric fia drops ingress location 0/1/cPU0
Wed Feb 19 13:37:27.159 EST
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 0
Tail Drop-0 0 <<<<<<<
Tail Drop-1 0 <<<<<<<
Tail Drop-2 0 <<<<<<<
Tail Drop-3 0 <<<<<<<
Tail Drop DE-0 0
Tail Drop DE-1 0
Tail Drop DE-2 0
Tail Drop DE-3 0
Hard Drop-0 0
Hard Drop-1 0
Hard Drop-2 0
Hard Drop-3 0
Hard Drop DE-0 0
Hard Drop DE-1 0
Hard Drop DE-2 0
Hard Drop DE-3 0
WRED Drop-0 0
WRED Drop-1 0
WRED Drop-2 0
WRED Drop-3 0
WRED Drop DE-0 0
WRED Drop DE-1 0
WRED Drop DE-2 0
WRED Drop DE-3 0
Mc No Rep 0
由于NP快速重置导致的硬故障
当发生PUNT_FABRIC_DATA_PATH_FAILED时,如果故障是由于NP快速重置引起的,则显示与这里列出的日志类似的基于台风的线路卡。运行状况监控机制在基于台风的线路卡上可用,但在基于Trident的线路卡上不可用。
LC/0/2/CPU0:Aug 26 12:09:15.784 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:18.798 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:21.812 CEST: prm_server_ty[303]:
prm_inject_health_mon_pkt : Error injecting health packet for NP0
status = 0x80001702
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST:
prm_server_ty[303]: NP-DIAG health monitoring failure on NP0
LC/0/2/CPU0:Aug 26 12:09:24.815 CEST: pfm_node_lc[291]:
%PLATFORM-NP-0-NP_DIAG : Set|prm_server_ty[172112]|
Network Processor Unit(0x1008000)| NP diagnostics warning on NP0.
LC/0/2/CPU0:Aug 26 12:09:40.492 CEST: prm_server_ty[303]:
Starting fast reset for NP 0 LC/0/2/CPU0:Aug 26 12:09:40.524 CEST:
prm_server_ty[303]: Fast Reset NP0 - successful auto-recovery of NP
对于基于Trident的线卡,通过快速重置NP可看到此日志:
LC/0/1/CPU0:Mar 29 15:27:43.787 test:
pfm_node_lc[279]: Fast Reset initiated on NP3
RSP440路由处理器和Typhoon线路卡之间的故障
思科解决了路由交换机处理器(RSP)440和背板上的基于Typhoon的线卡之间很少重新训练交换矩阵链路的问题。交换矩阵链路会重新训练,因为信号强度不是最佳的。此问题出现在基本Cisco IOS® XR软件版本4.2.1、4.2.2、4.2.3、4.3.0、4.3.1和4.3.2中。Cisco Connection Online上发布了这些版本中的软件维护更新(SMU),并使用Cisco Bug ID CSCuj10837和Cisco Bug ID CSCul39674进行跟踪。
当路由器上出现此问题时,可能会出现以下任何一种情况:
- 链路断开并接通。(瞬态)
- 链路永久断开。
思科漏洞ID CSCuj10837 - RSP和LC之间的交换矩阵重新训练(TX方向)
为了确认,请收集LC和两个RSP的ltrace输出(show controller fabric crossbar ltrace location <>)并检查RSP跟踪中是否显示此输出:
SMU已经可用
例如:
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain:
destslot:0 fmlgrp:3 rc:0
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (2,0,7) initiated
Oct 1 08:22:58.969 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (2,1,0),(2,2,0),0.
术语TX方向是指从RSP交叉开关交换矩阵接口的立场朝向基于Typon的线卡上的交换矩阵交叉开关接口的方向。
Cisco Bug ID CSCuj10837的特点是,Typhoon线路卡从RSP检测到RX链路上的问题并启动链路重新训练。任何一方(LC或RSP)都可以发起重新训练事件。对于Cisco Bug ID CSCuj10837,LC将启动重新训练,并可通过LC跟踪中的init xbar_trigger_link_retrain:消息进行检测。
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Oct 1 08:22:58.967 crossbar 0/0/CPU0 t1 init xbar_trigger_link_retrain: destslot:
0 fmlgrp:3 rc:0
当LC启动重新训练时,RSP在trace输出中报告rcvd link_retrain。
RP/0/RSP0/CPU0:ios#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Oct 1 08:22:58.999 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (1,1,0),(2,1,0),1.
