简介
本文档介绍BFD Hello数据包和应用感知路由隧道统计信息之间的关系。
先决条件
要求
思科建议您先了解下列主题的相关知识:
- Cisco Catalyst软件定义的广域网(SD-WAN)。
- 应用感知路由。
- BFD。
使用的组件
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
- Cisco Catalyst SD-WAN Manager。
- Cisco IOS® XE Catalyst SD-WAN边缘。
背景信息
双向转发检测(BFD)协议在Cisco IOS-XE Catalyst SD-WAN设备之间的所有数据平面隧道上运行。此协议用于监控隧道的活性和路径特性,例如报告为丢失、抖动和延迟的隧道性能。
边缘设备使用BFD Hello探针测量隧道上的数据包丢失、抖动和延迟。这些统计信息针对每个BFD Hello探测进行计算,并获取在称为轮询间隔的滑动时间窗口上。
应用感知路由使用这些丢失、延迟和抖动统计信息,根据策略中设置的要求传输流量,这些要求称为SLA类,其中确定在选择传输数据的隧道中允许的最大丢失、抖动和延迟。
因此,了解度量值的计算方式以及BFD值的更改如何影响隧道性能计算主要是平均损失非常重要。BFD参数包括:
| 参数 |
默认值 |
范围 |
使用 |
| BFD hello间隔
|
1 秒 |
1到65535秒 |
用于检测隧道连接的活动性和检测隧道上的故障的数据包。 |
| 轮询间隔 |
10分钟 (600,000毫秒) |
1 - 4,294,967毫秒 |
计算时段度量以提供统计信息的频率。 |
| 乘数 |
6 |
1 - 6 |
乘以轮询间隔以指定计算平均丢失、平均延迟和平均抖动的时间的值。
此值确定存储桶的数量。 |
隧道性能统计信息计算
对于设置为默认设置的BFD参数,统计信息的计算如下:
轮询间隔/ BFD Hello间隔= 600,000 ms / 1000 ms = 600 BFD问询/桶。
由于乘数设置为6,这意味着使用6个存储段来计算平均延迟、抖动和损耗。使用默认值等于1小时。此总时间也称为app-route间隔。
应用路由间隔=轮询间隔*乘数= 600,000毫秒x 6 = 3,600,000毫秒,等于1小时。
应用感知路由使用应用路由统计信息的计算来确定数据平面中的更改。为了使边缘设备利用应用路由统计信息,必须在AAR策略中指定SLA类,其中设置了可接受的最大数据包抖动、丢失和延迟。这些SLA类在AAR策略中用于根据SLA路由指定应用的流量。
在边缘设备中配置后,AAR统计信息用于与用所有存储段(在整个应用路由间隔内)计算的统计信息提供的平均丢失、平均延迟和平均抖动进行比较。此外,还必须注意,默认情况下,SLA会在每个轮询间隔之后每十分钟更新一次。
要获得平均损失、平均抖动和平均延迟,使用的公式为:
平均丢失=(所有存储段的总丢失* 100)/数据包总数。
平均延迟=(所有存储段上的总损失)/存储段的数量。
平均抖动=(所有存储段上的总抖动)/存储段数量。
可以在CLI中使用以下内容查看这些值与每个桶的平均值的计算:
vEdge#show app-route stats
cEdge#show sdwan app-route stats
而在GUI中,平均丢失、平均延迟和平均抖动只能在Monitor > Overview > Application-Aware Routing部分中查看。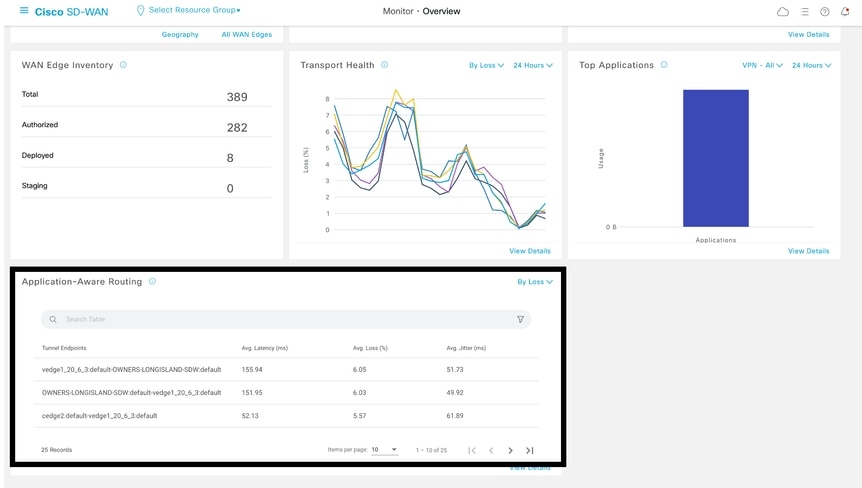
也可以在Monitor > Devices > Select Device > WAN > Tunnel部分中查看它。
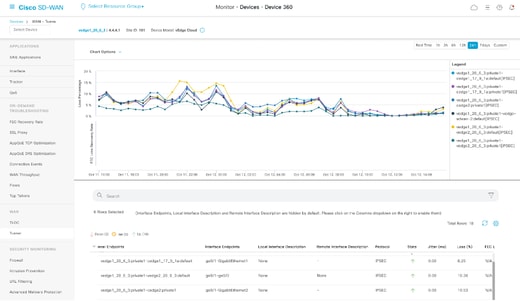
BFD值与损耗的关系示例
由于BFD Hello是可配置的值,因此可以根据需求进行修改;但是,在仔细考虑之后对其进行修改非常重要,否则可能会收到倾斜计算或误报统计信息,因为平均损失计算的准确性取决于BFD值。例如,默认值为:
| 参数 |
默认 |
| BFD hello数据包 |
1 秒 |
| 轮询间隔 |
(600,000毫秒) 10分钟 |
| 乘数 |
6 |
vEdge1# show app-route stats
app-route statistics 10.100.100.2 10.200.200.4 ipsec 12366 12346
remote-system-ip 10.1.1.1
local-color private1
remote-color private1
mean-loss 1
mean-latency 110
mean-jitter 51
sla-class-index 0,2
IPV6 TX IPV6 RX
TOTAL AVERAGE AVERAGE TX DATA RX DATA DATA DATA
INDEX PACKETS LOSS LATENCY JITTER PKTS PKTS PKTS PKTS
----------------------------------------------------------------------------
