在 Cisco Secure Firewall 3100/4200上为 ASA 部署集群
集群允许您将多个 ASA 作为单一逻辑设备组合到一起。集群具有单个设备的全部便捷性(管理、集成到一个网络中),同时还能实现吞吐量增加和多个设备的冗余性。
 注 |
关于 ASA 集群
本节介绍集群架构及其工作原理。
集群如何融入网络中
集群包含多台防火墙,作为单一设备工作。要用作集群,该防火墙需要以下基础设施:
-
独立的高速背板网络(称为集群控制链路)用于集群内的通信。
-
对每台防火墙的管理访问权限,用于进行配置和监控。
将集群接入网络中时,上游和下游路由器需要能够使用 跨区域以太网通道。将多个集群成员上的接口分组为一个 EtherChannel;EtherChannel 在设备之间执行负载均衡。
集群成员
集群成员协调工作来实现安全策略和流量的共享。本节介绍每种成员角色的性质。
引导程序配置
您要在每台设备上配置最低的引导程序配置,包括集群名称、集群控制链路接口和其他集群设置。启用集群的第一个节点通常成为控制节点。在后续节点上启用集群时,这些设备将作为数据节点加入集群。
控制和数据节点角色
一个集群成员是控制节点。如果多个集群节点同时上线,则控制节点由引导程序配置中的优先级设置决定;优先级可设置为 1 到 100,其中 1 为最高优先级。所有其他成员都是数据节点。 通常,当您首次创建集群时,您添加的第一个节点会成为控制节点,因为它是到目前为止集群中的唯一节点。
必须只能在控制节点上执行所有配置(引导程序配置除外);然后配置将被复制到数据节点中。如果是接口等物理资产,控制节点的配置将被镜像到所有数据节点。例如,如果将以太网接口 1/2 配置为内部接口,将以太网接口 1/1 配置为外部接口,则这些接口也将在数据节点上用作内部和外部接口。
有些功能在集群中无法扩展,控制节点将处理这些功能的所有流量。
集群接口
您可以将数据接口配置为 跨区以太网通道。有关详细信息,请参阅关于集群接口。
注 |
除管理接口以外,不支持单个接口。 |
集群控制链路
每台设备至少必须将一个硬件接口专门用作集群控制链路。有关详细信息,请参阅集群控制链路。
配置复制
集群中的所有节点共享一个配置。您只能在控制节点上进行配置更改(引导程序配置除外),这些更改会自动同步到集群中的所有其他节点。
ASA 集群管理
使用 ASA 集群的优势之一是易于管理。本节介绍如何管理集群。
管理网络
我们建议将所有设备都连接到一个管理网络。此网络与集群控制链路分隔开来。
管理接口
对于管理接口,我们建议使用一个专用管理接口。您可以将管理接口配置为独立接口(适用于路由和透明模式)或跨区以太网通道接口。
即便使用跨区以太网通道作为数据接口,我们仍然建议使用独立接口作为管理接口。独立接口可以根据需要直接连接到每台设备,而跨区以太网通道接口则只允许远程连接到当前的控制单元。
注 |
您无法为管理接口启用动态路由。您必须使用静态路由。 |
对于单个接口,主集群 IP 地址是集群的固定地址,始终属于当前的控制设备。您还要为每个接口配置一个地址范围,以便包括当前控制设备在内的每台设备都可以使用该范围内的本地地址。主集群 IP 地址提供对地址的统一管理访问;当主设备更改时,主集群 IP 地址将转移到新的主设备,使集群的管理得以无缝继续。本地 IP 地址用于路由,在排除故障时也非常有用。
例如,您可以连接到主集群 IP 地址来管理集群,该地址始终属于当前的控制设备。要管理单个成员,您可以连接到本地 IP 地址。
对于 TFTP 或系统日志等出站管理流量,包括控制设备在内的每台设备都使用本地 IP 地址连接到服务器。
对于跨区以太网通道接口,您只能配置一个 IP 地址,该 IP 地址始终属于控制设备。您无法使用 EtherChannel 接口直接连接到数据单元;我们建议将管理接口配置为独立接口,以便您连接到每台设备。请注意,您可以使用设备本地 EtherChannel 进行管理。
控制设备管理与数据设备管理
所有管理和监控均可在控制节点上进行。从控制节点中,您可以检查所有节点的运行时统计信息、资源使用情况或其他监控信息。您也可以向集群中的所有节点发出命令,并将控制台消息从数据节点复制到控制节点。
如果需要,您可以直接监控数据节点。虽然在控制节点上可以执行文件管理,但在数据节点上也可以如此(包括备份配置和更新映像)。以下功能在控制节点上不可用:
-
监控每个节点的集群特定统计信息。
-
监控每个节点的系统日志(控制台复制启用时发送至控制台的系统日志除外)。
-
SNMP
-
NetFlow
加密密钥复制
当您在控制节点上创建加密密钥时,该密钥将复制到所有数据节点。如果您有连接到主集群 IP 地址的 SSH 会话,则控制节点发生故障时连接将断开。新控制节点对 SSH 连接使用相同的密钥,这样当您重新连接到新的控制节点时,无需更新缓存的 SSH 主机密钥。
ASDM 连接证书 IP 地址不匹配
默认情况下,ASDM 连接将根据本地 IP 地址使用自签名证书。如果使用 ASDM 连接到主集群 IP 地址,则可能会因证书使用的是本地 IP 地址而不是主集群 IP 地址,系统会显示一则警告消息,指出 IP 地址不匹配。您可以忽略该消息并建立 ASDM 连接。但是,为了避免此类警告,您也可以注册一个包含主集群 IP 地址和 IP 地址池中所有本地 IP 地址的证书。然后,您可将此证书用于每个集群成员。有关详细信息,请参阅 https://www.cisco.com/c/en/us/td/docs/security/asdm/identity-cert/cert-install.html。
站点间集群
对于站点间安装,您只要遵循建议的准则即可充分发挥 ASA 集群的优势。
您可以将每个集群机箱配置为属于单独的站点 ID。
站点 ID 与站点特定的 MAC 地址和 IP 地址配合使用。集群发出的数据包使用站点特定的 MAC 地址和 IP 地址,而集群接收的数据包使用全局 MAC 地址和 IP 地址。此功能可防止交换机从两个不同端口上的两个站点获知相同全局 MAC 地址,导致 MAC 地址摆动;相反,它们仅获知站点 MAC 地址。只有使用跨区以太网通道的路由模式支持站点特定的 MAC 地址和 IP 地址。
站点 ID 还用于使用 LISP 检查、导向器本地化来实现流量移动,以提高性能、减少数据中心的站点间集群的往返时间延迟以及连接的站点冗余,其中流量流的备用所有者始终位于与所有者不同的站点上。
ASA 集群许可证
智能软件管理器常规版和本地版
每台设备需要Essentials许可证(默认启用)和相同的加密许可证。我们建议在启用集群之前使用许可服务器对每台设备进行许可,避免出现许可不匹配的问题,并在使用强加密许可证时出现集群控制链路加密问题。
集群功能本身不需要任何许可证。数据设备上的情景许可证不会产生额外成本。
当您应用注册令牌时,系统会自动为符合条件的用户启用强加密许可证。对于在 ASA 配置中启用的可选强加密 (3DES/AES) 功能许可证,请参阅下文。
在 ASA 许可证配置中,默认情况下,始终在所有设备上启用Essentials许可证。您只能在控制设备上配置智能许可。该配置会复制到数据设备,但某些许可证不使用该配置;它仍处于缓存状态,只有控制设备才会请求许可证。这些许可证将聚合成一个由集群设备共享的集群许可证,此聚合许可证也会缓存在数据设备上,以便将来某个从属设备变为控制设备时使用。各个许可证类型将按以下方式进行管理:
-
Essentials — 每台设备都会向服务器请求一个Essentials许可证。
-
情景 - 只有控制设备从服务器请求情景许可证。默认情况下,Essentials许可证包括 2 个情景,并且位于所有集群成员上。每台设备的Essentials许可证的值加上控制设备上的情景许可证的值共同形成了聚合集群许可证中的平台限制。例如:
-
您在集群中有 6 个 Cisco Secure Firewall 3100。Essentials许可证包括 2 个情景;因为有 6 台设备,因此这些许可证加起来总共包括 12 个情景。您在控制设备上额外配置一个包含 20 个情景的许可证。因此,聚合的集群许可证包括 32 个情景。由于一台机箱的平台限制为 100,因此合并许可证最多允许 100 个情景;32 个情景在该限制范围内。因此,您可以在控制设备上配置最多 32 个情景;每台数据设备通过配置复制也将拥有 32 个情景。
-
您在集群中有 3 个 Cisco Secure Firewall 3100。Essentials许可证包括 2 个情景;因为有 3 台设备,因此这些许可证加起来总共包括 6 个情景。您在控制设备上额外配置一个包含 100 个情景的许可证。因此,聚合的集群许可证包括 106 个情景。由于一台设备的平台限制为 100,因此合并许可证最多允许 100 个情景;106 个情景超出限制范围。因此,您仅可以在控制设备上配置最多 100 个情景;每台数据设备通过配置复制也将拥有 100 个情景。在此情况下,只能将控制设备情景许可证配置为 94 个情景。
-
-
强加密 (3DES) - 如果您的智能账户未获得强加密授权,但 Cisco 已确定允许您使用强加密,您可以手动将强加密许可证添加到您的账户。只有控制设备需要请求此许可证,并且由于许可证聚合,两台设备均可使用它。
如果选择了新的控制设备,新的控制设备继续使用聚合的许可证。它还会使用缓存的许可证配置再次请求控制设备许可证。当旧的控制设备作为数据设备重新加入集群后,它会释放控制设备许可证授权。在数据设备释放该许可证之前,如果帐户中没有可用的许可证,则控制设备的许可证可能处于一个非合规状态。保留的许可证的有效期为 30 天,但如果它在此宽限期过后仍处于非合规状态,您将无法对需要特殊许可证的功能进行配置更改;否则操作将不受影响。新主用设备会每隔 35 秒发送一次权限授权续约请求,直到许可证合规为止。在对许可证请求进行完整的处理之前,应避免进行配置更改。如果某台设备退出集群,缓存的控制配置将被删除,而按设备进行的授权将会保留。尤其是,您需要在非集群设备上重新请求情景许可证。
永久许可证预留
对于永久许可证预留,必须在配置集群之前为每个机箱单独购买许可证并启用。
ASA 集群要求和前提条件
型号要求
-
Cisco Secure Firewall 3100 - 最多 8 台设备
-
Cisco Secure Firewall 4200 - 最多 8 台设备
ASA 硬件和软件要求
集群中的所有设备:
-
必须为相同型号且 DRAM 相同。闪存的大小不必相同。
-
除在映像升级时以外,必须运行完全相同的软件。支持无中断升级。不匹配的软件版本可能会导致性能不佳,因此请务必在同一维护窗口中升级所有节点。
-
必须处于相同的安全情景模式下,无论是单情景模式还是多情景模式。
-
(单情景模式)必须处于相同的防火墙模式下,无论是路由模式还是透明模式。
-
在配置复制之前,新的集群成员对初始集群控制链路通信必须使用与控制单元相同的 SSL 加密设置(ssl encryption 命令)。
交换机要求
-
请务必先完成交换机配置,然后再对 ASA 配置集群。
-
有关受支持的交换机的列表,请参阅思科 ASA 兼容性。
ASA 要求
-
将设备加入管理网络之前,为每台设备提供唯一的 IP 地址。
-
有关连接到 ASA 并设置管理 IP 地址的详细信息,请参阅“入门”一章。
-
除用作控制单元(通常为添加到集群中的第一台设备)使用的 IP 地址外,这些管理 IP 地址仅供临时使用。
-
数据单元加入集群后,其管理接口配置将替换为从控制单元复制的配置。
-
调整站点间集群的数据中心互联
您应在数据中心互联 (DCI) 上为集群控制链路流量保留等同于以下计算结果的带宽:

如果各站点的成员数不同,请使用较大的数量进行计算。DCI 的最低带宽不得低于一个成员的集群控制链路的流量大小。
例如:
-
位于 4 个站点的 2 个成员:
-
总共 4 个集群成员
-
每个站点 2 个成员
-
每个成员 5 Gbps 集群控制链路
保留的 DCI 带宽 = 5 Gbps (2/2 x 5 Gbps)。
-
-
对位于 3 个站点的 6 个成员而言,规格加大:
-
总共 6 个集群成员
-
站点 1 有 3 个成员,站点 2 有 2 个成员,站点 3 有 1 个成员
-
每个成员 10 Gbps 集群控制链路
保留的 DCI 带宽 = 15 Gbps (3/2 x 10 Gbps)。
-
-
位于 2 个站点的 2 个成员:
-
总共 2 个集群成员
-
每个站点 1 个成员
-
每个成员 10 Gbps 集群控制链路
保留的 DCI 带宽 = 10 Gbps(1/2 x 10 Gbps = 5 Gbps;但最低带宽不得低于集群控制链路的流量大小 (10 Gbps))。
-
其他要求
我们建议使用终端服务器访问所有集群成员设备的控制台端口。为了进行初始设置和持续管理(例如在设备发生故障时),终端服务器对于远程管理非常有用。
ASA 集群准则
情景模式
每台成员设备上的模式必须匹配。
防火墙模式
对于单情景模式,所有设备上的防火墙模式必须匹配。
故障转移
集群不支持故障转移。
IPv6
集群控制链路只有在使用 IPv4 时才受支持。
交换机
-
确保连接的交换机与集群数据接口和集群控制链路接口的 MTU 匹配。您应将集群控制链路接口 MTU 配置为比数据接口 MTU 至少高 100 字节,因此请确保适当配置集群控制链路连接的交换机。由于集群控制链路流量包括数据包转发,因此集群控制链路需要能够容纳完整大小的数据包以及集群流量开销。
-
对于 Cisco IOS XR 系统,如果要设置非默认 MTU,请将 IOS XR 接口 MTU 设置为比集群设备 MTU 高 14 字节。除非使用 mtu-ignore 选项,否则 OSPF 邻近对等尝试可能会失败。请注意,集群设备 MTU 应与 IOS XR IPv4 MTU 匹配。Cisco Catalyst 和 Cisco Nexus 交换机不需要进行这种调整。
-
在用于集群控制链路接口的交换机上,您可以选择在连接到集群设备的交换机端口上启用生成树 PortFast 来加快新设备加入集群的过程。
-
在交换机上,我们建议使用以下其中一种 EtherChannel 负载均衡算法:source-dest-ip 或 source-dest-ip-port (请参阅思科 Nexus OS 和思科 IOS-XE port-channel load-balance 命令)。请勿在负载均衡算法中使用关键字 vlan,否则会导致传输到集群中的设备的流量分摊不均。请勿 更改集群设备上默认的负载均衡算法。
-
如果在交换机上更改 EtherChannel 的负载均衡算法,则交换机上的 EtherChannel 接口将暂时停止转发流量,生成树协议重新启动。在流量再次开始传输之前会存在延迟。
-
集群控制链路路径上的交换机不应验证第 4 层校验和。集群控制链路上的重定向流量没有正确的第 4 层校验和。交换机验证第 4 层校验和可能导致流量被丢弃。
-
端口通道绑定中断时间不得超过配置的 keepalive 间隔。
-
在 Supervisor 2T EtherChannel 上,默认的散列值分配算法是自适应算法。为了避免 VSS 设计中的非对称流量,请将连接到集群设备的端口通道上的散列算法更改为固定:
router(config)# port-channel id hash-distribution fixed
请勿全局更改算法;您可能需要对 VSS 对等链路使用自适应算法。
-
您应在所有面向集群的 EtherChannel 接口上为思科 Nexus 交换机禁用 LACP Graceful Convergence 功能。
EtherChannel
-
在低于 15.1(1)S2 的 Catalyst 3750-X 思科 IOS 软件版本中,此集群设备不支持将 EtherChannel 连接到交换机堆叠。在默认交换机设置下,如果跨堆栈连接集群设备 EtherChannel,则当控制设备交换机关闭时,连接到其余交换机的 EtherChannel 不会正常工作。要提高兼容性,请将 stack-mac persistent timer 命令设置为足够大的值,以将重载时间计算在内;例如,可将其设置为 8 分钟,或设置为 0 以表示无穷大。或者,您可以升级到更加稳定的交换机软件版本,例如 15.1(1)S2。
-
跨网络与设备本地 EtherChannel 配置 - 请务必为跨区以太网通道和设备本地 EtherChannel 适当地配置交换机。
-
跨区以太网通道 - 对于跨越所有集群成员的集群设备跨网络 EtherChannel,所有接口在交换机上合并为一个 EtherChannel。请确保每个接口都属于交换机上的同一个通道组。
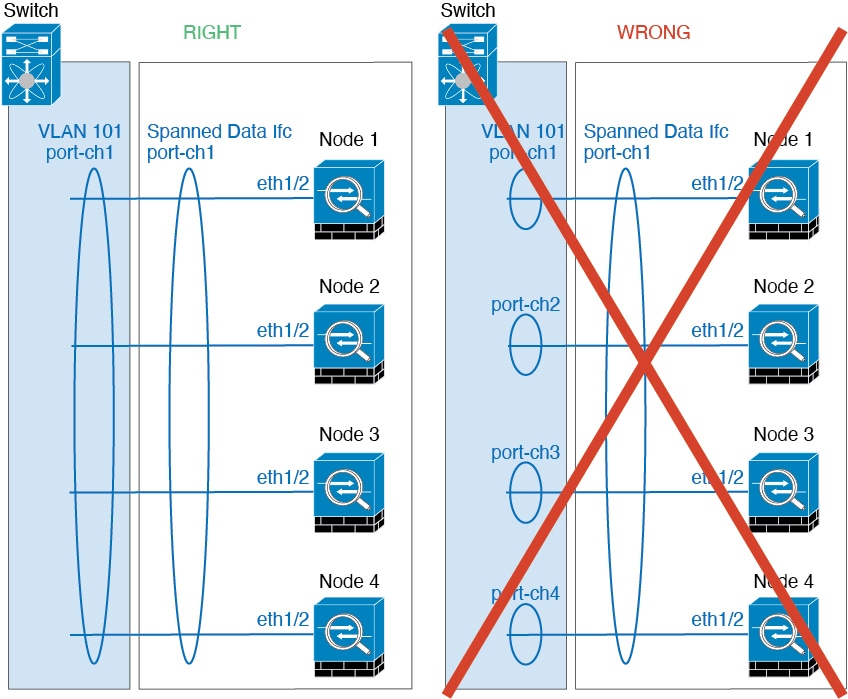
-
设备本地 EtherChannel - 对于集群设备本地 EtherChannels,包括为集群控制链路配置的任何 EtherChannel,请务必在交换机上配置分散的 EtherChannel;请勿在交换机上将多个集群设备 EtherChannel 合并为一个 EtherChannel。
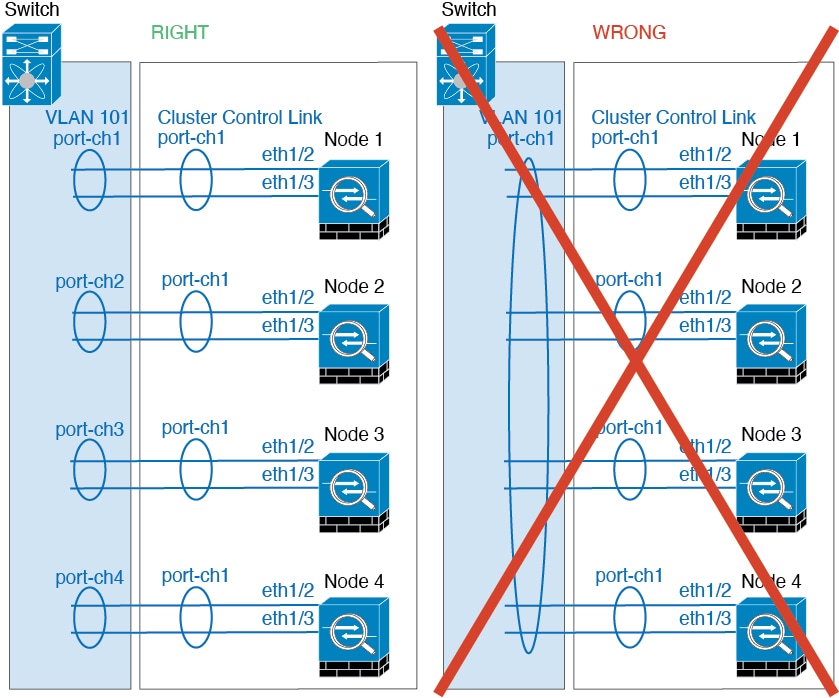
-
站点间准则
请参阅有关站点间集群的以下准则:
-
集群控制链路的延迟必须小于 20 微秒往返时间 (RTT)。
-
集群控制链路必须可靠,没有数据包无序或丢弃数据包的情况;例如,您应使用专用链路。
-
请勿配置连接再均衡;您不需要将连接再均衡到位于不同站点的集群成员。
-
ASA 不会加密集群控制链路上转发的数据流量,因为它是专用链接,即使在数据中心互连 (DCI) 上使用也是如此。如果您使用重叠传输虚拟化 (OTV) 或将集群控制链路扩展到本地管理域外部,可以在边界路由器(例如基于 OTV 的 802.1AE MacSec)上配置加密。
-
对于传入连接而言,位于多个站点的成员之间的集群实施没有区别;因此,给定连接的连接角色可以跨越所有站点。这是预期行为。但是,如果您启用导向器本地化,系统将始终从连接所有者所在同一站点选择本地导向器角色(根据站点 ID)。此外,如果原始所有者发生故障,本地导向器将在同一站点选择新的连接所有者(注意:如果不同站点间的流量非对称,且原始所有者发生故障后远程站点继续发出流量,则远程站点节点可能成为新的所有者,但条件是该设备在重新托管期间接收到数据包。)。
-
对于导向器本地化,以下流量类型不支持本地化:NAT 或 PAT 流量;SCTP 检查的流量;分段所有者查询。
-
对于透明模式,如果集群布置于内部和外部路由器对之间(AKA 南北插入),您必须确保两个内部路由器共享一个 MAC 地址,两个外部路由器共享一个 MAC 地址。当位于站点 1 的集群成员将连接转发到位于站点 2 的成员时,目标 MAC 地址会被保留。如果该 MAC 地址与位于站点 1 的路由器相同,则数据包只会到达位于站点 2 的路由器。
-
对于透明模式,如果集群布置于每个站点上的数据网络和网关路由器之间,用作内部网络之间的防火墙(AKA 东西插入),则每个网关路由器都应使用 HSRP 等第一跳冗余协议 (FHRP) 在每个站点提供相同的虚拟 IP 和 MAC 地址目标。数据 VLAN 使用重叠传输虚拟化 (OTV) 或类似技术扩展到多个站点。您需要创建过滤器,阻止发往本地网关路由器的流量通过 DCI 发送到另一站点。如果无法访问一个站点上的网关路由器,则您需要删除所有过滤器,使流量能够成功到达另一站点的网关。
-
对于透明模式,如果集群连接到 HSRP 路由器,则必须在 ASA。当邻接路由器使用 HSRP 时,发往 HSRP IP 地址的流量将发送到 HSRP MAC 地址,但返回流量将来自 HSRP 对中特定路由器接口的 MAC 地址。因此,ASA MAC 地址表通常仅在 HSRP IP 地址的 ASA ARP 表条目到期时更新,并且 ASA 发送 ARP 请求并接收应答。由于 ASA 的 ARP 表条目默认在 14400 秒后到期,但 MAC 地址表条目默认在 300 秒后到期,因此需要添加静态 MAC 地址条目来避免 MAC 地址表到期流量丢弃。
-
对于使用跨区以太网通道的路由模式,请配置站点特定的 MAC 地址。使用 OTV 或类似技术跨站点扩展数据 VLAN 。您需要创建过滤器,阻止发往全局 MAC 地址的流量通过 DCI 发送到另一站点。如果无法访问一个站点上的集群,则您需要删除所有过滤器,使流量能够成功到达另一站点的集群节点。当站点间集群作为扩展网段的第一跳路由器时,不支持动态路由。
其他准则
-
当拓扑发生重大更改时(例如添加或删除 EtherChannel 接口、启用或禁用 ASA 或交换机上的接口、添加额外的交换机形成 VSS、vPC、StackWise 或 StackWise Virtual),您应禁用运行状态检查功能,还要禁用对已禁用接口的接口监控。当拓扑更改完成且配置更改已同步到所有设备后,您可以重新启用接口运行状态检查功能。
-
将设备添加到现有集群时或重新加载设备时,会有限地暂时丢弃数据包/断开连接;这是预期行为。有些时候,丢弃的数据包会挂起连接;例如,丢弃 FTP 连接的 FIN/ACK 数据包将使 FTP 客户端挂起。在此情况下,您需要重新建立 FTP 连接。
-
如果使用连接到跨网络 EtherChannel 的 Windows 2003 服务器,当系统日志服务器端口关闭且服务器没有限制 ICMP 错误信息时,将会有大量 ICMP 消息被发送回 ASA 集群。这些消息会导致 ASA 集群的某些设备 CPU 使用率极高,进而影响性能。因此,我们建议您限制 ICMP 错误信息。
-
将更改复制到集群中的所有设备需要时间。如果进行较大的更改,例如,添加使用对象组的访问控制规则(在部署时会拆分为多个规则),完成更改所需的时间可能会超过集群设备响应的超时时间与成功消息。如果发生这种情况,您可能会看到“无法复制命令”消息。您可以忽略此消息。
ASA 集群的默认设置
-
使用跨区以太网通道时,将自动生成 cLACP 系统 ID 且系统优先级默认为 1。
-
默认情况下,集群运行状况检查功能处于启用状态,保持时间为 3 秒。默认情况下,在所有接口上启用接口运行状况监控。
-
用于发生故障的集群控制链路的集群自动重新加入功能为每 5 分钟尝试无限次。
-
用于发生故障的数据接口的集群自动重新加入功能为每 5 分钟尝试 3 次,增量间隔设置为 2。
-
默认情况下,连接再均衡处于禁用状态。如果启用连接再均衡,交换负载信息的默认间隔时间为 5 秒。
-
对于 HTTP 流量,默认启用 5 秒的连接复制延迟。
配置 ASA 集群
要配置集群,请执行以下任务。
注 |
要启用或禁用集群,您必须使用控制台连接(适用于 CLI)或 ASDM 连接。 |
使用电缆连接设备并配置接口
在配置集群之前,需要先使用电缆连接集群控制链路网络、管理网络和数据网络。然后,配置您的接口。
关于集群接口
您可以将数据接口配置为 跨区以太网通道。每台设备还必须至少将一个硬件接口专门用作集群控制链路。
集群控制链路
每台设备至少必须将一个硬件接口专门用作集群控制链路。我们建议将 EtherChannel 用于集群控制链路(如果可用)。
集群控制链路流量概述
集群控制链路流量包括控制流量和数据流量。
控制流量包括:
-
控制节点选举。
-
配置复制。
-
运行状况监控。
数据流量包括:
-
状态复制。
-
连接所有权查询和数据包转发。
集群控制链路接口和网络
您可以将任何数据接口用于集群控制链路,但以下情况除外:
-
VLAN 子接口不能用作集群控制链路。
-
管理 x/x 接口(无论是作为独立接口还是作为 EtherChannel),都不能用作集群控制链路。
您可以使用 EtherChannel 。
每条集群控制链路都有一个属于同一子网的 IP 地址。此子网应与所有其他流量隔离,并且只包括 ASA 集群控制链路接口。