思科漏洞ID CSCul39674 - RSP和LC之间的交换矩阵重新培训(接收方向)
为了确认,请收集线路卡和两个RSP(show controller fabric crossbar ltrace location <>)并检查RSP跟踪中是否显示此输出:
例如:
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain:
destslot:4 fmlgrp:3 rc:0
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 detail xbar_pfm_alarm_callback:
xbar_trigger_link_retrain(): (5,1,11) initiated
Jan 8 17:28:39.256 crossbar 0/RSP1/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (5,1,1),(0,1,0),0.
术语RX方向是指从RSP交叉开关交换矩阵接口的角度出发,从基于Typhoon的线卡上的交换矩阵交叉开关接口开始的方向。
Cisco Bug ID CSCul39674的特点是RSP从Typhoon线路卡检测到RX链路上的问题并启动链路重新训练。任何一方(LC或RSP)都可以发起重新训练事件。对于Cisco Bug ID CSCul39674,RSP将启动重新培训,并可通过RSP跟踪中的init xbar_trigger_link_retrain:消息进行检测。
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/rsp0/cpu0 |
in link_retrain
Jan 8 17:28:39.207 crossbar 0/RSP1/CPU0 t1 init xbar_trigger_link_retrain: destslot:4 fmlgrp:
3 rc:0
当RSP启动重新训练时,LC在trace输出中报告rcvd link_retrain事件。
RP/0/RSP0/CPU0:asr9k-2#show controllers fabric ltrace crossbar location 0/0/cpu0 |
in link_retrain
Jan 8 17:28:39.215 crossbar 0/0/CPU0 t1 detail xbar_fmlc_handle_link_retrain:
rcvd link_retrain for (0,1,0),(5,1,1),0.
版本4.3.2及更高版本中的交换矩阵重新训练差异
为了缩短在Cisco IOS XR版本4.3.2及更高版本中重新培训交换矩阵链路所需的时间,已经做了大量工作。现在,交换矩阵重新训练的发生时间为亚秒级,流量无法察觉。在Cisco IOS XR版本4.3.2中,当交换矩阵链路重新训练发生时,只看到这些syslog消息。
%PLATFORM-FABMGR-5-FABRIC_TRANSIENT_FAULT : Fabric backplane crossbar link
underwent link retraining to recover from a transient error: Physical slot 1
由于交换矩阵ASIC FIFO溢出导致的故障
思科解决了交换矩阵ASIC(FIA)因不可恢复的先进先出(FIFO)溢出情况而重置的问题。这是通过Cisco Bug ID CSCul66510解决的。此问题仅影响基于Trident的线路卡,并且仅在入口路径严重拥塞的极少数情况下出现。如果遇到此问题,则会在重置线路卡以从此情况恢复之前显示此系统日志消息。
RP/0/RSP0/CPU0:asr9k-2#show log
LC/0/3/CPU0:Nov 13 03:46:38.860 utc: pfm_node_lc[284]:
%FABRIC-FIA-0-ASIC_FATAL_FAULT Set|fialc[159814]
|Fabric Interface(0x1014000)|Fabric interface asic ASIC1 encountered fatal
fault 0x1b - OC_DF_INT_PROT_ERR_0
LC/0/3/CPU0:Nov 13 03:46:38.863 utc: pfm_node_lc[284]:
%PLATFORM-PFM-0-CARD_RESET_REQ : pfm_dev_sm_perform_recovery_action,
Card reset requested by: Process ID:159814 (fialc), Fault Sev: 0, Target node:
0/3/CPU0, CompId: 0x10, Device Handle: 0x1014000, CondID: 2545, Fault Reason:
Fabric interface asic ASIC1 encountered fatal fault 0x1b - OC_DF_INT_PROT_ERR_0
由于交换矩阵拥塞导致虚拟输出队列(VOQ)生成量过大而失败
思科已经解决了以下问题:长时间严重拥塞可能导致交换矩阵资源耗尽和流量损失。流量丢失甚至可能发生在无关的流量上。此问题通过Cisco Bug ID CSCug90300解决,并在Cisco IOS XR版本4.3.2及更高版本中解决。Cisco IOS XR版本4.2.3 CSMU#3、Cisco bug ID CSCui3805中也提供了此修复程序。基于Trident或Typhoon的线路卡可能会遇到此罕见问题。
相关命令
从以下命令收集输出:
show tech-support fabricshow controller fabric fia bridge flow-control location<===获取所有LC的此输出show controllers fabric fia q-depth location
以下是一些示例输出:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia q-depth location 0/6/CPU0
Sun Dec 29 23:10:56.307 UTC
********** FIA-0 **********
Category: q_stats_a-0
Voq ddr pri pktcnt
11 0 2 7