0 596 7 110 50 0 0 0 0
1 596 5 111 50 0 1 0 0
2 597 13 111 53 0 0 0 0
3 594 4 111 53 0 0 0 0
4 596 5 110 50 0 0 0 0
5 594 12 111 50 0 2 0 0
平均损耗=((7+5+13+4+5+12)100)/(596+596+597+594+596+594)
= 4600/3573
= 1.28 ~ 1%
平均延迟=(110+111+111+111+110+111)/6
= 110.66 ~ 110毫秒
平均抖动=(50+50+53+53+50+50)/ 6
= 3 /6 = 51毫秒
注:对于完成的每个计算,仅提供整数值。即使十进制是精确结果,也会将整数值四舍五入到最接近的较低整数。
通常,最好修改这些值以使计算更加频繁,但可能会造成重大影响;例如,如果轮询间隔不是默认值,则会被修改为:
| 参数 |
默认 |
| BFD hello数据包 |
1 秒 |
| 轮询间隔 |
(60,000毫秒) 1分钟 |
| 乘数 |
6 |
此更改意味着它使用1 x 60 = 60个数据包/桶而不是默认的600个数据包。平均损失的结果是:
vEdge1# show app-route stats
app-route statistics 10.100.100.2 10.200.200.4 ipsec 12366 12346
remote-system-ip 10.1.1.1
local-color private1
remote-color private1
mean-loss 3
mean-latency 112
mean-jitter 51
sla-class-index 0,2
IPV6 TX IPV6 RX
TOTAL AVERAGE AVERAGE TX DATA RX DATA DATA DATA
INDEX PACKETS LOSS LATENCY JITTER PKTS PKTS PKTS PKTS
----------------------------------------------------------------------------
0 59 1 113 53 0 0 0 0
1 60 3 111 52 0 1 0 0
2 59 1 111 51 0 1 0 0
3 60 3 111 50 0 1 0 0
4 60 2 115 50 0 0 0 0
5 59 1 111 50 0 2 0 0
平均损耗=((1+3+1+3+2+1)*100)/(59+60+59+60+60+59)
=(1100)/ 357
= 3.08 ~ 3%
此时,如果将SLA类设置为最大损失3,则隧道在违反SLA的限制下。但是,如果将轮询间隔修改为:
| 参数 |
默认 |
| BFD hello数据包 |
1 秒 |
| 轮询间隔 |
(6,000毫秒) 1 秒 |
| 乘数 |
6 |
此更改意味着它使用1 x 6 = 6个数据包/桶而不是默认的600个数据包。平均损失的结果是:
vEdge1# show app-route stats
app-route statistics 10.100.100.2 10.200.200.4 ipsec 12366 12346
remote-system-ip 10.1.1.1
local-color private1
remote-color private1
mean-loss 17
mean-latency 110
mean-jitter 0
sla-class-index None
IPV6 TX IPV6 RX
TOTAL AVERAGE AVERAGE TX DATA RX DATA DATA DATA
INDEX PACKETS LOSS LATENCY JITTER PKTS PKTS PKTS PKTS
----------------------------------------------------------------------------
0 5 1 113 2 0 0 0 0
1 6 1 110 1 0 1 0 0
2 6 1 111 2 0 0 0 0
3 6 0 111 0 0 0 0 0
4 6 1 111 0 0 0 0 0
5 6 1 111 0 0 2 0 0
平均损耗=((5)100)/(5+6+6+6+6+6)
=(500)/29
= 17.24 ~ 17%
无论是否缩短轮询间隔而不正确验证用于测量的数据包数量,都会影响平均损失,如果bfd hello — 间隔增加而不增加池间隔,同样的情况也会适用。
在最后一个示例中,由于使用的数据包很少,只有一个数据包丢失,因此平均丢失会受到显着影响。 这些计算的结果是应用感知策略行为,具有多次非常频繁的故障转移。
这种解释的目的并不是要避免对这些值的修改,相反,在许多情况下需要修改这些探针。这完全取决于网络要求,但检查可以减少多少hello数据包非常重要。
全局修改轮询间隔的配置命令为:
vEdge(config)# bfd app-route poll-interval 600000
 反馈
反馈