对于有 2 个成员的集群,请勿将集群控制链路从一台 ASA 直接连接到另一台 ASA。如果直接连接两个接口,则当一台设备发生故障时,集群控制链路失效,会导致剩下的那台正常设备也发生故障。而如果通过交换机连接集群控制链路,则集群控制链路仍会对正常设备打开。
确定集群控制链路规格
如果可能,应将集群控制链路的大小设定为与每个机箱的预期吞吐量匹配,以使集群控制链路可以处理最坏情况。
集群控制链路流量主要由状态更新和转发的数据包组成。集群控制链路在任一给定时间的流量大小不尽相同。转发流量的大小取决于负载均衡的效率或是否存在大量用于集中功能的流量。例如:
-
NAT 会使连接的负载均衡不佳,需要对所有返回流量进行再均衡,将其转发到正确的设备。
-
用于网络访问的 AAA 是集中功能,因此所有流量都会转发到控制设备。
-
当成员身份更改时,集群需要对大量连接进行再均衡,因此会暂时耗用大量集群控制链路带宽。
带宽较高的集群控制链路可以帮助集群在发生成员身份更改时更快地收敛,并防止出现吞吐量瓶颈。
注 |
如果集群中存在大量不对称(再均衡)流量,应增加集群控制链路的吞吐量大小。 |
集群控制链路冗余
我们建议将 EtherChannel 用于集群控制链路,以便在 EtherChannel 中的多条链路上传输流量,同时又仍能实现冗余。
下图显示了如何在虚拟交换系统 (VSS)、虚拟端口通道 (vPC)、StackWise 或 StackWise Virtual 环境中使用 EtherChannel 作为集群控制链路。EtherChannel 中的所有链路都是活动链路。如果交换机是冗余系统的一部分,则您可以将同一个 EtherChannel 中的防火墙接口连接到冗余系统中单独的交换机。交换机接口是同一个 EtherChannel 端口通道接口的成员,因为两台不同的交换机的行为就像一台交换机一样。请注意,此 EtherChannel 是设备本地的,而非跨网络 EtherChannel。
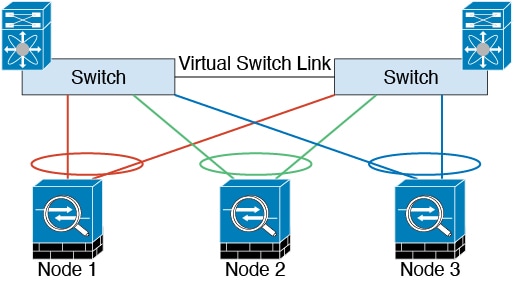
集群控制链路可靠性
为了确保集群控制链路的功能,设备之间的往返时间 (RTT) 务必要小于 20 毫秒。此最大延迟能够增强与不同地理位置安装的集群成员的兼容性。要检查延迟,请在设备之间的集群控制链路上执行 ping 操作。
集群控制链路必须可靠,没有数据包无序或丢弃数据包的情况;例如,站点间部署应使用专用链路。
集群控制链路故障
如果某台设备的集群控制链路线路协议关闭,则集群将被禁用;数据接口关闭。当您修复集群控制链路之后,必须通过重新启用集群来手动重新加入集群。
注 |
当 ASA 处于非活动状态时,所有数据接口关闭;只有管理专用接口可以发送和接收流量。管理接口将保持打开,使用设备从集群 IP 池接收的 IP 地址。但是,如果您重新加载而设备在集群中仍然处于非活动状态,管理接口将无法访问(因为它届时将使用与控制设备相同的主 IP 地址)。您必须使用控制台端口来进行任何进一步配置。 |
跨网络 EtherChannel
您可以将每个机箱的一个或多个接口组成跨集群中所有机箱的 EtherChannel。EtherChannel 汇聚通道中所有可用活动接口上的流量。在路由模式和透明防火墙模式下均可配置跨区以太网通道。在路由模式下,EtherChannel 配置为具有单个 IP 地址的路由接口。在透明模式下,IP 地址分配到 BVI 而非网桥组成员接口。负载均衡属于 EtherChannel 固有的基本操作。
最大吞吐量准则
要实现最大吞吐量,我们建议采取以下措施:
-
使用“对称”的负载均衡散列算法,亦即来自两个方向的数据包具有相同的散列值,并将在跨网络 EtherChannel 中发送到同一台 ASA。我们建议将源和目标 IP 地址(默认设置)或源和目标端口用作散列算法。
-
将 ASA 连接到交换机时使用相同类型的线路卡,以使应用于所有数据包的散列算法都相同。
负载均衡
EtherChannel 链路使用专有散列算法并且根据源或目标 IP 地址以及 TCP 和 UDP 端口号进行选择。
注 |
在交换机上,我们建议使用以下其中一种算法:source-dest-ip 或 source-dest-ip-port(请参阅思科 Nexus OS 或思科 IOS port-channel load-balance 命令)。请勿在负载均衡算法中使用关键字 vlan,否则会导致传输到集群中的 ASA 的流量分摊不均。 |
EtherChannel 中的链路数量会影响负载均衡。
对称的负载均衡有时并不能够实现。如果您配置了 NAT,则转发和返回数据包具有不同的 IP 地址和/或端口。返回流量将根据散列值被发送到不同的设备,因此集群不得不将大部分返回流量重定向到正确的设备。
EtherChannel 冗余
EtherChannel 有内置冗余。它监控所有链路的线路协议状态。如果一条链路发生故障,将在其余链路之间再均衡流量。如果 EtherChannel 中的所有链路在特定设备上发生故障,但其他设备仍然处于活动状态,则会从集群中删除该设备。
连接到冗余交换机系统
您可以在跨网络 EtherChannel 中包含每台 ASA 的多个接口。每台 ASA 有多个接口,对于连接到 VSS、vPC、StackWise 或 StackWise Virtual 中两台交换机的情况特别有用。
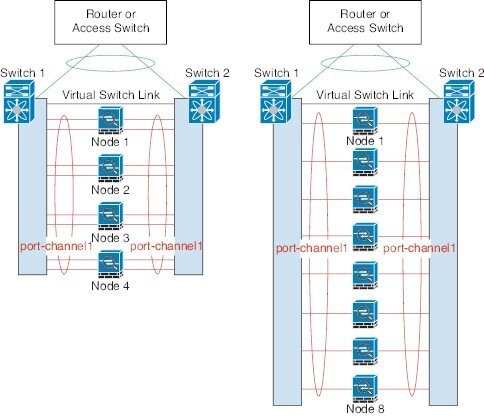
根据交换机的不同,最多可在跨网络 EtherChannel 中配置 32 条活动链路。此功能需要 vPC 中的两台交换机都支持各有 16 条活动链路的 EtherChannel(例如带 F2 系列 10 千兆以太网模块的思科 Nexus 7000)。
对于支持 EtherChannel 中有 8 条活动链路的交换机,在连接到冗余系统中的两台交换机时,最多可在跨区以太网通道 中配置 16 条活动链路。
下图所示为 4 节点集群和 8 节点集群中有 16 条活动链路的跨区以太网通道。
使用电缆连接集群设备并配置上游和下游设备
在配置集群之前,需要先使用电缆连接集群控制链路网络、管理网络和数据网络。
过程
|
步骤 1 |
使用电缆连接集群控制链路网络、管理网络和数据网络。
|
||
|
步骤 2 |
此外,还应配置上游和下游设备。例如,如果使用 EtherChannel,则应为上游和下游设备进行 EtherChannel 配置。 |
上在每个设备上配置集群接口模式
在启用集群之前,您需要将防火墙转换为使用跨区以太网通道。由于集群会限制您可以使用的接口类型,因此此过程允许您检查现有配置中是否存在不兼容的接口,然后阻止配置任何不受支持的接口。
开始之前
-
您必须在要添加到集群中的每台 ASA 上分别设置模式。
-
您始终可以将管理专用接口配置为独立接口(推荐)下亦如此。即使是在透明防火墙模式下,管理接口也可以是独立接口。
-
在,,如果将管理接口配置为独立接口,您将无法为管理接口启用动态路由。您必须使用静态路由。
过程
|
步骤 1 |
显示任何不兼容的配置,以便稍后强制设置接口模式并修复配置;该模式不会随以下命令而更改: cluster interface-mode spanned check-details 示例: |
|
步骤 2 |
为集群设置接口模式: cluster interface-mode spanned force 示例:不存在默认设置;您必须明确选择模式。如果尚未设置模式,则无法启用集群。 force 选项可直接更改模式而无需检查配置中是否存在不兼容的设置。更改模式后,您需要手动修复任何配置问题。由于任何接口配置都只能在设置完模式后修复,因此我们建议使用 force 选项,这样您至少可以从现有配置着手。设置模式后,您可以重新运行 check-details 选项来获得更多参考信息。 如果不使用 force 选项,当存在任何不兼容的配置时,系统将提示您清除配置并重新加载,从而需要您连接到控制台端口来重新配置管理访问。如果您的配置兼容(极为罕见),则会更改模式并保留配置。如果您不想清除配置,则可以键入 n 退出命令。 要删除接口模式,请输入 no cluster interface-mode 命令。 |
在控制节点上配置接口
启用集群之前,您必须修改所有当前配置了 IP 地址的接口,使其准备好加入集群。至于其他接口,您可以在启用集群之前或之后配置;我们建议预配置所有接口,以便将完整的配置同步到新的集群成员。
本节介绍如何将接口配置为与集群兼容。您可以将数据接口配置跨区以太网通道或独立接口。每种方法使用的负载均衡机制不同。在同一个配置中不能配置两种接口类型,只有管理接口除外,它即使在跨区以太网通道模式下也可以是独立接口。您可以将数据接口配置跨区以太网通道或独立接口。每种方法使用的负载均衡机制不同。在同一个配置中不能配置两种接口类型,只有管理接口除外,它即使在跨区以太网通道模式下也可以是独立接口。
将管理接口配置为独立接口
独立接口是正常的路由接口,每个接口都从 IP 地址池获取自己的 IP 地址。集群的主集群 IP 地址是集群的固定地址,始终属于控制节点。
我们 建议将管理接口配置为独立接口。独立接口可以根据需要直接连接到每台设备,而跨区以太网通道接口则只允许连接到控制节点。
开始之前
-
对于多情景模式,请在每个情景下执行本程序。如果您尚未进入情景配置模式,请输入 changeto context name 命令。
-
(可选)将接口配置为设备本地 EtherChannel 接口和/或配置子接口。
-
如果配置为 EtherChannel,则此 EtherChannel 是设备本地的,而非跨区以太网通道。
-
过程
|
步骤 1 |
配置本地 IP 地址池(IPv4 和/或 IPv6),其中一个地址将被分配到每个集群设备作为接口地址: (IPv4) ip local pool poolname first-address — last-address [mask mask] (IPv6) ipv6 local pool poolname ipv6-address/prefix-length number_of_addresses 示例:至少包含与集群中的设备数量相同的地址。如果计划扩展集群,则应包含更多地址。属于当前主设备的主集群 IP 地址不在此地址池中;请务必在同一个网络中为主集群 IP 地址保留一个 IP 地址。 您无法预先确定分配到每台设备的确切本地地址;要查看每台设备上使用的地址,请输入 show ip[v6] local pool poolname 命令。每个集群成员在加入集群时都会分配到一个成员 ID。此 ID 决定了所用的来自地址池中的本地 IP。 |
|
步骤 2 |
进入接口配置模式: interface interface_id 示例: |
|
步骤 3 |
将一个接口设置为管理专用模式,确保不会有流量流经该接口: management-only 默认情况下,管理类型的接口被配置为管理专用。在透明模式下,此命令对管理类型的接口始终启用。 |
|
步骤 4 |
为接口命名: nameif name 示例:name 是长度最多为 48 个字符的文本字符串,并且不区分大小写。使用一个新值重新输入此命令可更改名称。 |
|
步骤 5 |
设置主集群 IP 地址并确定集群池: (IPv4) ip address ip_address [mask] cluster-pool poolname (IPv6) ipv6 address ipv6-address/prefix-length cluster-pool poolname 示例:此 IP 地址必须与集群池地址属于同一个网络,但不在地址池中。您可以配置 IPv4 和/或 IPv6 地址。 不支持 DHCP、PPPoE 和 IPv6 自动配置;您必须手动配置 IP 地址。 |
|
步骤 6 |
设置安全级别,其中 number 为 0(最低)到 100(最高)之间的整数: security-level 编号 示例: |
|
步骤 7 |
启用接口: no shutdown |
示例
以下示例将以太网 1/3 和以太网 1/4 接口配置为设备本地 EtherChannel,然后将 EtherChannel 配置为独立接口:
ip local pool mgmt 10.1.1.2-10.1.1.9
ipv6 local pool mgmtipv6 2001:DB8:45:1002/64 8
interface ethernet 1/3
channel-group 1 mode active
no shutdown
interface ethernet 1/4
channel-group 1 mode active
no shutdown
interface port-channel 1
nameif management
ip address 10.1.1.1 255.255.255.0 cluster-pool mgmt
ipv6 address 2001:DB8:45:1002::99/64 cluster-pool mgmtipv6
security-level 100
management-only
配置跨区以太网通道
跨网络 EtherChannel 跨越集群中的所有 ASA,并在 EtherChannel 操作的过程中提供负载均衡。
开始之前
-
您必须处于跨网络 EtherChannel 接口模式下。
-
对于多情景模式,请在系统执行空间中开始本程序。如果尚未进入系统配置模式,请输入 changeto system 命令。
-
对于透明模式,请配置网桥组。
-
使用跨网络 EtherChannel 时,端口通道接口在集群完全启用之前不会进入工作状态。此要求可防止将流量转发到集群中并非处于活动状态的设备。
过程
|
步骤 1 |
指定要添加到通道组的接口: interface physical_interface 示例:The physical_interface ID includes the type, slot, and port number as type slot/ port. 通道组中的第一个接口决定了该组中所有其他接口的类型和速度。 |
|
步骤 2 |
将此接口分配到 EtherChannel: channel-group channel_id mode active 示例:channel_id 的值为 1 到 48。如果配置中尚没有此通道 ID 的端口通道接口,将自动添加一个接口: interface port-channel channel_id 跨网络 EtherChannel 只支持 active 模式。 |
|
步骤 3 |
启用接口: no shutdown |
|
步骤 4 |
(可选)通过重复该过程,将更多接口添加到 EtherChannel。 示例:每台设备在 EtherChannel 中有多个接口,对于连接到 VSS、vPC、StackWise 或 StackWise Virtual 中交换机的情况非常有用。 |
|
步骤 5 |
指定端口通道接口: interface port-channel channel_id 示例:在将接口添加到通道组时,将自动创建此接口。 |
|
步骤 6 |
(可选)如果准备在此 EtherChannel 上创建 VLAN 子接口,请立即执行此操作。 示例:本程序的其余部分适用于子接口。 |
|
步骤 7 |
(多情景模式)将接口分配到情景。然后输入: 示例:对于多情景模式,其余的接口配置将在每个情景中完成。 |
|
步骤 8 |
为接口命名: nameif name 示例:name 是长度最多为 48 个字符的文本字符串,并且不区分大小写。使用一个新值重新输入此命令可更改名称。 |
|
步骤 9 |
根据防火墙模式,执行以下其中一项操作。
|
|
步骤 10 |
设置安全级别: security-level number 示例:number 为 0(最低)到 100(最高)之间的整数。 |
|
步骤 11 |
为跨网络 EtherChannel 配置全局 MAC 地址,以避免潜在的网络连接问题: mac-address mac_address 示例:如果是手动配置的 MAC 地址,该 MAC 地址将始终属于当前的控制设备。如果不配置 MAC 地址,则如果控制设备发生更改,新的控制设备会将新的 MAC 地址用于该接口,而这可能导致临时网络故障。 在多情景模式下,如果您在情景之间共享接口,则应改为启用自动生成 MAC 地址,这样就无需手动设置 MAC 地址。请注意,您必须使用此命令为非共享 接口手动配置 MAC 地址。 mac_address 的格式为 H.H.H,其中 H 是 16 位十六进制数字。例如, MAC 地址 00-0C-F1-42-4C-DE 以 000C.F142.4CDE 的形式输入。 如果您还要使用自动生成的 MAC 地址,则手动 MAC 地址的前两个字节不能为 A2。 |
|
步骤 12 |
(路由模式)对于站点间集群,为每个站点配置一个站点特定的 MAC 地址和 IP 地址: mac-address mac_address site-id number site-ip ip_address
示例:站点特定的 IP 地址必须与全局 IP 地址位于同一子网。供设备使用的站点特定的 MAC 地址和 IP 地址取决于您在每台设备的引导程序配置中指定的站点 ID。 |
创建引导程序配置
集群中的每个节点都需要有引导程序配置才能加入集群。
配置控制节点引导程序设置
集群中的每个节点都需要有引导程序配置才能加入集群。通常,您配置为加入集群的第一个节点将是控制节点。启用集群后,集群会在选举时间结束后选举出一个控制节点。最初只有一个节点在集群中,该节点将成为控制节点。添加到集群的后续节点将是数据节点。
开始之前
-
请备份配置,以防稍后要退出集群而需要恢复配置。
-
对于多情景模式,请在系统执行空间中完成这些程序。要从该情景切换到系统执行空间,请输入 changeto system 命令。
-
您必须使用控制台端口来启用或禁用集群。您不能使用 Telnet 或 SSH。
-
将节点添加到正在运行的集群时,可能会有限地暂时丢弃数据包/断开连接;这是预期行为。
-
预先确定集群控制链路的吞吐量大小。请参阅确定集群控制链路规格。
过程
|
步骤 1 |
加入集群之前,先启用集群控制链路接口。 稍后,您要在启用集群时将此接口确定为集群控制链路。 如果您有足够的接口,我们建议您将多个集群控制链路接口合并到 EtherChannel 中。此 EtherChannel 是 ASA 本地的,而非跨区以太网通道。 集群控制链路接口配置不会从控制节点复制到数据节点;但是,必须在每个节点上使用相同的配置。由于此配置不会复制,您必须在每个节点上分别配置集群控制链路接口。
|
||
|
步骤 2 |
指定集群控制链路接口的最大传输节点至少比数据接口的最高 MTU 高 100 字节。 mtu cluster 字节 示例:将 MTU 设置为 1400 到 9198 字节之间的值。默认 MTU 为 1500 字节。我们建议将集群控制链路 MTU 设置为最大 。由于集群控制链路流量包括数据包转发,因此集群控制链路需要能够容纳完整大小的数据包以及集群流量开销。 例如,由于最大 MTU 为 9198 字节,因此最高的数据接口 MTU 可以是 9098,而集群控制链路则可以设置为 9198。 此命令是全局配置命令,但是也属于不会在节点之间复制的引导程序配置。 |
||
|
步骤 3 |
为集群命名并进入集群配置模式: cluster group 名称 示例:名称必须是长度为 1 到 38 个字符的 ASCII 字符串。每个节点只能配置一个集群组。集群的所有成员必须使用同一名称。 |
||
|
步骤 4 |
为此集群成员命名: local-unit unit_name 使用唯一的 ASCII 字符串,长度必须为 1 到 38 个字符。每个节点必须具有唯一的名称。集群中不允许存在名称重复的节点。 示例: |
||
|
步骤 5 |
指定集群控制链路接口,最好是 EtherChannel: cluster-interface interface_id ip ip_address mask 示例:不允许子接口和管理接口。 指定 IP 地址的 IPv4 地址;此接口不支持 IPv6。此接口不能配置 nameif。 对于每个节点,在同一网络上指定不同的 IP 地址。 |
||
|
步骤 6 |
如果使用站点间集群,请设置此节点的站点 ID,以便其使用站点特定的 MAC 地址: site-id 编号 示例:编号 介于 1 到 8 之间。 |
||
|
步骤 7 |
设置控制节点选择的此节点的优先级: priority priority_number 示例:优先级的值为 1 到 100,其中 1 为最高优先级。 |
||
|
步骤 8 |
(可选)设置身份验证密钥以便控制集群控制链路上的流量: key shared_secret 示例:共享密钥是长度介于 1 和 63 个字符之间的 ASCII 字符串。共享密钥用于生成密钥。此命令不会影响数据路径流量,包括始终以明文发送的连接状态更新和转发数据包。 |
||
|
步骤 9 |
(可选)手动指定 cLACP 系统 ID 和系统优先级: clacp system-mac {mac_address | auto} [system-priority number] 示例:使用跨区以太网通道时,ASA 使用 cLACP 与邻居交换机协商 EtherChannel。集群中的 ASA 在 cLACP 协商中协作,使其在交换机看来就好似一台(虚拟)设备。cLACP 协商中的一个参数是 MAC 地址格式的系统 ID。该集群中的所有 ASA 都使用同一个系统 ID:由控制单元(默认)自动生成并复制到所有辅助设备;也可以使用此命令,按照 H.H.H 的格式手动指定,其中 H 是 16 位十六进制数字。(例如,MAC 地址 00-0A-00-00-AA-AA 输入为 000A.0000.AAAA。)例如,您可能出于排除故障的目的而要手动配置 MAC 地址,以便使用易于识别的 MAC 地址。通常情况下,您会使用自动生成的 MAC 地址。 系统优先级的值为 1 到 65535,用于确定哪个节点负责作出绑定决定。默认情况下,ASA 使用优先级 1,即最高优先级。该优先级需要高于交换机上的优先级。 此命令并非引导程序配置的一部分,而是从控制节点复制到数据节点上的。但是,在启用集群后无法更改此值。 |
||
|
步骤 10 |
启用集群: enable [noconfirm] 示例:输入 enable 命令时,ASA 将扫描正在运行的配置,查找集群不支持的功能的不兼容命令,包括默认配置中可能存在的命令。系统会提示您删除不兼容命令。如果您选择 No,则不会启用集群。使用 noconfirm 关键字可绕过确认步骤并自动删除不兼容命令。 对于启用的第一个节点,会进行控制节点选择。由于到目前为止第一个节点应该是集群的唯一成员,因此它将成为控制节点。请勿在此期间执行任何配置更改。 要禁用集群,请输入 no enable 命令。
|
示例
以下示例先配置管理接口,再为集群控制链路配置设备本地 EtherChannel,然后为名为“node1”的 ASA 启用集群,由于该设备是第一台添加到集群的设备,因此将成为控制节点。
ip local pool mgmt 10.1.1.2-10.1.1.9
ipv6 local pool mgmtipv6 2001:DB8::1002/32 8
interface management 1/1
nameif management
ip address 10.1.1.1 255.255.255.0 cluster-pool mgmt
ipv6 address 2001:DB8::1001/32 cluster-pool mgmtipv6
security-level 100
management-only
no shutdown
interface ethernet 1/6
channel-group 1 mode on
no shutdown
interface ethernet 1/7
channel-group 1 mode on