********** FIA-0 **********
Category: q_stats_b-0
Voq ddr pri pktcnt
********** FIA-1 **********
Category: q_stats_a-1
Voq ddr pri pktcnt
11 0 0 2491
11 0 2 5701
********** FIA-1 **********
Category: q_stats_b-1
Voq ddr pri pktcnt
RP/0/RSP0/CPU0:asr9k-1#
RP/0/RSP0/CPU0:asr9k-1#show controllers pm location 0/1/CPU0 | in "switch|if"
Sun Dec 29 23:37:05.621 UTC
Ifname(2): TenGigE0_1_0_2, ifh: 0x2000200 : <==Corresponding interface ten 0/1/0/2
iftype 0x1e
switch_fabric_port 0xb <==== VQI 11
parent_ifh 0x0
parent_bundle_ifh 0x80009e0
RP/0/RSP0/CPU0:asr9k-1#
在正常情况下,数据包排队时很难看到VOQ。此命令是FIA队列的快速实时快照。此命令通常不会显示任何排队的数据包。
网桥/FPGA软错误对基于Trident的线卡造成的流量影响
软错误是导致状态机不同步的非永久性错误。在NP的交换矩阵端或FIA的入口端,这些数据包被视为循环冗余校验(CRC)、帧校验序列(FCS)或错误数据包。
以下是一些如何发现此问题的示例:
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia drops ingress location 0/3/CPU0
Fri Dec 6 19:50:42.135 UTC
********** FIA-0 **********
Category: in_drop-0
DDR Rx FIFO-0 0
DDR Rx FIFO-1 32609856 <=== Errors
RP/0/RSP0/CPU0:asr9k-1#show controllers fabric fia errors ingress location 0/3/CPU0
Fri Dec 6 19:50:48.934 UTC
********** FIA-0 **********
Category: in_error-0
DDR Rx CRC-0 0
DDR Rx CRC-1 32616455 <=== Errors
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/0/CPU0
Ingress Drop Stats (MC & UC combined)
**************************************
PriorityPacket Error Threshold
Direction Drops Drops
--------------------------------------------------
LP NP-3 to Fabric 0 0
HP NP-3 to Fabric 1750 0
RP/0/RSP1/CPU0:asr9k-1#
RP/0/RSP1/CPU0:asr9k-1#show controllers fabric fia bridge stats location 0/6/CPU0
Sat Jan 4 06:33:41.392 CST
********** FIA-0 **********
Category: bridge_in-0
UcH Fr Np-0 16867506
UcH Fr Np-1 115685
UcH Fr Np-2 104891
UcH Fr Np-3 105103
UcL Fr Np-0 1482833391
UcL Fr Np-1 31852547525
UcL Fr Np-2 3038838776
UcL Fr Np-3 30863851758
McH Fr Np-0 194999
McH Fr Np-1 793098
McH Fr Np-2 345046
McH Fr Np-3 453957
McL Fr Np-0 27567869
McL Fr Np-1 12613863
McL Fr Np-2 663139
McL Fr Np-3 21276923
Hp ErrFrNp-0 0
Hp ErrFrNp-1 0
Hp ErrFrNp-2 0
Hp ErrFrNp-3 0
Lp ErrFrNp-0 0
Lp ErrFrNp-1 0
Lp ErrFrNp-2 0
Lp ErrFrNp-3 0
Hp ThrFrNp-0 0
Hp ThrFrNp-1 0
Hp ThrFrNp-2 0
Hp ThrFrNp-3 0
Lp ThrFrNp-0 0
Lp ThrFrNp-1 0
Lp ThrFrNp-2 0
Lp ThrFrNp-3 0
********** FIA-0 **********
Category: bridge_eg-0
UcH to Np-0 779765
UcH to Np-1 3744578
UcH to Np-2 946908
UcH to Np-3 9764723
UcL to Np-0 1522490680
UcL to Np-1 32717279812
UcL to Np-2 3117563988
UcL to Np-3 29201555584
UcH ErrToNp-0 0
UcH ErrToNp-1 0
UcH ErrToNp-2 129 <==============
UcH ErrToNp-3 0
UcL ErrToNp-0 0
UcL ErrToNp-1 0
UcL ErrToNp-2 90359 <==========
针对基于Trident的线卡上的网桥/FPGA软错误收集的命令
从以下命令收集输出:
show tech-support fabricshow tech-support npshow controller fabric fia bridge stats location <>(获取多次)
从网桥/FPGA软错误中恢复
恢复方法是重新加载受影响的线路卡。
RP/0/RSP0/CPU0:asr9k-1#hw-module location 0/6/cpu0 reload
在线诊断测试报告
此 show diagnostic result location
