简介
本文档介绍从云本地部署平台(CNDP)设置中的初始服务器恢复Cluster Manager的过程。
先决条件
要求
Cisco 建议您了解以下主题:
- 思科用户微服务基础设施(SMI)
- 5G CNDP或SMI裸机(BM)架构
- 分布式复制块设备(DRBD)
使用的组件
本文档中的信息基于以下软件和硬件版本:
- SMI 2020.02.2.35
- Kubernetes v1.21.0
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
背景信息
什么是SMI Cluster Manager?
集群管理器是一个双节点保持连接的集群,用作控制平面和用户平面集群部署的初始点。它运行一个单节点Kubernetes集群和一组POD,负责整个集群设置。只有主群集管理器处于活动状态,辅助群集管理器仅在出现故障时进行接管,或手动关闭以进行维护。
什么是初始服务器?
此节点对作为基础的集群管理器(CM)执行生命周期管理,您可以在此处推送第0天配置。
此服务器通常按地区部署,或者与顶级协调功能(例如NSO)位于同一数据中心内,通常作为VM运行。
问题
集群管理器托管在带有分布式复制块设备(DRBD)的双节点集群中,并保留为Cluster Manager主集群和Cluster Manager辅助集群。在这种情况下,在UCS中初始化/安装OS时,Cluster Manager辅助自动进入关闭状态,这表示操作系统已损坏。
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 WFConnection Primary/Unknown UpToDate/DUnknown /mnt/stateful_partition ext4 568G 369G 170G 69%
维护程序
此过程有助于在CM服务器上重新安装操作系统。
确定主机
登录到Cluster-Manager并确定主机:
cloud-user@POD-NAME-cm-primary:~$ cat /etc/hosts | grep 'deployer-cm'
127.X.X.X POD-NAME-cm-primary POD-NAME-cm-primary
X.X.X.X POD-NAME-cm-primary
X.X.X.Y POD-NAME-cm-secondary
从初始服务器确定集群详细信息
登录到Insight服务器并进入Deployer,然后从Cluster-Manager使用hosts-IP验证集群名称。
成功登录初始服务器后,按此处所示登录到运营中心。
user@inception-server: ~$ ssh -p 2022 admin@localhost
从集群管理器SSH-IP验证集群名称(ssh-ip =节点SSH IP地址= ucs-server cimc ip地址)。
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tab
SSH
NAME NAME IP SSH IP IP ADDRESS
------------------------------------------------------------------------------
POD-NAME-deployer cm-primary - X.X.X.X 10.X.X.X ---> Verify Name and SSH IP if Cluster is part of inception server SMI.
cm-secondary - X.X.X.Y 10.X.X.Y
检查目标群集的配置。
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME-deployer
移除虚拟驱动器以清除服务器上的操作系统
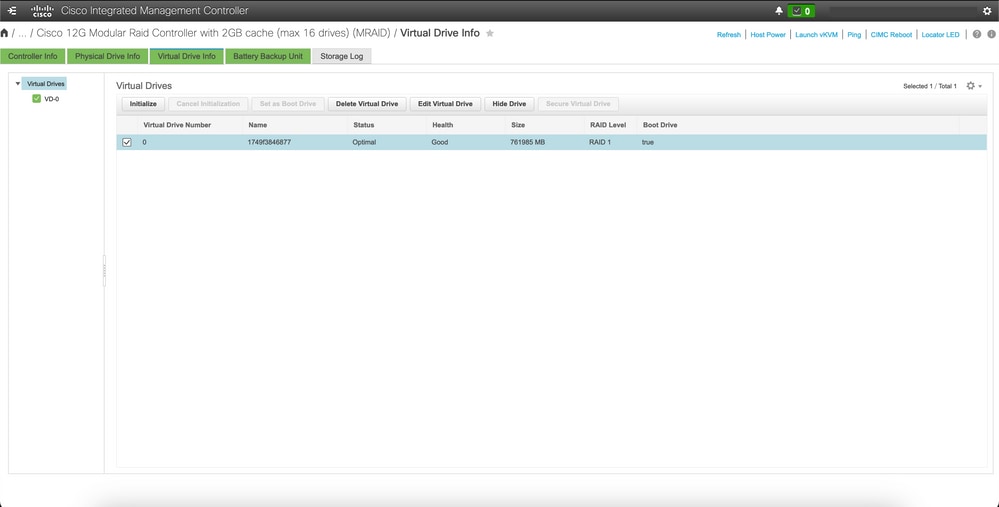
连接到受影响主机的CIMC,清除引导驱动器并删除虚拟驱动器(VD)。
a) CIMC > Storage > Cisco 12G Modular Raid Controller > Storage Log > Clear Boot Drive
b) CIMC > Storage > Cisco 12G Modular Raid Controller > Virtual drive > Select the virtual drive > Delete Virtual Drive
运行集群同步
从初始服务器运行Cluster-Manager的默认群集同步。
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
如果默认群集同步失败,请使用force-vm redeploy选项执行群集同步,以完成重新安装(群集同步活动可能需要约45-55分钟才能完成,具体取决于群集上托管的节点数量)
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true force-vm-redeploy true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
监控集群同步同步日志
[inception-server] SMI Cluster Deployer# monitor sync-logs POD-NAME-deployer
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Cluster name: POD-NAME
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Force VM Redeploy: true