no shutdown
cluster group pod1
local-unit node1
cluster-interface port-channel1 ip 192.168.1.1 255.255.255.0
priority 1
key chuntheunavoidable
enable noconfirm
配置数据节点引导程序设置
执行以下程序配置数据节点。
开始之前
-
您必须使用控制台端口来启用或禁用集群。您不能使用 Telnet 或 SSH。
-
请备份配置,以防稍后要退出集群而需要恢复配置。
-
对于多情景模式,请在系统执行空间中完成本程序。要从该情景切换到系统执行空间,请输入 changeto system 命令。
-
如果配置中有任何接口未被配置用于集群(例如,默认配置管理 1/1 接口),可以作为数据节点加入集群(在当前选择下不可能变成控制节点)。
-
将节点添加到正在运行的集群时,可能会有限地暂时丢弃数据包/断开连接;这是预期行为。
过程
|
步骤 1 |
配置集群控制链路接口,其必须与您为控制节点配置的接口相同。 示例: |
||
|
步骤 2 |
指定您为控制节点配置的同一 MTU: 示例: |
||
|
步骤 3 |
确定集群名称,其必须与您为控制节点配置的集群名称相同: 示例: |
||
|
步骤 4 |
用唯一的字符串为此集群成员命名: local-unit unit_name 示例:指定长度为 1 到 38 个字符的 ASCII 字符串。 每个节点必须具有唯一的名称。集群中不允许存在名称重复的节点。 |
||
|
步骤 5 |
指定您为控制节点配置的同一集群控制链路接口,但在每个节点的相同网络上指定不同的 IP 地址: cluster-interface interface_id ip ip_address mask 示例:指定 IP 地址的 IPv4 地址;此接口不支持 IPv6。此接口不能配置 nameif。 |
||
|
步骤 6 |
如果使用站点间集群,请设置此节点的站点 ID,以便其使用站点特定的 MAC 地址: site-id 编号 示例:number 介于 1 到 8 之间。 |
||
|
步骤 7 |
设置此节点在控制节点选择的优先级,通常设置为高于控制节点的值: priority priority_number 示例:设置值为 1 到 100 的优先级,其中 1 为最高优先级。 |
||
|
步骤 8 |
设置一个身份验证密钥,使其与您为控制节点设置的密钥相同: 示例: |
||
|
步骤 9 |
启用集群: enable as-data-node 使用 enable as-data-node 命令可避免任何配置不兼容(主要是任何尚未进行集群配置的接口的存在)。此命令可确保加入集群的数据节点不可能在任何当前选举中成为控制节点。从属设备的配置将被同步自控制节点的配置覆盖。 要禁用集群,请输入 no enable 命令。
|
示例
以下示例包括数据节点 node2 的配置:
interface ethernet 1/6
channel-group 1 mode on
no shutdown
interface ethernet 1/7
channel-group 1 mode on
no shutdown
cluster group pod1
local-unit node2
cluster-interface port-channel1 ip 192.168.1.2 255.255.255.0
priority 2
key chuntheunavoidable
enable as-data-node
自定义集群操作
您可以自定义集群运行状况监控、TCP 连接复制延迟、流移动性和其他优化。
在控制节点上执行这些程序。
配置基本 ASA 集群参数
您可以在控制节点上自定义集群设置。
开始之前
-
对于多情景模式,请在控制节点的系统执行空间中完成本程序。要从情景更改到系统执行空间,请输入 changeto system 命令。
过程
|
步骤 1 |
进入集群配置模式: cluster group name |
|
步骤 2 |
(可选) 启用数据节点到控制节点的控制台复制: console-replicate 默认情况下会禁用此功能。对于特定的重要事件,ASA 可将某些消息直接打印输出到控制台。如果启用了控制台复制,数据节点会将控制台消息发送到控制节点,因此您只需要监控集群的一个控制台端口。 |
|
步骤 3 |
设置集群事件的最低跟踪级别: trace-level 级别 根据需要设置最低级别:
|
|
步骤 4 |
设置从流所有者到导向器和备份所有者的流状态刷新消息(clu_keepalive 和 clu_update 消息)的保持连接间隔。 clu-keepalive-interval 秒
您可能想将间隔设置为比默认值更长的时间,以减少集群控制链路上的流量。 |
配置运行状态监控并自动重新加入设置
此程序可以配置节点和接口运行状态监控。
您可能想禁用不重要的接口(例如管理接口)的运行状况检查。可以监控任何端口通道 ID、冗余 ID 或单一物理接口 ID。运行状况监控不在 VLAN 子接口或虚拟接口(例如,VNI 或 BVI)上执行。您不能为集群控制链路配置监控;它始终处于被监控状态。
过程
|
步骤 1 |
进入集群配置模式。 cluster group name 示例: |
|
步骤 2 |
自定义集群节点运行状况检查功能。 health-check [holdtime timeout] [vss-enabled] 为了确定节点运行状况,ASA 集群节点会在集群控制链路上将 heartbeat 消息发送到其他节点。如果节点在保持期内未接收到来自对等节点的任何 heartbeat 消息,则对等节点被视为无响应或无法工作。
当拓扑发生任何更改时(例如添加或删除数据接口、启用或禁用 ASA、或交换机上的接口、或者添加额外的交换机形成 VSS、vPC、StackWise 或 StackWise Virtual),您应禁用运行状态检查功能(no health-check monitor-interface ),还要禁用对已禁用接口的接口监控。当拓扑结构更改完成且配置更改已同步到所有节点后,您可以重新启用运行状况检查功能。 示例: |
|
步骤 3 |
在接口上禁用接口运行状况检查。 no health-check monitor-interface interface_id 接口运行状态检查将监控链路故障。如果特定逻辑接口的所有物理端口在特定节点上发生故障,但在其他节点上的同一逻辑接口下仍有活动端口,则会从集群中删除该节点。ASA 在多长时间后从集群中删除成员取决于接口的类型以及该节点是既定成员还是正在加入集群的设备。默认情况下,为所有接口启用运行状况检查。您可以使用此命令的 no 形式逐个接口将其禁用。您可能想禁用不重要的接口(例如管理接口)的运行状况检查。
当拓扑发生任何更改时(例如添加或删除数据接口、启用或禁用 ASA、或交换机上的接口、或者添加额外的交换机形成 VSS、vPC、StackWise 或 StackWise Virtual),您应禁用运行状态检查功能 (no health-check ),还要禁用对已禁用接口的接口监控。当拓扑结构更改完成且配置更改已同步到所有节点后,您可以重新启用运行状况检查功能。 示例: |
|
步骤 4 |
自定义在运行状况检查发生故障后的自动重新加入集群设置。 health-check {data-interface | cluster-interface | system} auto-rejoin [unlimited | auto_rejoin_max] auto_rejoin_interval auto_rejoin_interval_variation
示例: |
|
步骤 5 |
配置 ASA 将接口视为发生故障并将节点从集群中删除之前经过的防反跳时间。 health-check monitor-interface debounce-time ms 示例:将防反跳时间设置为 300 到 9000 毫秒之间。默认值为 500 毫秒。较小的值可以加快检测接口故障的速度。请注意,如果配置的防反跳时间较低,会增加误报几率。在发生接口状态更新时,ASA 会等待指定的毫秒数,然后才将接口标记为发生故障,并将节点从集群中删除。 对于从故障状态转换为正常运行状态的 EtherChannel(例如,交换机重新加载或交换机启用 EtherChannel)而言,更长的防反跳时间可以防止集群节点上的接口仅仅因为另一个集群节点在绑定端口时的速度更快便显示为故障状态。 |
|
步骤 6 |
(可选) 配置流量负载监控。 load-monitor [ frequency seconds] [ intervals intervals]
您可以监控集群成员的流量负载,包括总连接计数、CPU 和内存使用情况以及缓冲区丢弃。如果负载过高,且剩余的节点可以处理负载,您可以选择在节点上手动禁用集群,或调整外部交换机上的负载均衡。默认情况下启用此功能。例如,对于每个机箱中具有 3 个安全模块的 Firepower 9300 上的机箱间集群,如果机箱中的 2 个安全模块离开集群,则与该机箱的相同数量的流量将被发送到剩余的模块,并可能压垮它。您可以定期监控流量负载。如果负载过高,您可以选择手动禁用节点上的集群。 使用 show cluster info load-monitor 命令查看流量负载。 示例: |
示例
以下示例将 health-check holdtime 配置为 0.3 秒;启用 VSS;禁用以太网 1/2 接口(用于管理)的监控;将数据接口的 auto-rejoin 设置为从 2 分钟开始的 4 次尝试,将 duration 增至上一次间隔的 3 倍;以及将集群控制链路的 auto-rejoin 设为 6 次尝试,每隔 2 分钟一次。
ciscoasa(config)# cluster group test
ciscoasa(cfg-cluster)# health-check holdtime .3 vss-enabled
ciscoasa(cfg-cluster)# no health-check monitor-interface ethernet1/2
ciscoasa(cfg-cluster)# health-check data-interface auto-rejoin 4 2 3
ciscoasa(cfg-cluster)# health-check cluster-interface auto-rejoin 6 2 1
配置连接再均衡和集群 TCP 复制延迟
可以配置连接再均衡。有关详细信息,请参阅跨集群实现新 TCP 连接再均衡
为 TCP 连接启用集群复制延迟有助于延迟创建导向器/备份数据流,从而消除与短期数据流相关的“非必要工作”。请注意,如果某个节点在创建导向器/备份数据流前出现故障,则无法恢复这些数据流。同样,如果流量在创建数据流前再均衡到其他节点,则无法恢复该数据流。不应为已对其禁用 TCP 随机化的流量启用 TCP 复制延迟。
过程
|
步骤 1 |
为 TCP 连接启用集群复制延迟: cluster replication delay seconds { http | match tcp {host ip_address | ip_address mask | any | any4 | any6} [{eq | lt | gt} port] { host ip_address | ip_address mask | any | any4 | any6} [{eq | lt | gt} port]} 示例:将 seconds 设置为介于 1 到 15 之间的值。默认启用 http 延迟,时间为 5 秒。 在多情景模式下,请在相应情景中配置此设置。 |
|
步骤 2 |
进入集群配置模式: cluster group name |
|
步骤 3 |
(可选)为 TCP 流量启用连接再均衡: conn-rebalance [ frequency seconds] 示例:此命令默认禁用。如果启用,ASA 会定期交换有关每秒连接数的信息,并将新连接从每秒连接数较多的设备分流到负载较低的设备。现有连接永远不会移动。此外,由于此命令仅基于每秒的连接数进行重新平衡,因此不会考虑每个节点上已建立的连接总数,并且连接总数可能并不相等。此频率的值为 1 到 360 秒,用于指定多长时间交换一次负载信息。默认值为 5 秒。 将连接分流到其他节点后,它将成为不对称连接。 请勿为站点间拓扑结构配置连接再均衡;您不需要将连接再均衡到位于不同站点的集群成员。 |
配置站点间功能
对于站点间集群,您可以自定义配置,以提高冗余性和稳定性。
启用导向器本地化
为了提高性能并缩短数据中心的站点间集群的往返时间延迟,您可以启用导向器本地化。新的连接通常实现了负载均衡,并且由特定站点中的集群成员拥有。但是,ASA 会向任意 站点的成员分配导向器角色。导向器本地化支持其他导向器角色:与所有者同一站点的本地导向器和可位于任意站点的全局导向器。将所有者和导向器保留在同一站点可以提高性能。此外,如果原始所有者发生故障,本地导向器将在同一站点选择新的连接所有者。当集群成员收到属于其他站点的连接的数据包时,使用全局导向器。
开始之前
-
在引导程序配置中为集群成员设置站点 ID。
-
以下流量类型不支持本地化:NAT 或 PAT 流量;SCTP 检查的流量;分段所有者查询。
过程
|
步骤 1 |
进入集群配置模式。 cluster group name 示例: |
|
步骤 2 |
启用导向器本地化。 director-localization |
启用站点冗余
为保护流量免受站点故障的影响,您可以启用站点冗余。如果连接的备份所有者与所有者位于同一站点,则将从另一个站点选择一个额外的备份所有者来保护流量免受站点故障的影响。
开始之前
-
在引导程序配置中为集群成员设置站点 ID。
过程
|
步骤 1 |
进入集群配置模式。 cluster group name 示例: |
|
步骤 2 |
启用站点冗余。 site-redundancy |
配置每站点免费 ARP
现在,ASA 可以生成免费 ARP (GARP) 数据包,以确保交换基础设施始终处于最新状态:它将作为每个站点优先级最高的成员,定期生成流向全局 MAC/IP 地址的 GARP 流量。
当使用来自集群的各站点 MAC 和 IP 地址数据包使用站点特定的 MAC 地址和 IP 地址时,集群接收的数据包使用全局 MAC 地址和 IP 地址。如果流量不是定期从全局 MAC 地址生成的,您的全局 MAC 地址交换机上可能会出现 MAC 地址超时。发生超时后,以全局 MAC 地址为目标的流量将在整个交换基础设施中进行泛洪,这有可能造成性能和安全问题。
当您为每台设备设置站点 ID 和为每个跨区以太网通道设置站点 MAC 地址时,默认情况下会启用 GARP。您可以自定义 GARP 间隔,也可以禁用 GARP。
开始之前
-
在引导程序配置中为集群成员设置站点 ID。
-
在控制设备配置中为跨区以太网通道设置每站点 MAC 地址。
过程
|
步骤 1 |
进入集群配置模式。 cluster group name 示例: |
|
步骤 2 |
自定义 GARP 间隔。 site-periodic-garp interval 秒
要禁用 GARP,请输入 no site-periodic-garp interval 。 |
配置集群流移动性
当服务器在站点之间移动时,您可以检查 LISP 流量以启用流移动性。
关于 LISP 检测
可以检查 LISP 流量,以便在站点间启用流移动性。
关于 LISP
利用数据中心的虚拟机移动性(例如,VMware VMotion),服务器可以在数据中心之间迁移,同时维持与客户端的连接。为了支持此类数据中心服务器移动性,路由器需要能够在服务器移动时更新通往服务器的入口路由。思科定位/ID 分离协议 (LISP) 架构将设备身份或终端标识符 (EID) 与设备位置或路由定位符 (RLOC) 分离开,并分隔到两个不同的编号空间,实现服务器迁移对客户端的透明化。例如,当服务器迁移到新的站点并且客户端向服务器发送流量时,路由器会将流量重定向到新位置。
LISP 需要充当特定角色的路由器和服务器,例如 LISP 出口隧道路由器 (ETR)、入口隧道路由器 (ITR)、第一跳路由器、映射解析器 (MR) 和映射服务器 (MS)。当服务器的第一跳路由器检测到服务器连接了其他路由器时,它会更新所有其他路由器和数据库,以便连接到客户端的 ITR 可以拦截、封装流量并将流量发送到新的服务器位置。
ASA LISP 支持
ASA 本身不运行 LISP;但是,它可以通过检查 LISP 流量确定位置更改,然后使用此信息进行无缝集群操作。如果不使用 LISP 集成,当服务器移动到新站点时,流量将到达位于新站点的 ASA 集群成员,而不是原始的流所有者。新 ASA将流量转发到旧站点的 ASA,然后旧 ASA必须将流量发回新站点,才能到达服务器。此类流量流并未处于最佳状态,称为“长号”或“发夹”。
如果使用 LISP 集成,ASA 集群成员可以检查第一跳路由器与 ETR 或 ITR 之间的 LISP 流量,然后将流所有者位置更改为新站点。
LISP 准则
-
ASA 集群成员必须位于第一跳路由器和该站点的 ITR 或 ETR 之间。ASA 集群本身不能作为扩展网段的第一跳路由器。
-
仅支持全分布数据流;集中数据流、半分布数据流或属于单个节点的数据流不会移动到新的所有者。半分布数据流包括应用(例如 SIP),其中作为父数据流所有者的同一 ASA 拥有所有子数据流。
-
集群仅移动第 3 和第 4 层流状态;一些应用数据可能丢失。
-
对于持续时间极短的数据流或非关键业务数据流,移动所有者可能并非最佳选择。在配置检查策略时,您可以控制该功能支持的流量类型,并应只对必要流量限制流移动性。
ASA LISP 实施
此功能包含多种相互关联的配置(本章将逐一说明):
-
(可选)基于主机或服务器 IP 地址限制检查的 EID - 第一跳路由器可能会向与 ASA 集群无关的主机或网络发送 EID 通知消息,因此,您可以限制只向与您的集群有关的服务器或网络发送 EID。例如,如果集群仅涉及 2 个站点,但是 LISP 在 3 个站点上运行,应只包括集群涉及的 2 个站点的 EID。
-
LISP 流量检查 - ASA 检查 UDP 端口 4342 上的 LISP 流量是否包含第一跳路由器与 ITR 或 ETR 之间发送的 EID 通知消息。ASA 维护着一个将 EID 和站点 ID 相关联的 EID 表。例如,您应检查包含第一跳路由器源 IP 地址以及 ITR 或 ETR 目标地址的 LISP 流量。请注意,没有为 LISP 流量分配导向器,并且 LISP 流量本身不参与集群状态共享。
-
用于启用指定流量的流移动性的服务策略 - 您应对关键业务流量启用流移动性。例如,您可以只对 HTTPS 流量和/或发送到特定服务器的流量启用流移动性。
-
站点 ID - ASA 使用集群中每个节点的站点 ID 确定新的所有者。
-
用于启用流移动性的集群级别配置 - 您还必须在集群级别启用流移动性。此开/关切换器允许您轻松地启用或禁用特定流量类或应用类的流移动性。
配置 LISP 检测
当服务器在站点之间移动时,您可以检查 LISP 流量以启用流移动性。
开始之前
-
根据配置控制节点引导程序设置和配置数据节点引导程序设置,为每个集群设备分配一个站点 ID。
-
LISP 流量未包含在 default-inspection-traffic 类中,因此,您在此过程中必须为 LISP 流量配置单独的类。
过程
|
步骤 1 |
(可选) 配置 LISP 检测映射以根据 IP 地址限制检测的 EID,并配置 LISP 预共享密钥: 示例: |
|
步骤 2 |
在端口 4342 上为第一跳路由器与 ITR 或ETR 之间的 UDP 流量配置 LISP检测: 示例:ASA 会检测 LISP 流量是否包含第一跳路由器与 ITR 或 ETR 之间发送的 EID 通知消息。ASA 维护着一个关联 EID 和站点 ID 的 EID 表。 |
|
步骤 3 |
为流量类启用流移动性: 示例: |
|
步骤 4 |
进入集群组配置模式,并为集群启用流移动性: cluster group name flow-mobility lisp 此开/关使您可以轻松地启用或禁用流移动性。 |
示例
以下示例:
-
将 EID 限制为 10.10.10.0/24 网络上的 EID
-
检查位于 192.168.50.89 的 LISP 路由器(内部)与位于 192.168.10.8 的 ITR 或 ETR 路由器(在另一个 ASA 接口上)之间的 LISP 流量 (UDP 4342)
-
为使用 HTTPS 在 10.10.10.0/24 上进入服务器的所有内部流量启用流移动性。
-
为集群启用流移动性。
access-list TRACKED_EID_LISP extended permit ip any 10.10.10.0 255.255.255.0
policy-map type inspect lisp LISP_EID_INSPECT
parameters
allowed-eid access-list TRACKED_EID_LISP
validate-key MadMaxShinyandChrome
!
access-list LISP_ACL extended permit udp host 192.168.50.89 host 192.168.10.8 eq 4342
class-map LISP_CLASS
match access-list LISP_ACL
policy-map INSIDE_POLICY
class LISP_CLASS
inspect lisp LISP_EID_INSPECT
service-policy INSIDE_POLICY interface inside
!
access-list IMPORTANT-FLOWS extended permit tcp any 10.10.10.0 255.255.255.0 eq https
class-map IMPORTANT-FLOWS-MAP
match access-list IMPORTANT-FLOWS
policy-map INSIDE_POLICY
class IMPORTANT-FLOWS-MAP
cluster flow-mobility lisp
!
cluster group cluster1
flow-mobility lisp
管理集群节点
部署集群后,您可以更改配置和管理集群节点。
成为非活动节点
要成为集群的非活动成员,请在节点上禁用集群,同时保持集群配置不变。
注 |
当 ASA 处于非活动状态(以手动方式或因运行状况检查失败)时,所有数据接口都将关闭;只有管理专用接口可以发送和接收流量。要恢复流量传输,请重新启用集群;或者,您也可以从集群中完全删除该节点。管理接口将保持打开,使用节点从集群 IP 池接收的 IP 地址。但如果您重新加载,而节点仍在集群中处于非主用状态(例如,您保存了已禁用集群的配置),则管理接口将被禁用。您必须使用控制台端口来进行任何进一步配置。 |
开始之前
-
您必须使用控制台端口;不能通过远程 CLI 连接启用或禁用集群。
-
对于多情景模式,请在系统执行空间中执行本程序。如果尚未进入系统配置模式,请输入 changeto system 命令。
过程
|
步骤 1 |
进入集群配置模式: cluster group name 示例: |
|
步骤 2 |
禁用集群: no enable 如果此节点是控制节点,则会进行新的控制选择,并且其他成员将成为控制节点。 集群配置保持不变,因此您可于稍后再次启用集群。 |
停用节点
要禁用您登录的节点以外的成员,请执行以下步骤。
注 |