命令提供所有联机诊断测试和失败以及测试通过时的最后时间戳的摘要。Punt交换矩阵数据路径故障的Test-ID为10。所有测试的列表以及测试数据包的频率可在 show diagnostic content location
命令。
punt交换矩阵数据路径测试结果的输出与以下示例输出类似:
RP/0/RSP0/CPU0:ios(admin)#show diagnostic result location 0/rsp0/cpu0 test 10 detail
Current bootup diagnostic level for RP 0/RSP0/CPU0: minimal
Test results: (. = Pass, F = Fail, U = Untested)
___________________________________________________________________________
10 ) FabricLoopback ------------------> .
Error code ------------------> 0 (DIAG_SUCCESS)
Total run count -------------> 357
Last test execution time ----> Sat Jan 10 18:55:46 2009
First test failure time -----> n/a
Last test failure time ------> n/a
Last test pass time ---------> Sat Jan 10 18:55:46 2009
Total failure count ---------> 0
Consecutive failure count ---> 0
自动恢复增强功能
如Cisco Bug ID CSCuc04493中所述,现在有一种方法可使路由器自动关闭与活动RP/RSP上发生的PUNT_FABRIC_DATA_PATH错误相关的所有端口。
第一种方法通过Cisco Bug ID CSCuc04493进行跟踪。对于版本4.2.3,此错误包含在Cisco Bug ID CSCui33805中。在此版本中,它设置为自动关闭与受影响的NP相关联的所有端口。
以下示例显示了系统日志的显示方式:
RP/0/RSP0/CPU0:Jun 10 16:11:26 BKK: pfm_node_rp[359]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System
Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/1/CPU0, 0)
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/0, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINK-3-UPDOWN : Interface
TenGigE0/1/0/1, changed state to Down
LC/0/1/CPU0:Jun 10 16:11:27 BKK: ifmgr[204]: %PKT_INFRA-LINEPROTO-5-UPDOWN : Line
protocol on Interface TenGigE0/1/0/1, changed state to Down
控制器指示接口关闭的原因是由于 DATA_PATH_DOWN.例如:
RP/0/RSP0/CPU0:ASR9006-E#show controllers gigabitEthernet 0/0/0/13 internal
Wed Dec 18 02:42:52.221 UTC
Port Number : 13
Port Type : GE
Transport mode : LAN
BIA MAC addr : 6c9c.ed08.3cbd
Oper. MAC addr : 6c9c.ed08.3cbd
Egress MAC addr : 6c9c.ed08.3cbd
Port Available : true
Status polling is : enabled
Status events are : enabled
I/F Handle : 0x04000400
Cfg Link Enabled : tx/rx enabled
H/W Tx Enable : no
UDLF enabled : no
SFP PWR DN Reason : 0x00000000
SFP Capability : 0x00000024
MTU : 1538
H/W Speed : 1 Gbps
H/W Duplex : Full
H/W Loopback Type : None
H/W FlowCtrl type : None
H/W AutoNeg Enable: Off
H/W Link Defects : (0x00080000) DATA_PATH_DOWN <<<<<<<<<<<
Link Up : no
Link Led Status : Link down -- Red
Input good underflow : 0
Input ucast underflow : 0
Output ucast underflow : 0
Input unknown opcode underflow: 0
Pluggable Present : yes
Pluggable Type : 1000BASE-LX
Pluggable Compl. : (Service Un) - Compliant
Pluggable Type Supp.: (Service Un) - Supported
Pluggable PID Supp. : (Service Un) - Supported
Pluggable Scan Flg: false
在版本4.3.1及更高版本中,必须启用此行为。为此,我们使用了一个新的admin-config命令。由于默认行为不再是关闭端口,因此必须手动配置此功能。
RP/0/RSP1/CPU0:ASR9010-A(admin-config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
在64位Cisco IOS XR上,配置命令在XR VM中可用(不在Sysadmin VM中):
RP/0/RSP0/CPU0:CORE-TOP(config)#fault-manager datapath port ?