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: Force partition Redeploy: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: reset_k8s_nodes: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: purge_data_disks: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: upgrade_strategy: auto
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: sync_phase: all
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: debug: true
...
...
...
服务器通过成功的集群同步重新调配和安装。
PLAY RECAP *********************************************************************
cm-primary : ok=535 changed=250 unreachable=0 failed=0 skipped=832 rescued=0 ignored=0
cm-secondary : ok=299 changed=166 unreachable=0 failed=0 skipped=627 rescued=0 ignored=0
localhost : ok=59 changed=8 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
Thursday 23 February 2023 13:17:24 +0000 (0:00:00.109) 0:56:20.544 *****. ---> ~56 mins to complete cluster sync
===============================================================================
2023-02-23 13:17:24.539 DEBUG cluster_sync.POD-NAME: Cluster sync successful
2023-02-23 13:17:24.546 DEBUG cluster_sync.POD-NAME: Ansible sync done
2023-02-23 13:17:24.546 INFO cluster_sync.POD-NAME: _sync finished. Opening lock
确认
检查受影响的Cluster Manager是否可访问,以及主要和辅助群集管理器的DRBD概述处于UpToDate状态。
cloud-user@POD-NAME-cm-primary:~$ ping X.X.X.Y
PING X.X.X.Y (X.X.X.Y) 56(84) bytes of data.
64 bytes from X.X.X.Y: icmp_seq=1 ttl=64 time=0.221 ms
64 bytes from X.X.X.Y: icmp_seq=2 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=3 ttl=64 time=0.151 ms
64 bytes from X.X.X.Y: icmp_seq=4 ttl=64 time=0.154 ms
64 bytes from X.X.X.Y: icmp_seq=5 ttl=64 time=0.172 ms
64 bytes from X.X.X.Y: icmp_seq=6 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=7 ttl=64 time=0.174 ms
--- X.X.X.Y ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 6150ms
rtt min/avg/max/mdev = 0.151/0.171/0.221/0.026 ms
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 Connected Primary/Secondary UpToDate/UpToDate /mnt/stateful_partition ext4 568G 17G 523G 4%
受影响的群集管理器已安装并已成功重新调配到网络。
2.2从Cluster Manager SSH-IP检验集群名称。
[initial-server] SMI Cluster Deployer# show running-config clusters *节点* k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | 选项卡
SSH
名称名称IP SSH IP IP地址
------------------------------------------------------------------------------
POD-NAME cm-primary - 192.X.X.X 10.192.X.X
cm-secondary - 192.X.X.Y 10.192.X.Y
*SSH IP =节点SSH IP
*IP ADDRESS = ucs-server cimc ip-address
2.3检查目标群集的配置。
[insight-server] SMI Cluster Deployer# show running-config clusters POD-NAME登录到Insight服务器并进入Deployer,然后从Cluster-Manager使用hosts-IP验证cluster-name。 登录到Insight服务器,进入Deployer,并从Cluster-Manager使用hosts-IP验证cluster-name。
 反馈
反馈