当 ASA 处于非活动状态时,所有数据接口关闭;只有管理专用接口可以发送和接收流量。要恢复流量流,请重新启用集群。管理接口将保持打开,使用节点从集群 IP 池接收的 IP 地址。但如果您重新加载,而节点仍在集群中处于非主用状态(例如,假设您保存了已禁用集群的配置),管理接口将被禁用。您必须使用控制台端口来进行任何进一步的配置。 |
开始之前
对于多情景模式,请在系统执行空间中执行本程序。如果尚未进入系统配置模式,请输入 changeto system 命令。
过程
|
从集群中删除该节点: cluster remove unit node_name 引导程序配置保持不变,从控制节点同步的最新配置也保持不变,因此您可于稍后重新添加该节点而不会丢失配置。如果在数据节点上输入此命令来删除控制节点,则会选择新的控制节点。 要查看成员名称,请输入 cluster remove unit ?,或者输入 show cluster info 命令。 示例: |
重新加入集群
如果从集群中删除了某个节点(例如针对出现故障的接口),或者如果您手动停用了某个成员,那么您必须手动重新加入集群。
开始之前
-
您必须使用控制台端口来重新启用集群。其他接口已关闭。
-
对于多情景模式,请在系统执行空间中执行本程序。如果尚未进入系统配置模式,请输入 changeto system 命令。
-
确保故障已解决,再尝试重新加入集群。
过程
|
步骤 1 |
在控制台中,进入集群配置模式: cluster group name 示例: |
|
步骤 2 |
启用集群。 enable |
离开集群
要完全退出集群,需要删除整个集群引导程序配置。由于每个节点上的当前配置相同(从主用设备同步),因此退出集群就意味着要么从备份恢复集群前的配置,要么清除现有配置并重新开始配置以免 IP 地址冲突。
开始之前
您必须使用控制台端口;删除集群配置时,所有接口都会关闭,包括管理接口和集群控制链路。而且,您不能通过远程 CLI 连接启用或禁用集群。
过程
|
步骤 1 |
对于数据节点,禁用集群: cluster group cluster_name no enable 示例:在数据节点上启用集群时,您无法进行配置更改。 |
|
步骤 2 |
清除集群配置: clear configure cluster ASA 将关闭所有接口,包括管理接口和集群控制链路。 |
|
步骤 3 |
禁用集群接口模式: no cluster interface-mode 模式并非存储于配置中,因此必须手动重置。 |
|
步骤 4 |
如果有备份配置,可将备份配置复制到正在运行的配置中: copy backup_cfg running-config 示例: |
|
步骤 5 |
将配置保存到启动配置: write memory |
|
步骤 6 |
如果没有备份配置,请重新配置管理访问。例如,确保更改接口 IP 地址,并恢复正确的主机名。 |
更改控制节点
 小心 |
要更改控制节点,最好的方法是在控制节点上禁用集群,等到新的控制选举后再重新启用集群。如果必须指定要成为控制节点的具体节点,请使用本节中的程序。但是请注意,对集中功能而言,如果使用本程序强制更改控制节点,则所有连接都将断开,而您必须在新的控制节点上重新建立连接。 |
要更改控制节点,请执行以下步骤:
开始之前
对于多情景模式,请在系统执行空间中执行本程序。如果尚未进入系统配置模式,请输入 changeto system 命令。
过程
|
将新节点设置为控制节点: cluster control-node unitnode_name 示例:您需要重新连接到主集群 IP 地址。 要查看成员名称,请输入 cluster control-node unit ? (可查阅除当前节点之外的所有名称),或输入 show cluster info 命令。 |
在整个集群范围内执行命令
要向集群中的所有节点或某个特定节点发送命令,请执行以下步骤。向所有节点发送 show 命令以收集所有输出并将其显示在当前节点的控制台上。也可在整个集群范围内执行其他命令(如 capture 和 copy)。
过程
|
发送命令到所有节点,或者如果指定了节点名称,则发送到特定节点: cluster exec [unit node_name] command 示例:要查看节点名称,请输入 cluster exec unit ? (可查阅除当前节点之外的所有名称),或输入 show cluster info 命令。 |
示例
要同时将同一捕获文件从集群中的所有节点复制到 TFTP 服务器,请在控制节点上输入以下命令:
ciscoasa# cluster exec copy /pcap capture: tftp://10.1.1.56/capture1.pcap
多个 PCAP 文件(一个文件来自一个节点)将复制到 TFTP 服务器。目标捕获文件名会自动附加节点名称,例如 capture1_asa1.pcap、capture1_asa2.pcap 等。在本例中,asa1和asa2是集群节点名称。
以下是 cluster exec show port-channel 汇总命令的输出示例,显示了集群内每个节点的 EtherChannel 信息:
ciscoasa# cluster exec show port-channel summary
control node(LOCAL):***********************************************************
Number of channel-groups in use: 2
Group Port-channel Protocol Span-cluster Ports
------+-------------+-----------+-----------------------------------------------
1 Po1 LACP Yes Gi0/0(P)
2 Po2 LACP Yes Gi0/1(P)
slave:******************************************************************
Number of channel-groups in use: 2
Group Port-channel Protocol Span-cluster Ports
------+-------------+-----------+-----------------------------------------------
1 Po1 LACP Yes Gi0/0(P)
2 Po2 LACP Yes Gi0/1(P)
监控 ASA 集群
您可以监控集群状态和连接并排除故障。
监控集群状态
请参阅以下命令来监控集群状态:
-
show cluster info [health [details]]
如果没有关键字,show cluster info 命令将显示所有集群成员的状态。
show cluster info health 命令将显示接口、节点和整个集群的当前运行状况。details 关键字显示心跳消息失败的次数。
请参阅 show cluster info 命令的以下输出:
ciscoasa# show cluster info Cluster stbu: On This is "C" in state DATA_NODE ID : 0 Site ID : 1 Version : 9.4(1) Serial No.: P3000000025 CCL IP : 10.0.0.3 CCL MAC : 000b.fcf8.c192 Last join : 17:08:59 UTC Sep 26 2011 Last leave: N/A Other members in the cluster: Unit "D" in state DATA_NODE ID : 1 Site ID : 1 Version : 9.4(1) Serial No.: P3000000001 CCL IP : 10.0.0.4 CCL MAC : 000b.fcf8.c162 Last join : 19:13:11 UTC Sep 23 2011 Last leave: N/A Unit "A" in state CONTROL_NODE ID : 2 Site ID : 2 Version : 9.4(1) Serial No.: JAB0815R0JY CCL IP : 10.0.0.1 CCL MAC : 000f.f775.541e Last join : 19:13:20 UTC Sep 23 2011 Last leave: N/A Unit "B" in state DATA_NODE ID : 3 Site ID : 2 Version : 9.4(1) Serial No.: P3000000191 CCL IP : 10.0.0.2 CCL MAC : 000b.fcf8.c61e Last join : 19:13:50 UTC Sep 23 2011 Last leave: 19:13:36 UTC Sep 23 2011 -
show cluster info auto-join
显示集群节点是否将在一段延迟后自动重新加入集群,以及是否已清除故障条件(例如等待许可证、机箱运行状况检查失败,等等)。如果节点已永久禁用,或节点已在集群中,则此命令将不会显示任何输出。
请参阅 show cluster info auto-join 命令的以下输出:
ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster in 253 seconds. Quit reason: Received control message DISABLE ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Control node has application down that data node has up. ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Chassis-blade health check failed. ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Service chain application became down. ciscoasa(cfg-cluster)# show cluster info auto-join Unit will try to join cluster when quit reason is cleared. Quit reason: Unit is kicked out from cluster because of Application health check failure. ciscoasa(cfg-cluster)# show cluster info auto-join Unit join is pending (waiting for the smart license entitlement: ent1) ciscoasa(cfg-cluster)# show cluster info auto-join Unit join is pending (waiting for the smart license export control flag) -
show cluster info transport{asp |cp [detail]}
显示以下项目传输相关的统计信息:
-
asp — 数据平面传输统计信息。
-
cp — 控制平面传输统计信息。
如果您输入 detail 关键字,您可以查看集群可靠传输协议的使用情况,以便确定控制平面中的缓冲区已满时的丢包问题。请参阅 show cluster info transport cp detail 命令的以下输出:
ciscoasa# show cluster info transport cp detail Member ID to name mapping: 0 - unit-1-1 2 - unit-4-1 3 - unit-2-1 Legend: U - unreliable messages UE - unreliable messages error SN - sequence number ESN - expecting sequence number R - reliable messages RE - reliable messages error RDC - reliable message deliveries confirmed RA - reliable ack packets received RFR - reliable fast retransmits RTR - reliable timer-based retransmits RDP - reliable message dropped RDPR - reliable message drops reported RI - reliable message with old sequence number RO - reliable message with out of order sequence number ROW - reliable message with out of window sequence number ROB - out of order reliable messages buffered RAS - reliable ack packets sent This unit as a sender -------------------------- all 0 2 3 U 123301 3867966 3230662 3850381 UE 0 0 0 0 SN 1656a4ce acb26fe 5f839f76 7b680831 R 733840 1042168 852285 867311 RE 0 0 0 0 RDC 699789 934969 740874 756490 RA 385525 281198 204021 205384 RFR 27626 56397 0 0 RTR 34051 107199 111411 110821 RDP 0 0 0 0 RDPR 0 0 0 0 This unit as a receiver of broadcast messages --------------------------------------------- 0 2 3 U 111847 121862 120029 R 7503 665700 749288 ESN 5d75b4b3 6d81d23 365ddd50 RI 630 34278 40291 RO 0 582 850 ROW 0 566 850 ROB 0 16 0 RAS 1571 123289 142256 This unit as a receiver of unicast messages --------------------------------------------- 0 2 3 U 1 3308122 4370233 R 513846 879979 1009492 ESN 4458903a 6d841a84 7b4e7fa7 RI 66024 108924 102114 RO 0 0 0 ROW 0 0 0 ROB 0 0 0 RAS 130258 218924 228303 Gated Tx Buffered Message Statistics ------------------------------------- current sequence number: 0 total: 0 current: 0 high watermark: 0 delivered: 0 deliver failures: 0 buffer full drops: 0 message truncate drops: 0 gate close ref count: 0 num of supported clients:45 MRT Tx of broadcast messages ============================= Message high watermark: 3% Total messages buffered at high watermark: 5677 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage Cluster Redirect Client 4153 73% Route Cluster Client 419 7% RRI Cluster Client 1105 19% Current MRT buffer usage: 0% Total messages buffered in real-time: 1 [Per-client message usage in real-time] Legend: F - MRT messages sending when buffer is full L - MRT messages sending when cluster node leave R - MRT messages sending in Rx thread ---------------------------------------------------------------------------- Client name Total messages Percentage F L R VPN Clustering HA Client 1 100% 0 0 0 MRT Tx of unitcast messages(to member_id:0) ============================================ Message high watermark: 31% Total messages buffered at high watermark: 4059 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage Cluster Redirect Client 3731 91% RRI Cluster Client 328 8% Current MRT buffer usage: 29% Total messages buffered in real-time: 3924 [Per-client message usage in real-time] Legend: F - MRT messages sending when buffer is full L - MRT messages sending when cluster node leave R - MRT messages sending in Rx thread ---------------------------------------------------------------------------- Client name Total messages Percentage F L R Cluster Redirect Client 3607 91% 0 0 0 RRI Cluster Client 317 8% 0 0 0 MRT Tx of unitcast messages(to member_id:2) ============================================ Message high watermark: 14% Total messages buffered at high watermark: 578 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage VPN Clustering HA Client 578 100% Current MRT buffer usage: 0% Total messages buffered in real-time: 0 MRT Tx of unitcast messages(to member_id:3) ============================================ Message high watermark: 12% Total messages buffered at high watermark: 573 [Per-client message usage at high watermark] --------------------------------------------------------------- Client name Total messages Percentage VPN Clustering HA Client 572 99% Cluster VPN Unique ID Client 1 0% Current MRT buffer usage: 0% Total messages buffered in real-time: 0
-
-
show cluster history
显示集群历史记录,以及有关集群节点加入失败的原因或节点离开集群的原因的错误消息。
捕获整个集群范围内的数据包
有关在集群中捕获数据包的信息,请参阅以下命令:
cluster exec capture
要支持集群范围的故障排除,您可以使用 cluster exec capture 命令在控制节点上启用捕获集群特定流量的功能,随后集群中的所有数据节点上将自动启用此功能。
监控集群资源
请参阅以下命令以监控集群资源:
show cluster {cpu | memory | resource} [options]
显示整个集群的聚合数据。可用 options 取决于数据类型。
监控集群流量
请参阅以下命令以监控集群流量:
-
show conn [detail], cluster exec show conn
show conn 命令显示一个传输是导向者、备用还是转发者传输。在任意节点上使用 cluster exec show conn 命令可查看所有连接。此命令可以显示单个流的流量到达集群中不同 ASA 的方式。集群的吞吐量取决于负载均衡的效率和配置。此命令可以让您很方便地查看某个连接的流量如何流经集群,也可以帮助您了解负载均衡器对传输的性能有何影响。
show conn detail 命令还显示哪些流应 遵守流移动性。
以下是 show conn detail 命令的输出示例:
ciscoasa/ASA2/data node# show conn detail 12 in use, 13 most used Cluster stub connections: 0 in use, 46 most used Flags: A - awaiting inside ACK to SYN, a - awaiting outside ACK to SYN, B - initial SYN from outside, b - TCP state-bypass or nailed, C - CTIQBE media, c - cluster centralized, D - DNS, d - dump, E - outside back connection, e - semi-distributed, F - outside FIN, f - inside FIN, G - group, g - MGCP, H - H.323, h - H.225.0, I - inbound data, i - incomplete, J - GTP, j - GTP data, K - GTP t3-response k - Skinny media, L - LISP triggered flow owner mobility, M - SMTP data, m - SIP media, n - GUP O - outbound data, o - offloaded, P - inside back connection, Q - Diameter, q - SQL*Net data, R - outside acknowledged FIN, R - UDP SUNRPC, r - inside acknowledged FIN, S - awaiting inside SYN, s - awaiting outside SYN, T - SIP, t - SIP transient, U - up, V - VPN orphan, W - WAAS, w - secondary domain backup, X - inspected by service module, x - per session, Y - director stub flow, y - backup stub flow, Z - Scansafe redirection, z - forwarding stub flow ESP outside: 10.1.227.1/53744 NP Identity Ifc: 10.1.226.1/30604, , flags c, idle 0s, uptime 1m21s, timeout 30s, bytes 7544, cluster sent/rcvd bytes 0/0, owners (0,255) Traffic received at interface outside Locally received: 7544 (93 byte/s) Traffic received at interface NP Identity Ifc Locally received: 0 (0 byte/s) UDP outside: 10.1.227.1/500 NP Identity Ifc: 10.1.226.1/500, flags -c, idle 1m22s, uptime 1m22s, timeout 2m0s, bytes 1580, cluster sent/rcvd bytes 0/0, cluster sent/rcvd total bytes 0/0, owners (0,255) Traffic received at interface outside Locally received: 864 (10 byte/s) Traffic received at interface NP Identity Ifc Locally received: 716 (8 byte/s)要对连接流进行故障排除,请先在任意节点上输入 cluster exec show conn 命令查看所有节点上的连接。寻找具有以下标志的流:导向者 (Y)、备用 (y) 和转发者 (z)。下例显示了三台 ASA 上的一条从 172.18.124.187:22 到 192.168.103.131:44727 的 SSH 连接;ASA 1 带有 z 标志,表示其是该连接的转发者;ASA3 带有 Y 标志,表示其是该连接的导向者;而 ASA2 则没有特殊的标志,表示其是所有者。在出站方向,此连接的数据包进入 ASA2 上的内部接口并从外部接口流出。在入站方向,此连接的数据包进入 ASA 1 和 ASA3 上的外部接口,通过集群控制链路被转发到 ASA2,然后流出 ASA2 上的内部接口。
ciscoasa/ASA1/control node# cluster exec show conn ASA1(LOCAL):********************************************************** 18 in use, 22 most used Cluster stub connections: 0 in use, 5 most used TCP outside 172.18.124.187:22 inside 192.168.103.131:44727, idle 0:00:00, bytes 37240828, flags z ASA2:***************************************************************** 12 in use, 13 most used Cluster stub connections: 0 in use, 46 most used TCP outside 172.18.124.187:22 inside 192.168.103.131:44727, idle 0:00:00, bytes 37240828, flags UIO ASA3:***************************************************************** 10 in use, 12 most used Cluster stub connections: 2 in use, 29 most used TCP outside 172.18.124.187:22 inside 192.168.103.131:44727, idle 0:00:03, bytes 0, flags Y -
show cluster info [conn-distribution | packet-distribution | loadbalance | flow-mobility counters]
show cluster info conn-distribution 和 show cluster info packet-distribution 命令显示流量在所有集群节点上的分布。这些命令可以帮助您评估和调整外部负载均衡器。
show cluster info loadbalance 命令显示连接再均衡统计信息。
The show cluster info flow-mobility counters 命令显示 EID 移动和流所有者移动信息。请参阅 show cluster info flow-mobility counters 的以下输出:
ciscoasa# show cluster info flow-mobility counters EID movement notification received : 4 EID movement notification processed : 4 Flow owner moving requested : 2 -
show cluster info load-monitor [details]
show cluster info load-monitor 命令显示最后一个间隔的集群成员的流量负载,以及已配置的总间隔数(默认情况下为 30)。使用 details 关键字查看每个时间间隔的每个度量值。
ciscoasa(cfg-cluster)# show cluster info load-monitor ID Unit Name 0 B 1 A_1 Information from all units with 20 second interval: Unit Connections Buffer Drops Memory Used CPU Used Average from last 1 interval: 0 0 0 14 25 1 0 0 16 20 Average from last 30 interval: 0 0 0 12 28 1 0 0 13 27 ciscoasa(cfg-cluster)# show cluster info load-monitor details ID Unit Name 0 B 1 A_1 Information from all units with 20 second interval Connection count captured over 30 intervals: Unit ID 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Unit ID 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Buffer drops captured over 30 intervals: Unit ID 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Unit ID 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Memory usage(%) captured over 30 intervals: Unit ID 0 25 25 30 30 30 35 25 25 35 30 30 30 25 25 30 25 25 35 30 30 30 25 25 25 25 20 30 30 30 30 Unit ID 1 30 25 35 25 30 30 25 25 35 25 30 35 30 30 35 30 30 30 25 20 30 25 25 30 20 30 35 30 30 35 CPU usage(%) captured over 30 intervals: Unit ID 0 25 25 30 30 30 35 25 25 35 30 30 30 25 25 30 25 25 35 30 30 30 25 25 25 25 20 30 30 30 30 Unit ID 1 30 25 35 25 30 30 25 25 35 25 30 35 30 30 35 30 30 30 25 20 30 25 25 30 20 30 35 30 30 35 -
show cluster {access-list | conn | traffic | user-identity | xlate} [options]
显示整个集群的聚合数据。可用 options 取决于数据类型。
请参阅 show cluster access-list 命令的以下输出:
ciscoasa# show cluster access-list hitcnt display order: cluster-wide aggregated result, unit-A, unit-B, unit-C, unit-D access-list cached ACL log flows: total 0, denied 0 (deny-flow-max 4096) alert-interval 300 access-list 101; 122 elements; name hash: 0xe7d586b5 access-list 101 line 1 extended permit tcp 192.168.143.0 255.255.255.0 any eq www (hitcnt=0, 0, 0, 0, 0) 0x207a2b7d access-list 101 line 2 extended permit tcp any 192.168.143.0 255.255.255.0 (hitcnt=0, 0, 0, 0, 0) 0xfe4f4947 access-list 101 line 3 extended permit tcp host 192.168.1.183 host 192.168.43.238 (hitcnt=1, 0, 0, 0, 1) 0x7b521307 access-list 101 line 4 extended permit tcp host 192.168.1.116 host 192.168.43.238 (hitcnt=0, 0, 0, 0, 0) 0x5795c069 access-list 101 line 5 extended permit tcp host 192.168.1.177 host 192.168.43.238 (hitcnt=1, 0, 0, 1, 0) 0x51bde7ee access list 101 line 6 extended permit tcp host 192.168.1.177 host 192.168.43.13 (hitcnt=0, 0, 0, 0, 0) 0x1e68697c access-list 101 line 7 extended permit tcp host 192.168.1.177 host 192.168.43.132 (hitcnt=2, 0, 0, 1, 1) 0xc1ce5c49 access-list 101 line 8 extended permit tcp host 192.168.1.177 host 192.168.43.192 (hitcnt=3, 0, 1, 1, 1) 0xb6f59512 access-list 101 line 9 extended permit tcp host 192.168.1.177 host 192.168.43.44 (hitcnt=0, 0, 0, 0, 0) 0xdc104200 access-list 101 line 10 extended permit tcp host 192.168.1.112 host 192.168.43.44 (hitcnt=429, 109, 107, 109, 104) 0xce4f281d access-list 101 line 11 extended permit tcp host 192.168.1.170 host 192.168.43.238 (hitcnt=3, 1, 0, 0, 2) 0x4143a818 access-list 101 line 12 extended permit tcp host 192.168.1.170 host 192.168.43.169 (hitcnt=2, 0, 1, 0, 1) 0xb18dfea4 access-list 101 line 13 extended permit tcp host 192.168.1.170 host 192.168.43.229 (hitcnt=1, 1, 0, 0, 0) 0x21557d71 access-list 101 line 14 extended permit tcp host 192.168.1.170 host 192.168.43.106 (hitcnt=0, 0, 0, 0, 0) 0x7316e016 access-list 101 line 15 extended permit tcp host 192.168.1.170 host 192.168.43.196 (hitcnt=0, 0, 0, 0, 0) 0x013fd5b8 access-list 101 line 16 extended permit tcp host 192.168.1.170 host 192.168.43.75 (hitcnt=0, 0, 0, 0, 0) 0x2c7dba0d要显示所有节点在用连接的汇聚计数,请输入:
ciscoasa# show cluster conn count Usage Summary In Cluster:********************************************* 200 in use (cluster-wide aggregated) cl2(LOCAL):*********************************************************** 100 in use, 100 most used cl1:****************************************************************** 100 in use, 100 most used -
show asp cluster counter
此命令对于数据路径故障排除非常有用。
监控集群路由
有关集群路由的信息,请参阅以下命令:
-
show route cluster
-
debug route cluster
显示集群的路由信息。
-
show lisp eid
显示 ASA EID 表,表中显示了 EID 和站点 ID。
请参阅 cluster exec show lisp eid 命令的以下输出。
ciscoasa# cluster exec show lisp eid L1(LOCAL):************************************************************ LISP EID Site ID 33.44.33.105 2 33.44.33.201 2 11.22.11.1 4 11.22.11.2 4 L2:******************************************************************* LISP EID Site ID 33.44.33.105 2 33.44.33.201 2 11.22.11.1 4 11.22.11.2 4 -
show asp table classify domain inspect-lisp
该命令对于故障排除非常有用。
配置集群日志记录
有关为集群配置日志记录的信息,请参阅以下命令:
logging device-id
集群中的每个节点将独立生成系统日志消息。您可以使用 logging device-id 命令来生成具有相同或不同设备 ID 的系统日志消息,以使消息看上去是来自集群中的相同或不同节点。
监控集群接口
请参阅以下用于监控集群接口的命令:
-
show cluster interface-mode
显示集群接口模式。
-
show port-channel
包括有关端口通道是否跨网络的信息。
-
show lacp cluster {system-mac | system-id}
显示 cLACP 系统 ID 和优先级。
-
debug lacp cluster [all | ccp | misc | protocol]
显示 cLACP 的调试消息。
-
show interface
显示使用中的站点 MAC 地址的使用情况:
ciscoasa# show interface port-channel1.3151 Interface Port-channel1.3151 "inside", is up, line protocol is up Hardware is EtherChannel/LACP, BW 1000 Mbps, DLY 10 usec VLAN identifier 3151 MAC address aaaa.1111.1234, MTU 1500 Site Specific MAC address aaaa.1111.aaaa IP address 10.3.1.1, subnet mask 255.255.255.0 Traffic Statistics for "inside": 132269 packets input, 6483425 bytes 1062 packets output, 110448 bytes 98530 packets dropped
调试集群
请参阅以下用于调试集群的命令:
-
debug cluster [ccp | datapath | fsm | general | hc | license | rpc | transport]
显示集群的调试消息。
-
debug cluster flow-mobility
显示与集群流移动性相关的事件。
-
debug lisp eid-notify-intercept
当 eid-notify 被拦截时显示事件。
-
show cluster info trace
show cluster info trace 命令显示调试信息,供进一步排除故障之用。
请参阅 show cluster info trace 命令的以下输出:
ciscoasa# show cluster info trace Feb 02 14:19:47.456 [DBUG]Receive CCP message: CCP_MSG_LOAD_BALANCE Feb 02 14:19:47.456 [DBUG]Receive CCP message: CCP_MSG_LOAD_BALANCE Feb 02 14:19:47.456 [DBUG]Send CCP message to all: CCP_MSG_KEEPALIVE from 80-1 at CONTROL_NODE例如,如果您看到以下消息显示两个具有相同 local-unit 名称的节点充当控制节点,这可能意味着两个节点具有相同的 local-unit 名称(请检查您的配置),或者某个节点正在接收自己的广播消息(请检查您的网络)。
ciscoasa# show cluster info trace May 23 07:27:23.113 [CRIT]Received datapath event 'multi control_nodes' with parameter 1. May 23 07:27:23.113 [CRIT]Found both unit-9-1 and unit-9-1 as control_node units. Control_node role retained by unit-9-1, unit-9-1 will leave then join as a Data_node May 23 07:27:23.113 [DBUG]Send event (DISABLE, RESTART | INTERNAL-EVENT, 5000 msecs, Detected another Control_node, leave and re-join as Data_node) to FSM. Current state CONTROL_NODE May 23 07:27:23.113 [INFO]State machine changed from state CONTROL_NODE to DISABLED
ASA 集群示例
这些示例包括典型部署中所有与集群相关的 ASA 配置。
ASA 和交换机配置示例
以下配置示例连接 ASA 与交换机之间的下列接口:
|
ASA 接口 |
交换机接口 |
|---|---|
|
以太网 1/2 |
GigabitEthernet 1/0/15 |
|
以太网 1/3 |
GigabitEthernet 1/0/16 |
|
以太网 1/4 |
GigabitEthernet 1/0/17 |
|
以太网1/5 |
GigabitEthernet 1/0/18 |
ASA 配置
每台设备上的接口模式
cluster interface-mode spanned force
ASA1 控制单元引导程序配置
interface Ethernet1/6
channel-group 1 mode on
no shutdown
!
interface Ethernet1/7
channel-group 1 mode on
no shutdown
!
interface Port-channel1
description Clustering Interface
!
cluster group Moya
local-unit A
cluster-interface Port-channel1 ip 10.0.0.1 255.255.255.0
priority 10
key emphyri0
enable noconfirm
ASA2 数据单元引导程序配置
interface Ethernet1/6
channel-group 1 mode on
no shutdown
!