shutdown Enable auto shutdown
toggle Enable auto toggle port status
Cisco Bug ID CSCui15435解决了基于Trident的线路卡上出现的软错误,如Traffic Impact Due to Bridge/FPGA Soft Errors on Trident线路卡部分所述。这使用的检测方法与Cisco Bug ID CSCuc04493中介绍的常规诊断方法不同。
此Bug还引入了一个新的admin-config CLI命令:
(admin-config)#fabric fia soft-error-monitor <1|2> location
1 = shutdown the ports
2 = reload the linecard
Default behavior: no action is taken.
遇到此错误时,可以观察此系统日志:
RP/0/RSP0/CPU0:Apr 30 22:17:11.351 : config[65777]: %MGBL-SYS-5-CONFIG_I : Configured
from console by root
LC/0/2/CPU0:Apr 30 22:18:52.252 : pfm_node_lc[283]:
%PLATFORM-BRIDGE-1-SOFT_ERROR_ALERT_1 : Set|fialc[159814]|NPU
Crossbar Fabric Interface Bridge(0x1024000)|Soft Error Detected on Bridge instance 1
RP/0/RSP0/CPU0:Apr 30 22:21:28.747 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|
System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3, (slot, NP) failed:
(0/2/CPU0, 2) (0/2/CPU0, 3)
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINK-3-UPDOWN :
Interface TenGigE0/2/0/2, changed state to Down
LC/0/2/CPU0:Apr 30 22:21:29.707 : ifmgr[194]: %PKT_INFRA-LINEPROTO-5-UPDOWN :
Line protocol on Interface TenGigE0/2/0/2, changed state to Down
RP/0/RSP1/CPU0:Apr 30 22:21:35.086 : pfm_node_rp[348]:
%PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED :
Set|online_diag_rsp[237646]|System Punt/Fabric/data Path Test(0x2000004)|failure
threshold is 3, (slot, NP) failed: (0/2/CPU0, 2) (0/2/CPU0, 3)
当受影响的端口关闭时,它允许网络冗余接管并避免流量黑洞。为了恢复,必须重新加载线路卡。
常见问题解答 (FAQ)
问:主路由处理器卡是否向系统中的每个NP发送keepalive或在线诊断数据包?
答:是的。两个路由处理器卡将联机诊断数据包发送到每个NP。
问:路由处理器卡1(RSP1)处于活动状态时,路径是否相同?
A.RSP0或RSP1的诊断路径相同。路径取决于RSP的状态。有关详细信息,请参阅本文档的交换矩阵诊断数据包路径部分。
问:RSP发送诊断数据包的频率如何?触发警报之前必须丢失多少诊断数据包?
A.每个RSP每分钟单独向每个NP发送一次诊断数据包。如果未确认三个诊断数据包,任一RSP都可以触发警报。
问:如何确定NP是否超额订用?
A.检查NP当前是否超订用或过去是否超订用的一种方法是检查NP内部是否存在某种类型的丢包和FIA中的尾部丢包。当NP超订用且无法跟上传入流量时,NP内部发生入口前端直接内存访问(IFDMA)丢弃。当出口NP断言流量控制(要求入口线卡发送较少的流量)时,就会发生FIA尾部丢弃。在流量控制场景下,入口FIA有尾部丢弃。
问:如何确定NP是否发生需要重置的故障?
A.通常通过快速重置清除NP故障。快速重置的原因会显示在日志中。
问:是否可以手动重置NP?
A.是,从线卡KSH:
run attach 0/[x]/CPU0 #show_np -e [np#] -d fast_reset
问:如果NP出现不可恢复的硬件故障,会显示什么?