interface Ethernet1/7
channel-group 1 mode on
no shutdown
!
interface Port-channel1
description Clustering Interface
!
cluster group Moya
local-unit B
cluster-interface Port-channel1 ip 10.0.0.2 255.255.255.0
priority 11
key emphyri0
enable as-data-node
控制单元接口配置
ip local pool mgmt-pool 10.53.195.231-10.53.195.232
interface Ethernet1/2
channel-group 10 mode active
no shutdown
!
interface Ethernet1/3
channel-group 10 mode active
no shutdown
!
interface Ethernet1/4
channel-group 11 mode active
no shutdown
!
interface Ethernet1/5
channel-group 11 mode active
no shutdown
!
interface Management1/1
management-only
nameif management
ip address 10.53.195.230 cluster-pool mgmt-pool
security-level 100
no shutdown
!
interface Port-channel10
mac-address aaaa.bbbb.cccc
nameif inside
security-level 100
ip address 209.165.200.225 255.255.255.224
!
interface Port-channel11
mac-address aaaa.dddd.cccc
nameif outside
security-level 0
ip address 209.165.201.1 255.255.255.224
思科 IOS 交换机配置
interface GigabitEthernet1/0/15
switchport access vlan 201
switchport mode access
spanning-tree portfast
channel-group 10 mode active
!
interface GigabitEthernet1/0/16
switchport access vlan 201
switchport mode access
spanning-tree portfast
channel-group 10 mode active
!
interface GigabitEthernet1/0/17
switchport access vlan 401
switchport mode access
spanning-tree portfast
channel-group 11 mode active
!
interface GigabitEthernet1/0/18
switchport access vlan 401
switchport mode access
spanning-tree portfast
channel-group 11 mode active
interface Port-channel10
switchport access vlan 201
switchport mode access
interface Port-channel11
switchport access vlan 401
switchport mode access
单臂防火墙
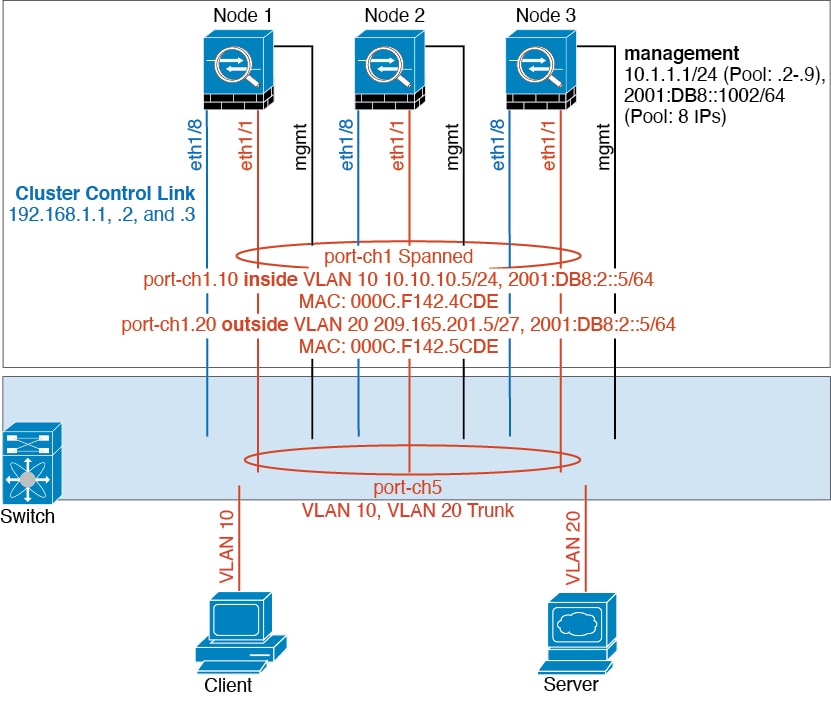
来自不同安全域的数据流量与不同的 VLAN 关联,例如,VLAN 10 用于内部网络,而 VLAN 20 用于外部网络。每台 ASA 都有一个连接到外部交换机或路由器的物理端口。启用中继使物理链路上的所有数据包都采用 802.1q 封装。ASA 是 VLAN 10 与 VLAN 20 之间的防火墙。
使用跨网络 EtherChannel 时,所有数据链路在交换机侧分组为一个 EtherChannel。如果一台 ASA 变得不可用,交换机将在其余设备之间再均衡流量。
每台设备上的接口模式
cluster interface-mode spanned force
设备 1 控制单元引导程序配置
interface ethernet1/8
no shutdown
description CCL
cluster group cluster1
local-unit asa1
cluster-interface ethernet1/8 ip 192.168.1.1 255.255.255.0
priority 1
key chuntheunavoidable
enable noconfirm
设备 2 数据单元引导程序配置
interface ethernet1/8
no shutdown
description CCL
cluster group cluster1
local-unit asa2
cluster-interface ethernet1/8 ip 192.168.1.2 255.255.255.0
priority 2
key chuntheunavoidable
enable as-data-node
单元 3 数据单元引导程序配置
interface ethernet1/8
no shutdown
description CCL
cluster group cluster1
local-unit asa3
cluster-interface ethernet1/8 ip 192.168.1.3 255.255.255.0
priority 3
key chuntheunavoidable
enable as-data-node
控制单元接口配置
ip local pool mgmt 10.1.1.2-10.1.1.9
ipv6 local pool mgmtipv6 2001:DB8::1002/64 8
interface management 1/1
nameif management
ip address 10.1.1.1 255.255.255.0 cluster-pool mgmt
ipv6 address 2001:DB8::1001/32 cluster-pool mgmtipv6
security-level 100
management-only
no shutdown
interface ethernet1/1
channel-group 1 mode active
no shutdown
interface port-channel 1
interface port-channel 1.10
vlan 10
nameif inside
ip address 10.10.10.5 255.255.255.0
ipv6 address 2001:DB8:1::5/64
mac-address 000C.F142.4CDE
interface port-channel 1.20
vlan 20
nameif outside
ip address 209.165.201.1 255.255.255.224
ipv6 address 2001:DB8:2::8/64
mac-address 000C.F142.5CDE
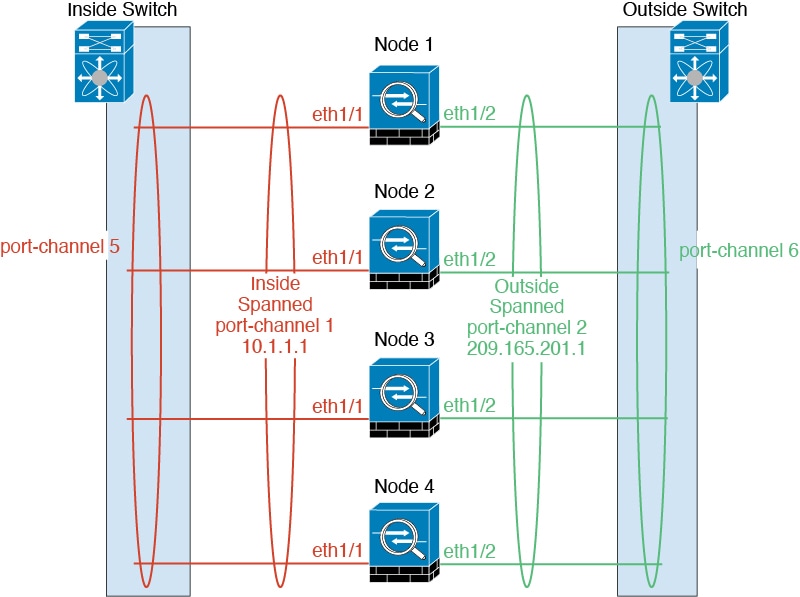
流量分隔
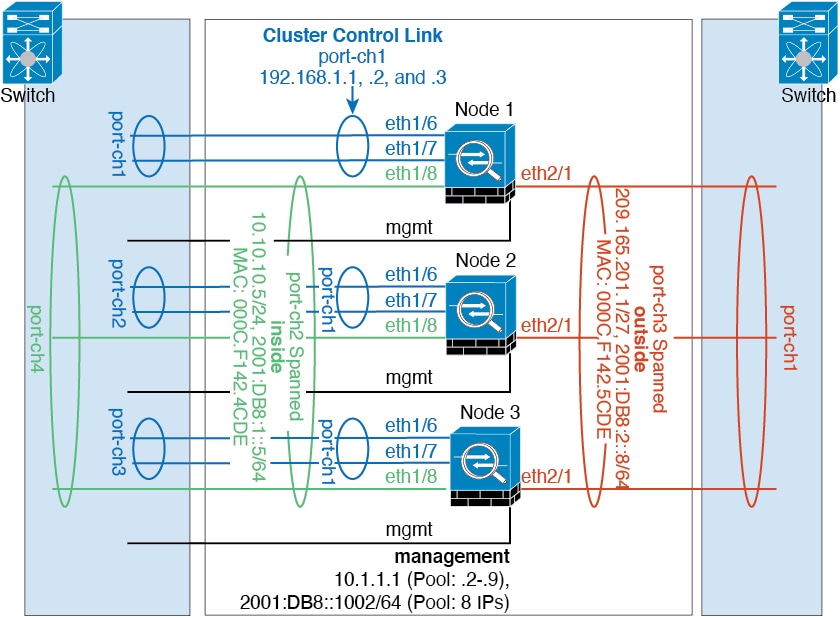
您可能更愿意在内部和外部网络之间采用物理方式分离流量。
如上图所示,左侧有一个跨网络 EtherChannel 连接到内部交换机,而右侧的另一个跨网络 EtherChannel 连接到外部交换机。如果需要,您还可以在每个 EtherChannel 上创建 VLAN 子接口。
每台设备上的接口模式
cluster interface-mode spanned force
设备 1 控制单元引导程序配置
interface ethernet 1/6
channel-group 1 mode on
no shutdown
interface ethernet 1/7
channel-group 1 mode on
no shutdown
interface port-channel 1
description CCL
cluster group cluster1
local-unit asa1
cluster-interface port-channel1 ip 192.168.1.1 255.255.255.0
priority 1
key chuntheunavoidable
enable noconfirm
设备 2 数据单元引导程序配置
interface ethernet 1/6
channel-group 1 mode on
no shutdown
interface ethernet 1/7
channel-group 1 mode on
no shutdown
interface port-channel 1
description CCL
cluster group cluster1
local-unit asa2
cluster-interface port-channel1 ip 192.168.1.2 255.255.255.0
priority 2
key chuntheunavoidable
enable as-data-node
单元 3 数据单元引导程序配置
interface ethernet 1/6
channel-group 1 mode on
no shutdown
interface ethernet 1/7
channel-group 1 mode on
no shutdown
interface port-channel 1
description CCL
cluster group cluster1
local-unit asa3
cluster-interface port-channel1 ip 192.168.1.3 255.255.255.0
priority 3
key chuntheunavoidable
enable as-data-node
控制单元接口配置
ip local pool mgmt 10.1.1.2-10.1.1.9
ipv6 local pool mgmtipv6 2001:DB8::1002/64 8
interface management 1/1
nameif management
ip address 10.1.1.1 255.255.255.0 cluster-pool mgmt
ipv6 address 2001:DB8::1001/32 cluster-pool mgmtipv6
security-level 100
management-only
no shutdown
interface ethernet 1/8
channel-group 2 mode active
no shutdown
interface port-channel 2
nameif inside
ip address 10.10.10.5 255.255.255.0
ipv6 address 2001:DB8:1::5/64
mac-address 000C.F142.4CDE
interface ethernet 2/1
channel-group 3 mode active
no shutdown
interface port-channel 3
nameif outside
ip address 209.165.201.1 255.255.255.224
ipv6 address 2001:DB8:2::8/64
mac-address 000C.F142.5CDE
路由模式站点间集群的 OTV 配置
使用跨区以太网通道的路由模式的站点间集群能否成功,取决于 OTV 的配置和监控是否适当。OTV 通过在 DCI 上转发数据包来发挥重要作用。仅当在其转发表中获知 MAC 地址时,OTV 才会通过 DCI 转发单播数据包。如果在 OTV 转发表中未获知 MAC 地址,它将丢弃单播数据包。
OTV 配置示例
//Sample OTV config:
//3151 – Inside VLAN, 3152 – Outside VLAN, 202 – CCL VLAN
//aaaa.1111.1234 – ASA inside interface global vMAC
//0050.56A8.3D22 – Server MAC
feature ospf
feature otv
mac access-list ALL_MACs
10 permit any any
mac access-list HSRP_VMAC
10 permit aaaa.1111.1234 0000.0000.0000 any
20 permit aaaa.2222.1234 0000.0000.0000 any
30 permit any aaaa.1111.1234 0000.0000.0000
40 permit any aaaa.2222.1234 0000.0000.0000
vlan access-map Local 10
match mac address HSRP_VMAC
action drop
vlan access-map Local 20
match mac address ALL_MACs
action forward
vlan filter Local vlan-list 3151-3152
//To block global MAC with ARP inspection:
arp access-list HSRP_VMAC_ARP
10 deny aaaa.1111.1234 0000.0000.0000 any
20 deny aaaa.2222.1234 0000.0000.0000 any
30 deny any aaaa.1111.1234 0000.0000.0000
40 deny any aaaa.2222.1234 0000.0000.0000
50 permit ip any mac
ip arp inspection filter HSRP_VMAC_ARP 3151-3152
no ip igmp snooping optimise-multicast-flood
vlan 1,202,1111,2222,3151-3152
otv site-vlan 2222
mac-list GMAC_DENY seq 10 deny aaaa.aaaa.aaaa ffff.ffff.ffff
mac-list GMAC_DENY seq 20 deny aaaa.bbbb.bbbb ffff.ffff.ffff
mac-list GMAC_DENY seq 30 permit 0000.0000.0000 0000.0000.0000
route-map stop-GMAC permit 10
match mac-list GMAC_DENY
interface Overlay1
otv join-interface Ethernet8/1
otv control-group 239.1.1.1
otv data-group 232.1.1.0/28
otv extend-vlan 202, 3151
otv arp-nd timeout 60
no shutdown
interface Ethernet8/1
description uplink_to_OTV_cloud
mtu 9198
ip address 10.4.0.18/24
ip igmp version 3
no shutdown
interface Ethernet8/2
interface Ethernet8/3
description back_to_default_vdc_e6/39
switchport
switchport mode trunk
switchport trunk allowed vlan 202,2222,3151-3152
mac packet-classify
no shutdown
otv-isis default
vpn Overlay1
redistribute filter route-map stop-GMAC
otv site-identifier 0x2
//OTV flood not required for ARP inspection:
otv flood mac 0050.56A8.3D22 vlan 3151
因站点故障需要修改 OTV 过滤器
如果站点断开,需要删除 OTV 的过滤器,因为无需再阻止全局 MAC 地址。还需要一些其他配置。
您需要在正常工作的站点中的 OTV 交换机上添加 ASA 全局 MAC 地址的静态条目。此条目将允许另一端的 OTV 在重叠接口上添加这些条目。之所以需要此步骤,是因为如果服务器和客户端已有 ASA 的 ARP 条目(对于现有连接即是如此),它们将不再发送该 ARP。因此,OTV 将不会有机会在其转发表中获知 ASA 全局 MAC 地址。由于 OTV 的转发表中没有该全局 MAC 地址,并且根据 OTV 设计,它不会通过重叠接口泛洪发送单播数据包,则它将丢弃从服务器到全局 MAC 地址的单播数据包,现有连接将中断。
//OTV filter configs when one of the sites is down
mac-list GMAC_A seq 10 permit 0000.0000.0000 0000.0000.0000
route-map a-GMAC permit 10
match mac-list GMAC_A
otv-isis default
vpn Overlay1
redistribute filter route-map a-GMAC
no vlan filter Local vlan-list 3151
//For ARP inspection, allow global MAC:
arp access-list HSRP_VMAC_ARP_Allow
50 permit ip any mac