答:您可以看到该NP的交换矩阵数据路径故障以及NP环回测试故障。NP环回测试失败消息将在本文档的附录部分讨论。
问:从一个路由处理器卡发出的诊断数据包是否会返回到同一个路由处理器卡?
A.由于诊断数据包来自两个路由处理器卡,并且按每个路由处理器卡进行跟踪,因此,来自路由处理器卡的诊断数据包被NP环回到同一个路由处理器卡。
问:Cisco Bug ID CSCuj10837 SMU为交换矩阵链路重新训练事件提供了修复方法。这是许多交换矩阵数据路径故障的原因和解决方案吗?
答:是,需要加载取代的SMU以查找Cisco Bug ID CSCul39674,从而避免交换矩阵链路重新培训事件。
问:一旦做出重新培训交换矩阵链路的决定,需要多长时间?
A.检测到链路故障后立即做出重新培训的决定。在版本4.3.2之前,重新培训可能需要几秒钟。版本4.3.2后,重新训练时间显着缩短,且花费不到一秒。
问:何时决定重新训练交换矩阵链路?
A.一旦检测到链路故障,交换矩阵ASIC驱动程序就会决定重新培训。
问:只是在活动路由处理器卡上的FIA与您使用第一个链路的交换矩阵之间,然后当有多个链路可用时,它是负载最低的链路吗?
A.正确。使用连接到主用路由处理器上的第一个XBAR实例的第一条链路将流量注入交换矩阵。来自NP的响应数据包可以返回连接到路由处理器卡的所有链路上的活动路由处理器卡。链路的选择取决于链路负载。
问:在重新培训期间,通过该交换矩阵链路发送的所有数据包是否都丢失了?
答:是,但是随着版本4.3.2及更高版本的增强功能,重新训练几乎无法检测。但是,在早期的代码中,可能需要几秒钟进行重新训练,这导致该时间段的数据包丢失。
问:在升级到版本或SMU并修复Cisco Bug ID CSCuj10837后,您预计多长时间会看到XBAR交换矩阵链路重新培训事件?
答:即使使用针对Cisco Bug ID CSCuj10837的修复程序,仍有可能由于Cisco Bug ID CSCul39674而看到交换矩阵链路重新培训。但是,一旦您对Cisco Bug ID CSCul39674进行了修复,RSP440和基于Typhoon的线卡之间的交换矩阵背板链路的交换矩阵链路再培训就永远不会发生。如果是,请向思科技术支持中心(TAC)提出服务请求以解决问题。
问:Cisco Bug ID CSCuj10837和Cisco Bug ID CSCul39674是否会影响ASR 9922上带有基于台风的线路卡的RP?
A.是
问:Cisco Bug ID CSCuj10837和Cisco Bug ID CSCul39674是否会影响ASR-9001和ASR-9001-S路由器?
A.否
问:如果遇到插槽故障,而此消息并不存在,则在10插槽机箱中,哪个插槽存在此问题?“PLATFORM-DIAGS-3-PUNT_FABRIC_DATA_PATH_FAILED : Set|online_diag_rsp[237686]|System Punt/Fabric/data Path Test(0x2000004)|failure threshold is 3,(slot, NP)failed:(8, 0)”。
A.在早期版本中,必须考虑物理和逻辑映射,如下所示。在本示例中,插槽8对应于0/6/CPU0。
For 9010 (10 slot chassis)
L P
#0 --- #0
#1 --- #1
#2 --- #2
#3 --- #3
RSP0 --- #4
RSP1 --- #5
#4 --- #6
#5 --- #7
#6 --- #8
#7 --- #9
For 9006 (6 slot chassis)
L P
RSP0 --- #0
RSP1 --- #1
#0 --- #2
#1 --- #3
#2 --- #4
#3 --- #5
创建服务请求之前要收集的数据
以下是执行任何操作之前收集输出的最少命令:
show loggingshow pfm location alladmin show diagn result loc 0/rsp0/cpu0 test 8 detailadmin show diagn result loc 0/rsp1/cpu0 test 8 detailadmin show diagn result loc 0/rsp0/cpu0 test 9 detailadmin show diagn result loc 0/rsp1/cpu0 test 9 detailadmin show diagn result loc 0/rsp0/cpu0 test 10 detailadmin show diagn result loc 0/rsp1/cpu0 test 10 detailadmin show diagn result loc 0/rsp0/cpu0 test 11 detailadmin show diagn result loc 0/rsp1/cpu0 test 11 detailshow controller fabric fia link-status locationshow controller fabric fia link-status locationshow controller fabric fia bridge sync-status locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 0 locationshow controller fabric crossbar link-status instance 1 locationshow controller fabric ltrace crossbar locationshow controller fabric ltrace crossbar locationshow tech fabric locationshow tech fabric locationfile
有用的诊断命令
以下是可用于诊断目的的命令列表:
show diagnostic ondemand settingsshow diagnostic content location < loc >show diagnostic result location < loc > [ test {id|id_list|all} ] [ detail ]show diagnostic statusadmin diagnostic start location < loc > test {id|id_list|test-suite}admin diagnostic stop location < loc >- admin diagnostic ondemand iterations < iteration-count >
admin diagnostic ondemand action-on-failure {continue failure-count|stop}- admin-config#
[ no ] diagnostic monitor location < loc > test {id | test-name} [disable] - admin-config#
[ no ] diagnostic monitor interval location < loc > test {id | test-name} day hour:minute:second.millisec - admin-config#
[ no ] diagnostic monitor threshold location < loc > test {id | test-name} failure count
结论
从Cisco IOS XR软件版本4.3.4的时间框架中,可以解决与交换矩阵数据路径故障相关的大部分问题。对于受Cisco Bug ID CSCuj10837和Cisco Bug ID CSCul39674影响的路由器,请为Cisco Bug ID CSCul39674加载取代的SMU,以避免交换矩阵链路重新训练事件。
平台团队安装了最先进的故障处理,因此当发生任何数据路径可恢复故障时,路由器可在数秒内恢复。但是,建议使用本文档了解此问题,即使未发现此类故障。
Appendix
NP环回诊断路径
在线卡CPU上执行的诊断应用程序通过定期检查NP的工作状态来跟踪每个NP的运行状况。从线路卡CPU将数据包注入本地NP,NP应环回并返回到线路卡CPU。此类定期数据包中的任何丢失都会用平台日志消息进行标记。以下是此类消息的一个示例:
LC/0/7/CPU0:Aug 18 19:17:26.924 : pfm_node[182]:
%PLATFORM-PFM_DIAGS-2-LC_NP_LOOPBACK_FAILED : Set|online_diag_lc[94283]|
Line card NP loopback Test(0x2000006)|link failure mask is 0x8
此日志消息表示此测试无法从NP3接收环回数据包。链路故障掩码为0x8(位3已设置),表示插槽7的线卡CPU与插槽7上的NP3之间发生故障。
要获取更多详细信息,请收集以下命令的输出:
admin show diagnostic result location 0//cpu0 test 9 detail show controllers NP counter NP<0-3> location 0//cpu0
交换矩阵调试命令
本节中列出的命令适用于所有基于Trident的线路卡以及基于Typhoon的100GE线路卡。基于台风的线路卡上没有Bridge FPGA ASIC(基于100GE台风的线路卡除外)。所以, show controller fabric fia bridge 命令不适用于基于Typhoon的线路卡,但100GE版本除外。
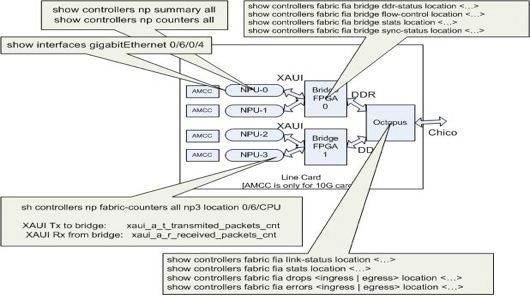
此图形表示有助于将每个show命令映射到数据路径中的位置。使用这些show命令来隔离数据包丢弃和故障。
修订历史记录
| 版本 | 发布日期 | 备注 |
|---|---|---|
2.0 |
26-Jun-2023 |
已更新思科漏洞ID CSCuc04493的自动恢复增强功能部分,并更新了“常见问题”部分。 |
1.0 |
29-Oct-2013 |
初始版本 |
由思科工程师提供
- 马赫什·希尔夏德思科TAC工程师
- 大卫·鲍尔斯思科TAC工程师
- 让 — 克里斯托夫·罗德思科TAC工程师
 反馈
反馈