ip arp inspection filter HSRP_VMAC_ARP_Allow 3151-3152
mac address-table static aaaa.1111.1234 vlan 3151 interface Ethernet8/3
//Static entry required only in the OTV in the functioning Site
当另一个站点恢复时,您需要重新添加过滤器,并删除 OTV 上的此静态条目。清除两个 OTV 上的动态 MAC 地址表,从而清除全局 MAC 地址的重叠条目,这一点非常重要。
MAC 地址表清除
当站点断开并且全局 MAC 地址的静态条目已添加到 OTV 时,您需要让另一个 OTV 获知重叠接口上的全局 MAC 地址。在另一个站点恢复后,应清除这些条目。务必清除 MAC 地址表,以确保 OTV 的转发表中没有这些条目。
cluster-N7k6-OTV# show mac address-table
Legend:
* - primary entry, G - Gateway MAC, (R) - Routed MAC, O - Overlay MAC
age - seconds since last seen,+ - primary entry using vPC Peer-Link,
(T) - True, (F) - False
VLAN MAC Address Type age Secure NTFY Ports/SWID.SSID.LID
---------+-----------------+--------+---------+------+----+------------------
G - d867.d900.2e42 static - F F sup-eth1(R)
O 202 885a.92f6.44a5 dynamic - F F Overlay1
* 202 885a.92f6.4b8f dynamic 5 F F Eth8/3
O 3151 0050.5660.9412 dynamic - F F Overlay1
* 3151 aaaa.1111.1234 dynamic 50 F F Eth8/3
OTV ARP 缓存监控
OTV 为代理 ARP 维护通过 OTV 接口获知的 IP 地址的 ARP 缓存。
cluster-N7k6-OTV# show otv arp-nd-cache
OTV ARP/ND L3->L2 Address Mapping Cache
Overlay Interface Overlay1
VLAN MAC Address Layer-3 Address Age Expires In
3151 0050.5660.9412 10.0.0.2 1w0d 00:00:31
cluster-N7k6-OTV#
站点间集群示例
以下示例显示支持的集群部署。
具有站点特定的 MAC 和 IP 地址的跨区以太网通道路由模式示例
以下示例显示了 2 个集群成员,这两个集群成员分别位于 2 个部署在每个站点上的网关路由器和内部网络之间(东西插入)的数据中心。集群成员由集群控制链路通过 DCI 连接。位于每个站点的集群成员使用面向内部和外部网络的跨区以太网通道连接到本地交换机。每个 EtherChannel 跨越集群中的所有机箱。
数据 VLAN 使用重叠传输虚拟化 (OTV) 或类似技术在站点之间扩展。您必须添加阻止全局 MAC 地址的过滤器,防止发往集群的流量通过 DCI 发送到另一站点。如果无法访问一个站点上的集群节点,则您必须删除过滤器,使流量能够发送到另一站点的集群节点。您应使用 VACL 来过滤全局 MAC 地址。对于某些交换机(例如具有 F3 系列线卡的 Nexus),您还必须使用 ARP 检查屏蔽来自全局 MAC 地址的 ARP 数据包。ARP 检查要求您在 ASA 上设置站点 MAC 地址和站点 IP 地址。如果仅配置站点 MAC 地址,请禁用 ARP 检查。
集群相当于内部网络的网关。所有集群节点共享的全局虚拟 MAC 仅用于接收数据包。传出数据包使用来自每个 DC 集群的站点特定的 MAC 地址。此功能可防止交换机从两个不同端口上的两个站点获知相同全局 MAC 地址,导致 MAC 地址摆动;相反,它们仅获知站点 MAC 地址。
在此场景中:
-
从集群发送的所有出口数据包使用站点 MAC 地址,并在数据中心进行本地化。
-
发送到集群的所有入口数据包使用全局 MAC 地址发送,因此可以被两个站点的任何节点接收;OTV 的过滤器将数据中心内的流量本地化。
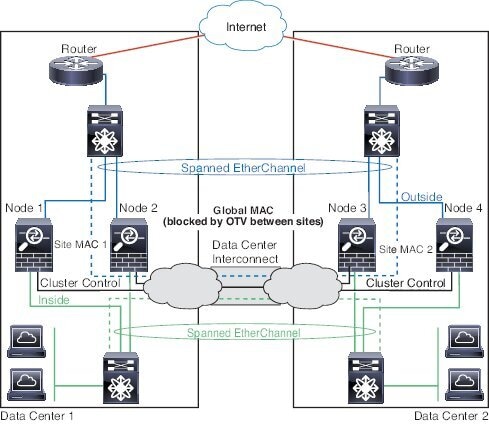
跨区以太网通道透明模式南北站点间集群示例
以下示例显示了 2 个集群成员,这两个集群成员分别位于 2 个部署在内部和外部路由器之间(南北插入)的数据中心。集群成员由集群控制链路通过 DCI 连接。位于每个站点的集群成员使用面向内部和外部的跨区以太网通道连接到本地交换机。每个 EtherChannel 跨越集群中的所有机箱。
位于每个数据中心的内部和外部路由器均使用 OSPF(可通过透明的 ASA)。与 MAC 地址不同,路由器 IP 地址在所有路由器上都是唯一的。通过指定 DCI 中开销较高的路由,可将流量保持在每个数据中心内,除非给定站点上的所有集群成员都中断连接。通过 ASA 的开销较低的路由必须经过位于每个站点的同一网桥组才能使集群维持非对称连接。如果位于一个站点的所有集群成员都发生故障,流量将从每台路由器通过 DCI 发往位于另一个站点的集群成员。
位于每个站点的交换机的实施可包括:
-
站点间 VSS、vPC、StackWise 或 StackWise Virtual - 在此情景中,一台交换机安装在数据中心 1,另一台交换机安装在数据中心 2。一个方案是将位于每个数据中心的集群节点只连接到本地交换机,而冗余交换机流量通过 DCI 传输。在此情况下,连接多半会保持在每个数据中心本地。如果 DCI 可以处理额外的流量,您也可以选择将每个节点通过 DCI 连接到两台交换机。在此情况下,流量跨数据中心分摊,因此 DCI 必须非常强健稳定。
-
位于每个站点的本地 VSS、vPC、StackWise 或 StackWise Virtual - 为了获得更高的交换机冗余能力,您可以在每个站点安装 2 对单独的冗余交换机。在此情况下,尽管集群节点仍然有一个跨区以太网通道将数据中心 1 的机箱仅连接到两台本地交换机,将数据中心 2 的机箱连接到本地交换机,但跨区以太网通道本质上是“分离的”。每个本地冗余交换机系统都会将跨区以太网通道视作站点本地的 EtherChannel。
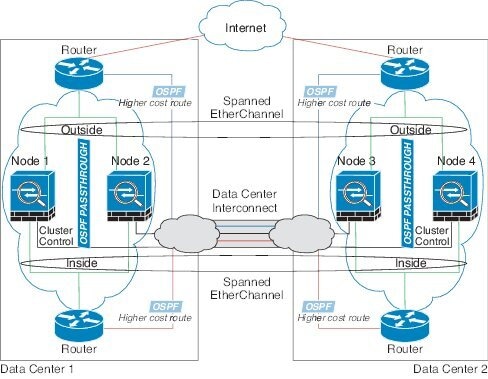
跨区以太网通道 透明模式东西站点间集群示例
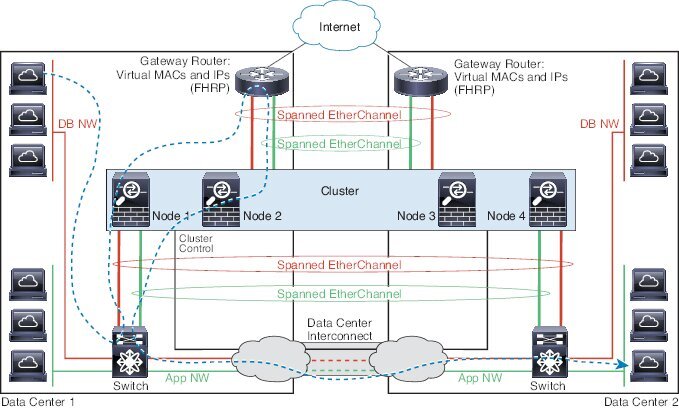
以下示例显示了 2 个集群成员,这两个集群成员分别位于 2 个部署在每个站点上的网关路由器和两个内部网络(应用网络和数据库网络)之间(东西插入)的数据中心。集群成员由集群控制链路通过 DCI 连接。每个站点上的集群成员使用面向内部与外部应用网络和数据库网络的跨区以太网通道连接到本地交换机。每个 EtherChannel 跨越集群中的所有机箱。
每个站点上的网关路由器使用 FHRP(例如 HSRP)在每个站点上提供相同的目标虚拟 MAC 和 IP 地址。要避免 MAC 地址意外摆动,最好使用使用 mac-address-table static outside_interface mac_address 命令将网关路由器实际 MAC 地址静态添加到 ASA MAC 地址表。如果没有这些条目,当位于站点 1 的网关与位于站点 2 的网关通信时,流量可能通过 ASA 并尝试从内部接口到达站点 2,从而导致出现问题。数据 VLAN 使用重叠传输虚拟化 (OTV) 或类似技术在站点之间扩展。您必须添加过滤器,阻止发往网关路由器的流量通过 DCI 发送到另一站点。如果无法访问一个站点上的网关路由器,则您必须删除过滤器,使流量能够发送到另一站点的网关路由器。
集群参考
本部分包括有关集群工作原理的详细信息。
ASA 功能和集群
部分 ASA 功能不受 ASA 集群支持,还有部分功能仅在控制节点上受支持。其他功能可能对如何正确使用规定了注意事项。
集群不支持的功能
以下功能在启用集群的情况下无法配置,相关命令会被拒绝。
-
依靠 TLS 代理实现的统一通信功能
-
远程访问 VPN(SSL VPN 和 IPsec VPN)
-
虚拟隧道接口 (VTI)
-
以下应用检查:
-
CTIQBE
-
H323、H225 和 RAS
-
IPsec 穿透
-
MGCP
-
MMP
-
RTSP
-
SCCP(瘦客户端)
-
WAAS
-
WCCP
-
-
僵尸网络流量过滤器
-
自动更新服务器
-
DHCP 客户端、服务器和代理。支持 DHCP 中继。
-
VPN 负载均衡
-
Azure 上的故障转移
-
集成路由和桥接
-
FIPS 型号
集群集中化功能
以下功能只有在控制节点上才受支持,且无法为集群扩展。
注 |
集中功能的流量从成员节点通过集群控制链路转发到控制节点。 如果使用再均衡功能,则会先将集中功能的流量再均衡到非控制节点的设备,然后再将该流量归类为集中功能;如果发生此情况,该流量随后将被发送回控制节点。 对集中功能而言,如果控制节点发生故障,则所有连接都将断开,而您必须在新的控制节点上重新建立连接。 |
-
以下应用检查:
-
DCERPC
-
ESMTP
-
IM
-
NetBIOS
-
PPTP
-
RADIUS
-
RSH
-
SNMP
-
SQLNET
-
SUNRPC
-
TFTP
-
XDMCP
-
-
静态路由监控
-
网络访问的身份验证和授权。记帐被分散。
-
筛选服务
-
站点间 VPN
-
IGMP 组播控制平面协议的处理(数据平面转发分布于整个集群中)
-
PIM 组播控制平面协议的处理(数据平面转发分布于整个集群中)
-
动态路由
应用到单个节点的功能
这些功能将应用到每个 ASA 节点而非整个集群或控制节点。
-
QoS - QoS 策略将于配置复制过程中在集群中同步。但是,该策略是在每个节点上独立执行。例如,如果对输出配置管制,则要对流出特定 ASA 的流量应用符合规则的速率和符合规则的突发量值。在包含 3 个节点且流量均衡分布的集群中,符合规则的速率实际上变成了集群速率的 3 倍。
-
威胁检测 - 威胁检测在各节点上独立工作;例如,排名统计信息就要视具体节点而定。以端口扫描检测为例,由于扫描的流量将在所有节点间进行负载均衡,而一个节点无法看到所有流量,因此端口扫描检测无法工作。
-
资源管理 - 多情景模式下的资源管理根据本地使用情况在每个节点上分别执行。
-
LISP 流量 - UDP 端口 4342 上的 LISP 流量由每个接收节点进行检查,但是没有为其分配导向器。每个节点都会添加到集群共享的 EID 表,但是 LISP 流量本身并不参与集群状态共享。
用于网络访问的 AAA 和集群
用于网络访问的 AAA 由三部分组成:身份验证、授权和记账。身份验证和授权作为集中功能在集群控制节点上实施,且数据结构复制到集群数据节点。如果选举出控制节点,新的控制节点将拥有所需的所有信息,以继续不间断运行经过验证的既有用户及其相关授权。当控制节点发生变化时,用户身份验证的空闲和绝对超时将保留。
记账作为分散的功能在集群中实施。记账按每次流量完成,因此在为流量配置记账时,作为流量所有者的集群节点会将记账开始和停止消息发送到 AAA 服务器。
连接设置和集群
连接限制在集群范围强制实施(请参阅 set connection conn-max 、set connection embryonic-conn-max 、set connection per-client-embryonic-max 和 set connection per-client-max 命令)。每个节点都有根据广播消息估计的集群范围的计数器值。出于效率考虑,在集群中配置的连接限制可能不会严格按限制数量实施。每个节点在任何指定时间都可能高估或低估集群范围内的计数器值。不过,在负载均衡的集群中,该信息将随时间而更新。
FTP 和集群
-
如果 FTP 数据通道和控制通道流量由不同的集群成员所有,则数据通道所有者会将空闲超时更新定期发送到控制通道所有者并更新空闲超时值。但是,如果重新加载控制流量所有者并重新托管控制流量,则不会再保持父/子流量关系;控制流量空闲超时不会更新。
-
如果您将 AAA 用于 FTP 访问,则控制通道流集中在控制节点上。
ICMP检测和集群
ICMP 和 ICMP 错误数据包通过集群的流取决于是否启用 ICMP/ICMP 错误检查。不启用 ICMP 检查时,ICMP 是单向流,并且不支持导向器流。启用 ICMP 检查时,ICMP 流变为双向流,并由导向器/备份流支持。被检查的 ICMP 流的一个不同之处在于导向器对转发数据包的处理:导向器会将 ICMP 回应应答数据包转发给流所有者,而不是将数据包返回给转发器。
组播路由和集群
跨区以太网通道模式下的组播路由
在跨区以太网通道模式下:控制单元负责处理所有组播路由数据包和数据包,直到建立快速路径转发为止。在连接建立之后,每台数据设备都可以转发组播数据包。
NAT 和集群
NAT 可能会影响集群的总吞吐量。入站和出站 NAT 数据包可被发送到集群中不同的 ASA,因为负载均衡算法取决于 IP 地址和端口,NAT 会导致入站和出站数据包具有不同的 IP 地址和/或端口。当数据包到达并非 NAT 所有者的 ASA时,会通过集群控制链路转发到所有者,导致集群控制链路上存在大量流量。请注意,接收节点不会创建流向所有者的转发流量,因为 NAT 所有者最终可能不会根据安全和策略检查结果为数据包创建连接。
如果您仍想在集群中使用 NAT,请考虑以下准则:
-
PAT 采用端口块分配 - 请参阅该功能的以下准则:
-
每主机最大流量限制并不针对整个集群,而是单独应用于每个节点。因此,在每主机最大流量限制配置为 1 的包含 3 个节点的集群中,如果在全部 3 个节点上对来自主机的流量实行负载均衡,则可以分配 3 个端口块,每个节点 1 个。
-
在执行每主机最大流量限制时,在备份池中的备份节点上创建的端口块不计算在内。
-
如果进行即时 PAT 规则修改(对 PAT 池改用全新的 IP 地址范围),会导致在新的池生效时仍在传输的转换项备份请求的转换项备份创建失败。此行为并非端口块分配功能所特有,它是一个暂时性 PAT 池问题,只发现于在集群节点之间分配池并执行流量负载均衡的集群部署。
-
在集群中操作时,不能直接更改块分配大小。只有在集群中重新加载每个设备后,新的大小才会生效。为避免重新加载每个设备,我们建议您删除所有块分配规则并清除与这些规则相关的所有转换。然后,您可以更改块大小并重新创建块分配规则。
-
-
对动态 PAT 使用 NAT 池地址分配 - 配置 PAT 池时,集群将池中的每个 IP 地址划分为端口块。默认情况下,每个块都是 512 个端口,但如果配置端口块分配规则,则使用块设置。这些块在集群中的各个节点之间均匀分配,因此每个节点都有一个或多个块对应 PAT 池中的每个 IP 地址。因此,在一个集群的 PAT 池中可以最少拥有一个 IP 地址,只要这足以支持您预期的 PAT 连接数即可。端口块覆盖的端口范围为 1024-65535,除非您在 PAT 池 NAT 规则中配置该选项以包含保留的端口 1-1023。
-
在多个规则中重复使用 PAT 池 - 要在多条规则中使用同一 PAT 池,必须注意规则中的接口选择。必须在所有规则中使用特定接口,或者在所有规则中使用“任意”接口。不能在规则中混合使用特定接口和“任意”接口,否则系统可能无法将返回流量与集群中的正确节点进行匹配。每条规则使用唯一的 PAT 池是最可靠的方案。
-
不使用轮询 - 集群不支持 PAT 池轮询。
-
无扩展 PAT - 集群不支持扩展 PAT。
-
控制节点管理的动态 NAT 转换 - 控制节点保留转换表并复制到数据节点。当数据节点收到需要动态 NAT 的连接并且转换不在表中时,它将请求从控制节点转换。数据节点拥有该连接。
-
过时 xlate - 连接所有者上的 xlate 空闲时间不会更新。因此,空闲时间值可能会超过空闲超时值。如果空闲计时器值高于配置的超时值(refcnt 为 0),则表示 xlate 过时。
-
每会话 PAT 功能 - 每会话 PAT 功能并非集群专用功能,但它能提高 PAT 的可扩展性,而且对集群而言,它允许每个数据节点成为 PAT 连接的所有者;相比之下,多会话 PAT 连接则必须转发到控制节点并由控制节点所有。默认情况下,所有 TCP 流量和 UDP DNS 流量均使用每会话 PAT 转换,而 ICMP 和所有其他 UDP 流量均使用多会话。您可以为 TCP 和 UDP 配置每会话 NAT 规则以更改这些默认设置,但是,您不能为 ICMP 配置每会话 PAT。对于使用多会话 PAT 的流量(例如 H.323、SIP 或 Skinny),您可以禁用关联 TCP 端口的每会话 PAT(这些 H.323 和 SIP 的 UDP 端口已默认为多会话)。有关每会话 PAT 的详细信息,请参阅防火墙配置指南。
-
对以下检查不使用静态 PAT:
-
FTP
-
PPTP
-
RSH
-
SQLNET
-
TFTP
-
XDMCP
-
SIP
-
-
如果您有大量 NAT 规则(超过一万条),则应使用设备 CLI 中的 asp rule-engine transactional-commit nat 命令启用事务提交模型。否则,节点可能无法加入集群。
动态路由和集群
本部分介绍如何使用动态路由和集群。
跨区以太网通道模式下的动态路由
注 |
跨区以太网通道模式不支持 IS-IS。 |
路由过程仅在控制节点上运行,并且通过控制节点学习路线后复制到数据节点。如果路由数据包到达数据节点,它将重定向到控制节点。
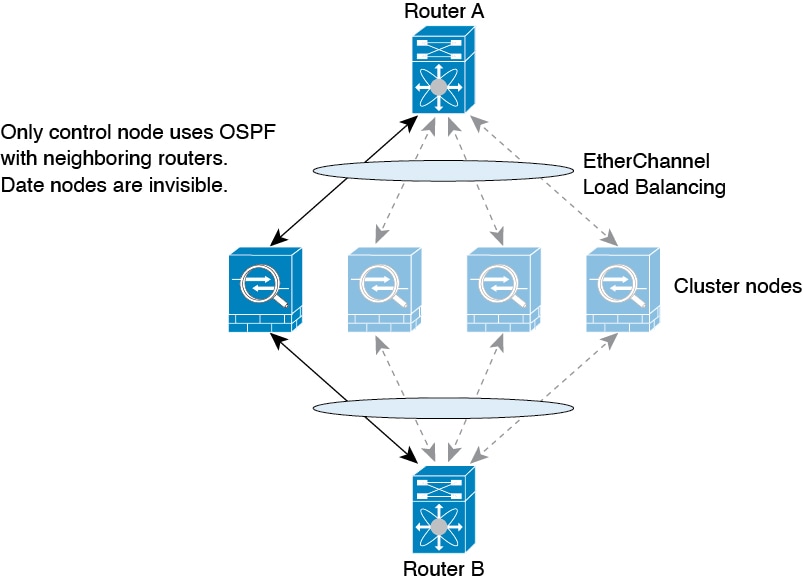
在数据节点向控制节点学习路线后,每个节点将单独做出转发决策。
OSPF LSA 数据库不会从控制节点同步到数据节点。如果切换了控制节点,邻近路由器将检测到重新启动;切换是不透明的。OSPF 进程将挑选一个 IP 地址作为其路由器 ID。您可以分配一个静态路由器 ID,尽管不要求这样做,但这可以确保整个集群中使用的路由器 ID 一致。请参阅 OSPF 无间断转发功能,解决中断问题。
SCTP 和集群
SCTP 关联可以在任何节点上创建(由于负载均衡),但其多宿主连接必须位于同一节点上。
SIP 检测和集群
控制流可以在任何节点上创建(由于负载均衡),但其子数据流必须位于同一节点上。
不支持 TLS 代理配置。
SNMP 和集群
SNMP 代理按照本地 IP 地址轮询每一个ASA。您无法轮询集群的合并数据。
您应始终使用本地地址而非主集群 IP 地址进行 SNMP 轮询。如果 SNMP 代理轮询主集群 IP 地址,则当选举出新的控制节点时,对新控制节点的轮询将失败。
当使用 SNMPv3 进行集群时,如果您在初始集群形成后添加新的集群节点,则 SNMPv3 用户不会复制到新节点。您必须在控制节点上重新添加它们以强制用户复制到新节点,或者直接在数据节点上复制。
STUN 和集群
故障转移和集群模式支持 STUN 检查,因为针孔被复制。但是,节点之间不进行事务 ID 的复制。如果节点在收到 STUN 请求后发生故障,并且另一个节点收到 STUN 响应,则该 STUN 响应将被丢弃。
系统日志与 NetFlow 和集群
-
系统日志 - 集群中的每个节点都会生成自己的系统日志消息。您可以配置日志记录,使每个节点在系统日志消息的报头字段中使用相同或不同的设备 ID。例如,集群中的所有节点都会复制和共享主机名配置。如果将日志记录配置为使用主机名作为设备 ID,则所有节点生成的系统日志消息都会看似来自一个节点。如果将日志记录配置为使用集群引导程序配置中指定的本地节点名称作为设备 ID,系统日志消息就会看似来自不同节点。
-
NetFlow - 集群中的每个节点都会生成自己的 NetFlow 数据流。NetFlow 收集器只能将每台 ASA 视为单独的 NetFlow 导出器。
思科 TrustSec 和集群
只有控制节点学习安全组标记 (SGT) 信息。然后,控制节点将 SGT 填充到数据节点,数据节点可以根据安全策略对 SGT 做出匹配决策。
VPN 和集群
站点间 VPN 是集中功能;只有控制节点支持 VPN 连接。
注 |
集群不支持远程访问 VPN。 |
VPN 功能仅限控制节点使用,且不能利用集群的高可用性功能。如果控制节点发生故障,所有现有的 VPN 连接都将断开,VPN 用户将遇到服务中断。选择新的控制节点后,必须重新建立 VPN 连接。
将 VPN 隧道连接到跨网络 EtherChannel 地址时,连接会自动转移到控制节点。
与 VPN 相关的密钥和证书将被复制到所有节点。
性能换算系数
将多台设备组成一个集群时,预计可以达到近似 80% 最大组合吞吐量的集群总体性能。
例如,如果您的型号在单独运行时可以处理大约 10 Gbps 的流量,则对于 8 台设备的集群,最大组合吞吐量约为 80 Gbps(8 台设备 x 10 Gbps)的 80%:64 Gbps。
控制节点选择
集群节点通过集群控制链路通信,如下选举控制节点:
-
当为节点启用集群(或当节点首次启动时已启用集群)时,设备会每 3 秒广播一个选举请求。
-
具有较高优先级的任何其他设备都会响应选举请求;优先级设置在 1 和 100 之间,其中 1 为最高优先级。
-
如果某节点在 45 秒后未收到另一个具有较高优先级的节点的响应,则该设备会成为控制节点。
注
如果多个节点并列获得最高优先级,则使用集群节点名称和序列号确定控制节点。
-
如果节点稍后加入具有更高优先级的集群,它不会自动成为控制节点;现有控制节点始终保持为控制节点,除非它停止响应,此时会选择新的控制节点。
-
在“裂脑”场景中,当临时存在多个控制节点时,具有最高优先级的节点将会保留角色,而其他节点则恢复为数据节点角色。
注 |
您可以手动强制节点成为控制节点。对集中功能而言,如果强制更改控制节点,则所有连接都将断开,而您必须在新的控制节点上重新建立连接。 |
集群中的高可用性
集群通过监控节点和接口的运行状况并在节点之间复制连接状态来提供高可用性。
节点运行状况监控
每个节点通过集群控制链路定期发送广播保持连接心跳数据包。如果控制节点在可配置的超时期限内未从数据节点接收任何keepalive心跳数据包或其他数据包,则控制节点会从集群中删除该数据节点。如果数据节点未从控制节点接收数据包,则从其余节点中选择新的控制节点。
如果节点因为网络故障而不是因为节点实际故障而无法通过集群控制链路相互访问,则集群可能会进入“裂脑”场景,其中隔离的数据节点将选择自己的控制节点。例如,如果路由器在两个集群位置之间发生故障,则位于位置1的原始控制节点将从集群中删除位置2数据节点。同时,位置2的节点将选择自己的控制节点并形成自己的集群。请注意,在这种情况下,非对称流量可能会失败。恢复集群控制链路后,优先级较高的控制节点将保留控制节点的角色。
有关详细信息,请参阅控制节点选择。
接口监控
每个节点都会监控使用中的所有已命名的硬件接口的链路状态,并向控制节点报告状态更改。
-
跨网络 EtherChannel - 使用集群链路聚合控制协议 (cLACP)。每个节点都会监控链路状态和 cLACP 协议消息,以便确定 EtherChannel 中的端口是否仍处于活动状态。状态会报告给控制节点。
当您启用运行状况监控时,默认情况下会监控所有物理接口(包括主要的 EtherChannel);您可以选择按接口禁用监控。只能监控已命名接口。例如,已命名的 EtherChannel 必须发生故障,才能将其视为发生故障,这意味着 EtherChannel 的所有成员端口必须发生故障才能触发集群删除(具体取决于您的最小端口绑定设置)。
如果某个节点被监控的接口发生故障,则将从集群中删除该设备。ASA 在多长时间后从集群中删除成员取决于该节点是既定成员还是正在加入集群的设备。如果既定成员上的接口关闭,ASA 将在 9 秒后删除该成员。ASA 在节点加入集群后的最初 90 秒不监控接口。在此期间的接口状态更改不会导致 ASA从集群中删除。如果是非 EtherChannel,则无论节点的成员状态如何,都会在 500 毫秒后删除设备。
发生故障后的状态
当集群中的节点发生故障时,该节点承载的连接将无缝转移到其他节点;流量的状态信息将通过控制节点的集群控制链路共享。
如果控制节点发生故障,则优先级最高(数字最小)的另一个集群成员将成为控制节点。
ASA将自动尝试重新加入集群,具体取决于故障事件。
注 |
当 ASA 变成不活动状态且无法自动重新加入集群时,所有数据接口都会关闭,仅管理专用接口可以发送和接收流量。管理接口将保持打开,使用节点从集群 IP 池接收的 IP 地址。但是,如果您重新加载而节点在集群中仍然处于非活动状态,管理接口将被禁用。您必须使用控制台端口来进行任何进一步配置。 |
重新加入集群
当集群节点从集群中删除之后,如何才能重新加入集群取决于其被删除的原因:
-
集群控制链路在 最初加入时出现故障 - 在解决集群控制链路存在的问题后,您必须通过在控制台端口输入 cluster group name ,然后输入 enable重新启用集群 ,以手动重新加入集群。
-
加入集群后出现故障的集群控制链路 - ASA 无限期地每 5 分钟自动尝试重新加入。此行为是可配置的。
-
出现故障的数据接口 - ASA 尝试在 5 分钟时、然后在 10 分钟时、最后在 20 分钟时重新加入。如果 20 分钟后仍加入失败,ASA 将禁用集群。解决数据接口问题之后,您必须在控制台端口上通过输入cluster group name ,然后输入enable 来手动启用集群。此行为是可配置的。
-
节点存在故障 - 如果节点因节点运行状况检查失败而从集群中删除,则如何重新加入集群取决于失败的原因。例如,临时电源故障意味节点将在重新启动时重新加入集群,只要集群控制链路打开并且仍然使用 enable 命令启用集群。ASA 每 5 秒钟尝试重新加入集群。
-
内部错误 - 内部故障包括:应用同步超时;应用状态不一致等。 节点将尝试以下列间隔自动重新加入集群:5 分钟,10 分钟,然后是 20 分钟。此行为是可配置的。
请参阅配置控制节点引导程序设置。
数据路径连接状态复制
每个连接在集群中都有一个所有者和至少一个备用所有者。备用所有者在发生故障时不会接管连接;而是存储 TCP/UDP 状态信息,使连接在发生故障时可以无缝转移到新的所有者。备用所有者通常也是导向器。
有些流量需要 TCP 或 UDP 层以上的状态信息。请参阅下表了解支持或不支持此类流量的集群。
|
流量 |
状态支持 |
备注 |
|---|---|---|
|
运行时间 |
是 |
跟踪系统运行时间。 |
|
ARP 表 |
是 |
- |
|
MAC 地址表 |
是 |
- |
|
用户标识 |
是 |
包括 AAA 规则 (uauth) 。 |
|
IPv6 邻居数据库 |
是 |
— |
|
动态路由 |
是 |
— |
|
SNMP 引擎 ID |
否 |
- |
|
适用于 Firepower 4100/9300的分布式 VPN(站点间) |
是 |
备用会话成为主用会话,并创建一个新的备用会话。 |
集群管理连接的方式
连接可以负载平衡到集群的多个节点。连接角色决定了在正常操作中和高可用性情况下处理连接的方式。
连接角色
请参阅为每个连接定义的下列角色:
-
所有者 - 通常为最初接收连接的节点。所有者负责维护 TCP 状态并处理数据包。一个连接只有一个所有者。如果原始所有者发生故障,则当新节点从连接接收到数据包时,导向器会从这些节点中选择新的所有者。
-
备用所有者 - 存储从所有者接收的 TCP/UDP 状态信息的节点,以便在出现故障时可以无缝地将连接转移到新的所有者。在发生故障时,备用所有者不会接管连接。如果所有者处于不可用状态,从该连接接收数据包的第一个节点(根据负载均衡而定)联系备用所有者获取相关的状态信息,以便成为新的所有者。
只要导向器(见下文)与所有者不是同一节点,导向器也可以是备用所有者。如果所有者选择自己作为导向器,则选择一个单独的备用所有者。
对于 Firepower 9300 上的在一个机箱中包括多达 3 个集群节点的集群,如果备用所有者与所有者在同一机箱上,则将从另一个机箱中选择一个额外的备用所有者来保护流量免受机箱故障的影响。
如果您对站点间集群启用导向器本地化,则有两个备用所有者角色:本地备用和全局备用。所有者始终选择与自身位于同一站点(基于站点 ID)的本地备用。全局备用可以位于任何站点,甚至可以与本地备用是同一个节点。所有者向两个备用所有者发送连接状态信息。
如果启用站点冗余,并且备用所有者与所有者位于同一站点,则将从另一个站点选择一个额外的备用所有者来保护流量免受站点故障的影响。机箱备份和站点备份是独立的,因此流量在某些情况将同时具有机箱备份和站点备份。
-
导向器 - 处理来自转发器的所有者查找请求的节点。当所有者收到新连接时,会根据源/目的 IP 地址和端口的散列值(有关 ICMP 散列详细信息,请参见下文)选择导向器,然后向导向器发送消息来注册该新连接。如果数据包到达除所有者以外的任何其他节点,该节点会向导向器查询哪一个节点是所有者,以便转发数据包。一个连接只有一个导向器。如果导向器发生故障,所有者会选择一个新的导向器。
只要导向器与所有者不是同一节点,导向器也可以是备用所有者(见上文)。如果所有者选择自己作为导向器,则选择一个单独的备用所有者。
如果您对站点间集群启用导向器本地化,则有两个导向器角色:本地导向器和全局导向器。所有者始终选择与它自身位于同一站点(基于站点 ID)的本地导向器。全局导向器可以位于任何站点,甚至可以与本地导向器是同一节点。如果原始所有者发生故障,本地导向器将在同一站点选择新的连接所有者。
ICMP/ICMPv6 散列详细信息:
-
对于 Echo 数据包,源端口为 ICMP 标识符,目的端口为 0。
-
对于 Reply 数据包,源端口为 0,目的端口为 ICMP 标识符。
-
对于其他数据包,源端口和目的端口均为 0。
-
-
转发器 - 向所有者转发数据包的节点。如果转发者收到并非其所有的连接的数据包,则会向导向器查询所有者,然后为其收到的此连接的任何其他数据包建立发往所有者的流量。导向器也可以是转发者。如果启用导向器本地化,转发器将始终向本地导向器查询。如果本地导向器未获知所有者,例如,当集群成员收到所有者位于其他站点上的连接的数据包时,转发者将仅查询全局导向器。请注意,如果转发者收到 SYN-ACK 数据包,它可以从数据包的 SYN Cookie 直接获知所有者,因此无需向导向器查询。(如果禁用 TCP 序列随机化,则不会使用 SYN Cookie;必须向导向器查询。)对于 DNS 和 ICMP 等持续时间极短的流量,转发者不会查询,而是立即将数据包发送到导向器,然后由其发送到所有者。一个连接了可以有多个转发器;采用良好的负载均衡方法可以做到没有转发器,让一个连接的所有数据包都由所有者接收,从而实现最高效率的吞吐量。
注
不建议您在使用集群时禁用 TCP 序列随机化。由于 SYN/ACK 数据包可能会被丢弃,因此少数情况下可能无法建立某些 TCP 会话。
-
分段所有者 - 对于分段的数据包,接收分段的集群节点使用分段源 IP 地址、目的 IP 地址和数据包 ID 的散列确定分段所有者。然后,所有片段都通过集群控制链路转发给片段所有者。片段可能均衡分发给不同的集群节点,因为只有第一个分段包含交换机负载均衡散列中使用的 5 元组。其他片段不包含源端口和目的端口,可能会均衡分发给其他集群节点。片段所有者临时重组数据包,以便根据源/目标 IP 地址和端口的散列来确定导向器。如果是新连接,则片段所有者将注册为连接所有者。如果是现有连接,则片段所有者将所有片段转发给集群控制链路上提供的连接所有者。然后,连接所有者将重组所有片段。
当连接使用端口地址转换 (PAT) 时,PAT 类型(每会话或多会话)会对哪个集群成员将成为新连接的所有者产生影响:
-
每会话 PAT - 所有者是接收连接中的初始数据包的节点。
默认情况下,TCP 和 DNS UDP 流量均使用每会话 PAT。
-
多会话 PAT - 所有者始终是控制节点。如果多会话 PAT 连接最初由数据节点接收,则数据节点会将连接转发给控制节点。
默认情况下,UDP(DNS UDP 除外)和 ICMP 流量使用多会话 PAT,因此这些连接始终归控制节点所有。
您可以更改 TCP 和 UDP 的每会话 PAT 默认设置,以便根据配置按每会话或多会话处理这些协议的连接。对于 ICMP,您不能更改默认的多会话 PAT。有关每会话 PAT 的详细信息,请参阅防火墙配置指南。
新连接所有权
通过负载均衡将新连接定向到集群节点时,该连接的两个方向都由此节点所有。如果该连接有任何数据包到达其他节点,这些数据包都会通过集群控制链路被转发到所有者节点。为了获得最佳性能,对于要到达同一个节点的流量的两个方向以及要在节点之间均摊的流量,都需要执行适当的外部负载均衡。如果反向流量到达其他节点,会被重定向回原始节点。
TCP 的数据流示例
以下图例显示了新连接的建立。
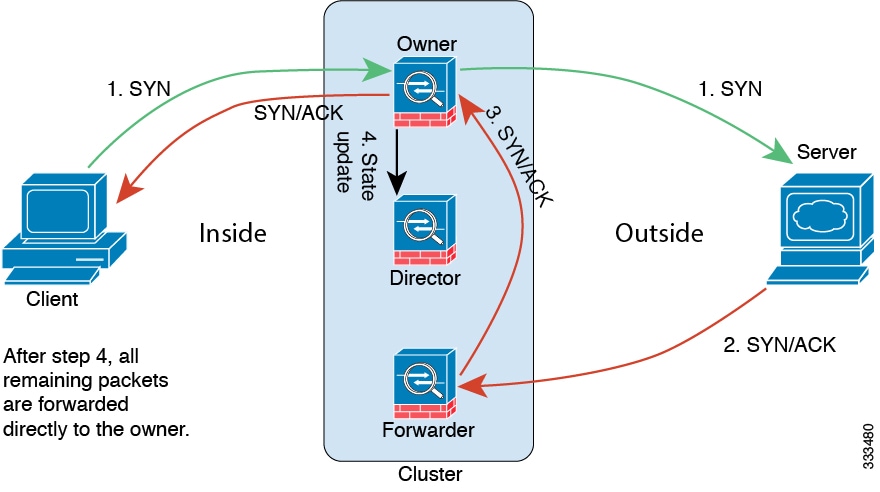
-
SYN 数据包从客户端发出,被传送到一台 ASA(基于负载均衡方法),该设备将成为所有者。所有者创建一个流量,将所有者信息编码为 SYN Cookie,然后将数据包转发到服务器。
-
SYN-ACK 数据包从服务器发出,被传送到一台不同的 ASA(基于负载均衡方法)。此 ASA是转发者。
-
由于转发器不是该连接的所有者,因此它将解码 SYN Cookie 中的所有者信息,然后创建发往所有者的转发流量,并将 SYN-ACK 数据包转发到所有者。
-
所有者将状态更新发送到导向器,然后将 SYN-ACK 数据包转发到客户端。
-
导向器接收来自所有者的状态更新,创建发往所有者的流量,并记录 TCP 状态信息以及所有者。导向器将充当该连接的备用所有者。
-
传送到转发器的任何后续数据包都会被转发到所有者。
-
如果数据包被传送到任何其他节点,它将向导向器查询所有者并建立一个流量。
-
该流量的任何状态更改都会导致所有者向导向器发送状态更新。
ICMP 和 UDP 的数据流示例
以下图例显示了新连接的建立。
-
图 2. ICMP 和 UDP 数据流 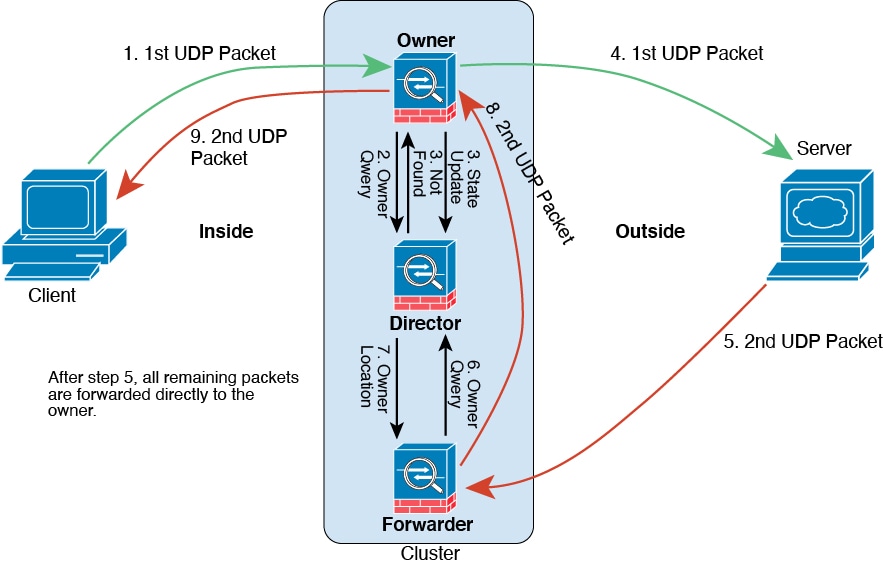
-
收到第一个数据包的节点查询基于源/目的 IP 地址和端口的散列值选择的导向器节点。
-
导向器找不到现有流,创建导向器流并将数据包转发回前一个节点。换句话说,导向器已为此流选择了所有者。
-
所有者创建流,向导向器发送状态更新,然后将数据包转发到服务器。
-
第二个 UDP 数据包从服务器发出,并被传送到转发器。
-
转发器向导向器查询所有权信息。对于 DNS 等持续时间极短的流量,转发者不会查询,而是立即将数据包发送到导向器,然后由其发送到所有者。
-
导向器向转发器回复所有权信息。
-
转发器创建转发流以记录所有者信息,并将数据包转发给所有者。
-
所有者将数据包转发到客户端。
跨集群实现新 TCP 连接再均衡
如果上游或下游路由器的负载平衡功能导致流量分布不平衡,则可以配置新的连接再平衡,这样每秒新连接数较高的节点就会将新 TCP 流量重定向到其他节点。现有流量将不会移至其他节点。
由于此命令仅基于每秒的连接数进行重新平衡,因此不会考虑每个节点上已建立的连接总数,并且连接总数可能并不相等。
将连接分流到其他节点后,它将成为不对称连接。
请勿为站点间拓扑结构配置连接再均衡;您不需要将新的连接再均衡到位于不同站点的集群成员。
Cisco Secure Firewall 3100/4200 的 ASA 集群历史记录
|
功能名称 |
版本 |
功能信息 |
|---|---|---|
|
流状态的可配置集群保持连接间隔 |
9.20(1) |
流所有者向导向器和备份所有者发送保持连接(clu_keepalive 消息)和更新(clu_update 消息),以刷新流状态。您现在可以设置保持连接的间隔。默认值为 15 秒,您也可以将间隔设为 15 到 55 秒。您可能想将间隔设置得更长,以减少集群控制链路上的流量。 新增/修改的命令:clu-keepalive-interval |
|
引入了对 Cisco Secure Firewall 4200上的集群的支持 |
9.20(1) |
在跨区以太网通道模式下,您最多可以对 8 台 Cisco Secure Firewall 4200 节点进行集群。 |
|
删除偏差语言 |
9.19(1) |
包含术语“主”和“从”的命令、命令输出和系统日志消息已被更改为“控制”和“数据”。 新增/修改的命令:cluster control-node 、enable as-data-node 、prompt 、show cluster history 、show cluster info |
|
引入了对 Cisco Secure Firewall 3100上的集群的支持 |
9.17(1) |
在跨区以太网通道模式下,您最多可以对 8 台 Cisco Secure Firewall 3100 节点进行集群。 |
 反馈
反馈